HDInsight 리소스 공급자에 대한 시스템 관리 ID 지원을 통해 HDInsight Log Analytics가 개선되었습니다.
이전 이미지(2024년 이전에 만들어짐)에 대한 mdsd 에이전트 버전을 업그레이드하기 위한 새 작업이 추가되었습니다.
MSAL 마이그레이션에 대한 지속적인 개선의 일환으로 게이트웨이에서 MISE를 사용하도록 설정합니다.
Spark Thrift Server Httpheader hiveConf를 Jetty HTTP ConnectionFactory에 통합합니다.
RANGER-3753 및 RANGER-3593을 되돌립니다.
Ranger 2.3.0 릴리스에 제공된 setOwnerUser 구현에는 Hive에서 사용될 때 심각한 회귀 문제가 있습니다. Ranger 2.3.0에서 HiveServer2가 정책을 평가하려고 하면 Ranger 클라이언트는 기본적으로 해당 테이블에 대한 액세스를 확인하기 위해 스토리지를 호출하는 setOwnerUser 함수에서 Metastore를 호출하여 하이브 테이블의 소유자를 가져오려고 합니다. 이 문제로 인해 Hive가 2.3.0 Ranger에서 실행될 때 쿼리가 느리게 실행됩니다.
SFI 이니셔티브의 일부로 Keyvault에 대한 토큰을 가져오기 위해 게이트웨이에 API를 추가했습니다.
새 로그 모니터 HDInsightSparkLogs 테이블에서 로그 형식 SparkDriverLog에 대한 일부 필드가 누락되었습니다. 예들 들어 LogLevel & Message입니다. 이 릴리스에서는 누락된 필드를 스키마에 추가하고 SparkDriverLog에 대한 서식을 수정했습니다.
Log Analytics 모니터링 SparkDriverLog 테이블에서 Livy 로그를 사용할 수 없습니다. 이는 SparkLivyLog 구성의 Livy 로그 소스 경로 및 로그 구문 분석 정규식 문제로 인해 발생했습니다.
ADLS Gen2를 기본 스토리지 계정으로 사용하는 모든 HDInsight 클러스터는 애플리케이션 코드 내에서 사용되는 모든 Azure 리소스(예: SQL, Keyvaults)에 대한 MSI 기반 액세스를 활용할 수 있습니다.
HDInsight는 2023년 11월 1일부터 HDInsight 5.1의 일반 공급에 대해 발표합니다. 이 릴리스는 오픈 소스 구성 요소 및 Microsoft의 통합에 대한 전체 스택 새로 고침을 제공합니다.
최신 오픈 소스 버전 – HDInsight 5.1에는 안정적인 최신 오픈 소스 버전이 제공됩니다. 고객은 모든 최신 오픈 소스 기능, Microsoft 성능 향상 및 버그 수정 혜택을 받을 수 있습니다.
보안 – 최신 버전에는 Microsoft의 오픈 소스 보안 수정 및 보안 개선 사항 모두에 대한 최신 보안 수정 사항이 제공됩니다.
낮은 TCO – 성능 향상을 통해 고객은 향상된 자동 크기 조정과 함께 운영 비용을 낮출 수 있습니다.
보안 스토리지에 대한 클러스터 권한
고객은 (클러스터를 만드는 동안) HDInsight 클러스터 노드에 보안 채널을 사용하여 스토리지 계정에 연결할지 여부를 지정할 수 있습니다.
사용자 지정 VNet을 사용하여 HDInsight 클러스터 만들기
HDInsight 클러스터의 전반적인 보안 태세를 개선하려면 사용자 지정 VNET을 사용하는 HDInsight 클러스터는 사용자가 만들기 작업을 수행하기 위해 Microsoft Network/virtualNetworks/subnets/join/action에 대한 권한이 있는지 확인해야 합니다. 이 검사를 사용하도록 설정하지 않으면 고객이 생성 실패에 직면할 수 있습니다.
비 ESP ABFS 클러스터 [Word 읽기 가능에 대한 클러스터 권한]
ESP ABFS 클러스터가 아닌 클러스터는 비 Hadoop 그룹 사용자가 스토리지 작업을 위해 Hadoop 명령을 실행하지 못하도록 제한합니다. 클러스터 보안 상태를 개선하기 위한 변경 내용입니다.
인라인 할당량 업데이트.
이제 내 할당량 페이지에서 직접 할당량 증가를 요청할 수 있습니다. 직접 API 호출을 사용하면 훨씬 더 빠릅니다. API 호출이 실패하는 경우 할당량 증가에 대한 새 지원 요청을 만들 수 있습니다.
출시 예정
클러스터의 보안 태세를 강화하기 위해 클러스터 이름의 최대 길이가 59자에서 45자로 변경됩니다. 이 변경 내용은 이후 릴리스를 시작하는 모든 지역에 롤아웃됩니다.
기본 및 표준 A 시리즈 VM 사용 중지.
2024년 8월 31일에 기본 및 표준 A 시리즈 VM을 사용 중지합니다. 이 날짜가 되기 전에 vCPU별로 더 많은 메모리를 제공하고 SSD(반도체 드라이브)에서 더 빠른 스토리지를 제공하는 Av2 시리즈 VM으로 워크로드를 마이그레이션해야 합니다.
서비스 중단을 방지하려면 2024년 8월 31일 마이그레이션에 기본 및 표준 A 시리즈 VM에서 Av2 시리즈 VM으로 워크로드를 마이그레이션합니다.
클러스터의 보안 태세를 강화하기 위해 클러스터 이름의 최대 길이가 59자에서 45자로 변경됩니다. 이 변경 내용은 2023년 9월 30일까지 시행됩니다.
보안 스토리지에 대한 클러스터 권한
고객은 (클러스터를 만드는 동안) HDInsight 클러스터 노드에 보안 채널을 사용하여 스토리지 계정에 연결할지 여부를 지정할 수 있습니다.
인라인 할당량 업데이트.
내 할당량 페이지에서 직접 할당량 증가를 요청합니다. 이는 직접 API 호출로 더 빠릅니다. API 호출이 실패하면 고객은 할당량 증가에 대한 새로운 지원 요청을 만들어야 합니다.
사용자 지정 VNet을 사용하여 HDInsight 클러스터 만들기
HDInsight 클러스터의 전반적인 보안 태세를 개선하려면 사용자 지정 VNET을 사용하는 HDInsight 클러스터는 사용자가 만들기 작업을 수행하기 위해 Microsoft Network/virtualNetworks/subnets/join/action에 대한 권한이 있는지 확인해야 합니다. 이 변경 내용은 2023년 9월 30일 이전에 클러스터 만들기 실패를 방지하기 위한 필수 확인 사항이므로 고객은 그에 따라 계획을 세워야 합니다.
기본 및 표준 A 시리즈 VM 사용 중지.
2024년 8월 31일에 기본/표준 A 시리즈 VM을 사용 중지합니다. 이 날짜가 되기 전에 vCPU별로 더 많은 메모리를 제공하고 SSD(반도체 드라이브)에서 더 빠른 스토리지를 제공하는 Av2 시리즈 VM으로 워크로드를 마이그레이션해야 합니다. 서비스 중단을 방지하려면 2024년 8월 31일 마이그레이션에 기본 및 표준 A 시리즈 VM에서 Av2 시리즈 VM으로 워크로드를 마이그레이션합니다.
비 ESP ABFS 클러스터[워드 읽기 가능 클러스터 사용]
비 ESP ABFS 클러스터의 변경을 도입하여 비 Hadoop 그룹 사용자가 스토리지 작업을 위해 Hadoop 명령을 실행하지 못하도록 제한할 계획입니다. 클러스터 보안 상태를 개선하기 위한 변경 내용입니다. 고객은 2023년 9월 30일 이전에 업데이트를 계획해야 합니다.
클러스터의 보안 태세를 강화하기 위해 클러스터 이름의 최대 길이가 59자에서 45자로 변경됩니다. 고객은 2023년 9월 30일 이전에 업데이트를 계획해야 합니다.
보안 스토리지에 대한 클러스터 권한
고객은 (클러스터를 만드는 동안) HDInsight 클러스터 노드에 보안 채널을 사용하여 스토리지 계정에 연결할지 여부를 지정할 수 있습니다.
인라인 할당량 업데이트.
내 할당량 페이지에서 직접 할당량 증가를 요청합니다. 이는 직접 API 호출로 더 빠릅니다. API 호출이 실패하면 고객은 할당량 증가에 대한 새로운 지원 요청을 만들어야 합니다.
사용자 지정 VNet을 사용하여 HDInsight 클러스터 만들기
HDInsight 클러스터의 전반적인 보안 태세를 개선하려면 사용자 지정 VNET을 사용하는 HDInsight 클러스터는 사용자가 만들기 작업을 수행하기 위해 Microsoft Network/virtualNetworks/subnets/join/action에 대한 권한이 있는지 확인해야 합니다. 이 변경 내용은 2023년 9월 30일 이전에 클러스터 만들기 실패를 방지하기 위한 필수 확인 사항이므로 고객은 그에 따라 계획을 세워야 합니다.
기본 및 표준 A 시리즈 VM 사용 중지
2024년 8월 31일에 기본/표준 A 시리즈 VM을 사용 중지합니다. 이 날짜가 되기 전에 vCPU별로 더 많은 메모리를 제공하고 SSD(반도체 드라이브)에서 더 빠른 스토리지를 제공하는 Av2 시리즈 VM으로 워크로드를 마이그레이션해야 합니다. 서비스 중단을 방지하려면 2024년 8월 31일 마이그레이션에 기본 및 표준 A 시리즈 VM에서 Av2 시리즈 VM으로 워크로드를 마이그레이션합니다.
비 ESP ABFS 클러스터[워드 읽기 가능 클러스터 사용]
비 ESP ABFS 클러스터의 변경을 도입하여 비 Hadoop 그룹 사용자가 스토리지 작업을 위해 Hadoop 명령을 실행하지 못하도록 제한할 계획입니다. 클러스터 보안 상태를 개선하기 위한 변경 내용입니다. 고객은 2023년 9월 30일 이전에 업데이트를 계획해야 합니다.
업그레이드된 모든 구성 요소는 이제 공개 미리 보기를 위해 비 ESP 클러스터에서 사용할 수 있습니다.
HDInsight의 향상된 자동 스케일링
Azure HDInsight는 자동 스케일링의 안정성 및 대기 시간을 크게 개선했으며, 중요한 변경 사항에는 스케일링 결정에 대한 피드백 루프 개선, 스케일링 대기 시간에 대한 상당한 개선 및 서비스 해제된 노드 서비스 등록, 향상된 기능에 대한 자세한 정보, 클러스터를 사용자 지정 구성하고 향상된 자동 스케일링으로 마이그레이션하는 방법이 포함됩니다. 향상된 자동 스케일링 기능은 지원되는 모든 지역에서 2023년 5월 17일부터 사용할 수 있습니다.
Apache Kafka 2.4.1용 Azure HDInsight ESP가 이제 일반 공급됩니다.
Apache Kafka 2.4.1용 Azure HDInsight ESP는 2022년 4월부터 공개 미리 보기로 제공됩니다. CVE 수정 및 안정성이 크게 개선된 후 Azure HDInsight ESP Kafka 2.4.1은 이제 프로덕션 워크로드에 대해 일반 공급되고 준비됩니다. 구성 및 마이그레이션 방법에 대한 세부 정보를 알아보세요.
HDInsight에 대한 할당량 관리
HDInsight는 현재 지역 수준에서 고객 구독에 할당량을 할당합니다. 고객에게 할당된 코어는 일반용이며 VM 제품군 수준에서 분류되지 않습니다(예: Dv2, Ev3, Eav4 등).
HDInsight는 가족 수준 VM에 대한 할당량 세부 정보와 분류를 제공하는 향상된 보기를 도입했으며, 이 기능을 통해 고객은 VM 제품군 수준에서 지역의 현재 할당량과 남은 할당량을 볼 수 있습니다. 향상된 보기를 통해 고객은 할당량 계획 및 더 나은 사용자 환경을 위해 보다 풍부한 가시성을 확보합니다. 이 기능은 현재 미국 동부 EUAP 지역의 HDInsight 4.x 및 5.x에서 사용할 수 있습니다. 다른 지역은 나중에 사용 가능합니다.
클러스터의 보안 태세를 강화하기 위해 클러스터 이름의 최대 길이가 59자에서 45자로 변경됩니다.
보안 스토리지에 대한 클러스터 권한
고객은 (클러스터를 만드는 동안) HDInsight 클러스터 노드에 보안 채널을 사용하여 스토리지 계정에 연결할지 여부를 지정할 수 있습니다.
인라인 할당량 업데이트
내 할당량 페이지에서 직접 할당량 증가를 요청합니다. 이는 직접 API 호출로 더 빠릅니다. API 호출이 실패하면 고객은 할당량 증가에 대한 새로운 지원 요청을 만들어야 합니다.
사용자 지정 VNet을 사용하여 HDInsight 클러스터 만들기
HDInsight 클러스터의 전반적인 보안 태세를 개선하려면 사용자 지정 VNET을 사용하는 HDInsight 클러스터는 사용자가 만들기 작업을 수행하기 위해 Microsoft Network/virtualNetworks/subnets/join/action에 대한 권한이 있는지 확인해야 합니다. 이 내용은 클러스터 만들기 실패를 방지하기 위한 필수 확인 사항이므로 고객은 그에 따라 계획을 세워야 합니다.
기본 및 표준 A 시리즈 VM 사용 중지
2024년 8월 31일에 기본/표준 A 시리즈 VM을 사용 중지합니다. 이 날짜가 되기 전에 vCPU별로 더 많은 메모리를 제공하고 SSD(반도체 드라이브)에서 더 빠른 스토리지를 제공하는 Av2 시리즈 VM으로 워크로드를 마이그레이션해야 합니다. 서비스 중단을 방지하려면 2024년 8월 31일 마이그레이션에 기본 및 표준 A 시리즈 VM에서 Av2 시리즈 VM으로 워크로드를 마이그레이션합니다.
비 ESP ABFS 클러스터 [월드 읽기 가능 클러스터 사용 권한]
비 ESP ABFS 클러스터의 변경을 도입하여 비 Hadoop 그룹 사용자가 스토리지 작업을 위해 Hadoop 명령을 실행하지 못하도록 제한할 계획입니다. 클러스터 보안 상태를 개선하기 위한 변경 내용입니다. 고객은 업데이트를 계획해야 합니다.
