In dit artikel wordt een architectuur beschreven die gebruikmaakt van Azure Machine Learning om delinquency en de standaardkans van aanvragers van leningen te voorspellen. De voorspellingen van het model zijn gebaseerd op het fiscale gedrag van de aanvrager. Het model maakt gebruik van een enorme set gegevenspunten om aanvragers te classificeren en een geschiktheidsscore te bieden voor elke aanvrager.
Apache®, Spark en het vlamlogo zijn geregistreerde handelsmerken of handelsmerken van de Apache Software Foundation in de Verenigde Staten en/of andere landen. Er wordt geen goedkeuring door de Apache Software Foundation geïmpliceerd door het gebruik van deze markeringen.
Architectuur

Een Visio-bestand van deze architectuur downloaden.
Gegevensstroom
De volgende gegevensstroom komt overeen met het voorgaande diagram:
Opslag: gegevens worden opgeslagen in een database zoals een Azure Synapse Analytics-pool als deze is gestructureerd. Oudere SQL-databases kunnen in het systeem worden geïntegreerd. Semi-gestructureerde en ongestructureerde gegevens kunnen in een data lake worden geladen.
Opname en voorverwerking: Azure Synapse Analytics-verwerkingspijplijnen en ETL-verwerking kunnen verbinding maken met gegevens die zijn opgeslagen in Azure- of externe bronnen via ingebouwde connectors. Azure Synapse Analytics ondersteunt meerdere analysemethoden die gebruikmaken van SQL, Spark, Azure Data Explorer en Power BI. U kunt ook bestaande Azure Data Factory-indeling gebruiken voor de gegevenspijplijnen.
Verwerking: Azure Machine Learning wordt gebruikt voor het ontwikkelen en beheren van de machine learning-modellen.
Initiële verwerking: tijdens deze fase worden onbewerkte gegevens verwerkt om een gecureerde gegevensset te maken waarmee een machine learning-model wordt getraind. Typische bewerkingen zijn onder andere gegevenstypeopmaak, imputatie van ontbrekende waarden, functie-engineering, functieselectie en dimensionaliteitsvermindering.
Training: Tijdens de trainingsfase gebruikt Azure Machine Learning de verwerkte gegevensset om het kredietrisicomodel te trainen en het beste model te selecteren.
Modeltraining: U kunt een reeks machine learning-modellen gebruiken, waaronder klassieke machine learning- en Deep Learning-modellen. U kunt hyperparameterafstemming gebruiken om de modelprestaties te optimaliseren.
Modelevaluatie: Azure Machine Learning evalueert de prestaties van elk getraind model, zodat u het beste voor implementatie kunt selecteren.
Modelregistratie: u registreert het model dat het beste presteert in Azure Machine Learning. Met deze stap maakt u het model beschikbaar voor implementatie.
c. Verantwoorde AI: Verantwoorde AI is een benadering voor het ontwikkelen, beoordelen en implementeren van AI-systemen op een veilige, betrouwbare en ethische manier. Omdat met dit model een goedkeurings- of weigeringsbeslissing voor een leningsaanvraag wordt afgeleid, moet u de principes van Verantwoorde AI implementeren.
Metrische gegevens over redelijkheid beoordelen het effect van oneerlijk gedrag en maken risicobeperkingsstrategieën mogelijk. Gevoelige functies en kenmerken worden geïdentificeerd in de gegevensset en in cohorten (subsets) van de gegevens. Zie Modelprestaties en -billijkheid voor meer informatie.
Interpreteerbaarheid is een meting van hoe goed u het gedrag van een machine learning-model kunt begrijpen. Dit onderdeel van Responsible AI genereert begrijpelijke beschrijvingen van de voorspellingen van het model. Zie Modelinterpretabiliteit voor meer informatie.
Realtime machine learning-implementatie: u moet realtime modeldeductie gebruiken wanneer de aanvraag onmiddellijk moet worden gecontroleerd voor goedkeuring.
- Beheerd online-eindpunt voor machine learning. Voor realtime scoren moet u een geschikt rekendoel kiezen.
- Onlineaanvragen voor leningen maken gebruik van realtime scoren op basis van invoer van het aanvragerformulier of de aanvraag voor leningen.
