학습
모듈
HoloLens 2의 개체에 대한 시선 추적 및 음성 명령 사용 - Training
이 과정에서는 사용자에게 시선 추적 및 음성 명령을 사용하는 방법에 대한 전반적인 이해를 제공합니다.
참고
이 항목에서는 주로 Windows 10(버전 1909 및 이전 버전)에서 제공되는 소비자 환경을 참조하세요. 자세한 내용은 Windows 및 Teams에서 Cortana에 대한 지원 종료를 참조 하세요.
개인 도우미 기술인 Cortana는 2013년 Microsoft BUILD 개발자 컨퍼런스에서 처음으로 시연되었습니다. Windows 음성 플랫폼은 Cortana 및 받아쓰기와 같은 Windows 10의 모든 음성 환경을 구동하는 데 사용됩니다. 음성 활성화는 사용자가 특정 문구인 "Hey Cortana"를 말함으로써 다양한 디바이스 전원 상태에서 음성 인식 엔진을 호출할 수 있게 해주는 기능입니다. 음성 활성화 기술을 지원하는 하드웨어를 만들려면 이 항목의 정보를 검토합니다.
참고
음성 활성화 구현은 중요한 프로젝트이며 SoC 공급업체가 완료한 작업입니다. OEM은 SoC 공급업체에 문의하여 SoC의 음성 활성화 구현에 대한 정보를 확인할 수 있습니다.
Windows에서 사용할 수 있는 음성 상호 작용 환경을 이해하려면 다음 항목을 검토하세요.
| 항목 | 설명 |
|---|---|
| Cortana란? | Cortana에 대한 제공 및 개요 및 사용 방향 |
VA("Hey Cortana" 음성 활성화) 기능을 사용하면 사용자가 자신의 음성을 사용하여 활성 컨텍스트(즉, 현재 화면에 있는 항목)를 벗어나 Cortana 환경을 신속하게 참여할 수 있습니다. 사용자는 디바이스를 물리적으로 조작하지 않고도 환경에 즉시 액세스할 수 있기를 원합니다. 전화 사용자의 경우 이것은 자동차에서 운전하고 차량 운영에 관심이있는 손 때문일 수 있습니다. Xbox 사용자의 경우 컨트롤러를 찾아서 연결하지 않기 때문일 수 있습니다. PC 사용자의 경우 여러 마우스, 터치 및/또는 키보드 작업(예: 주방의 컴퓨터)을 수행할 필요 없이 환경에 빠르게 액세스하기 때문일 수 있습니다.
음성 활성화는 미리 정의된 핵심 구 또는 "활성화 구"를 통해 항상 음성 입력을 수신 대기합니다. 핵심 구는 단독으로("Hey Cortana") 스테이징 명령으로 발화되거나, "이봐, Cortana, 내 다음 모임은 어디 있니?", 연결된 명령과 같은 음성 동작이 뒤따를 수 있습니다.
키워드 검색이라는 용어는 하드웨어 또는 소프트웨어에서 키워드(keyword) 검색하는 것을 설명합니다.
키워드만 활성화는 Cortana 키워드(keyword) 말한 경우에만 발생하며, Cortana는 수신 모드로 전환되었음을 나타내기 위해 EarCon 소리를 시작하고 재생합니다.
연결된 명령은 키워드(keyword) 바로 뒤에 명령을 실행하고(예: "안 함 Cortana, John에게 전화") Cortana를 시작하고(아직 시작하지 않은 경우) 명령을 따라(John과 전화 통화를 시작)하는 기능을 설명합니다.
이 다이어그램은 연결 및 키워드(keyword) 활성화만 보여 줍니다.
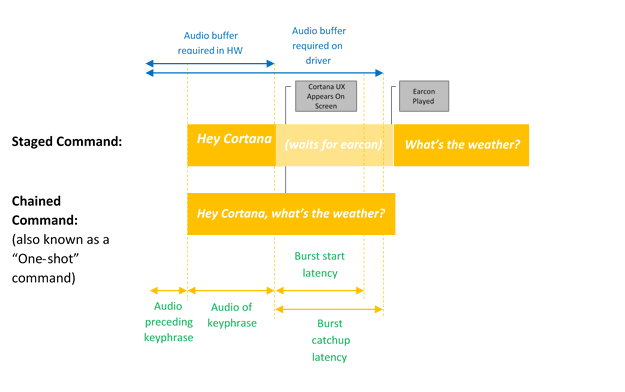
Microsoft는 하드웨어 키워드(keyword) 검색 품질을 보장하고 하드웨어 키워드(keyword) 검색을 사용할 수 없는 경우 Hey Cortana 환경을 제공하는 데 사용되는 OS 기본 키워드(keyword) 스포터(소프트웨어 키워드(keyword) 스포터)를 제공합니다.
