Azure Databricks 上の RAG (取得拡張生成)
重要
この機能はパブリック プレビュー段階にあります。
エージェント フレームワークは、開発者が取得拡張生成 (RAG) アプリケーションなどの運用品質の AI エージェントを構築、配置、評価するために支援するように設計された Databricks 上の一連のツールで構成されます。
この記事では、RAG とは何か、そして Azure Databricks で RAG アプリケーションを開発する利点について説明します。
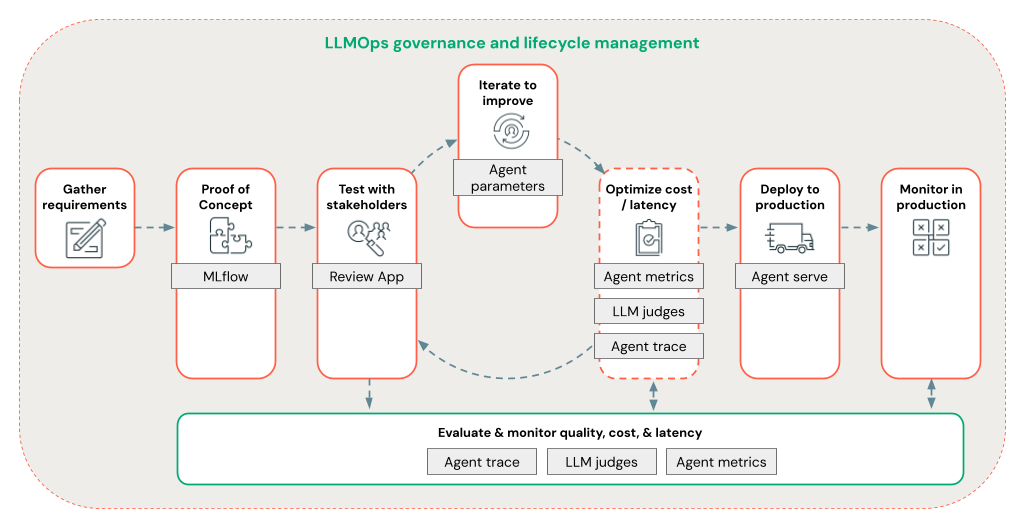
エージェント フレームワークを使用すると、開発者はエンド ツー エンドの LLMOps ワークフローを使用して RAG 開発のあらゆる側面をすばやく反復処理できます。
- Azure AI 搭載の AI 支援機能をワークスペースで有効にする必要があります。
- エージェント アプリケーションのすべてのコンポーネントは、1 つのワークスペース内に存在する必要があります。 たとえば、RAG アプリケーションの場合、提供モデルとベクトル検索インスタンスは同じワークスペース内に存在する必要があります。
RAG は、外部知識によって大規模言語モデル (LLM) を強化する生成 AI 設計手法です。 この手法は、次の方法で LLM を改善します。
- 独自の知識: RAG には、分野固有の質問に回答するためのメモ、メール、ドキュメントなど、最初は LLM のトレーニングに使用されなかった独自の情報を含めることができます。
- 最新の情報: RAG アプリケーションは、更新されたデータ ソースからの情報を LLM に提供できます。
- ソースの引用: RAG を使用すると、LLM は特定のソースを引用できるので、ユーザーは応答の実際の精度を確認できます。
- データ セキュリティとアクセス制御リスト (ACL): 取得手順は、ユーザー資格情報に基づいて個人または独自の情報を選択的に取得するように設計できます。
RAG アプリケーションは、複合 AI システムの一例です。LLM の言語機能を他のツールや手順と組み合わせて拡張します。
最も単純な形式では、RAG アプリケーションは次の処理を行います。
- 取得: ユーザーの要求は、ベクトル ストア、テキスト キーワード検索、SQL データベースなどの外部データ ストアのクエリに使用されます。 目標は、LLM の応答のサポート データを取得することです。
- 拡張: 取得したデータはユーザーの要求と組み合わされ、多くの場合、追加の書式設定と指示を含むテンプレートを使用してプロンプトを作成します。
- 生成: プロンプトが LLM に渡され、クエリに対する応答が生成されます。
RAG アーキテクチャは、非構造化または構造化されたサポート データを処理できます。 RAG で使用するデータは、ユース ケースによって異なります。
非構造化データ: 特定の構造や編成のないデータ。 テキストと画像、またはオーディオやビデオなどのマルチメディア コンテンツを含むドキュメント。
- Google/Office ドキュメント
- Wiki
- 画像
- ビデオ
構造化データ: データベース内のテーブルなど、特定のスキーマを持つ行と列に配置された表形式データ。
- BI またはデータ ウェアハウス システム内の顧客レコード
- SQL データベースのトランザクション データ
- アプリケーション API (SAP、Salesforce など) からのデータ
次の各セクションでは、非構造化データ用の RAG アプリケーションについて説明します。
