この記事では、レイクハウスのアーキテクチャガイダンスを提供し、データソース、インジェスト、変換、クエリと処理、サービス、分析、ストレージについて説明します。
各リファレンス アーキテクチャには、11 x 17 (A3) 形式のダウンロード可能な PDF があります。
Databricks 上の lakehouse はパートナー ツールからなる大規模なエコシステムと統合されたオープン プラットフォームですが、リファレンス アーキテクチャは Azure サービスと Databricks lakehouse のみに焦点を当てています。 画像内のクラウド プロバイダー サービスは、概念を示すために選択されており、すべてを網羅しているわけではありません。
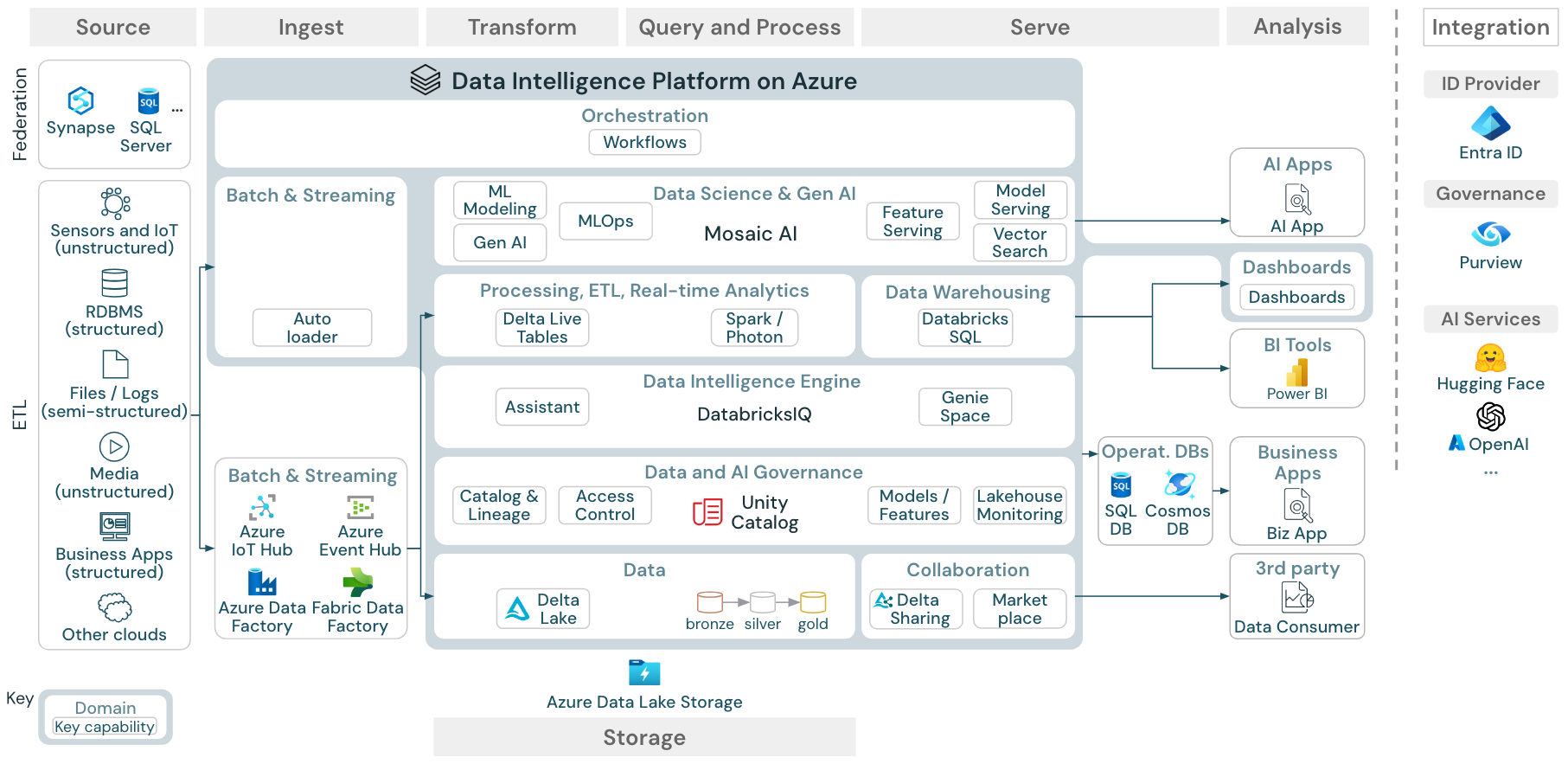
ダウンロード: Azure Databricks レイクハウスのリファレンス アーキテクチャ
Azure リファレンス アーキテクチャには、インジェスト、ストレージ、提供、分析のための次の Azure 固有のサービスが示されています。
- Lakehouse Federation のソース システムとしての Azure Synapse と SQL Server
- ストリーミング取り込み用の Azure IoT Hub と Azure Event Hubs
- バッチ 取り込み用の Azure Data Factory
- データと AI 資産のオブジェクト ストレージとしての Azure Data Lake Storage Gen 2 (ADLS)
- オペレーション データベースとしての Azure SQL DB と Azure Cosmos DB
- UC がスキーマと系列情報をエクスポートするエンタープライズ カタログとしての Azure Purview
- BI ツールとしての Power BI
- Azure OpenAI は、外部 LLM として機能するモデルで使用できます
リファレンス アーキテクチャの編成
参照アーキテクチャは、スイム レーン ソース、インジェスト、トランスフォーム、クエリ/プロセス、提供、分析、そして ストレージに沿って構成されています。
Source
外部データをデータ インテリジェンス プラットフォームに統合するには、次の 3 つの方法があります。
- ETL: このプラットフォームは、半構造化データと非構造化データ (センサー、IoT デバイス、メディア、ファイル、ログなど) と、リレーショナル データベースまたはビジネス アプリケーションからの構造化データを提供するシステムとの統合を可能にします。
