ピボットテーブルを使用すると、大量のデータを迅速に分析できます。 その力は複雑になります。 Office スクリプト API を使用すると、ニーズに合わせてピボットテーブルをカスタマイズできますが、API セットのスコープによって、作業を開始することが困難になります。 この記事では、一般的なピボットテーブル タスクを実行する方法と、重要なクラスとメソッドについて説明します。
注:
API で使用される用語のコンテキストを理解するには、まず Excel のピボットテーブル ドキュメントを参照してください。 「 ピボットテーブルを作成する」から始めて、ワークシート データを分析します。
オブジェクト モデル
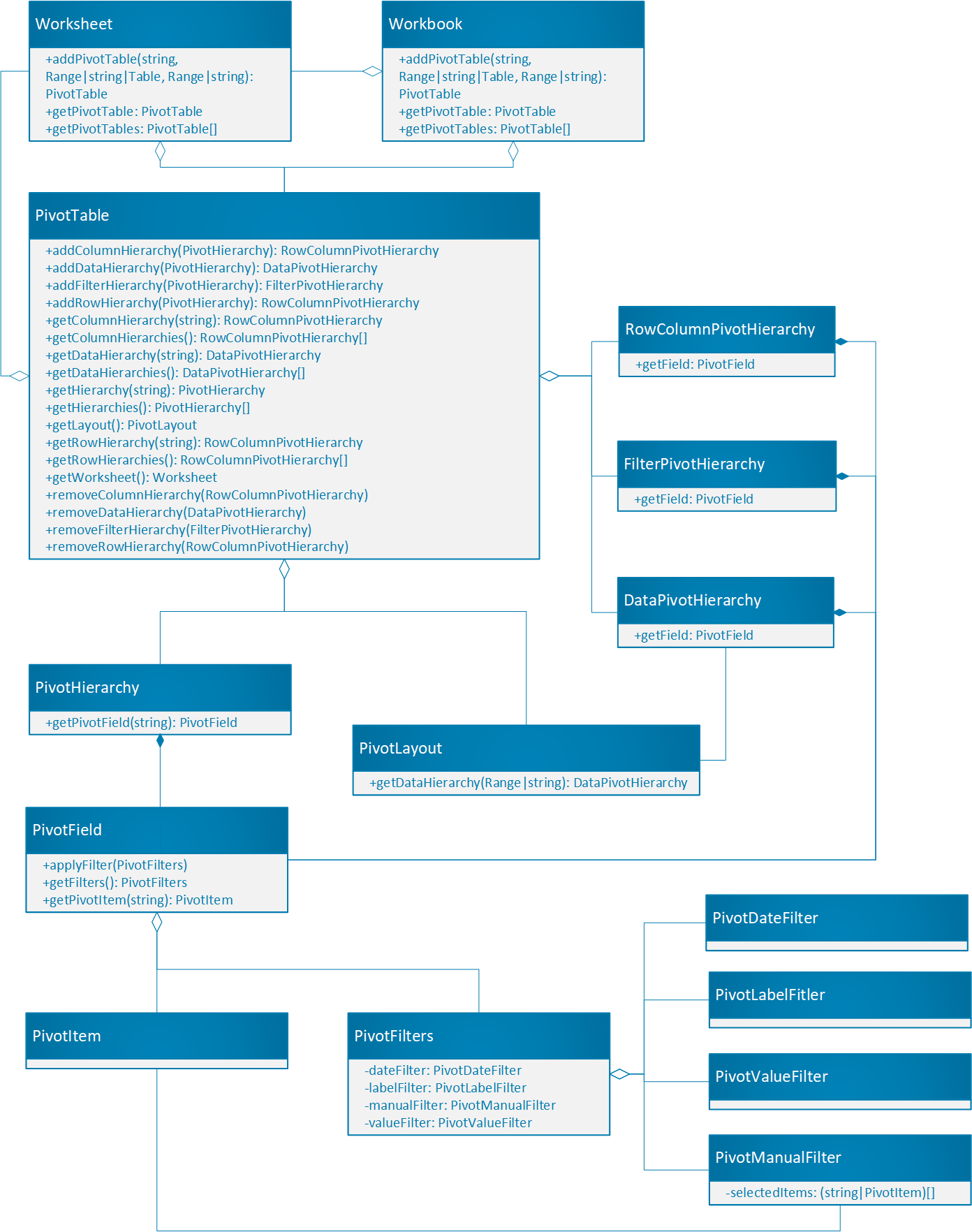
ピボットテーブルは、Office Scripts API のピボットテーブルの中心的なオブジェクトです。
- Workbook オブジェクトには、すべてのピボットテーブルのコレクションがあります。 各 ワークシート には、そのシートに対してローカルなピボットテーブル コレクションも含まれています。
- ピボットテーブルには、PivotHierarchies が含まれています。 階層は、テーブル内の列と考えることができます。
- PivotHierarchies は、行または列 (RowColumnPivotHierarchy)、データ (DataPivotHierarchy)、フィルター (FilterPivotHierarchy) として追加できます。
- 各 PivotHierarchy には、正確に 1 つの PivotField が含まれています。 Excel の外部のピボットテーブル構造には階層ごとに複数のフィールドが含まれている可能性があるため、この設計は将来のオプションをサポートするために存在します。 Office スクリプトの場合、フィールドと階層は同じ情報にマップされます。
- PivotField には複数の PivotItem が含まれています。 各 PivotItem は、フィールド内の一意の値です。 各項目はテーブル列の値と考えてください。 フィールドがデータに使用されている場合は、合計などの集計値を項目にすることもできます。
- PivotLayout は、PivotFields と PivotItems の表示方法を定義します。
- PivotFilters は、 異なる条件を使用して ピボットテーブル からデータをフィルター処理します。
これらのリレーションシップの実際の動作を確認するには、まずサンプル ブックをダウンロードします。 そのデータは、さまざまな農場からの果物の売上を表します。 これは、この記事のすべての例のベースです。 記事全体でサンプル スクリプトを実行して、ピボットテーブルを作成して探索します。
