Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Gebruik dit artikel voor meer informatie over Azure OpenAI On Your Data, waardoor ontwikkelaars gemakkelijker hun bedrijfsgegevens kunnen verbinden, opnemen en grondgewijze gegevens kunnen maken om snel gepersonaliseerde copilots (preview) te maken. Het verbetert het begrip van de gebruiker, versnelt de voltooiing van taken, verbetert de operationele efficiëntie en helpt besluitvorming.
Wat is Azure OpenAI op uw gegevens?
Met Azure OpenAI op uw gegevens kunt u geavanceerde AI-modellen uitvoeren, zoals GPT-35-Turbo en GPT-4 op uw eigen bedrijfsgegevens zonder dat u modellen hoeft te trainen of af te stemmen. U kunt met een grotere nauwkeurigheid chatten en uw gegevens analyseren. U kunt bronnen opgeven ter ondersteuning van de antwoorden op basis van de meest recente informatie die beschikbaar is in uw aangewezen gegevensbronnen. U hebt toegang tot Azure OpenAI op uw gegevens met behulp van een REST API, via de SDK of de webinterface in de Azure AI Foundry-portal. U kunt ook een web-app maken die verbinding maakt met uw gegevens om een verbeterde chatoplossing in te schakelen of deze rechtstreeks als copilot te implementeren in Copilot Studio (preview).
Ontwikkelen met Azure OpenAI op uw gegevens
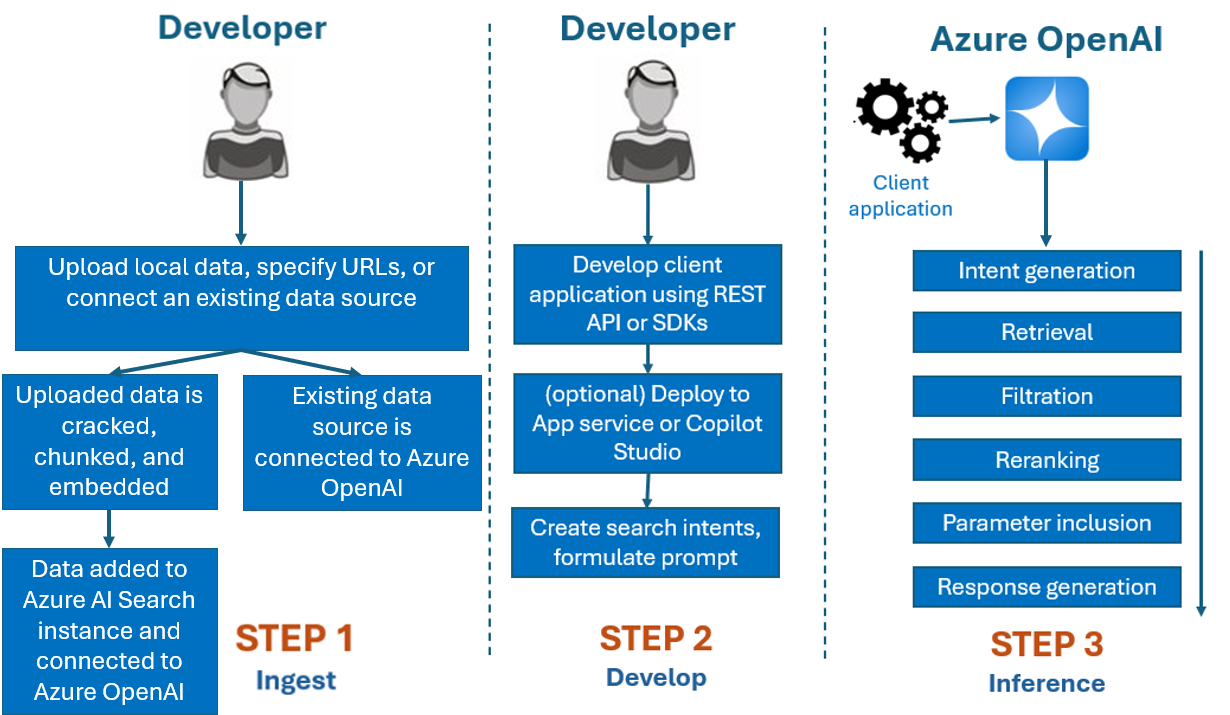
Normaal gesproken is het ontwikkelingsproces dat u met Azure OpenAI op uw gegevens zou gebruiken:
Opnemen: bestanden uploaden met behulp van de Azure AI Foundry-portal of de opname-API. Hierdoor kunnen uw gegevens worden gekraakt, gesegmenteerd en ingesloten in een Azure AI Search-exemplaar dat kan worden gebruikt door Azure OpenAI-modellen. Als u een bestaande ondersteunde gegevensbron hebt, kunt u deze ook rechtstreeks verbinden.
Ontwikkelen: Nadat u Azure OpenAI op uw gegevens hebt geprobeerd, begint u met het ontwikkelen van uw toepassing met behulp van de beschikbare REST API en SDK's, die beschikbaar zijn in verschillende talen. Er worden prompts en zoekintenties gemaakt die moeten worden doorgegeven aan de Azure OpenAI-service.
Deductie: Nadat uw toepassing is geïmplementeerd in uw voorkeursomgeving, worden er prompts naar Azure OpenAI verzonden. Hiermee worden verschillende stappen uitgevoerd voordat er een antwoord wordt geretourneerd:
Genereren van intentie: De service bepaalt de intentie van de prompt van de gebruiker om een correct antwoord te bepalen.
Ophalen: De service haalt relevante segmenten van beschikbare gegevens op uit de verbonden gegevensbron door er een query op uit te voeren. Bijvoorbeeld door een semantische of vectorzoekopdracht te gebruiken. Parameters zoals striktheid en het aantal documenten dat moet worden opgehaald, worden gebruikt om het ophalen te beïnvloeden.
