Zones voor gegevenslanding
Gegevenslandingszones zijn verbonden met uw landingszone voor gegevensbeheer door VNet-peering (virtual network). Elke gegevenslandingszone wordt beschouwd als een landingszone die is gerelateerd aan de Architectuur van de Azure-landingszone.
Belangrijk
Voordat u een gegevenslandingszone inricht, moet u ervoor zorgen dat uw DevOps- en CI/CD-bedrijfsmodel aanwezig is en dat er een landingszone voor gegevensbeheer is geïmplementeerd.
Elke gegevenslandingszone heeft verschillende lagen die flexibiliteit bieden voor de servicegegevensintegraties en gegevensproducten die deze bevat. U kunt een nieuwe gegevenslandingszone implementeren met een standaardset services waarmee de gegevenslandingszone gegevens kan opnemen en analyseren.
Uw Azure-abonnement dat is gekoppeld aan uw gegevenslandingszone heeft de volgende structuur:
| Laag | Vereist | Resourcegroepen |
|---|---|---|
| Kernservices | Ja | |
| Gegevenstoepassing | Optioneel |
|
| Visualization | Optioneel |
Notitie
Een gegevenstoepassing produceert een of meer gegevensproducten.
Architectuur van gegevenslandingszones
De architectuur van de gegevenslandingszone illustreert de lagen, de bijbehorende resourcegroepen en services die elke resourcegroep bevat. De architectuur biedt ook een overzicht van alle groepen en rollen die zijn gekoppeld aan uw gegevenslandingszone, plus de mate van toegang tot uw besturings- en gegevensvlakken.

Fooi
Voordat u een gegevenslandingszone implementeert, moet u rekening houden met het aantal initiële gegevenslandingszones dat u wilt implementeren.
Gebruik deze architectuur als uitgangspunt. Download het Visio-bestand en pas het aan zodat het voldoet aan uw specifieke zakelijke en technische vereisten bij het plannen van de implementatie van uw gegevenslandingszone.
Laag kernservices
De kernserviceslaag bevat alle services die nodig zijn om uw gegevenslandingszone in te schakelen binnen de context van analyses op cloudschaal. De volgende tabel bevat de resourcegroepen die de standaardsuite met beschikbare services bieden in elke datalandingszone die u implementeert.
| Resourcegroep | Vereist | Beschrijving |
|---|---|---|
| network-rg | Ja | Netwerken |
| databricks-monitoring-rg | Optioneel | Bewaking voor Azure Databricks-werkruimten |
| hive-rg | Optioneel | Hive-metastore voor Azure Databricks |
| storage-rg | Ja | Data Lakes-services |
| external-data-rg | Ja | Opnameopslag uploaden |
| runtimes-rg | Ja | Gedeelde integratieruntimes |
| mgmt-rg | Ja | CI/CD-agents |
| metadata-ingestion-rg | Optioneel | Gegevensagnostische opname |
| databricks-monitoring-rg | Optioneel | Log Analytics-werkruimte voor Databricks-werkruimten in landingszone |
| shared-synapse-rg | Optioneel | Gedeelde Azure Synapse |
| shared-databricks-rg | Optioneel | Gedeelde Azure Databricks-werkruimte |
Netwerken
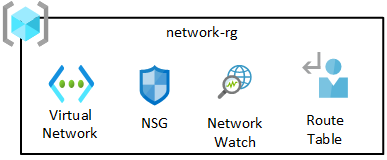
De netwerkresourcegroep bevat kernonderdelen, waaronder Azure Network Watcher, netwerkbeveiligingsgroepen (NSG) en een virtueel netwerk. Al deze services worden geïmplementeerd in één resourcegroep.
Het virtuele netwerk van uw gegevenslandingszone wordt automatisch gekoppeld aan het VNet van uw databeheerlandingszone en het VNet van uw connectiviteitsabonnement.
Bewaking van Azure Databricks-werkruimten
Deze resourcegroep is optioneel en wordt alleen geïmplementeerd met Azure Databricks.
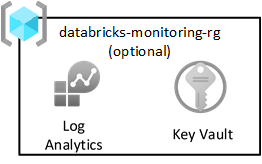
Het patroon azure-landingszone raadt u aan alle logboeken naar een centrale Log Analytics-werkruimte te verzenden. Elke gegevenslandingszone bevat echter ook een bewakingsresourcegroep om Spark-logboeken van Databricks vast te leggen. Elke resourcegroep bevat een gedeelde Log Analytics-werkruimte en Azure Key Vault voor het opslaan van Log Analytics-sleutels.
Belangrijk
Gebruik alleen de Log Analytics-werkruimte in uw Databricks-bewakingsresourcegroep om Azure Databricks Spark-logboeken vast te leggen.