"내 음성 알아보기" 기능을 사용하면 사용자가 Cortana가 고유한 음성을 인식하도록 학습할 수 있습니다. 이 작업은 Cortana 설정 화면에서 "안 함 Cortana"라고 말하는 방법을 선택하는 사용자가 수행합니다. 그런 다음 사용자는 사용자 음성의 고유한 특성을 식별하기에 충분한 다양한 윗주 패턴을 제공하는 6개의 신중하게 선택한 구를 반복합니다.
음성 활성화가 "내 음성 학습"과 페어링되면 두 알고리즘이 함께 작동하여 거짓 활성화를 줄입니다. 이것은 한 사람이 장치로 가득 찬 방에서 "이봐 Cortana"라고 말하는 회의실 시나리오에 특히 유용합니다. 이 기능은 Windows 10 버전 1903 이하에서만 사용할 수 있습니다.
음성 활성화는 핵심 구가 감지되면 반응하는 KWS(키워드(keyword) 스포터)를 통해 구동됩니다. KWS가 저전력 상태에서 디바이스를 절전 모드 해제하는 경우 솔루션을 WoV(Wake on Voice)라고 합니다. 자세한 내용은 Wake on Voice를 참조 하세요.
이 용어집에는 음성 활성화와 관련된 용어가 요약됩니다.
| 용어 | 예제/정의 |
|---|---|
| 스테이징된 명령 | 예: 코타나 <일시 중지, 이어콘> 을 기다립니다 날씨는 무엇입니까? 이를 "투샷 명령" 또는 "키워드 전용"이라고도 합니다. |
| 연결된 명령 | 예: 이봐 코타나 날씨는 무엇입니까? 이를 "단발 명령"이라고도 합니다. |
| 음성 활성화 | 미리 정의된 활성화 키의 키워드(keyword) 검색을 제공하는 시나리오입니다. 예를 들어 "Hey Cortana"는 Microsoft 음성 정품 인증 시나리오입니다. |
| WoV | Wake-on-Voice – 화면 끄기, 낮은 전원 상태에서 전체 전원 상태의 화면으로 음성 활성화를 가능하게 하는 기술입니다. |
| 최신 대기의 WoV | S0ix(최신 대기) 화면에서 전체 전원(S0) 상태의 화면으로의 절전 모드 해제 음성 |
| 최신 대기 | Windows 저전력 유휴 인프라 - Windows 10에서 커넥트 대기(CS)의 후속 작업입니다. 최신 대기 상태의 첫 번째 상태는 화면이 꺼져 있는 경우입니다. 가장 깊은 절전 상태는 DRIPS/복원력에 있는 경우입니다. 자세한 내용은 최신 대기를 참조하세요 . |
| Kws | 키워드 스포터 - "Hey Cortana"의 검색을 제공하는 알고리즘 |
| SW KWS | 소프트웨어 키워드(keyword) 스포터 - 호스트(CPU)에서 실행되는 KWS의 구현입니다. "Hey Cortana"의 경우 SW KWS가 Windows의 일부로 포함됩니다. |
| HW KWS | 하드웨어에서 오프로드된 키워드(keyword) 스포터 - 하드웨어에서 오프로드된 KWS 구현입니다. |
| 버스트 버퍼 | KWS 검색을 트리거한 모든 오디오가 포함되도록 KWS 검색 시 '버스트'할 수 있는 PCM 데이터를 저장하는 데 사용되는 순환 버퍼입니다. |
| 키워드 감지기 OEM 어댑터 | WoV 지원 HW가 Windows 및 Cortana 스택과 통신할 수 있도록 하는 드라이버 수준 shim입니다. |
| 모델 | KWS 알고리즘에서 사용하는 음향 모델 데이터 파일입니다. 데이터 파일이 정적입니다. 모델은 로캘당 하나씩 지역화됩니다. |
하드웨어 키워드(keyword) 스포터(HW KWS) SoC 공급업체를 구현하려면 다음 작업을 완료해야 합니다.
