Gegevens kopiëren naar Azure Data Explorer met behulp van Azure Data Factory
Belangrijk
Deze connector kan worden gebruikt in realtime analyses in Microsoft Fabric. Gebruik de instructies in dit artikel met de volgende uitzonderingen:
- Maak indien nodig databases met behulp van de instructies in Een KQL-database maken.
- Maak indien nodig tabellen aan de hand van de instructies in Een lege tabel maken.
- Haal query- of opname-URI's op met behulp van de instructies in URI kopiëren.
- Query's uitvoeren in een KQL-queryset.
Azure Data Explorer is een snelle, volledig beheerde gegevensanalyseservice. Het biedt realtime-analyse van grote hoeveelheden gegevens die vanuit veel bronnen worden gestreamd, zoals toepassingen, websites en IoT-apparaten. Met Azure Data Explorer kunt u gegevens iteratief verkennen en patronen en afwijkingen identificeren om producten te verbeteren, klantervaringen te verbeteren, apparaten te bewaken en bewerkingen te stimuleren. Hiermee kunt u nieuwe vragen verkennen en binnen enkele minuten antwoorden krijgen.
Azure Data Factory is een volledig beheerde, cloudgebaseerde service voor gegevensintegratie. U kunt deze gebruiken om uw Azure Data Explorer-database te vullen met gegevens uit uw bestaande systeem. Het kan u helpen tijd te besparen bij het bouwen van analyseoplossingen.
Wanneer u gegevens in Azure Data Explorer laadt, biedt Data Factory de volgende voordelen:
- Eenvoudige installatie: download een intuïtieve wizard in vijf stappen zonder scripting.
- Uitgebreide ondersteuning voor gegevensopslag: krijg ingebouwde ondersteuning voor een uitgebreide set on-premises en cloudgegevensarchieven. Zie de tabel met Ondersteunde gegevensarchieven voor een gedetailleerde lijst.
- Veilig en compatibel: gegevens worden overgedragen via HTTPS of Azure ExpressRoute. De aanwezigheid van de wereldwijde service zorgt ervoor dat uw gegevens nooit de geografische grens verlaten.
- Hoge prestaties: de laadsnelheid van gegevens is maximaal 1 gigabyte per seconde (GBps) in Azure Data Explorer. Zie Copy-activiteit prestaties voor meer informatie.
In dit artikel gebruikt u het hulpprogramma Data Factory Copy Data om gegevens uit Amazon Simple Storage Service (S3) te laden in Azure Data Explorer. U kunt een vergelijkbaar proces volgen om gegevens te kopiëren uit andere gegevensarchieven, zoals:
- Azure Blob Storage
- Azure SQL Database
- Azure SQL Data Warehouse
- Google BigQuery
- Oracle
- Bestandssysteem
Vereisten
- Een Azure-abonnement. Maak een gratis Azure-account.
- Een Azure Data Explorer-cluster en -database. Maak een cluster en database.
- Een gegevensbron.
Een gegevensfactory maken
Meld u aan bij de Azure-portal.
Selecteer in het linkerdeelvenster Een resource>maken Analytics>Data Factory.

Geef in het deelvenster Nieuwe gegevensfactory waarden op voor de velden in de volgende tabel:
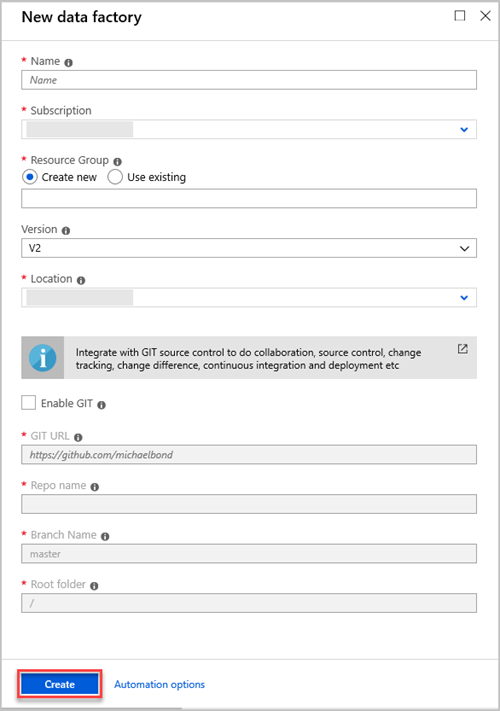
Instelling In te voeren waarde Naam Voer in het vak een wereldwijd unieke naam in voor uw data factory. Als u een foutmelding krijgt dat de naam van de gegevensfactory 'LoadADXDemo' niet beschikbaar is, voert u een andere naam in voor de data factory. Zie Naamgevingsregels voor Data Factory voor regels over de naamgeving van Data Factory-artefacten. Abonnement Selecteer in de vervolgkeuzelijst het Azure-abonnement waarin u de data factory wilt maken. Resourcegroep Selecteer Nieuwe maken en voer vervolgens de naam van een nieuwe resourcegroep in. Als u al een resourcegroep hebt, selecteert u Bestaande gebruiken. Versie Selecteer V2 in de vervolgkeuzelijst. Locatie Selecteer in de vervolgkeuzelijst de locatie voor de gegevensfactory. Alleen ondersteunde locaties worden weergegeven in de lijst. De gegevensarchieven die door de data factory worden gebruikt, kunnen zich op andere locaties of regio's bevinden. Selecteer Maken.