Filtratie en rerankering: Zoekresultaten uit de ophaalstap worden verbeterd door gegevens te rangschikken en te filteren om relevantie te verfijnen.
Antwoordgeneratie: de resulterende gegevens worden samen met andere informatie, zoals het systeembericht, verzonden naar het LLM (Large Language Model) en het antwoord wordt teruggestuurd naar de toepassing.
Om aan de slag te gaan, verbindt u uw gegevensbron met behulp van de Azure AI Foundry-portal en begint u vragen te stellen en te chatten over uw gegevens.
Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) voor het toevoegen van gegevensbronnen
Als u Azure OpenAI volledig wilt gebruiken voor uw gegevens, moet u een of meer Azure RBAC-rollen instellen. Zie Azure OpenAI op uw gegevensconfiguratie voor meer informatie.
Gegevensindelingen en bestandstypen
On Your Data van Azure OpenAI ondersteunt de volgende bestandstypen:
.txt.md.html.docx.pptx.pdf
Er is een uploadlimiet en er zijn enkele opmerkingen over documentstructuur en hoe dit van invloed kan zijn op de kwaliteit van reacties van het model:
Als u gegevens converteert van een niet-ondersteunde indeling naar een ondersteunde indeling, optimaliseert u daarmee de kwaliteit van de antwoorden van het model door de conversie te waarborgen:
- Leidt niet tot aanzienlijk gegevensverlies.
- Voegt geen onverwachte ruis toe aan uw gegevens.
Als uw bestanden speciale opmaak hebben, zoals tabellen en kolommen of opsommingstekens, bereidt u uw gegevens voor met het script voor gegevensvoorbereiding dat beschikbaar is op GitHub.
Voor documenten en gegevenssets met lange tekst moet u het beschikbare script voor gegevensvoorbereiding gebruiken. Het script segmenteert gegevens zodat de antwoorden van het model nauwkeuriger zijn. Dit script ondersteunt ook gescande PDF-bestanden en -afbeeldingen.
Ondersteunde gegevensbronnen
U moet verbinding maken met een gegevensbron om uw gegevens te uploaden. Wanneer u uw gegevens wilt gebruiken om te chatten met een Azure OpenAI-model, worden uw gegevens gesegmenteerd in een zoekindex, zodat relevante gegevens kunnen worden gevonden op basis van gebruikersquery's.
Opmerking
Uw gegevens moeten ongestructureerde tekst zijn voor de beste resultaten. Als u niet-tekstuele semi-gestructureerde of gestructureerde gegevens hebt, kunt u deze converteren naar tekst. Als uw bestanden speciale opmaak hebben, zoals tabellen en kolommen of opsommingstekens, bereidt u uw gegevens voor met het script voor gegevensvoorbereiding dat beschikbaar is op GitHub.
De Integrated Vector Database in azure Cosmos DB voor MongoDB op basis van vCore biedt systeemeigen ondersteuning voor integratie met Azure OpenAI On Your Data.
Voor sommige gegevensbronnen, zoals het uploaden van bestanden vanaf uw lokale computer (preview) of gegevens in een Blob Storage-account (preview), wordt Azure AI Search gebruikt. Wanneer u de volgende gegevensbronnen kiest, worden uw gegevens opgenomen in een Azure AI Search-index.
| Gegevens die zijn opgenomen via Azure AI Search | Beschrijving |
|---|---|
| Azure AI Search | Gebruik een bestaande Azure AI Search-index met Azure OpenAI op uw gegevens. |
| Bestanden uploaden (preview) | Upload bestanden vanaf uw lokale computer die moeten worden opgeslagen in een Azure Blob Storage-database en opgenomen in Azure AI Search. |
| URL/webadres (preview) | Webinhoud van de URL's wordt opgeslagen in Azure Blob Storage. |
| Azure Blob Storage (voorbeeld) | Upload bestanden uit Azure Blob Storage die moeten worden opgenomen in een Azure AI Search-index. |

- Azure AI Search
- Vector Database in Azure Cosmos DB voor MongoDB
- Azure Blob Storage (preview)
- Bestanden uploaden (preview)
- URL/webadres (preview)
- Elasticsearch (preview)
- MongoDB Atlas (preview)
U kunt overwegen om een Azure AI Search-index te gebruiken wanneer u het volgende wilt doen:
- Pas het proces voor het maken van de index aan.
- Gebruik een index die eerder is gemaakt, opnieuw door gegevens uit andere gegevensbronnen op te nemen.
Opmerking
- Als u een bestaande index wilt gebruiken, moet deze ten minste één doorzoekbaar veld hebben.
- Stel de optie CORS Origin-type toestaan in op en de
allop .* - U kunt geen complexe velden in uw zoekindex hebben.
Zoektypen
Azure OpenAI On Your Data biedt de volgende zoektypen die u kunt gebruiken wanneer u uw gegevensbron toevoegt.
Vectorzoekopdrachten met behulp van insluitmodellen van Ada, beschikbaar in geselecteerde regio's
Als u vectorzoekopdrachten wilt inschakelen, hebt u een bestaand insluitmodel nodig dat is geïmplementeerd in uw Azure OpenAI-resource. Selecteer de insluitimplementatie bij het verbinden van uw gegevens en selecteer vervolgens een van de vectorzoektypen onder Gegevensbeheer. Als u Azure AI Search als gegevensbron gebruikt, moet u ervoor zorgen dat u een vectorkolom in de index hebt.
Als u uw eigen index gebruikt, kunt u de veldtoewijzing aanpassen wanneer u uw gegevensbron toevoegt om de velden te definiëren die worden toegewezen bij het beantwoorden van vragen. Als u veldtoewijzing wilt aanpassen, selecteert u Aangepaste veldtoewijzing gebruiken op de pagina Gegevensbron wanneer u uw gegevensbron toevoegt.