Zie Bewaking van Azure Databricks voor meer informatie.
Hive-metastore voor Azure Databricks
Deze resourcegroep is optioneel en mag alleen worden geïmplementeerd met Azure Databricks.
De Hive-metastore voor Azure Databricks richt een Azure Database for MySQL-database en een sleutelkluis in. Alle Azure Databricks-werkruimten in uw data landingszone gebruiken deze metastore als hun externe Apache Hive-metastore.
Zie de externe Apache Hive-metastore voor meer informatie.
Data Lake-services
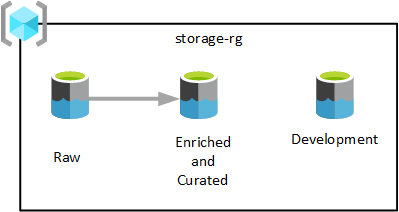
Zoals in het vorige diagram wordt weergegeven, worden drie Azure Data Lake Storage Gen2-accounts ingericht in één Data Lake Services-resourcegroep. Gegevens die in verschillende fasen worden getransformeerd, worden opgeslagen in een van de datalandingszones van uw datalandingszone. De gegevens zijn beschikbaar voor gebruik door uw analyse-, gegevenswetenschap- en visualisatieteams.
Data Lake-lagen gebruiken verschillende terminologie, afhankelijk van technologie en leverancier. Deze tabel bevat richtlijnen voor het toepassen van termen voor analyses op cloudschaal:
| Analyses op cloudschaal | Delta Lake | Andere termen | Omschrijving |
|---|---|---|---|
| Onbewerkt | Brons | Landing en conformiteit | Opnametabellen |
| Verrijkt | Zilver | Standaardisatiezone | Verfijnde tabellen. Opgeslagen volledige entiteit, recordsets die gereed zijn voor verbruik van systemen van records. |
| Gecureerd | Goud | Productzone | Functie- of samengevoegde tabellen. Primaire zone voor toepassingen, teams en gebruikers om gegevensproducten te gebruiken. |
| Ontwikkeling | -- | Ontwikkelzone | Locatie voor data engineers en wetenschappers, bestaande uit zowel een analyse-sandbox als een zone voor productontwikkeling. |
Notitie
In het vorige diagram heeft elke datalandingszone drie data lakes. Afhankelijk van uw vereisten wilt u echter mogelijk uw onbewerkte, verrijkte en gecureerde lagen consolideren in het ene opslagaccount en een ander opslagaccount onderhouden met de naam 'ontwikkeling' voor gegevensgebruikers om andere nuttige gegevensproducten in te voeren.
Zie voor meer informatie:
- Overzicht van Azure Data Lake Storage voor analyses op cloudschaal
- Gegevensstandaardisatie
- Azure Data Lake Storage Gen2-accounts inrichten voor elke gegevenslandingszone
- Belangrijke overwegingen voor Azure Data Lake Storage
- Toegangsbeheer en data lake-configuraties in Azure Data Lake Storage
Opnameopslag uploaden
Externe gegevensuitgevers moeten gegevens in uw platform landen, zodat uw datatoepassingsteams deze kunnen ophalen in hun data lakes. Zoals u in het volgende diagram kunt zien, kunt u met uw opslagresourcegroep voor uploaden blobarchieven inrichten voor derden.
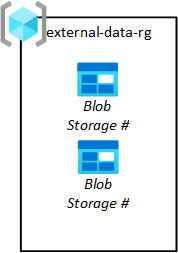
Uw datatoepassingsteams vragen deze opslagblobs aan. Hun aanvragen worden vervolgens goedgekeurd door uw operations-team voor gegevenslandingszones. Gegevens moeten worden verwijderd uit de bronopslag-blob zodra deze uit de opslagblob naar onbewerkte gegevens zijn opgehaald.
Belangrijk
Aangezien Azure Storage-blobs naar behoefte worden ingericht, moet u in eerste instantie een lege resourcegroep voor opslagservices implementeren in elke landingszone voor gegevens.
Gedeelde integratieruntimes
Implementeer een virtuele machine met zelf-hostende integration runtimes in uw data landingszone. Host deze in de resourcegroep voor gedeelde integratie. Met deze implementatie kunt u snel gegevensproducten onboarden naar uw datalandingszone.
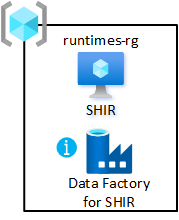
De resourcegroep inschakelen:
- Maak ten minste één Azure Data Factory in de gedeelde integratieresourcegroep van uw gegevenslandingszone. Gebruik dit alleen voor het koppelen van de gedeelde zelf-hostende Integration Runtime, niet voor gegevenspijplijnen.