릴리스 날짜: 2023년 2월 28일
이 릴리스는 HDInsight 4.0에 적용됩니다. 및 5.0, 5.1 HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있습니다. 이 릴리스는 이미지 번호 2302250400 적용할 수 있습니다. 이미지 번호를 확인하는 방법
HDInsight는 점진적 지역 배포를 포함하는 안전한 배포 방법을 사용합니다. 모든 지역에서 새 릴리스 또는 새 버전을 사용할 수 있기까지 영업일 기준 최대 10일이 소요될 수 있습니다.
OS 버전
HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
JoinGroupRequest 및 LeaveGroupRequest 에는 이유가 연결되어 있습니다.
Broker 개수 metric8이 추가되었습니다.
사소한 Maker2 개선 사항
HBase 2.4.11 업그레이드(미리 보기)
이 버전에는 블록 캐시에 대한 새로운 캐싱 메커니즘 유형 추가, HBase WEB UI에서 hbase:meta table을 변경하고 hbase:meta 테이블을 보는 기능과 같은 새로운 기능이 있습니다.
Phoenix 5.1.2 업그레이드(미리 보기)
Phoenix 버전은 이 릴리스에서 5.1.2로 업그레이드되었습니다. 이 업그레이드에는 Phoenix Query Server가 포함됩니다. Phoenix Query Server는 표준 Phoenix JDBC 드라이버를 프록시하고 이전 버전과 호환되는 유선 프로토콜을 제공하여 해당 JDBC 드라이버를 호출합니다.
Ambari CVEs
여러 Ambari CVE가 수정되었습니다.
참고
ESP는 이 릴리스에서 Kafka 및 HBase에 대해 지원되지 않습니다.
다음 단계
{b>자동 스케일링
향상된 대기 시간으로 자동 스케일링 및 몇 가지 개선 사항
클러스터 이름 변경 제한
클러스터 이름의 최대 길이는 공용, Azure 중국 및 Azure Government에서 59에서 45로 변경됩니다.
보안 스토리지에 대한 클러스터 권한
고객은 (클러스터를 만드는 동안) HDInsight 클러스터 노드에 보안 채널을 사용하여 스토리지 계정에 연결할지 여부를 지정할 수 있습니다.
비 ESP ABFS 클러스터 [월드 읽기 가능 클러스터 사용 권한]
비 ESP ABFS 클러스터의 변경을 도입하여 비 Hadoop 그룹 사용자가 스토리지 작업을 위해 Hadoop 명령을 실행하지 못하도록 제한할 계획입니다. 클러스터 보안 상태를 개선하기 위한 변경 내용입니다. 고객은 업데이트를 계획해야 합니다.
오픈 소스 업그레이드
Apache Spark 3.3.0 및 Hadoop 3.3.4는 HDInsight 5.1에서 개발 중이며 몇 가지 중요한 새로운 기능, 성능 및 기타 개선 사항을 포함합니다.
참고
고객은 최신 버전의 HDInsight 이미지를 사용하여 오픈 소스 업데이트, Azure 업데이트 및 보안 수정 사항을 최대한 활용하는 것이 좋습니다. 자세한 내용은 모범 사례를 참조하세요.
릴리스 날짜: 2022년 12월 12일
이 릴리스는 HDInsight 4.0에 적용됩니다. 및 5.0 HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다.
HDInsight는 점진적 지역 배포를 포함하는 안전한 배포 방법을 사용합니다. 모든 지역에서 새 릴리스 또는 새 버전을 사용할 수 있기까지 영업일 기준 최대 10일이 소요될 수 있습니다.
OS 버전
HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Log Analytics - 고객은 클래식 모니터링을 사용하도록 설정하여 최신 OMS 버전 14.19를 가져올 수 있습니다. 이전 버전을 제거하려면 클래식 모니터링을 사용하지 않도록 설정했다가 다시 사용하도록 설정합니다.
Spark - Spark 3.1.3의 최적화된 새 버전이 이 릴리스에 포함되어 있습니다. TPC-DS 벤치마크를 사용하여 Apache Spark 3.1.2(이전 버전) 및 Apache Spark 3.1.3(현재 버전)을 테스트했습니다. 이 테스트는 1TB 워크로드의 Apache Spark용 E8 V3 SKU를 사용하여 수행되었습니다. Apache Spark 3.1.3(현재 버전)은 동일한 하드웨어 사양을 사용하는 TPC-DS 쿼리에 대한 총 쿼리 런타임에서 Apache Spark 3.1.2(이전 버전)를 40% 이상 능가했습니다. Microsoft Spark 팀은 Azure HDInsight가 있는 Azure Synapse에서 사용할 수 있는 최적화를 추가했습니다. 자세한 내용은 Azure Synapse에서 Apache Spark 3.1.2에 대한 성능 업데이트를 통해 데이터 워크로드 가속화를 참조하세요.
카타르 중부
독일 북부
HDInsight는 Azul Zulu Java JDK 8에서 고품질 TCK 인증 런타임을 지원하는 Adoptium Temurin JDK 8 및 Java 에코시스템에서 사용하기 위한 관련 기술로 전환되었습니다.
HDInsight는 reload4j(으)로 마이그레이션되었습니다. log4j 변경 내용은 다음에 적용됩니다.
Apache Hadoop
Apache Zookeeper
Apache Oozie
Apache Ranger
Apache Sqoop
Apache Pig
Apache Ambari
Apache Kafka
Apache Spark
Apache Zeppelin
Apache Livy
Apache Rubix
Apache Hive
Apache Tez
Apache HBase
OMI
Apache Pheonix
앞으로 TLS1.2를 구현하기 위한 HDInsight 및 이전 버전이 플랫폼에서 업데이트됩니다. HDInsight를 기반으로 애플리케이션을 실행하고 있으며 TLS 1.0 및 1.1을 사용하는 경우 서비스 중단을 방지하기 위해 TLS 1.2로 업그레이드하세요.
Ubuntu 16.04 LTS의 Azure HDInsight 클러스터에 대한 지원 종료는 2022년 11월 30일부터 시작되었습니다. HDInsight는 2021년 6월 27일부터 Ubuntu 18.04를 사용하여 클러스터 이미지 릴리스를 시작합니다. Ubuntu 16.04를 사용하여 클러스터를 실행하는 고객은 2022년 11월 30일까지 최신 HDInsight 이미지로 클러스터를 다시 빌드하는 것이 좋습니다.
이제 공개 미리 보기를 위해 모든 지역에서 선택적 로깅 분석을 사용할 수 있습니다. 클러스터를 로그 분석 작업 영역에 연결할 수 있습니다. 사용하도록 설정되면 HDInsight Security Logs, Yarn Resource Manager, System Metrics 등과 같은 로그 및 메트릭을 볼 수 있습니다. 워크로드를 모니터링하고 클러스터 안정성에 미치는 영향을 확인할 수 있습니다. 선택적 로깅을 사용하면 모든 테이블을 사용하도록 설정/사용하지 않도록 설정하거나 로그 분석 작업 영역에서 선택적 테이블을 사용하도록 설정할 수 있습니다. 새 버전의 Geneva 모니터링에서는 하나의 테이블에 여러 원본이 있으므로 각 테이블의 원본 형식을 조정할 수 있습니다.
Geneva 모니터링 시스템은 모니터링 에이전트인 mdsd(MDS daemon)와 통합 로깅 계층을 사용하여 로그를 수집하는 fluentd를 사용합니다.
선택적 로깅은 스크립트 작업을 사용하여 테이블 및 해당 로그 형식을 사용하지 않도록 설정/사용하도록 설정합니다. 새 포트를 열거나 기존 보안 설정을 변경하지 않으므로 보안 변경 내용이 없습니다.
스크립트 작업은 지정된 모든 노드에서 병렬로 실행되며 테이블 및 해당 로그 형식을 사용하지 않도록 설정/사용하도록 설정하기 위한 구성 파일을 변경합니다.
최신 보안 업데이트를 적용하려면 OMS 버전 13을 실행하는 Azure HDInsight와 통합된 Log Analytics를 OMS 버전 14로 업그레이드해야 합니다.
OMS 버전 13과 함께 이전 버전의 클러스터를 사용하는 고객은 보안 요구 사항을 충족하기 위해 OMS 버전 14를 설치해야 합니다. (현재 버전 및 설치 14 확인 방법)
이제 공개 미리 보기를 위해 모든 지역에서 선택적 로깅 분석을 사용할 수 있습니다. 클러스터를 로그 분석 작업 영역에 연결할 수 있습니다. 사용하도록 설정되면 HDInsight Security Logs, Yarn Resource Manager, System Metrics 등과 같은 로그 및 메트릭을 볼 수 있습니다. 워크로드를 모니터링하고 클러스터 안정성에 미치는 영향을 확인할 수 있습니다. 선택적 로깅을 사용하면 모든 테이블을 사용하도록 설정/사용하지 않도록 설정하거나 로그 분석 작업 영역에서 선택적 테이블을 사용하도록 설정할 수 있습니다. 새 버전의 Geneva 모니터링에서는 하나의 테이블에 여러 원본이 있으므로 각 테이블의 원본 형식을 조정할 수 있습니다.
Geneva 모니터링 시스템은 모니터링 에이전트인 mdsd(MDS daemon)와 통합 로깅 계층을 사용하여 로그를 수집하는 fluentd를 사용합니다.
선택적 로깅은 스크립트 작업을 사용하여 테이블 및 해당 로그 형식을 사용하지 않도록 설정/사용하도록 설정합니다. 새 포트를 열거나 기존 보안 설정을 변경하지 않으므로 보안 변경 내용이 없습니다.
스크립트 작업은 지정된 모든 노드에서 병렬로 실행되며 테이블 및 해당 로그 형식을 사용하지 않도록 설정/사용하도록 설정하기 위한 구성 파일을 변경합니다.
최신 보안 업데이트를 적용하려면 OMS 버전 13을 실행하는 Azure HDInsight와 통합된 Log Analytics를 OMS 버전 14로 업그레이드해야 합니다.
OMS 버전 13과 함께 이전 버전의 클러스터를 사용하는 고객은 보안 요구 사항을 충족하기 위해 OMS 버전 14를 설치해야 합니다. (현재 버전 및 설치 14 확인 방법)
HDInsight는 Apache HIVE 3.1.2와 호환됩니다. 이 릴리스의 버그로 인해 Hive 버전은 Hive 인터페이스에서 3.1.0으로 표시됩니다. 그러나 기능에는 영향이 없습니다.
릴리스 날짜: 2022/06/03
이 릴리스는 HDInsight 4.0에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 다음 변경 내용이 표시되지 않으면 릴리스가 해당 지역에서 며칠에 걸쳐 릴리스될 때까지 기다리세요.
릴리스 관련 주요 사항
Spark v3.1.2의 HWC(Hive Warehouse Connector)
HWC(Hive Warehouse Connector)를 사용하면 Hive 및 Spark의 고유한 기능을 활용하여 강력한 빅 데이터 애플리케이션을 빌드할 수 있습니다. HWC는 현재 Spark v2.4에서만 지원됩니다. 이 기능은 Spark를 사용하여 Hive 테이블에서 ACID 트랜잭션을 허용하여 비즈니스 가치를 추가합니다. 이 기능은 데이터 자산에서 Hive와 Spark를 모두 사용하는 고객에게 유용합니다.
자세한 내용은 Apache Spark & Hive - Hive Warehouse Connector - Azure HDInsight | Microsoft Docs를 참조하세요.
Ambari
크기 조정 및 프로비저닝 개선 변경 내용
HDI 하이브는 이제 OSS 버전 3.1.2와 호환됩니다.
HDI Hive 3.1 버전이 OSS Hive 3.1.2로 업그레이드되었습니다. 이 버전에는 오픈 소스 Hive 3.1.2 버전에서 사용할 수 있는 모든 수정 사항과 기능이 있습니다.
참고
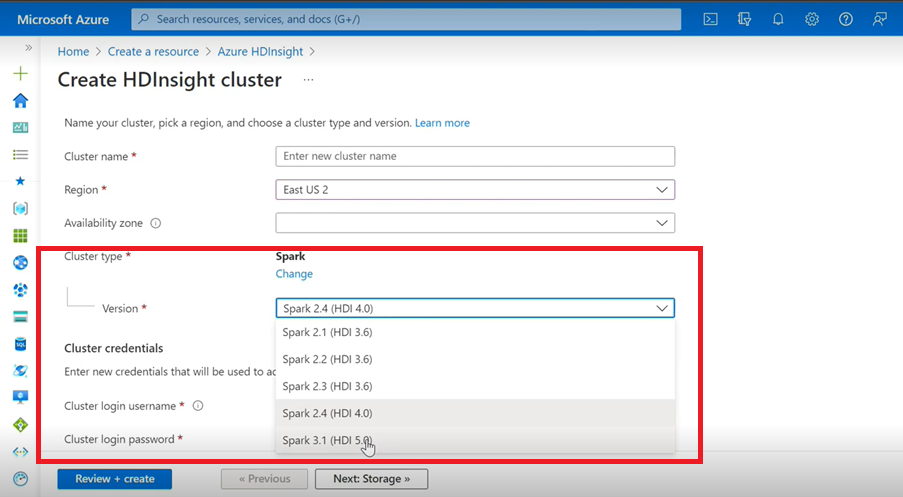
Spark
Azure 사용자 인터페이스를 사용하여 HDInsight용 Spark 클러스터를 만드는 경우 드롭다운 목록에 이전 버전과 함께 다른 버전 Spark 3.1(HDI 5.0)이 표시됩니다. 이 버전은 Spark 3.1.(HDI 4.0)의 이름이 변경된 버전입니다. 이는 UI 수준의 변경일 뿐이며 기존 사용자와 이미 ARM 템플릿을 사용하고 있는 사용자에게는 아무 영향도 미치지 않습니다.
참고
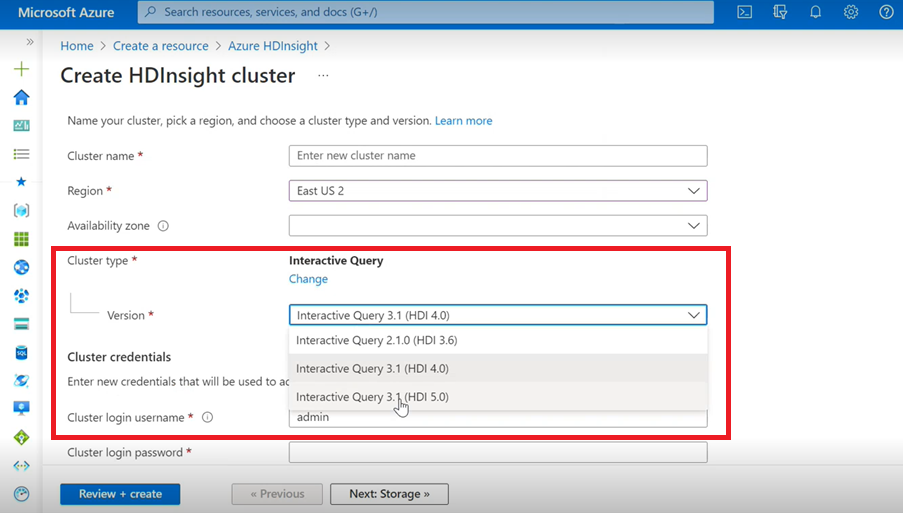
Interactive Query
Interactive Query 클러스터를 만드는 경우 드롭다운 목록에 Interactive Query 3.1(HDI 5.0)과 같은 다른 버전이 표시됩니다.