Belangrijk
- Semantische zoekopdrachten zijn onderhevig aan aanvullende prijzen. Je moet Basic of een hoger SKU kiezen om semantisch zoeken of vectorzoeken in te schakelen. Zie het verschil in prijscategorieën en servicelimieten voor meer informatie.
- Om de kwaliteit van het ophalen van gegevens en modelreacties te verbeteren, raden we u aan semantische zoekopdrachten in te schakelen voor de volgende gegevensbrontalen: Engels, Frans, Spaans, Portugees, Italiaans, Duitsland, Chinees (Zh), Japans, Koreaans, Russisch en Arabisch.
| Zoekoptie | Type ophalen | Aanvullende prijzen? | Voordelen |
|---|---|---|---|
| trefwoord | Trefwoorden zoeken | Geen extra prijzen. | Voert snelle en flexibele queryparsering en overeenkomende query's uit op doorzoekbare velden, met behulp van termen of woordgroepen in elke ondersteunde taal, met of zonder operators. |
| semantisch | Semantische zoekopdracht | Aanvullende prijzen voor semantisch zoekgebruik . | Verbetert de precisie en relevantie van zoekresultaten met behulp van een reranker (met AI-modellen) om inzicht te krijgen in de semantische betekenis van querytermen en documenten die worden geretourneerd door de initiële zoekrangschikking |
| vector | Zoeken met vectoren | Aanvullende prijzen voor uw Azure OpenAI-account van het aanroepen van het insluitmodel. | Hiermee kunt u documenten vinden die vergelijkbaar zijn met een bepaalde queryinvoer op basis van de vector-insluitingen van de inhoud. |
| hybride (vector + trefwoord) | Een hybride van vectorzoekopdrachten en trefwoorden zoeken | Aanvullende prijzen voor uw Azure OpenAI-account van het aanroepen van het insluitmodel. | Hiermee kunt u overeenkomsten zoeken op vectorvelden met behulp van vector-insluitingen, terwijl ook flexibele queryparsering en zoekopdrachten in volledige tekst worden ondersteund voor alfanumerieke velden met behulp van termenquery's. |
| hybride (vector + trefwoord) + semantisch | Een hybride van vectorzoekopdrachten, semantische zoekopdrachten en trefwoordzoekopdrachten. | Aanvullende prijzen voor uw Azure OpenAI-account van het aanroepen van het insluitmodel en aanvullende prijzen voor semantisch zoekgebruik . | Maakt gebruik van vector-insluitingen, taalbegrip en flexibele queryparsering om rijke zoekervaringen en generatieve AI-apps te maken die complexe en diverse scenario's voor het ophalen van gegevens kunnen verwerken. |
Intelligente zoekopdracht
Azure OpenAI On Your Data heeft intelligente zoekopdrachten ingeschakeld voor uw gegevens. Semantisch zoeken is standaard ingeschakeld als u zowel semantische zoekopdrachten als trefwoordzoekopdrachten hebt. Als u modellen hebt ingesloten, wordt intelligent zoeken standaard ingesteld op hybride en semantische zoekopdrachten.
Toegangsbeheer op documentniveau
Opmerking
Toegangsbeheer op documentniveau wordt ondersteund wanneer u Azure AI Search als uw gegevensbron selecteert.
Met Azure OpenAI op uw gegevens kunt u de documenten beperken die kunnen worden gebruikt in antwoorden voor verschillende gebruikers met Azure AI Search-beveiligingsfilters. Wanneer u toegang op documentniveau inschakelt, worden de zoekresultaten die worden geretourneerd door Azure AI Search en gebruikt om een antwoord te genereren, ingekort op basis van het microsoft Entra-groepslidmaatschap van de gebruiker. U kunt alleen toegang op documentniveau inschakelen voor bestaande Azure AI Search-indexen. Zie Azure OpenAI op uw gegevensnetwerk en toegangsconfiguratie voor meer informatie.
Indexveldtoewijzing
Als u uw eigen index gebruikt, wordt u gevraagd in de Azure AI Foundry-portal om te definiëren welke velden u wilt toewijzen voor het beantwoorden van vragen wanneer u uw gegevensbron toevoegt. U kunt meerdere velden opgeven voor inhoudsgegevens en alle velden bevatten met tekst die betrekking heeft op uw use-case.

In dit voorbeeld geven de velden die zijn toegewezen aan inhoudsgegevens en titel informatie aan het model om vragen te beantwoorden. Titel wordt ook gebruikt om bronvermeldingstekst te titel. Het veld dat is toegewezen aan bestandsnaam genereert de bronvermeldingsnamen in het antwoord.
Door deze velden correct toe te wijzen, zorgt u ervoor dat het model een betere reactie- en bronvermeldingskwaliteit heeft. U kunt deze ook configureren in de API met behulp van de fieldsMapping parameter.
Zoekfilter (API)
Als u aanvullende op waarden gebaseerde criteria wilt implementeren voor het uitvoeren van query's, kunt u een zoekfilter instellen met behulp van de filter parameter in de REST API.
Hoe gegevens worden opgenomen in Azure AI Search
Vanaf september 2024 zijn de opname-API's overgeschakeld naar geïntegreerde vectorisatie. Met deze update worden de bestaande API-contracten niet gewijzigd. Geïntegreerde vectorisatie, een nieuw aanbod van Azure AI Search, maakt gebruik van vooraf gedefinieerde vaardigheden voor het segmenteren en insluiten van de invoergegevens. De Azure OpenAI On Your Data-opnameservice maakt niet langer gebruik van aangepaste vaardigheden. Na de migratie naar geïntegreerde vectorisatie heeft het opnameproces enkele wijzigingen ondergaan en worden alleen de volgende assets gemaakt:
{job-id}-index-
{job-id}-indexer, als er een uur- of dagelijks schema is opgegeven, anders wordt de indexeerfunctie opgeschoond aan het einde van het opnameproces. {job-id}-datasource
De segmentcontainer is niet meer beschikbaar, omdat deze functionaliteit nu inherent wordt beheerd door Azure AI Search.
