Azure Data Factory gebruiken om gegevens te migreren van een on-premises Netezza-server naar Azure
VAN TOEPASSING OP: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Azure Data Factory biedt een krachtig, robuust en rendabel mechanisme voor het migreren van gegevens op schaal van een on-premises Netezza-server naar uw Azure-opslagaccount of Azure Synapse Analytics-database.
Dit artikel bevat de volgende informatie voor data engineers en ontwikkelaars:
- Prestaties
- Tolerantie voor kopiëren
- Netwerkbeveiliging
- Oplossingsarchitectuur op hoog niveau
- Best practices voor implementatie
Prestaties
Azure Data Factory biedt een serverloze architectuur waarmee parallelle uitvoering op verschillende niveaus mogelijk is. Als u een ontwikkelaar bent, betekent dit dat u pijplijnen kunt bouwen om zowel netwerk- als databasebandbreedte volledig te gebruiken om de doorvoer van gegevensverplaatsing voor uw omgeving te maximaliseren.
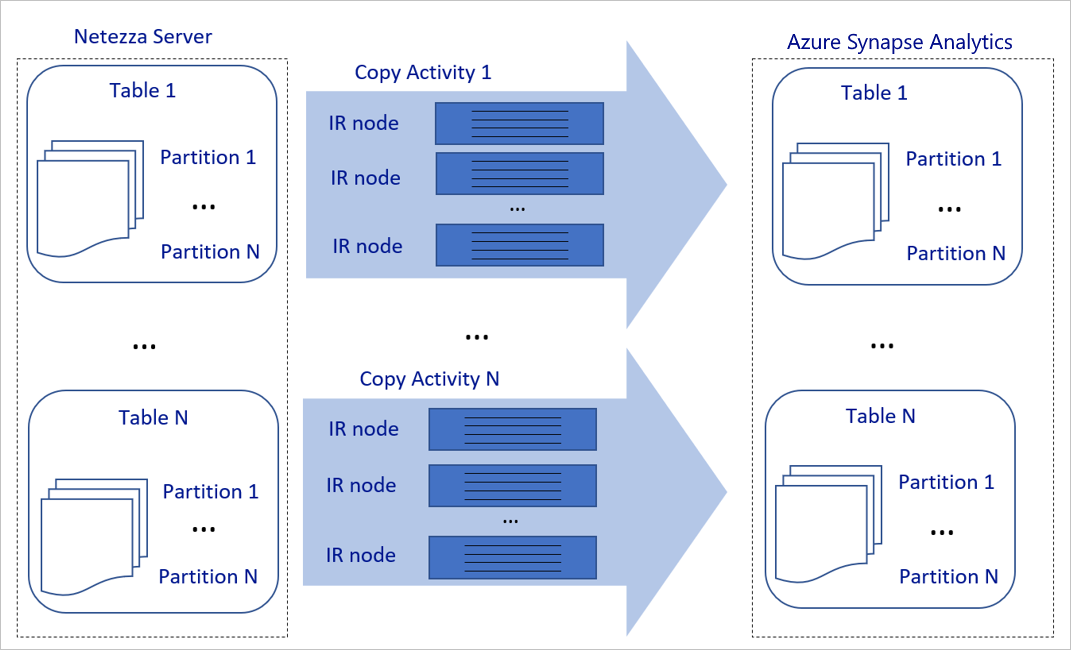
Het voorgaande diagram kan als volgt worden geïnterpreteerd:
Eén kopieeractiviteit kan profiteren van schaalbare rekenresources. Wanneer u Azure Integration Runtime gebruikt, kunt u maximaal 256 DIUs opgeven voor elke kopieeractiviteit op een serverloze manier. Met een zelf-hostende Integration Runtime (zelf-hostende IR) kunt u de machine handmatig omhoog schalen of uitschalen naar meerdere computers (maximaal vier knooppunten) en één kopieeractiviteit verdeelt de partitie over alle knooppunten.
Eén kopieeractiviteit leest van en schrijft naar het gegevensarchief met behulp van meerdere threads.
De controlestroom van Azure Data Factory kan meerdere kopieeractiviteiten parallel starten. De lus kan bijvoorbeeld worden gestart met behulp van een For Each-lus.
Zie Copy-activiteit handleiding voor prestaties en schaalbaarheid voor meer informatie.