하드웨어 오프로드된 키워드(keyword) 스포터(HW KWS) WoV 요구 사항
HW KWS에 대한 AEC 요구 사항
Windows 버전 1709의 경우
Windows 버전 1803의 경우
SYSVAD 가상 오디오 어댑터 샘플의 일부로 GitHub에서 음성 활성화를 구현하는 오디오 드라이버에 대한 샘플 코드가 있습니다. 이 코드를 시작점으로 사용하는 것이 좋습니다. 이 위치에서 코드를 사용할 수 있습니다.
https://github.com/Microsoft/Windows-driver-samples/tree/main/audio/sysvad/
SYSVAD 샘플 오디오 드라이버에 대한 자세한 내용은 샘플 오디오 드라이버를 참조 하세요.
음성 활성화를 사용하도록 설정하기 위한 오디오 스택 외부 인터페이스는 음성 플랫폼 및 오디오 드라이버에 대한 통신 파이프라인 역할을 합니다. 외부 인터페이스는 세 부분으로 나뉩니다.
오디오 엔드포인트 그래프 빌드는 일반적으로 발생합니다. 그래프는 실시간 캡처보다 빠르게 처리할 수 있도록 준비됩니다. 캡처된 버퍼의 타임스탬프는 true가 기본. 특히 타임스탬프는 과거에 캡처되고 버퍼링된 데이터를 올바르게 반영하며 이제는 "버스팅"됩니다.
드라이버는 평소처럼 캡처 디바이스에 대한 KS 필터를 노출합니다. 이 필터는 여러 KS 속성 및 검색 이벤트를 구성, 사용 및 신호를 보낼 KS 이벤트를 지원합니다. 필터에는 KWS(키워드(keyword) 스포터) 핀으로 식별되는 추가 핀 팩터리도 포함됩니다. 이 핀은 키워드(keyword) 스포터에서 오디오를 스트리밍하는 데 사용됩니다.
속성은 다음과 같습니다.
키워드(keyword) 감지될 때 발생하는 이벤트는 KSEVENT_SOUNDDETECTOR_MATCHDETECTED 이벤트입니다.
탐지기가 무장되어 있는 동안 하드웨어는 작은 FIFO 버퍼에서 오디오 데이터를 지속적으로 캡처하고 버퍼링할 수 있습니다. (이 FIFO 버퍼의 크기는 이 문서 외부의 요구 사항에 따라 결정되지만 일반적으로 수백 밀리초에서 몇 초 정도가 될 수 있습니다.) 검색 알고리즘은 이 버퍼를 통해 스트리밍되는 데이터에서 작동합니다. 드라이버와 하드웨어의 디자인은 무장하는 동안 드라이버와 하드웨어 간의 상호 작용이 없고 키워드(keyword) 감지될 때까지 "애플리케이션" 프로세서를 중단하지 않습니다. 이렇게 하면 다른 활동이 없는 경우 시스템이 더 낮은 전원 상태에 도달할 수 있습니다.
하드웨어가 키워드(keyword) 감지하면 인터럽트를 생성합니다. 드라이버가 인터럽트 서비스를 기다리는 동안 하드웨어는 버퍼에 오디오를 계속 캡처하여 버퍼 제한 내에서 키워드(keyword) 손실된 후 데이터가 없도록 합니다.
키워드(keyword) 감지한 후 모든 음성 활성화 솔루션은 키워드(keyword) 시작하기 전에 250ms를 포함하여 모든 음성 키워드(keyword) 버퍼링해야 합니다. 오디오 드라이버는 스트림에서 핵심 구의 시작과 끝을 식별하는 타임스탬프를 제공해야 합니다.
키워드(keyword) 시작/끝 타임스탬프를 지원하기 위해 DSP 소프트웨어는 DSP 클록을 기반으로 이벤트를 내부적으로 타임스탬프해야 할 수 있습니다. 키워드(keyword) 감지되면 DSP 소프트웨어가 드라이버와 상호 작용하여 KS 이벤트를 준비합니다. 드라이버 및 DSP 소프트웨어는 DSP 타임스탬프를 Windows 성능 카운터 값에 매핑해야 합니다. 이 작업을 수행하는 방법은 하드웨어 디자인과 관련이 있습니다. 한 가지 가능한 해결 방법은 드라이버가 현재 성능 카운터를 읽고, 현재 DSP 타임스탬프를 쿼리하고, 현재 성능 카운터를 다시 읽은 다음, 성능 카운터와 DSP 시간 간의 상관 관계를 예측하는 것입니다. 그런 다음 상관 관계가 지정된 경우 드라이버는 키워드(keyword) DSP 타임스탬프를 Windows 성능 카운터 타임스탬프에 매핑할 수 있습니다.