ACID 지원이 필요한 Hive와 함께 Spark 3.1 버전을 사용하려는 경우 이 버전 Interactive Query 3.1(HDI 5.0)을 선택해야 합니다.
TEZ 버그 수정
버그 수정
Apache JIRA
32MB보다 큰 구성의 TezUtils.createConfFromByteString에서 com.google.protobuf.CodedInputStream 예외 발생
이 릴리스는 HDInsight 4.0에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 다음 변경 내용이 표시되지 않으면 릴리스가 해당 지역에서 며칠에 걸쳐 릴리스될 때까지 기다리세요.
이 릴리스의 OS 버전은 다음과 같습니다.
HDInsight 4.0: Ubuntu 18.04.5
이제 Spark 3.1이 일반 공급됩니다.
Spark 3.1은 이제 HDInsight 4.0 릴리스부터 일반적으로 사용 가능합니다. 이 릴리스에는 다음 관리 팩이 포함되어 있습니다.
적응 쿼리 실행,
정렬 병합 조인을 브로드캐스트 해시 조인으로 변환,
Spark Catalyst Optimizer,
Dynamic Partition Pruning,
고객은 Spark 3.0(미리 보기) 클러스터가 아닌 새 Spark 3.1 클러스터를 만들 수 있습니다.
자세한 내용은 이제 HDInsight에서 일반적으로 사용 가능한 Apache Spark 3.1 - Microsoft 기술 커뮤니티를 참조하세요.
이제 Kafka 2.4.1이 일반적으로 사용 가능합니다. 자세한 내용은 Kafka 2.4.1 릴리스 정보를 참조하세요. 기타 기능에는 MirrorMaker 2 가용성, 새로운 메트릭 범주 AtMinIsr 토픽 파티션, 인덱스 파일의 요청 시 지연 mmap(으)로 브로커 작동 시간 개선, 사용자 폴링 동작을 관찰하기 위한 소비자 메트릭 증가 등이 있습니다.
HWC의 맵 데이터 형식은 이제 HDInsight 4.0에서 지원됩니다.
이 릴리스에는 HWC가 지원하는 Spark 셸 애플리케이션 및 기타 모든 Spark 클라이언트를 통한 HWC 1.0(Spark 2.4)에 대한 맵 데이터 형식 지원이 포함되어 있습니다. 다른 데이터 형식과 마찬가지로 다음과 같은 개선 사항이 포함됩니다.
사용자는 다음 작업을 수행할 수 있습니다.
Map 데이터 형식이 포함된 열로 Hive 테이블을 만들고 여기에 데이터를 삽입하고 결과를 읽습니다.
Map 형식으로 Apache Spark 데이터 프레임을 만들고 일괄 처리/스트림 읽기 및 쓰기를 수행합니다.
새 지역
HDInsight는 이제 두 개의 새로운 지역인 중국 동부 3과 중국 북부 3으로 지리적 입지를 확장했습니다.
OSS 백포트 변경 내용
Hive에 포함된 OSS 백포트(Map 데이터 형식을 지원하는 HWC 1.0(Spark 2.4) 포함)
이 릴리스에 대해 OSS 백포트된 Apache JIRA는 다음과 같습니다.
영향을 받는 기능
Apache JIRA
IN/(NOT IN)이 있는 Metastore 직접 SQL 쿼리는 SQL DB에서 허용하는 최대 매개 변수에 따라 분할되어야 합니다.
HDInsight는 더 이상 Azure Virtual Machine Scale Sets를 사용하여 클러스터를 프로비저닝하지 않으며 호환성이 손상되는 변경은 예상되지 않습니다. Virtual Machine Scale Sets의 기존 HDInsight 클러스터는 영향을 미치지 않으며 최신 이미지의 새 클러스터는 더 이상 Virtual Machine Scale Sets를 사용하지 않습니다.
Azure HDInsight HBase 워크로드의 크기 조정은 이제 수동 크기 조정을 통해서만 지원됩니다.
2022년 3월 1일부터 HDInsight는 HBase에 대한 수동 확장만 지원하며 클러스터 실행에는 영향이 없습니다. 새 HBase 클러스터는 일정 기반의 자동 크기 조정을 사용하도록 설정할 수 없습니다. HBase 클러스터를 수동으로 크기 조정하는 방법에 대한 자세한 내용은 Azure HDInsight 클러스터 수동 크기 조정에 대한 설명서를 참조하세요.
릴리스 날짜: 2021/12/27
이 릴리스는 HDInsight 4.0에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 다음 변경 내용이 표시되지 않으면 릴리스가 해당 지역에서 며칠에 걸쳐 릴리스될 때까지 기다리세요.
2021년 12월 27일 00:00 UTC 이후 만들어진 HDI 4.0 클러스터는 log4j 취약성을 완화하는 업데이트된 버전의 이미지로 만들어집니다. 따라서 고객은 이러한 클러스터를 패치/다시 부팅할 필요가 없습니다.
2021년 12월 16일 01:15 UTC에서 2021년 12월 27일 00:00 UTC 사이에 만들어진 새로운 HDInsight 4.0 클러스터의 경우, HDInsight 3.6 또는 2021년 12월 16일 이후에 고정된 구독에서 패치는 클러스터가 만들어진 시간 내에 자동으로 적용되지만 패치가 완료되려면 고객이 해당 노드를 다시 부팅해야 합니다(Kafka 관리 노드 제외, 자동으로 다시 부팅됨).
릴리스 날짜: 2021/07/27
이 릴리스는 HDInsight 3.6 및 4.0 모두에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
이 릴리스의 OS 버전은 다음과 같습니다.
HDInsight 3.6: Ubuntu 16.04.7 LTS
HDInsight 4.0: Ubuntu 18.04.5 LTS
새로운 기능
제한된 공용 연결에 대한 Azure HDInsight 지원은 2021년 10월 15일에 일반 공급됨
이제 Azure HDInsight는 모든 지역에서 제한된 공용 연결을 지원합니다. 아래에 이 기능의 주요 사항 중 일부가 나와 있습니다.
리소스 공급자를 클러스터에서 리소스 공급자로 아웃바운드하도록 클러스터 통신으로 되돌리는 기능
HDinsight 클러스터가 프라이빗 네트워크를 통해서만 리소스에 액세스할 수 있도록 고유한 Private Link 지원 리소스(예: 스토리지, SQL, 키 자격 증명 모음)를 가져오는 지원 기능
공용 IP 주소에 프로비전된 리소스가 없음
이 새로운 기능을 사용하면 HDInsight 관리 IP에 대한 인바운드 NSG(네트워크 보안 그룹) 서비스 태그 규칙을 건너뛸 수도 있습니다. 공용 연결 제한에 대해 자세히 알아보세요.
Azure Private Link에 대한 Azure HDInsight 지원은 2021년 10월 15일에 일반 공급됩니다.
이제 프라이빗 링크를 통해 HDInsight 클러스터에 연결하는 프라이빗 엔드포인트를 사용할 수 있습니다. 프라이빗 링크는 VNET 피어링을 사용할 수 없거나 사용하도록 설정되지 않은 VNET 간 시나리오에서 활용할 수 있습니다.
Azure Private Link를 사용하면 가상 네트워크의 프라이빗 엔드포인트를 통해 Azure PaaS Services(예: Azure Storage 및 SQL Database)와 Azure 호스팅 고객 소유/파트너 서비스에 액세스할 수 있습니다.
가상 네트워크와 서비스 사이의 트래픽은 Microsoft 백본 네트워크를 통해 이동합니다. 서비스를 공용 인터넷에 더 이상 노출할 필요가 없습니다.
새 Azure Monitor 통합 환경은 이번 릴리스와 함께 미국 동부와 서유럽에서 미리 보기로 제공됩니다. 새 Azure Monitor 환경에 대한 자세한 내용은 여기를 참조하세요.
감가 상각
HDInsight 3.6 버전은 2022년 10월 1일부터 사용 중지되었습니다.
동작 변경
HDInsight Interactive Query는 일정 기반 자동 스케일링만 지원합니다.
고객 시나리오가 점점 더 성숙하고 다양해짐에 따라 Interactive Query(LLAP) 부하 기반 자동 스케일링에 대한 몇 가지 제한 사항을 확인했습니다. 이 제한 사항은 LLAP 쿼리 역학의 특징, 향후 부하 예측 정확도 문제 및 LLAP 스케줄러의 작업 재배포 문제 때문에 발생합니다. 이러한 제한 사항으로 인해 사용자는 자동 크기 조정이 사용되는 경우 LLAP 클러스터에서 쿼리 실행 속도가 느려지는 것을 알 수 있습니다. 성능에 미치는 영향이 자동 스케일링의 비용 이점보다 클 수 있습니다.
2021년 7월부터 HDInsight의 Interactive Query 워크로드는 일정 기반 자동 스케일링만 지원합니다. 새 Interactive Query 클러스터에서는 더 이상 부하 기반 자동 스케일링을 사용하도록 설정할 수 없습니다. 기존에 실행 중인 클러스터는 위에서 설명된 알려진 제한 사항을 적용하여 계속 실행할 수 있습니다.
LLAP를 위해 일정 기반 자동 스케일링으로 이동하는 것이 좋습니다. Grafana Hive 대시보드를 통해 클러스터의 현재 사용 패턴을 분석할 수 있습니다. 자세한 내용은 Azure HDInsight 클러스터 자동 크기 조정을 참조하세요.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
ESP Spark 클러스터의 기본 제공 LLAP 구성 요소가 제거됩니다.
HDInsight 4.0 ESP Spark 클러스터에는 두 헤드 노드에서 모두 실행되는 기본 제공 LLAP 구성 요소가 있습니다. ESP Spark 클러스터의 LLAP 구성 요소는 원래 HDInsight 3.6 ESP Spark용으로 추가되었지만 HDInsight 4.0 ESP Spark용 실제 사용자 사례는 없습니다. 2021년 9월로 예정된 다음 릴리스에서 HDInsight는 HDInsight 4.0 ESP Spark 클러스터에서 기본 제공 LLAP 구성 요소를 제거합니다. 이렇게 변경하면 헤드 노드 워크로드를 오프로드하고 ESP Spark와 ESP Interactive Hive 클러스터 유형 간의 혼동을 방지하는 데 도움이 됩니다.
새 지역
미국 서부 3
Jio 인도 서부
오스트레일리아 중부
구성 요소 버전 변경
이 릴리스에서 변경된 구성 요소 버전은 다음과 같습니다.
ORC 버전 1.5.1에서 1.5.9로 변경
이 문서에서 HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 찾을 수 있습니다.
2021년 4월 25일에 HDInsight의 Dv2 VM 시리즈에 대한 가격 책정 오류가 수정되었습니다. 가격 책정 오류로 인해 4월 25일 이전 일부 고객의 청구서에서 요금이 적게 청구되었으며, 수정을 통해 가격은 이제 HDInsight 가격 책정 페이지 및 HDInsight 가격 계산기에 게시된 가격과 일치합니다. 가격 책정 오류는 Dv2 VM을 사용한 다음 지역의 고객에게 영향을 주었습니다.
캐나다 중부
캐나다 동부
동아시아
남아프리카 북부
동남 아시아
아랍에미리트 중부
2021년 4월 25일부터 Dv2 VM의 수정된 금액이 계정에 표시됩니다. 변경 전에 구독 소유자에게 고객 알림이 전송되었습니다. Azure Portal에서 가격 계산기, HDInsight 가격 책정 페이지 또는 HDInsight 클러스터 만들기 블레이드를 사용하여 해당 지역 Dv2 VM의 수정된 비용을 확인할 수 있습니다.
다른 작업은 필요하지 않습니다. 가격 수정은 지정된 지역에서 2021년 4월 25일 또는 그 이후 사용량에만 적용되며 이 날짜 이전 사용량에는 적용되지 않습니다. 가장 성능이 뛰어나고 비용 효율적인 솔루션을 사용하려면 Dv2 클러스터의 가격 책정, VCPU 및 RAM을 검토하고 Dv2 사양을 Ev3 VM과 비교하여 솔루션이 최신 VM 시리즈 중 하나를 유용하게 활용하는지 확인하는 것이 좋습니다.
릴리스 날짜: 2021/06/02
이 릴리스는 HDInsight 3.6 및 4.0 모두에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
이 릴리스의 OS 버전은 다음과 같습니다.
HDInsight 3.6: Ubuntu 16.04.7 LTS
HDInsight 4.0: Ubuntu 18.04.5 LTS
새로운 기능
OS 버전 업그레이드
Ubuntu의 릴리스 주기에서 언급된 대로 Ubuntu 16.04 커널은 2021년 4월에 EOL(수명 종료)에 도달합니다. 이 리릴스에서는 Ubuntu 18.04에서 실행되는 새 HDInsight 4.0 클러스터 이미지 출시를 시작했습니다. 새로 만든 HDInsight 4.0 클러스터는 제공된 후 기본적으로 Ubuntu 18.04에서 실행됩니다. Ubuntu 16.04의 기존 클러스터는 완벽한 지원과 함께 있는 그대로 실행됩니다.
HDInsight 3.6은 Ubuntu 16.04에서 계속 실행됩니다. 2021년 7월 1일부터 기본 지원(표준 지원에서)으로 변경됩니다. 날짜 및 지원 옵션에 관한 자세한 내용은 Azure HDInsight 버전을 참조하세요. HDInsight 3.6에서는 Ubuntu 18.04가 지원되지 않습니다. Ubuntu 18.04를 사용하려면 클러스터를 HDInsight 4.0으로 마이그레이션해야 합니다.
기존 HDInsight 4.0 클러스터를 Ubuntu 18.04로 이동하려면 클러스터를 삭제하고 다시 만들어야 합니다. Ubuntu 18.04 지원이 제공된 후 클러스터를 만들거나 다시 만들 계획입니다.