Als u het aanmaakproces wilt controleren, selecteert u Meldingen op de werkbalk. Nadat u de data factory hebt gemaakt, selecteert u deze.
Het deelvenster Data Factory wordt geopend.
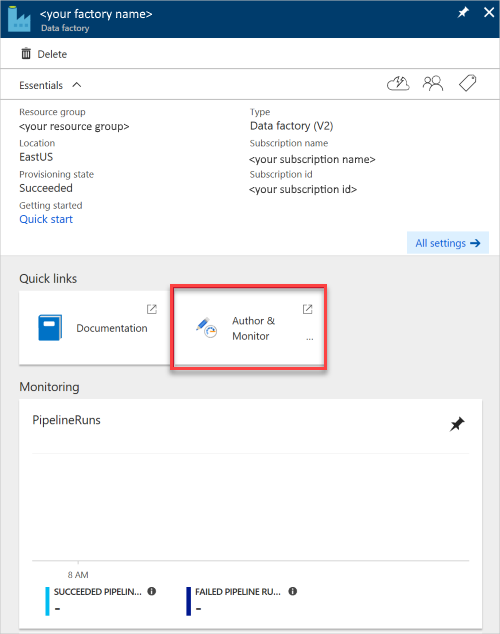
Als u de toepassing in een afzonderlijk deelvenster wilt openen, selecteert u de tegel Author & Monitor .
Gegevens laden in Azure Data Explorer
U kunt gegevens uit veel soorten gegevensarchieven laden in Azure Data Explorer. In dit artikel wordt beschreven hoe u gegevens laadt vanuit Amazon S3.
U kunt uw gegevens op een van de volgende manieren laden:
- Selecteer in de Azure Data Factory gebruikersinterface in het linkerdeelvenster het pictogram Auteur. Dit wordt weergegeven in de sectie Een gegevensfactory maken van Een gegevensfactory maken met behulp van de Azure Data Factory-gebruikersinterface.
- In de Azure Data Factory hulpprogramma Gegevens kopiëren, zoals wordt weergegeven in Het hulpprogramma Gegevens kopiëren gebruiken om gegevens te kopiëren.
Gegevens kopiëren uit Amazon S3 (bron)
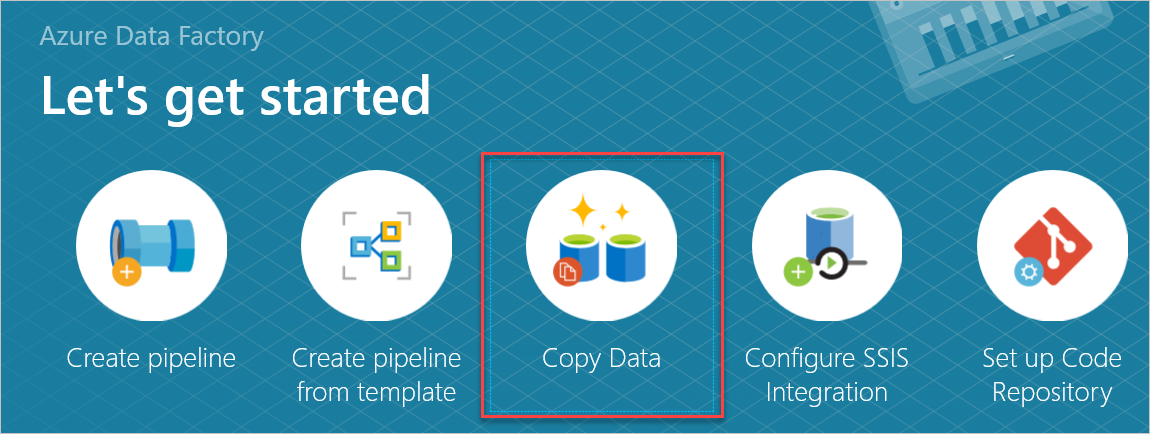
Open in het deelvenster Aan de slag het hulpprogramma Gegevens kopiëren door Gegevens kopiëren te selecteren.
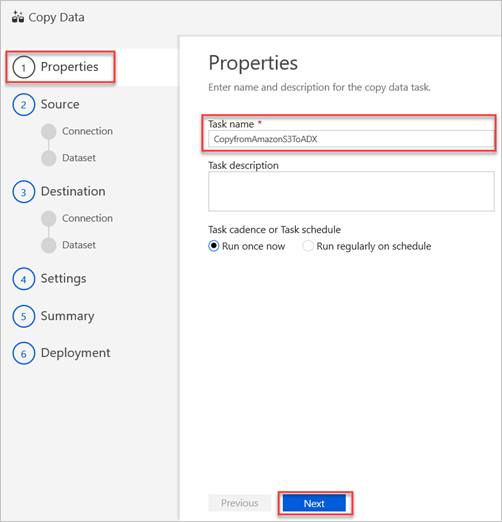
Voer in het deelvenster Eigenschappen in het vak Taaknaam een naam in en selecteer Volgende.