OEM은 OS와 드라이버 간의 중개자 역할을 하는 COM 개체 구현을 제공하여 KSPROPERTY_SOUNDDETECTOR_PATTERNS 및 KSPROPERTY_SOUNDDETECTOR_MATCHRESULT 통해 오디오 드라이버에 기록되고 읽은 불투명한 데이터를 계산하거나 구문 분석하는 데 도움이 됩니다.
COM 개체의 CLSID는 KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS 반환된 감지기 패턴 형식 GUID입니다. OS는 패턴 형식 GUID를 전달하는 CoCreateInstance를 호출하여 키워드(keyword) 패턴 형식과 호환되는 적절한 COM 개체를 인스턴스화하고 개체의 IKeywordDetectorOemAdapter 인터페이스에서 메서드를 호출합니다.
OEM의 구현은 COM 스레딩 모델 중 하나를 선택할 수 있습니다.
인터페이스 디자인은 개체 구현을 상태 비지정 상태로 유지하려고 시도합니다. 즉, 구현에서는 메서드 호출 사이에 상태를 저장하지 않아도 됩니다. 실제로 내부 C++ 클래스는 일반적으로 COM 개체를 구현하는 데 필요한 변수 이외의 멤버 변수가 필요하지 않을 수 있습니다.
다음 메서드를 구현합니다.
KEYWORDID 열거형은 키워드(keyword) 구 텍스트/함수를 식별하며 Windows 생체 인식 서비스 어댑터에도 사용됩니다. 자세한 내용은 생체 인식 프레임워크 개요 - 핵심 플랫폼 구성 요소를 참조 하세요.
typedef enum {
KwInvalid = 0,
KwHeyCortana = 1,
KwSelect = 2
} KEYWORDID;
KEYWORDSELECTOR 구조체는 특정 키워드(keyword) 언어를 고유하게 선택하는 ID 집합입니다.
typedef struct
{
KEYWORDID KeywordId;
LANGID LangId;
} KEYWORDSELECTOR;
정적 사용자 독립 모델 - OEM DLL에는 일반적으로 DLL에 기본 제공되거나 DLL에 포함된 별도의 데이터 파일에 일부 정적 사용자 독립 모델 데이터가 포함됩니다. GetCapabilities 루틴에서 반환되는 지원되는 키워드(keyword) ID 집합은 이 데이터에 따라 달라집니다. 예를 들어 GetCapabilities에서 반환된 지원되는 키워드(keyword) ID 목록에 KwHeyCortana가 포함된 경우 정적 사용자 독립 모델 데이터에는 지원되는 모든 언어에 대한 "Hey Cortana"(또는 해당 번역)에 대한 데이터가 포함됩니다.
동적 사용자 종속 모델 - IStream은 임의 액세스 스토리지 모델을 제공합니다. OS는 IKeywordDetectorOemAdapter 인터페이스의 여러 메서드에 IStream 인터페이스 포인터를 전달합니다. OS는 최대 1MB의 데이터에 적절한 스토리지를 사용하여 IStream 구현을 백업합니다.
이 스토리지 내의 데이터의 콘텐츠 및 구조는 OEM에 의해 정의됩니다. 의도된 목적은 OEM DLL에서 계산하거나 검색한 사용자 종속 모델 데이터의 영구 스토리지를 위한 것입니다.
OS는 특히 사용자가 키워드(keyword) 학습한 적이 없는 경우 빈 IStream을 사용하여 인터페이스 메서드를 호출할 수 있습니다. OS는 각 사용자에 대해 별도의 IStream 스토리지를 만듭니다. 즉, 지정된 IStream은 한 명의 사용자와 한 명의 사용자에 대한 모델 데이터를 저장합니다.
OEM DLL 개발자는 사용자 독립 및 사용자 종속 데이터를 관리하는 방법을 결정합니다. 그러나 IStream 외부에는 사용자 데이터를 저장하지 않습니다. 한 가지 가능한 OEM DLL 디자인은 현재 메서드의 매개 변수에 따라 IStream 액세스와 정적 사용자 독립적 데이터 간에 내부적으로 전환됩니다. 대체 디자인은 각 메서드 호출을 시작할 때 IStream을 검사 고정 사용자 독립적 데이터를 IStream에 추가합니다(아직 없는 경우). 이 경우 나머지 메서드는 모든 모델 데이터에 대한 IStream에만 액세스할 수 있습니다.
