適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
この記事では、データセットとは何か、JSON 形式で定義される方法、およびデータセットが Azure Data Factory および Synapse パイプラインでどのように使用されるかについて説明します。
Data Factory を初めて使用する場合は、
概要
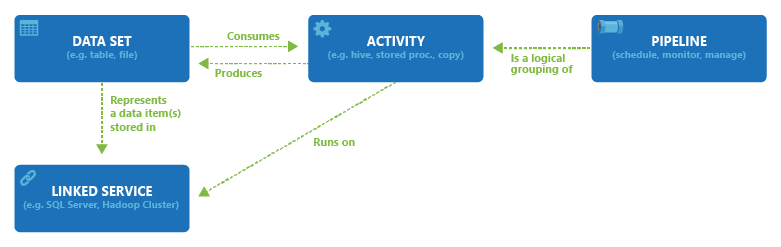
Azure Data Factoryワークスペースまたは Synapse ワークスペースには、1 つ以上のパイプラインを含めることができます。 パイプラインは、1 つのタスクを連携して実行するアクティビティの論理的なグループです。 パイプライン内の複数のアクティビティは、データに対して実行するアクションを定義します。 ここで、データセットとは、アクティビティで入力と出力として使用するデータを単に指定または参照するデータの名前付きビューです。 データセットは、テーブル、ファイル、フォルダー、ドキュメントなど、さまざまなデータ ストア内のデータを示します。 たとえば、Azure BLOB データセットは、アクティビティがデータを読み取るBlob Storage内の BLOB コンテナーとフォルダーを指定します。
データセットを作成する前に、リンクされたサービスを作成して、データ ストアをそのサービスにリンクする必要があります。 リンクされたサービスは、接続文字列によく似ており、サービスが外部リソースに接続するために必要な接続情報を定義します。 データセットはリンクされたデータ ストア内のデータの構造を表すもので、リンクされたサービスはデータ ソースへの接続を定義するもの、と捉えることができます。 たとえば、Azure Storageリンクされたサービスは、ストレージ アカウントをリンクします。 Azure BLOB データセットは、処理する入力 BLOB を含む BLOB コンテナーとそのAzure Storage アカウント内のフォルダーを表します。
次に示のはサンプル シナリオです。 BLOB ストレージから SQL Database にデータをコピーするには、Azure Blob StorageとAzure SQL Databaseという 2 つのリンクされたサービスを作成します。 次に、2つのデータセットを作成します。1つは、Azure Blob Storageにリンクされたサービスを参照する区切りテキストデータセット(ソースとしてテキストファイルがあると仮定します)であり、もう1つはAzure SQLデータベースにリンクされたサービスを参照するAzure SQLテーブルデータセットです。 Azure Blob StorageとAzure SQL Databaseのリンクされたサービスには、サービスが実行時にAzure StorageとAzure SQL Databaseに接続するために使用する接続文字列が含まれています。 区切りテキスト データセットは、Blob Storage内の入力 BLOB を含む BLOB コンテナーと BLOB フォルダーを、形式関連の設定と共に指定します。 Azure SQL テーブル データセットは、データのコピー先となる SQL Database 内の SQL テーブルを指定します。
次の図は、パイプライン、アクティビティ、データセット、リンクされたサービスの関係を示しています。
UI を使用して、データセットを作成します。
- Azureデータファクトリー
- Synapse Analytics
Azure Data Factory Studio でデータセットを作成するには、[Author]\(作成\) タブ (鉛筆アイコン付き) を選択し、プラス記号アイコンを選択して Dataset を選択します。
![新しいデータセット ボタンが選択されたAzure Data Factory Studio の [作成者] タブを表示します。](media/concepts-datasets-linked-services/create-dataset.png)
既存または新しいリンクされたサービスを設定するために、Azure Data Factoryで使用可能なコネクタのいずれかを選択するための新しいデータセット ウィンドウが表示されます。
![サポートされているいずれかのデータ ファクトリ コネクタへのリンク サービスの種類を選択できる [新しいデータセット] ウィンドウを示しています。](media/concepts-datasets-linked-services/choose-dataset-source.png)
次に、データセットの形式を選択するように求めるメッセージが表示されます。

最後に、データセットに対して選択した種類の既存のリンクされたサービスを選択するか、サービスがまだ定義されていない場合は新しいサービスを作成できます。
![前に選択した種類の既存のデータセットを選択するか、または新しいデータセットを作成できる [プロパティの設定] ウィンドウを示しています。](media/concepts-datasets-linked-services/choose-or-define-linked-service.png)