- Lakehouse フェデレーション: リレーショナル データベースなどの SQL ソースは、ETL なしで Lakehouse と Unity カタログ に統合できます。 この場合、ソース システム データは Unity カタログによって管理され、クエリはソース システムにプッシュダウンされます。
- カタログ フェデレーション: Hive Metastore カタログは、 カタログ フェデレーションを使用して Unity カタログに統合することもできます。これにより、Unity カタログは Hive Metastore に格納されているテーブルを制御できます。
Ingest
バッチまたはストリーミングを使用して Lakehouse にデータを取り込みます。
- Databricks Lakeflow Connect には、エンタープライズ アプリケーションとデータベースからのインジェスト用の組み込みコネクタが用意されています。 結果として得られるインジェスト パイプラインは Unity カタログによって管理され、サーバーレス コンピューティングとパイプラインを利用 します。
- クラウド ストレージに配信されたファイルは、Databricks Auto Loader を使って直接読み込むことができます。
- エンタープライズ アプリケーションから Delta Lake へのデータのバッチ インジェストの場合、Databricks レイクハウスは、このような記録システムに対応する特定のアダプターを備えたパートナーのインジェスト ツールを利用しています。
- ストリーミング イベントは、Databricks の構造化ストリーミングを使って、Kafka などのイベント ストリーミング システムから直接取り込むことができます。 ストリーミング ソースは、センサー、IoT、または変更データ キャプチャ プロセスの場合があります。
Storage
- 通常、データはクラウド ストレージ システムに格納されます。ETL パイプラインは medallion アーキテクチャ を使用して、 Delta ファイル/テーブル または Apache Iceberg テーブルとしてキュレーションされた方法でデータを格納します。
変換とクエリ/プロセス
Databricks レイクハウスは、すべての変換とクエリにエンジン Apache Spark と Photon を使っています。
パイプライン は、信頼性の高い保守可能でテスト可能なデータ処理パイプラインを簡素化および最適化するための宣言型フレームワークです。