Gegevensverbinding
U moet selecteren hoe u de verbinding wilt verifiëren vanuit Azure OpenAI, Azure AI Search en Azure Blob Storage. U kunt een door het systeem toegewezen beheerde identiteit of een API-sleutel kiezen. Door DE API-sleutel te selecteren als verificatietype, wordt de API-sleutel automatisch ingevuld zodat u verbinding kunt maken met uw Azure AI Search-, Azure OpenAI- en Azure Blob Storage-resources. Door door het systeem toegewezen beheerde identiteit te selecteren, wordt de verificatie gebaseerd op de roltoewijzing die u hebt. Door het systeem toegewezen beheerde identiteit is standaard geselecteerd voor beveiliging.

Zodra u de volgende knop selecteert, wordt uw installatie automatisch gevalideerd om de geselecteerde verificatiemethode te gebruiken. Als er een fout optreedt, raadpleegt u het artikel over roltoewijzingen om uw installatie bij te werken.
Nadat u de installatie hebt opgelost, selecteert u de volgende optie opnieuw om te valideren en door te gaan. API-gebruikers kunnen ook verificatie configureren met toegewezen beheerde identiteit en API-sleutels.









Implementeren in een copilot (preview), Teams-app (preview) of web-app
Nadat u Azure OpenAI hebt verbonden met uw gegevens, kunt u deze implementeren met behulp van de knop Implementeren inde Azure AI Foundry-portal.

Dit biedt u meerdere opties voor het implementeren van uw oplossing.
U kunt rechtstreeks vanuit de Azure AI Foundry-portal implementeren naar een copilot in Copilot Studio (preview), zodat u gesprekservaringen kunt overbrengen naar verschillende kanalen, zoals: Microsoft Teams, websites, Dynamics 365 en andere Azure Bot Service-kanalen. De tenant die wordt gebruikt in Azure OpenAI en Copilot Studio (preview) moet hetzelfde zijn. Zie Een verbinding met Azure OpenAI op uw gegevens gebruiken voor meer informatie.
Opmerking
Implementeren in een copilot in Copilot Studio (preview) is alleen beschikbaar in amerikaanse regio's.
Toegang en netwerken configureren voor Azure OpenAI op uw gegevens
U kunt Azure OpenAI op uw gegevens gebruiken en gegevens en resources beveiligen met op rollen gebaseerd toegangsbeheer van Microsoft Entra ID, virtuele netwerken en privé-eindpunten. U kunt ook de documenten beperken die kunnen worden gebruikt in antwoorden voor verschillende gebruikers met Azure AI Search-beveiligingsfilters. Zie Azure OpenAI op uw gegevenstoegang en netwerkconfiguratie.
Beste praktijken
Gebruik de volgende secties voor meer informatie over het verbeteren van de kwaliteit van reacties die door het model worden gegeven.
Opnameparameter
Wanneer uw gegevens worden opgenomen in Azure AI Search, kunt u de volgende aanvullende instellingen wijzigen in de studio- of opname-API.
Segmentgrootte (preview)
Azure OpenAI On Your Data verwerkt uw documenten door ze op te splitsen in segmenten voordat ze worden opgenomen. De segmentgrootte is de maximale grootte in termen van het aantal tokens van een segment in de zoekindex. Segmentgrootte en het aantal opgehaalde documenten bepalen samen hoeveel informatie (tokens) is opgenomen in de prompt die naar het model wordt verzonden. Over het algemeen is de segmentgrootte vermenigvuldigd met het aantal opgehaalde documenten het totale aantal tokens dat naar het model wordt verzonden.
Segmentgrootte instellen voor uw use-case
De standaardsegmentgrootte is 1024 tokens. Gezien de uniekheid van uw gegevens is het echter mogelijk dat u een andere segmentgrootte (zoals 256, 512 of 1536 tokens) effectiever vindt.
Door de segmentgrootte aan te passen, kunnen de prestaties van uw chatbot worden verbeterd. Bij het vinden van de optimale segmentgrootte is enige proef- en fout vereist, beginnend met het overwegen van de aard van uw gegevensset. Een kleinere segmentgrootte is over het algemeen beter voor gegevenssets met directe feiten en minder context, terwijl een grotere segmentgrootte nuttig kan zijn voor contextuelere informatie, hoewel dit van invloed kan zijn op de prestaties van het ophalen.
Een kleine segmentgrootte zoals 256 produceert gedetailleerdere segmenten. Deze grootte betekent ook dat het model minder tokens gebruikt om de uitvoer te genereren (tenzij het aantal opgehaalde documenten zeer hoog is), wat mogelijk minder kost. Kleinere segmenten betekenen ook dat het model geen lange tekstsecties hoeft te verwerken en te interpreteren, waardoor ruis en afleiding worden verminderd. Deze granulariteit en focus vormen echter een potentieel probleem. Belangrijke informatie bevindt zich mogelijk niet in de meest opgehaalde segmenten, met name als het aantal opgehaalde documenten is ingesteld op een lage waarde, zoals 3.
Aanbeveling
Houd er rekening mee dat het wijzigen van de segmentgrootte vereist dat uw documenten opnieuw worden opgenomen, dus het is handig om eerst runtimeparameters zoals striktheid en het aantal opgehaalde documenten aan te passen. Overweeg om de segmentgrootte te wijzigen als u nog steeds niet de gewenste resultaten krijgt:
- Als u een groot aantal antwoorden krijgt, zoals 'Ik weet het niet' voor vragen met antwoorden die in uw documenten moeten staan, kunt u overwegen om de segmentgrootte te verkleinen tot 256 of 512 om de granulariteit te verbeteren.