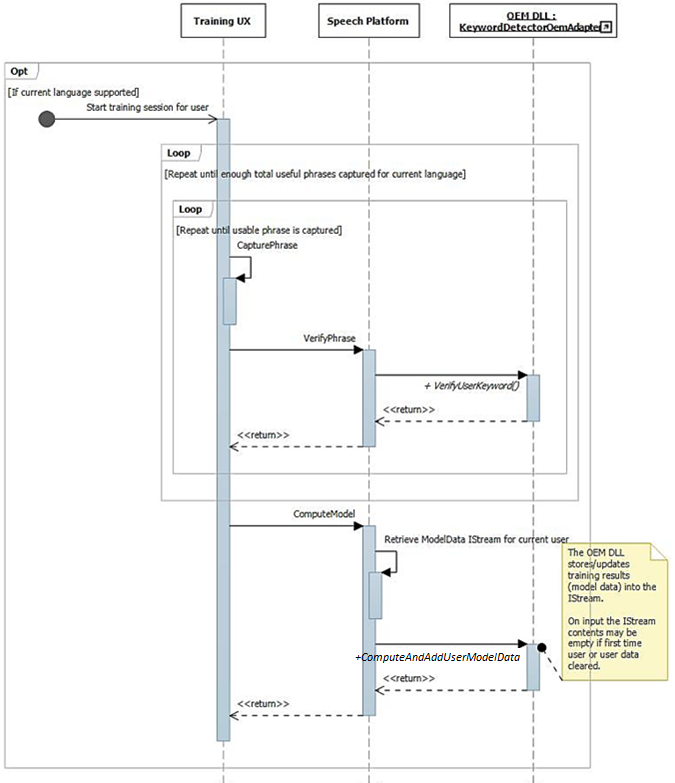
앞에서 설명한 대로 학습 UI 흐름은 오디오 스트림에서 전체 음성으로 풍부한 문장을 사용할 수 있게 합니다. 각 문장은 IKeywordDetectorOemAdapter::VerifyUserKeyword에 개별적으로 전달되어 예상된 키워드(keyword) 포함하고 허용 가능한 품질을 가지고 있는지 확인합니다. UI에서 모든 문장을 수집하고 확인한 후에는 모두 IKeywordDetectorOemAdapter::ComputeAndAddUserModelData에 대한 한 번의 호출로 전달됩니다.
오디오는 음성 활성화 학습을 위한 고유한 방식으로 처리됩니다. 다음 표에서는 음성 활성화 교육과 일반 음성 인식 사용량 간의 차이점을 요약합니다.
|
| 음성 교육 | 음성 인식 | |
| 모드 | Raw | 원시 또는 음성 |
| 고정 | 보통 | Kws |
| 오디오 형식 | 32비트 float(Type = Audio, Subtype = IEEE_FLOAT, 샘플링 속도 = 16kHz, 비트 = 32) | OS 오디오 스택에서 관리 |
| 마이크 | 마이크 0 | 배열의 모든 마이크 또는 모노 |
이 다이어그램은 키워드(keyword) 인식 시스템에 대한 개요를 제공합니다.
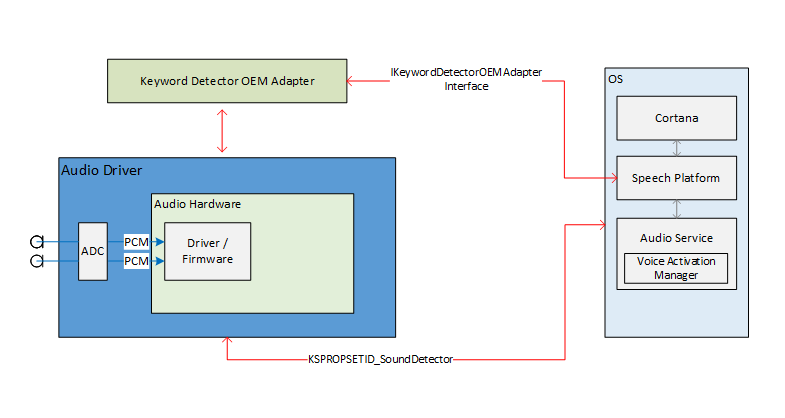
이러한 다이어그램에서 음성 런타임 모듈은 "음성 플랫폼"으로 표시됩니다. 이전에 멘션 Windows 음성 플랫폼은 Cortana 및 받아쓰기와 같은 Windows 10의 모든 음성 환경을 구동하는 데 사용됩니다.