- De beslissing en de invoer die wordt gebruikt voor het scoren van modellen, worden opgeslagen in permanente opslag en kunnen worden opgehaald voor toekomstige naslaginformatie.
Batch machine learning-implementatie: Voor offlineleningsverwerking wordt het model gepland om regelmatig te worden geactiveerd.
- Beheerd batch-eindpunt. Batchdeductie wordt gepland en de resultaatgegevensset wordt gemaakt. Besluiten zijn gebaseerd op de kredietwaardigheid van de aanvrager.
- De resultatenset van scoren van batchverwerking wordt bewaard in de database of het Azure Synapse Analytics-datawarehouse.
Interface voor gegevens over de activiteit van de aanvrager: de gegevensinvoer door de aanvrager, het interne kredietprofiel en de beslissing van het model worden allemaal gefaseerd en opgeslagen in de juiste gegevensservices. Deze details worden gebruikt in de beslissingsengine voor toekomstige scoren, zodat ze worden gedocumenteerd.
- Opslag: alle details van kredietverwerking worden bewaard in permanente opslag.
- Gebruikersinterface: De goedkeurings- of weigeringsbeslissing wordt aan de aanvrager gepresenteerd.
Rapportage: realtime inzichten over het aantal verwerkte en goedkeuren of weigeren resultaten van toepassingen worden continu gepresenteerd aan managers en leidinggevenden. Voorbeelden van rapportage zijn bijna realtime rapporten van goedgekeurde bedragen, de gemaakte leningportefeuille en modelprestaties.
Onderdelen
- Azure Blob Storage biedt schaalbare objectopslag voor ongestructureerde gegevens. Het is geoptimaliseerd voor het opslaan van bestanden zoals binaire bestanden, activiteitenlogboeken en bestanden die niet voldoen aan een specifieke indeling.
- Azure Data Lake Storage is de opslagbasis voor het maken van rendabele data lakes in Azure. Het biedt blob-opslag met een hiërarchische mapstructuur en verbeterde prestaties, beheer en beveiliging. Het biedt meerdere petabytes aan informatie en ondersteunt honderden gigabits aan doorvoer.
- Azure Synapse Analytics is een analyseservice die het beste van SQL- en Spark-technologieën en een uniforme gebruikerservaring voor Azure Synapse Data Explorer en pijplijnen combineert. Het is geïntegreerd met Power BI, Azure Cosmos DB en Azure Machine Learning. De service ondersteunt zowel toegewezen als serverloze resourcemodellen en de mogelijkheid om tussen deze modellen te schakelen.
- Azure SQL Database is een altijd up-to-date, volledig beheerde relationele database die is gebouwd voor de cloud.
- Azure Machine Learning is een cloudservice voor het beheren van de levenscyclus van machine learning-projecten. Het biedt een geïntegreerde omgeving voor gegevensverkenning, modelbouw en -beheer en implementatie en biedt ondersteuning voor code-first- en low-code-/no-code-benaderingen voor machine learning.
- Power BI is een visualisatieprogramma dat eenvoudige integratie met Azure-resources biedt.
- met Azure-app Service kunt u web-apps, mobiele back-ends en RESTful-API's bouwen en hosten zonder infrastructuur te beheren. Ondersteunde talen zijn .NET, .NET Core, Java, Ruby, Node.js, PHP en Python.
Alternatieven
U kunt Azure Databricks gebruiken om machine learning-modellen en analyseworkloadste ontwikkelen, implementeren en beheren. De service biedt een uniforme omgeving voor modelontwikkeling.
Scenariodetails
Organisaties in de financiële sector moeten het kredietrisico voorspellen van personen of bedrijven die krediet aanvragen. Dit model evalueert delinquency en de standaardkans van aanvragers van leningen.
Kredietrisicovoorspelling omvat een grondige analyse van populatiegedrag en classificatie van het klantenbestand in segmenten op basis van fiscale verantwoordelijkheid. Andere variabelen omvatten marktfactoren en economische omstandigheden, die een aanzienlijke invloed hebben op de resultaten.