새 클러스터를 만든 후 클러스터에 SSH를 실행하고 sudo lsb_release -a를 실행하여 Ubuntu 18.04에서 실행되는지 확인할 수 있습니다. 프로덕션으로 이동하기 전에 먼저 테스트 구독에서 애플리케이션을 테스트하는 것이 좋습니다.
HDInsight 클러스터 헤드 노드는 클러스터 초기화 및 관리를 처리합니다. Standard_A5 VM 크기는 HDInsight 4.0의 헤드 노드로서 안정성 문제가 있습니다. 이 릴리스부터 고객은 Standard_A5 VM 크기를 헤드 노드로 사용하여 새 클러스터를 만들 수 없습니다. E2_v3 또는 E2s_v3 같은 다른 2코어 VM을 사용할 수 있습니다. 기존 클러스터는 계속 운영됩니다. 프로덕션 HDInsight 클러스터의 고가용성 및 안정성을 보장하기 위해 헤드 노드에는 4코어 VM을 사용하는 것이 좋습니다.
Azure Virtual Machine Scale Sets에서 실행되는 클러스터에 대한 네트워크 인터페이스 리소스가 표시되지 않음
HDInsight는 Azure Virtual Machine Scale Sets로 점진적으로 마이그레이션되고 있습니다. 가상 머신의 네트워크 인터페이스는 Azure Virtual Machine Scale Sets를 사용하는 클러스터의 고객에게는 더 이상 표시되지 않습니다.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
HDInsight Interactive Query는 일정 기반 자동 스케일링만 지원합니다.
고객 시나리오가 점점 더 성숙하고 다양해짐에 따라 Interactive Query(LLAP) 부하 기반 자동 스케일링에 대한 몇 가지 제한 사항을 확인했습니다. 이 제한 사항은 LLAP 쿼리 역학의 특징, 향후 부하 예측 정확도 문제 및 LLAP 스케줄러의 작업 재배포 문제 때문에 발생합니다. 이러한 제한 사항으로 인해 사용자는 자동 크기 조정이 사용되는 경우 LLAP 클러스터에서 쿼리 실행 속도가 느려지는 것을 알 수 있습니다. 성능에 미치는 영향이 자동 스케일링의 비용 이점보다 클 수 있습니다.
2021년 7월부터 HDInsight의 Interactive Query 워크로드는 일정 기반 자동 스케일링만 지원합니다. 새 Interactive Query 클러스터에서는 더 이상 자동 스케일링을 사용하도록 설정할 수 없습니다. 기존에 실행 중인 클러스터는 위에서 설명된 알려진 제한 사항을 적용하여 계속 실행할 수 있습니다.
LLAP를 위해 일정 기반 자동 스케일링으로 이동하는 것이 좋습니다. Grafana Hive 대시보드를 통해 클러스터의 현재 사용 패턴을 분석할 수 있습니다. 자세한 내용은 Azure HDInsight 클러스터 자동 크기 조정을 참조하세요.
VM 호스트 이름은 2021년 7월 1일에 변경됩니다.
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 이 서비스는 Azure Virtual Machine Scale Sets로 점진적으로 마이그레이션됩니다. 이 마이그레이션은 클러스터 호스트 이름 FQDN 이름 형식을 변경하며 호스트 이름의 숫자는 순서대로 보장되지 않습니다. 각 노드에 대한 FQDN 이름을 가져오려면 클러스터 노드의 호스트 이름 찾기를 참조하세요.
Azure 가상 머신 확장 집합으로 이동
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 이 서비스는 Azure 가상 머신 확장 집합으로 점진적으로 마이그레이션됩니다. 전체 프로세스는 몇 개월이 소요될 수 있습니다. 지역 및 구독이 마이그레이션된 후에는 새로 생성된 HDInsight 클러스터가 고객의 작업 없이도 Virtual Machine Scale Sets에서 실행됩니다. 호환성이 손상되는 변경 사항은 없을 것으로 예상됩니다.
릴리스 날짜: 2021/03/24
새로운 기능
Spark 3.0 미리 보기
HDInsight는 HDInsight 4.0에 Spark 3.0.0 지원을 미리 보기 기능으로 추가했습니다.
Kafka 2.4 미리 보기
HDInsight는 HDInsight 4.0에 Kafka 2.4.1 지원을 미리 보기 기능으로 추가했습니다.
Eav4 시리즈 지원
HDInsight는 이 릴리스에서 Eav4 시리즈 지원 기능을 추가했습니다.
Azure Virtual Machine Scale Sets로 전환
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 이 서비스는 Azure Virtual Machine Scale Sets로 점진적으로 마이그레이션됩니다. 전체 프로세스는 몇 개월이 소요될 수 있습니다. 지역 및 구독이 마이그레이션된 후에는 새로 생성된 HDInsight 클러스터가 고객의 작업 없이도 Virtual Machine Scale Sets에서 실행됩니다. 호환성이 손상되는 변경 사항은 없을 것으로 예상됩니다.
감가 상각
이 릴리스에서는 사용 중단되지 않습니다.
동작 변경
기본 클러스터 버전이 4.0으로 변경됨
HDInsight 클러스터의 기본 버전이 3.6에서 4.0으로 변경되었습니다. 사용 가능한 버전에 관한 자세한 내용은 사용 가능한 버전을 참조하세요. HDInsight 4.0의 새로운 기능에 관해 자세히 알아보세요.
기본 클러스터 VM 크기가 Ev3 시리즈로 변경됨
기본 클러스터 VM 크기가 D 시리즈에서 Ev3 시리즈로 변경됩니다. 이 변경 내용은 헤드 노드와 작업자 노드에 적용됩니다. 이러한 변경 내용이 테스트된 워크플로에 영향을 주지 않도록 하려면 ARM 템플릿에서 사용할 VM 크기를 지정합니다.
Azure Virtual Machine Scale Sets에서 실행되는 클러스터에 대한 네트워크 인터페이스 리소스가 표시되지 않음
HDInsight는 Azure Virtual Machine Scale Sets로 점진적으로 마이그레이션되고 있습니다. 가상 머신의 네트워크 인터페이스는 Azure Virtual Machine Scale Sets를 사용하는 클러스터의 고객에게는 더 이상 표시되지 않습니다.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
HDInsight Interactive Query는 일정 기반 자동 스케일링만 지원합니다.
고객 시나리오가 점점 더 성숙하고 다양해짐에 따라 Interactive Query(LLAP) 부하 기반 자동 스케일링에 대한 몇 가지 제한 사항을 확인했습니다. 이 제한 사항은 LLAP 쿼리 역학의 특징, 향후 부하 예측 정확도 문제 및 LLAP 스케줄러의 작업 재배포 문제 때문에 발생합니다. 이러한 제한 사항으로 인해 사용자는 자동 크기 조정이 사용되는 경우 LLAP 클러스터에서 쿼리 실행 속도가 느려지는 것을 알 수 있습니다. 성능에 미치는 영향이 자동 스케일링의 비용 이점보다 클 수 있습니다.
2021년 7월부터 HDInsight의 Interactive Query 워크로드는 일정 기반 자동 스케일링만 지원합니다. 새 Interactive Query 클러스터에서는 더 이상 자동 스케일링을 사용하도록 설정할 수 없습니다. 기존에 실행 중인 클러스터는 위에서 설명된 알려진 제한 사항을 적용하여 계속 실행할 수 있습니다.
LLAP를 위해 일정 기반 자동 스케일링으로 이동하는 것이 좋습니다. Grafana Hive 대시보드를 통해 클러스터의 현재 사용 패턴을 분석할 수 있습니다. 자세한 내용은 Azure HDInsight 클러스터 자동 크기 조정을 참조하세요.
OS 버전 업그레이드
HDInsight 클러스터는 현재 Ubuntu 16.04 LTS에서 실행되고 있습니다. Ubuntu의 릴리스 주기에서 언급된 대로 Ubuntu 16.04 커널은 2021년 4월에 EOL(수명 종료)에 도달합니다. 2021년 5월에 Ubuntu 18.04에서 실행되는 새 HDInsight 4.0 클러스터 이미지 출시를 시작합니다. 새로 만든 HDInsight 4.0 클러스터는 제공된 후 기본적으로 Ubuntu 18.04에서 실행됩니다. Ubuntu 16.04의 기존 클러스터는 완벽한 지원과 함께 있는 그대로 실행됩니다.
HDInsight 3.6은 Ubuntu 16.04에서 계속 실행됩니다. 2021년 6월 30일까지 표준 지원이 종료되고 2021년 7월 1일부터 기본 지원으로 변경됩니다. 날짜 및 지원 옵션에 대한 자세한 내용은 Azure HDInsight 버전을 참조하세요. HDInsight 3.6에서는 Ubuntu 18.04가 지원되지 않습니다. Ubuntu 18.04를 사용하려면 클러스터를 HDInsight 4.0으로 마이그레이션해야 합니다.
기존 클러스터를 Ubuntu 18.04로 이동하려면 클러스터를 삭제하고 다시 만들어야 합니다. Ubuntu 18.04 지원이 제공된 후 클러스터를 만들거나 다시 만들 계획을 세웁니다. 새 이미지가 모든 지역에서 사용할 수 있게 되면 또 다른 알림을 보냅니다.
HDInsight 클러스터 헤드 노드는 클러스터 초기화 및 관리를 처리합니다. Standard_A5 VM 크기는 HDInsight 4.0의 헤드 노드로서 안정성 문제가 있습니다. 2021년 5월의 다음 릴리스부터, 고객은 Standard_A5 VM 크기를 헤드 노드로 사용하여 새 클러스터를 만들 수 없습니다. E2_v3 또는 E2s_v3 같은 다른 2코어 VM을 사용할 수 있습니다. 기존 클러스터는 계속 운영됩니다. 프로덕션 HDInsight 클러스터의 고가용성 및 안정성을 보장하기 위해 헤드 노드에는 4코어 VM을 사용하는 것이 좋습니다.
버그 수정
HDInsight는 계속해서 클러스터 안정성과 성능을 향상시킵니다.
구성 요소 버전 변경
Spark 3.0.0 및 Kafka 2.4.1에 대한 지원이 미리 보기로 추가되었습니다.
이 문서에서 HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 찾을 수 있습니다.
릴리스 날짜: 02/05/2021
이 릴리스는 HDInsight 3.6 및 4.0 모두에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
새로운 기능
Dav4 시리즈 지원
HDInsight는 이 릴리스에서 Dav4 시리즈 지원 기능을 추가했습니다. Dav4 시리즈에 대한 자세한 정보는 여기에서 알아봅니다.
Kafka REST 프록시 GA
Kafka REST 프록시를 사용하면 HTTPS를 통한 REST API를 통해 Kafka 클러스터와 상호 작용할 수 있습니다. 이번 릴리스부터는 Kafka REST 프록시가 일반적으로 사용 가능합니다. Kafka REST 프록시에 대한 자세한 정보는 여기에서 자세히 알아봅니다.
Azure Virtual Machine Scale Sets로 전환
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 이 서비스는 Azure Virtual Machine Scale Sets로 점진적으로 마이그레이션됩니다. 전체 프로세스는 몇 개월이 소요될 수 있습니다. 지역 및 구독이 마이그레이션된 후에는 새로 생성된 HDInsight 클러스터가 고객의 작업 없이도 Virtual Machine Scale Sets에서 실행됩니다. 호환성이 손상되는 변경 사항은 없을 것으로 예상됩니다.
감가 상각
사용하지 않는 VM 크기
2021년 1월 9일부터 HDInsight는 standard_A8, standard_A9, standard_A10 및 standard_A11 VM 크기를 사용하여 클러스터를 만드는 모든 고객을 차단합니다. 기존 클러스터는 계속 운영됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 HDInsight 4.0으로 전환하는 것이 좋습니다.
동작 변경
기본 클러스터 VM 크기가 Ev3 시리즈로 변경됩니다
기본 클러스터 VM 크기가 D 시리즈에서 Ev3 시리즈로 변경됩니다. 이 변경 내용은 헤드 노드와 작업자 노드에 적용됩니다. 이러한 변경 내용이 테스트된 워크플로에 영향을 주지 않도록 하려면 ARM 템플릿에서 사용할 VM 크기를 지정합니다.
Azure Virtual Machine Scale Sets에서 실행되는 클러스터에 대한 네트워크 인터페이스 리소스가 표시되지 않음
HDInsight는 Azure Virtual Machine Scale Sets로 점진적으로 마이그레이션되고 있습니다. 가상 머신의 네트워크 인터페이스는 Azure Virtual Machine Scale Sets를 사용하는 클러스터의 고객에게는 더 이상 표시되지 않습니다.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
기본 클러스터 버전이 4.0으로 변경됩니다
2021년 2월부터 HDInsight 클러스터의 기본 버전이 3.6에서 4.0으로 변경됩니다. 사용 가능한 버전에 관한 자세한 내용은 사용 가능한 버전을 참조하세요. HDInsight 4.0의 새로운 기능에 관해 자세히 알아보세요.
OS 버전 업그레이드
HDInsight는 Ubuntu 16.04에서 18.04로 OS 버전을 업그레이드하고 있습니다. 업그레이드는 2021년 4월 이전에 완료됩니다.
2021년 6월 30일자로 HDInsight 3.6 지원 종료
HDInsight 3.6은 지원이 종료될 예정입니다. 2021년 6월 30일부터 고객은 새로운 HDInsight 3.6 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 HDInsight 4.0으로 전환하는 것이 좋습니다.
구성 요소 버전 변경
이 릴리스에 대한 구성 요소 버전이 변경되지 않았습니다. 이 문서에서 HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 찾을 수 있습니다.
릴리스 날짜: 11/18/2020
이 릴리스는 HDInsight 3.6 및 4.0 모두에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
새로운 기능
휴지 상태의 고객 관리형 키 암호화를 위한 자동 키 회전
이 릴리스부터 고객은 미사용 고객 관리형 키 암호화에 Azure KeyVault 버전 없는 암호화 키 URL을 사용할 수 있습니다. HDInsight는 키가 만료되거나 새 버전으로 바뀔 때 자동으로 키를 회전시킵니다. 자세한 내용은 여기를 참조하세요.
Spark, Hadoop 및 ML 서비스에 대한 다양한 Zookeeper 가상 머신 크기를 선택하는 기능
이전에 HDInsight는 Spark, Hadoop 및 ML 서비스 클러스터 유형에 대한 Zookeeper 노드 크기 사용자 지정을 지원하지 않았습니다. 기본적으로 A2_v2/A2 가상 머신 크기가 무료로 제공됩니다. 이 릴리스부터는 시나리오에 가장 적합한 Zookeeper 가상 머신 크기를 선택할 수 있습니다. A2_v2/A2 이외의 가상 머신 크기를 포함하는 Zookeeper 노드에는 요금이 부과됩니다. A2_v2 및 A2 가상 머신은 계속 무료로 제공됩니다.