Selecteer in het deelvenster Brongegevensarchiefde optie Nieuwe verbinding maken.
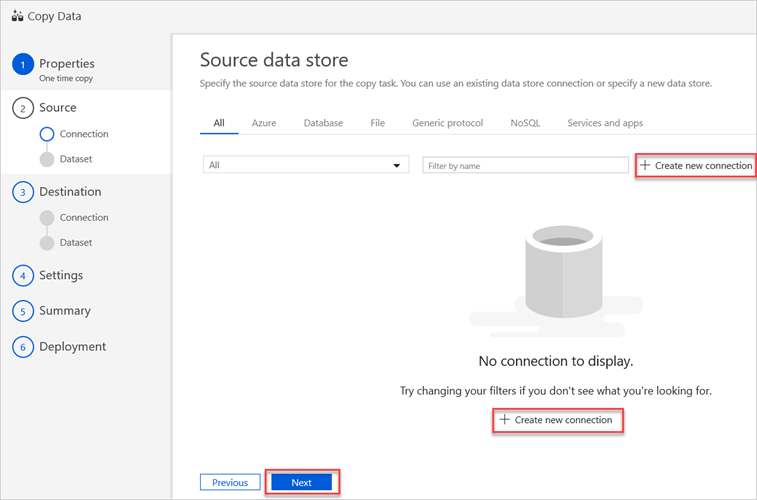
Selecteer Amazon S3 en selecteer vervolgens Doorgaan.
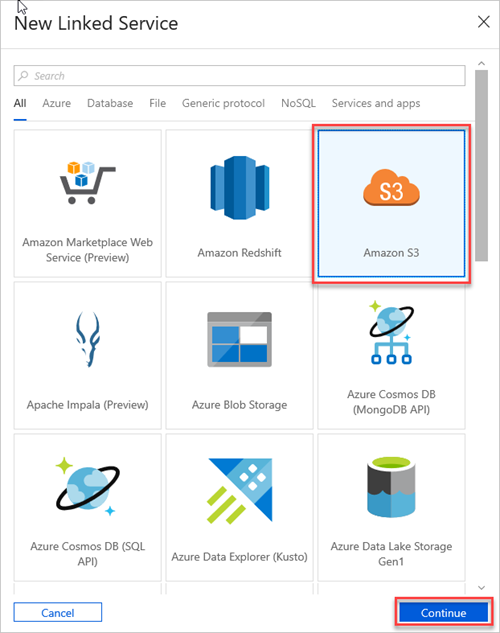
Ga als volgt te werk in het deelvenster Nieuwe gekoppelde service (Amazon S3 ):
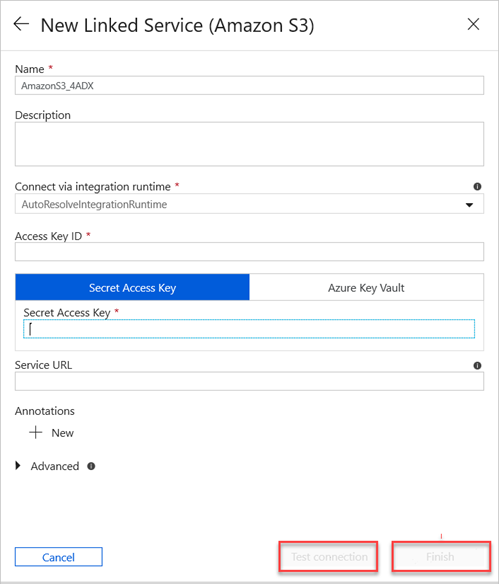
a. Voer in het vak Naam de naam van de nieuwe gekoppelde service in.
b. Selecteer de waarde in de vervolgkeuzelijst Verbinding maken via Integratieruntime .
c. Voer in het vak Toegangssleutel-id de waarde in.
Notitie
Als u in Amazon S3 uw toegangssleutel wilt vinden, selecteert u uw Amazon-gebruikersnaam op de navigatiebalk en selecteert u vervolgens Mijn beveiligingsreferenties.
d. Voer in het vak Geheime toegangssleutel een waarde in.
e. Als u de gekoppelde serviceverbinding wilt testen die u hebt gemaakt, selecteert u Verbinding testen.
f. Selecteer Finish.
In het deelvenster Brongegevensarchief wordt uw nieuwe AmazonS31-verbinding weergegeven.
Selecteer Next.
