Azure HDInsight の高可用性ソリューション アーキテクチャのケース スタディ
Azure HDInsight のレプリケーション メカニズムを高可用性ソリューション アーキテクチャに統合できます。 この記事では、Contoso Retail の架空のケース スタディを使用して、考えられる高可用性ディザスター リカバリー方法、コストに関する考慮事項、および対応する設計について説明します。
高可用性ディザスター リカバリーの推奨事項には、多数の順列組み合わせが考えられます。 各オプションの長所と短所を熟慮した後で、これらのソリューションに到達しています。 この記事では、考えられる 1 つのソリューションのみについて説明します。
次の図は、Contoso Retail のプライマリ アーキテクチャを示しています。 このアーキテクチャは、ストリーミング ワークロード、バッチ ワークロード、サービス レイヤー、消費レイヤー、ストレージ レイヤー、およびバージョン管理で構成されています。
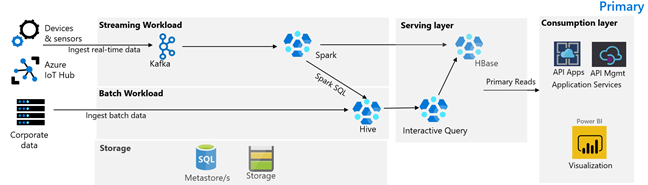
デバイスとセンサーによって、メッセージング フレームワークを構成する HDInsight Kafka に送信されるデータが生成されます。 An HDInsight Spark コンシューマーによって、Kafka トピックからの読み取りが行われます。 Spark によって、受信メッセージが変換され、サービス レイヤーの HDInsight HBase クラスターに書き込まれます。
Hive と MapReduce 取り込みデータを実行している HDInsight Hadoop クラスターで、オンプレミスのトランザクション システムからデータが取り込まれます。 Hive と MapReduce によって変換された生データは、Azure Data Lake Storage Gen2 によってバックアップされるデータ レイクの論理パーティション上の Hive テーブルに格納されます。 Hive テーブルに格納されたデータは、Spark SQL でも使用可能であり、選別されたデータをサービスのために HBase に格納する前にバッチ変換が行われます。
Apache Phoenix を使用する HDInsight HBase クラスターを使用して、Web アプリケーションと視覚化ダッシュボードにデータが提供されます。 内部レポート要件に対応するために、An HDInsight LLAP クラスターが使用されます。
Azure API Apps と API Management レイヤーによって、パブリックに公開される Web ページがバックアップされます。 内部レポート要件は Power BI によって対応されます。
エンタープライズ データ レイクとして、論理的にパーティション分割された Azure Data Lake Storage Gen2 が使用されます。 Azure SQL DB によって、HDInsight メタストアがバックアップされます。
Azure Pipelines に統合されたバージョン管理システムは、Azure の外部でホストされます。
災害が発生した場合に必要とする最小限のビジネス機能を決定することが重要です。