Uitdagingen. Invoergegevens omvatten tientallen miljoenen klantprofielen en gegevens over klantkredietgedrag en bestedingsgewoonten die zijn gebaseerd op miljarden records van verschillende systemen, zoals interne klantactiviteitensystemen. De gegevens van derden over economische omstandigheden en de marktanalyse van het land/de regio kunnen afkomstig zijn van maandelijkse of driemaandelijkse momentopnamen waarvoor het laden en onderhouden van honderden GB's aan bestanden is vereist. Kredietbureaugegevens over de aanvrager of semi-gestructureerde rijen klantgegevens, en kruiskoppelingen tussen deze gegevenssets en kwaliteitscontroles om de integriteit van de gegevens te valideren, zijn nodig.
De gegevens bestaan meestal uit tabellen in brede kolommen met klantgegevens van kredietbureaus, samen met marktanalyse. De klantactiviteit bestaat uit records met dynamische indeling die mogelijk niet gestructureerd is. Gegevens zijn ook beschikbaar in vrije tekst uit de notities van de klantenservice en formulieren voor interactie tussen aanvragers.
Het verwerken van deze grote hoeveelheden gegevens en ervoor zorgen dat de resultaten actueel zijn, vereist gestroomlijnde verwerking. U hebt een opslag met lage latentie nodig en het proces voor ophalen. De gegevensinfrastructuur moet kunnen worden geschaald om verschillende gegevensbronnen te ondersteunen en de mogelijkheid te bieden om de gegevensperimeter te beheren en te beveiligen. Het Machine Learning-platform moet ondersteuning bieden voor de complexe analyse van de vele modellen die worden getraind, getest en gevalideerd in veel populatiesegmenten.
Vertrouwelijkheid en privacy van gegevens. De gegevensverwerking voor dit model omvat persoonlijke gegevens en demografische gegevens. U moet de profilering van populaties vermijden. Directe zichtbaarheid van alle persoonsgegevens moet worden beperkt. Voorbeelden van persoonsgegevens zijn rekeningnummers, creditcardgegevens, burgerservicenummers, namen, adressen en postcodes.
Creditcard- en bankrekeningnummers moeten altijd worden verborgen. Bepaalde gegevenselementen moeten worden gemaskeerd en altijd versleuteld, waardoor er geen toegang wordt geboden tot de onderliggende informatie, maar beschikbaar is voor analyse.
Gegevens moeten in rust, tijdens overdracht en tijdens de verwerking via beveiligde enclaves worden versleuteld. Toegang tot gegevensitems wordt vastgelegd in een bewakingsoplossing. Het productiesysteem moet worden ingesteld met de juiste CI/CD-pijplijnen met goedkeuringen die modelimplementaties en -processen activeren. Controle van de logboeken en werkstroom moet de interacties met de gegevens bieden voor eventuele nalevingsbehoeften.
In verwerking. Voor dit model is een hoge rekenkracht vereist voor analyse, contextualisatie en modeltraining en -implementatie. Modelscores worden gevalideerd op basis van willekeurige steekproeven om ervoor te zorgen dat kredietbeslissingen geen ras-, geslacht-, etnische of geografische locatie-vooroordelen bevatten. Het beslissingsmodel moet worden gedocumenteerd en gearchiveerd voor toekomstige naslaginformatie. Elke factor die betrokken is bij de beslissingsresultaten, wordt opgeslagen.
Gegevensverwerking vereist een hoog CPU-gebruik. Het omvat SQL-verwerking van gestructureerde gegevens in DB- en JSON-indeling, Spark-verwerking van de gegevensframes of big data-analyses op terabytes aan informatie in verschillende documentindelingen. Gegevens-ELT-/ETL-taken worden gepland of geactiveerd met regelmatige intervallen of in realtime, afhankelijk van de waarde van de meest recente gegevens.
Nalevings- en regelgevingskader. Elk detail van de verwerking van leningen moet worden gedocumenteerd, inclusief de ingediende toepassing, de functies die worden gebruikt bij het scoren van modellen en de resultatenset van het model. Modeltrainingsgegevens, gegevens die worden gebruikt voor training en trainingsresultaten moeten worden geregistreerd voor toekomstige referentie- en controle- en nalevingsaanvragen.
Batch versus realtime scoren. Bepaalde taken zijn proactief en kunnen worden verwerkt als batchtaken, zoals vooraf goedgekeurde saldooverdrachten. Voor sommige aanvragen, zoals toename van onlinetegoedregel, is realtime goedkeuring vereist.