Apache Spark と Photon を活用した Databricks Data Intelligence Platform は、2 種類のワークロードをサポートしています。SQL ウェアハウスを介した SQL クエリと、ワークスペース クラスターを介した SQL、Python、Scala のワークロードです。
データ サイエンス (ML モデリングと Gen AI) の場合、Databricks の AI および機械学習プラットフォームには、AutoML と ML ジョブのコーディングに特化した ML ランタイムが用意されています。 すべてのデータ サイエンスと MLOps ワークフローは MLflow によって最適にサポートされます。
Serving
データ ウェアハウス (DWH) と BI のユースケースにおいて、Databricks レイクハウスは、Databricks SQL、SQL ウェアハウスによって提供されるデータ ウェアハウス、およびサーバーレス SQL ウェアハウスを提供します。
機械学習の場合、 Mosaic AI Model Serving は、Databricks コントロール プレーンでホストされるスケーラブルでリアルタイムのエンタープライズ レベルのモデル サービス機能です。 Mosaic AI Gateway は、サポートされている生成 AI モデルとそれに関連するモデルサービス エンドポイントへのアクセスを管理および監視するための Databricks のソリューションです。
Collaboration:
ビジネス パートナーは 、差分共有を通じて必要なデータに安全にアクセスできます。
Delta Sharing に基づいた Databricks Marketplace は、データ製品を交換するためのオープン フォーラムです。
Clean Rooms は、複数のユーザーが互いのデータに直接アクセスすることなく機密性の高いエンタープライズ データに対して共同作業を行うことができる、セキュリティで保護されたプライバシー保護環境です。
Analysis
最終的なビジネス アプリケーションはこのスイム レーンにあります。 たとえば、リアルタイム推論のために Mosaic AI Model Serving に接続された AI アプリケーションや、レイクハウスからオペレーション データベースにプッシュされたデータにアクセスするアプリケーションなどのカスタム クライアントなどがあります。