- リージョンでの障害またはサービスの正常性の問題から保護される必要がある。
- お客様に 404 エラーが表示されないようにする必要がある。 パブリック コンテンツを常に提供する必要がある。 (RTO = 0)
- ほぼ一年中、5 時間前の古いパブリック コンテンツを表示できる。 (RPO = 5 時間)
- ホリデー シーズン中は、パブリックに公開されているコンテンツを常に最新の状態にする必要がある。 (RPO = 0)
- ビジネス継続性にとって、社内レポート要件は重要ではないとみなされている。
- ビジネス継続性にかかるコストを最適化する。
次の図に、Contoso Retail の高可用性ディザスター リカバリー アーキテクチャを示します。
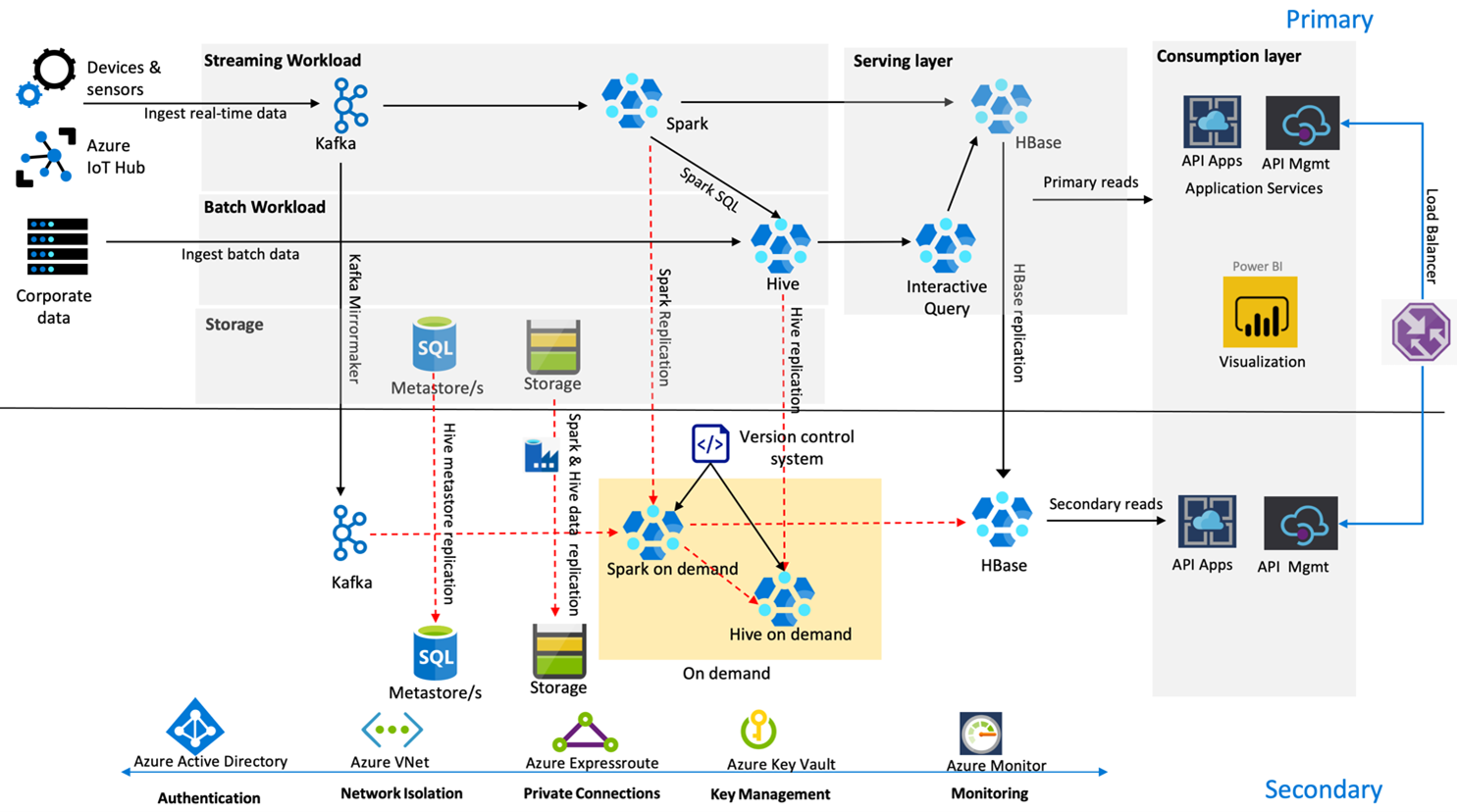
Kafka では、アクティブ/パッシブ レプリケーションを使用して、プライマリ リージョンからセカンダリ リージョンに Kafka トピックがミラー化されます。 Kafka のレプリケーションに対する代替手段として、両方のリージョンに Kafka を生成することができます。
Hive と Spark では、平常時はアクティブ プライマリ/オンデマンド セカンダリ レプリケーション モデルが使用されます。 Hive レプリケーション プロセスが定期的に実行され、Hive Azure SQL メタストアと Hive ストレージ アカウントのレプリケーションが同時に実行されます。 ADF DistCP を使用して、Spark ストレージ アカウントが定期的にレプリケートされます。 これらのクラスターの一時的な性質は、コストを最適化するのに役立ちます。 RPO に到達するためにレプリケーションは 4 時間ごとにスケジュールされ、5 時間という要件に十分対応します。
HBase レプリケーションでは、平常時はリーダー/フォロワー モデルを使用して、リージョンに関係なくデータが常に確実に提供され、RPO が非常に低くなります。
プライマリ リージョンでリージョン障害が発生した場合、ある程度古くなった 5 時間前の Web ページとバックエンドのコンテンツがセカンダリ リージョンから提供されます。 Azure サービス正常性ダッシュボードに、5 時間のリカバリ ETA が示されない場合、Contoso Retail では、セカンダリ リージョンに Hive および Spark 変換レイヤーを作成した後、すべてのアップストリーム データ ソースをセカンダリ リージョンに向けます。 セカンダリ リージョンを書き込み可能にすると、プライマリへのレプリケーションを伴うフェールバック プロセスが発生します。
ショッピング シーズンのピーク時は、セカンダリ パイプライン全体が常にアクティブになり、実行されます。 Kafka プロデューサーによって、両方のリージョンに対する生成が行われ、HBase レプリケーションはリーダー/フォロワーからリーダー/リーダーに変更され、パブリックに公開されているコンテンツが常に最新の状態になります。
ビジネス継続性にとって重要ではないため、内部レポート用のフェールオーバー ソリューションを設計する必要はありません。
この記事で説明した項目の詳細については、次を参照してください。