この記事では、GPU ハードウェア スケジューリング ステージ 2 で GPU 間の真の同期に使用できる GPU フェンス同期オブジェクトについて説明します。 この機能は、Windows 11 バージョン 24H2 (WDDM 3.2) 以降でサポートされています。 グラフィックス ドライバーの開発者は、WDDM 2.0 と GPU ハードウェア スケジューリング ステージ 1 を理解している必要があります。
WDDM 2.x の監視対象フェンス同期オブジェクト
WDDM 2.x の 監視対象フェンス同期オブジェクト では、次の操作がサポートされています。
- CPU は、監視対象のフェンス値を待機します。次のいずれかの方法で行います。
- CPU 仮想アドレス (VA) を使用したポーリング。
- CPU で新しい監視対象フェンス値が観測されると通知される Dxgkrnl 内のブロック待機のキュー。
- 監視対象値の CPU シグナル。
- 監視対象フェンス GPU VA に書き込み、監視対象フェンス シグナル割り込みを起動して CPU に値の更新を通知する、監視対象値の GPU シグナル。
サポートされなかったのは、監視対象のフェンス値に対する GPU 上のネイティブ待機でした。 代わりに、OS は CPU の待機値に依存する GPU 作業を保持しました。 この作業は、値が通知されたときにのみ GPU にリリースされました。
GPU ネイティブ フェンス同期オブジェクトを追加しました
WDDM 3.2 以降、監視対象のフェンス オブジェクトは、次の追加機能をサポートするように拡張されました。
- GPU は監視対象フェンス値を待機します。これにより、CPU ラウンドトリップを必要とせずに、ハイ パフォーマンスのエンジン間同期が可能になります。
- CPU 待機処理のある GPU フェンス シグナルのみに対する、条件付き割り込み通知。 この機能により、すべての GPU 作業がキューに入ると CPU が低電力状態に入り、大幅な省電力が可能になります。
- (システム メモリではなく) GPU ローカル メモリ内にあるフェンス値ストレージ。
GPU ネイティブ フェンス同期オブジェクトの設計
次の図は、GPU ネイティブ フェンス オブジェクトの基本的なアーキテクチャを示すもので、CPU と GPU の間で共有される同期オブジェクトの状態に焦点を当てています。
: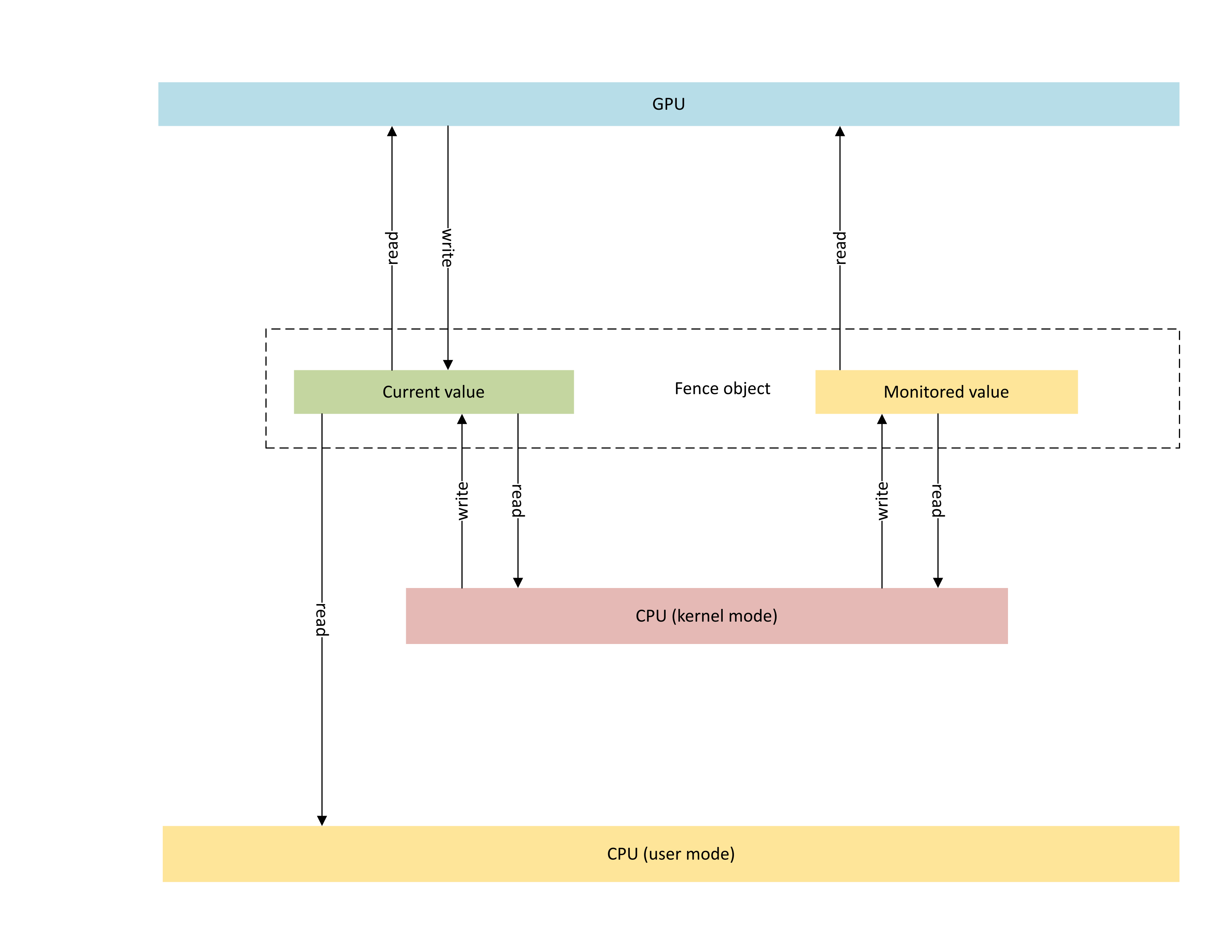
この図には、次の 2 つのメイン コンポーネントが含まれています。
現在の値 (この記事では CurrentValue と呼ばれます)。 このメモリ位置には、現在通知されている 64 ビットのフェンス値が含まれています。 CurrentValue は、CPU (カーネル モードから書き込み可能、ユーザー モードとカーネル モードの両方から読み取り可能) と GPU (GPU 仮想アドレスを使用して読み取りと書き込みが可能) の両方にマップされ、アクセスできます。 CurrentValue では、CPU と GPU の両方の観点から 64 ビットの書き込みをアトミックにする必要があります。 つまり、上位 32 ビットと下位 32 ビットの更新は破棄できないため、同時に表示する必要があります。 この概念は、既存の監視対象フェンス オブジェクトに既に存在しています。
監視対象値 (この記事では MonitoredValue と呼ばれます)。 このメモリ位置には、CPU によって 1 つ減算された、現在待機されている最小の値が含まれます。 MonitoredValue は、CPU (カーネル モードから読み取り可能で書き込み可能、ユーザー モードアクセスなし) と GPU (GPU VA を使用して読み取り可能、書き込みアクセスなし) の両方にマップされ、アクセスできます。 OS は、指定されたフェンス オブジェクトについて未処理の CPU 待機処理リストを保持しており、待機処理が追加および削除されると MonitoredValue を更新します。 未処理の待機処理がない場合、値は UINT64_MAX に設定されます。 これは、GPU ネイティブ フェンス同期オブジェクトの新しい概念です。
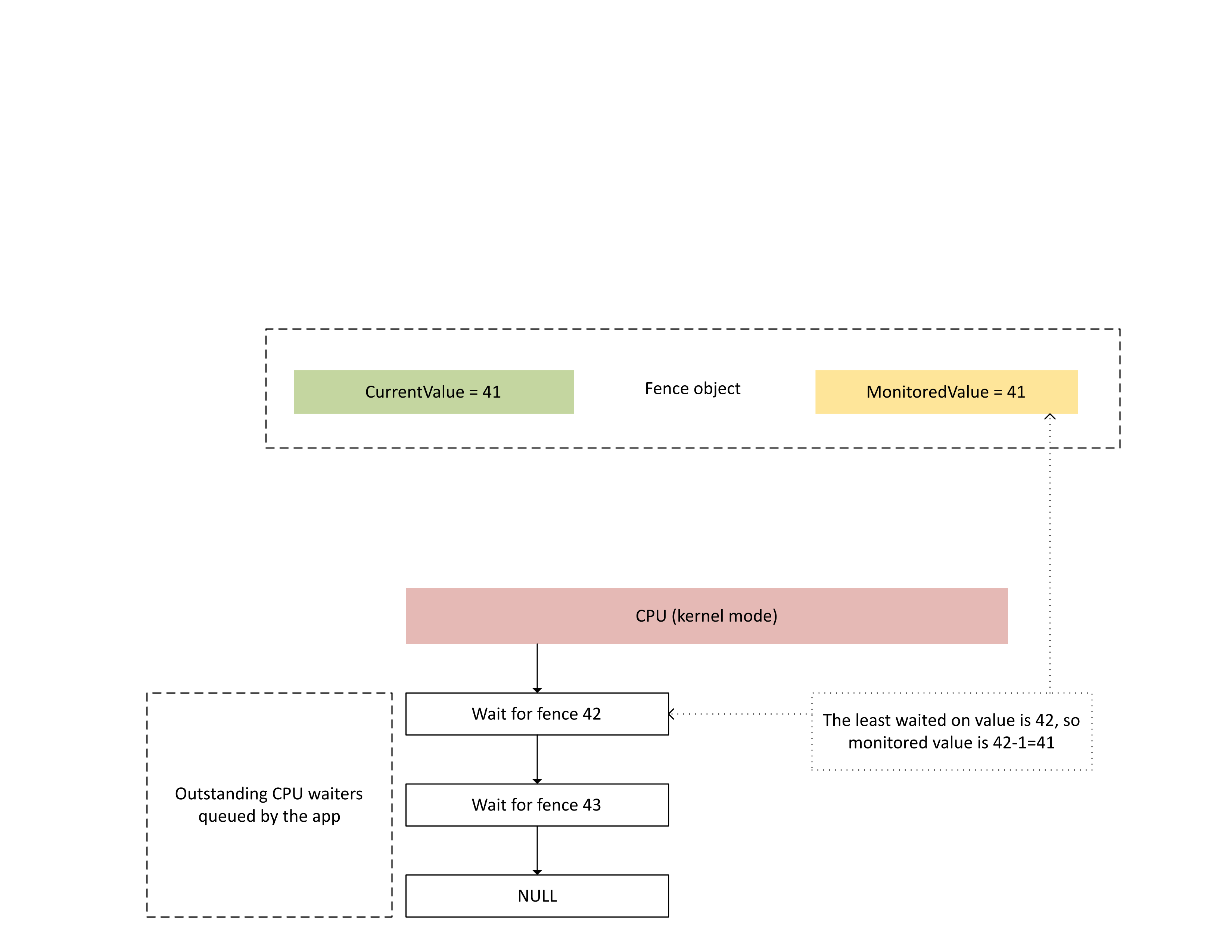
次の図は、Dxgkrnl が特定の監視対象フェンス値で未処理の CPU 待機処理を追跡する方法を示しています。 また、任意の時点で設定された監視対象フェンス値も表示されています。 CurrentValue と MonitoredValue はどちらも 41 です。これは次のことを意味します。
- GPU は、フェンス値 41 までのすべてのタスクを完了しました。
- CPU は、41 以下のフェンス値で待機していません。
:
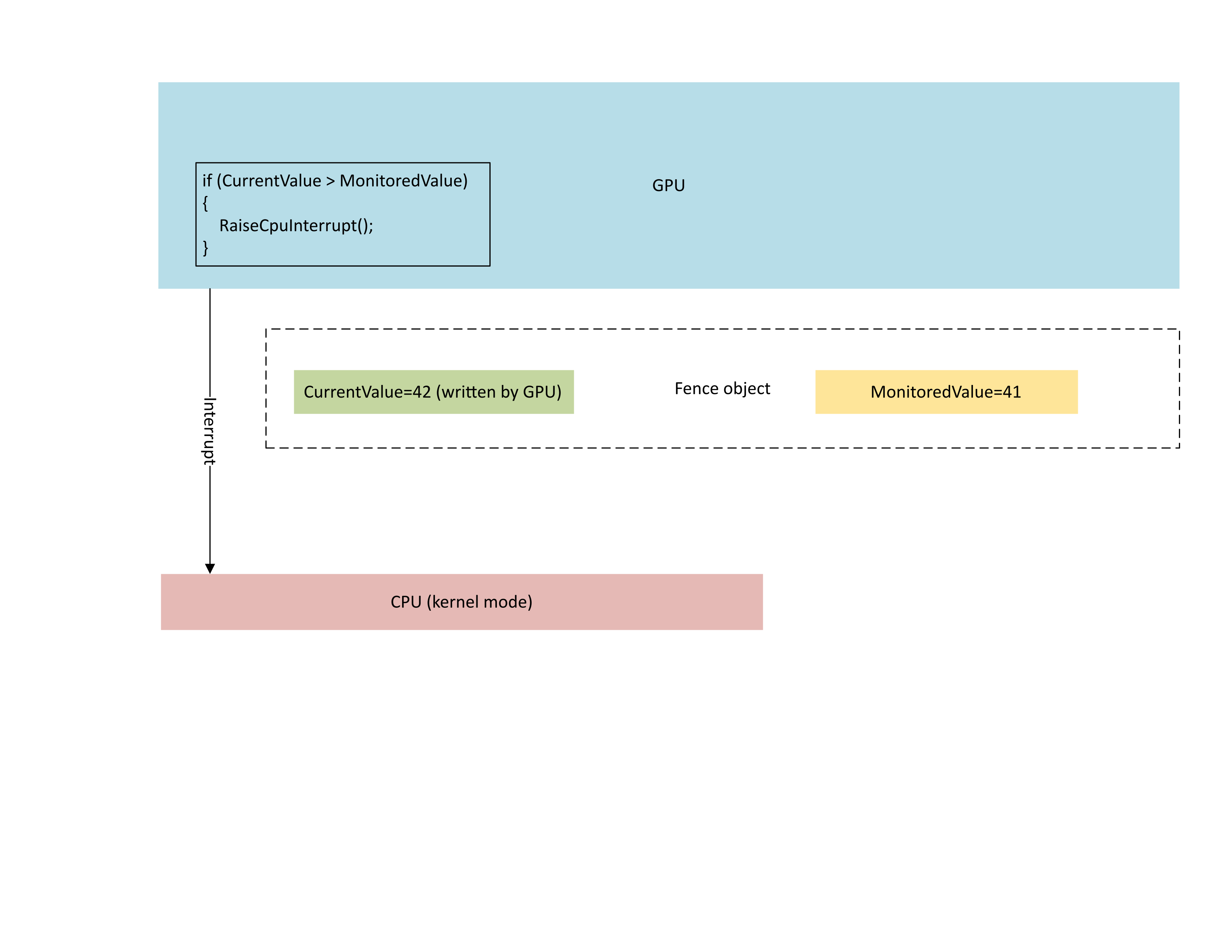
次の図は、新しいフェンス値が監視対象値よりも大きい場合にのみ、GPU のコンテキスト管理プロセッサ (CMP) が条件付きで CPU 割り込みを起動する方法を示しています。 このような割り込みは、新たに書き込まれた値で完了できる未処理の CPU 待機処理があることを意味します。
:
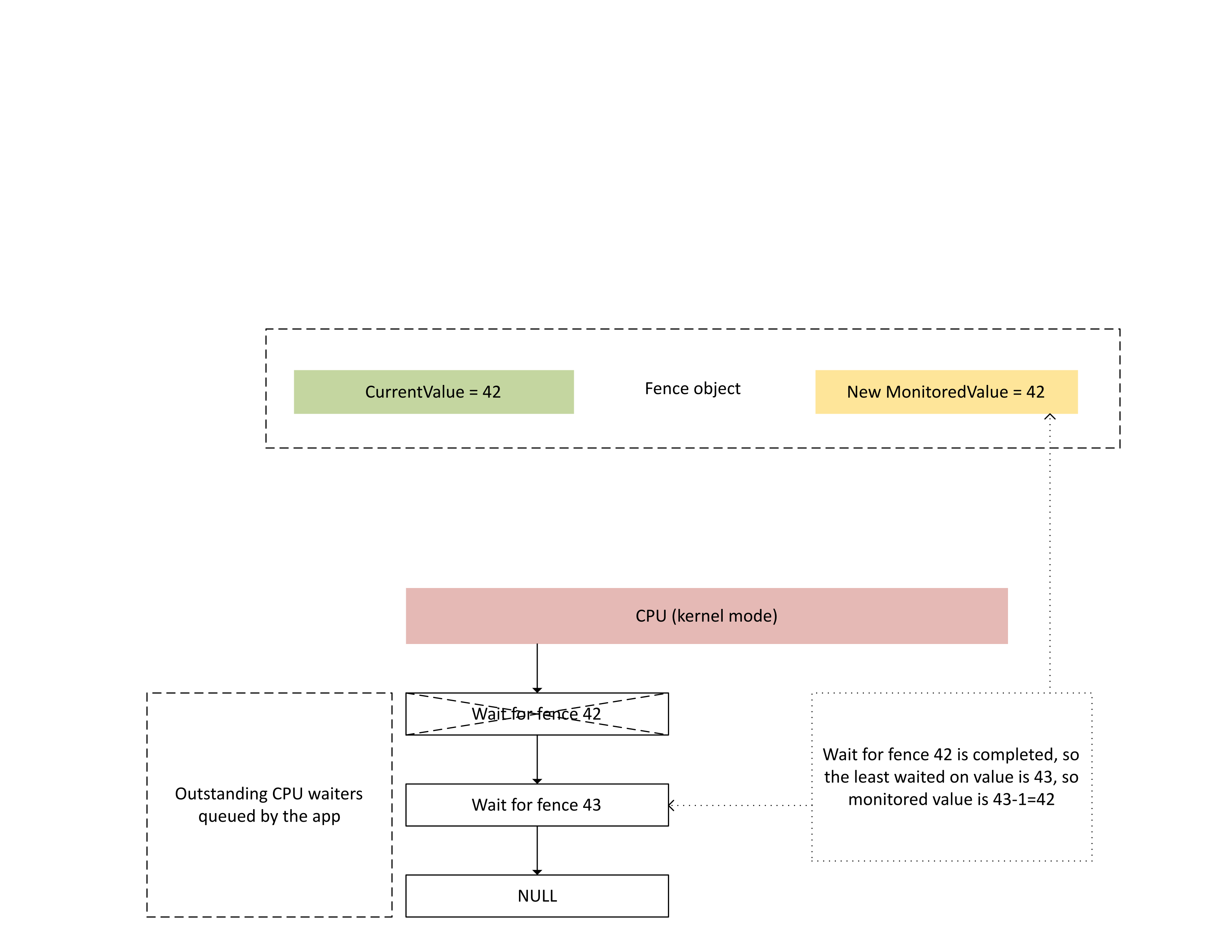
CPU がこの割り込みを処理すると、Dxgkrnl は次の図に示すように次のアクションを実行します。
- 新たに書き込まれたフェンスで完了した CPU 待機処理はブロックが解除されます。
- 未処理待機値から 1 を減算した値に対応するよう、監視対象値を進めます。
:
現在のフェンス値と監視対象フェンス値の物理メモリ ストレージ
指定されたフェンス オブジェクトの場合、CurrentValue と MonitoredValue は別々の場所に格納されます。
共有できないフェンス オブジェクトには、同じメモリ ページにパックされた同じプロセス内の異なるフェンス オブジェクト用のフェンス値ストレージがあります。 値は、この記事で後述するネイティブ フェンス KMD 上限で指定されたストライド値に従ってパックされます。
共有可能なフェンス オブジェクトの現在の値と監視対象値は、他のフェンス オブジェクトと共有されていないメモリ ページに配置されます。
現在の値
現在の値は、 D3DDDI_NATIVEFENCE_TYPEで指定されたフェンスの種類に応じて、システム メモリまたは GPU ローカル メモリに存在できます。
クロス アダプター フェンスの現在の値は、常にシステム メモリ内にあります。
現在の値がシステム メモリに格納されている場合、ストレージは内部システム メモリ プールから割り当てられます。
現在の値がローカル メモリに格納されると、ドライバーが D3DKMDT_FENCESTORAGESURFACEDATAで指定したメモリ セグメントからストレージが割り当てられます。
監視対象値
監視対象の値は、 D3DDDI_NATIVEFENCE_TYPEに応じて、システムまたは GPU ローカル メモリに存在することもできます。
監視対象の値がシステム メモリに格納されている場合、OS は内部システム メモリ プールから記憶域を割り当てます。
監視対象の値がローカル メモリに格納されている場合、OS は、ドライバーが D3DKMDT_FENCESTORAGESURFACEDATAで指定したメモリ セグメントから記憶域を割り当てます。
OS の CPU 待機条件が変化すると、KMD の DxgkDdiUpdateMonitoredValues コールバックを呼び出して、監視対象の値を指定した値に更新するように KMD に指示します。
同期の問題