RAG データ パイプラインは、ドキュメントの前処理とインデックス作成を行い、迅速かつ正確な取得を実現します。
次の図は、セマンティック検索アルゴリズムを使用した非構造化データセットのサンプル データ パイプラインを示しています。 Databricks ジョブは各ステップを調整します。

- データ インジェスト - 独自のソースからデータを取り込みます。 このデータを Delta テーブルまたは Unity Catalog ボリュームに保存します。
- ドキュメント処理: Databricks ジョブ、Databricks ノートブック、Delta ライブ テーブルを使用して、これらのタスクを実行できます。
- 生のドキュメントの解析: 生データを使用可能な形式に変換します。 たとえば、PDF のコレクションからテキスト、テーブル、画像を抽出したり、光学式文字認識手法を使用して画像からテキストを抽出したりします。
- メタデータの抽出: 取得手順のクエリをより正確に行うために、ドキュメント タイトル、ページ番号、URL などのドキュメント メタデータを抽出します。
- ドキュメントのチャンク: データを、LLM のコンテキスト ウィンドウに収まるチャンクに分割します。 ドキュメント全体ではなく、これらのフォーカスされたチャンクを取得すると、応答を生成するためのよりターゲットを絞ったコンテンツが LLM に提供されます。
- チャンクの埋め込み - 埋め込みモデルは、チャンクを使用して、ベクトル埋め込みと呼ばれる情報の数値表現を作成します。 ベクトルは、サーフェス レベルのキーワードだけでなく、テキストのセマンティックの意味を表します。 このシナリオでは、埋め込みを自分で計算し、Model Serving を使用して埋め込みモデルを提供できます。
- 埋め込みストレージ - ベクトル埋め込みとチャンクのテキストを、ベクトル検索と同期された Delta テーブルに格納します。
- ベクトル データベース - ベクトル検索の一部として、埋め込みとメタデータはインデックス付けされてベクトル データベースに保存され、RAG エージェントで簡単にクエリできるようになります。 ユーザーがクエリを実行すると、その要求はベクトルに埋め込まれます。 次に、データベースはベクトル インデックスを使用して、最も類似したチャンクを検索して返します。
各ステップには、RAG アプリケーションの品質に影響を与えるエンジニアリング上の決定が含まれます。 たとえば、手順 (3) で適切なチャンク サイズを選択すると、LLM は特定のコンテキスト化された情報を確実に受け取り、手順 (4) で適切な埋め込みモデルを選択すると、取得時に返されるチャンクの精度が決まります。
多くの場合、類似性の計算は計算コストが高くなりますが、Databricks ベクトル検索のようなベクトル インデックスは、埋め込みを効率的に整理することでこれを最適化します。 ベクトル検索では、各埋め込みをユーザーのクエリと個別に比較することなく、最も関連性の高い結果をすばやくランク付けできます。
ベクトル検索は、Delta テーブルに追加された新しい埋め込みを自動的に同期し、ベクトル検索インデックスを更新します。
取得拡張生成 (RAG) エージェントは、外部データ取得を統合することによって大規模言語モデル (LLM) の機能を強化する RAG アプリケーションの重要な部分です。 RAG エージェントは、ユーザー クエリを処理し、ベクトル データベースから関連データを取得し、このデータを LLM に渡して応答を生成します。
LangChain や Pyfunc などのツールは、入力と出力を接続してこれらの手順をリンクします。
