HDInsight Spark-cluster gebruiken om gegevens te analyseren in Data Lake Storage Gen1
In dit artikel gebruikt u Jupyter Notebook die beschikbaar is met HDInsight Spark-clusters om een taak uit te voeren waarmee gegevens uit een Data Lake Storage-account worden gelezen.
Vereisten
Azure Data Lake Storage Gen1-account. Volg de instructies bij Aan de slag met Azure Data Lake Storage Gen1 met behulp van Azure Portal.
Azure HDInsight Spark-cluster met Data Lake Storage Gen1 als opslag. Volg de instructies in quickstart: Clusters instellen in HDInsight.
De gegevens voorbereiden
Notitie
U hoeft deze stap niet uit te voeren als u het HDInsight-cluster hebt gemaakt met Data Lake Storage als standaardopslag. Tijdens het maken van het cluster worden enkele voorbeeldgegevens toegevoegd aan het Data Lake Storage-account dat u opgeeft tijdens het maken van het cluster. Ga naar de sectie HDInsight Spark-cluster gebruiken met Data Lake Storage.
Als u een HDInsight-cluster met Data Lake Storage hebt gemaakt als extra opslag en Azure Storage Blob als standaardopslag, moet u eerst enkele voorbeeldgegevens naar het Data Lake Storage-account kopiëren. U kunt de voorbeeldgegevens gebruiken uit de Azure Storage-blob die is gekoppeld aan het HDInsight-cluster.
Open een opdrachtprompt en navigeer naar de map waarin AdlCopy is geïnstalleerd, meestal
%HOMEPATH%\Documents\adlcopy.Voer de volgende opdracht uit om een specifieke blob van de broncontainer naar Data Lake Storage te kopiëren:
AdlCopy /source https://<source_account>.blob.core.windows.net/<source_container>/<blob name> /dest swebhdfs://<dest_adls_account>.azuredatalakestore.net/<dest_folder>/ /sourcekey <storage_account_key_for_storage_container>Kopieer het HVAC.csv voorbeeldgegevensbestand op /HdiSamples/HdiSamples/SensorSampleData/hvac/ naar het Azure Data Lake Storage-account. Het codefragment moet er als volgt uitzien:
AdlCopy /Source https://mydatastore.blob.core.windows.net/mysparkcluster/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv /dest swebhdfs://mydatalakestore.azuredatalakestore.net/hvac/ /sourcekey uJUfvD6cEvhfLoBae2yyQf8t9/BpbWZ4XoYj4kAS5Jf40pZaMNf0q6a8yqTxktwVgRED4vPHeh/50iS9atS5LQ==Waarschuwing
Zorg ervoor dat de bestands- en padnamen het juiste hoofdlettergebruik gebruiken.
U wordt gevraagd de referenties in te voeren voor het Azure-abonnement waaronder u uw Data Lake Storage-account hebt. Het volgende (of een vergelijkbaar) codefragment wordt weergegeven:
Initializing Copy. Copy Started. 100% data copied. Copy Completed. 1 file copied.Het gegevensbestand (HVAC.csv) wordt gekopieerd onder een map /hvac in het Data Lake Storage-account.
Een HDInsight Spark-cluster gebruiken met Data Lake Storage Gen1
Klik vanuit Azure Portal vanaf het startboard op de tegel voor uw Apache Spark-cluster (als u het hebt vastgemaakt aan het startboard). U kunt ook naar uw cluster navigeren onder Bladeren>HDInsight-clusters.
Klik vanuit de blade Spark-cluster op Snelkoppelingen. Klik vervolgens vanuit het Cluster-dashboard op Jupyter Notebook. Voer de beheerdersreferenties voor het cluster in als u daarom wordt gevraagd.
Notitie
Mogelijk bereikt u de Jupyter-notebook voor uw cluster ook door de volgende URL in uw browser te openen. Vervang CLUSTERNAME door de naam van uw cluster.
https://CLUSTERNAME.azurehdinsight.net/jupyterMaak een nieuwe notebook. Klik op Nieuw en klik vervolgens op PySpark.
