Architectuurbenaderingen voor AI en ML in multitenant-oplossingen
Een steeds groter aantal multitenant-oplossingen wordt gebouwd rond kunstmatige intelligentie (AI) en machine learning (ML). Een multitenant AI/ML-oplossing is een oplossing die vergelijkbare ML-mogelijkheden biedt voor een willekeurig aantal tenants. Tenants kunnen in het algemeen de gegevens van een andere tenant niet zien of delen, maar in sommige gevallen kunnen tenants dezelfde modellen gebruiken als andere tenants.
Multitenant AI/ML-architecturen moeten rekening houden met de vereisten voor gegevens en modellen, evenals de rekenresources die nodig zijn voor het trainen van modellen en het uitvoeren van deductie van modellen. Het is belangrijk om na te gaan hoe ai-/ML-modellen met meerdere tenants worden geïmplementeerd, gedistribueerd en ingedeeld, en om ervoor te zorgen dat uw oplossing nauwkeurig, betrouwbaar en schaalbaar is.
Belangrijke overwegingen en vereisten
Wanneer u met AI en ML werkt, is het belangrijk om afzonderlijk rekening te houden met uw vereisten voor training en voor deductie. Het doel van training is het bouwen van een voorspellend model dat is gebaseerd op een set gegevens. U voert deductie uit wanneer u het model gebruikt om iets in uw toepassing te voorspellen. Elk van deze processen heeft verschillende vereisten. In een multitenant-oplossing moet u overwegen hoe uw tenancymodel van invloed is op elk proces. Door rekening te houden met elk van deze vereisten, kunt u ervoor zorgen dat uw oplossing nauwkeurige resultaten biedt, goed onder belasting presteert, kostenefficiënt is en kan worden geschaald voor uw toekomstige groei.
Isolatie van tenants
Zorg ervoor dat tenants geen onbevoegde of ongewenste toegang krijgen tot de gegevens of modellen van andere tenants. Behandel modellen met een vergelijkbare gevoeligheid voor de onbewerkte gegevens die ze hebben getraind. Zorg ervoor dat uw tenants begrijpen hoe hun gegevens worden gebruikt om modellen te trainen en hoe modellen die zijn getraind op gegevens van andere tenants, kunnen worden gebruikt voor deductiedoeleinden voor hun workloads.
Er zijn drie algemene benaderingen voor het werken met ML-modellen in multitenant-oplossingen: tenantspecifieke modellen, gedeelde modellen en afgestemde gedeelde modellen.
Tenantspecifieke modellen