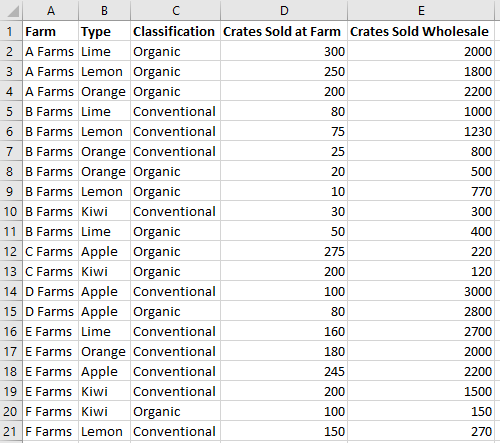
フィールドを含むピボットテーブルを作成する
ピボットテーブルは、既存のデータへの参照を使用して作成されます。 範囲とテーブルの両方をピボットテーブルのソースにすることができます。 また、ブックに存在する場所も必要です。 ピボットテーブルのサイズは動的であるため、変換先範囲の左上隅のみが指定されます。
次のコード スニペットは、データ範囲に基づいてピボットテーブルを作成します。 ピボットテーブルには階層がないため、データはまだグループ化されていません。
const dataSheet = workbook.getWorksheet("Data");
const pivotSheet = workbook.getWorksheet("Pivot");
const farmPivot = pivotSheet.addPivotTable(
"Farm Pivot", /* The name of the PivotTable. */
dataSheet.getUsedRange(), /* The source data range. */
pivotSheet.getRange("A1") /* The location to put the new PivotTable. */);
階層とフィールド
ピボットテーブルは階層を通じて編成されます。 これらの階層は、特定の種類の階層として追加されたときにデータをピボットするために使用されます。 階層には 4 種類あります。
- [行]: 水平行の項目を表示します。
- 列: 垂直列の項目を表示します。
- データ: 行と列に基づいて値の集計を表示します。
- フィルター: ピボットテーブルの項目を追加または削除します。
ピボットテーブルには、これらの特定の階層に割り当てられたフィールドの数または数を指定できます。 ピボットテーブルには、集計された数値データを表示するために少なくとも 1 つのデータ階層が必要であり、その概要をピボットする行または列が少なくとも 1 つ必要です。 次のコード スニペットは、2 つの行階層と 2 つのデータ階層を追加します。
farmPivot.addRowHierarchy(farmPivot.getHierarchy("Farm"));
farmPivot.addRowHierarchy(farmPivot.getHierarchy("Type"));
farmPivot.addDataHierarchy(farmPivot.getHierarchy("Crates Sold at Farm"));
farmPivot.addDataHierarchy(farmPivot.getHierarchy("Crates Sold Wholesale"));
