Gegevens kopiëren van of naar Azure Data Explorer met behulp van Azure Data Factory of Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u de kopieeractiviteit in Azure Data Factory- en Synapse Analytics-pijplijnen gebruikt om gegevens te kopiëren naar of vanuit Azure Data Explorer. Het is gebaseerd op het artikel over het overzicht van kopieeractiviteiten, dat een algemeen overzicht van de kopieeractiviteit biedt.
Tip
Voor meer informatie over Azure Data Explorer-integratie met de service leest u Over het algemeen Integratie van Azure Data Explorer.
Ondersteunde mogelijkheden
Deze Azure Data Explorer-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR |
|---|---|
| Copy-activiteit (bron/sink) | (1) (2) |
| Toewijzingsgegevensstroom (bron/sink) | (1) |
| Activiteit Lookup | (1) (2) |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
U kunt gegevens kopiëren uit elk ondersteund brongegevensarchief naar Azure Data Explorer. U kunt ook gegevens van Azure Data Explorer kopiëren naar een ondersteund sinkgegevensarchief. Zie de tabel Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die door de kopieeractiviteit worden ondersteund als bronnen of sinks.
Notitie
Het kopiëren van gegevens naar of van Azure Data Explorer via een on-premises gegevensarchief met behulp van zelf-hostende Integration Runtime wordt ondersteund in versie 3.14 en hoger.
Met de Azure Data Explorer-connector kunt u het volgende doen:
- Kopieer gegevens met behulp van verificatie van de Microsoft Entra-toepassingstoken met een service-principal.
- Als bron haalt u gegevens op met behulp van een KQL-query (Kusto).
- Als sink voegt u gegevens toe aan een doeltabel.
Aan de slag
Tip
Zie Gegevens kopiëren naar/van Azure Data Explorer en bulksgewijs kopiëren van een database naar Azure Data Explorer voor een overzicht van de Azure Data Explorer-connector.
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde service maken in Azure Data Explorer met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde service te maken voor Azure Data Explorer in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar Explorer en selecteer de Azure Data Explorer-connector (Kusto).
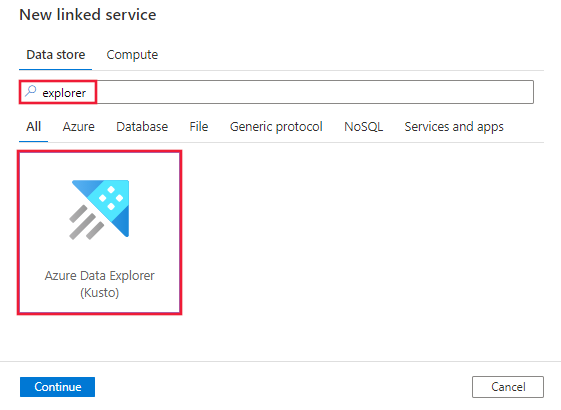
Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
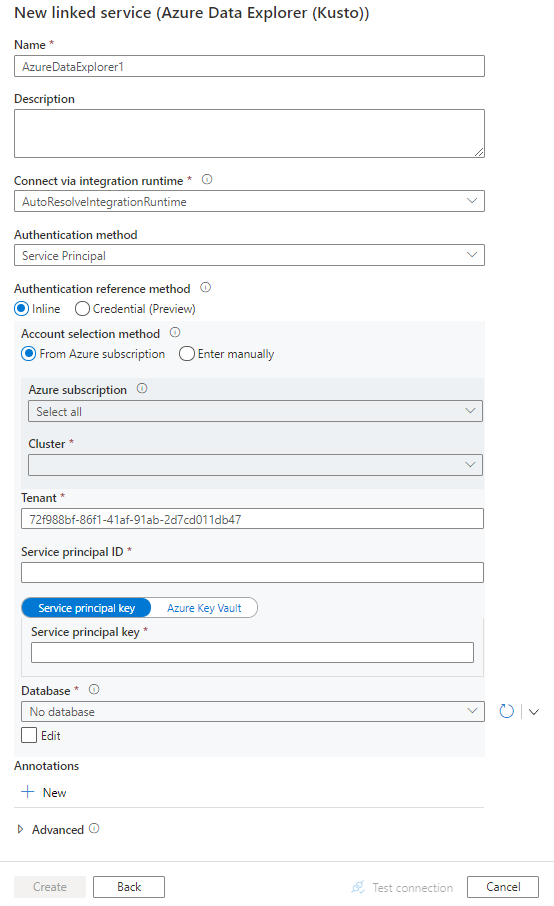
Configuratiedetails van connector
De volgende secties bevatten details over eigenschappen die worden gebruikt om entiteiten te definiëren die specifiek zijn voor de Azure Data Explorer-connector.