Azure Virtual Machine Scale Sets로 전환
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 이 릴리스부터 서비스는 Azure Virtual Machine Scale Sets로 점진적으로 마이그레이션됩니다. 전체 프로세스는 몇 개월이 소요될 수 있습니다. 지역 및 구독이 마이그레이션된 후에는 새로 생성된 HDInsight 클러스터가 고객의 작업 없이도 Virtual Machine Scale Sets에서 실행됩니다. 호환성이 손상되는 변경 사항은 없을 것으로 예상됩니다.
감가 상각
HDInsight 3.6 ML 서비스 클러스터의 사용 중단
HDInsight 3.6 ML 서비스 클러스터 유형은 2020년 12월 31일부터 지원이 종료됩니다. 고객은 2020년 12월 31일 이후 새로운 3.6 ML 서비스 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 여기에서 HDInsight 버전 및 클러스터 유형 지원 만료를 확인하세요.
사용하지 않는 VM 크기
2020년 11월 16일부터 HDInsight는 standard_A8, standard_A9, standard_A10 및 standard_A11 VM 크기를 사용하여 클러스터를 만드는 새 고객을 차단합니다. 지난 3개월 동안 이러한 VM 크기를 사용한 기존 고객에게는 영향이 없습니다. 2021년 1월 9일부터 HDInsight는 standard_A8, standard_A9, standard_A10 및 standard_A11 VM 크기를 사용하여 클러스터를 만드는 모든 고객을 차단합니다. 기존 클러스터는 계속 운영됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 HDInsight 4.0으로 전환하는 것이 좋습니다.
동작 변경
크기 조정 작업 전에 NSG 규칙 검사 추가
HDInsight는 크기 조정 작업을 통해 NSG(네트워크 보안 그룹) 및 UDR(사용자 정의 경로) 검사를 추가했습니다. 클러스터 만들기뿐만 아니라 클러스터 크기 조정을 위해서도 동일한 유효성 검사가 수행됩니다. 이 유효성 검사는 예기치 않은 오류를 방지하는 데 유용합니다. 유효성 검사를 통과하지 못하면 크기 조정이 실패합니다. NSG 및 UDR을 올바르게 구성하는 방법에 대한 자세한 내용은 HDInsight 관리 IP 주소를 참조하세요.
구성 요소 버전 변경
이 릴리스에 대한 구성 요소 버전이 변경되지 않았습니다. 이 문서에서 HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 찾을 수 있습니다.
릴리스 날짜: 11/09/2020
이 릴리스는 HDInsight 3.6 및 4.0 모두에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
새로운 기능
HIB(HDInsight Identity Broker)는 이제 GA입니다
이 릴리스로 ESP 클러스터에 대한 OAuth 인증을 사용하는 HIB(HDInsight Identity Broker)가 이제 일반적으로 공급됩니다. 이 릴리스 이후에 생성되는 모든 HIB 클러스터는 최신 HIB의 기능을 제공합니다.
HA(고가용성)
MFA(Multi-Factor Authentication) 지원
페더레이션 사용자는 AAD-DS에 대한 암호 해시 동기화를 사용하지 않고 로그인합니다. 자세한 내용은 HIB 설명서를 참조하세요.
Azure Virtual Machine Scale Sets로 전환
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 이 릴리스부터 서비스는 Azure Virtual Machine Scale Sets로 점진적으로 마이그레이션됩니다. 전체 프로세스는 몇 개월이 소요될 수 있습니다. 지역 및 구독이 마이그레이션된 후에는 새로 생성된 HDInsight 클러스터가 고객의 작업 없이도 Virtual Machine Scale Sets에서 실행됩니다. 호환성이 손상되는 변경 사항은 없을 것으로 예상됩니다.
감가 상각
HDInsight 3.6 ML 서비스 클러스터의 사용 중단
HDInsight 3.6 ML 서비스 클러스터 유형은 2020년 12월 31일부터 지원이 종료됩니다. 고객은 2020년 12월 31일 이후 새로운 3.6 ML 서비스 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 여기에서 HDInsight 버전 및 클러스터 유형 지원 만료를 확인하세요.
사용하지 않는 VM 크기
2020년 11월 16일부터 HDInsight는 standard_A8, standard_A9, standard_A10 및 standard_A11 VM 크기를 사용하여 클러스터를 만드는 새 고객을 차단합니다. 지난 3개월 동안 이러한 VM 크기를 사용한 기존 고객에게는 영향이 없습니다. 2021년 1월 9일부터 HDInsight는 standard_A8, standard_A9, standard_A10 및 standard_A11 VM 크기를 사용하여 클러스터를 만드는 모든 고객을 차단합니다. 기존 클러스터는 계속 운영됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 HDInsight 4.0으로 전환하는 것이 좋습니다.
동작 변경
이 릴리스에 동작 변경은 없습니다.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
Spark, Hadoop 및 ML 서비스에 대한 다양한 Zookeeper 가상 머신 크기를 선택하는 기능
현재 HDInsight는 Spark, Hadoop 및 ML 서비스 클러스터 유형에 대한 Zookeeper 노드 크기 사용자 지정을 지원하지 않습니다. 기본적으로 A2_v2/A2 가상 머신 크기가 무료로 제공됩니다. 향후 릴리스에서는 시나리오에 가장 적합한 Zookeeper 가상 머신 크기를 선택할 수 있습니다. A2_v2/A2 이외의 가상 머신 크기를 포함하는 Zookeeper 노드에는 요금이 부과됩니다. A2_v2 및 A2 가상 머신은 계속 무료로 제공됩니다.
기본 클러스터 버전이 4.0으로 변경됩니다
2021년 2월부터 HDInsight 클러스터의 기본 버전이 3.6에서 4.0으로 변경됩니다. 사용 가능한 버전에 대한 자세한 내용은 지원되는 버전을 참조하세요. HDInsight 4.0의 새로운 기능에 대한 자세한 정보를 알아봅니다
2021년 6월 30일자로 HDInsight 3.6 지원 종료
HDInsight 3.6은 지원이 종료될 예정입니다. 2021년 6월 30일부터 고객은 새로운 HDInsight 3.6 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 HDInsight 4.0으로 전환하는 것이 좋습니다.
이 릴리스에 대한 구성 요소 버전이 변경되지 않았습니다. 이 문서에서 HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 찾을 수 있습니다.
릴리스 날짜: 10/08/2020
이 릴리스는 HDInsight 3.6 및 4.0 모두에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
새로운 기능
공용 IP 및 프라이빗 링크가 없는 HDInsight 개인 클러스터(미리 보기)
이제 HDInsight는 미리 보기에서 클러스터에 대한 공용 IP 및 프라이빗 링크 액세스 권한이 없는 클러스터 만들기를 지원합니다. 고객은 새로운 고급 네트워킹 설정을 사용하여 공용 IP가 없는 완전히 격리된 클러스터를 만들고 자신의 프라이빗 엔드포인트를 사용하여 클러스터에 액세스할 수 있습니다.
Azure Virtual Machine Scale Sets로 전환
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 이 릴리스부터 서비스는 Azure Virtual Machine Scale Sets로 점진적으로 마이그레이션됩니다. 전체 프로세스는 몇 개월이 소요될 수 있습니다. 지역 및 구독이 마이그레이션된 후에는 새로 생성된 HDInsight 클러스터가 고객의 작업 없이도 Virtual Machine Scale Sets에서 실행됩니다. 호환성이 손상되는 변경 사항은 없을 것으로 예상됩니다.
감가 상각
HDInsight 3.6 ML 서비스 클러스터의 사용 중단
HDInsight 3.6 ML 서비스 클러스터 유형은 2020년 12월 31일부터 지원이 중단됩니다. 그 이후부터 고객은 새로운 3.6 ML 서비스 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 여기에서 HDInsight 버전 및 클러스터 유형 지원 만료를 확인하세요.
동작 변경
이 릴리스에 동작 변경은 없습니다.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
Spark, Hadoop 및 ML 서비스에 대한 다양한 Zookeeper 가상 머신 크기를 선택하는 기능
현재 HDInsight는 Spark, Hadoop 및 ML 서비스 클러스터 유형에 대한 Zookeeper 노드 크기 사용자 지정을 지원하지 않습니다. 기본적으로 A2_v2/A2 가상 머신 크기가 무료로 제공됩니다. 향후 릴리스에서는 시나리오에 가장 적합한 Zookeeper 가상 머신 크기를 선택할 수 있습니다. A2_v2/A2 이외의 가상 머신 크기를 포함하는 Zookeeper 노드에는 요금이 부과됩니다. A2_v2 및 A2 가상 머신은 계속 무료로 제공됩니다.
버그 수정
HDInsight는 계속해서 클러스터 안정성과 성능을 향상시킵니다.
구성 요소 버전 변경
이 릴리스에 대한 구성 요소 버전이 변경되지 않았습니다. 이 문서에서 HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 찾을 수 있습니다.
릴리스 날짜: 09/28/2020
이 릴리스는 HDInsight 3.6 및 4.0 모두에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
새로운 기능
HDInsight 4.0을 사용하여 Interactive Query 자동 크기 조정이 이제 일반적으로 사용 가능합니다
Interactive Query 클러스터 유형에 대한 자동 크기 조정 기능은 이제 HDInsight 4.0에 GA(일반 공급)로 제공됩니다. 2020년 8월 27일 이후에 만들어진 모든 Interactive Query 4.0 클러스터에는 자동 크기 조정에 대한 GA 지원이 포함됩니다.
HBase 클러스터는 Premium ADLS Gen2를 지원
이제 HDInsight는 HDInsight HBase 3.6 및 4.0 클러스터에 대한 기본 스토리지 계정으로 Premium ADLS Gen2를 지원합니다. 가속 쓰기로 HBase 클러스터의 더 나은 성능을 얻을 수 있습니다.
Azure 장애 도메인의 Kafka 파티션 배포
장애 도메인은 Azure 데이터 센터에 있는 기본 하드웨어의 논리적 그룹입니다. 장애 도메인마다 공통 전원과 네트워크 스위치를 공유합니다. HDInsight Kafka가 모든 파티션 복제본을 같은 장애 도메인에 저장하기 전에. 이 릴리스부터 이제 HDInsight는 Azure 장애 도메인을 기반으로 Kafka 파티션의 자동 배포를 지원합니다.
전송 중 암호화
고객은 플랫폼 관리형 키로 IPsec 암호화를 사용하여 클러스터 노드 간에 전송 중인 암호화를 사용하도록 설정할 수 있습니다. 이 옵션은 클러스터를 만들 때 사용할 수 있습니다. 전송 중 암호화를 사용하는 방법에 대한 자세한 내용을 참조하세요.
호스트에서 암호화
호스트에서 암호화를 사용하도록 설정하면 VM 호스트에 저장된 데이터는 휴지 상태로 암호화되고 스토리지 서비스에 암호화된 채로 전송됩니다. 이 릴리스부터 클러스터를 만들 때 임시 데이터 디스크의 호스트에서 암호화를 사용할 수 있습니다. 호스트의 암호화는 제한된 지역의 특정 VM SKU에서만 지원됩니다. HDInsight는 다음 노드 구성 및 SKU를 지원합니다. 호스트에서 암호화를 사용하는 방법에 대한 자세한 내용을 참조하세요.
Azure Virtual Machine Scale Sets로 전환
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 이 릴리스부터 서비스는 Azure Virtual Machine Scale Sets로 점진적으로 마이그레이션됩니다. 전체 프로세스는 몇 개월이 소요될 수 있습니다. 지역 및 구독이 마이그레이션된 후에는 새로 생성된 HDInsight 클러스터가 고객의 작업 없이도 Virtual Machine Scale Sets에서 실행됩니다. 호환성이 손상되는 변경 사항은 없을 것으로 예상됩니다.
감가 상각
이 릴리스는 사용 중단되지 않습니다.
동작 변경
이 릴리스에 동작 변경은 없습니다.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
Spark, Hadoop 및 ML 서비스에 대해 다양한 Zookeeper SKU를 선택하는 기능
현재 HDInsight는 Spark, Hadoop 및 ML 서비스 클러스터 유형에 대한 Zookeeper SKU 변경을 지원하지 않습니다. Zookeeper 노드에는 A2_v2/A2 SKU가 사용되고 고객은 이에 관련된 요금은 청구받지 않습니다. 향후 릴리스에서 고객은 필요에 따라 Spark, Hadoop 및 ML 서비스의 Zookeeper SKU를 변경할 수 있습니다. A2_v2/A2가 아닌 SKU를 사용하는 Zookeeper 노드에는 요금이 청구됩니다. 기본 SKU는 A2_V2/A2로 유지되며 무료로 제공됩니다.
버그 수정
HDInsight는 계속해서 클러스터 안정성과 성능을 향상시킵니다.
구성 요소 버전 변경
이 릴리스에 대한 구성 요소 버전이 변경되지 않았습니다. 이 문서에서 HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 찾을 수 있습니다.
릴리스 날짜: 08/09/2020
이 릴리스는 HDInsight 4.0에만 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
새로운 기능
SparkCruise 지원
SparkCruise는 Spark의 자동 계산 재사용 시스템입니다. 이전 쿼리 워크로드를 기준으로 구체화할 공통 하위 식을 선택합니다. SparkCruise는 이러한 하위 식을 쿼리 처리의 일부로 구체화하며 계산 재사용은 백그라운드에서 자동으로 적용됩니다. Spark 코드를 수정하지 않고 SparkCruise의 혜택을 누릴 수 있습니다.
HDInsight 4.0의 Hive View 지원
Apache Ambari Hive View는 웹 브라우저에서 Hive 쿼리를 작성, 최적화 및 실행하는 데 유용하게 설계되었습니다. Hive View는 이 릴리스부터 HDInsight 4.0 클러스터에 기본적으로 지원됩니다. 기존 클러스터에는 적용되지 않습니다. 기본 제공 Hive View를 가져오려면 클러스터를 삭제하고 다시 만들어야 합니다.
HDInsight 4.0의 Tez View 지원
Apache Tez View는 Hive Tez 작업의 실행을 추적하고 디버그하는 데 사용됩니다. Tez VIew는 이 릴리스부터 HDInsight 4.0에 기본적으로 지원됩니다. 기존 클러스터에는 적용되지 않습니다. 기본 제공 Tez View를 가져오려면 클러스터를 삭제하고 다시 만들어야 합니다.
