適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
この記事では、Azure Data Factory パイプラインと Synapse Analytics パイプラインでコピー アクティビティを使用して、Amazon Redshift からデータをコピーする方法について説明します。 この記事は、コピー アクティビティの概要を示しているコピー アクティビティの概要に関する記事に基づいています。
Von Bedeutung
Amazon Redshift コネクタ バージョン 2.0 では、ネイティブ Amazon Redshift のサポートが強化されています。 ソリューションで Amazon Redshift コネクタ バージョン 1.0 を使用している場合は、 Amazon Redshift コネクタをアップグレード してください。バージョン 1.0 は サポート終了段階です。 パイプラインは 、2026 年 4 月 30 日以降に失敗します。 バージョン 2.0 とバージョン 1.0 の違いについて詳しくは、こちらのセクションをご覧ください。
サポートされる機能
この Amazon Redshift コネクタは、次の機能でサポートされています。
| サポートされる機能 | IR |
|---|---|
| コピー アクティビティ (ソース/-) | (1) (2) |
| Lookup アクティビティ | (1) (2) |
(1) Azure統合ランタイム (2) セルフホステッド統合ランタイム
コピー アクティビティによってソースまたはシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関する記事の表をご覧ください。
このサービスには、接続を有効にする組み込みのドライバーが用意されているため、ドライバーを手動でインストールする必要はありません。
Amazon Redshift コネクタでは、クエリまたは組み込みの Redshift UNLOAD サポートを使用して Redshift からデータを取得できます。
コネクタは、このarticleのWindowsバージョンをサポートしています。
ヒント
Redshift から大量のデータをコピーするときに最適なパフォーマンスを得るには、Amazon S3 経由で組み込みの Redshift UNLOAD を使用することを検討します。 詳細については、「Amazon Redshift からのデータ コピーでの UNLOAD の使用」セクションをご覧ください。
前提条件
Self-hosted Integration Runtime を使用してオンプレミスのデータ ストアにデータをコピーする場合は、Amazon Redshift クラスターへのアクセスをIntegration Runtime (コンピューターの IP アドレスを使用) を付与します。 手順については、「 クラスターへのアクセスを承認する 」を参照してください。 バージョン 2.0 の場合、セルフホステッド統合ランタイムのバージョンは 5.60 以上である必要があります。
Azure データ ストアにデータをコピーする場合は、Azure データ センターで使用されるコンピューティング IP アドレスと SQL 範囲については、「Azure Data Center の IP 範囲」を参照してください。
データ ストアがマネージド クラウド データ サービスの場合は、Azure Integration Runtimeを使用できます。 アクセスがファイアウォール規則で承認されている IP に制限されている場合は、許可リストに Azure Integration Runtime IP を追加できます。
Azure Data Factoryの 管理された仮想ネットワーク統合ランタイム機能を使用して、セルフホステッド統合ランタイムをインストールして構成することなく、オンプレミス ネットワークにアクセスすることもできます。
作業の開始
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用できます。
- データのコピー ツール
- Azure Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Azure Resource Manager テンプレート
UI を使用して Amazon Redshift にリンク サービスを作成する
Azure ポータル UI で Amazon Redshift へのリンクされたサービスを作成するには、次の手順に従います。
Azure Data Factoryまたは Synapse ワークスペースの [管理] タブを参照し、[リンクされたサービス] を選択し、[新規] をクリックします。
- Azureデータファクトリー
- Azure Synapse
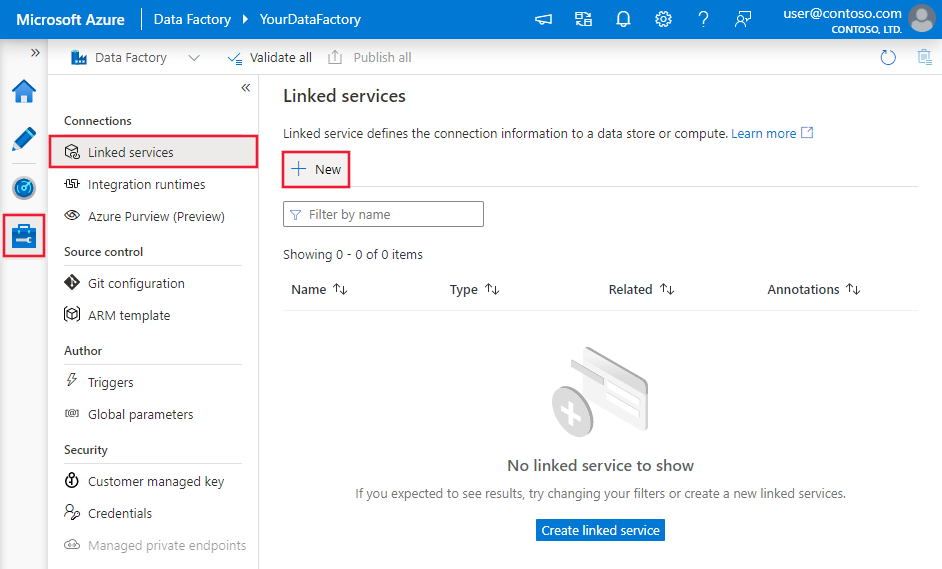
Amazon を検索し、Amazon Redshift コネクタを選択します。
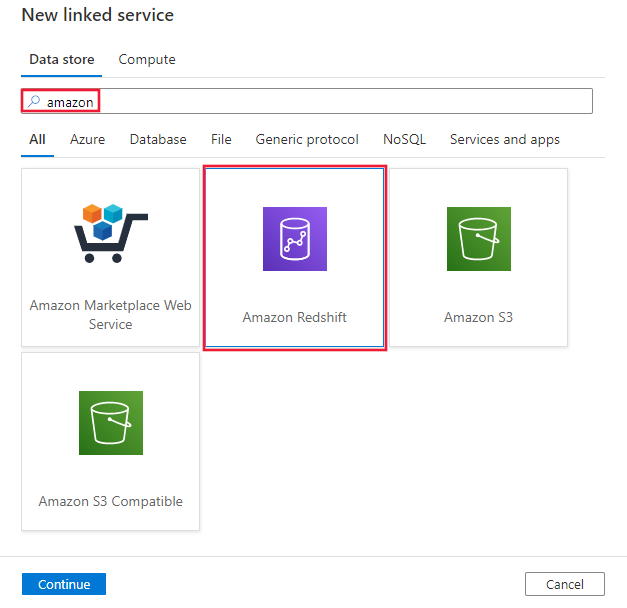
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
次のセクションでは、Amazon Redshift コネクターに固有の Data Factory エンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
Amazon Redshift のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | type プロパティを AmazonRedshiftに設定する必要があります。 | はい |