BI のユース ケースでは、通常、アナリストは BI ツールを使ってデータ ウェアハウスにアクセスします。 SQL 開発者は、クエリとダッシュボードのためにさらに Databricks SQL Editor (図には示されていません) を使用できます。
Data Intelligence Platform には、データの視覚化を構築して分析情報を共有できるダッシュボードも用意されています。
Integrate
- Databricks プラットフォームは、ユーザー管理とシングル サインオン (SSO) のために標準 ID プロバイダーと統合されます。
OpenAI、LangChain、HuggingFace などの外部 AI サービスは、Databricks Intelligence Platform 内から直接使用できます。
外部オーケストレーターでは、包括的な REST API を使用することも、Apache Airflow など、外部オーケストレーション ツール専用コネクタを使用することもできます。
Unity Catalog は、Databricks Intelligence Platform 内のすべてのデータおよび AI ガバナンスに使用され、Lakehouse Federation を介して他のデータベースをそのガバナンスに統合できます。
さらに、Unity カタログは、他のエンタープライズ カタログ、例えば Purview
などと統合できます。 詳細については、エンタープライズ カタログ ベンダーにお問い合わせください。
すべてのワークロードに共通する機能
さらに、Databricks レイクハウスには、すべてのワークロードをサポートする管理機能が付属しています。
データと AI ガバナンス
Databricks Data Intelligence Platform の中心となるデータと AI のガバナンス システムは Unity Catalog です。 Unity Catalog は、1 つの場所ですべてのワークスペースに適用されるデータ アクセス ポリシーを管理できます。また、テーブル、ボリューム、特徴量 (特徴量ストア)、モデル (モデル レジストリ) など、レイクハウスで作成または使用されるすべての資産をサポートします。 Unity Catalog を使って、Databricks 上で実行されたクエリ全体のランタイム データ系列を取り込むこともできます。
Databricks データ品質監視 を使用すると、アカウント内のすべてのテーブルのデータ品質を監視できます。 すべてのテーブル の異常を検出 し、各テーブルの 完全なデータ プロファイル を提供します。
