多くの場合、画像には検索シナリオに関連する有用な情報が含まれています。 画像を ベクター化 して、検索インデックス内の視覚的なコンテンツを表すことができます。 または、 AI エンリッチメントとスキルセット を使用して、次のような画像から検索可能な テキスト を作成および抽出できます。
OCR を使用して、停止標識の "STOP" の単語など、写真や絵からテキストを抽出することができます。 また、画像分析を使用して、画像のテキスト表現を生成することもできます (たんぽぽの写真から、たんぽぽや色といったテキストを生成するなど)。 さらに、画像に関するメタデータを抽出することもできます (サイズなど)。
この記事では、スキルセットで画像を操作する基礎について説明します。また、埋め込み画像の操作、カスタム スキル、元の画像での視覚化のオーバーレイなど、いくつかの一般的なシナリオについても説明します。
スキルセットで画像コンテンツを操作するには、次のものが必要です:
- 画像を含むソース ファイル
- 画像操作用に構成された検索インデクサー
- OCR や画像分析を呼び出す組み込みスキルまたはカスタム スキルを含むスキルセット
- 分析されたテキスト出力を受け取るフィールドを含む検索インデックス、および関連付けを確立するインデクサーの出力フィールド マッピング
必要に応じて、プロジェクションを定義して、データ マイニング シナリオのナレッジ ストアに画像分析出力を取り込むことができます。
ソース ファイルの設定
画像処理はインデクサーによって駆動されます。つまり、未加工の入力は、サポートされるデータ ソースにある必要があります。
- 画像分析では、JPEG、PNG、GIF、および BMP がサポートされます
- OCR では、JPEG、PNG、BMP、および TIF がサポートされます
画像は、スタンドアロン バイナリ ファイルにすることも、ドキュメント (PDF、RTF、および Microsoft アプリケーション ファイル) に埋め込むこともできます。 特定のドキュメントから最大 1,000 個の画像を抽出できます。 ドキュメントに 1,000 を超える画像がある場合は、最初の 1,000 個が抽出され、その後警告が生成されます。
Azure Blob Storage は、Azure AI Search での画像処理に最もよく使用されるストレージです。 BLOB コンテナーからの画像取得に関連する 3 つの主要タスクがあります。
コンテナー内のコンテンツへのアクセスを有効にします。 キーを含むフル アクセス接続文字列を使用している場合は、そのキーによってコンテンツへのアクセスが許可されます。 または、Microsoft Entra ID を使用して認証、または信頼されたサービスとして接続することもできます。
ファイルを格納する BLOB コンテナーに接続する azureblob 型のデータ ソースを作成します。
サービス レベルの制限を確認して、ソース データがインデクサーとエンリッチメントの最大サイズと数量の制限に達していないことを確認します。
画像処理用のインデクサーの構成
ソース ファイルが設定されたら、インデクサー構成で imageAction パラメーターを設定して、画像の正規化を有効にします。 画像の正規化は、ダウンストリーム処理のために画像をより均一にするのに役立ちます。 画像の正規化には、次の操作が含まれます。
- 大きい画像は、均一にするために、高さと幅の最大値にサイズ変更されます。
- 印刷の向きを指定するメタデータを持つ画像の場合、画像の回転は垂直方向の読み込みに合わせて調整されます。
imageAction (このパラメーターを none 以外に設定) を有効にすると、Azure AI Search の価格に従って画像抽出に追加料金が発生することに注意してください。
メタデータの調整結果は、各画像用に作成された複合型に取得されます。 画像の正規化の要件をオプトアウトすることはできません。 OCR や画像分析など、画像を反復処理するスキルには、正規化された画像が必要です。
インデクサーを作成または更新して、構成プロパティを設定します:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }dataToExtractをcontentAndMetadataに設定します (必須)。parsingModeが既定に設定されていることを確認します (必須)。このパラメーターにより、インデックスに作成される検索ドキュメントの細分性が決まります。 既定のモードでは 1 対 1 の対応が設定されるため、1 つの BLOB が 1 つの検索ドキュメントになります。 ドキュメントのサイズが大きい場合、またはスキルが小さなテキストのチャンクを必要とする場合は、処理のためにドキュメントをページングに再分割するテキスト分割スキルを追加できます。 ただし、検索シナリオでは、エンリッチメントに画像処理が含まれる場合、ドキュメントごとに 1 つの BLOB が必要です。