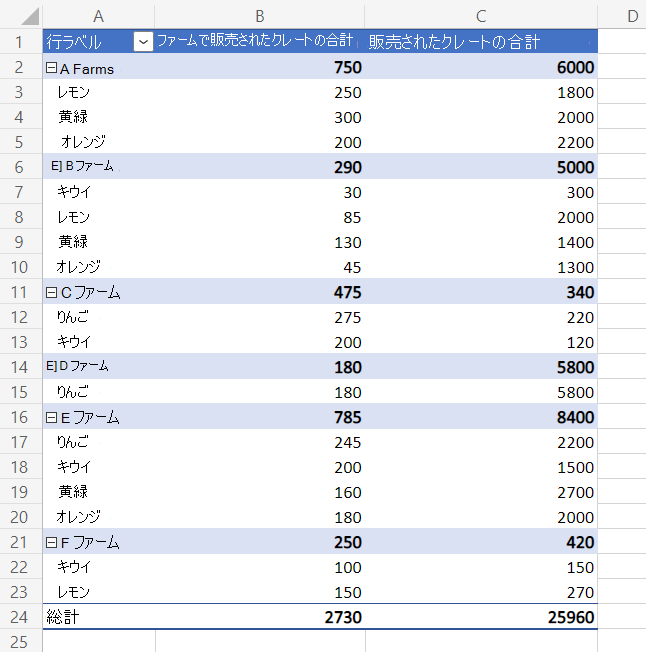
レイアウト範囲
ピボットテーブルの各部分は、範囲にマップされます。 これにより、スクリプトはピボットテーブルからデータを取得し、スクリプトの後半で使用したり、 Power Automate フローで返したりできます。 これらの範囲は、PivotTable.getLayout()から取得された PivotLayout オブジェクトを介してアクセスされます。 次の図は、 PivotLayout の メソッドによって返される範囲を示しています。
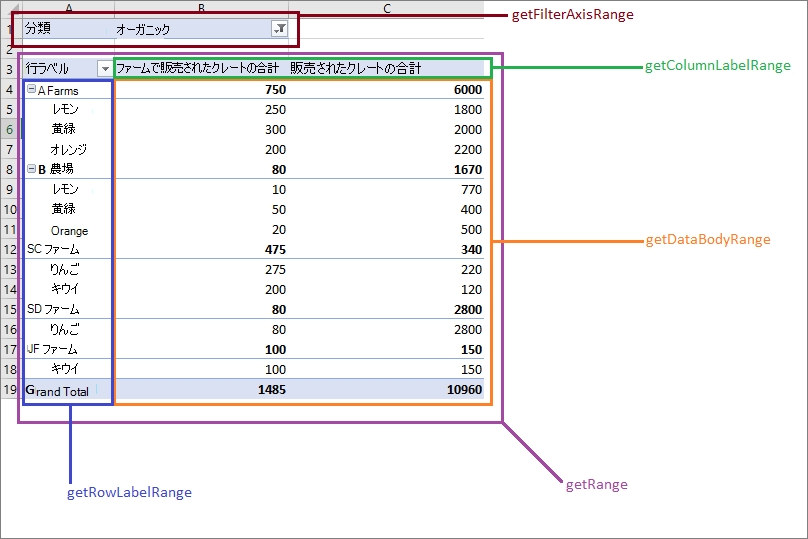
ピボットテーブルの合計出力
合計行の場所は、レイアウトに基づいています。
PivotLayout.getBodyAndTotalRangeを使用し、列の最後の行を取得して、スクリプトのピボットテーブルからデータを使用します。
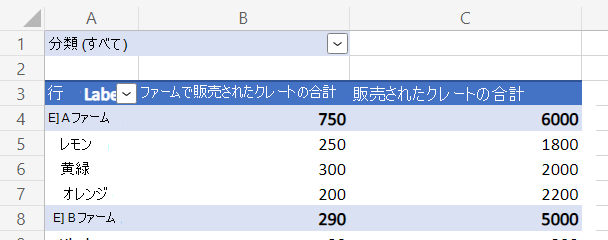
次の例では、ブック内の最初のピボットテーブルを検索し、[総計] セルの値をログに記録します (下の図では緑色で強調表示されています)。
![[総計] 行が緑色に強調表示された果物の売上を示すピボットテーブル。](../images/sample-pivottable-grand-total-row.png)
function main(workbook: ExcelScript.Workbook) {
// Get the first PivotTable in the workbook.
const pivotTable = workbook.getPivotTables()[0];
// Get the names of each data column in the PivotTable.
const pivotColumnLabelRange = pivotTable.getLayout().getColumnLabelRange();
// Get the range displaying the pivoted data.
const pivotDataRange = pivotTable.getLayout().getBodyAndTotalRange();
// Get the range with the "grand totals" for the PivotTable columns.
const grandTotalRange = pivotDataRange.getLastRow();
// Print each of the "Grand Totals" to the console.
