REST チュートリアル: スキルセットを使用して Azure AI 検索で検索可能なコンテンツを生成する
[アーティクル] 2024/09/03
20 人の共同作成者
フィードバック
この記事の内容
概要
前提条件
REST ファイルを設定する
パイプラインを作成する
インデックス作成の監視
結果をチェックする
リセットして再実行する
重要なポイント
リソースをクリーンアップする
次のステップ
さらに 6 個を表示
このチュートリアルでは、インデックス作成中にコンテンツの抽出と変換のための AI エンリッチメント パイプライン を作成する REST API を呼び出す方法について説明します。
スキルセットは生コンテンツに AI 処理を追加し、そのコンテンツをより統一して検索できるようにします。 スキルセットのしくみを把握したら、画像分析から自然言語処理、外部から提供するカスタマイズされた処理まで、幅広い変換をサポートできます。
このチュートリアルでは、次のことを行う方法について説明します:
エンリッチメント パイプラインでオブジェクトを定義する。
スキルセットを構築する。 OCR、言語検出、エンティティ認識、キー フレーズ抽出を呼び出します。
パイプラインを実行する。 検索インデックスを作成して読み込みます。
フルテキスト検索を使用して結果を確認する。
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウント を作成してください。
このチュートリアルでは、REST クライアントおよび Azure AI Search REST API を使用して、データ ソース、インデックス、インデクサー、スキルセットを作成します。
インデクサー は、Azure Storage 上の BLOB コンテナー内のサンプル データ (非構造化テキストとイメージ) のコンテンツ抽出から始めて、パイプライン内の各ステップを実行します。
コンテンツが抽出されると、スキルセット は Microsoft の組み込みスキルを実行して情報を検索および抽出します。 これらのステップには、画像の光学式文字認識 (OCR)、テキストの言語検出、キーフレーズの抽出、エンティティ認識 (組織) が含まれます。 スキルセットによって作成された新しい情報は、インデックス 内のフィールドに送信されます。 インデックスが作成されると、クエリ、ファセット、およびフィルター内のフィールドを使用できるようになります。
このチュートリアルには無料の検索サービスを使用できます。 Free レベルでは、インデックス、インデクサー、データ ソースがそれぞれ 3 つに限定されています。 このチュートリアルでは、それぞれ 1 つずつ作成します。 開始する前に、ご利用のサービスに新しいリソースを受け入れる余地があることを確認してください。
サンプル データ リポジトリの zip ファイルをダウンロードし、内容を抽出します。 方法については、こちら をご覧ください。
サンプル データを Azure Storage にアップロードする
Azure Storage で新しいコンテナーを作成し、cog-search-demo という名前を付けます。
サンプル データ ファイルのアップロード 。
Azure AI 検索で接続を作成できるように、ストレージ接続文字列を取得します。
左側で、[アクセス キー] を選びます。
キー 1 またはキー 2 の接続文字列をコピーします。 接続文字列は、次の例のような URL です:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
組み込みの AI エンリッチメントは、自然言語と画像の処理のための言語サービスや Azure AI Vision などの Azure AI サービスによってサポートされています。 このチュートリアルのような小規模なワークロードでは、インデクサーごとに 20 トランザクションの無料割り当てを使用できます。 大規模なワークロードの場合は、Azure AI サービスのマルチリージョン リソースを従量課金制の価格のスキルセットにアタッチ します。
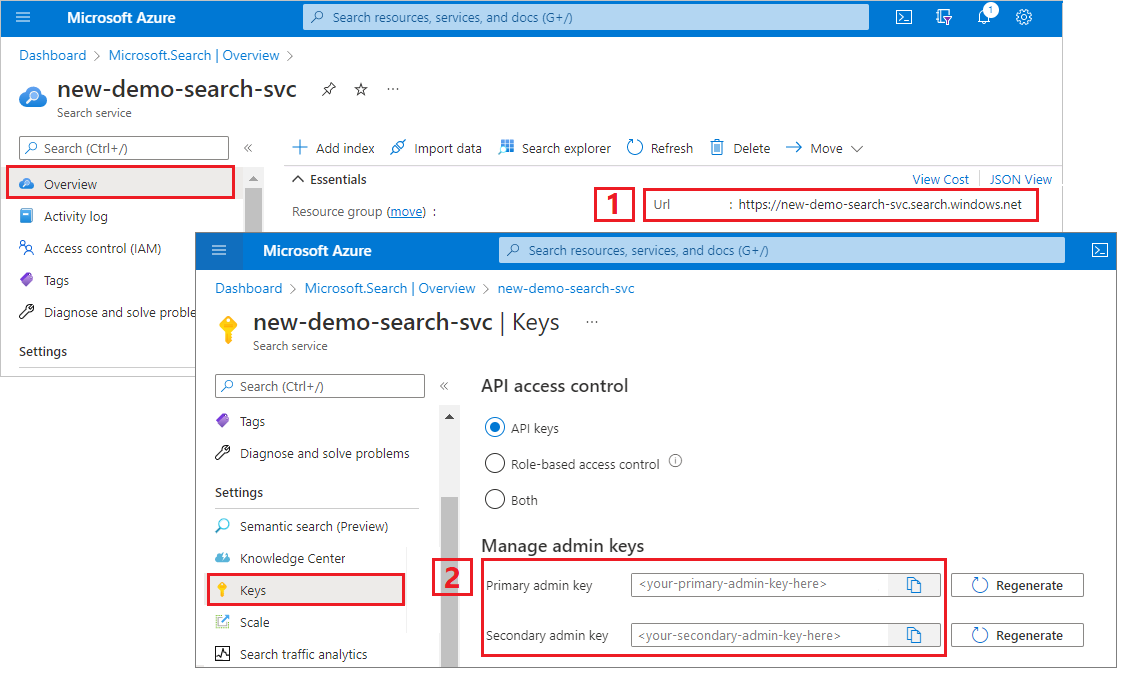
検索サービスの URL と API キーをコピーする このチュートリアルでは、Azure AI 検索への接続にエンドポイントと API キーが必要です。 これらの値は Azure portal から取得できます。
Azure portal にサインインし、検索サービスの [概要] ページに移動して URL をコピーします。 たとえば、エンドポイントは https://mydemo.search.windows.net のようになります。
[設定] >[キー] で管理者キーをコピーします。 管理者キーは、オブジェクトの追加、変更、削除で使用します。 2 つの交換可能な管理者キーがあります。 どちらかをコピーします。
Visual Studio Code を起動し、skillset-tutorial.rest ファイルを開きます。 REST クライアントに関するヘルプが必要な場合は、「クイック スタート: REST を使用したテキスト検索 」を参照してください。
変数の値 (検索サービス エンドポイント、検索サービス管理者 API キー、インデックス名、Azure Storage アカウントへの接続文字列、BLOB コンテナー名) を指定します。