- Als de chatbot een aantal juiste details opgeeft, maar andere gegevens mist, wat zichtbaar wordt in de bronvermeldingen, kan het vergroten van de segmentgrootte tot 1536 helpen bij het vastleggen van meer contextuele informatie.
Parameters voor uitvoeringstijd
U kunt de volgende aanvullende instellingen wijzigen in de sectie Gegevensparameters in de Azure AI Foundry-portal en de API. U hoeft uw gegevens niet opnieuw op te nemen wanneer u deze parameters bijwerkt.
| Parameternaam | Beschrijving |
|---|---|
| Antwoorden beperken tot uw gegevens | Met deze vlag configureert u de aanpak van de chatbot voor het verwerken van query's die niet zijn gerelateerd aan de gegevensbron of wanneer zoekdocumenten onvoldoende zijn voor een volledig antwoord. Wanneer deze instelling is uitgeschakeld, vult het model de antwoorden aan met zijn eigen kennis naast uw documenten. Wanneer deze instelling is ingeschakeld, probeert het model alleen te vertrouwen op uw documenten voor antwoorden. Dit is de inScope parameter in de API en is standaard ingesteld op true. |
| Opgehaalde documenten | Deze parameter is een geheel getal dat kan worden ingesteld op 3, 5, 10 of 20 en bepaalt het aantal documentsegmenten dat is opgegeven aan het grote taalmodel voor het formuleren van het uiteindelijke antwoord. Dit is standaard ingesteld op 5. Het zoekproces kan luidruchtig zijn en soms, vanwege segmentering, kunnen relevante informatie worden verspreid over meerdere segmenten in de zoekindex. Als u een top-K-getal selecteert, zoals 5, zorgt u ervoor dat het model relevante informatie kan extraheren, ondanks de inherente beperkingen van zoeken en segmenteren. Als u het aantal te hoog verhoogt, kan het model echter mogelijk afleiden. Daarnaast is het maximum aantal documenten dat effectief kan worden gebruikt, afhankelijk van de versie van het model, omdat elk een andere contextgrootte en capaciteit heeft voor het verwerken van documenten. Als u merkt dat reacties belangrijke context missen, kunt u deze parameter verhogen. Dit is de topNDocuments parameter in de API en is standaard 5. |
| Gestrengheid | Bepaalt de sterkte van het systeem bij het filteren van zoekdocumenten op basis van hun overeenkomstenscores. Het systeem voert query's uit op Azure Search of andere documentarchieven en bepaalt vervolgens welke documenten moeten worden verstrekt aan grote taalmodellen, zoals ChatGPT. Het uitfilteren van irrelevante documenten kan de prestaties van de end-to-end chatbot aanzienlijk verbeteren. Sommige documenten worden uitgesloten van de top-K-resultaten als ze lage overeenkomstenscores hebben voordat ze naar het model worden doorgestuurd. Dit wordt bepaald door een geheel getal tussen 1 en 5. Als u deze waarde instelt op 1, betekent dit dat het systeem documenten minimaal filtert op basis van zoekopdrachten die vergelijkbaar zijn met de gebruikersquery. Omgekeerd geeft een instelling van 5 aan dat het systeem documenten agressief uitfiltert, waarbij een zeer hoge gelijkenisdrempel wordt toegepast. Als u merkt dat de chatbot relevante informatie weglaat, verlaagt u de striktheid van het filter (stel de waarde dichter bij 1 in) om meer documenten op te nemen. Als irrelevante documenten daarentegen de antwoorden afleiden, verhoogt u de drempelwaarde (stel de waarde dichter bij 5 in). Dit is de strictness parameter in de API en is standaard ingesteld op 3. |
Niet-aangesproken verwijzingen
Het is mogelijk dat het model wordt geretourneerd "TYPE":"UNCITED_REFERENCE" in plaats van "TYPE":CONTENT in de API voor documenten die worden opgehaald uit de gegevensbron, maar niet in de bronvermelding. Dit kan handig zijn voor foutopsporing en u kunt dit gedrag beheren door de striktheid en opgehaalde runtimeparameters voor documenten te wijzigen die hierboven worden beschreven.
Systeembericht
U kunt een systeembericht definiëren om het antwoord van het model te sturen wanneer u Azure OpenAI op uw gegevens gebruikt. Met dit bericht kunt u uw antwoorden aanpassen boven op het rag-patroon (Augmented Generation) ophalen dat door Azure OpenAI op uw gegevens wordt gebruikt. Het systeembericht wordt gebruikt naast een interne basisprompt om de ervaring te bieden. Ter ondersteuning hiervan kapen we het systeembericht af na een specifiek aantal tokens om ervoor te zorgen dat het model vragen kan beantwoorden met behulp van uw gegevens. Als u extra gedrag definieert boven op de standaardervaring, controleert u of uw systeemprompt gedetailleerd is en legt u de exacte verwachte aanpassing uit.
Zodra u uw gegevensset hebt toegevoegd, kunt u de sectie Systeembericht in de Azure AI Foundry-portal of de role_informationparameter in de API gebruiken.

Mogelijke gebruikspatronen
Een rol definiëren
U kunt een rol definiëren die u wilt gebruiken voor uw assistent. Als u bijvoorbeeld een ondersteuningsbot bouwt, kunt u 'U bent een deskundige ondersteuningsassistent voor incidenten waarmee gebruikers nieuwe problemen kunnen oplossen' toevoegen .
Het type gegevens definiëren dat wordt opgehaald
U kunt ook de aard van de gegevens die u aan assistent verstrekt, toevoegen.
- Definieer het onderwerp of het bereik van uw gegevensset, zoals 'financieel rapport', 'academisch document' of 'incidentrapport'. Voor technische ondersteuning kunt u bijvoorbeeld 'U beantwoordt query's toevoegen met behulp van gegevens uit vergelijkbare incidenten in de opgehaalde documenten.'
- Als uw gegevens bepaalde kenmerken hebben, kunt u deze details toevoegen aan het systeembericht. Als uw documenten zich bijvoorbeeld in het Japans bevinden, kunt u 'U haalt Japanse documenten op en u moet ze zorgvuldig lezen in het Japans en antwoorden in het Japans'.
- Als uw documenten gestructureerde gegevens bevatten zoals tabellen uit een financieel rapport, kunt u dit feit ook toevoegen aan de systeemprompt. Als uw gegevens bijvoorbeeld tabellen bevatten, kunt u 'U krijgt gegevens in de vorm van tabellen met betrekking tot financiële resultaten en u moet de tabelregel per regel lezen om berekeningen uit te voeren om vragen van gebruikers te beantwoorden'.
De uitvoerstijl definiëren
U kunt ook de uitvoer van het model wijzigen door een systeembericht te definiëren. Als u er bijvoorbeeld voor wilt zorgen dat de antwoorden van de assistent in het Frans zijn, kunt u een prompt toevoegen zoals 'U bent een AI-assistent waarmee gebruikers die Franse informatie zoeken begrijpen' kunnen begrijpen. De gebruikersvragen kunnen in het Engels of Frans zijn. Lees de opgehaalde documenten zorgvuldig en beantwoord ze in het Frans. Vertaal de kennis van documenten naar het Frans om ervoor te zorgen dat alle antwoorden in het Frans zijn."
Kritiek gedrag bevestigen
Azure OpenAI On Your Data werkt door instructies naar een groot taalmodel te verzenden in de vorm van prompts om gebruikersquery's te beantwoorden met behulp van uw gegevens. Als er een bepaald gedrag is dat essentieel is voor de toepassing, kunt u het gedrag in het systeembericht herhalen om de nauwkeurigheid ervan te vergroten. Als u bijvoorbeeld het model wilt begeleiden om alleen antwoord uit documenten te geven, kunt u 'Antwoord alleen beantwoorden met opgehaalde documenten en zonder uw kennis te gebruiken. Genereer bronvermeldingen om documenten op te halen voor elke claim in uw antwoord. Als de gebruikersvraag niet kan worden beantwoord met behulp van opgehaalde documenten, moet u de redenering achter waarom documenten relevant zijn voor gebruikersquery's uitleggen. Beantwoord in ieder geval niet met uw eigen kennis."
Prompt Engineering-trucs
Er zijn veel trucs in prompt engineering die u kunt proberen om de uitvoer te verbeteren. Een voorbeeld hiervan is een vraag om na te denken waar u stap voor stap kunt nadenken over informatie in opgehaalde documenten om gebruikersquery's te beantwoorden. Pak relevante kennis uit gebruikersquery's uit documenten stap voor stap uit en vorm een antwoord onderaan de geëxtraheerde informatie uit relevante documenten."
Opmerking
Het systeembericht wordt gebruikt om te wijzigen hoe GPT-assistent reageert op een gebruikersvraag op basis van de opgehaalde documentatie. Dit heeft geen invloed op het ophaalproces. Als u instructies wilt geven voor het ophaalproces, kunt u deze beter opnemen in de vragen. Het systeembericht is alleen richtlijnen. Het model voldoet mogelijk niet aan elke instructie die is opgegeven omdat het is voorzien van bepaald gedrag, zoals objectiviteit, en het vermijden van controversieel instructies. Onverwacht gedrag kan optreden als het systeembericht in strijd is met dit gedrag.
Antwoorden beperken tot uw gegevens
Deze optie moedigt het model aan om alleen te reageren met uw gegevens en is standaard geselecteerd. Als u deze optie uitschakelt, kan het model de interne kennis van het model gemakkelijker toepassen om te reageren. Bepaal de juiste selectie op basis van uw use-case en scenario.
Interactie met het model
Gebruik de volgende procedures voor de beste resultaten bij het chatten met het model.
Gespreksgeschiedenis
- Voordat u een nieuw gesprek start (of een vraag stelt die niet aan de vorige is gerelateerd), wist u de chatgeschiedenis.
- Het ophalen van verschillende antwoorden voor dezelfde vraag tussen de eerste gesprekswisseling en de volgende beurten kan worden verwacht omdat de gespreksgeschiedenis de huidige status van het model wijzigt. Als u onjuiste antwoorden ontvangt, meldt u het als een kwaliteitsfout.
Modelantwoord
Als u niet tevreden bent met het modelantwoord voor een specifieke vraag, kunt u de vraag specifieker of algemener maken om te zien hoe het model reageert en uw vraag dienovereenkomstig omkaderen.
Keten-van-gedachteprompt is gebleken dat het effectief is bij het verkrijgen van het model om gewenste uitvoer te produceren voor complexe vragen/taken.
Lengte van vraag
Vermijd het stellen van lange vragen en het opsplitsen ervan in meerdere vragen, indien mogelijk. De GPT-modellen hebben limieten voor het aantal tokens dat ze kunnen accepteren. Tokenlimieten worden geteld voor: de gebruikersvraag, het systeembericht, de opgehaalde zoekdocumenten (segmenten), interne prompts, de gespreksgeschiedenis (indien van toepassing) en het antwoord. Als de vraag de tokenlimiet overschrijdt, wordt deze afgekapt.
Meertalige ondersteuning
Op dit moment worden zoekopdrachten op trefwoorden en semantische zoekopdrachten in Azure OpenAI On Your Data ondersteund in dezelfde taal als de gegevens in de index. Als uw gegevens zich bijvoorbeeld in het Japans hebben, moeten invoerquery's ook in het Japans zijn. Voor het ophalen van kruislingse documenten raden we u aan om de index te bouwen met Vector search ingeschakeld.