監視のために、 システム テーブル は、アカウントの運用データの Databricks でホストされる分析ストアです。 システム テーブルは、アカウント全体の履歴監視に使用できます。
データ インテリジェンス エンジン
Databricks データ インテリジェンス プラットフォームを使用すると、組織全体でデータと AI を使用し、生成型 AI と Lakehouse の統一の利点を組み合わせて、データの独自のセマンティクスを理解できます。 Databricks AI 支援機能を参照してください。
Genie Code は、Databricks ノートブック、SQL エディター、ファイル エディターなどで、ユーザーのコンテキスト対応 AI アシスタントとして使用できます。
オートメーション & オーケストレーション
Lakeflow ジョブは 、Databricks データ インテリジェンス プラットフォーム上のデータ処理、機械学習、および分析パイプラインを調整します。 Lakeflow Spark 宣言型パイプライン を使用すると、宣言構文を使用して信頼性と保守性に優れた ETL パイプラインを構築できます。 このプラットフォームでは、CI/CD と MLOps もサポートされています
Azure 上の Data Intelligence Platform のハイレベルなユース ケース
Lakeflow Connect を使用した SaaS アプリとデータベースからの組み込みインジェスト
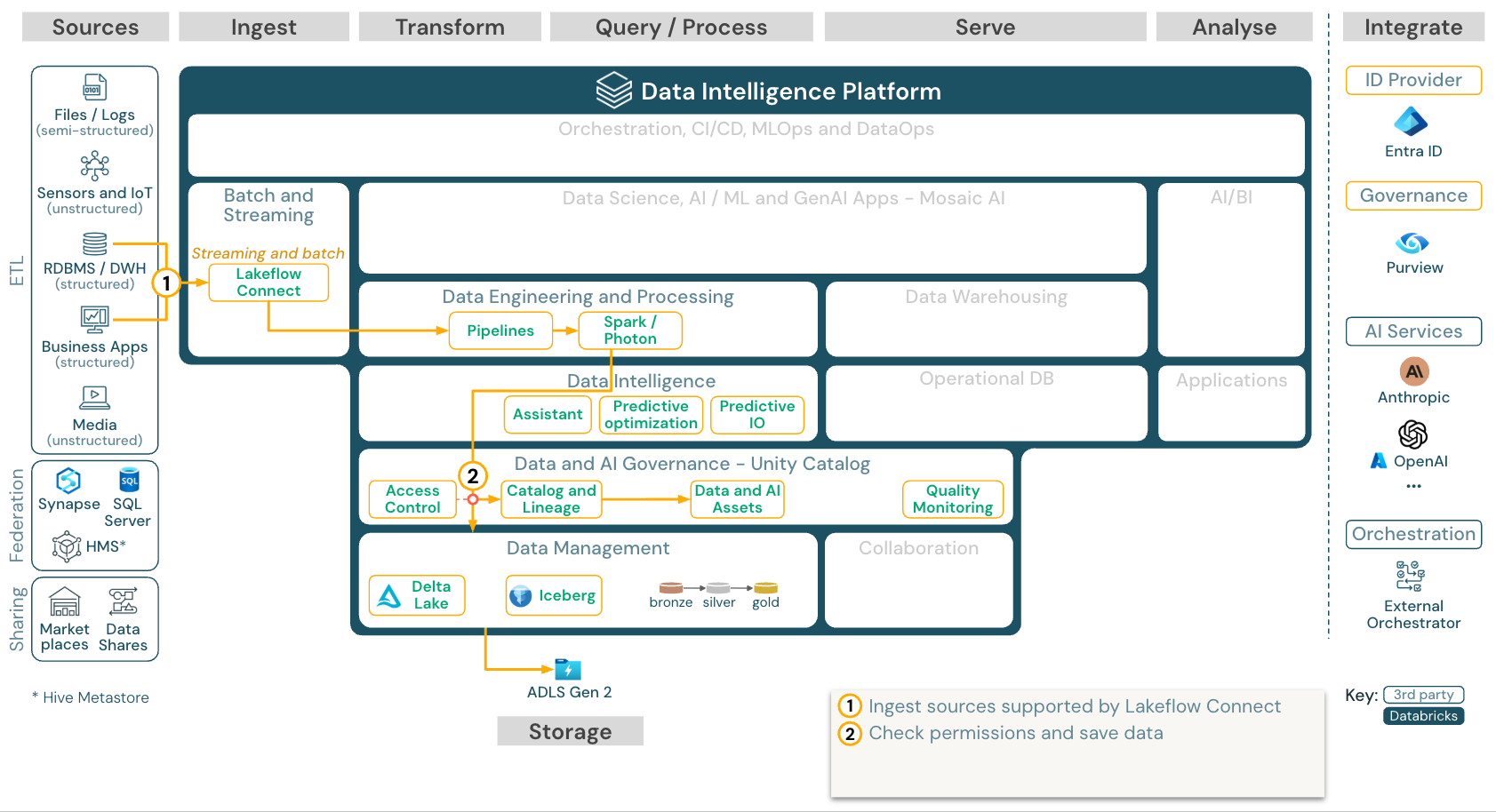
ダウンロード: Azure Databricks の Lakeflow Connect リファレンス アーキテクチャ。
Databricks Lakeflow Connect には、エンタープライズ アプリケーションとデータベースからのインジェスト用の組み込みコネクタが用意されています。 結果として得られるインジェスト パイプラインは Unity カタログによって管理され、サーバーレス コンピューティングと Lakeflow Spark 宣言パイプラインを利用します。
Lakeflow Connect は、効率的な増分読み書きを活用して、データインジェストを高速化し、スケーラブルでコスト効率を高めます。また、データをダウンストリームで使用するために常に最新の状態に保ちます。
バッチ インジェストと ETL
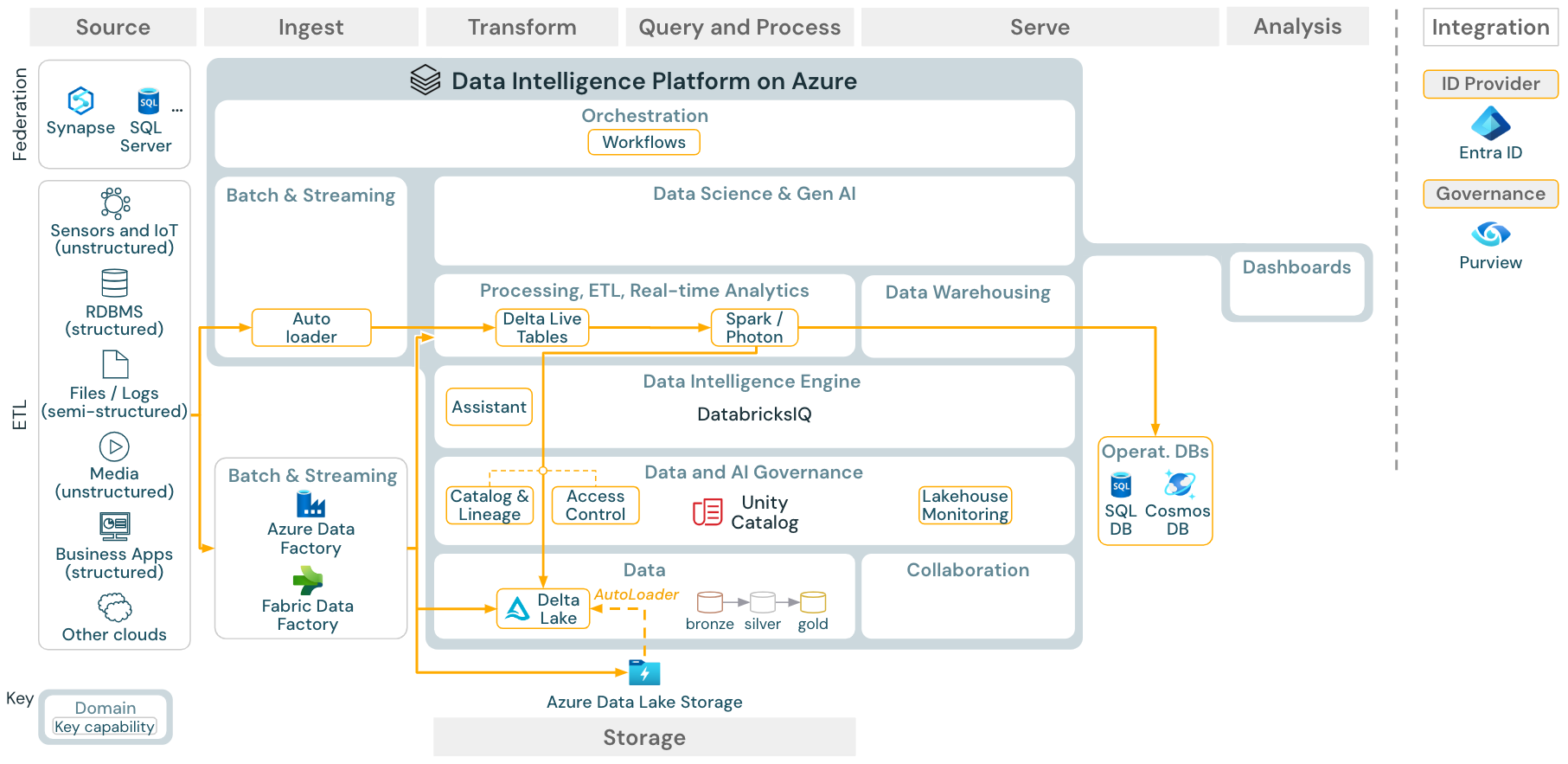
ダウンロード: Azure Databricks 用のバッチ ETL リファレンス アーキテクチャ