- Maak en configureer een zelf-hostende Integration Runtime op de virtuele machine.
- Koppel de zelf-hostende Integration Runtime aan Azure-gegevensfactory's in uw datalandingszone(s).
- Stel Azure Automation in om de zelf-hostende Integration Runtime periodiek bij te werken.
Notitie
De bovenstaande implementatie biedt één implementatie van virtuele machines met zelf-hostende integration runtimes. U kunt een zelf-hostende Integration Runtime koppelen aan meerdere on-premises machines of virtuele machines in Azure. Deze machines worden knooppunten genoemd. U kunt maximaal vier knooppunten koppelen aan een zelf-hostende Integration Runtime. De voordelen van het hebben van meerdere knooppunten op on-premises machines waarop een gateway is geïnstalleerd voor een logische gateway zijn:
- Hogere beschikbaarheid van de zelf-hostende Integration Runtime, zodat het geen single point of failure meer is in uw big data-oplossing of cloudgegevensintegratie. Deze beschikbaarheid zorgt voor continuïteit wanneer u maximaal vier knooppunten gebruikt.
- Verbeterde prestaties en doorvoer tijdens gegevensverplaatsing tussen on-premises en cloudgegevensarchieven. Meer informatie over prestatievergelijkingen.
U kunt meerdere knooppunten koppelen door de zelf-hostende Integration Runtime-software te installeren vanuit het Downloadcentrum. Registreer deze vervolgens met behulp van een van de verificatiesleutels die zijn verkregen uit de cmdlet New-AzDataFactoryV2IntegrationRuntimeKey , zoals beschreven in de zelfstudie.
Futher-informatie wordt beschreven in Azure Datafactory High availability en schaalbaarheid.
Belangrijk
Implementeer gedeelde integratieruntimes zo dicht mogelijk bij de gegevensbron. Hun implementatie beperkt uw implementatie van integratieruntimes in een gegevenslandingszone of in clouds van derden niet. In plaats daarvan biedt het een terugval voor cloudeigen gegevensbronnen in de regio.
CI/CD-agents
CI/CD-agents helpen u bij het implementeren van gegevenstoepassingen en wijzigingen in de gegevenslandingszone.
Zie Azure Pipeline-agents voor meer informatie.
Gegevensagnostische opname
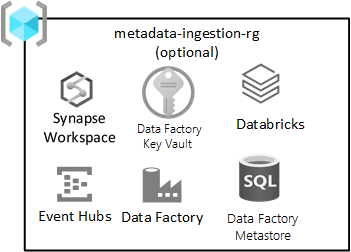
Deze resourcegroep is optioneel en voorkomt niet dat u uw landingszone implementeert.
Deze resourcegroep is van toepassing als u een gegevensagnostische opname-engine hebt (of ontwikkelt) voor het automatisch opnemen van gegevens op basis van het registreren van metagegevens (inclusief verbindingsreeks s, het pad naar het kopiëren van en naar en het opnameschema. De opname- en verwerkingsresourcegroep bevat belangrijke services voor dit soort frameworks.
Implementeer een Azure SQL Database-exemplaar voor het opslaan van metagegevens die worden gebruikt door Azure Data Factory. Richt een Azure Key Vault in voor het opslaan van geheimen met betrekking tot geautomatiseerde opnameservices. Deze geheimen kunnen het volgende omvatten:
- Referenties voor Azure Data Factory-metastore
- Referenties van de service-principal voor uw geautomatiseerde opnameproces
Zie Hoe geautomatiseerde opnameframeworks cloudanalyses in Azure ondersteunen voor meer informatie.
Services die zijn opgenomen in deze resourcegroep zijn onder andere:
| Onderhoud | Vereist | Richtlijnen |
|---|---|---|
| Azure Data Factory | Ja | Azure Data Factory is uw orchestration-engine voor gegevensagnostische opname. |
| Azure SQL Database | Ja | Azure SQL DB is de metastore voor Azure Data Factory. |
| Event Hubs of IoT Hub | Optioneel | Event Hubs of IoT Hub kan realtime streamen naar Event Hubs, plus batch- en streamingverwerking via een Databricks-engineeringwerkruimte. |
| Azure Databricks | Optioneel | U kunt Azure Databricks of Azure Synapse Spark implementeren voor gebruik met uw gegevensagnostische opname-engine. |
| Azure Synapse | Optioneel | U kunt Azure Databricks of Azure Synapse Spark implementeren voor gebruik met de gegevensagnostische opname-engine. |
Gedeelde Databricks
Deze resourcegroep is optioneel en wordt alleen geïmplementeerd met Azure Databricks. Iedereen in uw datalandingszone kan een Databricks-werkruimte gebruiken.