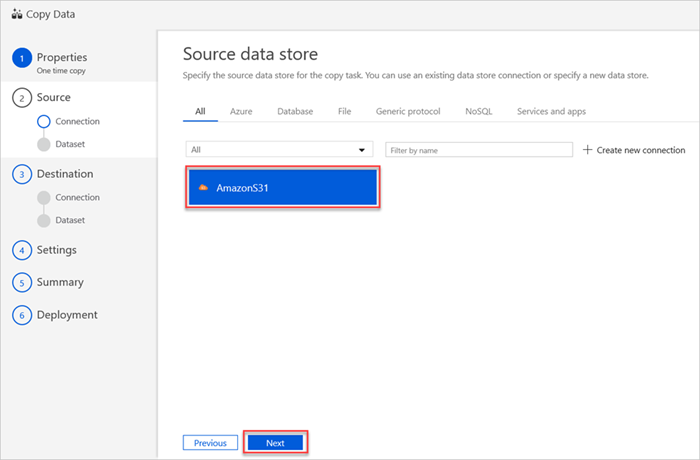
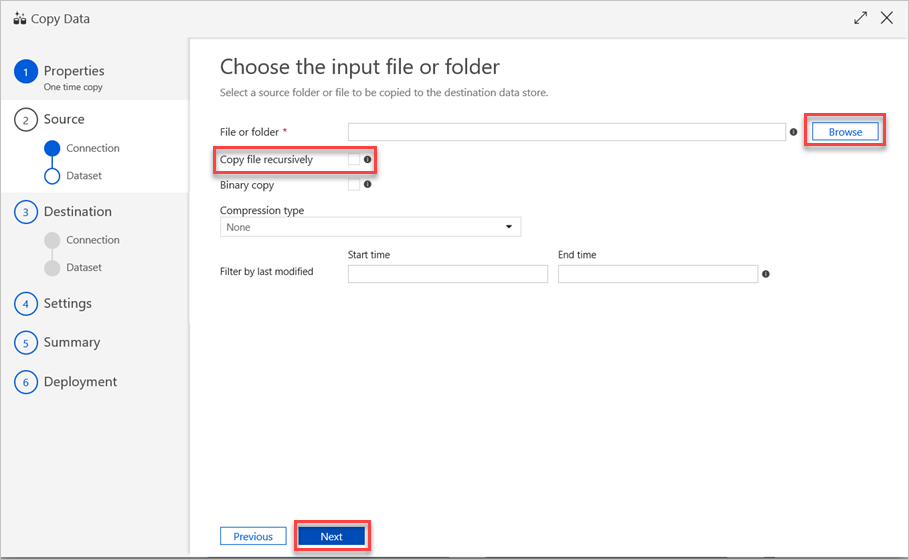
Voer in het deelvenster Het invoerbestand of de invoermap kiezen de volgende stappen uit:
a. Blader naar het bestand of de map die u wilt kopiëren en selecteer het.
b. Selecteer het gewenste kopieergedrag. Zorg ervoor dat het selectievakje Binair kopiëren is uitgeschakeld.
c. Selecteer Volgende.
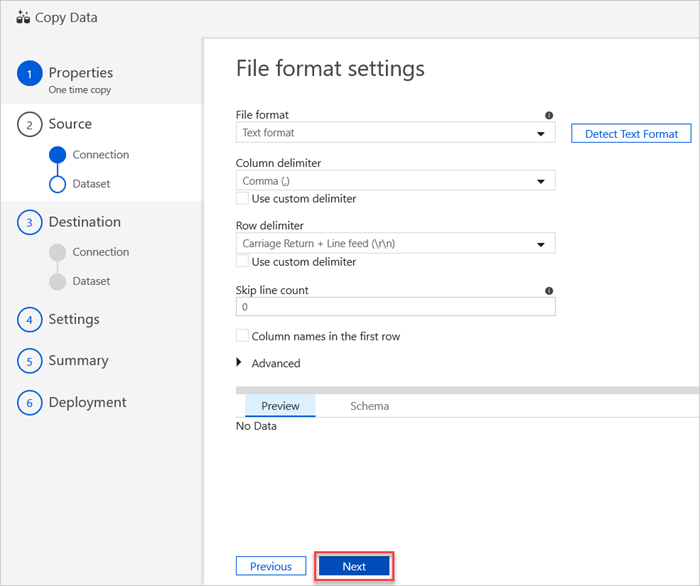
Selecteer in het deelvenster Bestandsindelingsinstellingen de relevante instellingen voor uw bestand. en selecteer volgende.
Gegevens kopiëren naar Azure Data Explorer (doel)
De nieuwe gekoppelde Azure Data Explorer-service wordt gemaakt om de gegevens te kopiëren naar de Azure Data Explorer doeltabel (sink) die in deze sectie is opgegeven.
Notitie
Gebruik de opdrachtactiviteit Azure Data Factory om Azure Data Explorer-beheeropdrachten uit te voeren en een van de gegevens uit queryopdrachten te gebruiken, zoals .set-or-replace.
De gekoppelde Azure Data Explorer-service maken
Voer de volgende stappen uit om de gekoppelde Azure Data Explorer-service te maken:
Als u een bestaande gegevensarchiefverbinding wilt gebruiken of een nieuw gegevensarchief wilt opgeven, selecteert u in het deelvenster Doelgegevensarchiefde optie Nieuwe verbinding maken.