AI エンリッチメントはインデクサー駆動型です。 チュートリアルのこの部分では、データ ソース、インデックス定義、スキルセット、インデクサーという 4 つのオブジェクトを作成します。
データ ソースの作成 を呼び出し、サンプルデータファイルを含む Blob コンテナーへの接続文字列を設定します。
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
スキルセットの作成 を呼び出し、コンテンツに適用するエンリッチメントのステップを指定します。 スキルは、依存関係がない限り並列で実行されます。
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
重要なポイント:
要求の本文では、次の組み込みスキルが指定されています。
テーブルを展開する
スキル
説明
光学式文字認識 画像ファイル内のテキストと数値を認識します。
テキスト マージ 以前に分離されたコンテンツを再結合する "マージ コンテンツ" を作成します。画像を埋め込んだドキュメント (PDF、DOCX など) に有効です。 画像とテキストは、ドキュメント解析フェーズ中に分離します。 マージ スキルでそれを再結合するには、認識されたテキストや画像キャプション、エンリッチメントの際に作成されたタグを、そのドキュメント内で画像が抽出された場所に挿入します。
スキルセットでマージされたコンテンツを扱う場合、このノードには、OCR や画像解析を行わないテキストのみのドキュメントを含む、ドキュメント内のすべてのテキストが含まれます。
言語検出 言語を検出し、言語名またはコードを出力します。 多言語データ セットでは、言語フィールドがフィルターに役立ちます。
エンティティの認識 マージされたコンテンツから、人、組織、場所の名前を抽出します。
テキスト分割 キー フレーズの抽出スキルを呼び出す前に、マージされた大きいコンテンツを小さいチャンクに分割します。 キー フレーズ抽出は、50,000 文字以下の入力を受け入れます。 いくつかのサンプル ファイルは、分割してこの制限内に収める必要があります。
キー フレーズ抽出 上位のキー フレーズを抜き出します。
各スキルは、ドキュメントのコンテンツで実行されます。 処理中に、Azure AI Search が各ドキュメントを解読して、さまざまなファイル形式からコンテンツを読み取ります。 ソース ファイルから配信されたテキストが見つかると、ドキュメントごとに 1 つずつ、生成された content フィールドに配置されます。 そのため、入力は "/document/content" になります。
キー フレーズの抽出では、テキスト スプリッター スキルを使用して大きなファイルをページに分割するため、キー フレーズ抽出スキルのコンテキストは "/document/content" ではなく、"document/pages/*" (ドキュメント内の各ページ) になります。
出力はインデックスにマップすることができ、ダウンストリーム スキルへの入力として、または言語コードと同様に両方として使用されます。 インデックスでは、言語コードはフィルター処理に役立ちます。 スキルセットの基礎の詳細については、スキルセットを定義する方法 に関するページをご覧ください。
Create Index を呼び出して、Azure AI Search で転置インデックスやその他の構成を作成するために使用するスキーマを提供します。
インデックスの最大コンポーネントはフィールド コレクションであり、ここで、データ型と属性によって Azure AI Search でのコンテンツと動作が決まります。 新しく生成された出力のフィールドがあることを確認してください。
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Create Indexer を呼び出し、パイプラインを駆動させます。 これまでに作成した 3 つのコンポーネント (データ ソース、スキルセット、インデックス) は、インデクサーへの入力です。 Azure AI Search でのインデクサーの作成は、パイプライン全体を動かすイベントです。
この手順は完了までに数分かかる予定です。 データ セットが小さい場合でも、分析スキルは計算を集中的に行います。
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
重要なポイント:
要求の本文には、前のオブジェクトへの参照、画像処理に必要な構成プロパティ、2 種類のフィールド マッピングが含まれます。
スキルセットの前に "fieldMappings" が処理されて、データ ソースからインデックス内のターゲット フィールドにコンテンツが送信されます。 フィールド マッピングを使用して、変更されていない既存のコンテンツをインデックスに送信します。 フィールド名と型が両側で共通していれば、マッピングは必要ありません。
"outputFieldMappings" は、スキルセットの実行後にスキルによって作成されたフィールドを対象としています。 outputFieldMappings での sourceFieldName への参照は、ドキュメント解析またはエンリッチメントによって作成されるまでは存在しません。 targetFieldName はインデックス内のフィールドであり、インデックス スキーマで定義されています。
