Gegevenssets in Azure Data Factory en Azure Synapse Analytics
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven wat gegevenssets zijn, hoe ze zijn gedefinieerd in JSON-indeling en hoe ze worden gebruikt in Azure Data Factory- en Synapse-pijplijnen.
Zie Inleiding tot Azure Data Factory voor een overzicht als u geen toegang hebt tot Data Factory. Zie Wat is Azure Synapse voor meer informatie over Azure Synapse
Overzicht
Een Azure Data Factory- of Synapse-werkruimte kan een of meer pijplijnen hebben. Een pijplijn is een logische groepering van activiteiten die samen een taak uitvoeren. De activiteiten in een pijplijn bepalen acties die moeten worden uitgevoerd op uw gegevens. Een gegevensset is nu een benoemde weergave van gegevens die alleen naar de gegevens verwijst die u in uw activiteiten wilt gebruiken als invoer en uitvoer. Met gegevenssets worden gegevens binnen andere gegevensarchieven geïdentificeerd, waaronder tabellen, bestanden, mappen en documenten. Een Azure Blob-gegevensset geeft bijvoorbeeld de blobcontainer en map in Blob Storage op waaruit de activiteit de gegevens moet lezen.
Voordat u een gegevensset maakt, moet u een gekoppelde service maken om uw gegevensarchief aan de service te koppelen. Gekoppelde services zijn vergelijkbaar met verbindingsreeks s, waarmee de verbindingsgegevens worden gedefinieerd die nodig zijn voor de service om verbinding te maken met externe resources. Denk er zo aan; de gegevensset vertegenwoordigt de structuur van de gegevens in de gekoppelde gegevensarchieven en de gekoppelde service definieert de verbinding met de gegevensbron. Een gekoppelde Azure Storage-service koppelt bijvoorbeeld een opslagaccount. Een Azure Blob-gegevensset vertegenwoordigt de blobcontainer en de map in dat Azure Storage-account dat de invoer-blobs bevat die moeten worden verwerkt.
Hier volgt een voorbeeldscenario. Als u gegevens wilt kopiëren van Blob Storage naar een SQL Database, maakt u twee gekoppelde services: Azure Blob Storage en Azure SQL Database. Maak vervolgens twee gegevenssets: gegevensset met scheidingstekens (die verwijst naar de gekoppelde Azure Blob Storage-service, ervan uitgaande dat u tekstbestanden als bron hebt) en Azure SQL Table-gegevensset (die verwijst naar de gekoppelde Azure SQL Database-service). De gekoppelde Azure Blob Storage- en Azure SQL Database-services bevatten verbindingsreeks s die de service tijdens runtime gebruikt om verbinding te maken met uw Azure Storage en Azure SQL Database. De gegevensset Met scheidingstekens voor tekst geeft de blobcontainer en blobmap op die de invoer-blobs in uw Blob Storage bevat, samen met instellingen voor opmaak. De Azure SQL Table-gegevensset geeft de SQL-tabel in uw SQL Database op waarnaar de gegevens moeten worden gekopieerd.
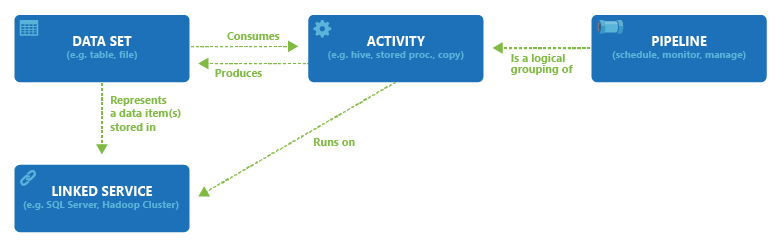
In het volgende diagram ziet u de relaties tussen pijplijn, activiteit, gegevensset en gekoppelde services:
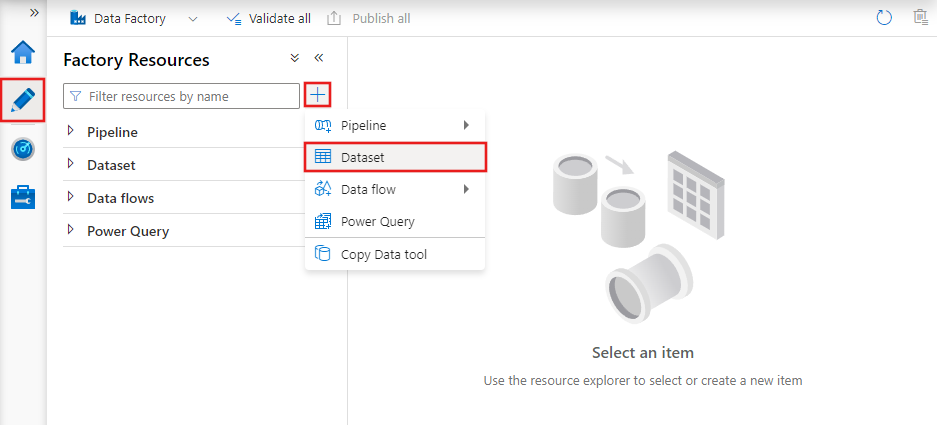
Een gegevensset maken met de gebruikersinterface
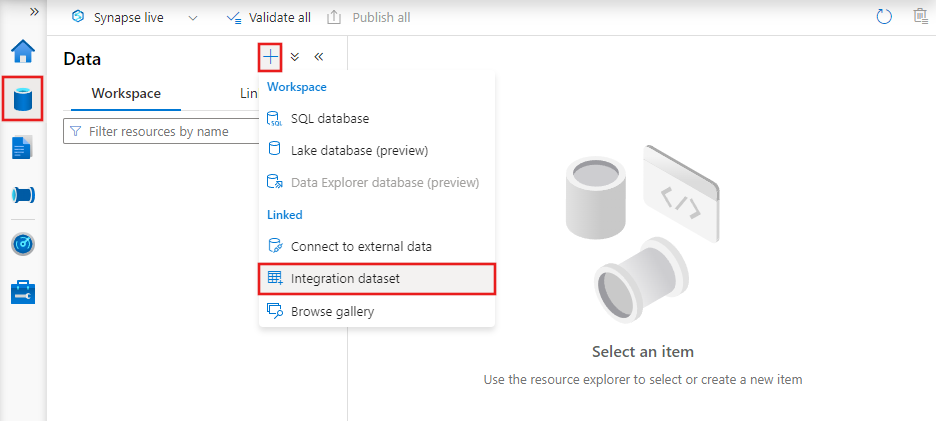
Als u een gegevensset wilt maken met Azure Data Factory Studio, selecteert u het tabblad Auteur (met het potloodpictogram) en vervolgens het plustekenpictogram om Gegevensset te kiezen.
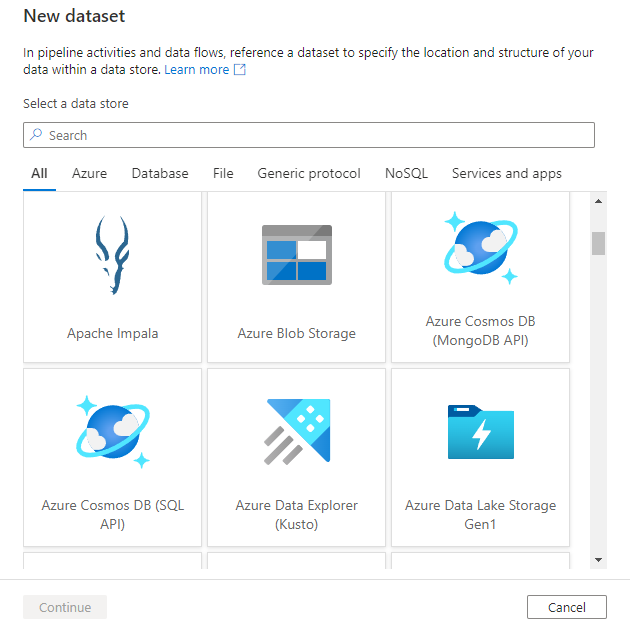
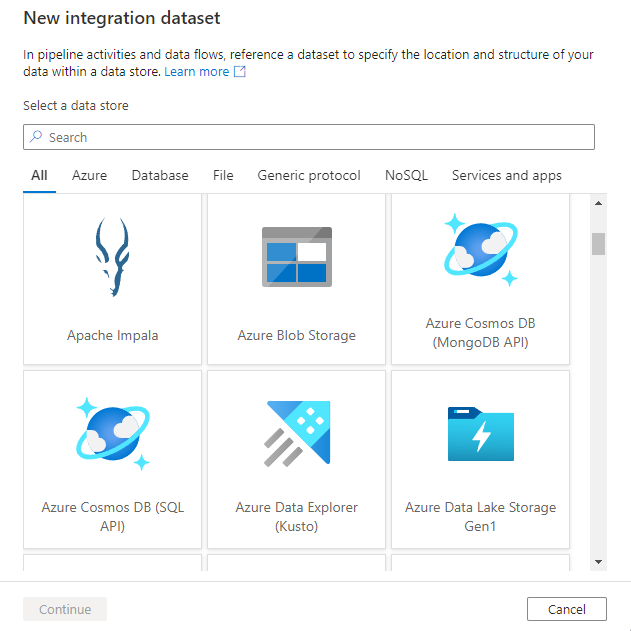
U ziet het venster nieuwe gegevensset om een van de connectors te kiezen die beschikbaar zijn in Azure Data Factory, om een bestaande of nieuwe gekoppelde service in te stellen.