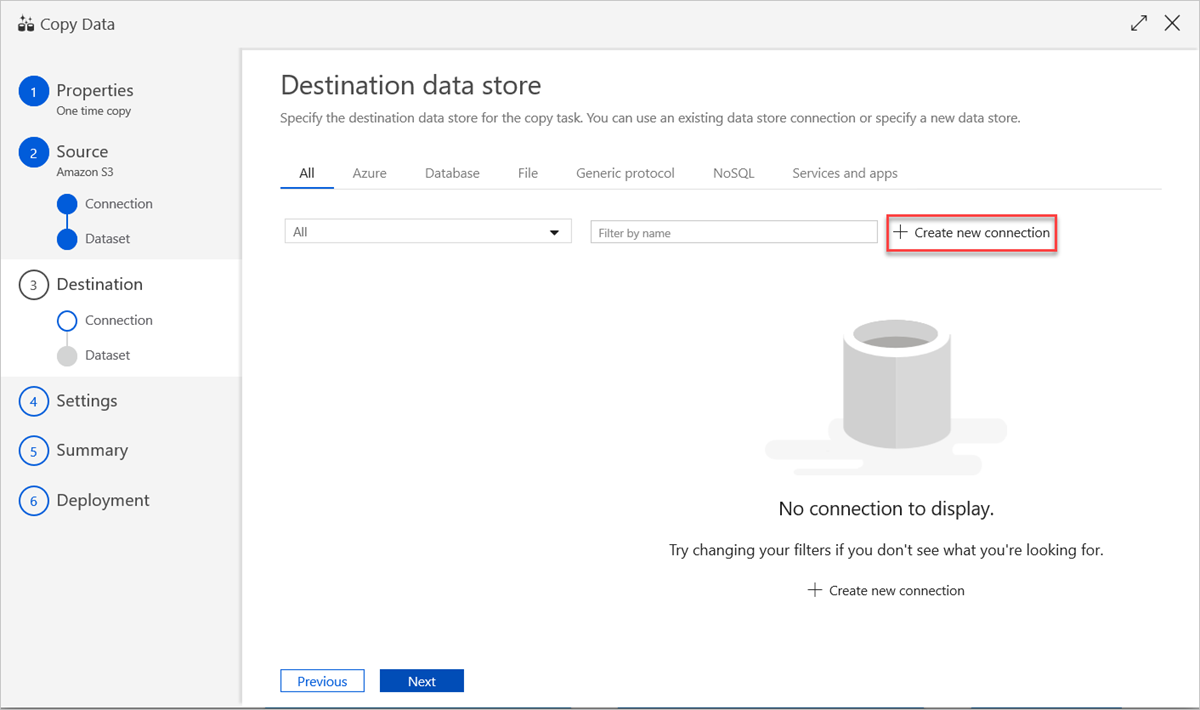
Selecteer in het deelvenster Nieuwe gekoppelde servicede optie Azure Data Explorer en selecteer vervolgens Doorgaan.

Voer in het deelvenster Nieuwe gekoppelde service (Azure Data Explorer) de volgende stappen uit:
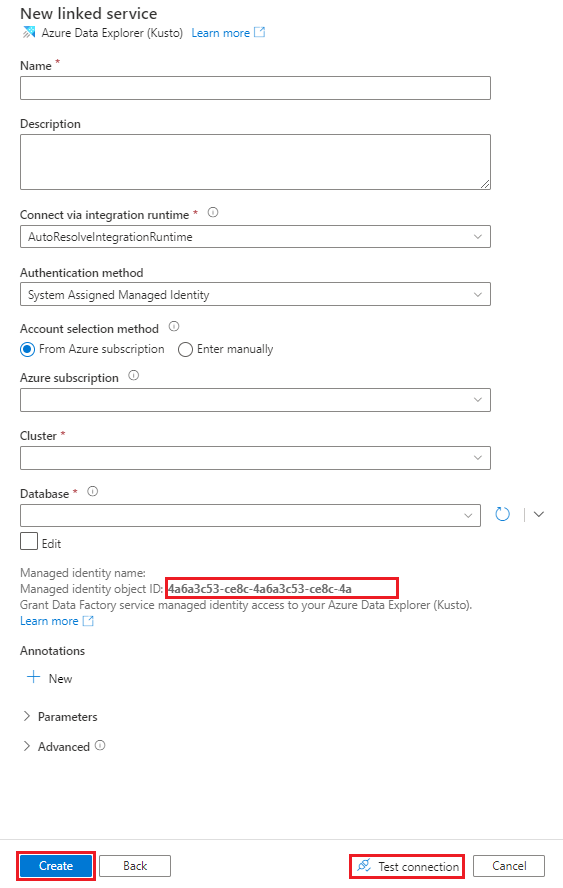
Voer in het vak Naam een naam in voor de gekoppelde Azure Data Explorer service.
Kies onder Verificatiemethode de optie Door het systeem toegewezen beheerde identiteit of service-principal.
Als u wilt verifiëren met een beheerde identiteit, verleent u de beheerde identiteit toegang tot de database met behulp van de naam van de beheerde identiteit of de object-id van de beheerde identiteit.
Verifiëren met behulp van een service-principal:
- Voer in het vak Tenant de naam van de tenant in.
- Voer in het vak Service-principal-id de service-principal-id in.
- Selecteer Service-principalsleutel en voer vervolgens in het vak Service-principalsleutel de waarde voor de sleutel in.
Notitie
- De service-principal wordt door Azure Data Factory gebruikt om toegang te krijgen tot de Azure Data Explorer-service. Als u een service-principal wilt maken, gaat u naar een Microsoft Entra service-principal maken.
- Als u machtigingen wilt toewijzen aan een beheerde identiteit of een service-principal of , raadpleegt u Machtigingen beheren.
- Gebruik niet de Azure Key Vault-methode of door de gebruiker toegewezen beheerde identiteit.