前述のメカニズムには、現在の値および監視対象値の CPU と GPU による読み取りと書き込みの間に固有の競合状態があります。 特別な注意を払わないと、次の問題が発生する可能性があります。
- GPU が以前の MonitoredValue を読み取り、CPU で想定どおりに割り込みを起動できない可能性があります。
- CMP が割り込み条件を判断している最中に、GPU が新しい CurrentValue を書き込む可能性があります。 この新しい CurrentValue では、割り込みが想定どおりに起動しない場合や、現在の値をフェッチする際に CPU に表示されない可能性があります。
エンジンと CMP 間の GPU 内同期
効率を高める目的で、多くの個別 GPU は、次の間の GPU のローカル メモリに存在するシャドウ状態を使用して、監視対象のフェンス信号セマンティクスを実装します。
コマンド バッファー ストリームを実行し、CMP へのハードウェア シグナルを条件付きで起動する GPU エンジン。
CPU 割り込みを起動するかどうかを判断する GPU CMP。
この場合、CMP は、フェンス値へのメモリ書き込みを実行する GPU エンジンとメモリ アクセスを同期する必要があります。 特に、シャドウ MonitoredValue を更新する操作は、CMP の観点から順序付ける必要があります。
- 新しい MonitoredValue (シャドウ GPU ストレージ) を書き込みます。
- メモリ バリアを実行して、メモリ アクセスを GPU エンジンと同期します。
-
CurrentValue を読み取る。
- CurrentValue>MonitoredValue の場合は、CPU 割り込みが起動します。
- CurrentValue<= MonitoredValue の場合は、CPU 割り込みを起動しないでください。
この競合状態を適切に解決するには、手順 2 のメモリ バリアが正しく機能している必要があります。 手順 1 で MonitoredValue 更新が表示されていないコマンドから発生した、CurrentValue に対する保留中のメモリ書き込み操作を、手順 3 で行ってはいけません。 この状況では、手順 3 で書き込まれたフェンスが手順 1 で更新された値より大きい場合、割り込みが生成されます。
GPU と CPU 間の同期
CPU は、MonitoredValue の更新と CurrentValue の読み取りを、実行中のシグナルの割り込み通知を失わない方法で実行する必要があります。
- 新しい CPU 待機処理がシステムに追加されたときや、既存の CPU 待機処理が廃止された場合、OS は MonitoredValue を変更する必要があります。
- OS は DxgkDdiUpdateMonitoredValues を呼び出し、新しい監視対象値を GPU に通知します。
- DxgkDdiUpdateMonitoredValue はデバイスの割り込みレベルで実行され、監視対象フェンス シグナルの割り込みサービス ルーチン (ISR) と同期されます。
- DxgkDdiUpdateMonitoredValue は返された後で、新しい MonitoredValue が観測されてから、任意のプロセッサ コアによって読み取られた CurrentValue が GPU CMP によって書き込まれたことを保証する必要があります。
- DxgkDdiUpdateMonitoredValue から戻ると、OS が CurrentValue のリサンプルを行い、新しい CurrentValue によってブロック解除されたすべての待機処理を完了します。
割り込みを実行するかどうかを GPU で決定するために使用するものよりも新しい CurrentValue を CPU で観測することは完全に許容されます。 この状況では、待機処理をブロック解除しない割り込み通知が発生することがあります。 受け入れられないのは、監視された最新の CurrentValue 更新 (つまり、CurrentValue>MonitoredValue) に対して、CPU で割り込み通知が受信されない場合です。
OS におけるネイティブ フェンス機能の有効化のクエリ
ドライバーは、ドライバーの初期化中に OS でネイティブ フェンス機能が有効になっているかどうかを照会する必要があります。WDDM 3.2 以降、OS は追加された IsFeatureEnabled インターフェイスを使用して、ネイティブ フェンス機能を含む特定の機能が有効かどうかを制御します。
その結果、KMD は IsFeatureEnabled インターフェイスを実装する必要があります。 KMD の実装では、DXGK_VIDSCHCAPSでネイティブ フェンスのサポートをアドバタイズする前に、OS でDXGK_FEATURE_NATIVE_FENCE機能が有効になっているかどうかをクエリする必要があります。 OS が機能を有効にしていないときに KMD がネイティブ フェンスのサポートをアドバタイズした場合、OS はアダプターの初期化に失敗します。
機能有効化インターフェイスの詳細については、「 QUERYing WDDM 機能のサポートと有効化を参照してください。
ネイティブ フェンス機能の有効化を照会する DDI
次のインターフェイスは、OS がネイティブ フェンス機能を有効にしたかどうかのクエリを KMD で実行できるように導入されました。
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
OS は、DXGK_FEATURE_NATIVE_FENCE のバージョン 1 専用の追加された DXGKCB_FEATURE_NATIVEFENCE_CAPS_1 インターフェイス テーブルを実装します。 KMD では、この機能インターフェイス テーブルのクエリを実行し、OS の機能を判断する必要があります。 今後の OS リリースでは、新しい機能のサポートの詳細を記載したこのインターフェイス テーブルの新しいバージョンが OS に導入される可能性があります。
サポートのクエリを実行するためのサンプル ドライバー コード
次のサンプル コードは、サポートのクエリを実行するために、ドライバーが DXGK_FEATURE_INTERFACE インターフェイスでDXGK_FEATURE_NATIVE_FENCE機能を使用する方法を示しています。
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
ネイティブ フェンス機能
ネイティブ フェンス キャップのクエリを実行できるように、次のインターフェイスが更新または導入されます。
NativeGpuFence フィールドが DXGK_VIDSCHCAPS に追加されます。 OS により DXGK_FEATURE_NATIVE_FENCE 機能が有効になった場合、ドライバーは、DXGK_VIDSCHCAPS::NativeGpuFence ビットを 1 に設定すると、アダプターの初期化中にネイティブ GPU フェンス機能のサポートを宣言できます。
DXGKQAITYPE_NATIVE_FENCE_CAPS が DXGK_QUERYADAPTERINFOTYPE に追加されます。
Dxgkrnl は、追加された対応する D3DKMT_WDDM_3_1_CAPS::NativeGpuFenceSupported 構造/ビットを使用して、この機能をユーザー モードに公開します。
KMTQAITYPE_WDDM_3_1_CAPS が KMTQUERYADAPTERINFOTYPE に追加されます。