| バージョン | 指定するバージョン。 | はい (バージョン 2.0 の場合)。 |
| サーバー | Amazon Redshift サーバーの IP アドレスまたはホスト名。 | はい |
| ポート | Amazon Redshift サーバーがクライアント接続のリッスンに使用する TCP ポートの数。 | いいえ (既定値は 5439 です) |
| データベース | Amazon Redshift データベースの名前。 | はい |
| ユーザー名 | データベースへのアクセスを持つユーザーの名前。 | はい |
| パスワード | ユーザー アカウントのパスワード。 このフィールドを SecureString としてマークして安全に格納するか、 |
はい |
| sslmode | Amazon Redshift に接続するときに使用する SSL 証明書検証モード。 このプロパティは、バージョン 2.0 でのみサポートされています。 - Verify_full: SSL、信頼された証明機関、および証明書に一致するサーバー名のみを使用して接続します。 - Verify_ca: SSL と信頼された証明機関のみを使用して接続します。 - 必須: SSL のみを使用して接続します。 - 推奨: 使用可能な場合は、SSL を使用して接続します。 それ以外の場合は、SSL を使用せずに接続します。 - 許可: 既定では、SSL を使用せずに接続します。 サーバーで SSL 接続が必要な場合は、SSL を使用します。 - 無効: SSL を使用せずに接続します。 オプション: verify-full (既定値) / verify-ca / require / prefer / allow / disable |
いいえ。既定値は verify-full |
| connectVia (接続ビア) | データ ストアへの接続に使用するIntegration Runtime。 Azure Integration Runtimeまたはセルフホステッド Integration Runtimeを使用できます (データ ストアがプライベート ネットワークにある場合)。 指定しない場合は、既定のAzure Integration Runtimeが使用されます。 | いいえ |
注
バージョン 2.0 では、Azure Integration Runtimeおよびセルフホステッド Integration Runtime バージョン 5.60 以降がサポートされています。 セルフホステッド Integration Runtime バージョン 5.60 以降では、ドライバーのインストールは必要なくなりました。
例: バージョン 2.0
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"version": "2.0",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: バージョン 1.0
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。 このセクションでは、Amazon Redshift データセットでサポートされるプロパティの一覧を示します。
Amazon Redshift からのデータ コピーについては、次のプロパティがサポートされています。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | データセットの type プロパティは、AmazonRedshiftTable に設定する必要があります | はい |
| スキーマ | スキーマの名前。 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
| テーブル | テーブルの名前。 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
| テーブル名 | スキーマがあるテーブルの名前。 このプロパティは下位互換性のためにサポートされています。 新しいワークロードでは、schema と table を使用します。 |
いいえ (アクティビティ ソースの "query" が指定されている場合) |
例
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
RelationalTable 型のデータセットを使用していた場合、現状のまま引き続きサポートされますが、今後は新しいものを使用することをお勧めします。
Copy アクティビティ のプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、Amazon Redshift ソースでサポートされるプロパティの一覧を示します。
ソースとしての Amazon Redshift
Amazon Redshift からデータをコピーするには、コピー アクティビティでソースの型を AmazonRedshiftSource に設定します。 コピー アクティビティの source セクションでは、次のプロパティがサポートされます。
| プロパティ | 説明 | 必須 |
|---|---|---|
| 型 | コピー アクティビティのソースの type プロパティを AmazonRedshiftSource に設定する必要があります。 | はい |
| クエリ | カスタム クエリを使用してデータを読み取ります。 例: Select * from MyTable。 | いいえ (データセットの "tableName" が指定されている場合) |
| redshiftUnloadSettings | Amazon Redshift の UNLOAD を使用する場合のプロパティ グループ。 | いいえ |