시작하는 동안 IKeywordDetectorOemAdapter::GetCapabilities를 사용하여 기능이 수집됩니다.
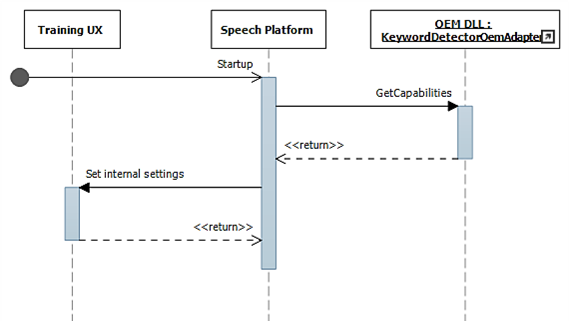
나중에 사용자가 "내 음성 학습"을 선택하면 학습 흐름이 호출됩니다.
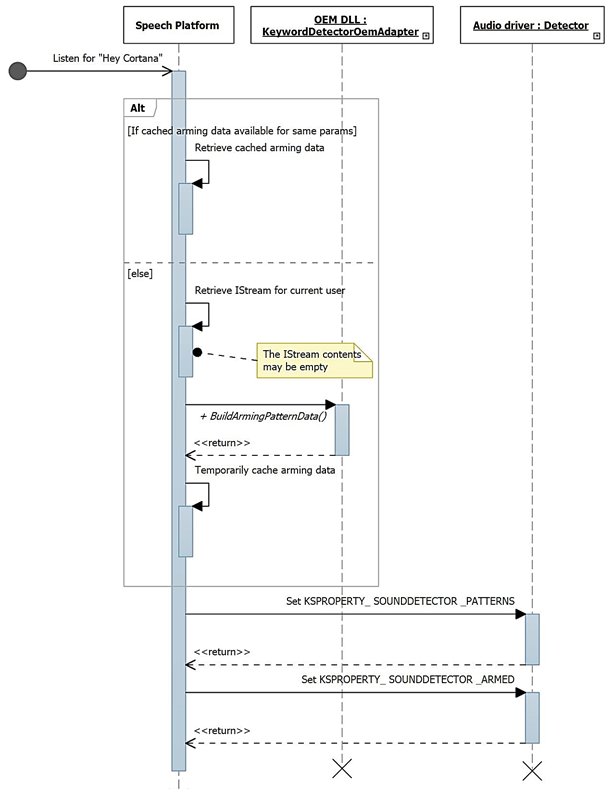
이 다이어그램에서는 키워드(keyword) 검색을 위한 무장 프로세스를 설명합니다.
미니포트 인터페이스는 WaveRT 미니포트 드라이버에서 구현하도록 정의됩니다. 이러한 인터페이스는 오디오 드라이버를 간소화하거나, OS 오디오 파이프라인 성능 및 안정성을 향상시키거나, 새로운 시나리오를 지원하는 방법을 제공합니다. 드라이버가 OS에 버퍼 크기 제약 조건의 정적 식을 제공할 수 있도록 새 PnP 디바이스 인터페이스 속성이 정의됩니다.
드라이버는 OS, 드라이버 및 하드웨어 간에 오디오 데이터를 이동할 때 다양한 제약 조건에서 작동합니다. 이러한 제약 조건은 메모리와 하드웨어 간에 데이터를 이동하는 물리적 하드웨어 전송 및/또는 하드웨어 또는 관련 DSP 내의 신호 처리 모듈로 인해 발생할 수 있습니다.
HW-KWS 솔루션은 최소 100ms 및 최대 200ms의 오디오 캡처 크기를 지원해야 합니다.
드라이버는 KS 스트리밍 핀이 있는 KS 필터의 KSCATEGORY_AUDIO PnP 디바이스 인터페이스에서 DEVPKEY_KsAudio_PacketSize_Constraints 디바이스 속성을 설정하여 버퍼 크기 제약 조건을 표현합니다. KS 필터 인터페이스를 사용하는 동안 이 속성은 기본 유효하고 안정적이어야 합니다. OS는 드라이버에 대한 핸들을 열고 드라이버를 호출하지 않고도 언제든지 이 값을 읽을 수 있습니다.