ネイティブ GPU フェンス機能のサポート機能を示すため、KMD に対して次のエンティティが追加されます。
DXGK_NATIVE_FENCE_CAPS 構造では、GPU のネイティブ フェンス機能について説明されています。 KMD は、この構造体の MapToGpuSystemProcess ビットを設定すると、OS に対して、CMP 用のシステム プロセス GPU 仮想アドレス空間を予約し、ネイティブ フェンスの CurrentValue と MonitoredValue 用にそのアドレス空間に GPU VA マッピングを作成するよう指示します。 これらの GPU VA は、後で KMD のフェンス作成コールバックに DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa および MonitoredValueSystemProcessGpuVa として渡されます。
追加された DXGKQAITYPE_NATIVE_FENCE_CAPS クエリ アダプター情報の種類を使用して DxgkDdiQueryAdapterInfo 関数が呼び出されると、KMD は設定された DXGK_NATIVE_FENCE_CAPS 構造体を返します。
ネイティブ フェンス オブジェクトを作成する、開く、閉じる、および破棄する KMD DDI
次の KMD によって実装された DDI は、ネイティブ フェンス オブジェクトを作成する、開く、閉じる、および破棄するために導入されました。 Dxgkrnl は、ユーザーモード コンポーネントの代わりにこれらの DDI を呼び出します。 Dxgkrnl は、OS が DXGK_FEATURE_NATIVE_FENCE 機能を有効にした場合にのみ、それらを呼び出します。
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiOpenNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDestroyNativeFence/DXGKARG_DESTROYNATIVEFENCE
ネイティブ フェンス オブジェクトをサポートするため、次の DDI が更新されました。
次のメンバーが DRIVER_INITIALIZATION_DATA に追加されました。 ネイティブ GPU フェンス オブジェクトをサポートするドライバーは、関数を実装し、この構造体を介して Dxgkrnl にポインターを提供する必要があります。
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence (WDDM 3.1 で追加)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDestroyNativeFence (WDDM 3.1 で追加)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence (WDDM 3.2 で追加)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence (WDDM 3.2 で追加)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer (WDDM 3.2 で追加)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs (WDDM 3.2 で追加)
共有フェンスのグローバル ハンドルとローカル ハンドル
プロセス A で共有ネイティブ フェンスが作成され、その後プロセス B でこのフェンスが開かれるとします。
プロセス A で共有ネイティブ フェンスが作成されると、Dxgkrnl は、このフェンスの作成場所であるアダプター ドライバー ハンドルを使用して DxgkDdiCreateNativeFence を呼び出します。 hGlobalNativeFence で作成され、返されるフェンス ハンドルは、グローバル フェンス ハンドルです。
Dxgkrnl はその後、 DxgkDdiOpenNativeFence を呼び出してプロセス A の特定のローカル ハンドル (hLocalNativeFenceA) を開きます。
プロセス B で同じ共有ネイティブ フェンスが開かれると、Dxgkrnl は DxgkDdiOpenNativeFence を呼び出して、プロセス B 固有のローカル ハンドル (hLocalNativeFenceB) を開きます。
プロセス A で共有のネイティブ フェンス インスタンスが破棄された場合、Dxgkrnl は、このグローバル フェンスへの保留中の参照が残っていることを確認するため、ドライバーの DxgkDdiCloseNativeFence(hLocalNativeFenceA) のみを呼び出してプロセス A 固有の構造をクリーンアップします。 hGlobalNativeFence ハンドルは、まだ存在しています。
プロセス B でフェンス インスタンスが破棄されると、Dxgkrnl は DxgkDdiCloseNativeFence(hLocalNativeFenceB) と DxgkDdiDestroyNativeFence(hGlobalNativeFence) を呼び出し、KMD でグローバル フェンス データを破棄できるようにします。
CMP で使用するためのページング プロセス アドレス空間における GPU VA マッピング
KMD は、ネイティブ フェンス GPU VA も GPU ページング プロセスのアドレス空間にマップする必要があるハードウェアに、DXGK_NATIVE_FENCE_CAPS::MapToGpuSystemProcess の上限を設定します。 設定された MapToGpuSystemProcess ビットは、CMP で使用するために、ネイティブ フェンスの CurrentValue と MonitoredValue のページング プロセス アドレス空間に GPU VA マッピングを作成するよう OS に指示します。 これらの GPU VA は、後で DxgkDdiCreateNativeFence に DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa および MonitoredValueSystemProcessGpuVa として渡されます。
ネイティブ フェンスを作成、開き、破棄するための D3DKMT カーネル API
ネイティブ フェンス オブジェクトを作成して開くために、次の D3DKMT カーネル モード API が導入されています。
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl は、既存の D3DKMTDestroySynchronizationObject 関数を呼び出して、既存のネイティブ フェンス オブジェクトを閉じて破棄 (解放) します。
導入または更新される構造体と列挙型のサポートには、次のものが含まれます。
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
ローカル メモリへのネイティブ フェンス値の配置をサポートする DDI
ローカル メモリへのネイティブ フェンス値の配置をサポートするために、次の DDI が追加または変更されました。
D3DKMDT_FENCESTORAGESURFACEDATA構造体が追加されます。