データセットを作成したら、Azure Data Factory内の任意のパイプライン内でデータセットを使用できます。
![新しい統合データセット ボタンが選択されたSynapse Studioの [作成者] タブを表示します。](media/concepts-datasets-linked-services/create-dataset-synapse.png)
データセットの JSON
データセットは JSON 形式では次のように定義されます。
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
次の表では、上記の JSON のプロパティについて説明します。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 名前 | データセットの名前。 「キューの名前付け規則」を参照してください。 | はい |
| 型 | データセットの型。 Data Factory でサポートされている型のいずれかを指定します (たとえば、DelimitedText、AzureSqlTable)。 詳細については、データセットの型を参照してください。 |
はい |
| スキーマ | データセットのスキーマは、実際のデータ型と形状を表します。 | いいえ |
| タイププロパティ | 型のプロパティは型によって異なります。 サポートされている型とそのプロパティの詳細については、「データセットの型」セクションを参照してください。 | はい |
データセットのスキーマをインポートするときに、 [スキーマのインポート] ボタンを選択し、ソースまたはローカル ファイルのどちらからインポートするかを選択します。 ほとんどの場合、ソースからスキーマを直接インポートします。 ただしローカル スキーマ ファイルが既にある (Parquet ファイルまたはヘッダー付きの CSV) 場合は、そのファイルのスキーマを基に、サービスに指示できます。
コピー アクティビティのデータセットは、ソースとシンクで使用されます。 データセットで定義されているスキーマは、参照用として省略可能です。 ソースとシンクの間に列/フィールド マッピングを適用する場合は、スキーマと型のマッピングに関するページを参照してください。
Data Flowでは、データセットはソース変換とシンク変換で使用されます。 データセットは、基本的なデータ スキーマを定義します。 データがスキーマを持たない場合は、ソースとシンクのスキーマ ドリフトを使用できます。 データセットから取得されたメタデータは、ソース変換でソース プロジェクションとして表示されます。 ソース変換のプロジェクションは、定義された名前と型を持つData Flow データを表します。
データセットの型
サービスでは、使用するデータ ストアに応じて、さまざまな種類のデータセットがサポートされています。 サポートされているデータ ストアの一覧については、コネクタの概要に関する記事を参照してください。 データ ストアを選択すると、それに対応するリンクされたサービスとデータセットの作成方法を確認できます。
たとえば、区切りテキスト データセットの場合、次の JSON サンプルに示すように、データセットの型は DelimitedText に設定されます。
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
注意
スキーマ値は JSON 構文を使用して定義されます。 スキーマ マッピングとデータ型マッピングの詳細については、Azure Data Factoryコピー アクティビティスキーマと型マッピングドキュメントを参照してください。
データセットを作成する
データセットは、.NET API、PowerShell、REST API、Azure Resource Manager テンプレート、Azure ポータルのいずれかを使用して作成できます。
最新バージョンとバージョン 1 のデータセットの比較
Data Factory の現在のバージョン (およびAzure Synapse) のデータセットと、従来の Data Factory バージョン 1 の違いを次に示します。
- 外部プロパティは最新バージョンではサポートされません。 トリガーに置き換えられます。
- ポリシーと可用性のプロパティは、最新バージョンではサポートされません。 パイプラインの開始時刻は、トリガーによって異なります。
- 範囲指定されたデータセット (パイプラインで定義されたデータセット) は、最新バージョンではサポートされません。
関連するコンテンツ
クイックスタート
これらのツールや SDK のいずれかを使用してパイプラインとデータセットを作成する詳しい手順については、次のチュートリアルを参照してください。
Quickstart: .NET - クイック スタート: PowerShell を使用してデータ ファクトリを作成する
- クイック スタート: REST API を使用してデータ ファクトリを作成する
Quickstart: Azure ポータル