Flexibiliteit
Binnen één uitvoering van een kopieeractiviteit heeft Azure Data Factory een ingebouwd mechanisme voor opnieuw proberen, waarmee een bepaald niveau van tijdelijke fouten in de gegevensarchieven of in het onderliggende netwerk kan worden verwerkt.
Wanneer u met de kopieeractiviteit van Azure Data Factory gegevens kopieert tussen bron- en sinkgegevensarchieven, hebt u twee manieren om incompatibele rijen te verwerken. U kunt de kopieeractiviteit afbreken en mislukken of de rest van de gegevens blijven kopiëren door de incompatibele gegevensrijen over te slaan. Daarnaast kunt u de incompatibele rijen in Azure Blob Storage of Azure Data Lake Store vastleggen, de gegevens in de gegevensbron corrigeren en de kopieeractiviteit opnieuw uitvoeren om de oorzaak van de fout te achterhalen.
Netwerkbeveiliging
Azure Data Factory draagt standaard gegevens van de on-premises Netezza-server over naar een Azure-opslagaccount of Azure Synapse Analytics-database met behulp van een versleutelde verbinding via Hypertext Transfer Protocol Secure (HTTPS). HTTPS biedt gegevensversleuteling tijdens overdracht en voorkomt afluisteren en man-in-the-middle-aanvallen.
Als u niet wilt dat gegevens via het openbare internet worden overgedragen, kunt u ook een hogere beveiliging bereiken door gegevens over te dragen via een privépeeringskoppeling via Azure Express Route.
In de volgende sectie wordt beschreven hoe u een hogere beveiliging kunt bereiken.
Architectuur voor de oplossing
In deze sectie worden twee manieren besproken om uw gegevens te migreren.
Gegevens migreren via het openbare internet
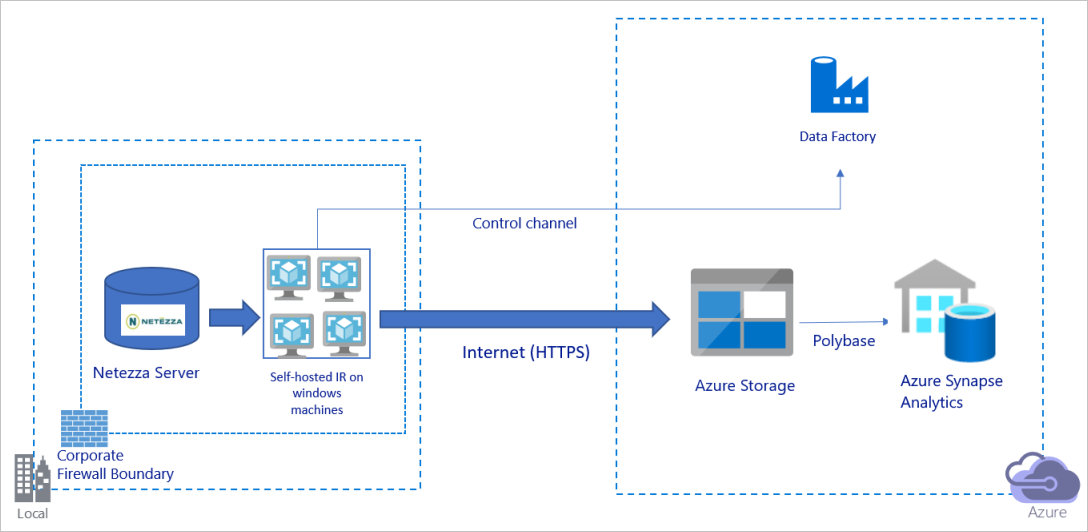
Het voorgaande diagram kan als volgt worden geïnterpreteerd:
In deze architectuur brengt u gegevens veilig over met behulp van HTTPS via het openbare internet.
Voor deze architectuur moet u de Azure Data Factory Integration Runtime (zelf-hostend) installeren op een Windows-computer achter een bedrijfsfirewall. Zorg ervoor dat deze integration runtime rechtstreeks toegang heeft tot de Netezza-server. Als u uw netwerk en gegevensopslagbandbreedte volledig wilt gebruiken om gegevens te kopiëren, kunt u uw machine handmatig omhoog schalen of uitschalen naar meerdere computers.
Met deze architectuur kunt u zowel de eerste momentopnamegegevens als deltagegevens migreren.