imageActionを設定して、エンリッチメント ツリー内のnormalized_imagesノードを有効にします:generateNormalizedImages。ドキュメント解析の一部として正規化された画像の配列を生成します。generateNormalizedImagePerPage(PDF にのみ適用されます)。PDF 内の各ページを 1 つの出力画像にレンダリングする正規化された画像の配列を生成します。 PDF 以外のファイルの場合、このパラメーターの動作は、generateNormalizedImagesを設定した場合と同様です。 ただし、generateNormalizedImagePerPageを設定すると、設計上インデックス作成操作 (特に大きなドキュメントの場合) がパフォーマンスが低下する可能性があります。これは複数の画像を生成する必要がある場合があるためです。
必要に応じて、生成された正規化画像の幅または高さを調整します。
normalizedImageMaxWidth(ピクセル単位)。 既定値は 2,000 です。 最大値は 10,000 です。normalizedImageMaxHeight(ピクセル単位)。 既定値は 2,000 です。 最大値は 10,000 です。
正規化された画像の最大幅と最大高さの既定値 (2000 ピクセル) は、OCR スキルと画像分析スキルでサポートされる最大サイズに基づいています。 OCR のスキルでは、英語以外の言語の場合は最大の幅と高さ 4,200、英語の場合は 10,000 がサポートされます。 上限を引き上げると、スキルセットの定義とドキュメントの言語によっては、大きな画像で処理が失敗する可能性があります。
必要に応じて、ワークロードが特定のファイルの種類を対象とする場合に、ファイルの種類の条件を設定します。 BLOB インデクサーの構成には、ファイルのインクルージョンと除外の設定が含まれます。 不要なファイルを除外できます。
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
正規化された画像について
imageAction を none 以外の値に設定すると、新しい normalized_images フィールドに画像の配列が格納されます。 各画像は、次のメンバーを含んだ複合型になります。
| 画像のメンバー | 説明 |
|---|---|
| データ | JPEG 形式の正規化画像を BASE64 でエンコードした文字列。 |
| 幅 | 正規化画像の幅 (ピクセル単位)。 |
| 高さ | 正規化画像の高さ (ピクセル単位)。 |
| originalWidth | 正規化する前の、画像の元の幅。 |
| originalHeight | 正規化する前の、画像の元の高さ。 |
| rotationFromOriginal | 正規化された画像の作成時に発生した、反時計回りの回転角度。 0 ~ 360 度の値になります。 このステップでは、カメラやスキャナーで生成された画像からのメタデータが読み取られます。 通常は、90 度の倍数になります。 |
| contentOffset | 画像が抽出された位置の、content フィールド内での文字オフセット。 このフィールドは、埋め込み画像があるファイルにのみ適用されます。 PDF ドキュメントから抽出された画像の contentOffset は、ドキュメント内から抽出されたページのテキストの末尾に常に表示されます。 つまり、画像は、ページ内にある画像の元の位置に関係なく、そのページのすべてのテキストの後に配置されます。 |
| ページ番号 | 画像が PDF から抽出またはレンダリングされた場合、このフィールドには、抽出元またはレンダリング元の PDF のページ番号 (1 から始まる) が含まれます。 画像が PDF からのものではない場合、このフィールドは 0 です。 |