ネイティブ フェンスの種類 MonitoredValue および CurrentValue は D3DDDI_NATIVEFENCE_TYPE_INTRA_GPU ローカル デバイス メモリに配置できます。 これを行うために、OS は、フェンス ストレージを配置するメモリ セグメントを指定するようにドライバーに要求します。 DxgkDdiGetStandardAllocation は、このような情報を提供するように拡張されています。
D3DKMDT_STANDARDALLOCATION_FENCESTORAGE が DXGKARG_GETSTANDARDALLOCATIONDRIVERDATAに追加されます。
ハードウェア キューのネイティブ進行状況フェンスを示す
ネイティブ ハードウェア キューの進行状況フェンス オブジェクトを示すために、次の更新が導入されています。
DxgkDdiCreateHwQueue の呼び出しに NativeProgressFence フラグが追加されています。
- サポートされているシステムでは、OS はハードウェア キューの進行状況フェンスをネイティブ フェンスに更新します。 OS は、NativeProgressFence を設定すると、DXGKARG_CREATEHWQUEUE::hHwQueueProgressFence ハンドルが、DxgkDdiCreateNativeFence を使用して以前に作成されたネイティブ GPU フェンス オブジェクトのドライバー ハンドルを指していることを KMD に示します。
ネイティブ フェンス シグナル割り込み
ネイティブ フェンス シグナル割り込みをサポートするため、割り込みメカニズムに次の変更が加えられます。
DXGK_INTERRUPT_TYPE 列挙型は、DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED 割り込み型に更新されます。
DXGKARGCB_NOTIFY_INTERRUPT_DATA構造体が更新され、ネイティブ フェンス通知割り込みを示す NativeFenceSignaled 構造体が含まれる
NativeFenceSignaled は、CPU によって監視されている一連のネイティブ フェンス GPU オブジェクトが GPU エンジンで通知されたことを OS に通知するために使用されます。 アクティブな CPU 待機処理を持つオブジェクトの正確なサブセットを GPU が特定できる場合、このサブセットは pSignaledNativeFenceArray を介して渡されます。 この配列内のハンドルは、DxgkddiCreateNativeFence で DXgkrnl が KMD に渡した有効な hGlobalNativeFence ハンドルである必要があります。 破棄されたネイティブ フェンス オブジェクトにハンドルを渡すと、バグ チェックが実行されます。
DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS 構造が更新され、EvaluateLegacyMonitoredFences メンバーが含められます。
GPU は、次の条件下で NULL pSignaledNativeFenceArray を渡すことができます。
- GPU は、アクティブな CPU 待機処理を持つオブジェクトの正確なサブセットを特定できません。
- 複数のシグナル割り込みが同時に折りたたまれるため、アクティブな待機処理によるシグナル セットの特定が困難になります。
NULL 値は、未処理のネイティブ GPU フェンス オブジェクト待機処理をすべてスキャンするよう OS に指示します。
OS とドライバーの間のコントラクトは、OS にアクティブな CPU 待機処理 (MonitoredValue で表されるもの) があり、GPU エンジンが CPU 割り込みを必要とする値にオブジェクトを通知した場合、GPU は次のいずれかのアクションを実行する必要があります。
- このネイティブ フェンス ハンドルを pSignaledNativeFenceArray に含めます。
- NULL pSignaledNativeFenceArray を使用して NativeFenceSignaled 割り込みを発生させます。
既定では、KMD が NULL pSignaledNativeFenceArray でこの割り込みを発生させると、Dxgkrnl は保留中のすべてのネイティブ フェンス待機処理のみスキャンし、従来の監視対象のフェンス待機処理をスキャンしません。 従来の DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED と DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED を区別できないハードウェアでは、KMD は pSignaledNativeFenceArray = NULL および EvaluateLegacyMonitoredFences = 1 を使用して導入された DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED 割り込みのみ常に発生させることができます。これは、OS に対してすべての待機処理 (従来の監視対象フェンス待機処理とネイティブ フェンス待機処理) をスキャンすることを示しています。
値のバッチを更新するよう KMD に指示する
現在の値または監視対象の値のバッチを更新するよう KMD に指示するため、次のインターフェイスが導入されています。
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
クロスアダプター ネイティブ フェンス
既存の DX12 アプリがクロス アダプター監視対象フェンスを作成して使用するため、OS はクロスアダプター ネイティブ フェンスの作成をサポートしている必要があります。 これらのアプリの基になるキューとスケジュールがユーザーモードの送信に切り替えられる場合、監視対象フェンスもネイティブ フェンスに切り替える必要があります (ユーザーモード キューは監視対象フェンスをサポートできません)。
クロスアダプター フェンスは、D3DDDI_NATIVEFENCE_TYPE_DEFAULT 型で作成する必要があります。 それ以外の場合、D3DKMTCreateNativeFence は失敗します。
すべての GPU は、常にシステム メモリに割り当てられる CurrentValue ストレージの同じコピーを共有します。 ランタイムで GPU1 にクロスアダプター ネイティブ フェンスが作成され、GPU2 で開かれると、両方の GPU 上の GPU VA マッピングは同じ CurrentValue 物理ストレージを指します。
各 GPU は、MonitoredValue の独自のコピーを取得します。 そのため、MonitoredValue ストレージは、システム メモリまたはローカル メモリに割り当てることができます。
クロスアダプター ネイティブ フェンスは、GPU2 が通知したネイティブ フェンスで GPU1 が待機している状態を解決する必要があります。 現在、GPU 間シグナルの概念は存在しません。そのため、OS は CPU から GPU1 に通知することで、この状態を明示的に解決します。 この通知は、クロスアダプター フェンスの MonitoredValue を有効期間中に 0 に設定すると行われます。 次に、GPU2 がネイティブ フェンスを通知すると、CPU 割り込みも発生します。これにより、Dxgkrnl は GPU1 の CurrentValue を更新し (NotificationOnly フラグが TRUE に設定された DxgkDdiUpdateCurrentValuesFromCpu を使用)、その GPU の保留中の CPU/GPU 待機処理のブロックを解除できます。