Gegevens migreren via een particulier netwerk
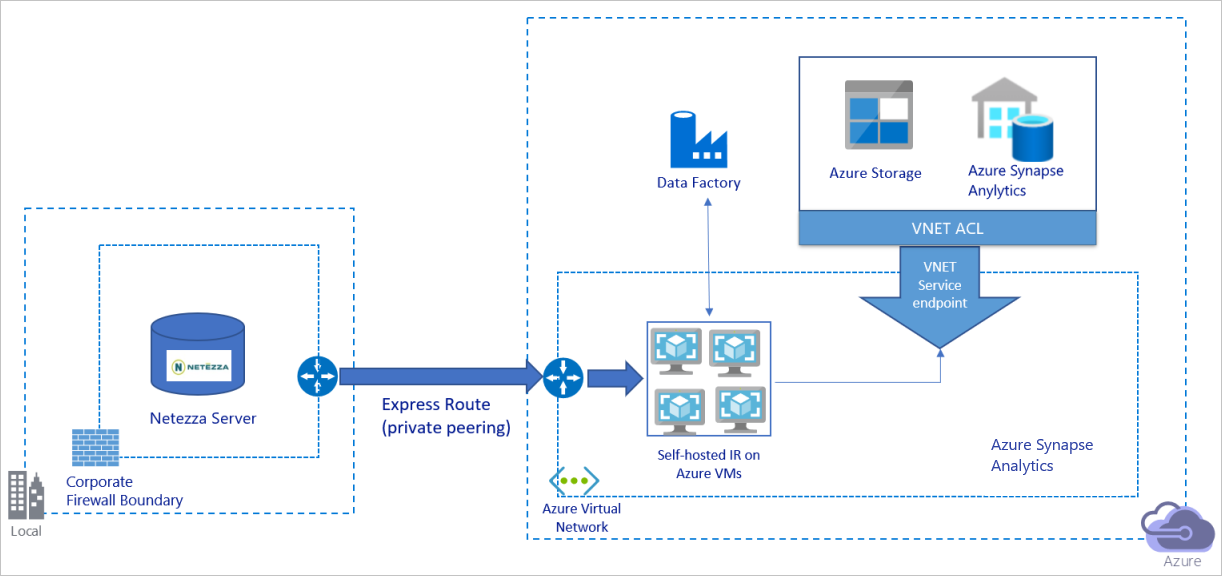
Het voorgaande diagram kan als volgt worden geïnterpreteerd:
In deze architectuur migreert u gegevens via een privépeeringskoppeling via Azure Express Route, en gegevens gaan nooit via het openbare internet.
Voor deze architectuur moet u de Azure Data Factory Integration Runtime (zelf-hostend) installeren op een virtuele Windows-machine (VM) in uw virtuele Azure-netwerk. Als u uw netwerk en gegevensopslagbandbreedte volledig wilt gebruiken om gegevens te kopiëren, kunt u uw VIRTUELE machine handmatig omhoog schalen of uitschalen naar meerdere VM's.
Met deze architectuur kunt u zowel de eerste momentopnamegegevens als deltagegevens migreren.
Best practices implementeren
Verificatie en referenties beheren
Voor verificatie bij Netezza kunt u ODBC-verificatie gebruiken via verbindingsreeks.
Verifiëren bij Azure Blob Storage:
We raden u ten zeerste aan beheerde identiteiten te gebruiken voor Azure-resources. Op basis van een automatisch beheerde Azure Data Factory-identiteit in Microsoft Entra ID kunt u met beheerde identiteiten pijplijnen configureren zonder dat u referenties hoeft op te geven in de definitie van de gekoppelde service.
U kunt zich ook verifiëren bij Azure Blob Storage met behulp van een service-principal, een handtekening voor gedeelde toegang of een sleutel voor een opslagaccount.
Verifiëren bij Azure Data Lake Storage Gen2:
We raden u ten zeerste aan beheerde identiteiten te gebruiken voor Azure-resources.
U kunt ook een service-principal of een opslagaccountsleutel gebruiken.
Verifiëren bij Azure Synapse Analytics:
We raden u ten zeerste aan beheerde identiteiten te gebruiken voor Azure-resources.
U kunt ook service-principal- of SQL-verificatie gebruiken.
Wanneer u geen beheerde identiteiten gebruikt voor Azure-resources, raden we u ten zeerste aan de referenties op te slaan in Azure Key Vault om het eenvoudiger te maken om sleutels centraal te beheren en te roteren zonder gekoppelde Azure Data Factory-services te hoeven wijzigen. Dit is ook een van de aanbevolen procedures voor CI/CD.