| s3LinkedServiceName | リンクされた AmazonS3 型のサービス名を指定することで、中間ストアとして使用される Amazon S3 を参照します。 | アンロードを使用する場合は はい |
| bucketName | 中間データを格納する S3 バケットを指定します。 指定しない場合、サービスによって自動的に生成されます。 | アンロードを使用する場合は はい |
アンロードを使用したコピー アクティビティでの Amazon Redshift ソースの例:
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
次のセクションから、UNLOAD を使用して、効率的に Amazon Redshift からデータをコピーする方法の詳細について説明します。
Amazon Redshift からのデータ コピーで UNLOAD を使用する
UNLOAD は、Amazon Redshift が提供するメカニズムであり、Amazon Simple Storage Service (Amazon S3) 上に 1 つまたは複数のファイルへのクエリの結果をアンロードできます。 これは、Redshift から大きなデータ セットをコピーするために、Amazon から推奨されている方法です。
Example: UNLOAD、ステージングコピー、PolyBase を使用して Amazon Redshift からAzure Synapse Analyticsにデータをコピーします
このサンプルユース ケースでは、コピー アクティビティは"redshiftUnloadSettings" で構成されている Amazon Redshift から Amazon S3 にデータをアンロードし、次に "stagingSettings" で指定されたとおりに Amazon S3 から Azure BLOB にデータをコピーし、最後に PolyBase を使用してデータをAzure Synapse Analyticsに読み込みます。 すべての中間形式が、コピー アクティビティによって正しく処理されます。

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Amazon Redshift のデータ型マッピング
Amazon Redshift からデータをコピーする場合、Amazon Redshift のデータ型からサービスで使用される内部データ型へのマッピングが次のように適用されます。 コピー アクティビティでソースのスキーマとデータ型がシンクにマッピングされるしくみについては、スキーマとデータ型のマッピングに関する記事を参照してください。
| Amazon Redshift のデータ型 | 中間サービスのデータ型 (バージョン 2.0 の場合) | 中間サービスのデータ型 (バージョン 1.0 の場合) |
|---|---|---|
| bigint | Int64 | Int64 |
| ブーリアン | ブール値 | 糸 |
| CHAR | 糸 | 糸 |
| 日付 | 日付と時間 | 日付と時間 |
| DECIMAL (精度 <= 28) | Decimal | Decimal |
| DECIMAL (有効桁数 > 28) | 糸 | 糸 |
| 倍精度 | Double | Double |
| 整数 | Int32 | Int32 |
| real | シングル | シングル |
| SMALLINT | Int16 | Int16 |
| [TEXT] | 糸 | 糸 |
| timestamp | 日付と時間 | 日付と時間 |
| VARCHAR | 糸 | 糸 |
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
Amazon Redshift コネクタのライフサイクルとアップグレード
次の表は、Amazon Redshift コネクタのさまざまなバージョンのリリース ステージと変更ログを示しています。
| Version | リリース段階 | 変更ログ |
|---|---|---|
| バージョン 1.0 | サポート終了が発表されました | / |
| バージョン 2.0 | GA バージョンあり | • Azure Integration Runtimeおよびセルフホステッド Integration Runtime バージョン 5.60 以降をサポートします。 セルフホステッド Integration Runtime バージョン 5.60 以降では、ドライバーのインストールは必要なくなりました。 • BOOLEAN はブール型として読み取られます。 • リンクされたサービスでの sslmode のサポート。 |
Amazon Redshift コネクタをバージョン 1.0 からバージョン 2.0 にアップグレードする
[ リンクされたサービスの編集] ページで、バージョン 2.0 を選択し、リンクされたサービスプロパティを参照して リンクされたサービスを構成します。
Amazon Redshift のリンクされたサービス バージョン 2.0 のデータ型マッピングは、バージョン 1.0 とは異なります。 最新のデータ型マッピングについては、「 Amazon Redshift のデータ型マッピング」を参照してください。
バージョン 5.60 以上のセルフホステッド統合ランタイムを適用します。 セルフホステッド Integration Runtime バージョン 5.60 以降では、ドライバーのインストールは必要なくなりました。
関連コンテンツ
Copy アクティビティでソースおよびシンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。