MonitoredValue はクロスアダプター ネイティブ フェンスでは常に 0 ですが、同じ GPU 上で送信される待機とシグナルは、GPU 同期の高速化によるメリットを依然として享受できます。 ただし、CPU 待機処理や他の GPU の待機処理がない場合でも、CPU 割り込みは無条件に発生するため、CPU 割り込みの削減による電力削減の利点は失われます。 このトレードオフは、クロスアダプター ネイティブ フェンスの設計と実装のコストをシンプルに保つために行われます。
OS では、GPU1 でネイティブ フェンス オブジェクトが作成され、GPU2 で開かれるシナリオがサポートされています。GPU1 では機能がサポートされますが、GPU2 ではサポートされません。 フェンス オブジェクトは、GPU2 で通常の MonitoredFence として開かれます。
OS では、通常の監視対象フェンス オブジェクトが GPU1 上に作成され、この機能をサポートする GPU2 上でネイティブ フェンスとして開かれるシナリオがサポートされます。 フェンス オブジェクトは、GPU2 のネイティブ フェンスとして開かれます。
クロス アダプター待機/シグナルの組み合わせ
次のサブセクションの表では、iGPU および dGPU システムの例を示しており、CPU/GPU からのネイティブ フェンス待機/シグナルに使用できるさまざまな構成を示しています。 次の 2 つの事例が考えられます。
- 両方の GPU でネイティブ フェンスがサポートされます。
- iGPU ではネイティブ フェンスがサポートされませんが、dGPU ではネイティブ フェンスがサポートされます。
2 番目のシナリオは、両方の GPU でネイティブ フェンスがサポートされているが、ネイティブ フェンスの待機/シグナルが iGPU のカーネル モード キューに送信される場合にも似ています。
テーブルは、列から待機とシグナルのペア (たとえば、WaitFromGPU - SignalFromGPU または WaitFromGPU - SignalFromCPU など) を選択して読み取る必要があります。
シナリオ 1
シナリオ 1 では、dGPU と iGPU の両方でネイティブ フェンスがサポートされています。
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| UMD は、コマンド バッファーに hfence CurrentValue == 10 命令の待機を挿入します | ランタイムが D3DKMTWaitForSynchronizationObjectFromCpu を呼び出します | ||
| VidSch は、ネイティブ フェンス CPU 待機処理リストでこの同期オブジェクトを追跡します | |||
| UMD は、コマンド バッファーに書き込み hFence CurrentValue = 10 信号命令を挿入します | ランタイムが D3DKMTSignalSynchronizationObjectFromCpu を呼び出します | ||
| CurrentValue が書き込まれると、VidSch は ISR に通知されるネイティブ フェンスを受け取ります (MonitoredValue == 0 が常に発生するためです) | VidSch が DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) を呼び出します | ||
| VidSch はシグナル (hFence, 10) を iGPU に伝達します | VidSch はシグナル (hFence, 10) を iGPU に伝達します | ||
| VidSch は伝達されたシグナルを受信し、DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) を呼び出します | VidSch は伝達されたシグナルを受信し、DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) を呼び出します | ||
| KMD は、hFence を待機していた HW チャネルのブロックを解除するために実行リストを再スキャンします | VidSch は、KEVENT に通知することで CPU 待機状態のブロックを解除します |
シナリオ 2a
シナリオ 2a では、iGPU はネイティブ フェンスをサポートしていませんが、dGPU はサポートしています。 待機は iGPU で送信され、シグナルは dGPU で送信されます。
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| ランタイムが D3DKMTWaitForSynchronizationObjectFromGpu を呼び出します | ランタイムが D3DKMTWaitForSynchronizationObjectFromCpu を呼び出します | ||
| VidSch は、監視対象フェンス待機リストでこの同期オブジェクトを追跡します | VidSch は、監視対象フェンス CPU 待機処理リスト ヘッドでこの同期オブジェクトを追跡します | ||
| UMD は、コマンド バッファーに書き込み hFence CurrentValue = 10 シグナル命令を挿入します | ランタイムが D3DKMTSignalSynchronizationObjectFromCpu を呼び出します | ||
| CurrentValue が書き込まれると、VidSch は NativeFenceSignaledISR を受け取ります (MV == 0 が常に発生するため) | VidSch が DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) を呼び出します | ||
| VidSch はシグナル (hFence, 10) を iGPU に伝達します | VidSch はシグナル (hFence, 10) を iGPU に伝達します | ||
| VidSch は伝達されたシグナルを受信し、新しいフェンス値を観察します | VidSch は伝達されたシグナルを受信し、新しいフェンス値を観察します | ||
| VidSch は、監視対象フェンス待機リストをスキャンし、ソフトウェア コンテキストのブロックを解除します | VidSch は、監視対象フェンス CPU 待機処理リスト ヘッドをスキャンし、KEVENT に通知することで CPU 待機のブロックを解除します |
シナリオ 2b
シナリオ 2b では、ネイティブ フェンスのサポートは同じままです (iGPU はサポートしていませんが、dGPU はサポートしています)。 今回は、シグナルが iGPU で送信され、待機が dGPU で送信されます。
| iGPU SignalFromGPU (hFence, 10) | iGPU SignalFromCPU (hFence, 10) | dGPU WaitFromGpu (hFence, 10) | dGPU WaitFromCpu(hFence, 10) |
|---|---|---|---|
| UMD は、コマンド バッファーに hfence CurrentValue == 10 命令の待機を挿入します | ランタイムが D3DKMTWaitForSynchronizationObjectFromCpu を呼び出します | ||
| VidSch は、ネイティブ フェンス CPU 待機処理リストでこの同期オブジェクトを追跡します | |||