Tenantspecifieke modellen worden alleen getraind op de gegevens voor één tenant en vervolgens worden ze toegepast op die ene tenant. Tenantspecifieke modellen zijn geschikt wanneer de gegevens van uw tenants gevoelig zijn of wanneer er weinig bereik is om te leren van de gegevens die door de ene tenant worden geleverd en u het model toepast op een andere tenant. In het volgende diagram ziet u hoe u een oplossing kunt bouwen met tenantspecifieke modellen voor twee tenants:
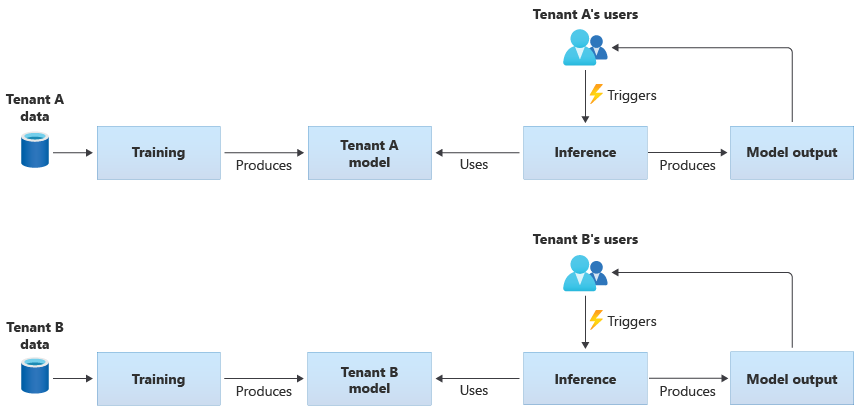
Gedeelde modellen
In oplossingen die gebruikmaken van gedeelde modellen, voeren alle tenants deductie uit op basis van hetzelfde gedeelde model. Gedeelde modellen kunnen vooraf getrainde modellen zijn die u verkrijgt of verkrijgt van een communitybron. In het volgende diagram ziet u hoe één vooraf getraind model kan worden gebruikt voor deductie door alle tenants:
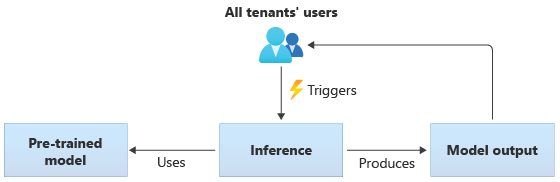
U kunt ook uw eigen gedeelde modellen bouwen door ze te trainen op basis van de gegevens van al uw tenants. In het volgende diagram ziet u één gedeeld model, dat wordt getraind op gegevens van alle tenants:
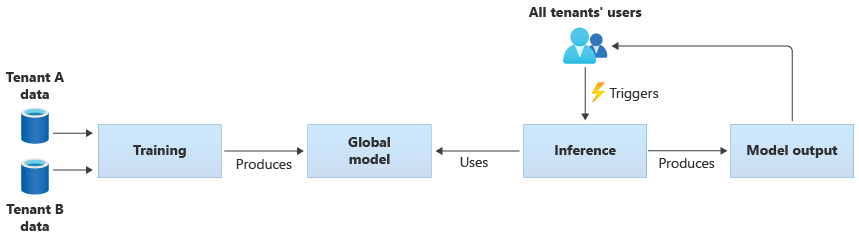
Belangrijk
Als u een gedeeld model traint op basis van de gegevens van uw tenants, moet u ervoor zorgen dat uw tenants het gebruik van hun gegevens begrijpen en ermee akkoord gaan. Zorg ervoor dat de identificatiegegevens worden verwijderd uit de gegevens van uw tenants.
Bedenk wat u moet doen als een tenantobjecten op hun gegevens worden gebruikt om een model te trainen dat wordt toegepast op een andere tenant. Kunt u bijvoorbeeld de gegevens van specifieke tenants uitsluiten van de trainingsgegevensset?
Gedeelde modellen afgestemd
U kunt er ook voor kiezen om een vooraf getraind basismodel te verkrijgen en vervolgens verdere modelafstemming uit te voeren om deze van toepassing te maken op elk van uw tenants, op basis van hun eigen gegevens. In het volgende diagram ziet u deze benadering:
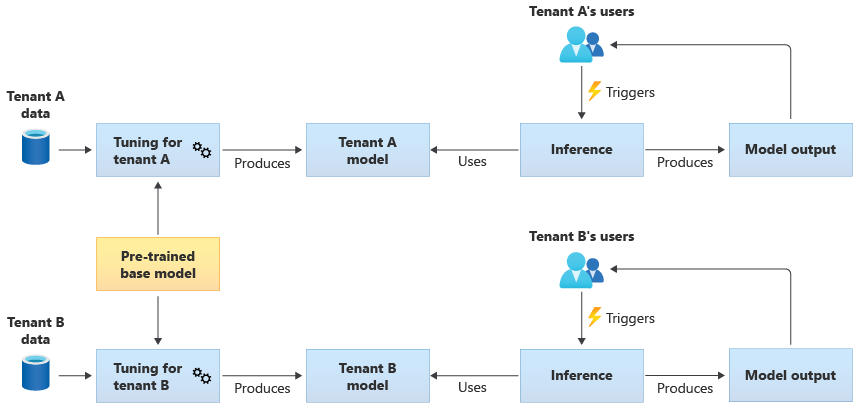
Schaalbaarheid
Bedenk hoe de groei van uw oplossing van invloed is op uw gebruik van AI- en ML-onderdelen. Groei kan verwijzen naar een toename van het aantal tenants, de hoeveelheid gegevens die is opgeslagen voor elke tenant, het aantal gebruikers en het aantal aanvragen voor uw oplossing.
