Azure Databricks は、エンタープライズ グレードのデータ ソリューションを大規模に構築、デプロイ、共有、保守するための統合されたツール セットです。 Databricks Data Intelligence Platform は、クラウド アカウントのクラウド ストレージとセキュリティと統合され、クラウド インフラストラクチャを管理およびデプロイします。
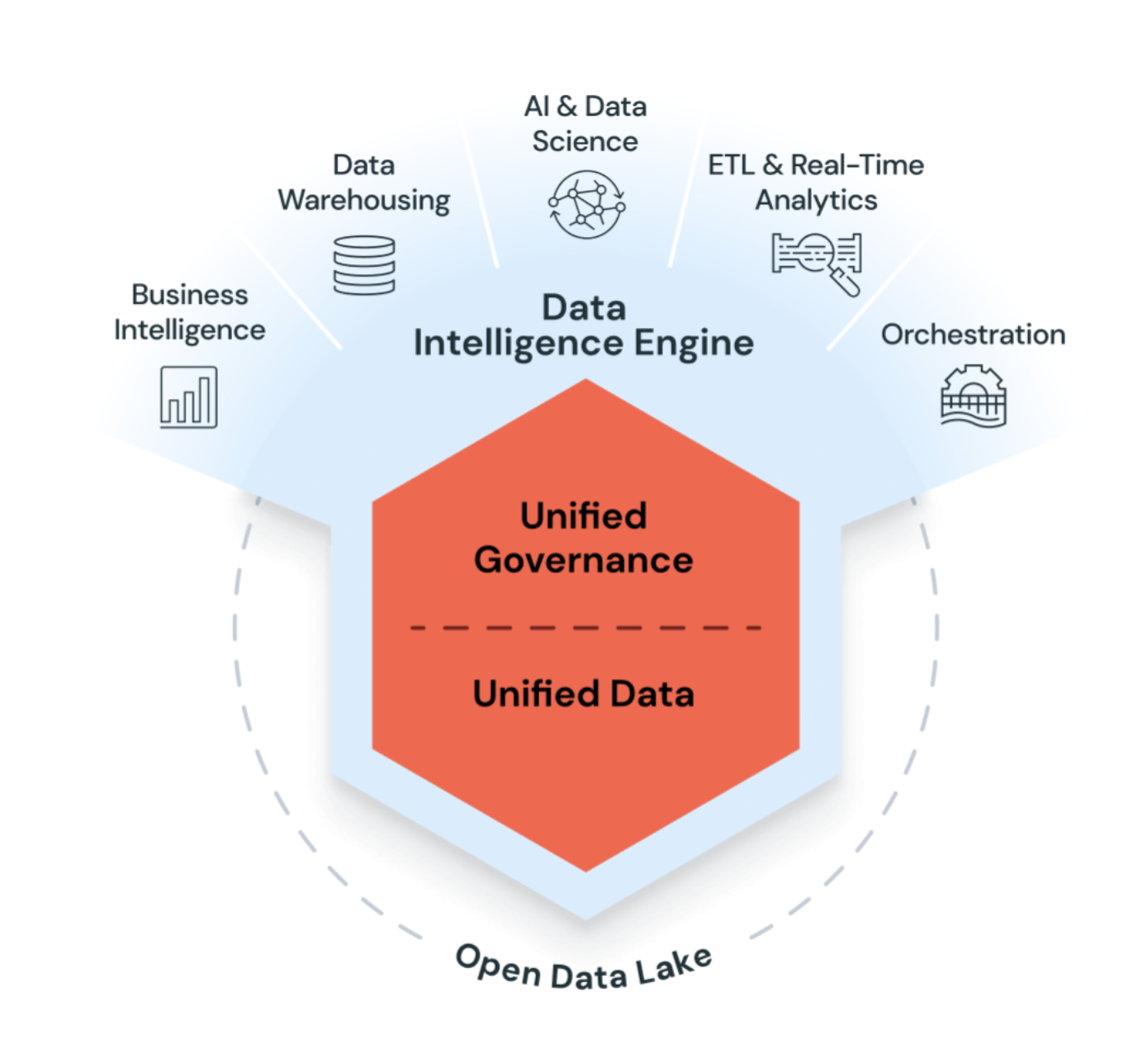
Azure Databricks では、データ レイクハウスで生成 AI を使用して、データの固有のセマンティクスを理解します。 その後、ビジネス ニーズに合わせてパフォーマンスが自動的に最適化され、インフラストラクチャが管理されます。
自然言語処理はビジネスの言語を学習するので、自分の言葉で質問することでデータを検索および検出できます。 自然言語の支援は、コードの記述、エラーのトラブルシューティング、ドキュメントでの回答の検索に役立ちます。
マネージド オープン ソース統合
Databricks はオープン ソース コミュニティにコミットされ、Databricks Runtime リリースとのオープン ソース統合の更新を管理します。 以下のテクノロジは、元々は Databricks の従業員によって作成されたオープンソース プロジェクトです。
一般的なユース ケース
次のユース ケースでは、お客様が Azure Databricks を使用して、重要なビジネス機能と意思決定を推進するデータの処理、格納、分析に不可欠なタスクを実行する方法をいくつか紹介します。
エンタープライズ データ レイクハウスを構築する
Data Lakehouse は、エンタープライズ データ ウェアハウスとデータ レイクを組み合わせて、エンタープライズ データ ソリューションを高速化、簡素化、統合します。 データ エンジニア、データ サイエンティスト、アナリスト、運用システムはすべて、データ レイクハウスを単一の信頼できる情報源として使用でき、一貫性のあるデータへのアクセスを提供し、多くの分散データ システムの構築、保守、同期の複雑さを軽減できます。 「データ レイクハウスとは」をご覧ください。
ETL とデータ エンジニアリング
ダッシュボードを生成する場合でも、人工知能アプリケーションを活用する場合でも、データ エンジニアリングは、効率的な検出と使用のためにデータが使用可能でクリーンで、データ モデルに格納されていることを確認することで、データ中心の企業のバックボーンを提供します。 Azure Databricks は 、Apache Spark の機能と Delta およびカスタム ツールを組み合わせて、比類のない ETL エクスペリエンスを提供します。 SQL、Python、Scala を使用して ETL ロジックを作成し、数回のクリックでスケジュールされたジョブのデプロイを調整します。
Lakeflow パイプラインは、 データセット間の依存関係をインテリジェントに管理し、運用インフラストラクチャを自動的にデプロイおよびスケーリングすることで ETL をさらに簡素化し、仕様へのタイムリーで正確なデータ配信を保証します。
Azure Databricks には、自動ローダーを含むデータ インジェスト用のツールが用意されています。これは、クラウド オブジェクト ストレージとデータ レイクから Data Lakehouse にデータを増分的かつべき等的に読み込むための効率的でスケーラブルなツールです。
機械学習、AI、データ サイエンス