DEVPKEY_KsAudio_PacketSize_Constraints 속성 값에는 물리적 하드웨어 제약 조건을 설명하는 KSAUDIO_PACKETSIZE_CONSTRAINTS 구조가 포함되어 있습니다(즉, WaveRT 버퍼에서 오디오 하드웨어로 데이터를 전송하는 메커니즘으로 인해). 구조체에는 신호 처리 모드와 관련된 제약 조건을 설명하는 0개 이상의 KSAUDIO_PACKETSIZE_PROCESSINGMODE_CONSTRAINT 구조체 배열이 포함됩니다. 드라이버는 PcRegisterSubdevice를 호출하거나 스트리밍 핀에 대한 KS 필터 인터페이스를 사용하도록 설정하기 전에 이 속성을 설정합니다.
드라이버는 드라이버에서 OS로 오디오 데이터 흐름을 더 잘 조정하기 위해 이 인터페이스를 구현합니다. 이 인터페이스를 캡처 스트림에서 사용할 수 있는 경우 OS는 이 인터페이스의 메서드를 사용하여 WaveRT 버퍼의 데이터에 액세스합니다. 자세한 내용은 IMiniportWaveRTInputStream::GetReadPacket을 참조 하세요.
WaveRT 미니포트는 필요에 따라 OS에서 쓰기 진행률을 확인하고 정확한 스트림 위치를 반환하도록 이 인터페이스를 구현합니다. 자세한 내용은 IMiniportWaveRTOutputStream::SetWritePacket, IMiniportWaveRTOutputStream::GetOutputStreamPresentationPosition 및 IMiniportWaveRTOutputStream::GetPacketCount를 참조하세요.
몇 가지 드라이버 루틴은 디바이스에서 샘플을 캡처하거나 표시하는 시간을 반영하는 Windows 성능 카운터 타임스탬프를 반환합니다.
복잡한 DSP 파이프라인 및 신호 처리가 있는 디바이스에서는 정확한 타임스탬프를 계산하는 것이 어려울 수 있으며 신중하게 수행해야 합니다. 타임스탬프는 샘플이 OS에서 DSP로 전송된 시간을 단순히 반영해서는 안 됩니다.
이 섹션에서는 버스트 읽기에 대한 OS 및 드라이버 상호 작용에 대해 설명합니다. 버스트 읽기는 드라이버가 IMiniportWaveRTInputStream::GetReadPacket 함수를 포함하여 패킷 기반 스트리밍 WaveRT 모델을 지원하는 한 음성 활성화 시나리오 외부에서 발생할 수 있습니다.
두 가지 버스트 예제 읽기 시나리오에 대해 설명합니다. 한 시나리오에서 미니포트가 핀 범주가 KSNODETYPE_AUDIO_KEYWORDDETECTOR 핀을 지원하는 경우 드라이버는 키워드(keyword) 감지될 때 데이터를 캡처하고 내부적으로 버퍼링하기 시작합니다. 다른 시나리오에서는 OS가 IMiniportWaveRTInputStream::GetReadPacket을 호출하여 데이터를 충분히 빠르게 읽지 못하는 경우 드라이버가 선택적으로 WaveRT 버퍼 외부의 데이터를 내부적으로 버퍼링할 수 있습니다.
KSSTATE_RUN 전환하기 전에 캡처된 데이터를 버스트하려면 드라이버는 버퍼링된 캡처 데이터와 함께 정확한 샘플 타임스탬프 정보를 유지해야 합니다. 타임스탬프는 캡처된 샘플의 샘플링 인스턴트를 식별합니다.
스트림이 KSSTATE_RUN 전환된 후 드라이버는 이미 사용 가능한 데이터가 있으므로 버퍼 알림 이벤트를 즉시 설정합니다.
이 이벤트에서 OS는 GetReadPacket()을 호출하여 사용 가능한 데이터에 대한 정보를 가져옵니다.
a. 드라이버는 유효한 캡처된 데이터의 패킷 번호(KSSTATE_STOP에서 KSSTATE_RUN로 전환한 후 첫 번째 패킷의 경우 0)를 반환하며, 여기서 OS는 스트림 시작에 상대적인 패킷 위치뿐만 아니라 WaveRT 버퍼 내에서 패킷 위치를 파생시킬 수 있습니다.