감가 상각
HDInsight 3.6 Spark 클러스터의 Spark 2.1 및 2.2 사용 중단
2020년 7월 1일부터 고객은 HDInsight 3.6에서 Spark 2.1 및 2.2를 사용하여 새로운 Spark 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 3.6의 Spark 2.3으로 전환하는 것이 좋습니다.
HDInsight 4.0 Spark 클러스터의 Spark 2.3 사용 중단
2020년 7월 1일부터 고객은 HDInsight 4.0에서 Spark 2.3을 사용하여 새로운 Spark 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 4.0의 Spark 2.4로 전환하는 것이 좋습니다.
HDInsight 4.0 Kafka 클러스터의 Kafka 1.1 사용 중단
2020년 7월 1일부터 고객은 HDInsight 4.0의 Kafka 1.1을 사용하여 새 Kafka 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 4.0의 Kafka 2.1로 전환하는 것이 좋습니다.
동작 변경
Ambari 스택 버전 변경
이 릴리스에서 Ambari 버전은 2.x.x.x에서 4.1로 변경됩니다. Ambari: Ambari > 사용자 > 버전에서 스택 버전(HDInsight 4.1)을 확인할 수 있습니다.
이 릴리스에 대한 구성 요소 버전이 변경되지 않았습니다. 이 문서에서 HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 찾을 수 있습니다.
알려진 문제
Azure Portal에서 사용자가 SSH 인증 유형의 공개 키를 사용하여 Azure HDInsight 클러스터를 만들 때 오류가 발생하던 문제가 해결되었습니다. 사용자가 검토 + 만들기를 클릭하면 "SSH 사용자 이름에서 연속된 문자 세 개를 포함해서는 안 됩니다" 오류가 표시됩니다. 이 문제는 해결되었지만 수정된 보기를 로드하려면 CTRL + F5를 눌러 브라우저 캐시를 새로 고쳐야 할 수도 있습니다. 이 문제에 대한 해결 방법은 ARM 템플릿을 사용하여 클러스터를 만드는 것이었습니다.
릴리스 날짜: 07/13/2020
이 릴리스는 HDInsight 3.6 및 4.0 둘 다에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
새로운 기능
Microsoft Azure용 고객 Lockbox 지원
Azure HDInsight는 이제 Azure 고객 Lockbox를 지원합니다. 이는 고객 데이터 액세스 요청을 검토하고 승인하거나 거부하기 위한 인터페이스입니다. 지원 요청 시 Microsoft 엔지니어가 고객 데이터에 액세스해야 하는 경우에 사용됩니다. 자세한 내용은 Microsoft Azure용 고객 Lockbox를 참조하세요.
스토리지에 대한 서비스 엔드포인트 정책
이제 고객은 HDInsight 클러스터 서브넷에서 SEP(서비스 엔드포인트 정책)를 사용할 수 있습니다. Azure 서비스 엔드포인트 정책에 대한 자세한 정보를 알아봅니다.
감가 상각
HDInsight 3.6 Spark 클러스터의 Spark 2.1 및 2.2 사용 중단
2020년 7월 1일부터 고객은 HDInsight 3.6에서 Spark 2.1 및 2.2를 사용하여 새로운 Spark 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 3.6의 Spark 2.3으로 전환하는 것이 좋습니다.
HDInsight 4.0 Spark 클러스터의 Spark 2.3 사용 중단
2020년 7월 1일부터 고객은 HDInsight 4.0에서 Spark 2.3을 사용하여 새로운 Spark 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 4.0의 Spark 2.4로 전환하는 것이 좋습니다.
HDInsight 4.0 Kafka 클러스터의 Kafka 1.1 사용 중단
2020년 7월 1일부터 고객은 HDInsight 4.0의 Kafka 1.1을 사용하여 새 Kafka 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 4.0의 Kafka 2.1로 전환하는 것이 좋습니다.
동작 변경
주의해야 하는 동작 변경은 없습니다.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
Spark, Hadoop 및 ML 서비스에 대해 다양한 Zookeeper SKU를 선택하는 기능
현재 HDInsight는 Spark, Hadoop 및 ML 서비스 클러스터 유형에 대한 Zookeeper SKU 변경을 지원하지 않습니다. Zookeeper 노드에는 A2_v2/A2 SKU가 사용되고 고객은 이에 관련된 요금은 청구받지 않습니다. 향후 릴리스에서 고객은 필요에 따라 Spark, Hadoop 및 ML 서비스의 Zookeeper SKU를 변경할 수 있습니다. A2_v2/A2가 아닌 SKU를 사용하는 Zookeeper 노드에는 요금이 청구됩니다. 기본 SKU는 A2_V2/A2로 유지되며 무료로 제공됩니다.
버그 수정
HDInsight는 계속해서 클러스터 안정성과 성능을 향상시킵니다.
Hive Warehouse Connector 문제를 해결했습니다
이전 릴리스에는 Hive Warehouse Connector 유용성에 문제가 있었습니다. 이 문제가 해결되었습니다.
Zeppelin Notebook이 선행 0을 잘라 버리는 문제를 해결
Zeppelin이 문자열 형식의 테이블 출력에서 선행 0을 잘못 자르는 문제가 있었습니다. 이 릴리스에서는 이 문제가 해결되었습니다.
구성 요소 버전 변경
이 릴리스에 대한 구성 요소 버전이 변경되지 않았습니다. 이 문서에서 HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 찾을 수 있습니다.
릴리스 날짜: 06/11/2020
이 릴리스는 HDInsight 3.6 및 4.0 둘 다에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
새로운 기능
Azure Virtual Machine Scale Sets로 전환
이제 HDInsight는 Azure 가상 머신을 사용하여 클러스터를 프로비저닝합니다. 이 릴리스부터, 새로 만든 HDInsight 클러스터는 Azure Virtual Machine Scale Sets를 사용합니다. 변경 내용은 점진적으로 롤아웃됩니다. 호환성이 손상되는 변경 내용은 없을 것으로 예상됩니다. Azure Virtual Machine Scale Sets에 대한 자세한 정보를 알아봅니다.
HDInsight 클러스터에서 VM 재부팅
이 릴리스에서는 응답이 없는 노드를 재부팅하기 위해 HDInsight 클러스터의 VM을 재부팅하는 기능을 지원합니다. 현재는 API를 통해서만 이 작업을 수행할 수 있으며, PowerShell 및 CLI 지원은 추가하는 중입니다. API에 대한 자세한 내용은 이 문서를 참조하세요.
감가 상각
HDInsight 3.6 Spark 클러스터의 Spark 2.1 및 2.2 사용 중단
2020년 7월 1일부터 고객은 HDInsight 3.6에서 Spark 2.1 및 2.2를 사용하여 새로운 Spark 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 3.6의 Spark 2.3으로 전환하는 것이 좋습니다.
HDInsight 4.0 Spark 클러스터의 Spark 2.3 사용 중단
2020년 7월 1일부터 고객은 HDInsight 4.0에서 Spark 2.3을 사용하여 새로운 Spark 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 4.0의 Spark 2.4로 전환하는 것이 좋습니다.
HDInsight 4.0 Kafka 클러스터의 Kafka 1.1 사용 중단
2020년 7월 1일부터 고객은 HDInsight 4.0의 Kafka 1.1을 사용하여 새 Kafka 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 4.0의 Kafka 2.1로 전환하는 것이 좋습니다.
동작 변경
ESP Spark 클러스터 헤드 노드 크기 변경
ESP Spark 클러스터에 허용되는 최소 헤드 노드 크기가 Standard_D13_V2로 변경됩니다.
코어 수가 낮거나 메모리를 헤드 노드로 사용하는 VM은 CPU와 메모리 용량이 상대적으로 적기 때문에 ESP 클러스터 문제를 일으킬 수 있습니다. 이 릴리스부터는 Standard_D13_V2 보다 높은 SKU를 사용하고 Standard_E16_V3를 ESP Spark 클러스터의 헤드 노드로 합니다.
헤드 노드에는 최소 4코어 VM이 필요합니다.
HDInsight 클러스터의 고가용성 및 안정성을 보장하기 위해 헤드 노드에는 최소 4코어 VM이 필요합니다. 2020년 4월 6일부터 고객은 새 HDInsight 클러스터에 대한 헤드 노드로 4코어 이상의 VM만 선택할 수 있습니다. 기존 클러스터는 계속해서 예상대로 실행됩니다.
클러스터 작업자 노드 프로비저닝 변경
작업자 노드의 80%가 준비되면 클러스터가 작동 단계에 들어갑니다. 이 단계에서 고객은 스크립트 및 작업 실행과 같은 모든 데이터 평면 작업을 수행할 수 있습니다. 하지만 고객은 규모 확장/축소와 같은 컨트롤 플레인 작업을 수행할 수는 없습니다. 오직 삭제만 지원됩니다.
작동 단계 이후 클러스터는 남은 20%의 작업자 노드를 다시 60분 동안 기다립니다. 이 60분이 끝나면 모든 작업자 노드를 아직 사용할 수 없더라도 클러스터가 실행 단계로 전환됩니다. 클러스터가 실행 단계로 들어가면 정상적으로 사용할 수 있습니다. 규모 확장/축소와 같은 제어 계획 작업과 스크립트 및 작업 실행과 같은 데이터 계획 작업이 모두 허용됩니다. 요청된 작업자 노드 중 일부를 사용할 수 없는 경우 클러스터가 부분 성공으로 표시됩니다. 성공적으로 배포된 노드에 대한 요금이 청구됩니다.
HDInsight를 통해 새 서비스 주체 만들기
이전에는 클러스터를 만들 때 고객이 Azure Portal의 연결된 ADLS Gen 1 계정에 액세스하는 새 서비스 주체를 만들 수 있었습니다. 2020년 6월 15일부터 HDInsight 만들기 워크플로에 새 서비스 주체를 만들 수 없으며 기존 서비스 주체만 지원됩니다. Azure Active Directory를 사용하여 서비스 주체 및 인증서 만들기를 참조하세요.
클러스터를 만들기를 이용한 스크립트 작업 시간 초과
HDInsight는 클러스터 만들기를 이용한 스크립트 작업 실행을 지원합니다. 이 릴리스부터 클러스터 만들기를 이용한 모든 스크립트 작업은 60분 이내에 완료되어야 하며 그렇지 않으면 시간 제한이 초과됩니다. 실행 중인 클러스터에 제출된 스크립트 작업에는 영향을 주지 않습니다. 자세한 내용은 여기를 참조하세요.
예정된 변경
주의해야 할 호환성이 손상되는 변경 사항은 없습니다.
버그 수정
HDInsight는 계속해서 클러스터 안정성과 성능을 향상시킵니다.
구성 요소 버전 변경
HBase 2.0-2.1.6
HBase 버전이 2.0에서 2.1.6으로 업그레이드되었습니다.
Spark 2.4.0-2.4.4
Spark 버전이 2.4.0에서 2.4.4로 업그레이드되었습니다.
Kafka 2.1.0-2.1.1
Kafka 버전이 2.1.0에서 2.1.1로 업그레이드되었습니다.
이 문서에서 HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 찾을 수 있습니다
알려진 문제
Hive Warehouse Connector 문제
이 릴리스에는 Hive Warehouse Connector에 문제가 있습니다. 다음 릴리스에서 수정될 예정입니다. 이 릴리스 이전에 만든 기존 클러스터는 영향을 받지 않습니다. 가능하면 클러스터를 삭제하고 다시 만들지 마세요. 이에 대한 추가 도움이 필요한 경우 지원 티켓을 엽니다.
릴리스 날짜: 2020/09/01
이 릴리스는 HDInsight 3.6 및 4.0 둘 다에 적용됩니다. HDInsight 릴리스는 며칠 동안의 준비 작업을 거쳐 모든 지역에서 사용할 수 있게 됩니다. 여기에 나오는 릴리스 날짜는 첫 번째 지역 릴리스 날짜를 나타냅니다. 아래의 변경 내용이 표시되지 않으면 며칠 후에 해당 지역에서 릴리스가 라이브될 때까지 기다려주세요.
새로운 기능
TLS 1.2 적용
TLS(전송 계층 보안) 및 SSL(Secure Sockets Layer)은 컴퓨터 네트워크를 통해 통신 보안을 제공하는 암호화 프로토콜입니다. TLS에 대해 자세히 알아봅니다. HDInsight는 퍼블릭 HTTP의 엔드포인트에서 TLS 1.2를 사용하지만 TLS 1.1은 이전 버전과의 호환성을 위해 계속 지원됩니다.
이 릴리스에서 고객은 퍼블릭 클러스터 엔드포인트를 통한 모든 연결에 대해서만 TLS 1.2를 옵트인(opt in)할 수 있습니다. 이를 지원하기 위해 새 속성 minSupportedTlsVersion이 도입되었으며 클러스터를 만드는 동안 이 속성을 지정할 수 있습니다. 이 속성을 설정하지 않으면 클러스터는 현재 동작처럼 TLS 1.0, 1.1 및 1.2를 계속 지원합니다. 고객은 이 속성의 값을 "1.2"로 설정할 수 있습니다. 이렇게 하면 클러스터는 TLS 1.2 이상만 지원합니다. 자세한 내용은 전송 계층 보안을 참조하세요.
디스크 암호화를 위한 사용자 고유 키 가져오기
HDInsight의 모든 관리 디스크는 Azure SSE(스토리지 서비스 암호화)로 보호됩니다. 기본적으로 해당 디스크의 데이터는 Microsoft 관리 키를 사용하여 암호화됩니다. 이 릴리스부터는 디스크 암호화에 대해 BYOK(Bring Your Own Key)를 수행하고 Azure Key Vault를 사용하여 관리할 수 있습니다. BYOK 암호화는 다른 비용 없이 클러스터를 만드는 동안 진행되는 1단계 구성입니다. Azure Key Vault를 통해 HDInsight를 관리 ID로 등록하고 클러스터를 만들 때 암호화 키를 추가합니다. 자세한 내용은 고객 관리형 키 디스크 암호화를 참조하세요.
감가 상각
이 릴리스의 사용 중단은 없습니다. 예정된 사용 중단을 대비하려면 예정된 변경을 참조하세요.
동작 변경
이 릴리스에 대한 동작 변경은 없습니다. 예정된 변경을 대비하려면 예정된 변경을 참조하세요.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
HDInsight 3.6 Spark 클러스터의 Spark 2.1 및 2.2 사용 중단
2020년 7월 1일부터 고객은 HDInsight 3.6의 Spark 2.1 및 2.2를 사용하여 새 Spark 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 3.6의 Spark 2.3으로 전환하는 것이 좋습니다.
HDInsight 4.0 Spark 클러스터의 Spark 2.3 사용 중단
2020년 7월 1일부터 고객은 HDInsight 4.0의 Spark 2.3을 사용하여 새 Spark 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 4.0의 Spark 2.4로 전환하는 것이 좋습니다.