Azure Databricks 機械学習では、MLflow や Databricks Runtime for Machine Learning など、データ サイエンティストや ML エンジニアのニーズに合わせて調整された一連のツールを使用して、プラットフォームのコア機能を拡張します。
大規模言語モデルと生成 AI
Databricks Runtime for Machine Learning には、既存の事前トレーニング済みモデルやその他のオープン ソース ライブラリをワークフローに統合できる Hugging Face Transformers などのライブラリが含まれています。 Databricks MLflow 統合により、トランスフォーマー パイプライン、モデル、処理コンポーネントで MLflow 追跡サービスを簡単に使用できます。 John Snow Labs などのパートナーの OpenAI モデルまたはソリューションを Databricks ワークフローに統合します。
Azure Databricks を使用して、特定のタスクに合わせてデータの LLM をカスタマイズします。 Hugging Face や DeepSpeed などのオープン ソース ツールをサポートすることで、基礎 LLM を効率的に取得し、独自のデータを使用してトレーニングを開始し、ドメインとワークロードの精度を高めることができます。
さらに、Azure Databricks には、SQL データ アナリストがデータ パイプラインとワークフロー内で直接、OpenAI を含む LLM にアクセスするために使用できる AI 関数が用意されています。 AI 関数を使用したデータのエンリッチを参照してください。
データ ウェアハウス、分析、BI
Azure Databricks は、ユーザーフレンドリーな UI、コスト効率の高いコンピューティング リソース、および無限に拡張可能な低価格のストレージを組み合わせて、分析クエリを実行するための強力なプラットフォームを提供します。 管理者はスケーラブルなコンピューティング クラスターを SQL ウェアハウスとして構成するため、エンド ユーザーはクラウドでの作業の複雑さを管理することなくクエリを実行できます。 SQL ユーザーは、 SQL クエリ エディター またはノートブックを使用して、lakehouse 内のデータに対してクエリを実行できます。 ノートブックでは、SQL に加えてPython、R、Scala がサポートされており、マークダウンで記述されたリンク、画像、解説と共に視覚化を埋め込むことができます。
一貫性のある分析情報を提供するには、Unity カタログ セマンティクスを使用して共有セ マンティック レイヤーを定義します。 ビジネス KPI を メトリック ビュー として 1 回定義し、任意のディメンションにわたってクエリを実行し、ユーザーと AI ツールの両方にメトリックの単一の管理されたソースを提供します。 このレイヤーの上に、AI 支援の作成、強化された視覚化ライブラリ、合理化された構成エクスペリエンスを提供する AI /BI ダッシュボードを構築できます。 ビジネス ユーザーは、組織の用語とデータに合わせて調整された生成 AI を使用する Genie Agents を使用して、自然言語でデータを探索することもできます。
データ ガバナンスとセキュリティで保護されたデータ共有