Eigenschappen van gekoppelde service
De Azure Data Explorer-connector ondersteunt de volgende verificatietypen. Zie de bijbehorende secties voor meer informatie:
- Verificatie van service-principal
- Door het systeem toegewezen beheerde identiteitverificatie
- Door de gebruiker toegewezen beheerde identiteitverificatie
Verificatie van service-principal
Voer de volgende stappen uit om een service-principal op te halen en machtigingen te verlenen om verificatie van de service-principal te gebruiken:
Een toepassing registreren bij het Microsoft-identiteitsplatform. Zie quickstart: Een toepassing registreren bij het Microsoft Identity Platform voor meer informatie. Noteer deze waarden, die u gebruikt om de gekoppelde service te definiëren:
- Toepassings-id
- Toepassingssleutel
- Tenant-id
Verdeel de service-principal de juiste machtigingen in Azure Data Explorer. Zie Databasemachtigingen voor Azure Data Explorer beheren voor gedetailleerde informatie over rollen en machtigingen en over het beheren van machtigingen. Over het algemeen moet u het volgende doen:
- Als bron verleent u ten minste de rol databaseviewer aan uw database
- Als sink verleent u ten minste de gebruikersrol Database aan uw database
Notitie
Wanneer u de gebruikersinterface gebruikt om te schrijven, wordt standaard uw aanmeldingsgebruikersaccount gebruikt om Azure Data Explorer-clusters, -databases en -tabellen weer te geven. U kunt ervoor kiezen om de objecten weer te geven met behulp van de service-principal door op de vervolgkeuzelijst naast de knop Vernieuwen te klikken of de naam handmatig in te voeren als u niet gemachtigd bent voor deze bewerkingen.
De volgende eigenschappen worden ondersteund voor de gekoppelde Azure Data Explorer-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap moet worden ingesteld op AzureDataExplorer. | Ja |
| endpoint | Eindpunt-URL van het Azure Data Explorer-cluster, met de indeling als https://<clusterName>.<regionName>.kusto.windows.net. |
Ja |
| database | Naam van database. | Ja |
| tenant | Geef de tenantgegevens (domeinnaam of tenant-id) op waaronder uw toepassing zich bevindt. Dit staat bekend als 'Authority ID' in Kusto verbindingsreeks. Haal deze op door de muisaanwijzer in de rechterbovenhoek van Azure Portal aan te wijzen. | Ja |
| servicePrincipalId | Geef de client-id van de toepassing op. Dit staat bekend als de client-id van de Microsoft Entra-toepassing in Kusto verbindingsreeks. | Ja |
| servicePrincipalKey | Geef de sleutel van de toepassing op. Dit staat bekend als 'Microsoft Entra-toepassingssleutel' in Kusto verbindingsreeks. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar beveiligde gegevens die zijn opgeslagen in Azure Key Vault. | Ja |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken als uw gegevensarchief zich in een particulier netwerk bevindt. Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Voorbeeld: verificatie van de service-principalsleutel gebruiken
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"tenant": "<tenant name/id e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
}
}
Door het systeem toegewezen beheerde identiteitverificatie
Als u door het systeem toegewezen beheerde identiteitverificatie wilt gebruiken, voert u de volgende stappen uit om machtigingen te verlenen:
Haal de informatie over de beheerde identiteit op door de waarde van de object-id van de beheerde identiteit te kopiëren die samen met uw factory of Synapse-werkruimte is gegenereerd.
Verdeel de beheerde identiteit de juiste machtigingen in Azure Data Explorer. Zie Databasemachtigingen voor Azure Data Explorer beheren voor gedetailleerde informatie over rollen en machtigingen en over het beheren van machtigingen. Over het algemeen moet u het volgende doen:
- Als bron verleent u de rol Databaseviewer aan uw database.
- Als sink verleent u de rollen Database ingestor en Database viewer aan uw database.
Notitie
Wanneer u de gebruikersinterface gebruikt om te schrijven, wordt uw aanmeldingsgebruikersaccount gebruikt om Azure Data Explorer-clusters, -databases en -tabellen weer te geven. Voer de naam handmatig in als u niet gemachtigd bent voor deze bewerkingen.