インジェスト ツールでは、ソース固有のアダプターを使用してソースからデータを読み取り、自動ローダーが読み取ることができるクラウド ストレージに格納するか、Databricks を直接呼び出します (たとえば、パートナーのインジェスト ツールが Databricks Lakehouse に統合されている場合)。 データを読み込むには、Databricks ETL と処理エンジンがパイプラインを介してクエリを実行 します。 Lakeflow ジョブを使用して単一またはマルチタスク ジョブを調整し、Unity カタログ (アクセス制御、監査、系列など) を使用してそれらを管理します。 待機時間の短い運用システムで特定のゴールデン テーブルにアクセスできるようにするには、ETL パイプラインの最後にある RDBMS やキー値ストアなどのオペレーション データベースにテーブルをエクスポートします。
ストリーミングと変更データ キャプチャ (CDC)
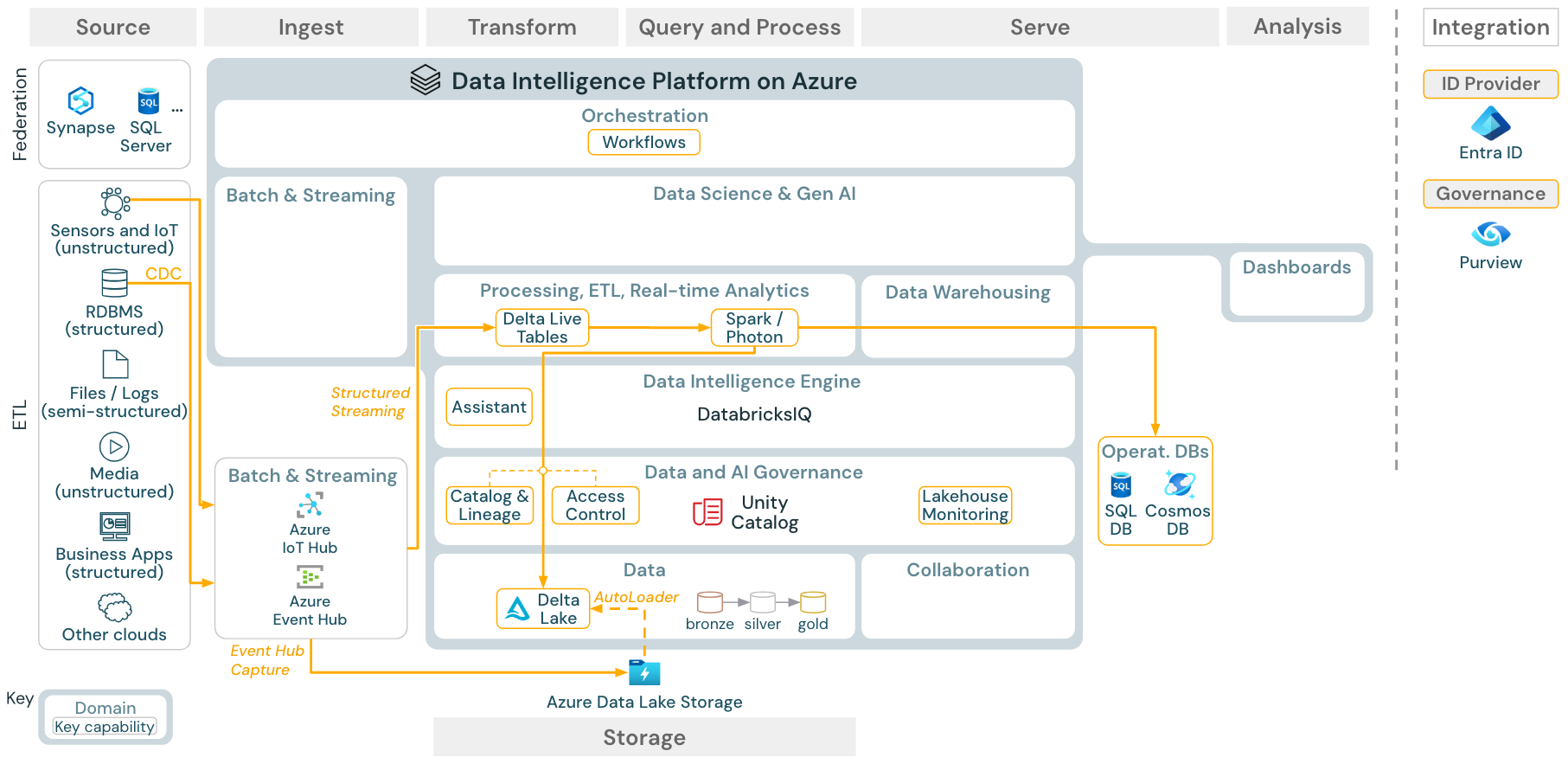
ダウンロード: Azure Databricks 用の Spark 構造化ストリーミング アーキテクチャ
Databricks ETL エンジンは 、Spark 構造化ストリーミングを 使用して、Apache Kafka や Azure Event Hub などのイベント キューから読み取ります。 ダウンストリームの手順は、上記の Batch ユース ケースのアプローチに従います。
リアルタイム 変更データ キャプチャ (CDC) は、通常、抽出されたイベントをイベント キューに格納します。 以降、ユース ケースはストリーミングのユース ケースに従います。
CDC がバッチで実行され、抽出されたレコードが最初にクラウド ストレージに格納されている場合、Databricks 自動ローダーはそれらを読み取ることができ、ユース ケースは Batch ETL に従います。
機械学習と AI (従来)
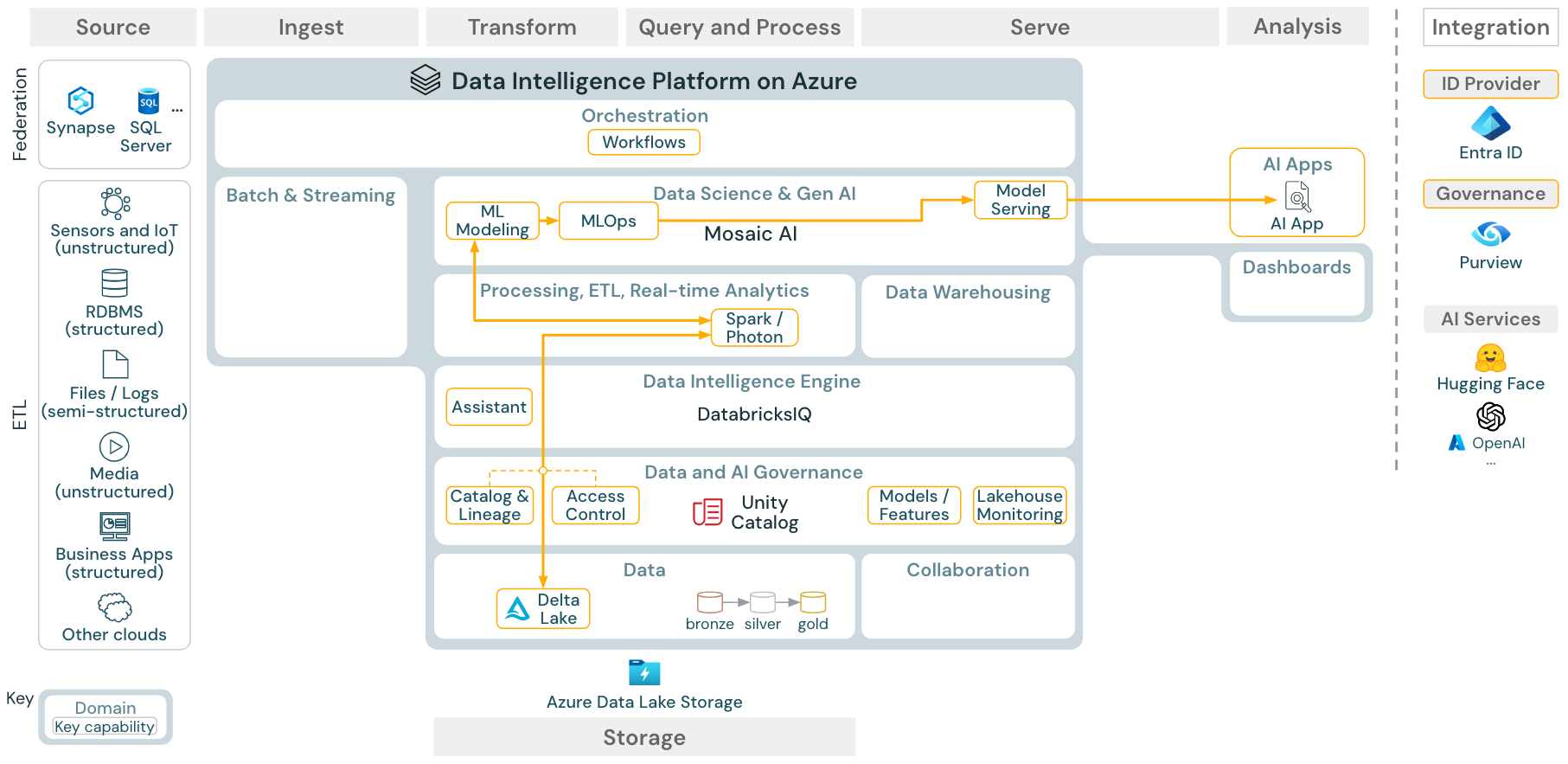
ダウンロード: Azure Databricks 用の機械学習と AI リファレンス アーキテクチャ
機械学習の場合、Databricks Data Intelligence Platform には、最先端の 機械学習ライブラリとディープ ラーニング ライブラリが付属するモザイク AI が用意されています。 機能ストアやモデル レジストリ (Unity カタログに統合)、AutoML を使用したローコード機能、データ サイエンス ライフサイクルへの MLflow 統合などの機能が提供されます。