grandTotalRange.getValues()[0].forEach((column, columnIndex) => {
console.log(`Grand total of ${pivotColumnLabelRange.getValues()[0][columnIndex]}: ${grandTotalRange.getValues()[0][columnIndex]}`);
// Example log: "Grand total of Sum of Crates Sold Wholesale: 11000"
});
}
フィルターとスライサー
ピボットテーブルをフィルター処理するには、3 つの方法があります。
FilterPivotHierarchies
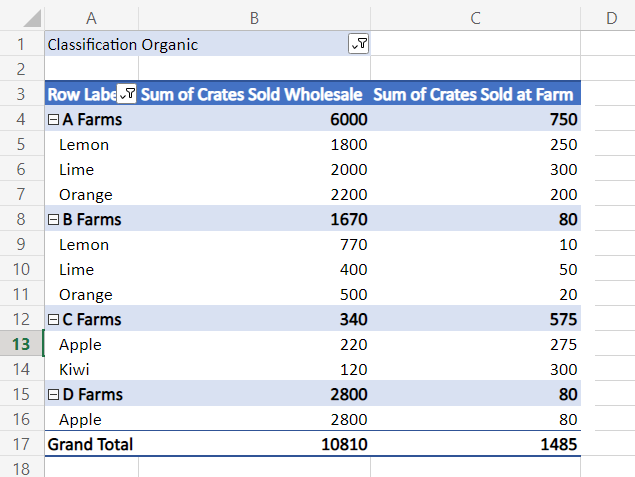
FilterPivotHierarchies 追加の階層を追加して、すべてのデータ行をフィルター処理します。 除外された項目を含む行は、ピボットテーブルとその概要から除外されます。 これらのフィルターは項目に基づいているため、個別の値でのみ機能します。 "分類" がサンプルのフィルター階層の場合、ユーザーはフィルターの "Organic" と "Conventional" の値を選択できます。 同様に、"クレート販売卸売" が選択されている場合、フィルター オプションは数値範囲ではなく、120 や 150 などの個々の数値になります。
FilterPivotHierarchies は、すべての値が選択された状態で作成されます。 つまり、ユーザーがフィルター コントロールを手動で操作するか、FilterPivotHierarchyに属するフィールドにPivotManualFilterが設定されるまで、何もフィルター処理されません。
次のコード スニペットは、フィルター階層として "分類" を追加します。
farmPivot.addFilterHierarchy(farmPivot.getHierarchy("Classification"));
PivotFilters
PivotFilters オブジェクトは、1 つのフィールドに適用されるフィルターのコレクションです。 各階層には正確に 1 つのフィールドがあるため、フィルターを適用するときは、常に PivotHierarchy.getFields() の最初のフィールドを使用する必要があります。 フィルターの種類は 4 つあります。
- 日付フィルター: カレンダーの日付ベースのフィルター処理。
- ラベル フィルター: テキスト比較フィルター。
- 手動フィルター: カスタム入力フィルター処理。
- 値フィルター: 数値比較フィルター。 これにより、関連付けられている階層内の項目と、指定したデータ階層内の値が比較されます。
通常、4 種類のフィルターのうちの 1 つだけが作成され、フィールドに適用されます。 スクリプトで互換性のないフィルターを使用しようとすると、"引数が無効であるか、または不足しているか、形式が正しくない" というテキストでエラーがスローされます。
次のコード スニペットは、2 つのフィルターを追加します。 1 つ目は、既存の "分類" フィルター階層内の項目を選択する手動フィルターです。 2 番目のフィルターは、"クレート販売卸売" が 300 未満のファームを削除します。 これにより、元のデータの個々の行ではなく、これらのファームの "合計" が除外されることに注意してください。
const classificationField = farmPivot.getFilterHierarchy("Classification").getFields()[0];
classificationField.applyFilter({
manualFilter: {
selectedItems: ["Organic"] /* The included items. */
}
});
const farmField = farmPivot.getHierarchy("Farm").getFields()[0];
farmField.applyFilter({
valueFilter: {
condition: ExcelScript.ValueFilterCondition.greaterThan, /* The relationship of the value to the comparator. */
comparator: 300, /* The value to which items are compared. */
value: "Sum of Crates Sold Wholesale" /* The name of the data hierarchy. Note the "Sum of" prefix. */
}
});
スライサー
スライサーは 、ピボットテーブル (または標準テーブル) 内のデータをフィルター処理します。 これらはワークシート内の移動可能なオブジェクトであり、選択を簡単にフィルター処理できます。 スライサーは、手動フィルターと同様の方法で動作し、 PivotFilterHierarchy。