De volgende eigenschappen worden ondersteund voor de gekoppelde Azure Data Explorer-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap moet worden ingesteld op AzureDataExplorer. | Ja |
| endpoint | Eindpunt-URL van het Azure Data Explorer-cluster, met de indeling als https://<clusterName>.<regionName>.kusto.windows.net. |
Ja |
| database | Naam van database. | Ja |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken als uw gegevensarchief zich in een particulier netwerk bevindt. Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Voorbeeld: door het systeem toegewezen beheerde identiteitverificatie gebruiken
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
}
}
}
Door de gebruiker toegewezen beheerde identiteitverificatie
Volg deze stappen om door de gebruiker toegewezen beheerde identiteitverificatie te gebruiken:
Maak een of meer door de gebruiker toegewezen beheerde identiteiten en verken machtigingen in Azure Data Explorer. Zie Databasemachtigingen voor Azure Data Explorer beheren voor gedetailleerde informatie over rollen en machtigingen en over het beheren van machtigingen. Over het algemeen moet u het volgende doen:
- Als bron verleent u ten minste de rol databaseviewer aan uw database
- Als sink verleent u ten minste de rol Database ingestor aan uw database
Wijs een of meerdere door de gebruiker toegewezen beheerde identiteiten toe aan uw data factory of Synapse-werkruimte en maak referenties voor elke door de gebruiker toegewezen beheerde identiteit.
De volgende eigenschappen worden ondersteund voor de gekoppelde Azure Data Explorer-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap moet worden ingesteld op AzureDataExplorer. | Ja |
| endpoint | Eindpunt-URL van het Azure Data Explorer-cluster, met de indeling als https://<clusterName>.<regionName>.kusto.windows.net. |
Ja |
| database | Naam van database. | Ja |
| aanmeldingsgegevens | Geef de door de gebruiker toegewezen beheerde identiteit op als referentieobject. | Ja |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken als uw gegevensarchief zich in een particulier netwerk bevindt. Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Voorbeeld: door de gebruiker toegewezen beheerde identiteitverificatie gebruiken
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
}
}
}
Eigenschappen van gegevensset
Zie Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets. In deze sectie vindt u eigenschappen die door de Azure Data Explorer-gegevensset worden ondersteund.
Als u gegevens wilt kopiëren naar Azure Data Explorer, stelt u de typeeigenschap van de gegevensset in op AzureDataExplorerTable.
De volgende eigenschappen worden ondersteund:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap moet worden ingesteld op AzureDataExplorerTable. | Ja |
| table | De naam van de tabel waarnaar de gekoppelde service verwijst. | Ja voor sink; Nee voor bron |
Voorbeeld van gegevensseteigenschappen:
{
"name": "AzureDataExplorerDataset",
"properties": {
"type": "AzureDataExplorerTable",
"typeProperties": {
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure Data Explorer linked service name>",
"type": "LinkedServiceReference"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie Pijplijnen en activiteiten voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die door Azure Data Explorer-bronnen en -sinks worden ondersteund.
Azure Data Explorer als bron
Als u gegevens uit Azure Data Explorer wilt kopiëren, stelt u de typeeigenschap in de Copy-activiteit bron in op AzureDataExplorerSource. De volgende eigenschappen worden ondersteund in de sectie bron van kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op: AzureDataExplorerSource | Ja |
| query | Een alleen-lezen aanvraag die is opgegeven in een KQL-indeling. Gebruik de aangepaste KQL-query als verwijzing. | Ja |
| queryTimeout | De wachttijd voordat er een time-out optreedt voor de queryaanvraag. De standaardwaarde is 10 minuten (00:10:00); toegestane maximumwaarde is 1 uur (01:00:00). | Nee |
| noTruncation | Hiermee wordt aangegeven of de geretourneerde resultatenset moet worden afgekapt. Standaard wordt het resultaat afgekapt na 500.000 records of 64 MB (megabytes). Afkapping wordt sterk aanbevolen om het juiste gedrag van de activiteit te garanderen. | Nr. |
Notitie
Azure Data Explorer-bron heeft standaard een groottelimiet van 500.000 records of 64 MB. Als u alle records wilt ophalen zonder afkapping, kunt u aan het begin van de query opgeven set notruncation; . Zie Querylimieten voor meer informatie.