Realtime toegang tot de status van online leningsaanvragen moet beschikbaar zijn voor de aanvrager. De uitgevende financiële instelling bewaakt continu de prestaties van het kredietmodel en heeft inzicht nodig in metrische gegevens zoals de status van goedkeuring van leningen, het aantal goedgekeurde leningen, uitgegeven dollarbedragen en de kwaliteit van nieuwe leningen.
Verantwoorde AI
Het dashboard Responsible AI biedt één interface voor meerdere hulpprogramma's waarmee u Verantwoorde AI kunt implementeren. De Responsible AI Standard is gebaseerd op zes principes:
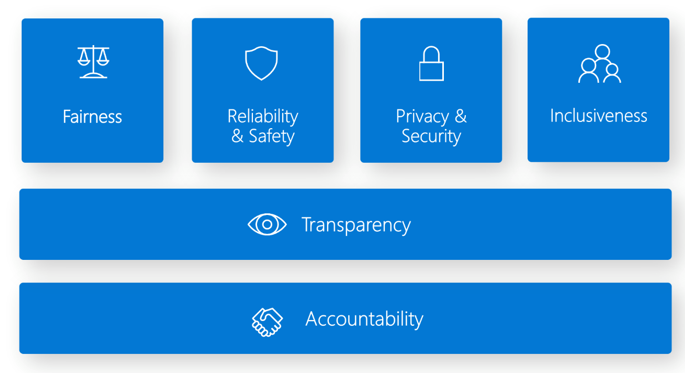
Redelijkheid en inclusiefheid in Azure Machine Learning. Dit onderdeel van het verantwoordelijke AI-dashboard helpt u bij het evalueren van oneerlijk gedrag door schade aan de toewijzing en schade van de kwaliteit van de service te voorkomen. U kunt het gebruiken om eerlijkheid te beoordelen voor gevoelige groepen die zijn gedefinieerd in termen van geslacht, leeftijd, etniciteit en andere kenmerken. Tijdens de evaluatie wordt redelijkheid gekwantificeerd via metrische gegevens over dispariteit. U moet de beperkingsalgoritmen implementeren in het opensource-pakket Fairlearn , waarbij pariteitsbeperkingen worden gebruikt.
Betrouwbaarheid en veiligheid in Azure Machine Learning. Het onderdeel foutanalyse van verantwoorde AI kan u helpen:
- Krijg inzicht in hoe fouten worden gedistribueerd voor een model.
- Identificeer cohorten van gegevens met een hoger foutpercentage dan de algehele benchmark.
Transparantie in Azure Machine Learning. Een cruciaal onderdeel van transparantie is begrijpen hoe functies van invloed zijn op het machine learning-model.
- Modelinterpreteerbaarheid helpt u te begrijpen wat het gedrag van het model beïnvloedt. Het genereert begrijpelijke beschrijvingen van de voorspellingen van het model. Deze kennis helpt ervoor te zorgen dat u het model kunt vertrouwen en helpt u fouten op te sporen en te verbeteren. InterpretML kan u helpen inzicht te verkrijgen in de structuur van glasdoosmodellen of de relatie tussen functies in deep neurale netwerkmodellen in black box.
- Counterfactual what-if kan u helpen een machine learning-model te begrijpen en fouten op te sporen in termen van hoe het reageert op functiewijzigingen en verstoringen.
Privacy en beveiliging in Azure Machine Learning. Machine learning-beheerders moeten een veilige configuratie maken om de implementatie van modellen te ontwikkelen en te beheren. Beveiligings- en governancefuncties kunnen u helpen te voldoen aan het beveiligingsbeleid van uw organisatie. Met andere hulpprogramma's kunt u uw modellen beoordelen en beveiligen.