| boundingPolygon | 画像が PDF から抽出またはレンダリングされた場合、このフィールドには、ページ上の画像を囲む境界ポリゴンの座標が含まれます。 多角形は、ポイントの入れ子になった配列として表されます。各ポイントには、ページの寸法に正規化された x 座標と y 座標があります。 これは、 imageAction: generateNormalizedImagesを使用して抽出されたイメージにのみ適用されます。 |
normalized_images のサンプル値:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2,
"boundingPolygon": "[[{\"x\":0.0,\"y\":0.0},{\"x\":500.0,\"y\":0.0},{\"x\":0.0,\"y\":300.0},{\"x\":500.0,\"y\":300.0}]]"
}
]
注
境界ポリゴン データは、JSON でエンコードされた二重入れ子の多角形配列を含む文字列として表されます。 各ポリゴンはポイントの配列であり、各ポイントには x 座標と y 座標があります。 座標は PDF ページを基準にしており、原点 (0, 0) は左上隅にあります。
現在、 imageAction: generateNormalizedImages を使用して抽出された画像は常に 1 つの多角形を生成しますが、複数の多角形をサポートする Document Layout スキルとの一貫性を保つため、二重入れ子構造が維持されます。
画像処理用のスキルセットの定義
このセクションでは、画像処理に関連するスキルの入力、出力、およびパターンを操作するコンテキストを提供することによって、スキル リファレンスの記事を補足します。
スキルを追加するためのスキルセットを作成または更新します。
OCR および画像分析用のテンプレートを Azure portal から追加するか、スキル リファレンス ドキュメントから定義をコピーします。 これをスキルセット定義のスキル配列に挿入します。
必要に応じて、スキルセットの Azure AI サービス プロパティにマルチサービス キーを含めます。 Azure AI Search は、無料の制限 (1 日あたりインデクサーあたり 20 個) を超えるトランザクションに対して、OCR と画像解析のために課金対象の Azure AI サービス リソースを呼び出します。 Azure AI サービスは、検索サービスと同じリージョンにある必要があります。
元の画像が PDF や、PPTX または DOCX などのアプリケーション ファイルに埋め込まれている場合、画像出力とテキスト出力をまとめたい場合は、テキスト マージ スキルを追加する必要があります。 埋め込み画像の操作については、この記事で後に詳しく説明します。
スキルセットの基本的なフレームワークが作成され、Azure AI サービスが構成されたら、個々のイメージ スキルに焦点を当て、入力とソース コンテキストを定義し、出力をインデックスまたはナレッジ ストアのフィールドにマッピングできます。
注
画像処理とダウンストリーム自然言語処理を組み合わせたスキルセットの例については、「REST チュートリアル: REST と AI を使用して Azure Blob から検索可能なコンテンツを生成する」を参照してください。 ここでは、エンティティ認識とキー フレーズ抽出にスキル イメージング出力をフィードする方法が紹介されています。
画像処理の入力について
前述のように、画像はドキュメント解析中に抽出され、準備手順として正規化されます。 正規化された画像は、画像処理スキルへの入力であり、常に次の 2 つのいずれかの方法で、エンリッチされたドキュメント ツリーで表されます。
/document/normalized_images/*は、全体で処理されるドキュメントを対象としています。/document/normalized_images/*/pagesは、チャンク (ページ) で処理されるドキュメントを対象としています。
OCR と画像分析を同じように使用しているかどうかにかかわらず、入力はほぼ同じ構造になります。
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
出力を検索フィールドにマップする
スキルセットでは、画像分析と OCR スキルの出力は常にテキストです。 出力テキストは内部のエンリッチされたドキュメント ツリー内のノードとして表され、各ノードは、お使いのアプリでコンテンツを利用するには、検索インデックスのフィールドまたはナレッジ ストアのプロジェクションにマップされる必要があります。
スキルセットで、各スキルの