Training: Er zijn verschillende factoren die van invloed zijn op de resources die nodig zijn om uw modellen te trainen. Deze factoren omvatten het aantal modellen waarmee u moet trainen, de hoeveelheid gegevens waarmee u de modellen traint en de frequentie waarmee u modellen traint of opnieuw traint. Als u tenantspecifieke modellen maakt, neemt de hoeveelheid rekenresources en opslag die u nodig hebt, waarschijnlijk ook toe naarmate uw aantal tenants toeneemt. Als u gedeelde modellen maakt en traint op basis van gegevens van al uw tenants, is het minder waarschijnlijk dat de resources voor training worden geschaald met hetzelfde tarief als de groei in uw aantal tenants. Een toename van de totale hoeveelheid trainingsgegevens is echter van invloed op de resources die worden verbruikt, om zowel de gedeelde als tenantspecifieke modellen te trainen.
Deductie: de resources die nodig zijn voor deductie, zijn meestal evenredig met het aantal aanvragen dat toegang heeft tot de modellen voor deductie. Naarmate het aantal tenants toeneemt, neemt het aantal aanvragen waarschijnlijk ook toe.
Het is een goede gewoonte om Azure-services te gebruiken die goed worden geschaald. Omdat AI/ML-workloads vaak gebruikmaken van containers, zijn AKS -workloads (Azure Kubernetes Service) en Azure Container Instances (ACI) meestal algemene keuzes voor AI/ML-workloads. AKS is meestal een goede keuze om grootschalige schaal mogelijk te maken en uw rekenresources dynamisch te schalen op basis van vraag. Voor kleine workloads kan ACI een eenvoudig rekenplatform zijn om te configureren, hoewel het niet zo eenvoudig kan worden geschaald als AKS.
Prestaties
Houd rekening met de prestatievereisten voor de AI/ML-onderdelen van uw oplossing, voor zowel training als deductie. Het is belangrijk om uw latentie- en prestatievereisten voor elk proces te verduidelijken, zodat u naar behoefte kunt meten en verbeteren.
Training: Training wordt vaak uitgevoerd als een batchproces, wat betekent dat het mogelijk niet zo prestatiegevoelig is als andere onderdelen van uw workload. U moet er echter voor zorgen dat u voldoende resources inricht om uw modeltraining efficiënt uit te voeren, inclusief wanneer u schaalt.
Deductie: deductie is een latentiegevoelig proces, waarbij vaak een snelle of zelfs realtime reactie nodig is. Zelfs als u deductie niet in realtime hoeft uit te voeren, moet u ervoor zorgen dat u de prestaties van uw oplossing bewaakt en de juiste services gebruikt om uw workload te optimaliseren.
Overweeg om de krachtige computingmogelijkheden van Azure te gebruiken voor uw AI- en ML-workloads. Azure biedt veel verschillende typen virtuele machines en andere hardware-exemplaren. Overweeg of uw oplossing baat heeft bij het gebruik van CPU's, GPU's, FPGA's of andere hardware-versnelde omgevingen. Azure biedt ook realtime deductie met NVIDIA GPU's, waaronder NVIDIA Triton Inference Servers. Voor rekenvereisten met lage prioriteit kunt u overwegen om AKS-spot-knooppuntgroepen te gebruiken. Zie Architectuurbenaderingen voor berekeningen in multitenant-oplossingen voor meer informatie over het optimaliseren van rekenservices in multitenant-oplossingen.
Modeltraining vereist doorgaans veel interacties met uw gegevensarchieven, dus het is ook belangrijk om rekening te houden met uw gegevensstrategie en de prestaties die uw gegevenslaag biedt. Zie Architectuurbenaderingen voor opslag en gegevens in multitenant-oplossingen voor meer informatie over multitenancy- en gegevensservices.
Overweeg om de prestaties van uw oplossing te profileren. Azure Machine Learning biedt bijvoorbeeld profileringsmogelijkheden die u kunt gebruiken bij het ontwikkelen en instrumenteren van uw oplossing.