Voorbeeld:
"activities":[
{
"name": "CopyFromAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "AzureDataExplorerSource",
"query": "TestTable1 | take 10",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
},
"inputs": [
{
"referenceName": "<Azure Data Explorer input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
]
}
]
Azure Data Explorer als sink
Als u gegevens wilt kopiëren naar Azure Data Explorer, stelt u de typeeigenschap in de sink van de kopieeractiviteit in op AzureDataExplorerSink. De volgende eigenschappen worden ondersteund in de sectie sink voor kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de sink van de kopieeractiviteit moet worden ingesteld op: AzureDataExplorerSink. | Ja |
| ingestionMappingName | Naam van een vooraf gemaakte toewijzing in een Kusto-tabel. Als u de kolommen van de bron wilt toewijzen aan Azure Data Explorer (die van toepassing is op alle ondersteunde bronarchieven en -indelingen, inclusief CSV/JSON/Avro-indelingen), kunt u de kolomtoewijzing voor kopieeractiviteiten (impliciet op naam of expliciet zoals geconfigureerd) en/of Azure Data Explorer-toewijzingen gebruiken. | Nee |
| additionalProperties | Een eigenschappentas die kan worden gebruikt voor het opgeven van een van de opname-eigenschappen die niet al door de Azure Data Explorer-sink worden ingesteld. Het kan handig zijn voor het opgeven van opnametags. Meer informatie vindt u in Azure Data Explore-document voor gegevensopname. | Nee |
Voorbeeld:
"activities":[
{
"name": "CopyToAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataExplorerSink",
"ingestionMappingName": "<optional Azure Data Explorer mapping name>",
"additionalProperties": {<additional settings for data ingestion>}
}
},
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Data Explorer output dataset name>",
"type": "DatasetReference"
}
]
}
]
Eigenschappen van toewijzingsgegevensstroom
Wanneer u gegevens transformeert in de toewijzingsgegevensstroom, kunt u lezen van en schrijven naar tabellen in Azure Data Explorer. Zie de brontransformatie en sinktransformatie in toewijzingsgegevensstromen voor meer informatie. U kunt ervoor kiezen om een Azure Data Explorer-gegevensset of een inlinegegevensset te gebruiken als bron- en sinktype.
Brontransformatie
De onderstaande tabel bevat de eigenschappen die worden ondersteund door de Azure Data Explorer-bron. U kunt deze eigenschappen bewerken op het tabblad Bronopties .
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Tabel | Als u Tabel als invoer selecteert, haalt de gegevensstroom alle gegevens op uit de tabel die is opgegeven in de Azure Data Explorer-gegevensset of in de bronopties bij gebruik van inlinegegevensset. | Nee | String | (alleen voor inlinegegevensset) tableName |
| Query | Een alleen-lezen aanvraag die is opgegeven in een KQL-indeling. Gebruik de aangepaste KQL-query als verwijzing. | Nee | String | query |
| Timeout | De wachttijd voordat er een time-out optreedt voor de queryaanvraag. De standaardwaarde is 172000 (2 dagen) | Nee | Geheel getal | timeout |
Voorbeelden van Azure Data Explorer-bronscripts
Wanneer u azure Data Explorer-gegevensset als brontype gebruikt, is het bijbehorende gegevensstroomscript:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'table | take 10',
format: 'query') ~> AzureDataExplorerSource
Als u inlinegegevensset gebruikt, is het bijbehorende gegevensstroomscript:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'table | take 10',
store: 'azuredataexplorer') ~> AzureDataExplorerSource
Sinktransformatie
De onderstaande tabel bevat de eigenschappen die worden ondersteund door de Azure Data Explorer-sink. U kunt deze eigenschappen bewerken op het tabblad Instellingen . Wanneer u een inlinegegevensset gebruikt, ziet u aanvullende instellingen, die hetzelfde zijn als de eigenschappen die worden beschreven in de sectie eigenschappen van de gegevensset.
| Name | Beschrijving | Vereist | Toegestane waarden | Eigenschap gegevensstroomscript |
|---|---|---|---|---|
| Tabelactie | Bepaalt of alle rijen uit de doeltabel opnieuw moeten worden gemaakt of verwijderd voordat ze worden geschreven. - Geen: Er wordt geen actie uitgevoerd voor de tabel. - Opnieuw maken: de tabel wordt verwijderd en opnieuw gemaakt. Vereist als u dynamisch een nieuwe tabel maakt. - Afkappen: alle rijen uit de doeltabel worden verwijderd. |
Nee | true of false |
recreëren truncate |
| Pre- en post-SQL-scripts | Geef meerdere Kusto-besturingsopdrachten op die worden uitgevoerd vóór (voorverwerking) en na (naverwerking) gegevens naar uw sinkdatabase worden geschreven. | Nee | String | preSQLs; postSQLs |
| Timeout | De wachttijd voordat er een time-out optreedt voor de queryaanvraag. De standaardwaarde is 172000 (2 dagen) | Nee | Geheel getal | timeout |
Voorbeelden van sinkscripts voor Azure Data Explorer
Wanneer u de Azure Data Explorer-gegevensset als sinktype gebruikt, is het bijbehorende gegevensstroomscript:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
preSQLs:['pre SQL scripts'],
postSQLs:['post SQL script'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Als u inlinegegevensset gebruikt, is het bijbehorende gegevensstroomscript:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
store: 'azuredataexplorer',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Eigenschappen van opzoekactiviteit
Zie Lookup-activiteit voor meer informatie over de eigenschappen.
Gerelateerde inhoud
Zie ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die door de kopieeractiviteit worden ondersteund als bronnen en sinks.
Meer informatie over het kopiëren van gegevens uit Azure Data Factory en Synapse Analytics naar Azure Data Explorer.