HDInsight 4.0 Kafka 클러스터의 Kafka 1.1 사용 중단
2020년 7월 1일부터 고객은 HDInsight 4.0의 Kafka 1.1을 사용하여 새로운 Kafka 클러스터를 만들 수 없습니다. 기존 클러스터는 Microsoft의 지원 없이 있는 그대로 실행됩니다. 잠재적인 시스템/지원 중단을 방지하기 위해 2020년 6월 30일까지 HDInsight 4.0의 Kafka 2.1로 전환하는 것이 좋습니다. 자세한 내용은 Azure HDInsight 4.0으로 Apache Kafka 워크로드 마이그레이션을 참조하세요.
HBase 2.0-2.1.6
예정된 HDInsight 4.0 릴리스에서 HBase 버전은 버전 2.0에서 2.1.6로 업그레이드됩니다.
Spark 2.4.0-2.4.4
예정된 HDInsight 4.0 릴리스에서 Spark 버전은 버전 2.4.0에서 2.4.4로 업그레이드됩니다.
Kafka 2.1.0-2.1.1
예정된 HDInsight 4.0 릴리스에서 Kafka 버전은 버전 2.1.0에서 2.1.1로 업그레이드됩니다.
헤드 노드에는 최소 4코어 VM이 필요합니다.
HDInsight 클러스터의 고가용성 및 안정성을 보장하기 위해 헤드 노드에는 최소 4코어 VM이 필요합니다. 2020년 4월 6일부터 고객은 새 HDInsight 클러스터에 대한 헤드 노드로 4코어 이상의 VM만 선택할 수 있습니다. 기존 클러스터는 계속해서 예상대로 실행됩니다.
ESP Spark 클러스터 노드 크기 변경
예정된 릴리스에서 ESP Spark 클러스터에 허용되는 최소 노드 크기가 Standard_D13_V2로 변경됩니다.
A 시리즈 VM은 비교적 낮은 CPU와 메모리 용량 때문에 ESP 클러스터 이슈를 유발할 수 있습니다. A 시리즈 VM은 새 ESP 클러스터를 만드는 데 사용되지 않습니다.
Azure Virtual Machine Scale Sets로 전환
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 예정된 릴리스에서 HDInsight는 Azure Virtual Machine Scale Sets를 대신 사용합니다. Azure Virtual Machine Scale Sets에 대한 자세한 정보를 알아봅니다.
버그 수정
HDInsight는 계속해서 클러스터 안정성과 성능을 향상시킵니다.
구성 요소 버전 변경
이 릴리스에 대한 구성 요소 버전이 변경되지 않았습니다. HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 여기에서 찾을 수 있습니다.
릴리스 날짜: 12/17/2019
이 릴리스는 HDInsight 3.6 및 4.0 둘 다에 적용됩니다.
새로운 기능
서비스 태그
서비스 태그는 Azure 서비스에 대한 네트워크 액세스를 쉽게 제한하도록 하여 Azure 가상 머신 및 Azure 가상 네트워크에 대한 보안을 간소화합니다. NSG(네트워크 보안 그룹) 규칙에서 서비스 태그를 사용하여 전역적으로 또는 Azure 지역에 따라 특정 Azure 서비스에 대한 트래픽을 허용하거나 거부할 수 있습니다. Azure는 각 태그를 기반으로 하는 IP 주소의 유지 관리를 제공합니다. NSG(네트워크 보안 그룹)의 HDInsight 서비스 태그는 상태 및 관리 서비스에 대한 IP 주소 그룹입니다. 이러한 그룹은 보안 규칙 만들기의 복잡성을 최소화하는 데 유용합니다. HDInsight 고객은 Azure Portal, PowerShell, REST API를 통해 서비스 태그를 사용할 수 있습니다. 자세한 내용은 Azure HDInsight용 NSG(네트워크 보안 그룹) 서비스 태그를 참조하세요.
사용자 지정 Ambari DB
이제 HDInsight를 사용하여 Apache Ambari에 고유 SQL DB를 사용할 수 있습니다. 이 사용자 지정 Ambari DB는 Azure Portal 또는 Resource Manager 템플릿을 통해 구성할 수 있습니다. 이 기능을 사용하여 처리 및 용량 요구 사항에 적합한 SQL DB를 선택할 수 있습니다. 비즈니스 성장 요구 사항에 맞게 간단히 업그레이드할 수도 있습니다. 자세한 내용은 사용자 지정 Ambari DB를 사용하여 HDInsight 클러스터 설정을 참조하세요.
감가 상각
이 릴리스의 사용 중단은 없습니다. 예정된 사용 중단을 대비하려면 예정된 변경을 참조하세요.
동작 변경
이 릴리스에 대한 동작 변경은 없습니다. 예정된 동작 변경에 대비하려면 예정된 변경을 참조하세요.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
TLS(전송 계층 보안) 1.2 적용
TLS(전송 계층 보안) 및 SSL(Secure Sockets Layer)은 컴퓨터 네트워크를 통해 통신 보안을 제공하는 암호화 프로토콜입니다. 자세한 내용은 전송 계층 보안을 참조하세요. Azure HDInsight 클러스터는 공용 HTTPS 엔드포인트에서 TLS 1.2 연결을 허용하지만, 구 클라이언트와의 호환성을 위해 TLS 1.1은 계속 지원됩니다.
다음 릴리스부터 TLS 1.2 연결만 수락하도록 새 HDInsight 클러스터를 옵트인하고 구성할 수 있습니다.
이후 6/30/2020부터 Azure HDInsight는 모든 HTTPS 연결에 TLS 1.2 또는 그 이상 버전을 적용합니다. 모든 클라이언트가 TLS 1.2 이상 버전을 처리할 수 있도록 대비하는 것이 좋습니다.
Azure Virtual Machine Scale Sets로 전환
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 2020년 2월(정확한 날짜는 나중에 전달 예정)부터 HDInsight는 Azure Virtual Machine Scale Sets를 대신 사용합니다. Azure Virtual Machine Scale Sets에 대한 자세한 정보를 알아봅니다.
ESP Spark 클러스터 노드 크기 변경
예정된 릴리스에서는 다음을 수행합니다.
ESP Spark 클러스터에 허용되는 최소 노드 크기가 Standard_D13_V2로 변경됩니다.
A 시리즈 VM은 CPU와 메모리 용량이 상대적으로 부족해서 ESP 클러스터 문제를 일으킬 수 있으므로 새 ESP 클러스터를 만드는 데 사용되지 않습니다.
HBase 2.0에서 2.1로
예정된 HDInsight 4.0 릴리스에서 HBase 버전은 버전 2.0에서 2.1로 업그레이드됩니다.
버그 수정
HDInsight는 계속해서 클러스터 안정성과 성능을 향상시킵니다.
구성 요소 버전 변경
HDInsight 3.6 지원이 2020년 12월 31일까지 연장되었습니다. 자세한 내용은 지원되는 HDInsight 버전에서 확인할 수 있습니다.
HIB(HDInsight Identity Broker)를 사용하면 사용자가 MFA(다단계 인증)를 사용하여 Apache Ambari에 로그인하고 AAD-DS(Azure Active Directory Domain Services)에서 암호 해시 없이도 필요한 Kerberos 티켓을 가져올 수 있습니다. 현재 HIB는 ARM(Azure Resource Management) 템플릿을 통해 배포된 클러스터에만 사용할 수 있습니다.
Kafka REST API 프록시(미리 보기)
Kafka REST API 프록시는 보호되는 Azure AD 권한 부여 및 OAuth 프로토콜을 통해 Kafka 클러스터와 함께 고가용성 REST 프록시의 원클릭 배포 기능을 제공합니다.
자동 크기 조정
Azure HDInsight의 자동 크기 조정은 이제 Apache Spark 및 Hadoop 클러스터 유형의 모든 지역에서 일반 공급됩니다. 이 기능을 사용하면 보다 비용 효율적이고 생산적인 방식으로 빅 데이터 분석 워크로드를 관리할 수 있습니다. 이제 HDInsight 클러스터 사용을 최적화하고 필요한 만큼만 비용을 지불할 수 있습니다.
원하는 대로 부하 기반 및 일정 기반 자동 크기 조정 중에서 선택할 수 있습니다. 부하 기반 자동 크기 조정은 현재 리소스 요구에 따라 클러스터 크기를 확장 및 축소 스케일링할 수 있는 반면 일정 기반 자동 크기 조정에서는 미리 정의된 일정에 따라 클러스터 크기를 변경할 수 있습니다.
이제 HDInsight는 고객이 자신의 Ambari용 SQL DB를 사용하도록 새 용량을 제공합니다. 이제 고객은 Ambari에 적합한 SQL DB를 선택하고, 고유한 비즈니스 성장 요구 사항에 따라 간편하게 업그레이드할 수 있습니다. 배포에는 Azure Resource Manager 템플릿을 사용합니다. 자세한 내용은 사용자 지정 Ambari DB를 사용하여 HDInsight 클러스터 설정을 참조하세요.
이제 HDInsight로 F 시리즈 가상 머신을 사용할 수 있습니다
F 시리즈 VM(가상 머신)은 가벼운 처리 요구 사항으로 HDInsight를 시작하는 데 적합합니다. 시간당 가격이 더 낮은 F 시리즈는 vCPU당 ACU(Azure 컴퓨팅 단위)를 기준으로 하는 Azure 포트폴리오에서 가격 대비 성능이 가장 좋습니다. 자세한 내용은 Azure HDInsight 클러스터에 적합한 VM 크기 선택을 참조하세요.
감가 상각
G 시리즈 가상 머신 사용 중단
이 릴리스부터 G 시리즈 VM은 더 이상 HDInsight에서 제공되지 않습니다.
Dv1 가상 머신 사용 중단
이 릴리스부터 HDInsight에서 Dv1 VM 사용이 중단됩니다. Dv1에 대한 고객 요청은 자동으로 Dv2(으)로 제공됩니다. Dv1및 Dv2 VM 사이에는 가격 차이가 없습니다.
동작 변경
클러스터 관리 디스크 크기 변경
HDInsight는 클러스터에 관리 디스크 공간을 제공합니다. 이 릴리스부터는 새로 만든 클러스터의 각 노드에 대한 관리 디스크 크기가 128GB로 변경되었습니다.
예정된 변경
이후 릴리스에서는 다음과 같은 변경이 수행됩니다.
Azure Virtual Machine Scale Sets로 전환
이제 HDInsight는 Azure Virtual Machines를 사용하여 클러스터를 프로비저닝합니다. 12월부터 HDInsight는 Azure Virtual Machine Scale Sets를 대신 사용합니다. Azure Virtual Machine Scale Sets에 대한 자세한 정보를 알아봅니다.
HBase 2.0에서 2.1로
예정된 HDInsight 4.0 릴리스에서 HBase 버전은 버전 2.0에서 2.1로 업그레이드됩니다.
A 시리즈 가상 머신의 ESP 클러스터 사용 중단
A 시리즈 VM은 비교적 낮은 CPU와 메모리 용량으로 인해 ESP 클러스터 문제를 일으킬 수 있습니다. 향후 릴리스에서 A 시리즈 VM은 새 ESP 클러스터를 만드는 데 사용되지 않습니다.
버그 수정
HDInsight는 계속해서 클러스터 안정성과 성능을 향상시킵니다.
구성 요소 버전 변경
이 릴리스에 대한 구성 요소 버전이 변경되지 않았습니다. HDInsight 4.0 및 HDInsight 3.6의 최신 구성 요소 버전을 여기에서 찾을 수 있습니다.
릴리스 날짜: 08/07/2019
구성 요소 버전
모든 HDInsight 4.0 구성 요소의 공식 Apache 버전은 다음과 같습니다. 나열된 구성 요소는 사용 가능한 가장 최신의 안정적인 버전의 릴리스입니다.
Apache Ambari 2.7.1
Apache Hadoop 3.1.1
Apache HBase 2.0.0
Apache Hive 3.1.0
Apache Kafka 1.1.1, 2.1.0
Apache Mahout 0.9.0 이상
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.3.1, 2.4.0
Apache Sqoop 1.4.7
Apache TEZ 0.9.1
Apache Zeppelin 0.8.0
Apache ZooKeeper 3.4.6
이후 버전의 Apache 구성 요소는 위에 나열된 버전 외에도 HDP 배포에 번들로 제공되기도 합니다. 이 경우 이러한 최신 버전은 Technical Previews 표에 나열되며 프로덕션 환경에서 위의 목록에 있는 Apache 구성 요소 버전을 대체해서는 안 됩니다.
Apache 패치 정보
HDInsight 4.0에서 사용할 수 있는 패치에 대한 자세한 내용은 아래 표에 나와 있는 각 제품의 패치 목록을 참조하세요.
R Server 9.1을 Machine Learning Services 9.3으로 업데이트 – 이 릴리스에서는 데이터 과학자와 엔지니어에게 알고리즘 혁신과 간편 조작화 성능을 통해 향상된 최상의 오픈 소스를 Apache Spark의 속도로 기본 설정 언어로 모두 사용할 수 있게 제공합니다. 이 릴리스는 Python에 대한 추가 지원을 통해 R Server에서 제공되는 기능을 확장하므로 클러스터 이름이 R 서버에서 ML 서비스로 변경됩니다.
Azure Data Lake Storage Gen2에 대한 지원 – HDInsight는 Azure Data Lake Storage Gen2의 미리 보기 릴리스를 지원합니다. 사용 가능한 지역에서 고객은 ADLS Gen2 계정을 HDInsight 클러스터용 기본 또는 보조 저장소로 선택할 수 있습니다.
HDInsight Enterprise Security Package 업데이트(미리 보기) - (미리 보기) Azure Blob Storage, ADLS Gen1, Cosmos DB 및 Azure DB에 대한 가상 네트워크 서비스 엔드포인트가 지원됩니다.
구성 요소 버전
모든 HDInsight 3.6 구성 요소의 공식 Apache 버전은 다음과 같습니다. 여기에 나열된 구성 요소는 모두 사용 가능한 가장 안정적인 버전의 공식 Apache 릴리스입니다.
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0 이상
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ 0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
위에 나열된 버전 외에도, 이후 버전의 몇 가지 Apache 구성 요소는 HDP 배포에서 번들로 제공되는 경우가 있습니다. 이 경우 이러한 최신 버전은 Technical Previews 표에 나열되며 프로덕션 환경에서 위의 목록에 있는 Apache 구성 요소 버전을 대체해서는 안 됩니다.