Implementatiecomplexiteit
Wanneer u een oplossing bouwt voor het gebruik van AI en ML, kunt u ervoor kiezen om vooraf gemaakte onderdelen te gebruiken of om aangepaste onderdelen te bouwen. Er zijn twee belangrijke beslissingen die u moet nemen. De eerste is het platform of de service die u gebruikt voor AI en ML. De tweede is of u vooraf getrainde modellen gebruikt of uw eigen aangepaste modellen bouwt.
Platforms: Er zijn veel Azure-services die u kunt gebruiken voor uw AI- en ML-workloads. Azure Cognitive Services en Azure OpenAI Service bieden bijvoorbeeld API's voor het uitvoeren van deductie op basis van vooraf gedefinieerde modellen en Microsoft beheert de onderliggende resources. Met Azure Cognitive Services kunt u snel een nieuwe oplossing implementeren, maar u hebt minder controle over de manier waarop training en deductie worden uitgevoerd, en dit past mogelijk niet bij elk type workload. Azure Machine Learning is daarentegen een platform waarmee u uw eigen ML-modellen kunt bouwen, trainen en gebruiken. Azure Machine Learning biedt controle en flexibiliteit, maar het verhoogt de complexiteit van uw ontwerp en implementatie. Bekijk de machine learning-producten en -technologieën van Microsoft om een weloverwogen beslissing te nemen bij het selecteren van een benadering.
Modellen: Zelfs als u geen volledig model gebruikt dat wordt geleverd door een service zoals Azure Cognitive Services, kunt u uw ontwikkeling nog steeds versnellen met behulp van een vooraf getraind model. Als een vooraf getraind model niet precies aan uw behoeften voldoet, kunt u overwegen om een vooraf getraind model uit te breiden door een techniek toe te passen, leren of af te stemmen. Met leren overdragen kunt u een bestaand model uitbreiden en toepassen op een ander domein. Als u bijvoorbeeld een multitenant muziekaanbevelingsservice bouwt, kunt u overwegen om een vooraf getraind model van muziekaanbeveling op te bouwen en gebruik overdrachtsleer om het model te trainen voor de muziekvoorkeuren van een specifieke gebruiker.
Met behulp van een vooraf samengesteld ML-platform, zoals Azure Cognitive Services of Azure OpenAI Service, of een vooraf getraind model, kunt u de initiële kosten voor onderzoek en ontwikkeling aanzienlijk verlagen. Het gebruik van vooraf samengestelde platforms kan u vele maanden aan onderzoek besparen en de noodzaak om hooggekwalificeerde gegevenswetenschappers te werven om modellen te trainen, ontwerpen en optimaliseren.
Kostenoptimalisatie
Over het algemeen maken AI- en ML-workloads het grootste deel van hun kosten uit de rekenresources die nodig zijn voor modeltraining en -deductie. Bekijk architectuurbenaderingen voor berekeningen in oplossingen met meerdere tenants om te begrijpen hoe u de kosten van uw rekenworkload kunt optimaliseren voor uw vereisten.
Houd rekening met de volgende vereisten bij het plannen van uw AI- en ML-kosten:
- Bepaal reken-SKU's voor training. Raadpleeg bijvoorbeeld richtlijnen voor hoe u dit doet met Azure Machine Learning.
- Bepaal reken-SKU's voor deductie. Raadpleeg de richtlijnen voor Azure Machine Learning voor een voorbeeld van een kostenraming voor deductie.
- Bewaak uw gebruik. Door het gebruik van uw rekenresources te observeren, kunt u bepalen of u de capaciteit moet verlagen of vergroten door verschillende SKU's te implementeren of de rekenresources te schalen wanneer uw vereisten veranderen. Zie Azure Machine Learning Monitor.
- Optimaliseer uw rekenclusteromgeving. Wanneer u rekenclusters gebruikt, bewaakt u het clustergebruik of configureert u automatisch schalen om rekenknooppunten omlaag te schalen .
- Deel uw rekenresources. Overweeg of u de kosten van uw rekenresources kunt optimaliseren door ze te delen in meerdere tenants.
- Houd rekening met uw budget. Begrijp of u een vast budget hebt en bewaak uw verbruik dienovereenkomstig. U kunt budgetten instellen om overbesteding te voorkomen en quota toe te wijzen op basis van tenantprioriteit.