| UMD が D3DKMTSignalSynchronizationObjectFromGpu を呼び出します | UMD が D3DKMTSignalSynchronizationObjectFromCpu を呼び出します | ||
| パケットがソフトウェア コンテキストの先頭にある場合、VidSch は CPU からフェンス値を直接更新します | VidSch は、CPU からフェンス値を直接更新します | ||
| VidSch はシグナル (hFence, 10) を dGPU に伝達します | VidSch はシグナル (hFence, 10) を dGPU に伝達します | ||
| VidSch は伝達されたシグナルを受信し、DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) を呼び出します | VidSch は伝達されたシグナルを受信し、DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) を呼び出します | ||
| KMD は、hFence を待機していた HW チャネルのブロックを解除するために実行リストを再スキャンします | VidSch は、KEVENT に通知することで CPU 待機状態のブロックを解除します |
将来の GPU 間クロスアダプター シグナル
「同期の問題」で説明したように、クロスアダプター ネイティブ フェンスでは、CPU 割り込みが無条件に発生するため、電力節約が失われます。
将来のリリースでは、OS が、共通のドアベル メモリに書き込むことによって 1 つの GPU 上の GPU シグナルが他の GPU に割り込むことを可能にするインフラストラクチャを開発し、他の GPU を起動して実行リストを処理し、準備完了の HW キューをブロック解除可能にします。
この処理の課題は、次の設計です。
- 共通のドアベル メモリ。
- GPU がドアベルに書き込むことができるインテリジェントなペイロードまたはハンドル。これにより、他の GPU は、HWQueues のサブセットのみをスキャンできるよう、通知されたフェンスを特定できます。
このようなクロス アダプター シグナルを使用すると、すべての GPU が読み取りと書き込みを行うネイティブ フェンス ストレージ (クロスアダプター スキャン アウト割り当てに似た、線形形式のクロスアダプター割り当て) の同じコピーを GPU が共有すことも可能になります。
ネイティブ フェンス ログ バッファーの設計
ネイティブ フェンスおよびユーザーモード送信では、Dxgkrnl は、ネイティブ GPU 待機と、UMD からエンキューされたシグナルが特定の HWQueue の GPU でブロック解除されるタイミングを可視化できません。 ネイティブ フェンスを使用すると、特定のフェンスに対して監視対象フェンスのシグナル割り込みを抑制することができます。
:
この GPUView イメージに示されているように、フェンス操作を再作成する方法が必要です。 濃いピンクのボックスはシグナルで、薄いピンクのボックスは待機です。 各ボックスは、操作が CPU 上で Dxgkrnl に送信されたときに開始され、Dxgkrnl が CPU で操作を完了すると終了します。 これにより、コマンドの存続期間全体を調査することができます。
そのため、ログに記録する必要がある HWQueue あたりの条件は、大まかに言うと次のとおりです。
| 条件 | 意味 |
|---|---|
| FENCE_WAIT_QUEUED | UMD が GPU 待機命令をコマンド キューに挿入したときの CPU タイムスタンプ |
| FENCE_SIGNAL_QUEUED | UMD が GPU シグナル命令をコマンド キューに挿入したときの CPU タイムスタンプ |
| FENCE_SIGNAL_EXECUTED | HWQueue の GPU でシグナル コマンドが実行されたときの GPU タイムスタンプ |
| FENCE_WAIT_UNBLOCKED | GPU で待機条件が満たされ、HWQueue がブロック解除されたときの GPU タイムスタンプ |
ネイティブ フェンス ログ バッファー DDI
ネイティブ フェンス ログ バッファーをサポートするため、次の DDI、構造体、および列挙型が導入されています。
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- ログ エントリのヘッダーと配列を含むログ バッファー。 ヘッダーは、エントリが待機用かシグナル用かを識別し、各エントリは操作の種類 (実行またはブロック解除) を識別します。
ログ バッファーの設計は、ネイティブ フェンスと ユーザー モードの送信キューを対象としています。このキューでは ログ バッファー ペイロードは GPU エンジン/CMP によって書き込まれ、 Dxgkrnl KMD から関与しません。 そのため、UMD は待機/シグナル コマンド バッファーの生成中に命令を挿入し、実行時にログ バッファー ペイロードをログ バッファー エントリに書き込む GPU をプログラミングします。 非ユーザー モード送信 (つまり、カーネル モード キュー) の場合、待機とシグナルは Dxgkrnl 内のソフトウェア コマンドであるため、これらの操作のタイムスタンプやその他の詳細は既にわかっており、ログ バッファーを更新するためにハードウェア/KMD は必要ありません。 このようなカーネル モード キューの場合、 Dxgkrnl はログ バッファーを作成しません。
ログ バッファー メカニズム
Dxgkrnl は、HWQueue ごとに 2 つの専用 4 KB (キロバイト) ログ バッファーを割り当てます。
- 1 つは待機のログ記録用です。
- 1 つはシグナルのログ記録用です。
これらのログ バッファーには、カーネルモードの CPU VA (LogBufferCpuVa)、プロセス アドレス空間内の GPU VA (LogBufferGpuVa)、CMP VA (LogBufferSystemProcessGpuVa) のマッピングがあり、KMD、GPU エンジン、および CMP に対する読み取り/書き込みを行うことができます。 Dxgkrnl は DxgkDdiSetNativeFenceLogBuffer を 2 回呼び出します。1 回は待機をログ記録するためのログ バッファーを設定し、1 回はシグナルをログ記録するためのログ バッファーを設定します。
UMD は、コマンド リストにネイティブ フェンス待機命令またはシグナル命令を挿入した直後に、特定のエントリのペイロードをログ バッファーに書き込むよう GPU に指示するコマンドも挿入します。
GPU エンジンがフェンス操作を実行すると、特定のエントリにペイロードをログ バッファーに書き込む UMD 命令が表示されます。 さらに、GPU は現在の FenceEndGpuTimestamp もこのログ バッファー エントリに書き込みます。
UMD は、GPU アクセス可能なログ バッファーにアクセスすることができませんが、ログ バッファーの進行を制御します。 つまり、UMD は、書き込む次の空きエントリ (ある場合) を決定し、この情報を使用して GPU をプログラミングします。 GPU がログ バッファーに書き込むと、ログ ヘッダーの FirstFreeEntryIndex 値が増分されます。 UMD は、ログ エントリへの書き込みが単調に増加していることを確認する必要があります。
以下のシナリオについて考えてみます。