Kies onder Accountselectiemethode een van de volgende opties:
Selecteer Uit Azure-abonnement en selecteer vervolgens in de vervolgkeuzelijsten uw Azure-abonnement en uw cluster.
Notitie
- In de vervolgkeuzelijst Cluster worden alleen clusters weergegeven die zijn gekoppeld aan uw abonnement.
- Uw cluster moet de juiste SKU hebben voor de beste prestaties.
Selecteer Handmatig invoeren en voer vervolgens uw eindpunt in.
Selecteer in de vervolgkeuzelijst Database de naam van uw database. U kunt ook het selectievakje Bewerken inschakelen en de naam van de database invoeren.
Als u de gekoppelde serviceverbinding wilt testen die u hebt gemaakt, selecteert u Verbinding testen. Als u verbinding kunt maken met uw gekoppelde service, wordt in het deelvenster een groen vinkje en het bericht Verbinding gemaakt weergegeven.
Als u de gekoppelde serviceverbinding wilt testen die u hebt gemaakt, selecteert u Verbinding testen. Als u verbinding kunt maken met uw gekoppelde service, wordt in het deelvenster een groen vinkje en het bericht Verbinding gemaakt weergegeven.
Selecteer Maken om het maken van de gekoppelde service te voltooien.
De Azure Data Explorer-gegevensverbinding configureren
Nadat u de gekoppelde serviceverbinding hebt gemaakt, wordt het deelvenster Doelgegevensarchief geopend en is de verbinding die u hebt gemaakt beschikbaar voor gebruik. Voer de volgende stappen uit om de verbinding te configureren:
Selecteer Next.
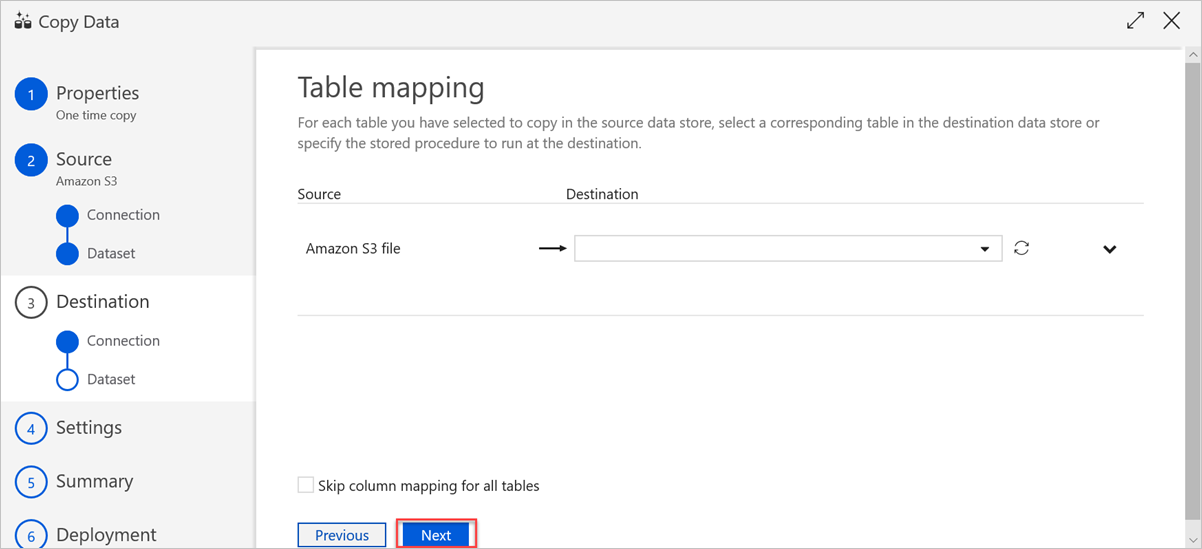
Stel in het deelvenster Tabeltoewijzing de naam van de doeltabel in en selecteer volgende.
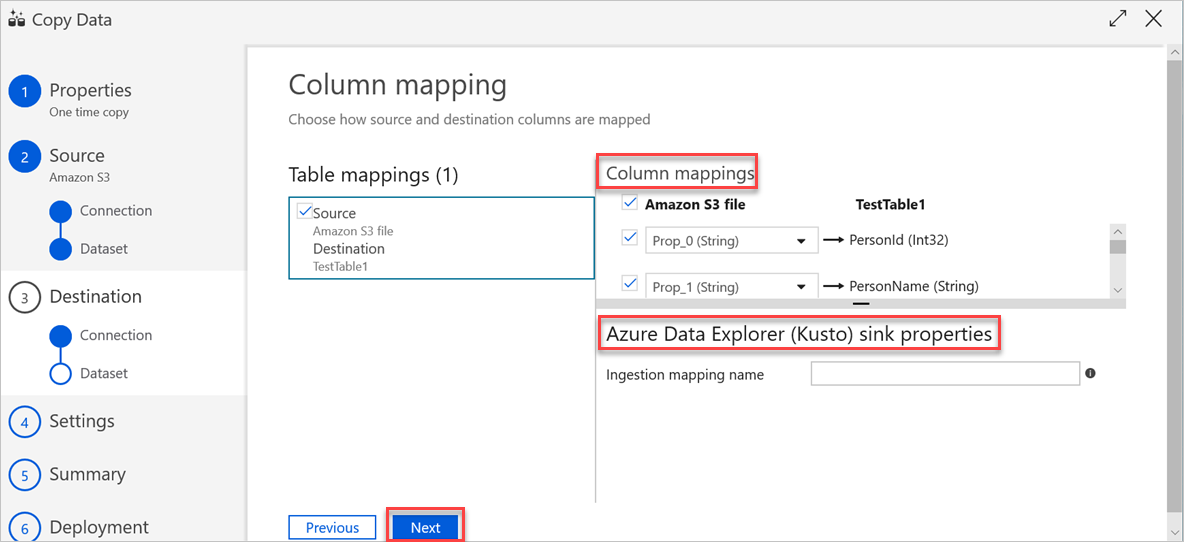
In het deelvenster Kolomtoewijzing vinden de volgende toewijzingen plaats:
a. De eerste toewijzing wordt uitgevoerd door Azure Data Factory volgens de Azure Data Factory schematoewijzing. Ga als volgt te werk:
Stel de kolomtoewijzingen in voor de Azure Data Factory doeltabel. De standaardtoewijzing wordt weergegeven van de bron naar de Azure Data Factory doeltabel.