Unity Catalog は、データ レイクハウス用の統合データ ガバナンス モデルを提供します。 クラウド管理者は、Unity Catalog の大まかなアクセス制御アクセス許可を構成して統合し、Azure Databricks 管理者はチームと個人のアクセス許可を管理できます。 権限は、ユーザーフレンドリな UI または SQL 構文を使用してアクセス制御リスト (ACL) で管理されるため、データベース管理者は、データへのアクセスを簡単にセキュリティで保護することができ、クラウドネイティブの ID アクセス管理 (IAM) とネットワーク上で拡張する必要はありません。
Unity Catalog は、クラウドでの安全な分析の実行をシンプルにし、プラットフォームの管理者とエンド ユーザーの両方に必要なスキルの再構築やスキルアップを制限するのに役立つ責任の分割を提供します。 「Unity Catalog とは」を参照してください。
レイクハウスを使用すると、テーブルまたはビューへのクエリ アクセスを許可するのと同じくらい簡単に組織内でデータを共有できます。 セキュリティで保護された環境の外部で共有するために、Unity カタログには OpenSharing のマネージド バージョンが用意されています。
DevOps、CI/CD、タスク オーケストレーション
ETL パイプライン、ML モデル、分析ダッシュボードの開発ライフサイクルには、それぞれ固有の課題があります。 Azure Databricks を使用すると、すべてのユーザーが 1 つのデータ ソースを利用できるため、重複する作業と同期されていないレポートが削減されます。 さらに、バージョン管理、自動化、スケジュール設定、コードと運用リソースのデプロイのための一連の共通ツールを提供することで、監視、オーケストレーション、および操作のオーバーヘッドをシンプルにすることできます。
ジョブは、Azure Databricks ノートブック、SQL クエリ、およびその他の任意のコードをスケジュールします。 宣言型オートメーション バンドル を使用すると、ジョブやパイプラインなどの Databricks リソースをプログラムで定義、デプロイ、実行できます。 Git フォルダーを使用すると、Azure Databricks プロジェクトを多数の人気のある Git プロバイダーと同期できます。
CI/CD のベスト プラクティスと推奨事項については、 Databricks の CI/CD ワークフローと Databricks の 開発者のベスト プラクティスを参照してください。 開発者向けツールの完全な概要については、「 Databricks での開発」を参照してください。
リアルタイムのストリーミング分析
Azure Databricks では、Apache Spark Structured Streaming を利用して、ストリーミング データと増分のデータ変更を処理します。 構造化ストリーミングは Delta Lake と緊密に統合されており、これらのテクノロジは Lakeflow パイプラインと自動ローダーの両方の基盤を提供します。 構造化ストリーミングの概念を参照してください。
オンライン トランザクション処理
Lakebase は、Databricks Data Intelligence Platform と完全に統合されたオンライン トランザクション処理 (OLTP) データベースです。 このフル マネージド Postgres データベースを使用すると、Azure Databricks マネージド ストレージに格納されている OLTP データベースを作成および管理できます。 Lakebase Postgres を参照してください。