- HWQueueA と HWQueueB という 2 つの HWQueue があり、対応するフェンス ログ バッファーと、FenceLogA および FenceLogB の GPU CA があります。 HWQueueA は待機をログ記録するためのログ バッファーに関連付けられ、HWQueueB はシグナルをログ記録するためのログ バッファーに関連付けられています。
- FenceF のユーザーモード D3DKMT_HANDLE を持つネイティブ フェンス オブジェクトがあります。
- 値 V1 の FenceF における GPU 待機は、CPUT1 時に HWQueueA にキューに入れられます。 UMD は、コマンド バッファーを構築するときに、ペイロードをログに記録するよう GPU に指示するコマンド、LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED) を挿入します。
- 値 V1 を持つ FenceF への GPU シグナルは、時刻 CPUT2 で HWQueueB にキューに入れられます。 UMD は、コマンド バッファーを構築するときに、ペイロードをログに記録するよう GPU に指示するコマンド、LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED) を挿入します。
GPU スケジューラは、GPU 時間 GPUT1 に HWQueueB で GPU シグナルを実行した後、UMD ペイロードを読み取り、HWQueueB の OS 提供のフェンス ログにイベントを記録します。
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
GPU スケジューラは、GPU 時間 GPUT2 に HWQueueA がブロック解除されていることを確認した後、UMD ペイロードを読み取り、HWQueueA の OS で提供されるフェンス ログにイベントを記録します。
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
Dxgkrnl は、ログ バッファーを破棄して再作成できます。 毎回 DxgkDdiSetNativeFenceLogBuffer を呼び出して、新しい場所を KMD に通知します。
フェンス キューに登録された操作の CPU タイムスタンプ
次の点を考えると、UMD ログにこれらの CPU タイムスタンプを作成するメリットはほとんどありません。
- コマンド リストは、コマンド リストを含むコマンド バッファーの GPU 実行の数分前に記録できます。
- これらの数分間は、同じコマンド バッファー内にある他の同期オブジェクトと順序が異なる場合があります。
UMD の GPU 書き込みログ バッファへの命令に CPU タイムスタンプを含めるにはコストがかかるため、CPU タイムスタンプはログ エントリ ペイロードに含まれていません。
代わりに、ランタイムまたは UMD は、コマンド リストの記録時に CPU タイムスタンプを使用して、フェンス キューに登録されたネイティブ ETW イベントを生成できます。 そのため、ツールは、この新しいイベントの CPU タイムスタンプとログ バッファー エントリからの GPU タイムスタンプを組み合わせることにより、フェンス キューに登録された完了イベントのタイムラインを構築することができます。
フェンスの通知時またはブロック解除時の GPU における操作の順序
UMD は、フェンスの通知/ブロック解除を GPU に指示するコマンド リストを作成するとき、次の順序が維持されるようにする必要があります。
- 新しいフェンス値を書き込み、GPU VA/CMP VA をフェンスします。
- 対応するログ バッファー GPU VA/CMP VA にログ ペイロードを書き込みます。
- 必要に応じて、ネイティブ フェンス シグナル割り込みを発生させます。
この操作の順序により、割り込みが OS に対して発生したとき、Dxgkrnl に最新のログ エントリが確実に表示されます。
ログ バッファー オーバーランが許可されている
GPU は、OS がまだ認識していないエントリを上書きすることにより、ログ バッファーをオーバーランする可能性があります。 これは WraparoundCount を増分することによって行います。
OS が最終的にログを読み取ると、ログ ヘッダーの新しい WraparoundCount 値とそのキャッシュされた値を比較することにより、オーバーランが発生したことを検出できます。 オーバーランが発生した場合、OS には次のフォールバック オプションがあります。
- オーバーランが発生したときにフェンスをブロック解除するために、OS はすべてのフェンスをスキャンし、ブロック解除された待機処理を決定します。
- トレースが有効になった場合、OS はトレースにフラグを出力して、イベントが失われたことをユーザーに通知できます。 さらに、トレースが有効になっている場合、OS は最初にログ バッファーのサイズを大きくして、最初にオーバーランを防ぎます。
ログ バッファー エントリの進行中、UMD でバック プレッシャー サポートを実装する必要はありません。
空または繰り返しのログ バッファー タイムスタンプ
一般的なケースでは、Dxgkrnl はログ エントリのタイムスタンプが単調に増加することを想定しています。 ただし、後続のログ エントリのタイムスタンプがゼロになるか、以前のログ エントリと同じになる場合があります。
たとえば、リンクされたディスプレイ アダプターを使用するシナリオでは、LDA のチェーン アダプターの 1 つでフェンス書き込み操作がスキップされる可能性があります。 この場合、ログ バッファー エントリのタイムスタンプは 0 です。 Dxgkrnl は、このようなケースを処理します。 とは言うものの、Dxgkrnl では、指定されたログ エントリのタイムスタンプが前のログ エントリのタイムスタンプより小さくなることは想定されません。つまり、タイムスタンプを後方に移動することはできません。
ネイティブ フェンス ログの同期的な更新
フェンス値と対応するログ バッファーを更新する GPU 書き込みでは、CPU 読み取り前に書き込みが完全に伝達されるようにする必要があります。 この要件では、メモリ バリアを使用する必要があります。 次に例を示します。
- Signal Fence(N): N を新しい現在の値として書き込みます
- GPU タイムスタンプを含む LOG エントリを書き込む
- MemoryBarrier
- FirstFreeEntryIndexをインクリメントする
- MemoryBarrier
- 監視対象フェンス割り込み (N): アドレス "M" を読み取り、値を N と比較して CPU 割り込みの配信を決定します
すべての GPU シグナルに 2 つのバリアを挿入するのはコストがかかりすぎます。特に、条件付き割り込みチェックが満たされておらず、CPU 割り込みが不要である可能性が高い場合はそうです。 その結果、設計によって、メモリ バリアの 1 つを GPU (プロデューサー) から CPU (コンシューマー) に挿入するコストが移動されます。 Dxgkrnl は、導入された DxgkDdiUpdateNativeFenceLogs 関数を呼び出して、KMD が保留中のネイティブ フェンス ログ書き込みをオンデマンドで同期的にフラッシュします (HW フリップ キュー ログ フラッシュに DxgkddiUpdateflipqueuelog が導入された方法と同様です)。
GPU 操作の場合:
- Signal Fence(N): N を新しい現在の値として書き込みます
- GPU タイムスタンプを含む LOG エントリを書き込む
- FirstFreeEntryIndexを増やす
- MemoryBarrier =>FirstFreeEntryIndex が完全に反映されていることを確認します
- 監視対象フェンス割り込み (N): アドレス "M" を読み取り、値を N と比較してり込みの配信を決定します
CPU 操作の場合:
Dxgkrnl のネイティブ フェンス シグナル割り込みハンドラー (DISPATCH_IRQL):
- HWQueue ログごと: FirstFreeEntryIndex を読み取り、新しいエントリが書き込まれるかどうかを判断します。
- 新しいエントリを含むすべての HWQueue ログ: DxgkDdiUpdateNativeFenceLogs を呼び出し、それらの HWQueues のカーネル ハンドルを指定します。 この DDI では、KMD は指定された各 HWQueue にメモリ バリアを挿入します。これにより、すべてのログ エントリの書き込みが確実にコミットされます。
- Dxgkrnl は、ログ エントリを読み取り、タイムスタンプ ペイロードを抽出します。
そのため、ハードウェアが FirstFreeEntryIndex への書き込み後にメモリ バリアを挿入する限り、Dxgkrnl は常に KMD の DDI を呼び出し、Dxgkrnl がログ エントリを読み取る前に KMD がメモリ バリアを挿入できるようにします。
今後のハードウェア要件
現在の世代のハードウェアのほとんどは、ネイティブ フェンス シグナル割り込みで通知されたフェンス オブジェクトのカーネル ハンドルの書き込みのみサポートしている可能性があります。 この設計については、「ネイティブ フェンス シグナル割り込み」で説明しました。 この場合、Dxgkrnl は割り込みペイロードを以下のように処理します。
- OS は、フェンス値の読み取り (PCI 経由で実行される可能性があります) を実行します。
- 通知されたフェンスとフェンス値がわかっているので、OS はそのフェンス/値を待機している CPU 待機処理を起動します。
- それとは別に、このフェンスの親デバイスの場合、OS は、そのすべての HWQueues のログ バッファーをスキャンします。 OS は、最後に書き込まれたログ バッファー エントリを読み取って、どの HWQueue がシグナルを実行したかを判断し、対応するタイムスタンプ ペイロードを抽出します。 このアプローチでは、PCI 全体で一部のフェンス値が冗長に読み取られます。
今後のプラットフォームでは、Dxgkrnl はネイティブ フェンス シグナル割り込みでカーネル HwQueue ハンドルの配列を取得することを優先します。 このアプローチにより、OS は次のことが可能になります。
- その HwQueue の最新のログ バッファー エントリを読み取る。 ユーザー デバイスは割り込みハンドラーに認識されません。そのため、この HwQueue ハンドルはカーネル ハンドルである必要があります。
- ログ バッファーで、通知されたフェンスと値を示すログ エントリをスキャンする。 ログ バッファーのみ読み取る場合、フェンス値とログ バッファーを冗長に読み取る必要なく、PCI 経由で 1 回の読み取りが保証されます。 ログ バッファーがオーバーランしない (Dxgkrnl が読み取らないエントリを削除する) 限り、この最適化は成功します。
- OS は、ログ バッファーがオーバーランしたことを検出すると、同じデバイスが所有するすべてのフェンスのライブ値を読み取る、最適化されていないパスにフォールバックします。 パフォーマンスは、デバイスが所有するフェンスの数に比例します。 フェンス値がビデオ メモリ内にある場合、これらの読み取りは PCI 全体でキャッシュ コヒーレントになります。
- 通知されたフェンスとフェンス値を知ることにより、OS はそれらのフェンス/値を待機している CPU 待機処理を起動します。
最適化されたネイティブ フェンス シグナル割り込み
「ネイティブ フェンス シグナル割り込み」で説明されている変更に加えて、最適化されたアプローチをサポートするため、次の変更も行われます。
- OptimizedNativeFenceSignaledInterrupt 上限が DXGK_VIDSCHCAPS に追加されます。
ハードウェアでサポートされている場合、通知されたフェンス ハンドルの配列を入力する代わりに、GPU は割り込みが発生したときに実行されていた HWQueue の KMD ハンドルのみメンションする必要があります。 Dxgkrnl は、この HWQueue のフェンス ログ バッファーをスキャンし、最後の更新以降に GPU によって完了されたすべてのフェンス操作を読み取り、対応する CPU 待機処理をブロック解除します。 通知されたフェンスのサブセットを GPU が特定できなかった場合、NULL HWQueue ハンドルを指定する必要があります。 Dxgkrnl が NULL HWQueue ハンドルを認識すると、フォールバックしてこのエンジン上のすべての HWQueue のログ バッファーを再スキャンし、通知されたフェンスを特定します。
この最適化のサポートは省略可能です。KMD は、ハードウェアでサポートされている場合、DXGK_VIDSCHCAPS:OptimizedNativeFenceSignaledInterrupt 上限を設定する必要があります。 OptimizedNativeFenceSignaledInterrupt 上限が設定されていない場合、GPU/KMD は「ネイティブ フェンス シグナル割り込み」で説明されている動作に従う必要があります。
最適化されたネイティブ フェンス シグナル割り込みの例
HWQueueA: GPU シグナルからフェンス F1、値 V1 -> ログ バッファー エントリ E1 への書き込み - >割り込みは不要
HWQueueA: GPU シグナルからフェンス F1、値 V2 -> ログ バッファー エントリ E2 への書き込み - >割り込みは不要
HWQueueA: GPU シグナルからフェンス F2、値 V3 -> ログ バッファー エントリ E3 への書き込み - >割り込みは不要
HWQueueA: GPU シグナルからフェンス F2、値 V3 -> ログ バッファー エントリ E4 への書き込み - >割り込みが発生
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;Dxgkrnl は、HWQueueA のログ バッファーを読み取ります。 ログ バッファー エントリ E1、E2、E3、E4 を読み取って、シグナル フェンス F1 @ 値 V1、F1 @ 値 V2、F2 @ 値 V3、および F2 @ 値 V3 を観察し、それらのフェンスと値を待機している待機処理をブロック解除します。
省略可能なログ記録と必須のログ記録
DXGK_NATIVE_FENCE_LOG_TYPE_WAITS と DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS のネイティブ フェンス ログのサポートは必須です。
将来、GPUView などのツールが OS で詳細 ETW ログを有効にする場合のみ、他のログ記録の種類が追加される可能性があります。 これらの詳細イベントのログ記録が選択的に有効になるよう、OS は UMD と KMD の両方に、詳細ログが有効および無効になるタイミングを通知する必要があります。