Apache 패치 정보
Hadoop은
이 릴리스에서는 Hadoop Common 2.7.3 및 다음 Apache 패치를 제공합니다.
HADOOP-13190: KMS HA 설명서의 LoadBalancingKMSClientProvider에 대해 설명합니다.
HADOOP-13227: AsyncCallHandler에서 이벤트 기반 아키텍처를 사용하여 비동기 호출을 처리해야 합니다.
HADOOP-14104: 클라이언트에서 KMS 공급자 경로에 대해 항상 namenode를 요청해야 합니다.
KAFKA-6274: KTable 원본 상태 저장소에 대한 이름 자동 생성을 향상시킵니다.
Mahout
HDP-2.3.x 및 2.4.x에서는 Mahout의 특정 Apache 릴리스를 전달하는 대신, Apache Mahout 트렁크의 특정 수정 버전 지점에 동기화했습니다. 이 수정 버전 지점은 0.9.0 릴리스 이후 및 0.10.0 릴리스 이전입니다. 이렇게 하면 0.9.0 릴리스에 비해 많은 수의 버그 수정과 향상된 기능을 제공하지만, 0.10.0의 새로운 Spark 기반 Mahout로 완전히 변환하기 전에 안정적인 릴리스의 Mahout 기능을 제공합니다.
HDP 2.3.x 및 2.4.x에서 Mahout에 대해 선택된 수정 버전 지점은 Apache Mahout의 "mahout-0.10.x" 분기(2014년 12월 19일 기준, GitHub의 0f037cb03e77c096 수정 버전)에 있습니다.
HDP-2.5.x 및 2.6.x에서는 가능한 보안 문제가 있는 쓸모 없는 라이브러리로 간주하고 Mahout의 Hadoop-Client를 2.7.3 버전(HDP-2.5에서 사용된 것과 동일한 버전)으로 업그레이드했기 때문에 Mahout에서 "commons-httpclient" 라이브러리를 제거했습니다. 결과적으로 다음이 수행됩니다.
이전에 컴파일된 Mahout 작업은 HDP-2.5 또는 2.6 환경에서 다시 컴파일해야 합니다.
일부 Mahout 작업에서 "org.apache.commons.httpclient", "net.java.dev.jets3t" 또는 관련 클래스 이름 접두사와 관련된 “ClassNotFoundException” 또는 “클래스를 로드할 수 없습니다” 오류가 발생할 수 있는 가능성이 약간 있습니다. 이러한 오류가 발생하면 사용되지 않는 라이브러리의 보안 문제에 대한 위험이 사용자 환경에서 허용되는 경우 작업에 필요한 jar를 클래스 경로에 수동으로 설치할지 여부를 고려할 수 있습니다.
이진 호환성 문제로 인해 Mahout의 hbase-client 코드에서 hadoop-common 라이브러리를 호출할 때 일부 Mahout 작업에서 충돌이 발생할 가능성이 훨씬 더 작습니다. 유감스럽게도 보안 문제가 있을 수 있는 Mahout의 HDP-2.4.2 버전으로 되돌아가는 것을 제외하고는 이 문제를 해결할 수 있는 방법이 없습니다. 다시 말하지만, 이는 예외적이며 지정된 Mahout 작업 모음에서 발생할 가능성은 거의 없습니다.
Oozie
이 릴리스에서는 Oozie 4.2.0에 다음 Apache 패치를 제공합니다.
OOZIE-2571: Scala 2.11을 사용할 수 있도록 spark.scala.binary.version Maven 속성을 추가합니다.
이 섹션에서는 이 릴리스에서 해결된 모든 CVE(일반 취약성 및 노출)에 대해 설명합니다.
CVE-2017-7676
요약: Apache Ranger 정책 평가에서 ‘*’ 와일드카드 문자 뒤에 나오는 문자를 무시합니다.
심각도: 위험
공급업체: Hortonworks
영향을 받는 버전: HDInsight 3.6 버전(Apache Ranger 버전 0.5.x/0.6.x/0.7.0 포함)
영향을 받는 사용자: ‘*’ 와일드카드 문자 뒤에 문자가 있는 Ranger 정책(예: my*test, test*.txt)을 사용하는 환경
Impact: 정책 리소스 검사기에서 ‘*’ 와일드카드 문자 뒤의 문자를 무시하므로, 의도하지 않은 동작이 발생할 수 있습니다.
수정 세부 정보: Ranger 정책 리소스 선택기에서 와일드카드 일치를 올바르게 처리하도록 업데이트되었습니다.
권장되는 작업: HDI 3.6(Apache Ranger 0.7.1 이상 포함)으로 업그레이드합니다.
CVE-2017-7677
요약: 외부 위치가 지정되면 Apache Ranger Hive 권한 부여자가 RWX 권한을 확인해야 합니다.
심각도: 위험
공급업체: Hortonworks
영향을 받는 버전: HDInsight 3.6 버전(Apache Ranger 버전 0.5.x/0.6.x/0.7.0 포함)
영향을 받는 사용자: Hive 테이블에 대한 외부 위치를 사용하는 환경
영향: Hive 테이블에 대한 외부 위치를 사용하는 환경에서 Apache Ranger Hive 권한 부여자는 테이블 만들기에 지정된 외부 위치에 대한 RWX 권한을 확인해야 합니다.
수정 세부 정보: Ranger Hive 권한 부여자가 외부 위치에 대한 권한 확인을 올바르게 처리하도록 업데이트되었습니다.
권장되는 작업: 사용자가 HDI 3.6(Apache Ranger 0.7.1 이상 포함)으로 업그레이드해야 합니다.
CVE-2017-9799
요약: Apache Storm에서 코드가 잠재적으로 잘못된 사용자로 실행될 수 있습니다.
심각도: 중요
공급업체: Hortonworks
영향을 받는 버전: HDP 2.4.0, HDP-2.5.0, HDP-2.6.0
영향을 받는 사용자: Storm을 보안 모드에서 사용하고, blobstore를 사용하여 토폴로지 기반 아티팩트 또는 토폴로지 리소스를 배포하는 사용자
영향: Storm의 일부 상황과 구성에 따라 이론적으로 토폴로지의 소유자가 감독자를 속여 작업자를 루트가 아닌 다른 사용자로 시작할 수 있습니다. 최악의 경우, 이로 인해 다른 사용자의 보안 자격 증명이 손상될 수 있습니다. 이 취약성은 보안을 활성화된 Apache Storm 설치에만 적용됩니다.
완화: 현재 해결 방법이 없으므로 HDP-2.6.2.1로 업그레이드합니다.
CVE-2016-4970
요약: 4.0.37 이전 Netty 4.0.x의 handler/ssl/OpenSslEngine.java 4.1.1 이전의 Final 및 4.1.x Final은 원격 공격자가 서비스 거부(무한 루프)를 일으킬 수 있도록 합니다.
심각도: 보통
공급업체: Hortonworks
영향을 받는 버전: 2.3.x 이후의 HDP 2.x.x
영향을 받는 사용자: HDFS를 사용하는 모든 사용자
영향: Hortonworks는 Hadoop 코드베이스에서 OpenSslEngine.java를 직접 사용하지 않으므로 영향이 적습니다.
권장되는 작업: HDP 2.6.3으로 업그레이드합니다.
CVE-2016-8746
요약: 정책 평가에서 Apache Ranger 경로 일치 문제가 발생합니다.
심각도: 정상
공급업체: Hortonworks
영향을 받는 버전: 모든 HDP 2.5 버전(Apache Ranger 버전 0.6.0/0.6.1/0.6.2 포함)
영향을 받는 사용자: Ranger 정책 관리 도구를 사용하는 모든 사용자
영향: 정책에 와일드카드 및 재귀 플래그가 포함된 경우 Ranger 정책 엔진에서 특정 조건의 경로를 잘못 일치시킵니다.
수정 세부 정보: 정책 평가 논리가 수정되었습니다.
권장되는 작업: 사용자가 HDP 2.5.4 이상(Apache Ranger 0.6.3 이상 포함) 또는 HDP 2.6 이상(Apache Ranger 0.7.0 이상 포함)으로 업그레이드해야 합니다.
CVE-2016-8751
요약: Apache Ranger에서 저장된 사이트 간 스크립팅 문제가 발생합니다.
심각도: 정상
공급업체: Hortonworks
영향을 받는 버전: 모든 HDP 2.3/2.4/2.5 버전(Apache Ranger 버전 0.5.x/0.6.0/0.6.1/0.6.2 포함)
영향을 받는 사용자: Ranger 정책 관리 도구를 사용하는 모든 사용자
영향: Apache Ranger는 사용자 지정 정책 조건을 입력할 때 저장된 사이트 간 스크립팅에 취약합니다. 일반 사용자가 로그인하고 정책에 액세스할 때 관리자 사용자는 몇 가지 임의의 JavaScript 코드 실행을 저장할 수 있습니다.
수정 세부 정보: 사용자 입력을 삭제하는 논리가 추가되었습니다.
권장되는 작업: 사용자가 HDP 2.5.4 이상(Apache Ranger 0.6.3 이상 포함) 또는 HDP 2.6 이상(Apache Ranger 0.7.0 이상 포함)으로 업그레이드해야 합니다.
해결된 지원 문제
해결된 문제는 이전에 Hortonworks 지원을 통해 기록된 문제를 나타내지만, 이제는 현재 릴리스에서 해결되었습니다. 이러한 문제는 알려진 문제 섹션의 이전 버전에서 보고되었을 수 있습니다. 이는 고객이 보고하거나 Hortonworks 품질 엔지니어링 팀에서 확인한 문제임을 나타냅니다.
Azure Data Lake Storage(Gen2)가 클러스터의 기본 스토리지인 경우 Spark 샘플 Notebook을 사용할 수 없습니다.
Enterprise Security Package
Spark Thrift Server는 ODBC 클라이언트로부터의 연결을 허용하지 않습니다.
문제 해결 단계는 다음과 같습니다.
클러스터를 만든 후 약 15분 정도 기다립니다.
Ranger UI에서 hivesampletable_policy가 있는지 확인합니다.
Spark 서비스를 다시 시작합니다.
이제는 STS 연결이 작동합니다.
Ranger 서비스 확인 실패에 대한 해결 방법
RANGER-1607: 이전 HDP 버전에서 HDP 2.6.2로 업그레이드하는 동안 Ranger 서비스 확인 실패에 대한 해결 방법.
참고
Ranger에서 SSL을 사용하는 경우에만 가능합니다.
이 문제는 Ambari를 통해 이전 HDP 버전에서 HDP-2.6.1로 업그레이드하려고 할 때 발생합니다. Ambari는 curl 호출을 사용하여 Ambari의 Ranger 서비스에 대한 서비스 확인을 수행합니다. Ambari에서 사용하는 JDK 버전이 JDK-1.7인 경우 curl 호출은 다음 오류로 인해 실패합니다.
다음 예제에서는 태그가 `tags-test`인 정책을 만들고, 모든 Hive 구성 요소 권한(예: select, update, create, drop, alter, index, lock, all)을 선택하여 astags.attr['type']=='abc' 정책 조건으로 해당 정책을 `공용` 그룹에 할당합니다.
다음 예제에서는 태그가 `tags-test`인 정책을 업데이트하고, 모든 Hive 구성 요소 권한(예: select, update, create, drop, alter, index, lock, all)을 선택하여 astags.attr['type']=='abc' 정책 조건으로 해당 정책을 `공용` 그룹에 할당합니다.
/usr/hdp/current/ranger-admin에서 PermissionList.js 파일을 찾습니다.
renderPolicyCondtion 함수의 정의를 찾습니다(줄 번호: 404).
해당 함수에서 다음 줄을 제거(즉, 표시 함수 아래)합니다(줄 번호: 434).
val = _.escape(val);//Line No:460
위에서 언급한 줄이 제거되면 Ranger UI를 통해 특수 문자를 포함할 수 있는 정책 조건으로 정책을 만들 수 있으며 동일한 정책에 대한 정책 평가가 성공적으로 수행됩니다.
ADLS Gen 2와 HDInsight 통합: ESP 클러스터의 사용자 디렉터리 및 권한 문제 1. 헤드 노드 1에서 사용자용 홈 디렉터리를 만들지 않습니다. 대안으로 이러한 디렉터리를 수동으로 만들고 소유권을 해당하는 사용자의 UPN으로 변경합니다.
2. 현재 /hdp의 권한은 751로 설정되지 않습니다. 이는 a. chmod 751 /hdp b. chmod –R 755 /hdp/apps로 설정되어야 합니다.
감가 상각
OMS 포털: OMS 포털을 가리키는 HDInsight 리소스 페이지에서 링크를 제거했습니다. Azure Monitor 로그는 처음에는 OMS 포털이라는 자체 포털을 사용하여 구성을 관리하고 수집된 데이터를 분석했습니다. 이 포털의 모든 기능은 Azure Portal로 이동되었으며 계속 개발될 예정입니다. HDInsight는 OMS 포털에 대한 지원을 중단했습니다. 고객은 Azure Portal에서 HDInsight Azure Monitor 로그 통합을 사용하게 됩니다.
HDInsight 3.6에서는 이러한 모든 기능을 사용할 수 있습니다. 최신 버전의 Spark, Kafka 및 R Server(Machine Learning Services)를 얻으려면, HDInsight 3.6 클러스터를 만들 때 Spark, Kafka, ML Services 버전을 선택합니다. ADLS에 대한 지원을 받으려면 ADLS 스토리지 유형을 옵션으로 선택할 수 있습니다. 기존 클러스터는 이러한 버전으로 자동 업그레이드되지 않습니다.
2018년 6월 이후에 만든 모든 새 클러스터는 모든 오픈 소스 프로젝트에서 1,000개 이상의 버그 수정을 자동으로 가져옵니다. 최신 HDInsight 버전으로 업그레이드하는 방법에 대한 모범 사례는 이 가이드를 참조합니다.
Azure HPC는 최고의 애플리케이션 성능, 스케일링 기능 및 가치를 제공하기 위해 최첨단 프로세서와 HPC급 InfiniBand 상호 연결을 사용하는 HPC 및 AI 워크로드용으로 특화된 클라우드 기능입니다. 사용자는 Azure HPC를 사용하여 비즈니스 및 기술 요구 사항이 달라질 때 동적으로 할당될 수 있는 고가용성의 HPC 및 AI 기술을 통해 뛰어난 혁신, 생산성 및 비즈니스 민첩성을 얻을 수 있습니다. 이 학습 경로는 Azure HPC에서 시작하는 데 도움이 되는 모듈 시리즈입니다. 가장 관심 있는 토픽을 선택하거나 하나씩 진행할 수 있습니다.
 출시 예정
출시 예정 새로운 기능
새로운 기능