"maxFailedItems" パラメータは -1 に設定します。これにより、インデックス作成エンジンに、データのインポート中のエラーを無視するよう指示します。 デモのデータ ソースにはドキュメントがほとんどないため、これは許容できます。 大きいデータ ソースの場合は、この値を 0 より大きい値に設定します。
"dataToExtract":"contentAndMetadata" ステートメントは、BLOB のコンテンツ プロパティと各オブジェクトのメタデータから値を自動的に抽出するようにインデクサーに指示します。
imageAction パラメータは、インデクサーに対して、データ ソースで見つかった画像からテキストを抽出するように指示します。 "imageAction":"generateNormalizedImages" 構成は、OCR スキルおよびテキスト マージ スキルと組み合わされて、イメージからテキスト (たとえば、一時停止の道路標識から "stop" という単語) を抽出し、それをコンテンツ フィールドの一部として埋め込むよう、インデクサーに指示します。 この動作は、埋め込まれている画像 (PDF 内の画像など) と、スタンドアロン画像 (JPG ファイルなど) の両方に適用されます。
インデクサーを作成すると、パイプラインが呼び出されます。 データ、入力と出力のマッピング、または操作の順序に及ぶ問題がある場合は、この段階で現れます。 コードまたはスクリプトに変更を加えてパイプラインを再実行するには、最初にオブジェクトを削除する必要がある場合があります。 詳細については、「リセットして再実行する 」をご覧ください。
インデックス作成とエンリッチメントは、インデクサー作成要求を送信するとすぐに開始されます。 スキルセットの複雑さと操作によっては、インデックス作成に時間がかかる場合があります。
インデクサーがまだ動作しているかどうかを調べるには、Get Indexer Status を呼び出してインデクサーの状態を確認します。
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
重要なポイント:
警告は一部のシナリオで一般的であり、必ずしも問題があることを示すとは限りません。 たとえば、BLOB コンテナーに画像ファイルが含まれていて、パイプラインで画像を処理しない場合、画像が処理されなかったことを示す警告が表示されます。
このサンプルには、テキストが含まれない PNG ファイルがあります。 このファイルでは、テキスト ベースの 5 つのスキル (言語検出、場所、組織、人、キー フレーズ抽出のエンティティ認識) すべての実行に失敗します。 結果の通知は実行履歴に表示されます。
AI が生成したコンテンツを含むインデックスを作成したので、Search Documents を呼び出していくつかのクエリを実行し、結果を確認します。
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
フィルターは、目的の項目に結果を絞り込むのに役立ちます:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
これらのクエリは、Azure AI Search によって作成された新しいフィールドでクエリ構文やフィルターを使用するいくつかの方法を示しています。 その他のクエリの例については、Search Documents REST API の例 、単純構文クエリの例 、および完全な Lucene クエリの例 に関するページを参照してください。
開発の初期段階で設計を繰り返すことはよくあります。 リセットして再実行 は、反復に役立ちます。
このチュートリアルでは、REST API を使用して AI エンリッチメント パイプライン (データ ソース、スキルセット、インデックス、インデクサー) を作成するための基本的な手順について説明します。
組み込みのスキル については、入力と出力を介したスキルの連結のしくみを示すスキルセットの定義と共に概要説明しました。 また、Azure AI Search サービスでエンリッチされた値をパイプラインから検索可能なインデックス内にルーティングするには、インデクサーの定義に outputFieldMappings が必要であることも学習しました。
最後に、結果をテストし、今後の反復のためにシステムをリセットする方法について学習しました。 インデックスに対するクエリを発行すると、エンリッチされたインデックス作成パイプラインによって作成された出力が返されることを学習しました。
所有するサブスクリプションを使用している場合は、プロジェクトの終了時に、不要になったリソースを削除することをお勧めします。 リソースを実行したままにすると、お金がかかる場合があります。 リソースは個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
ポータルの左側のナビゲーション ウィンドウにある [すべてのリソース] または [リソース グループ] リンクを使って、リソースを検索および管理できます。
AI エンリッチメント パイプラインのオブジェクトをすべて理解したら、スキルセットの定義と個々のスキルについて詳しく見てみましょう。