Unity Catalog は、データ サイエンス関連のすべての資産 (テーブル、機能、モデル) を管理し、データ サイエンティストは Lakeflow ジョブ を使用してジョブを調整できます。
スケーラブルでエンタープライズ レベルの方法でモデルをデプロイするには、 MLOps 機能を使用してモデル サービスでモデルを公開します。
AI エージェント アプリケーション (Gen AI)
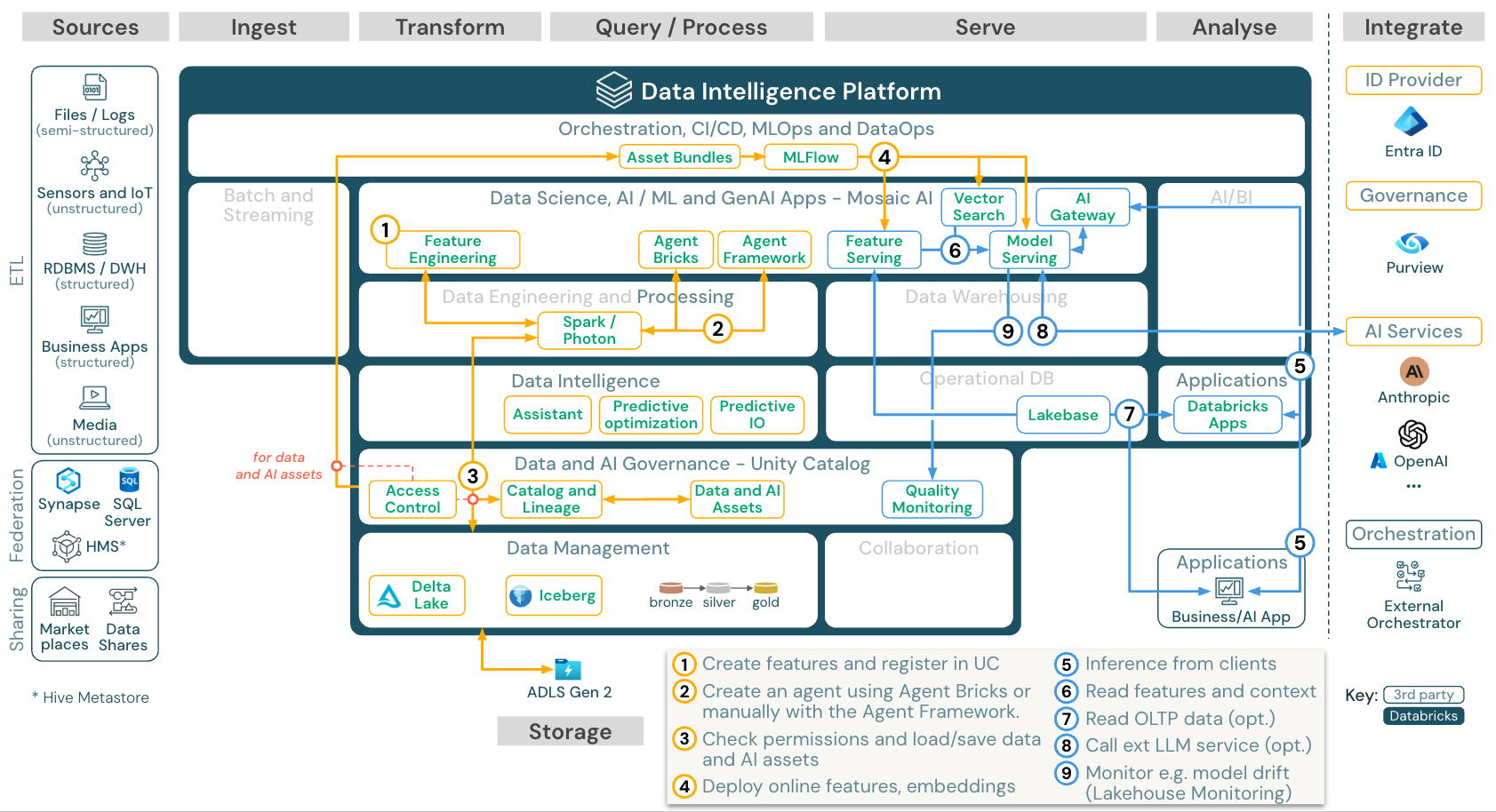
ダウンロード: Azure Databricks の Gen AI アプリケーションリファレンス アーキテクチャ
スケーラブルなエンタープライズレベルの方法でモデルをデプロイするには、MLOps 機能を使ってモデル提供でモデルを公開します。
BI と SQL の分析
azure Databricks の 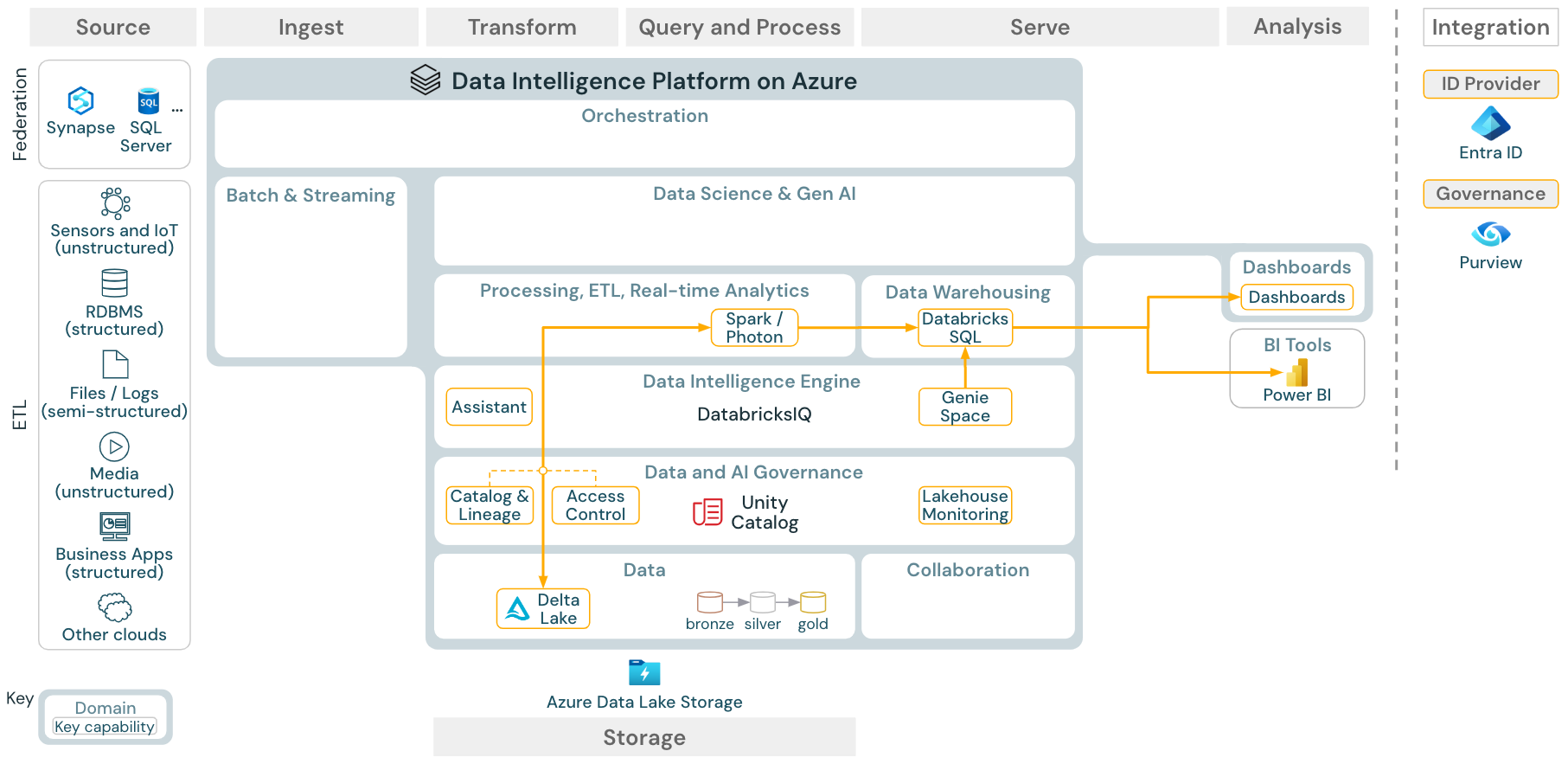
ダウンロード: Azure Databricks 用の BI および SQL 分析リファレンス アーキテクチャ
BI のユース ケースでは、ビジネス アナリストは ダッシュボード、 Databricks SQL エディター 、または Tableau や Power BI などの BI ツール を使用できます。 いずれの場合も、エンジンは Databricks SQL (サーバーレスまたは非サーバーレス) であり、Unity Catalog はデータの検出、探索、およびアクセス制御を提供します。
ビジネスアプリ

ダウンロード: Business Apps for Databricks for Azure Databricks
Databricks Apps を使用すると、開発者は、セキュリティで保護されたデータと AI アプリケーションを Databricks プラットフォームに直接構築してデプロイできるため、個別のインフラストラクチャが不要になります。 アプリは Databricks サーバーレス プラットフォームでホストされ、主要なプラットフォーム サービスと統合されます。 アプリで Lakehouse から同期された OLTP データが必要な場合は、Lakebase を使用します。
Lakehouse フェデレーション
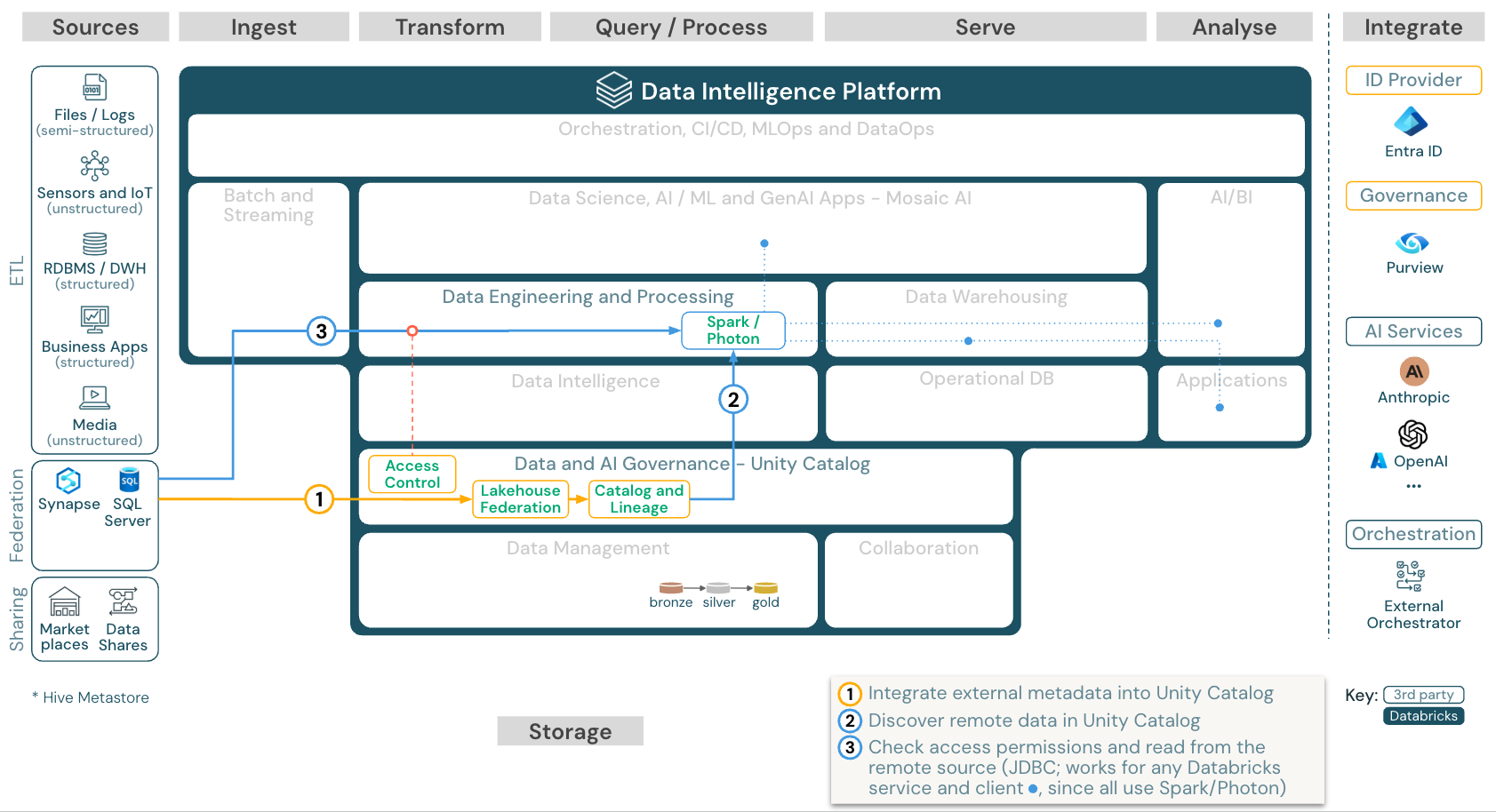
ダウンロード: Azure Databricks 用の Lakehouse フェデレーション リファレンス アーキテクチャ