outputsセクションを確認して、エンリッチされたドキュメントに存在するノードを特定します。{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }スキルの出力を受け入れるフィールドを追加するために、検索インデックスを作成または更新します。
次のフィールド コレクションの例では、コンテンツは BLOB コンテンツです。 Metadata_storage_name にはファイルの名前が含まれます (
retrievableを true に設定)。 Metadata_storage_path は BLOB の一意のパスであり、既定のドキュメント キーです。 Merged_content はテキスト マージの出力です (画像が埋め込まれている場合に便利です)。Text と layoutText は OCR スキルの出力であり、ドキュメント全体に対して OCR によって生成されるすべての出力をキャプチャするために文字列コレクションである必要があります。
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],インデクサーを更新して、スキルセット出力 (エンリッチメント ツリー内のノード) をインデックス フィールドにマップします。
エンリッチされたドキュメントは内部的です。 エンリッチメントされたドキュメント ツリー内のノードを外部化するには、ノード コンテンツを受け取るインデックス フィールドを指定する出力フィールド マッピングを設定します。 エンリッチされたデータは、インデックス フィールドを介してアプリによってアクセスされます。 次の例は、検索インデックスの text フィールドにマップされたエンリッチされたドキュメントの text ノード (OCR 出力) を示しています。
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]インデクサーを実行して、ソース ドキュメントの取得、画像処理、およびインデックス作成を呼び出します。
検証結果
インデックスに対してクエリを実行して、画像処理の結果を確認します。 検索クライアントとしての Search エクスプローラーまたは HTTP 要求を送信する任意のツールを使用します。 次のクエリでは、画像処理の出力を含むフィールドを選択します。
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR は、画像ファイル内のテキストを認識します。 つまり、ソース ドキュメントがピュア テキストまたはピュア画像の場合、OCR フィールド (text と layoutText) は空になります。 同様に、ソース ドキュメントの入力が厳密に指定されているテキストである場合、画像分析フィールド (imageCaption と imageTags) は空になります。 インデクサーの実行では、イメージング入力が空の場合、警告が出力されます。 このような警告が発生するのは、エンリッチされたドキュメントでノードが設定されていない場合です。 BLOB のインデックス作成では、コンテンツの種類を個別に使用する場合に、ファイルの種類を含めたり除外したりできることを思い出してください。 これらの設定を使用して、インデクサー実行中のノイズを減らすことができます。
結果を確認するための代替クエリには、content と merged_content の各フィールドが含まれている場合があります。 これらのフィールドには、イメージ処理が実行されなかった BLOB ファイルのコンテンツも含まれます。
スキルの出力について
スキルの出力には、text (OCR)、layoutText (OCR)、merged_content、captions (画像分析)、tags (画像分析) が含まれます:
textは、OCR で生成された出力を格納します。 このノードは、型Collection(Edm.String)のフィールドにマップする必要があります。 複数の画像を含むドキュメントの場合、コンマ区切り文字列で構成されるtextフィールドが検索ドキュメントごとに 1 つあります。 次の図は、3 つのドキュメントの OCR 出力を示しています。 1 つ目は、画像のないファイルが含まれているドキュメントです。 2 つ目は、Microsoft という 1 つの単語を含むドキュメント (画像ファイル) です。 3 つ目は、複数の画像を含むドキュメントです。テキストを含まないもの ("",) もあります。"