Annuleer de selectie van de kolommen die u niet nodig hebt om de kolomtoewijzing te definiëren.
b. De tweede toewijzing vindt plaats wanneer deze gegevens in tabelvorm worden opgenomen in Azure Data Explorer. Toewijzing wordt uitgevoerd volgens CSV-toewijzingsregels. Zelfs als de brongegevens geen CSV-indeling hebben, converteert Azure Data Factory de gegevens naar een tabelindeling. Daarom is CSV-toewijzing de enige relevante toewijzing in deze fase. Ga als volgt te werk:
(Optioneel) Voeg onder Eigenschappen van Azure Data Explorer (Kusto) de relevante naam van de opnametoewijzing toe, zodat kolomtoewijzing kan worden gebruikt.
Als de naam van opnametoewijzing niet is opgegeven, wordt de toewijzingsvolgorde op basis van de naam gebruikt die is gedefinieerd in de sectie Kolomtoewijzingen . Als de toewijzing van de by-name mislukt, probeert Azure Data Explorer de gegevens op te nemen in een volgorde van kolomposities (dat wil gezegd, het wordt toegewezen op positie als de standaardinstelling).
Selecteer Next.
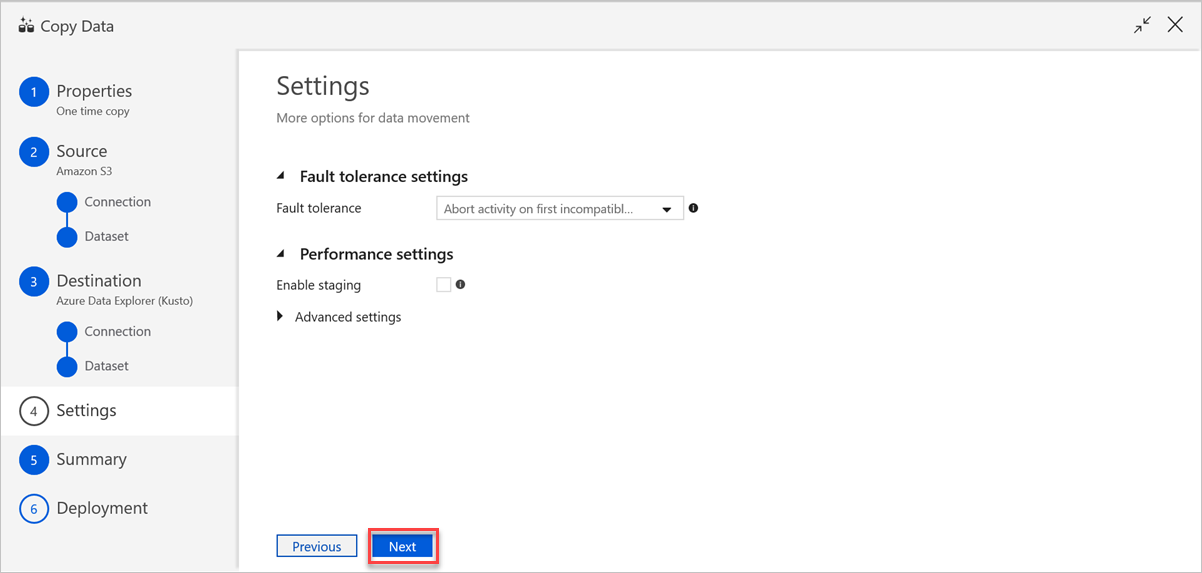
Voer in het deelvenster Instellingen de volgende stappen uit:
a. Voer onder Instellingen voor fouttolerantie de relevante instellingen in.
b. Onder Prestatie-instellingen is fasering inschakelen niet van toepassing en geavanceerde instellingen omvat kostenoverwegingen. Als u geen specifieke vereisten hebt, laat u deze instellingen staan.
c. Selecteer Volgende.
Controleer de instellingen in het deelvenster Samenvatting en selecteer volgende.