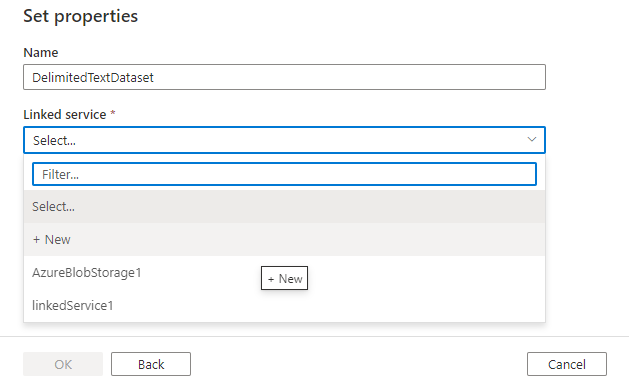
Vervolgens wordt u gevraagd om de indeling van de gegevensset te kiezen.

Ten slotte kunt u een bestaande gekoppelde service kiezen van het type dat u hebt geselecteerd voor de gegevensset of een nieuwe maken als deze nog niet is gedefinieerd.
Zodra u de gegevensset hebt gemaakt, kunt u deze in elke pijplijn in Azure Data Factory gebruiken.
JSON-gegevensset
Een gegevensset wordt gedefinieerd in de volgende JSON-indeling:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
In de volgende tabel worden eigenschappen in de bovenstaande JSON beschreven:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| naam | Naam van de gegevensset. Zie Naamgevingsregels. | Ja |
| type | Type van de gegevensset. Geef een van de typen op die worden ondersteund door Data Factory (bijvoorbeeld: DelimitedText, AzureSqlTable). Zie Gegevenssettypen voor meer informatie. |
Ja |
| schema | Het schema van de gegevensset vertegenwoordigt het fysieke gegevenstype en de vorm. | Nee |
| typeProperties | De typeeigenschappen verschillen voor elk type. Zie Het type gegevensset voor meer informatie over de ondersteunde typen en de bijbehorende eigenschappen. | Ja |
Wanneer u het schema van de gegevensset importeert, selecteert u de knop Schema importeren en kiest u ervoor om te importeren uit de bron of uit een lokaal bestand. In de meeste gevallen importeert u het schema rechtstreeks vanuit de bron. Maar als u al een lokaal schemabestand (een Parquet-bestand of CSV met headers) hebt, kunt u de service omsturen om het schema op dat bestand te baseren.
Bij kopieeractiviteit worden gegevenssets gebruikt in de bron en sink. Het schema dat in de gegevensset is gedefinieerd, is optioneel als verwijzing. Als u kolom-/veldtoewijzing tussen bron en sink wilt toepassen, raadpleegt u Schema en typetoewijzing.
In Gegevensstroom worden gegevenssets gebruikt in bron- en sinktransformaties. De gegevenssets definiëren de basisgegevensschema's. Als uw gegevens geen schema hebben, kunt u schemadrift gebruiken voor uw bron en sink. Metagegevens van de gegevenssets worden weergegeven in uw brontransformatie als bronprojectie. De projectie in de brontransformatie vertegenwoordigt de Gegevensstroom gegevens met gedefinieerde namen en typen.
Gegevenssettype
De service ondersteunt veel verschillende typen gegevenssets, afhankelijk van de gegevensarchieven die u gebruikt. U vindt de lijst met ondersteunde gegevensarchieven in het overzichtsartikel van de connector. Selecteer een gegevensarchief voor meer informatie over het maken van een gekoppelde service en een gegevensset.
Voor een gegevensset met scheidingstekens wordt het gegevenssettype bijvoorbeeld ingesteld op DelimitedText , zoals wordt weergegeven in het volgende JSON-voorbeeld:
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
Notitie
De schemawaarde wordt gedefinieerd met behulp van JSON-syntaxis. Raadpleeg het Azure Data Factory-kopieeractiviteitsschema en de documentatie over typetoewijzingen voor meer gedetailleerde informatie over schematoewijzing en toewijzing van gegevenstypen.
Gegevenssets maken
U kunt gegevenssets maken met behulp van een van deze hulpprogramma's of SDK's: .NET API, PowerShell, REST API, Azure Resource Manager-sjabloon en Azure Portal
Huidige versie versus versie 1-gegevenssets
Hier volgen enkele verschillen tussen gegevenssets in de huidige versie van Data Factory (en Azure Synapse) en de verouderde Data Factory-versie 1:
- De externe eigenschap wordt niet ondersteund in de huidige versie. Deze wordt vervangen door een trigger.
- Het beleid en de beschikbaarheidseigenschappen worden niet ondersteund in de huidige versie. De begintijd voor een pijplijn is afhankelijk van triggers.
- Bereikgegevenssets (gegevenssets die zijn gedefinieerd in een pijplijn) worden niet ondersteund in de huidige versie.
Gerelateerde inhoud
Snelstartgidsen
Zie de volgende zelfstudie voor stapsgewijze instructies voor het maken van pijplijnen en gegevenssets met behulp van een van deze hulpprogramma's of SDK's.
- Snelstartgids: een gegevensfactory maken met .NET
- Quickstart: een data factory maken met Behulp van PowerShell
- Quickstart: een data factory maken met behulp van REST API
- Quickstart: Een data factory maken met behulp van Azure Portal