Benaderingen en patronen om rekening mee te houden
Azure biedt een set services voor het inschakelen van AI- en ML-workloads. Er zijn verschillende algemene architectuurmethoden die worden gebruikt in multitenant-oplossingen: voor het gebruik van vooraf gedefinieerde AI/ML-oplossingen, voor het bouwen van een aangepaste AI/ML-architectuur met behulp van Azure Machine Learning en voor het gebruik van een van de Azure-analyseplatforms.
Vooraf gemaakte AI/ML-services gebruiken
Het is een goede gewoonte om vooraf gemaakte AI/ML-services te gebruiken, waar u dat kunt. Uw organisatie kan bijvoorbeeld beginnen met het bekijken van AI/ML en snel willen integreren met een nuttige service. Of misschien hebt u basisvereisten waarvoor geen aangepaste ML-modeltraining en -ontwikkeling is vereist. Met vooraf gemaakte ML-services kunt u deductie gebruiken zonder uw eigen modellen te bouwen en te trainen.
Azure biedt verschillende services die AI- en ML-technologie bieden voor verschillende domeinen, waaronder taalbegrip, spraakherkenning, kennis, document- en formulierherkenning en computer vision. De vooraf gebouwde AI/ML-services van Azure omvatten Azure Cognitive Services, Azure OpenAI Service, Azure Cognitive Search en Azure Form Recognizer. Elke service biedt een eenvoudige interface voor integratie en een verzameling vooraf getrainde en geteste modellen. Als beheerde services bieden ze serviceovereenkomsten en vereisen weinig configuratie of doorlopend beheer. U hoeft uw eigen modellen niet te ontwikkelen of te testen om deze services te gebruiken.
Veel beheerde ML-services vereisen geen modeltraining of -gegevens, dus er zijn meestal geen problemen met isolatie van tenantgegevens. Wanneer u echter met Cognitive Search in een multitenant-oplossing werkt, controleert u ontwerppatronen voor SaaS-toepassingen met meerdere tenants en Azure Cognitive Search.
Houd rekening met de schaalvereisten voor de onderdelen in uw oplossing. Veel API's binnen Azure Cognitive Services ondersteunen bijvoorbeeld een maximum aantal aanvragen per seconde. Als u één Cognitive Services-resource implementeert om te delen tussen uw tenants, moet u mogelijk naar meerdere resources schalen naarmate het aantal tenants toeneemt.
Notitie
Met sommige beheerde services kunt u trainen met uw eigen gegevens, waaronder de Custom Vision-service, de Face-API, aangepaste Form Recognizer-modellen en sommige OpenAI-modellen die ondersteuning bieden voor aanpassing en fine-tunning. Wanneer u met deze services werkt, is het belangrijk om rekening te houden met de isolatievereisten voor de gegevens van uw tenants.
Aangepaste AI/ML-architectuur
Als uw oplossing aangepaste modellen vereist of als u in een domein werkt dat niet wordt gedekt door een beheerde ML-service, kunt u overwegen uw eigen AI/ML-architectuur te bouwen. Azure Machine Learning biedt een reeks mogelijkheden voor het organiseren van de training en implementatie van ML-modellen. Azure Machine Learning ondersteunt veel opensource-machine learning-bibliotheken, waaronder PyTorch, Tensorflow, Scikit en Keras. U kunt continu de prestatiegegevens van modellen bewaken, gegevensdrift detecteren en opnieuw trainen activeren om de modelprestaties te verbeteren. Gedurende de levenscyclus van uw ML-modellen maakt Azure Machine Learning controlebaarheid en governance mogelijk met ingebouwde tracering en herkomst voor al uw ML-artefacten.
Wanneer u in een multitenant-oplossing werkt, is het belangrijk om rekening te houden met de isolatievereisten van uw tenants tijdens zowel de trainings- als deductiefase. U moet ook het modeltrainings- en implementatieproces bepalen. Azure Machine Learning biedt een pijplijn voor het trainen van modellen en voor het implementeren ervan in een omgeving die moet worden gebruikt voor deductie. Overweeg in een context met meerdere tenants of modellen moeten worden geïmplementeerd op gedeelde rekenresources of of elke tenant toegewezen resources heeft. Ontwerp uw modelimplementatiepijplijnen op basis van uw isolatiemodel en uw tenantimplementatieproces.