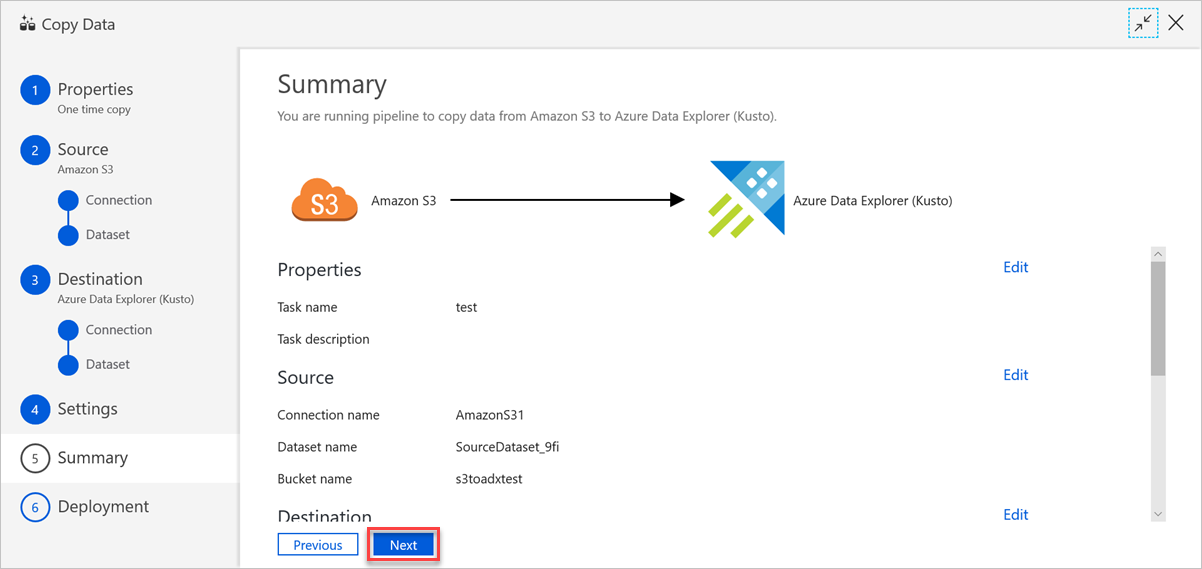
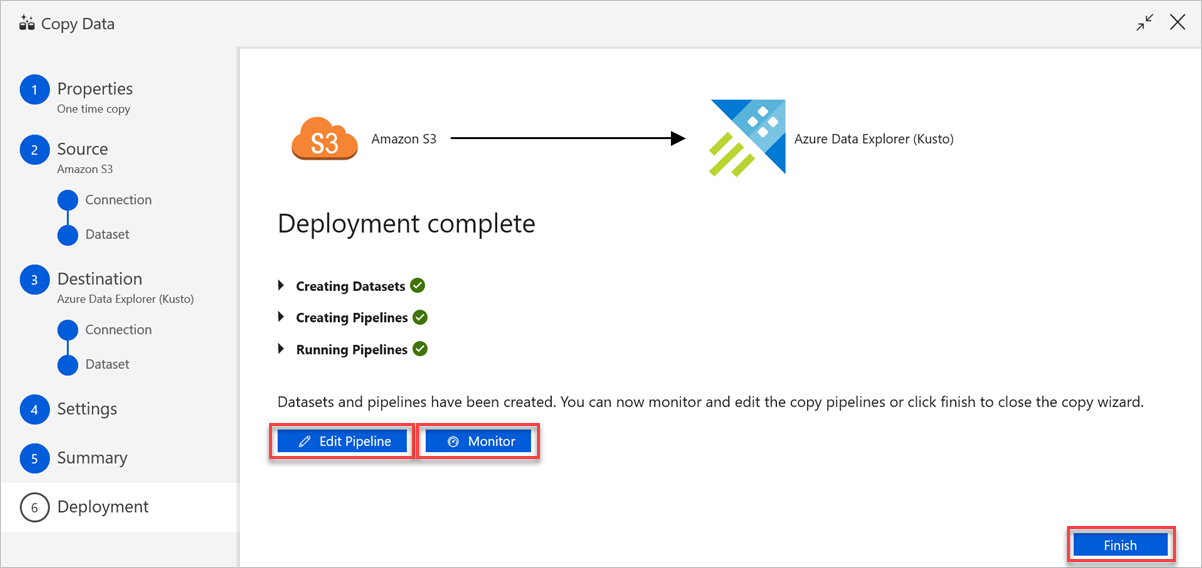
Ga als volgt te werk in het deelvenster Implementatie voltooid :
a. Als u wilt overschakelen naar het tabblad Controleren en de status van de pijplijn wilt weergeven (dat wil gezegd, voortgang, fouten en gegevensstroom), selecteert u Bewaken.
b. Als u gekoppelde services, gegevenssets en pijplijnen wilt bewerken, selecteert u Pijplijn bewerken.
c. Selecteer Voltooien om de kopieertaak voor gegevens te voltooien.
Gerelateerde inhoud
- Meer informatie over de Azure Data Explorer-connector voor Azure Data Factory.
- Bewerk gekoppelde services, gegevenssets en pijplijnen in de gebruikersinterface van Data Factory.
- Query's uitvoeren op gegevens in de webgebruikersinterface van Azure Data Explorer.