Om de kwaliteit van het ophalen van gegevens en modelreacties te verbeteren, raden we u aan semantische zoekopdrachten in te schakelen voor de volgende talen: Engels, Frans, Spaans, Portugees, Italiaans, Duitsland, Chinees (Zh), Japans, Koreaans, Russisch, Arabisch
We raden u aan een systeembericht te gebruiken om het model te informeren dat uw gegevens zich in een andere taal bevinden. Voorbeeld:
*"*U bent een AI-assistent die is ontworpen om gebruikers te helpen bij het extraheren van informatie uit opgehaalde Japanse documenten. Controleer de Japanse documenten zorgvuldig voordat u een antwoord formuleert. De query van de gebruiker is in het Japans en u moet ook in het Japans reageren.
Als u documenten in meerdere talen hebt, raden we u aan voor elke taal een nieuwe index te maken en deze afzonderlijk te verbinden met Azure OpenAI.
Streaminggegevens
U kunt een streamingaanvraag verzenden met behulp van de stream parameter, zodat gegevens incrementeel kunnen worden verzonden en ontvangen zonder te wachten op het volledige API-antwoord. Dit kan de prestaties en gebruikerservaring verbeteren, met name voor grote of dynamische gegevens.
{
"stream": true,
"data_sources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Gespreksgeschiedenis voor betere resultaten
Wanneer u met een model chat, helpt het model om een geschiedenis van de chat op te geven, de resultaten van een hogere kwaliteit te retourneren. U hoeft de eigenschap van de context assistentberichten in uw API-aanvragen niet op te nemen voor een betere antwoordkwaliteit. Raadpleeg de API-referentiedocumentatie voor voorbeelden.
Functie aanroepen
Met sommige Azure OpenAI-modellen kunt u hulpprogramma's en tool_choice parameters definiëren om functie-aanroepen in te schakelen. U kunt functie-aanroepen instellen via REST API/chat/completions. Als beide tools en gegevensbronnen zich in de aanvraag bevinden, wordt het volgende beleid toegepast.
- Als
tool_choicedat het isnone, worden de hulpprogramma's genegeerd en worden alleen de gegevensbronnen gebruikt om het antwoord te genereren. -
tool_choiceAls dit niet het geval is of opgegeven alsautoof een object, worden de gegevensbronnen genegeerd en bevat het antwoord de naam van de geselecteerde functies en de argumenten, indien van toepassing. Zelfs als het model besluit dat er geen functie is geselecteerd, worden de gegevensbronnen nog steeds genegeerd.
Als het bovenstaande beleid niet aan uw behoeften voldoet, kunt u andere opties overwegen, bijvoorbeeld: promptstroom of assistent-API.
Schatting van tokengebruik voor Azure OpenAI op uw gegevens
Azure OpenAI On Your Data Retrieval Augmented Generation (RAG) is een service die gebruikmaakt van zowel een zoekservice (zoals Azure AI Search) als het genereren (Azure OpenAI-modellen) om gebruikers antwoord te geven op hun vragen op basis van opgegeven gegevens.
Als onderdeel van deze RAG-pijplijn zijn er drie stappen op hoog niveau:
Herformuleer de gebruikersquery in een lijst met zoekintenties. Dit wordt gedaan door een aanroep naar het model te maken met een prompt die instructies, de gebruikersvraag en gespreksgeschiedenis bevat. Laten we dit een intentieprompt noemen.
Voor elke intentie worden meerdere documentsegmenten opgehaald uit de zoekservice. Nadat u irrelevante segmenten hebt uitgefilterd op basis van de door de gebruiker opgegeven drempelwaarde voor striktheid en het opnieuw rangken/samenvoegen van de segmenten op basis van interne logica, wordt het door de gebruiker opgegeven aantal documentsegmenten gekozen.
Deze documentsegmenten, samen met de gebruikersvraag, gespreksgeschiedenis, rolgegevens en instructies, worden naar het model verzonden om het uiteindelijke modelantwoord te genereren. We noemen dit de generatieprompt.
In totaal worden er twee aanroepen gedaan naar het model:
Voor het verwerken van de intentie: de tokenraming voor de intentieprompt bevat de instructies voor de vraag van de gebruiker, de gespreksgeschiedenis en de instructies die naar het model worden verzonden voor het genereren van intenties.
Voor het genereren van het antwoord: De schatting van het token voor de generatieprompt bevat die voor de gebruikersvraag, gespreksgeschiedenis, de opgehaalde lijst met documentsegmenten, rolgegevens en de instructies die naar het bericht zijn verzonden voor het genereren.
Het model gegenereerde uitvoertokens (zowel intenties als reactie) moeten in aanmerking worden genomen voor de totale schatting van tokens. Als u alle vier de onderstaande kolommen optelt, krijgt u het gemiddelde totale aantal tokens dat wordt gebruikt voor het genereren van een antwoord.
| Modelleren | Aantal prompttoken genereren | Aantal intentieprompttoken | Aantal reactietoken | Aantal intentietoken |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | vijfentwintig |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
De bovenstaande getallen zijn gebaseerd op testen op een gegevensset met:
- 191 gesprekken
- 250 vragen
- 10 gemiddelde tokens per vraag
- 4 gespreksdraaiers per gesprek gemiddeld
En de volgende parameters.
| Configuratie | Waarde |
|---|---|
| Aantal opgehaalde documenten | 5 |
| Gestrengheid | 3 |
| Segmentgrootte | 1024 |
| Antwoorden beperken tot opgenomen gegevens? | Klopt |
Deze schattingen variëren op basis van de waarden die zijn ingesteld voor de bovenstaande parameters. Als het aantal opgehaalde documenten bijvoorbeeld is ingesteld op 10 en de strengheid is ingesteld op 1, gaat het aantal tokens omhoog. Als geretourneerde antwoorden niet beperkt zijn tot de opgenomen gegevens, zijn er minder instructies gegeven aan het model en gaat het aantal tokens omlaag.