value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]layoutTextには、正規化画像の境界ボックスと座標で表される、ページ上のテキストの位置に関する OCR 生成情報が格納されます。 このノードは、型Collection(Edm.String)のフィールドにマップする必要があります。 コンマ区切り文字列で構成されるlayoutTextフィールドが検索ドキュメントごとに 1 つあります。merged_contentは、テキスト マージ スキルの出力を格納します。これは、画像の代わりにEdm.Stringが埋め込まれた、ソース ドキュメントからの未加工のテキストを格納する、型textの 1 つの大きなフィールドである必要があります。 ファイルがテキストのみの場合、OCR と画像分析では何も行われず、merged_contentはcontent(BLOB のコンテンツを含む BLOB プロパティ) と同じになります。imageCaptionは、個別のタグや長いテキストの説明として画像の説明をキャプチャします。imageTagsは、画像に関するタグをキーワードのコレクション、すなわちソース ドキュメント内のすべての画像に対する 1 つのコレクションとして格納します。
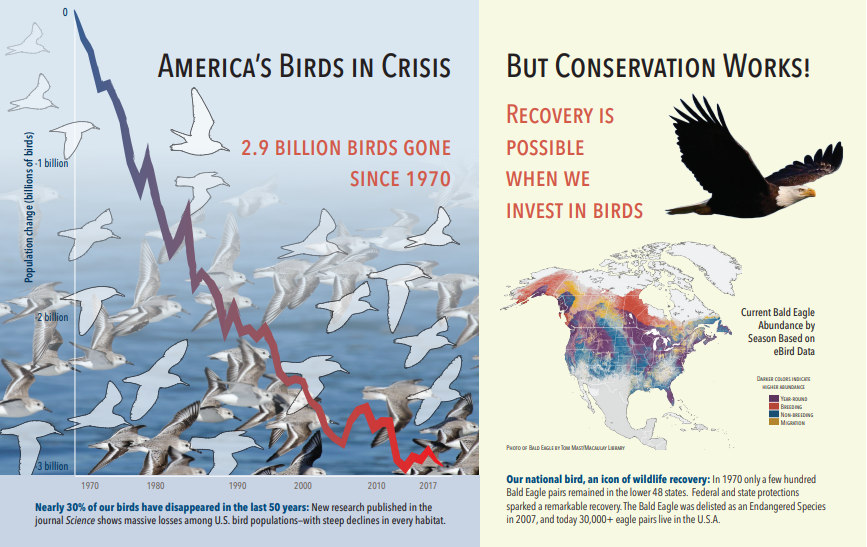
次のスクリーンショットは、テキストと埋め込み画像を含む PDF の図です。 ドキュメント解析は、カモメの群れ、地図、ワシの 3 つの埋め込み画像を検出しました。 この例の他のテキスト (タイトル、見出し、本文を含む) はテキストとして抽出され、画像処理から除外されました。
画像分析の出力は、次の JSON (検索結果) に示されています。 スキル定義を使用すると、目的の視覚機能を指定できます。 この例では、タグと説明が生成されましたが、より多くの出力から選択できます。
imageCaption出力は、画像ごとに 1 つの説明の配列であり、画像を記述する単一の単語と長い語句で構成されるtagsで表されます。 タグは、水中を泳ぐカモメの群れ、または鳥の接写で構成されています。imageTags出力は単一のタグの配列で、作成順に列挙されています。 タグが繰り返されていることに注目してください。 集計もグループ化も行われません。
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
シナリオ: PDF 内の埋め込み画像
処理する画像が PDF や DOCX などの他のファイルに埋め込まれている場合、エンリッチメント パイプラインは画像だけを抽出してから処理のために OCR または画像分析に渡します。 画像抽出は、ドキュメント解析フェーズ中に行われます。画像が分離されると、処理された出力を元のソース テキストに明示的にマージしない限り、分離されたままになります。
テキスト マージは、画像処理出力をドキュメントに戻すのに使用されます。 テキスト マージは、厳格な要件ではありませんが、画像出力 (OCR テキスト、OCR layoutText、画像タグ、画像キャプション) をドキュメントに再導入できるように、頻繁に呼び出されます。 スキルに応じて、画像出力では埋め込みバイナリ画像が同等のインプレース テキストに置き換えられます。 画像分析出力は、画像の場所でマージできます。 OCR 出力は、常に各ページの最後に表示されます。
次のワークフローでは、画像の抽出、分析、マージのプロセス、およびパイプラインを拡張して、画像処理された出力をエンティティ認識やテキスト翻訳などのテキスト ベースの他のスキルにプッシュする方法の概要を示します。
データ ソースに接続した後、インデクサーはソース ドキュメントの読み込みと解析、画像とテキストの抽出、および処理のための各コンテンツ タイプのキューイングを行います。 ルート ノード (ドキュメント) のみで構成されるエンリッチされたドキュメントが作成されます。
キュー内の画像は正規化され、エンリッチメントされたドキュメントにド document/normalized_images ノードとして渡されます。
"/document/normalized_images"を入力として使用して画像のエンリッチメントが実行されます。画像出力は、各出力を個別のノードとして、エンリッチされたドキュメント ツリーに渡されます。 出力は、スキルによって異なります (OCR 用のテキストと layoutText、画像分析用のタグとキャプション)。