b. 또한 드라이버는 패킷에서 첫 번째 샘플의 샘플링 인스턴스에 해당하는 성능 카운터 값을 반환합니다. 이 성능 카운터 값은 하드웨어 또는 드라이버(WaveRT 버퍼 외부) 내에서 버퍼링된 캡처 데이터의 양에 따라 비교적 오래되었을 수 있습니다.
c. 읽지 않은 버퍼링된 데이터가 더 있는 경우 드라이버도 사용할 수 있습니다. i. 해당 데이터를 WaveRT 버퍼의 사용 가능한 공간(즉, GetReadPacket에서 반환된 패킷에서 사용하지 않는 공간)으로 즉시 전송하고, MoreData에 대해 true를 반환하고, 이 루틴에서 반환하기 전에 버퍼 알림 이벤트를 설정합니다. 또는, ii. 다음 패킷을 WaveRT 버퍼의 사용 가능한 공간으로 버스트하도록 하드웨어를 프로그래밍하고, MoreData에 대해 false를 반환하고, 나중에 전송이 완료되면 버퍼 이벤트를 설정합니다.
OS는 GetReadPacket()에서 반환된 정보를 사용하여 WaveRT 버퍼에서 데이터를 읽습니다.
OS는 다음 버퍼 알림 이벤트를 기다립니다. 드라이버가 단계(2c)에서 버퍼 알림을 설정하는 경우 대기가 즉시 종료될 수 있습니다.
드라이버가 2c단계에서 이벤트를 즉시 설정하지 않은 경우 드라이버는 더 많은 캡처된 데이터를 WaveRT 버퍼로 전송한 후 이벤트를 설정하고 OS에서 읽을 수 있도록 합니다.
(2)로 이동합니다. KSNODETYPE_AUDIO_KEYWORDDETECTOR 키워드(keyword) 감지기 핀의 경우 드라이버는 최소 5,000ms의 오디오 데이터에 충분한 내부 버스트 버퍼링을 할당해야 합니다. OS가 버퍼 오버플로 전에 핀에 스트림을 만들지 못하면 드라이버는 내부 버퍼링 작업을 종료하고 연결된 리소스를 해제할 수 있습니다.
WoV(Wake On Voice)를 사용하면 사용자가 "Hey Cortana"와 같은 특정 키워드(keyword) 말함으로써 화면 꺼짐, 낮은 전원 상태, 화면 켜짐, 전체 전원 상태로 음성 인식 엔진을 활성화하고 쿼리할 수 있습니다.
이 기능을 사용하면 화면이 꺼져 있고 디바이스가 유휴 상태일 때를 포함하여 디바이스가 저전력 상태인 동안 디바이스가 항상 사용자의 음성을 수신 대기할 수 있습니다. 일반 마이크 녹음 중에 볼 수 있는 훨씬 더 높은 전력 사용량에 비해 전력이 낮은 수신 모드를 사용하여 이 작업을 수행합니다. 저전력 음성 인식을 사용하면 사용자가 "Hey Cortana"와 같은 미리 정의된 핵심 구를 말한 다음 "다음 약속일 때"와 같은 연결된 음성 구를 말하여 핸즈프리 방식으로 음성을 호출할 수 있습니다. 디바이스가 사용 중인지 아니면 화면이 꺼져 있는 상태에서 유휴 상태인지에 관계없이 작동합니다.
오디오 스택은 절전 모드 해제 데이터(화자 ID, 키워드(keyword) 트리거, 신뢰 수준)를 전달하고 관심 있는 클라이언트에게 키워드(keyword) 감지되었음을 알립니다.
시스템 유휴 상태의 WoV는 AC 전원의 최신 대기 절전 모드 해제 온 음성 기본 테스트와 HLK의 DC 전원 원본 에 대한 최신 대기 절전 모드 해제 온 음성 기본 테스트를 사용하여 최신 대기 시스템에서 유효성을 검사할 수 있습니다. 이러한 테스트는 시스템에 하드웨어 키워드(keyword) 스포터(HW-KWS)가 있고 DRIPS(Deepest Runtime 유휴 플랫폼 상태)에 진입할 수 있으며 시스템 다시 시작 대기 시간이 1초 미만 또는 같음인 음성 명령에서 최신 대기 상태에서 절전 모드 해제할 수 있음을 검사.
학습
모듈
HoloLens 2의 개체에 대한 시선 추적 및 음성 명령 사용 - Training
이 과정에서는 사용자에게 시선 추적 및 음성 명령을 사용하는 방법에 대한 전반적인 이해를 제공합니다.