De schattingen zijn ook afhankelijk van de aard van de documenten en vragen die worden gesteld. Als de vragen bijvoorbeeld open zijn, zijn de antwoorden waarschijnlijk langer. Op dezelfde manier zou een langer systeembericht bijdragen aan een langere prompt die meer tokens verbruikt, en als de gespreksgeschiedenis lang is, is de prompt langer.
| Modelleren | Maximum aantal tokens voor systeembericht |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
In de bovenstaande tabel ziet u het maximum aantal tokens dat kan worden gebruikt voor het systeembericht. Zie het artikel modellen om het maximum aantal tokens voor het modelantwoord weer te geven. Daarnaast verbruiken de volgende ook tokens:
De metaprompt: als u reacties van het model beperkt tot de inhoud van de grondgegevens (
inScope=Truein de API), is het maximum aantal tokens hoger. Anders (bijvoorbeeld alsinScope=False) het maximum lager is. Dit getal is variabel, afhankelijk van de tokenlengte van de gebruikersvraag en gespreksgeschiedenis. Deze schatting bevat de basisprompt en de prompts voor het herschrijven van query's voor het ophalen.Gebruikersvraag en geschiedenis: Variabele, maar beperkt tot 2000 tokens.
Opgehaalde documenten (segmenten): Het aantal tokens dat wordt gebruikt door de opgehaalde documentsegmenten, is afhankelijk van meerdere factoren. De bovengrens hiervoor is het aantal opgehaalde documentsegmenten vermenigvuldigd met de segmentgrootte. Deze wordt echter afgekapt op basis van de tokens die beschikbaar zijn voor het specifieke model dat wordt gebruikt na het tellen van de rest van de velden.
20% van de beschikbare tokens zijn gereserveerd voor het modelantwoord. De resterende 80% van de beschikbare tokens omvatten de metaprompt, de gebruikersvraag en gespreksgeschiedenis en het systeembericht. Het resterende tokenbudget wordt gebruikt door de opgehaalde documentsegmenten.
Gebruik het volgende codevoorbeeld om het aantal tokens te berekenen dat wordt verbruikt door uw invoer (zoals uw vraag, de informatie over het systeembericht/de rol).
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
Probleemoplossingsproces
Als u mislukte bewerkingen wilt oplossen, moet u altijd letten op fouten of waarschuwingen die zijn opgegeven in het API-antwoord of de Azure AI Foundry-portal. Hier volgen enkele veelvoorkomende fouten en waarschuwingen:
Mislukte opnametaken
Problemen met quotumbeperkingen
Er kan geen index met de naam X in service Y worden gemaakt. Het indexquotum is overschreden voor deze service. U moet eerst ongebruikte indexen verwijderen, een vertraging toevoegen tussen aanvragen voor het maken van de index of de service upgraden voor hogere limieten.
Het standaardindexeerquotum van X is overschreden voor deze service. U hebt momenteel X-standaardindexeerfuncties. U moet eerst ongebruikte indexeerfuncties verwijderen, de indexeerfunctie executionMode wijzigen of de service upgraden voor hogere limieten.
Resolutie:
Voer een upgrade uit naar een hogere prijscategorie of verwijder ongebruikte assets.
Time-outproblemen vooraf verwerken
Kan vaardigheid niet uitvoeren omdat de web-API-aanvraag is mislukt
Kan vaardigheid niet uitvoeren omdat het antwoord van web-API-vaardigheden ongeldig is
Resolutie:
De invoerdocumenten opsplitsen in kleinere documenten en het opnieuw proberen.
Problemen met machtigingen
Deze aanvraag is niet gemachtigd om deze bewerking uit te voeren
Resolutie:
Dit betekent dat het opslagaccount niet toegankelijk is met de opgegeven referenties. Controleer in dit geval de referenties van het opslagaccount die zijn doorgegeven aan de API en zorg ervoor dat het opslagaccount niet verborgen is achter een privé-eindpunt (als een privé-eindpunt niet is geconfigureerd voor deze resource).
503-fouten bij het verzenden van query's met Azure AI Search
Elk gebruikersbericht kan worden vertaald naar meerdere zoekquery's, die allemaal parallel naar de zoekresource worden verzonden. Dit kan beperkingsgedrag opleveren wanneer het aantal zoekreplica's en partities laag is. Het maximum aantal query's per seconde dat door één partitie en één replica kan worden ondersteund, is mogelijk niet voldoende. In dit geval kunt u overwegen om uw replica's en partities te verhogen of slaapstand-/nieuwe pogingslogica toe te voegen in uw toepassing. Raadpleeg de Documentatie voor Azure AI Search voor meer informatie.
Regionale beschikbaarheid en modelondersteuning
Opmerking
De volgende modellen worden niet ondersteund door Azure OpenAI op uw gegevens:
- o1-modellen
- o3-modellen
- modelrouter
| Regio | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Oost-Australië | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Canada Oost | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Oostelijke VS | ✅ | ✅ | ✅ | |||||
| Oostelijke Verenigde Staten 2 | ✅ | ✅ | ✅ | ✅ | ||||
| Centraal Frankrijk | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Oost-Japan | ✅ | |||||||
| Noord-Centraal VS | ✅ | ✅ | ✅ | |||||
| Noorwegen - oost | ✅ | ✅ | ||||||
| Zuid-Centraal Verenigde Staten | ✅ | ✅ | ||||||
| Zuid-India | ✅ | ✅ | ||||||
| Zweden - centraal | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Zwitserland - noord | ✅ | ✅ | ✅ | |||||
| Verenigd Koninkrijk Zuid | ✅ | ✅ | ✅ | ✅ | ||||
| Westelijke VS | ✅ | ✅ | ✅ |
**Dit is een alleen-tekst-implementatie
Als uw Azure OpenAI-resource zich in een andere regio bevindt, kunt u Azure OpenAI niet gebruiken op uw gegevens.