PivotFieldの項目は、ピボットテーブルに含めるか、ピボットテーブルから除外するように切り替えられます。
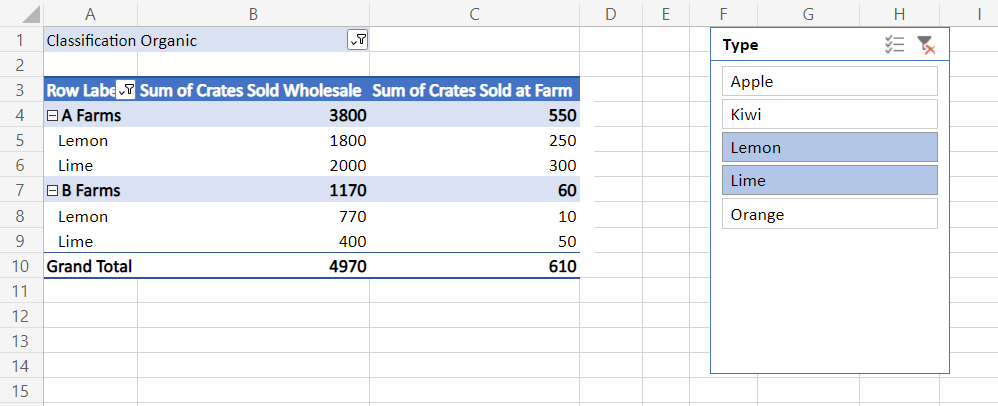
次のコード スニペットは、"Type" フィールドのスライサーを追加します。 選択した項目を "Lemon" と "Lime" に設定し、スライサーを左に 400 ピクセル移動します。
const fruitSlicer = pivotSheet.addSlicer(
farmPivot, /* The table or PivotTale to be sliced. */
farmPivot.getHierarchy("Type").getFields()[0] /* What source to use as the slicer options. */
);
fruitSlicer.selectItems(["Lemon", "Lime"]);
fruitSlicer.setLeft(400);
集計の値フィールド設定
ピボットテーブルでこれらの設定を使用してデータを集計および表示する方法を変更します。 各データ階層のフィールドでは、パーセンテージ、標準偏差、相対比較など、さまざまな方法でデータを表示できます。
サマリー
データ階層フィールドの既定の集計は合計です。
DataPivotHierarchy.setSummarizeBy では、各行または列のデータを別の方法で結合できます。
AggregationFunction には、使用可能なすべてのオプションが一覧表示されます。
次のコード スニペットでは、合計ではなく各項目の標準偏差を表示するように "クレート販売卸売" を変更します。
const wholesaleSales = farmPivot.getDataHierarchy("Sum of Crates Sold Wholesale");
wholesaleSales.setSummarizeBy(ExcelScript.AggregationFunction.standardDeviation);
値を として表示する
DataPivotHierarchy.setShowAs は、データ階層の値に計算を適用します。 既定の合計の代わりに、ピボットテーブルの他の部分に対する値またはパーセンテージを表示できます。
ShowAsRuleを使用して、データ階層の値の表示方法を設定します。
次のコード スニペットは、"ファームで販売されたクレート" の表示を変更します。 値は、フィールドの総計に対する割合として表示されます。
const farmSales = farmPivot.getDataHierarchy("Sum of Crates Sold at Farm");
const rule : ExcelScript.ShowAsRule = {
calculation: ExcelScript.ShowAsCalculation.percentOfGrandTotal
};
farmSales.setShowAs(rule);
一部の ShowAsRuleでは、比較としてそのフィールドに別のフィールドまたは項目が必要です。 次のコード スニペットは、"ファームで販売されたクレート" の表示をもう一度変更します。 今度は、フィールドには、そのファーム行の "レモン" の値との各値の差が表示されます。 ファームがレモンを販売していない場合、フィールドには "#N/A" と表示されます。
const typeField = farmPivot.getRowHierarchy("Type").getFields()[0];
const farmSales = farmPivot.getDataHierarchy("Sum of Crates Sold at Farm");
const rule: ExcelScript.ShowAsRule = {
calculation: ExcelScript.ShowAsCalculation.differenceFrom,
baseField: typeField, /* The field to use for the difference. */
baseItem: typeField.getPivotItem("Lemon") /* The item within that field that is the basis of comparison for the difference. */
};
farmSales.setShowAs(rule);
farmSales.setName("Difference from Lemons of Crates Sold at Farm");
関連項目
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
Office Scripts