Eerste momentopnamegegevens migreren
Voor kleine tabellen (dat wil gezegd, tabellen met een volume van minder dan 100 GB of die binnen twee uur naar Azure kunnen worden gemigreerd), kunt u elke kopieertaakgegevens per tabel laden. Voor een grotere doorvoer kunt u meerdere Azure Data Factory-kopieertaken uitvoeren om afzonderlijke tabellen gelijktijdig te laden.
Binnen elke kopieertaak, om parallelle query's uit te voeren en gegevens te kopiëren op partities, kunt u ook een bepaald niveau van parallelle uitvoering bereiken met behulp van de parallelCopies eigenschapsinstelling met een van de volgende opties voor gegevenspartitie:
Voor een betere efficiëntie raden we u aan om te beginnen vanuit een gegevenssegment. Zorg ervoor dat de waarde in de
parallelCopiesinstelling kleiner is dan het totale aantal partities in gegevenssegmenten in uw tabel op de Netezza-server.Als het volume van elke gegevenssegmentpartitie nog steeds groot is (bijvoorbeeld 10 GB of hoger), raden we u aan over te schakelen naar een partitie voor dynamisch bereik. Met deze optie hebt u meer flexibiliteit om het aantal partities en het volume van elke partitie per partitiekolom, bovengrens en ondergrens te definiëren.
Voor grotere tabellen (dat wil gezegd, tabellen met een volume van 100 GB of hoger of die niet binnen twee uur naar Azure kunnen worden gemigreerd), raden we u aan om de gegevens te partitioneren op basis van een aangepaste query en vervolgens elke kopieertaak één partitie tegelijk te kopiëren. Voor een betere doorvoer kunt u meerdere Azure Data Factory-kopieertaken gelijktijdig uitvoeren. Voor elk kopieertaakdoel voor het laden van één partitie per aangepaste query, kunt u de doorvoer verhogen door parallellisme in te schakelen via een gegevenssegment of dynamisch bereik.
Als een kopieertaak mislukt vanwege een tijdelijk probleem met een netwerk of gegevensarchief, kunt u de mislukte kopieertaak opnieuw uitvoeren om die specifieke partitie opnieuw uit de tabel te laden. Andere kopieertaken die andere partities laden, worden niet beïnvloed.
Wanneer u gegevens in een Azure Synapse Analytics-database laadt, raden we u aan PolyBase in te schakelen binnen de kopieertaak met Azure Blob Storage als fasering.
Deltagegevens migreren
Als u de nieuwe of bijgewerkte rijen uit uw tabel wilt identificeren, gebruikt u een tijdstempelkolom of een incrementele sleutel in het schema. Vervolgens kunt u de meest recente waarde opslaan als een hoog watermerk in een externe tabel en deze vervolgens gebruiken om de deltagegevens te filteren wanneer u de gegevens de volgende keer laadt.
Elke tabel kan een andere watermerkkolom gebruiken om de nieuwe of bijgewerkte rijen te identificeren. U wordt aangeraden een externe besturingstabel te maken. In de tabel vertegenwoordigt elke rij één tabel op de Netezza-server met de specifieke kolomnaam van het watermerk en een hoge grenswaarde.
Een zelf-hostende Integration Runtime configureren
Als u gegevens migreert van de Netezza-server naar Azure, of de server zich on-premises achter de firewall van uw bedrijf of in een virtuele netwerkomgeving bevindt, moet u een zelf-hostende IR installeren op een Windows-machine of -VM. Dit is de engine die wordt gebruikt om gegevens te verplaatsen. Wanneer u de zelf-hostende IR installeert, raden we de volgende methode aan:
Begin voor elke Windows-machine of VM met een configuratie van 32 vCPU's en 128 GB geheugen. U kunt het CPU- en geheugengebruik van de IR-machine tijdens de gegevensmigratie blijven bewaken om te zien of u de machine verder moet schalen voor betere prestaties of de machine omlaag moet schalen om kosten te besparen.
U kunt ook uitschalen door maximaal vier knooppunten te koppelen aan één zelf-hostende IR. Met één kopieertaak die wordt uitgevoerd op een zelf-hostende IR, worden automatisch alle VM-knooppunten toegepast om de gegevens parallel te kopiëren. Voor hoge beschikbaarheid begint u met vier VM-knooppunten om een single point of failure tijdens de gegevensmigratie te voorkomen.
Uw partities beperken
Als best practice voert u een poC (Performance Proof of Concept) uit met een representatieve voorbeeldgegevensset, zodat u de juiste partitiegrootte voor elke kopieeractiviteit kunt bepalen. We raden u aan om elke partitie binnen twee uur naar Azure te laden.
Als u een tabel wilt kopiëren, begint u met één kopieeractiviteit met één zelf-hostende IR-machine. Verhoog geleidelijk de parallelCopies instelling op basis van het aantal partities in gegevenssegmenten in uw tabel. Kijk of de hele tabel binnen twee uur naar Azure kan worden geladen, afhankelijk van de doorvoer die het resultaat is van de kopieertaak.
Als het niet binnen twee uur in Azure kan worden geladen en de capaciteit van het zelf-hostende IR-knooppunt en het gegevensarchief niet volledig worden gebruikt, verhoogt u geleidelijk het aantal gelijktijdige kopieeractiviteiten totdat u de limiet van uw netwerk of de bandbreedtelimiet van de gegevensarchieven bereikt.
Blijf het CPU- en geheugengebruik op de zelf-hostende IR-machine bewaken en klaar zijn om de machine omhoog te schalen of uit te schalen naar meerdere computers wanneer u ziet dat de CPU en het geheugen volledig worden gebruikt.
Wanneer u bandbreedtebeperkingsfouten ondervindt, zoals gerapporteerd door de kopieeractiviteit van Azure Data Factory, vermindert u de gelijktijdigheid of parallelCopies instelling in Azure Data Factory, of kunt u overwegen de bandbreedte- of I/O-bewerkingen per seconde (IOPS) van het netwerk en de gegevensarchieven te verhogen.
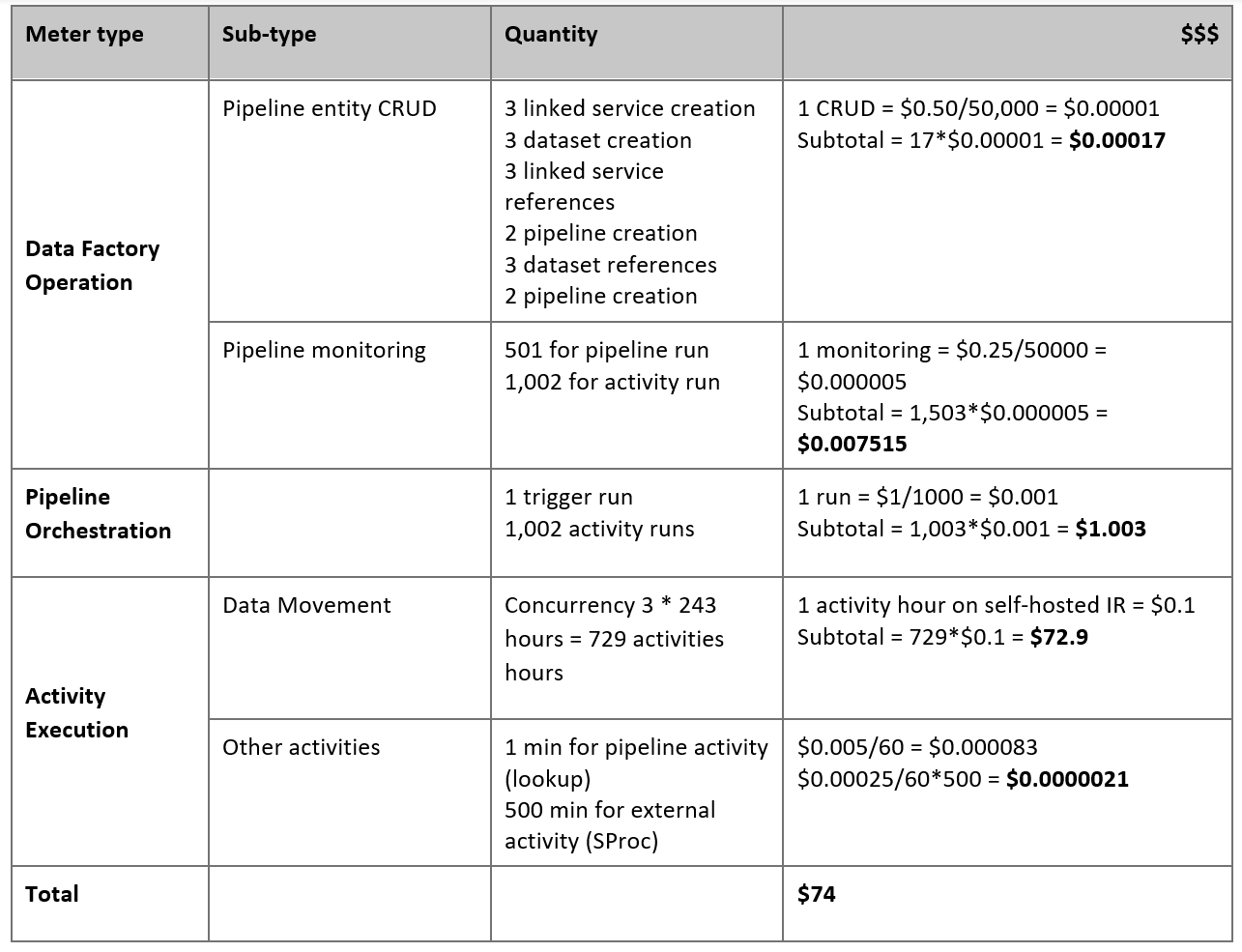
Uw prijzen schatten
Overweeg de volgende pijplijn, die is samengesteld om gegevens van de on-premises Netezza-server te migreren naar een Azure Synapse Analytics-database:
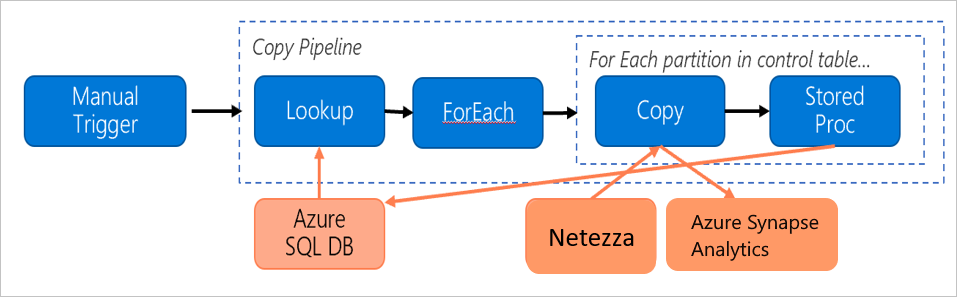