Wanneer u opensource-modellen gebruikt, moet u deze modellen mogelijk opnieuw trainen met behulp van het leren of afstemmen van overdrachten. Bedenk hoe u de verschillende modellen en trainingsgegevens voor elke tenant en versies van het model beheert.
In het volgende diagram ziet u een voorbeeldarchitectuur die gebruikmaakt van Azure Machine Learning. In het voorbeeld wordt de isolatiebenadering van tenantspecifieke modellen gebruikt.
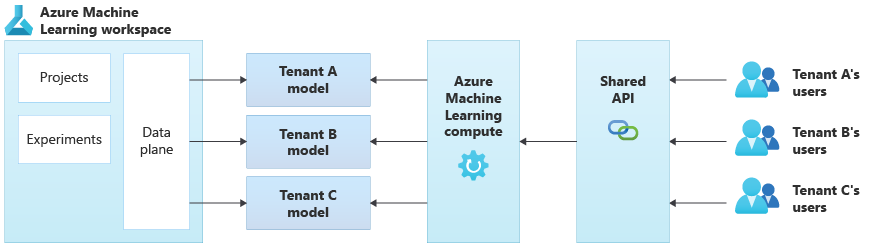
Geïntegreerde AI/ML-oplossingen
Azure biedt verschillende krachtige analyseplatforms die kunnen worden gebruikt voor verschillende doeleinden. Deze platforms omvatten Azure Synapse Analytics, Databricks en Apache Spark.
U kunt overwegen deze platforms voor AI/ML te gebruiken wanneer u uw ML-mogelijkheden moet schalen naar een zeer groot aantal tenants en wanneer u grootschalige reken- en indelingsfuncties nodig hebt. U kunt ook overwegen deze platforms voor AI/ML te gebruiken wanneer u een breed analyseplatform nodig hebt voor andere onderdelen van uw oplossing, zoals voor gegevensanalyse en integratie met rapportage via Microsoft Power BI. U kunt één platform implementeren dat betrekking heeft op al uw analyses en AI/ML-behoeften. Wanneer u gegevensplatforms in een multitenant-oplossing implementeert, bekijkt u architectuurbenaderingen voor opslag en gegevens in multitenant-oplossingen.
Antipatroon om te voorkomen
- Kan geen isolatievereisten overwegen. Het is belangrijk om zorgvuldig na te denken over hoe u de gegevens en modellen van tenants kunt isoleren, zowel voor training als deductie. Als u dit niet doet, kunnen wettelijke of contractuele vereisten worden geschonden. Het kan ook de nauwkeurigheid van uw modellen verminderen om te trainen over de gegevens van meerdere tenants, als de gegevens aanzienlijk verschillen.
- Luidruchtige buren. Overweeg of uw trainings- of deductieprocessen kunnen worden onderworpen aan het probleem van Noisy Neighbor. Als u bijvoorbeeld meerdere grote tenants en één kleine tenant hebt, moet u ervoor zorgen dat de modeltraining voor de grote tenants niet per ongeluk alle rekenresources verbruikt en de kleinere tenants verhongert. Gebruik resourcebeheer en bewaking om het risico te beperken van de rekenworkload van een tenant die wordt beïnvloed door de activiteit van de andere tenants.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- Kevin Ashley | Senior klanttechnicus, FastTrack voor Azure
Andere Inzenders:
- Paul Burpo | Principal Customer Engineer, FastTrack voor Azure
- John Downs | Principal Software Engineer
- Daniel Scott-Raynsford | PartnerTechnologie Strategist
- Arsen Vladimirskiy | Principal Customer Engineer, FastTrack voor Azure
Volgende stappen
- Bekijk architectuurbenaderingen voor berekening in oplossingen met meerdere tenants.
- Zie A Solution for ML Pipeline op multitenancy voor meer informatie over het ontwerpen van Azure Machine Learning-pijplijnen ter ondersteuning van meerdere tenants.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor