gebeurtenis
31 mrt, 23 - 2 apr, 23
De grootste fabric-, Power BI- en SQL-leerevenement. 31 maart – 2 april. Gebruik code FABINSIDER om $ 400 te besparen.
Zorg dat u zich vandaag nog registreertDeze browser wordt niet meer ondersteund.
Upgrade naar Microsoft Edge om te profiteren van de nieuwste functies, beveiligingsupdates en technische ondersteuning.
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie gebruikt u Azure PowerShell om een Data Factory-pijplijn te maken waarmee gegevens worden gekopieerd van een SQL Server-database naar een Azure Blob-opslag. U gaat een zelf-hostende Integration Runtime maken en gebruiken. Deze verplaatst gegevens van on-premises gegevensarchieven en gegevensarchieven in de cloud en omgekeerd.
Notitie
Dit artikel is geen gedetailleerde introductie tot de Data Factory-service. Zie voor meer informatie Inleiding tot Azure Data Factory.
In deze zelfstudie voert u de volgende stappen uit:
Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint.
Als u data factory-exemplaren wilt maken, moet het gebruikersaccount waarmee u zich bij Azure aanmeldt, toegewezen zijn aan de rollen Inzender of Eigenaar, of moet dit een beheerder van het Azure-abonnement zijn.
Als u de machtigingen die u hebt in het abonnement wilt bekijken, gaat u naar Azure Portal, selecteert u rechtsboven in de hoek uw gebruikersnaam en selecteert u vervolgens Machtigingen. Als u toegang tot meerdere abonnementen hebt, moet u het juiste abonnement selecteren. Zie het artikel Azure Portal toewijzen voor voorbeeldinstructies voor het toevoegen van een gebruiker aan een rol.
In deze zelfstudie gebruikt u een SQL Server-database als een brongegevensopslag. De pijplijn in de data factory die u in deze zelfstudie gaat maken, kopieert gegevens van deze SQL Server-database (bron) naar Azure Blob-opslag (sink). Maak een tabel met de naam emp in uw SQL Server-database en voeg een aantal voorbeeldgegevens toe aan de tabel.
Start SQL Server Management Studio. Als dit niet al is geïnstalleerd op uw computer, gaat u naar SQL Server Management Studio downloaden.
Maak verbinding met SQL Server-exemplaar met behulp van uw referenties.
Maak een voorbeelddatabase. Klik in de structuurweergave met de rechtermuisknop op Databases en selecteer Nieuwe database.
Voer in het venster Nieuwe database een naam in voor de database en selecteer OK.
Voer het volgende queryscript uit voor de database. Hiermee wordt de emp-tabel gemaakt en worden enkele voorbeeldgegevens ingevoegd in deze tabel. In de structuurweergave klikt u met de rechtermuisknop op de database die u hebt gemaakt en selecteert u Nieuwe query.
CREATE TABLE dbo.emp
(
ID int IDENTITY(1,1) NOT NULL,
FirstName varchar(50),
LastName varchar(50)
)
GO
INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe')
INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe')
GO
In deze zelfstudie gaat u een algemeen Azure Storage-account (en dan met name Azure Blob Storage) gebruiken als een doel/sink-gegevensopslag. Zie het artikel Een opslagaccount maken als u geen Azure Storage-account hebt voor algemene doeleinden. De pijplijn in de data factory die u in deze zelfstudie gaat maken, kopieert gegevens van de SQL Server-database (bron) naar deze Azure Blob-opslag (sink).
In deze QuickStart gaat u de naam en sleutel van uw Azure Storage-account gebruiken. Als u de naam en sleutel van uw opslagaccount wilt ophalen, doet u het volgende:
Meld u aan bij Azure Portal met uw Azure gebruikersnaam en wachtwoord.
Selecteer in het linkerdeelvenster Meer services, filter met behulp van het sleutelwoord Opslag en selecteer vervolgens Opslagaccounts.
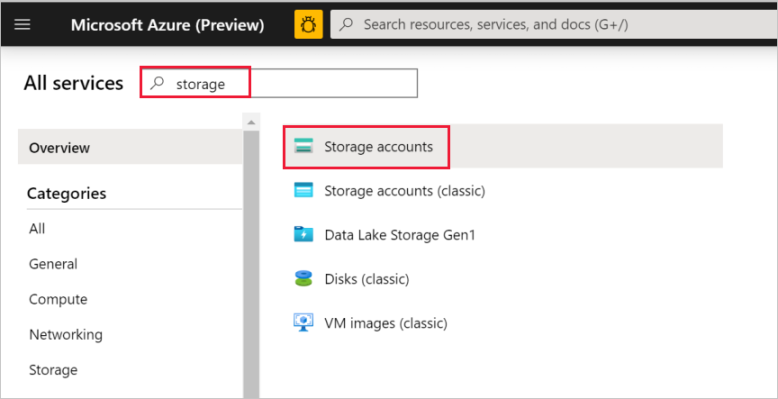
Filter in de lijst met opslagaccounts op uw opslagaccount (indien nodig) en selecteer vervolgens uw opslagaccount.
Selecteer in het venster Opslagaccount de optie Toegangssleutels.
Kopieer de waarden in de vakken opslagaccountnaam en key1 en plak deze in Kladblok of een andere editor voor later gebruik in de zelfstudie.
In deze sectie maakt u in uw Azure Blob Storage een blobcontainer met de naam adftutorial.
Schakel in het venster Opslagaccount over naar Overzicht en klik vervolgens op Blobs.
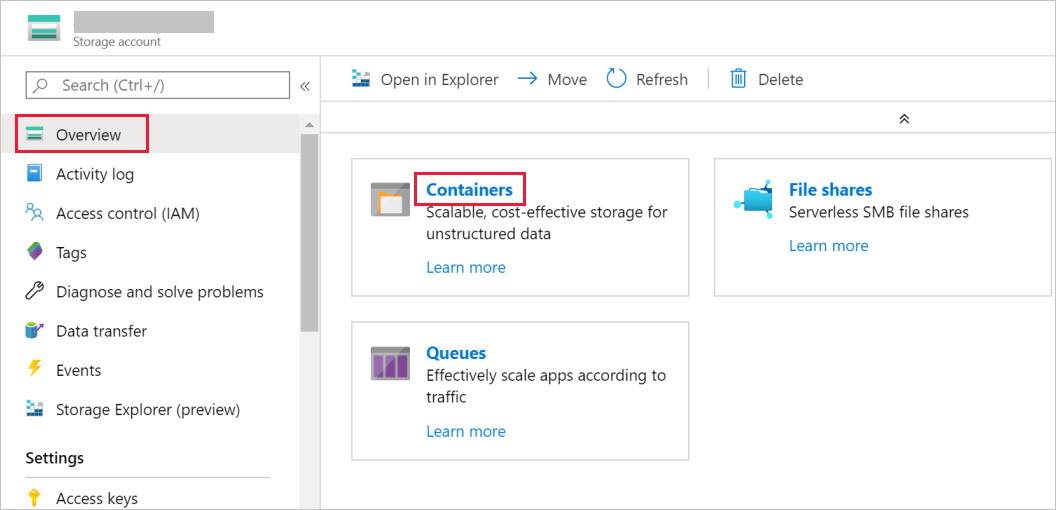
Selecteer in het venster Blob-serviceContainer.
Voer in het venster Nieuwe container in het vak Naamadftutorial in en selecteer OK.
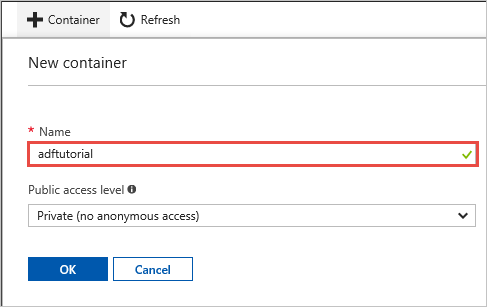
Selecteer adftutorial in de lijst met containers.
Houd het venster Container voor adftutorial geopend. U gaat hiermee aan het einde van deze zelfstudie de uitvoer controleren. In Data Factory wordt automatisch in deze container de uitvoermap gemaakt, zodat u er zelf geen hoeft te maken.
Notitie
Het wordt aanbevolen de Azure Az PowerShell-module te gebruiken om te communiceren met Azure. Zie Azure PowerShell installeren om aan de slag te gaan. Raadpleeg Azure PowerShell migreren van AzureRM naar Az om te leren hoe u naar de Azure PowerShell-module migreert.
Installeer de nieuwste versie van Azure PowerShell als u deze niet al op uw computer hebt. Zie Azure PowerShell installeren en configureren voor gedetailleerde instructies.
Start PowerShell op uw computer en houd dit programma geopend totdat deze Quick Start-zelfstudie is afgerond. Als u het programma sluit en opnieuw opent, moet u deze opdrachten opnieuw uitvoeren.
Voer de volgende opdracht uit en geef de gebruikersnaam en het wachtwoord op waarmee u zich aanmeldt bij Azure Portal:
Connect-AzAccount
Als u meerdere Azure-abonnementen hebt, voert u de volgende opdracht uit om het abonnement te selecteren waarmee u wilt werken. Vervang SubscriptionId door de id van uw Azure-abonnement:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Definieer een variabele voor de naam van de resourcegroep die u later gaat gebruiken in PowerShell-opdrachten. Kopieer de tekst van de volgende opdracht naar PowerShell, geef een naam op voor de Azure-resourcegroep (bijvoorbeeld tussen dubbele aanhalingstekens) "adfrg"en voer de opdracht uit.
$resourceGroupName = "ADFTutorialResourceGroup"
Voer de volgende opdracht uit om de resourcegroep te maken:
New-AzResourceGroup $resourceGroupName -location 'East US'
Als de resourcegroep al bestaat, wilt u waarschijnlijk niet dat deze wordt overschreven. Wijs een andere waarde toe aan de $resourceGroupName-variabele en voer de opdracht opnieuw uit.
Definieer een variabele voor de naam van de data factory die u later kunt gebruiken in PowerShell-opdrachten. De naam moet beginnen met een letter of cijfer en mag alleen letters, cijfers en streepjes (-) bevatten.
Belangrijk
Werk de naam van de data factory zodanig bij dat deze uniek is. Bijvoorbeeld: ADFTutorialFactorySP1127.
$dataFactoryName = "ADFTutorialFactory"
Definieer een variabele voor de locatie van de data factory:
$location = "East US"
Voer voor het maken van de data factory de cmdlet Set-AzDataFactoryV2 uit:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Notitie
The specified data factory name 'ADFv2TutorialDataFactory' is already in use. Data factory names must be globally unique.
In deze sectie kunt u een zelf-hostende Integration Runtime maken en deze koppelen aan een on-premises computer met de SQL Server database. De zelf-hostende Integration Runtime is het onderdeel waarmee gegevens worden gekopieerd van SQL Server-database op uw computer naar Azure Blob Storage.
Maak een variabele voor de naam van een Integration Runtime. Gebruik een unieke naam en noteer deze. U gaat deze verderop in de zelfstudie gebruiken.
$integrationRuntimeName = "ADFTutorialIR"
Een zelf-hostende Integration Runtime maken.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $integrationRuntimeName -Type SelfHosted -Description "selfhosted IR description"
Hier volgt een voorbeeld van uitvoer:
Name : ADFTutorialIR
Type : SelfHosted
ResourceGroupName : <resourceGroupName>
DataFactoryName : <dataFactoryName>
Description : selfhosted IR description
Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>
Voer de volgende opdracht uit om de status van de gemaakte zelf-hostende Integration Runtime op te halen:
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Status
Hier volgt een voorbeeld van uitvoer:
State : NeedRegistration
Version :
CreateTime : 9/10/2019 3:24:09 AM
AutoUpdate : On
ScheduledUpdateDate :
UpdateDelayOffset :
LocalTimeZoneOffset :
InternalChannelEncryption :
Capabilities : {}
ServiceUrls : {eu.frontend.clouddatahub.net}
Nodes : {}
Links : {}
Name : <Integration Runtime name>
Type : SelfHosted
ResourceGroupName : <resourceGroup name>
DataFactoryName : <dataFactory name>
Description : selfhosted IR description
Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>
Voer de volgende opdracht uit om verificatiesleutels op te halen voor het registreren van de zelf-hostende Integration Runtime met Data Factory-service in de cloud. Kopieer een van de sleutels (zonder de aanhalingstekens) om de zelf-hostende Integration Runtime te registeren die u tijdens de volgende stap op uw computer gaat installeren.
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-Json
Hier volgt een voorbeeld van uitvoer:
{
"AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=",
"AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy="
}
Download Azure Data Factory Integration Runtime op een lokale Windows-computer en voer de installatie uit.
Klik bij Welkom bij de installatiewizard van Microsoft Integration Runtime op Volgende.
Ga in het venster Gebruiksrechtovereenkomst akkoord met de voorwaarden en de gebruiksrechtovereenkomst en selecteer Volgende.
Selecteer in het venster DoelmapVolgende.
Selecteer in het venster Gereed om Microsoft Integration Runtime te installerenInstalleren.
Klik in De installatiewizard voor Microsoft Integration Runtime is voltooid op Voltooien.
Plak de sleutel die u in de vorige sectie hebt opgeslagen in het venster Integration Runtime (zelf-hostend) registreren en selecteer Registreren.
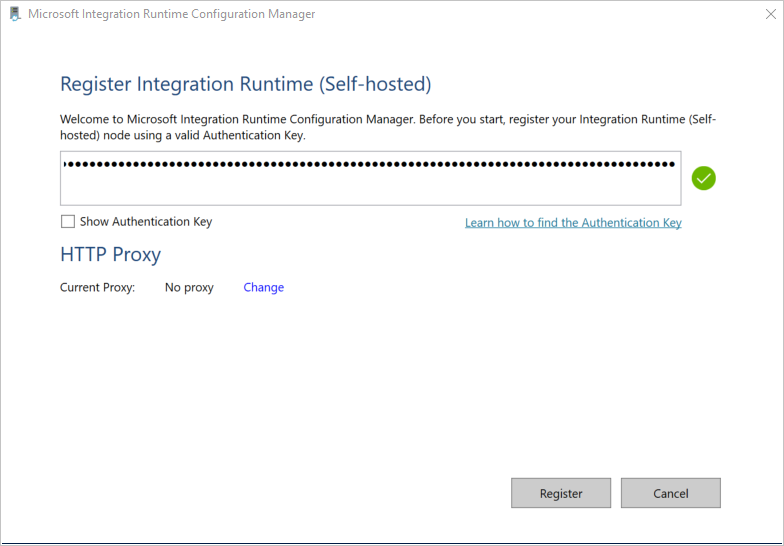
Klik in het venster Nieuw knooppunt voor Integration Runtime (zelf-hostend) op Voltooien.
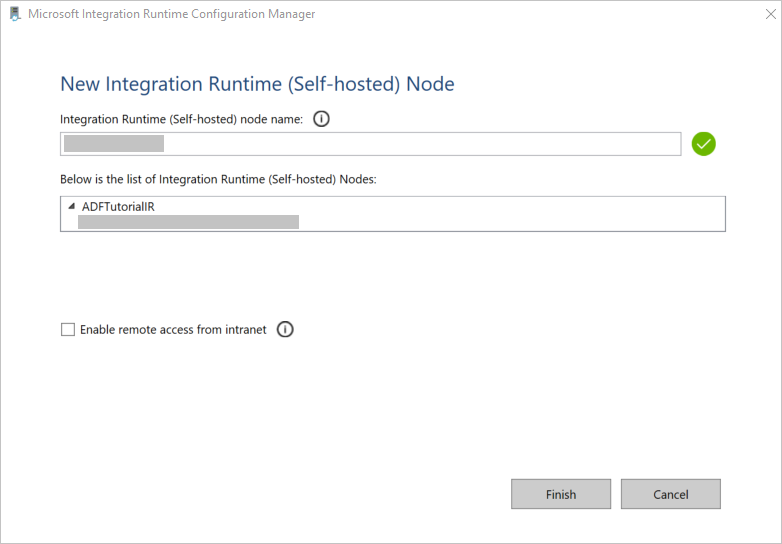
U ziet het volgende bericht wanneer de zelf-hostende Integration Runtime is geregistreerd:
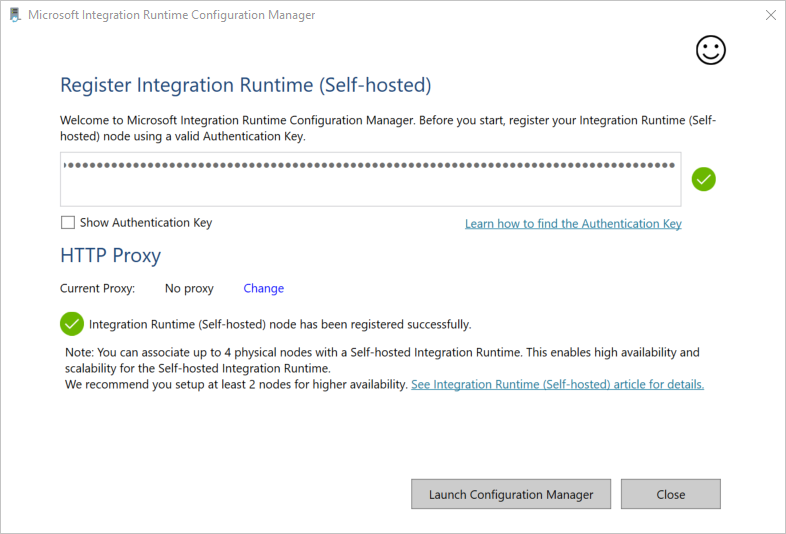
In het venster Integration Runtime (zelf-hostend) registeren selecteert u Configuration Manager starten.
Wanneer het knooppunt is verbonden met de cloudservice, ziet u het volgende bericht:
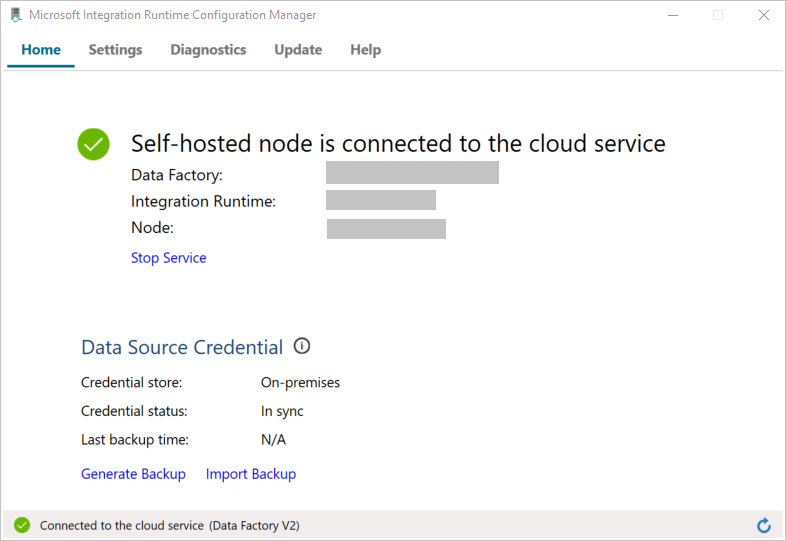
Test nu de verbinding met uw SQL Server-database door het volgende te doen:
a. Schakel in het venster Configuratiebeheer over naar het tabblad Diagnostische gegevens.
b. Selecteer in het vak Type gegevensbronSqlServer.
c. Voer de naam van de server in.
d. Voer de naam van de database in.
e. Selecteer de verificatiemethode.
f. Voer de gebruikersnaam in.
g. Voer het wachtwoord in dat bij de gebruikersnaam hoort.
h. Selecteer Test om te controleren of Integration Runtime verbinding kan maken met de SQL Server.
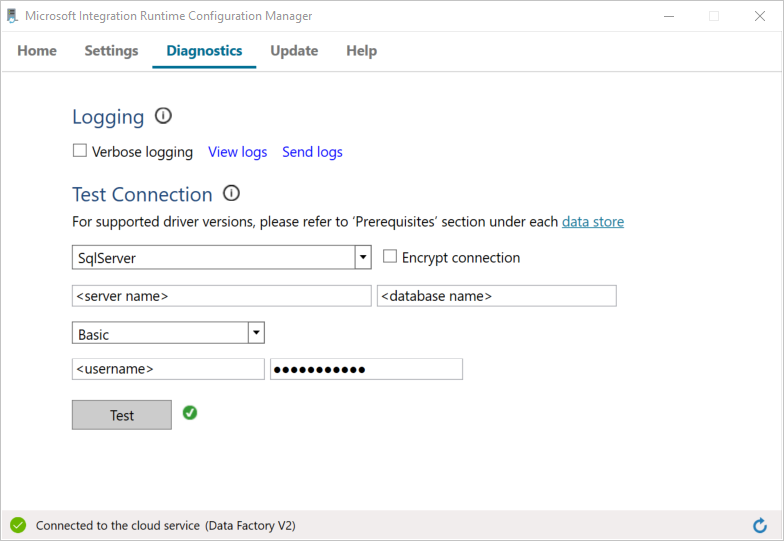
U ziet een groen vinkje als het gelukt is om verbinding te maken. Anders ontvangt u een foutmelding die bij de fout hoort. Los eventuele problemen op en zorg ervoor dat de Integration Runtime verbinding met uw SQL Server-exemplaar kan maken.
Noteer alle voorgaande waarden voor later gebruik in deze zelfstudie.
Maak gekoppelde services in een data factory om uw gegevensarchieven en compute-services aan de data factory te koppelen. In deze zelfstudie gaat u uw Azure Storage-account en uw SQL Server-exemplaar aan de gegevensopslag koppelen. De gekoppelde services beschikken over de verbindingsgegevens die de Data Factory-service tijdens runtime gebruikt om er een verbinding mee tot stand te brengen.
Tijdens deze stap koppelt u uw Azure Storage-account aan de data factory.
Maak een JSON-bestand met de naam AzureStorageLinkedService.json in de map C:\ADFv2Tutorial met de volgende code. Maak de map ADFv2Tutorial als deze nog niet bestaat.
Belangrijk
Voordat u het bestand opslaat, vervangt <u accountName> en <accountKey> door de naam en sleutel van uw Azure-opslagaccount. U hebt deze genoteerd in de sectie Vereisten.
{
"name": "AzureStorageLinkedService",
"properties": {
"annotations": [],
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net"
}
}
}
Schakel in PowerShell over naar de map C:\ADFv2Tutorial.
Set-Location 'C:\ADFv2Tutorial'
Voer om een gekoppelde service te maken met de naam AzureStorageLinkedService de volgende Set-AzDataFactoryV2LinkedService cmdlet uit:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"
Hier volgt een voorbeeld van uitvoer:
LinkedServiceName : AzureStorageLinkedService
ResourceGroupName : <resourceGroup name>
DataFactoryName : <dataFactory name>
Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedService
Als u de fout Bestand niet gevonden krijgt, bevestig dan dat het bestand bestaat door de opdracht dir uit te voeren. Als de bestandsnaam de extensie .txt heeft (bijvoorbeeld AzureStorageLinkedService.json.txt), verwijdert u deze en voert u vervolgens de PowerShell-opdracht opnieuw uit.
In deze stap gaat u uw SQL Server-exemplaar aan de data factory koppelen.
Maak een JSON-bestand met de naam SqlServerLinkedService.json in de map C:\ADFv2Tutorial met de volgende code:
Belangrijk
Selecteer de sectie op basis van de verificatie die u gebruikt om verbinding te maken met SQL Server.
SQL-verificatie gebruiken (sa):
{
"name":"SqlServerLinkedService",
"type":"Microsoft.DataFactory/factories/linkedservices",
"properties":{
"annotations":[
],
"type":"SqlServer",
"typeProperties":{
"connectionString":"integrated security=False;data source=<serverName>;initial catalog=<databaseName>;user id=<userName>;password=<password>"
},
"connectVia":{
"referenceName":"<integration runtime name> ",
"type":"IntegrationRuntimeReference"
}
}
}
Windows-verificatie gebruiken:
{
"name":"SqlServerLinkedService",
"type":"Microsoft.DataFactory/factories/linkedservices",
"properties":{
"annotations":[
],
"type":"SqlServer",
"typeProperties":{
"connectionString":"integrated security=True;data source=<serverName>;initial catalog=<databaseName>",
"userName":"<username> or <domain>\\<username>",
"password":{
"type":"SecureString",
"value":"<password>"
}
},
"connectVia":{
"referenceName":"<integration runtime name>",
"type":"IntegrationRuntimeReference"
}
}
}
Belangrijk
Voor het versleutelen van gevoelige gegevens (gebruikersnaam, wachtwoord, enz.), voer de New-AzDataFactoryV2LinkedServiceEncryptedCredential cmdlet uit.
Deze versleuteling zorgt ervoor dat de referenties zijn versleuteld met behulp van DPAPI (Data Protection Application Programming Interface). De versleutelde referenties worden lokaal op het zelf-hostende Integration Runtime-knooppunt (lokale computer) opgeslagen. De uitvoerpayload kan worden omgeleid naar een ander JSON-bestand (in dit geval encryptedLinkedService.json). Dit bestand bevat de versleutelde referenties.
New-AzDataFactoryV2LinkedServiceEncryptedCredential -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -IntegrationRuntimeName $integrationRuntimeName -File ".\SQLServerLinkedService.json" > encryptedSQLServerLinkedService.json
Voer de volgende opdracht uit. Hiermee wordt de EncryptedSqlServerLinkedService gemaakt:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "EncryptedSqlServerLinkedService" -File ".\encryptedSqlServerLinkedService.json"
In deze stap gaat u gegevenssets voor invoer en uitvoer maken. Deze vertegenwoordigen invoer- en uitvoergegevenssets voor de kopieerbewerking, die gegevens van de SQL Server-database naar Azure Blob-opslag kopiëren.
Tijdens deze stap definieert u een gegevensset die gegevens in de SQL Server-database vertegenwoordigt. De gegevensset is van het type SqlServerTable. Deze gegevensset verwijst naar de gekoppelde SQL Server-service die u in de vorige stap hebt gemaakt. De gekoppelde service beschikt over de verbindingsgegevens die de Data Factory-service gebruikt om tijdens runtime een verbinding met uw SQL Server-exemplaar tot stand te brengen. Deze gegevensset bepaalt welke SQL-tabel in de database de gegevens bevat. In deze zelfstudie bevat de tabel emp de brongegevens.
Maak een JSON-bestand met de naam SqlServerDataset.json in de map C:\ADFv2Tutorial met de volgende code:
{
"name":"SqlServerDataset",
"properties":{
"linkedServiceName":{
"referenceName":"EncryptedSqlServerLinkedService",
"type":"LinkedServiceReference"
},
"annotations":[
],
"type":"SqlServerTable",
"schema":[
],
"typeProperties":{
"schema":"dbo",
"table":"emp"
}
}
}
Voer voor het maken van de gegevensset SqlServerDataset de cmdlet Set-AzDataFactoryV2Dataset uit.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerDataset" -File ".\SqlServerDataset.json"
Hier volgt een voorbeeld van uitvoer:
DatasetName : SqlServerDataset
ResourceGroupName : <resourceGroupName>
DataFactoryName : <dataFactoryName>
Structure :
Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Tijdens deze stap gaat u een gegevensset definiëren die gegevens vertegenwoordigt die moeten worden gekopieerd naar de Azure Blob-opslag. De gegevensset is van het type AzureBlob. Deze gegevensset verwijst naar de gekoppelde Azure Storage-service die u eerder in deze zelfstudie hebt gemaakt.
De gekoppelde service beschikt over de verbindingsgegevens die de Data Factory-service tijdens runtime gebruikt om verbinding met uw Azure Storage-account te maken. Deze gegevensset duidt de map in de Azure-opslag aan waarnaar de gegevens van de SQL Server-database worden gekopieerd. In deze zelfstudie is de map adftutorial/fromonprem waar de adftutorial blobcontainer is en is fromonprem de map.
Maak een JSON-bestand met de naam AzureBlobDataset.json in de map C:\ADFv2Tutorial met de volgende code:
{
"name":"AzureBlobDataset",
"properties":{
"linkedServiceName":{
"referenceName":"AzureStorageLinkedService",
"type":"LinkedServiceReference"
},
"annotations":[
],
"type":"DelimitedText",
"typeProperties":{
"location":{
"type":"AzureBlobStorageLocation",
"folderPath":"fromonprem",
"container":"adftutorial"
},
"columnDelimiter":",",
"escapeChar":"\\",
"quoteChar":"\""
},
"schema":[
]
},
"type":"Microsoft.DataFactory/factories/datasets"
}
Voer voor het maken van de gegevensset AzureBlobDataset de cmdlet Set-AzDataFactoryV2Dataset uit.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureBlobDataset" -File ".\AzureBlobDataset.json"
Hier volgt een voorbeeld van uitvoer:
DatasetName : AzureBlobDataset
ResourceGroupName : <resourceGroupName>
DataFactoryName : <dataFactoryName>
Structure :
Properties : Microsoft.Azure.Management.DataFactory.Models.DelimitedTextDataset
Tijdens deze stap maakt u een pijplijn met een kopieeractiviteit. Tijdens de kopieeractiviteit wordt de SqlServerDataset als invoergegevensset en AzureBlobDataset als de uitvoergegevensset gebruikt. Het brontype is ingesteld op SqlSource en het sinktype is ingesteld op BlobSink.
Maak een JSON-bestand met de naam SqlServerToBlobPipeline.json in de map C:\ADFv2Tutorial met de volgende code:
{
"name":"SqlServerToBlobPipeline",
"properties":{
"activities":[
{
"name":"CopySqlServerToAzureBlobActivity",
"type":"Copy",
"dependsOn":[
],
"policy":{
"timeout":"7.00:00:00",
"retry":0,
"retryIntervalInSeconds":30,
"secureOutput":false,
"secureInput":false
},
"userProperties":[
],
"typeProperties":{
"source":{
"type":"SqlServerSource"
},
"sink":{
"type":"DelimitedTextSink",
"storeSettings":{
"type":"AzureBlobStorageWriteSettings"
},
"formatSettings":{
"type":"DelimitedTextWriteSettings",
"quoteAllText":true,
"fileExtension":".txt"
}
},
"enableStaging":false
},
"inputs":[
{
"referenceName":"SqlServerDataset",
"type":"DatasetReference"
}
],
"outputs":[
{
"referenceName":"AzureBlobDataset",
"type":"DatasetReference"
}
]
}
],
"annotations":[
]
}
}
De pijplijn SqlServerToBlobPipeline maken: voer de Set-AzDataFactoryV2Pipeline cmdlet uit.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SQLServerToBlobPipeline" -File ".\SQLServerToBlobPipeline.json"
Hier volgt een voorbeeld van uitvoer:
PipelineName : SQLServerToBlobPipeline
ResourceGroupName : <resourceGroupName>
DataFactoryName : <dataFactoryName>
Activities : {CopySqlServerToAzureBlobActivity}
Parameters :
Start een pijplijnuitvoering voor de pijplijn SQLServerToBlobPipeline en leg de id voor de pijplijnuitvoering vast voor toekomstige controle.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName 'SQLServerToBlobPipeline'
Voer het volgende script in PowerShell uit om continu de uitvoeringsstatus van de pijplijn SQLServerToBlobPipeline te controleren, en druk het eindresultaat af:
while ($True) {
$result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30)
if (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) {
Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow"
Start-Sleep -Seconds 30
}
else {
Write-Host "Pipeline 'SQLServerToBlobPipeline' run finished. Result:" -foregroundcolor "Yellow"
$result
break
}
}
Hier volgt een voorbeeld van de voorbeelduitvoering:
ResourceGroupName : <resourceGroupName>
DataFactoryName : <dataFactoryName>
ActivityRunId : 24af7cf6-efca-4a95-931d-067c5c921c25
ActivityName : CopySqlServerToAzureBlobActivity
ActivityType : Copy
PipelineRunId : 7b538846-fd4e-409c-99ef-2475329f5729
PipelineName : SQLServerToBlobPipeline
Input : {source, sink, enableStaging}
Output : {dataRead, dataWritten, filesWritten, sourcePeakConnections...}
LinkedServiceName :
ActivityRunStart : 9/11/2019 7:10:37 AM
ActivityRunEnd : 9/11/2019 7:10:58 AM
DurationInMs : 21094
Status : Succeeded
Error : {errorCode, message, failureType, target}
AdditionalProperties : {[retryAttempt, ], [iterationHash, ], [userProperties, {}], [recoveryStatus, None]...}
U kunt de run-id van de pijplijn SQLServerToBlobPipeline ophalen en vervolgens het gedetailleerde uitvoeringsresultaat van de activiteit controleren met de volgende opdracht:
Write-Host "Pipeline 'SQLServerToBlobPipeline' run result:" -foregroundcolor "Yellow"
($result | Where-Object {$_.ActivityName -eq "CopySqlServerToAzureBlobActivity"}).Output.ToString()
Hier volgt een voorbeeld van de voorbeelduitvoering:
{
"dataRead":36,
"dataWritten":32,
"filesWritten":1,
"sourcePeakConnections":1,
"sinkPeakConnections":1,
"rowsRead":2,
"rowsCopied":2,
"copyDuration":18,
"throughput":0.01,
"errors":[
],
"effectiveIntegrationRuntime":"ADFTutorialIR",
"usedParallelCopies":1,
"executionDetails":[
{
"source":{
"type":"SqlServer"
},
"sink":{
"type":"AzureBlobStorage",
"region":"CentralUS"
},
"status":"Succeeded",
"start":"2019-09-11T07:10:38.2342905Z",
"duration":18,
"usedParallelCopies":1,
"detailedDurations":{
"queuingDuration":6,
"timeToFirstByte":0,
"transferDuration":5
}
}
]
}
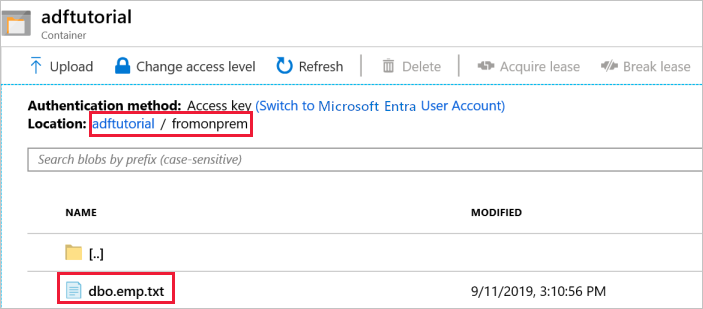
De uitvoermap fromonprem wordt automatisch door de pijplijn gemaakt in de adftutorial blobcontainer. Controleer of u het bestand dbo.emp.txt in de uitvoermap ziet.
Klik in Azure Portal op het venster met de adftutorial-container op Vernieuwen om de uitvoermap weer te geven.
Selecteer fromonprem in de lijst met mappen.
Controleer of u een bestand met de naam dbo.emp.txt ziet.
Met de pijplijn in dit voorbeeld worden gegevens gekopieerd van de ene locatie naar een andere locatie in een Azure Blob-opslag. U hebt geleerd hoe u:
Zie Ondersteunde gegevensopslagexemplaren voor een lijst met gegevensopslagexemplaren die worden ondersteund door Data Factory.
Ga door naar de volgende zelfstudie voor informatie over het bulksgewijs kopiëren van gegevens uit een bron naar een bestemming:
gebeurtenis
31 mrt, 23 - 2 apr, 23
De grootste fabric-, Power BI- en SQL-leerevenement. 31 maart – 2 april. Gebruik code FABINSIDER om $ 400 te besparen.
Zorg dat u zich vandaag nog registreert