Azure Databricks is een belangrijke consument van de Azure Data Lake Storage-service. Atomische bestandsbewerkingen zijn geoptimaliseerd voor Spark-analyse-engines. Deze optimalisatie versnelt de voltooiing van Spark-taken die problemen ondervinden met de Azure Databricks-service.
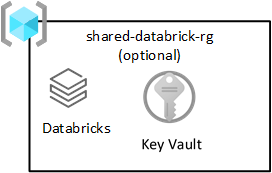
Belangrijk
Een Azure Databricks-werkruimte genaamd de Azure Databricks-werkruimte (analyse) wordt ingericht voor alle gegevenswetenschappers en DataOps, zoals wordt weergegeven in de resourcegroep voor gedeelde producten.
U kunt deze werkruimte configureren om verbinding te maken met uw Azure Data Lake met behulp van Microsoft Entra Passthrough of toegangsbeheer voor tabellen. Afhankelijk van uw use-case kunt u voorwaardelijke toegang configureren als een andere beveiligingsmaatregel.
Volg best practices voor analyses op cloudschaal om Azure Databricks te integreren:
- Beveiligde toegang tot Azure Data Lake Gen2 vanuit Azure Databricks
- Best practices voor Azure Databricks
Het patroon azure-landingszone raadt u aan alle logboeken naar een centrale Log Analytics-werkruimte te verzenden. Elke gegevenslandingszone bevat echter ook een bewakingsresourcegroep om Spark-logboeken van Databricks vast te leggen.
Gedeelde Azure Synapse Analytics
Deze resourcegroep is optioneel.
Tijdens de eerste installatie van een gegevenslandingszone wordt één Azure Synapse Analytics-werkruimte geïmplementeerd voor gebruik door alle gegevensanalisten en wetenschappers in de resourcegroep voor gedeelde producten.
U kunt meer Synapse-werkruimten instellen voor gegevensproducten als kostenbeheer en opladen vereist zijn. Uw gegevenstoepassingsteams kunnen gebruikmaken van toegewezen Azure Synapse Analytics-werkruimten om toegewezen Azure SQL Database-pools te maken als een leesgegevensarchief dat wordt gebruikt door uw visualisatielaag.
Belangrijk
Voorkom het gebruik van uw gedeelde Azure Synapse-werkruimte voor het maken van gegevensproduct door de werkruimte te vergrendelen om alleen SQL On-demand-query's toe te staan. Het is er alleen voor exploitatieve doeleinden.
Gegevenstoepassing
Elke gegevenslandingszone kan meerdere gegevensproducten hebben. U kunt deze gegevensproducten maken door gegevens op te nemen uit de bron. U kunt ook gegevensproducten maken van andere gegevensproducten binnen dezelfde gegevenslandingszone of vanuit andere gegevenslandingszones. Het maken van gegevensproducten van de gegevensproducten is onderworpen aan goedkeuring van de gegevenssteward.
Resourcegroep voor gegevensproduct
Het product van de gegevensproductresourcegroep bevat alle services die nodig zijn om dat gegevensproduct te maken. Een Azure Database is bijvoorbeeld vereist voor MySQL, dat wordt gebruikt door een visualisatieprogramma. Gegevens moeten worden opgenomen en getransformeerd voordat ze terechtkomen in die MySQL-database. In dit geval kunt u Azure Database for MySQL en een Azure Data Factory implementeren in de resourcegroep van het gegevensproduct.
Fooi
Als u ervoor kiest om geen engine voor gegevensagnostiek te implementeren voor het opnemen van gegevens uit operationele bronnen of als complexe verbindingen niet worden gefaciliteerd in de engine voor gegevensagnostiek, maakt u een op de bron afgestemde gegevenstoepassing. Zie Gegevenstoepassingen (bron uitgelijnd) voor meer informatie
Zie Gegevensproducten op cloudschaal in Azure voor meer informatie over het onboarden van gegevensproducten op cloudschaal.
Visualisatie
Er wordt een lege visualisatieresourcegroep gemaakt voor elke gegevenslandingszone. Vul deze resourcegroep in met services die u nodig hebt om uw visualisatieoplossing te implementeren. Met behulp van uw bestaande VNet kan uw oplossing verbinding maken met gegevensproducten.
Deze resourcegroep kan virtuele machines hosten voor visualisatieservices van derden.
Fooi
Vanwege licentiekosten is het misschien voordeliger om visualisatieproducten van derden te implementeren in uw landingszone voor gegevensbeheer, en voor die producten om verbinding te maken tussen gegevenslandingszones om gegevens terug te halen.