次の図は、チャットボットの RAG エージェントと、各エージェントのビルドに使用される Databricks 機能を示しています。

- クエリの前処理 - ユーザーがクエリを送信し、ベクトル データベースのクエリに適したものになるように前処理されます。 これには、テンプレートへの要求の配置やキーワードの抽出が含まれます。
- クエリのベクトル化 - Model Serving を使用して、データ パイプラインにチャンクを埋め込むために使ったものと同じ埋め込みモデルを使って要求を埋め込みます。 これらの埋め込みにより、要求と前処理されたチャンク間のセマンティックの類似性の比較が可能になります。
- 取得フェーズ - 関連情報をフェッチするアプリケーションであるレトリーバーは、ベクトル化されたクエリを受け取り、ベクトル検索を使用してベクトル類似性検索を実行します。 クエリとの類似性に基づいて、最も関連性の高いデータ チャンクがランク付けされ、取得されます。
- プロンプト拡張 - レトリーバーは、取得したデータ チャンクを元のクエリと組み合わせて、LLM に追加のコンテキストを提供します。 プロンプトは、LLM がクエリのコンテキストを確実に理解できるように慎重に構成されています。 多くの場合、LLM には応答の書式設定用のテンプレートがあります。 プロンプトを調整するこのプロセスは、プロンプト エンジニアリングと呼ばれます。
- LLM 生成フェーズ - LLM は、取得結果によってエンリッチされた拡張クエリを使用して応答を生成します。 LLM には、カスタム モデルまたは基礎モデルがあります。
- ポスト プロセス - LLM の応答は、追加のビジネス ロジックを適用したり、引用を追加したり、定義済みのルールや制約に基づいて生成されたテキストを調整したりするために処理される場合があります
エンタープライズ ポリシーに確実に準拠するために、このプロセス全体でさまざまなガードレールを適用できます。 これには、適切な要求のフィルター処理、データ ソースにアクセスする前のユーザーのアクセス許可の確認、生成された応答でのコンテンツ モデレーション手法の使用が含まれる場合があります。
次の機能を使用して、エージェント開発をすばやく繰り返します。
任意のライブラリと MLflow を使用してエージェントを作成し、ログを記録します。 エージェントをパラメーター化して、エージェント開発を迅速に実験し、反復します。
トークン ストリーミングと要求/応答ログのネイティブ サポートに加えて、エージェントのユーザー フィードバックを取得するための組み込みのレビュー アプリを使用して、運用環境にエージェントをデプロイします。
エージェント トレースを使用すると、エージェント コード全体のトレースをログに記録、分析、比較して、エージェントが要求にどのように応答するかをデバッグし、理解できます。
評価と監視は、RAG アプリケーションが品質、コスト、待ち時間の要件を満たしているかどうかを判断するのに役立ちます。 評価は開発中に行われますが、監視はアプリケーションが運用環境にデプロイされた後に行われます。
非構造化データに対する RAG には、品質に影響を与える多くのコンポーネントがあります。 たとえば、データの書式設定の変更は、取得されたチャンクと、関連する応答を生成する LLM の機能に影響を与える可能性があります。 そのため、アプリケーション全体に加えて、個々のコンポーネントを評価することが重要です。
詳細については、「Mosaic AI エージェント 評価 とは?」を参照してください。
エージェント フレームワークのリージョンの可用性については、「利用可能なリージョンに制限がある機能」を参照してください