Lakehouse Federation を使用すると、外部データ SQL データベース (MySQL、Postgres、SQL Server、Azure Synapse など) を Databricks と統合できます。
最初にデータをオブジェクト ストレージに ETL することなく、すべてのワークロード (AI、DWH、BI) がこの恩恵を受けられます。 外部ソース カタログは Unity カタログにマップされ、Databricks プラットフォーム経由のアクセスにきめ細かいアクセス制御を適用できます。
カタログ連携
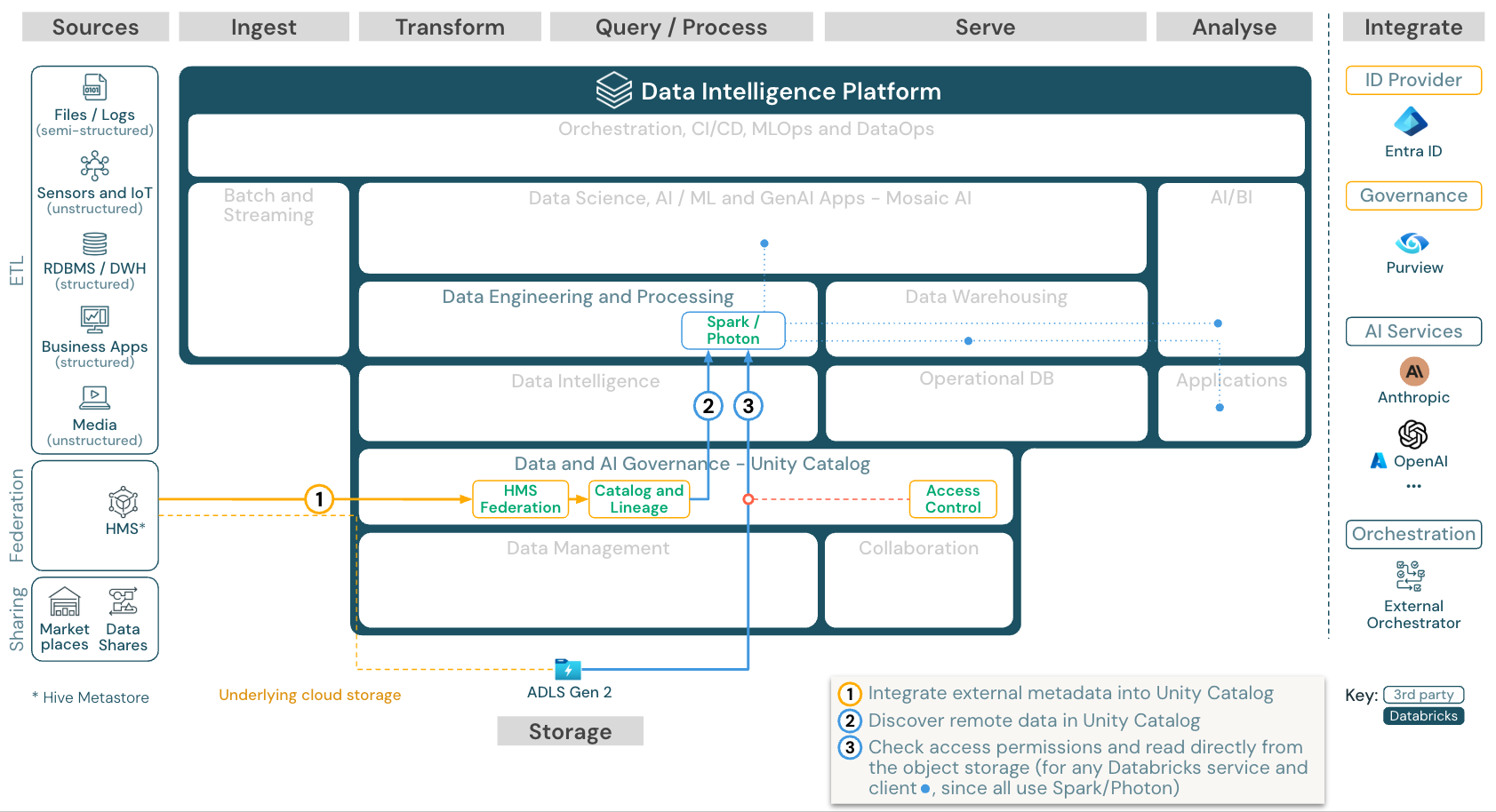
ダウンロード: Azure Databricks のカタログ フェデレーション参照アーキテクチャ
カタログ フェデレーション を使用すると、外部の Hive メタストア (MySQL、Postgres、SQL Server、Azure Synapse など) を Databricks と統合できます。
最初にデータをオブジェクト ストレージに ETL することなく、すべてのワークロード (AI、DWH、BI) がこの恩恵を受けられます。 外部ソース カタログが Unity カタログに追加され、Databricks プラットフォームを介してきめ細かいアクセス制御が適用されます。
サード パーティ製ツールとデータを共有する
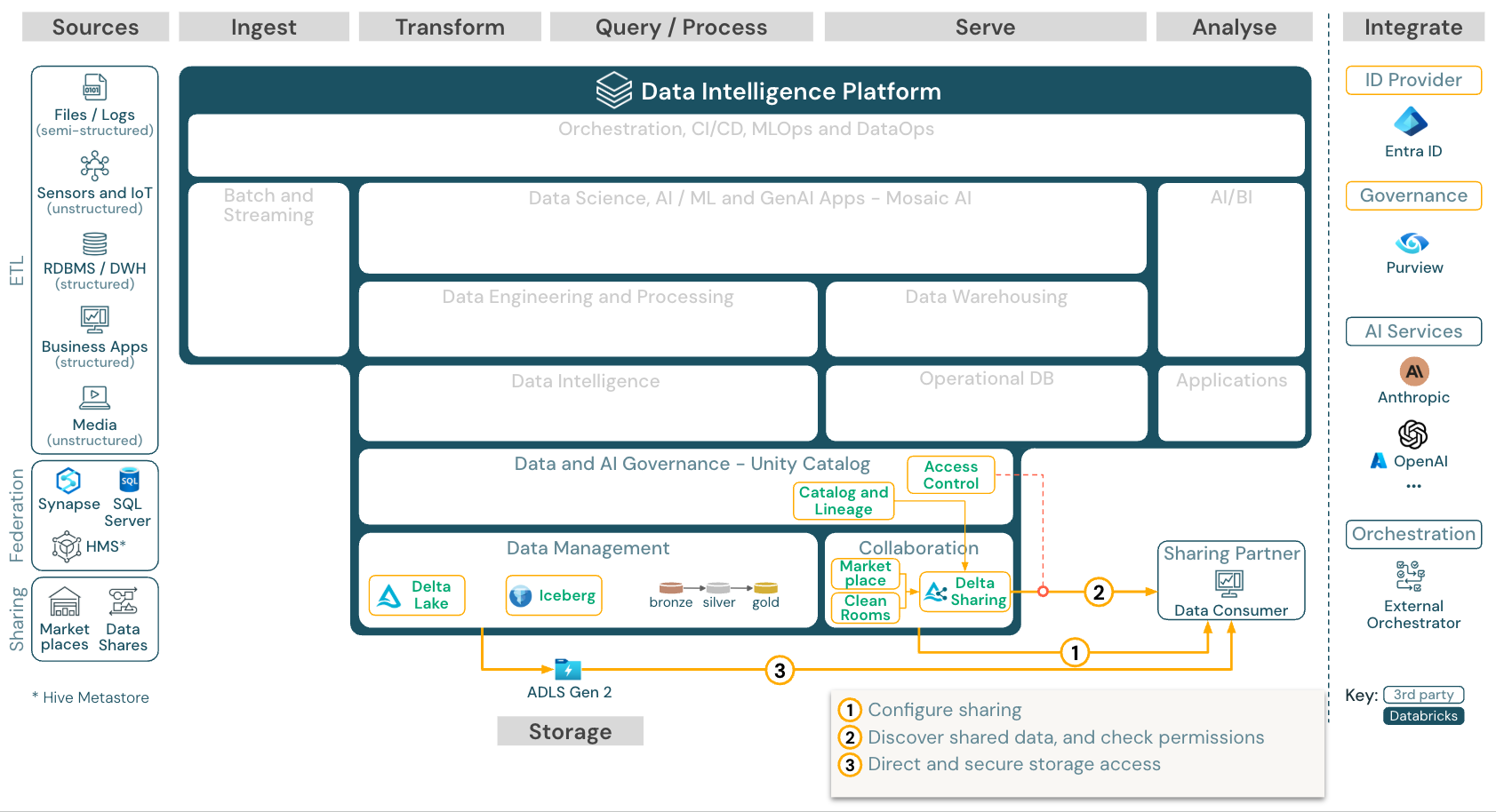
ダウンロード: Azure Databricks のサード パーティ製ツールの参照アーキテクチャでデータを共有する
サード パーティとのエンタープライズ レベルのデータ共有は、 Delta Sharing によって提供されます。 これにより、Unity カタログによって保護されたオブジェクト ストア内のデータに直接アクセスできます。 この機能は、データ製品を交換するためのオープン フォーラムである Databricks Marketplace でも使用されます。
Databricks から共有データを使用する
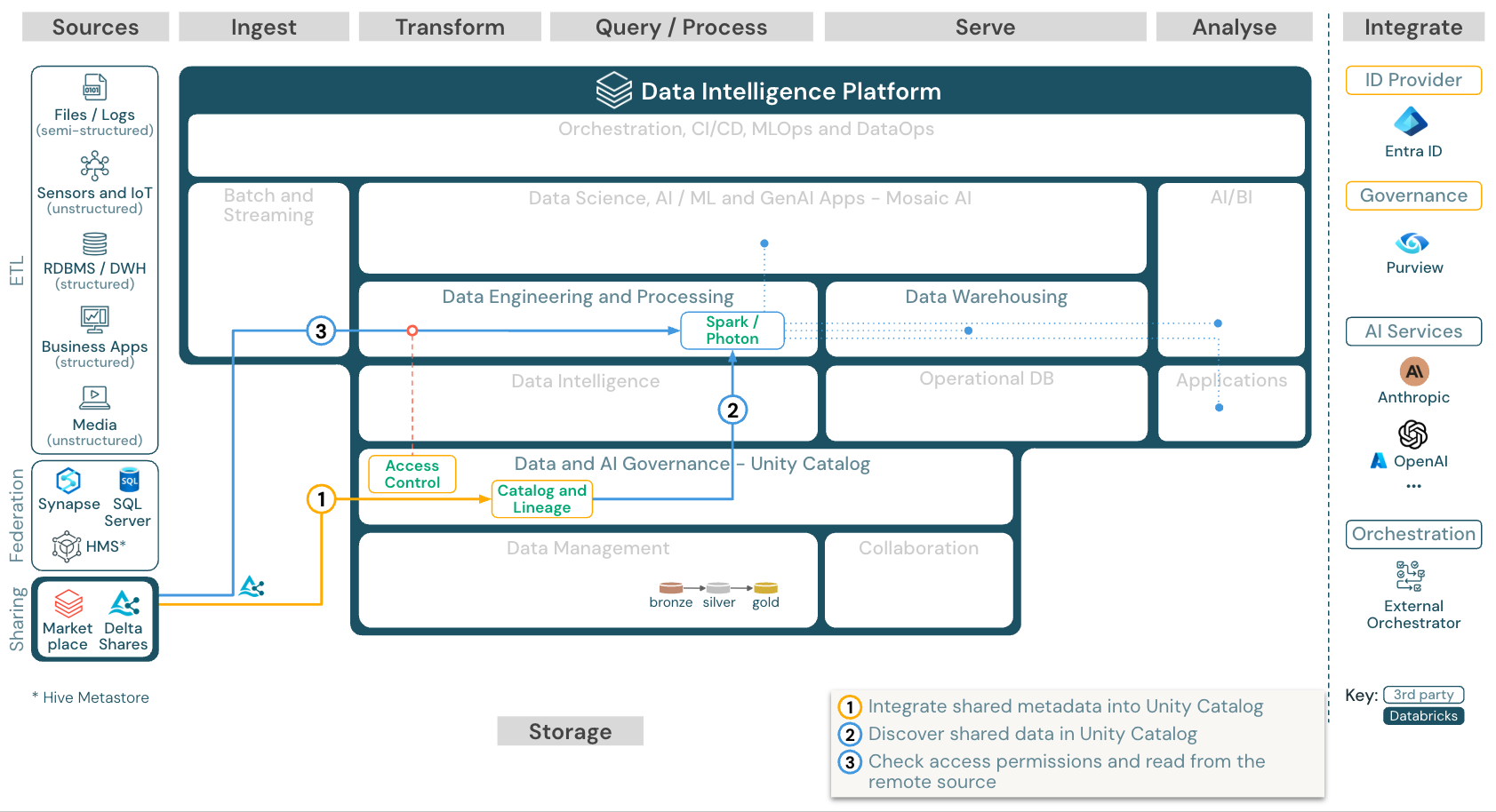
ダウンロード: Azure Databricks 用の Databricks 参照アーキテクチャから共有データを消費する
Delta Sharing Databricks-to-Databricks プロトコルを使用すると、ユーザーは、Unity カタログが有効になっているワークスペースにアクセスできる限り、アカウントやクラウド ホストに関係なく、Databricks ユーザーと安全にデータを共有できます。