それらの画像のテキスト表現を、ファイルから抽出された未加工のテキストと組み合わせることで、テキスト マージが実行されます。省略可能ですが、検索ドキュメントにテキストと画像由来のテキストの両方を一緒に含めたい場合にはお勧めします。 テキスト チャンクは 1 つの大きな文字列に統合され、最初にテキストが文字列に挿入されてから、OCR テキスト出力または画像タグとキャプションが挿入されます。
テキスト マージの出力が、テキストの処理を実行するダウンストリーム スキルを分析するための最終的なテキストになります。 たとえば、スキルセットに OCR とエンティティ認識の両方が含まれている場合、エンティティ認識への入力は
"document/merged_text"(テキスト マージ スキル出力の targetName) である必要があります。すべてのスキルを実行すると、エンリッチされたドキュメントが完成します。 最後の手順では、インデクサーは出力フィールド マッピングを参照して、検索インデックス内の個々のフィールドにエンリッチされたコンテンツを送信します。
次のスキルセットの例では、埋め込み画像の代わりに OCR 処理されたテキストを埋め込んで、ドキュメントの元のテキストを含む merged_text フィールドを作成します。 また、入力として merged_text を使用するエンティティ認識スキルも含まれています。
要求本文の構文
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
merged_text フィールドが作成されたら、それを検索可能フィールドとしてインデクサー定義内にマップできます。 ファイルのすべてのコンテンツ (画像のテキストを含む) が検索可能になります。
シナリオ: 境界ボックスの視覚化
もう 1 つの一般的なシナリオとして、検索結果のレイアウト情報を視覚化するケースが挙げられます。 たとえば、特定のテキストが画像内のどこで検出されたかを、検索結果の一部として強調表示することができます。
OCR ステップは正規化された画像に対して実行されるため、レイアウト座標は正規化された画像空間内にありますが、元の画像を表示する必要がある場合は、レイアウト内の座標ポイントを元の画像座標系に変換します。
次のアルゴリズムはパターンを示したものです。
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
シナリオ: カスタム画像スキル
画像をカスタム スキルに渡したり、そこから返したりすることもできます。 スキルセットは、カスタム スキルに渡される画像を Base64 でエンコードします。 カスタム スキル内で画像を使用するには、カスタム スキルへの入力として "/document/normalized_images/*/data" を設定します。 カスタム スキル コード内で、文字列を画像に変換する前に Base64 でデコードします。 スキルセットに画像を返す場合は、画像をスキルセットに返す前に Base64 でエンコードします。
画像は、次のプロパティを持つオブジェクトとして返されます。
{
"$type": "file",
"data": "base64String"
}
Azure Search Python サンプル リポジトリには、イメージを強化するカスタム スキルの Python で実装された完全なサンプルがあります。
カスタム スキルに画像を渡す
画像を操作するためにカスタム スキルが必要なシナリオでは、画像をカスタム スキルに渡したり、スキルからテキストまたは画像が返されるようにしたりできます。 次のスキルセットはサンプルからのものです。
次のスキルセットでは、(ドキュメント解析中に取得した) 正規化された画像を取得し、画像のスライスを出力します。
サンプル スキルセット
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
カスタム スキルの例
カスタム スキル自体は、スキルセットの外部にあります。 この場合、最初にカスタム スキル形式で要求レコードのバッチをループ処理してから、base64 エンコード文字列を画像に変換するのは Python コードです。
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
同様に、画像を返すには、JSON オブジェクト内で$typeの プロパティを使用して base64 エンコード文字列を返します。
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}