Stel dat de volgende instructies waar zijn:
Het totale gegevensvolume is 50 terabytes (TB).
We migreren gegevens met behulp van de architectuur van de eerste oplossing (de Netezza-server bevindt zich on-premises achter de firewall).
Het volume van 50 TB is onderverdeeld in 500 partities en elke kopieeractiviteit verplaatst één partitie.
Elke kopieeractiviteit wordt geconfigureerd met één zelf-hostende IR op vier computers en bereikt een doorvoer van 20 megabytes per seconde (MBps). (Binnen kopieeractiviteit
parallelCopiesis ingesteld op 4 en elke thread voor het laden van gegevens uit de tabel bereikt een doorvoer van 5 MBps.)De Gelijktijdigheid van ForEach is ingesteld op 3 en de geaggregeerde doorvoer is 60 MBps.
In totaal duurt het 243 uur om de migratie te voltooien.
Op basis van de voorgaande veronderstellingen is dit de geschatte prijs:
Notitie
De prijzen in de voorgaande tabel zijn hypothetisch. De werkelijke prijzen zijn afhankelijk van de werkelijke doorvoer in uw omgeving. De prijs voor de Windows-computer (waarbij de zelf-hostende IR is geïnstalleerd) is niet inbegrepen.
Aanvullende naslaginformatie
Zie de volgende artikelen en handleidingen voor meer informatie:
- Netezza-connector
- ODBC-connector
- Azure Blob Storage-connector
- Azure Data Lake Storage Gen2-connector
- Azure Synapse Analytics-connector
- handleiding voor het afstemmen van Copy-activiteit prestaties
- Zelf-hostende Integration Runtime maken en configureren
- Zelf-hostende Integration Runtime HA en schaalbaarheid
- Beveiligingsoverwegingen voor gegevensverplaatsing
- Referenties opslaan in Azure Key Vault
- Gegevens incrementeel kopiëren uit één tabel
- Gegevens incrementeel kopiëren uit meerdere tabellen
- Pagina met prijzen voor Azure Data Factory