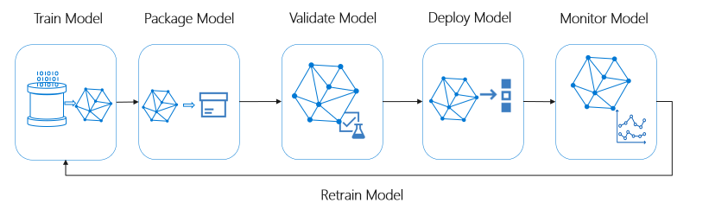
Verantwoordelijkheid in Azure Machine Learning. Machine learning-bewerkingen (MLOps) is gebaseerd op DevOps-principes en -procedures die de efficiëntie van AI-werkstromen verhogen. Met Azure Machine Learning kunt u MLOps-mogelijkheden implementeren:
- Modellen registreren, verpakken en implementeren
- Meldingen en waarschuwingen ontvangen voor wijzigingen in modellen
- Governancegegevens vastleggen voor de end-to-end levenscyclus
- Toepassingen controleren op operationele problemen
In dit diagram ziet u de MLOps-mogelijkheden van Azure Machine Learning:
Potentiële gebruikscases
U kunt deze oplossing toepassen op de volgende scenario's:
- Financiën: Ontvang financiële analyse van klanten of analyse van cross-sales van klanten voor gerichte marketingcampagnes.
- Gezondheidszorg: Gebruik patiëntgegevens als invoer om behandelingsaanbiedingen voor te stellen.
- Gastvrijheid: Maak een klantprofiel om aanbiedingen voor hotels, vluchten, cruisepakketten en lidmaatschappen voor te stellen.
Overwegingen
Met deze overwegingen worden de pijlers van het Azure Well-Architected Framework geïmplementeerd. Dit is een set richtlijnen die u kunt gebruiken om de kwaliteit van een workload te verbeteren. Zie Microsoft Azure Well-Architected Framework voor meer informatie.
Beveiliging
Beveiliging biedt garanties tegen opzettelijke aanvallen en misbruik van uw waardevolle gegevens en systemen. Zie Overzicht van de beveiligingspijler voor meer informatie.
Azure-oplossingen bieden diepgaande verdediging en een Zero Trust-benadering.
Overweeg de volgende beveiligingsfuncties in deze architectuur te implementeren:
- Toegewezen Azure-services implementeren in virtuele netwerken
- Beveiligingsmogelijkheden van Azure SQL Database
- De referenties in data factory beveiligen met Key Vault
- Bedrijfsbeveiliging en -governance voor Azure Machine Learning
- Azure-beveiligingsbasislijn voor Synapse Analytics-werkruimte
Kostenoptimalisatie
Kostenoptimalisatie gaat over het verminderen van onnodige uitgaven en het verbeteren van operationele efficiëntie. Zie Overzicht van de pijler kostenoptimalisatie voor meer informatie.
Als u de kosten voor het implementeren van deze oplossing wilt schatten, gebruikt u de Azure-prijscalculator.
Houd ook rekening met deze resources:
- Kosten voor Azure Synapse Analytics plannen en beheren
- Kosten voor Azure Machine Learning plannen en beheren
Operationele uitmuntendheid
Operationele uitmuntendheid omvat de operationele processen die een toepassing implementeren en deze in productie houden. Zie Overzicht van de operationele uitmuntendheidpijler voor meer informatie.
Machine learning-oplossingen moeten schaalbaar en gestandaardiseerd zijn voor eenvoudiger beheer en onderhoud. Zorg ervoor dat uw oplossing doorlopende deductie ondersteunt met hertrainingscycli en geautomatiseerde herverdeling van modellen.
Zie De oplossingsversneller van Azure MLOps (v2) voor meer informatie.
Prestatie-efficiëntie
Prestatie-efficiëntie is de mogelijkheid om op efficiënte wijze uw werkbelasting te schalen om te voldoen aan de vereisten die gebruikers eraan stellen. Zie overzicht van de pijler Prestatie-efficiëntie voor meer informatie.
- Zie de controlelijst prestatie-efficiëntie voor meer informatie over het ontwerpen van schaalbare oplossingen.
- Zie Ai- en machine learning-initiatieven schalen in gereglementeerde branches voor meer informatie over gereglementeerde branches.
- Beheer uw Azure Synapse Analytics-omgeving met SQL-, Spark- of serverloze SQL-pools .
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- Charitha Basani | Senior Cloud Solution Architect
Andere inzender:
- Mick Alberts | Technische schrijver
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Volgende stappen
- Azure-beveiligingsbasislijn voor Azure Machine Learning
- Azure Synapse Analytics
- Machine Learning-modellen implementeren in Azure
- Wat is Responsible AI?