Omdat u de notebook met behulp van de PySpark-kernel hebt gemaakt, hoeft u niet expliciet contexten te maken. De Spark- en Hive-contexten worden automatisch voor u gemaakt tijdens het uitvoeren van de eerste codecel. Als eerste stap importeert u de typen die voor dit scenario zijn vereist. Plak hiertoe het volgende codefragment in een cel en druk op SHIFT + ENTER.
from pyspark.sql.types import *Telkens wanneer u een taak in Jupyter uitvoert, toont de venstertitel van uw webbrowser de status (Bezet) samen met de notebooktitel. Ook ziet u een gevulde cirkel naast de PySpark-tekst in de rechterbovenhoek. Nadat de taak is voltooid, verandert deze in een lege cirkel.

Laad voorbeeldgegevens in een tijdelijke tabel met behulp van het HVAC.csv-bestand dat u naar het Data Lake Storage Gen1-account hebt gekopieerd. U hebt toegang tot de gegevens in het Data Lake Storage-account met behulp van het volgende URL-patroon.
Als u Data Lake Storage Gen1 als standaardopslag hebt, bevindt HVAC.csv zich op het pad dat vergelijkbaar is met de volgende URL:
adl://<data_lake_store_name>.azuredatalakestore.net/<cluster_root>/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvU kunt ook een verkorte indeling gebruiken, zoals de volgende:
adl:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvAls u Data Lake Storage als extra opslag hebt, bevindt HVAC.csv zich op de locatie waar u deze hebt gekopieerd, zoals:
adl://<data_lake_store_name>.azuredatalakestore.net/<path_to_file>Plak in een lege cel het volgende codevoorbeeld, vervang MYDATALAKESTORE door de naam van uw Data Lake Storage-account en druk op Shift+Enter. Dit codevoorbeeld registreert de gegevens in een tijdelijke tabel genaamd hvac.
# Load the data. The path below assumes Data Lake Storage is default storage for the Spark cluster hvacText = sc.textFile("adl://MYDATALAKESTORazuredatalakestore. net/cluster/mysparkclusteHdiSamples/HdiSamples/ SensorSampleData/hvac/HVAC.csv") # Create the schema hvacSchema = StructType([StructField("date", StringTy(), False) ,StructField("time", StringType(), FalseStructField ("targettemp", IntegerType(), FalseStructField("actualtemp", IntegerType(), FalseStructField("buildingID", StringType(), False)]) # Parse the data in hvacText hvac = hvacText.map(lambda s: s.split(",")).filt(lambda s: s [0] != "Date").map(lambda s:(str(s[0]), s(s[1]), int(s[2]), int (s[3]), str(s[6]) )) # Create a data frame hvacdf = sqlContext.createDataFrame(hvac,hvacSchema) # Register the data fram as a table to run queries against hvacdf.registerTempTable("hvac")
Omdat u een PySpark-kernel gebruikt, kunt u nu rechtstreeks een SQL-query uitvoeren op de tijdelijke tabel hvac, die u zojuist hebt gemaakt met behulp van de
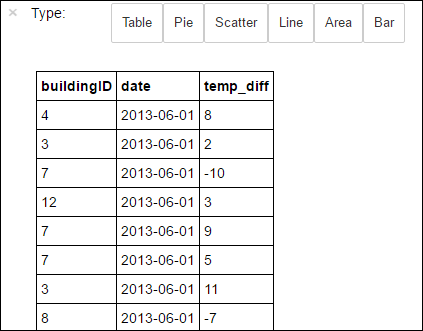
%%sql-magic. Zie Kernels die beschikbaar zijn op Jupyter Notebooks met Apache Spark HDInsight-clusters voor meer informatie over de%%sqlmagie en andere magics die beschikbaar zijn met de PySpark-kernel.%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Nadat de taak is voltooid, wordt standaard de volgende uitvoer in tabelvorm weergegeven.
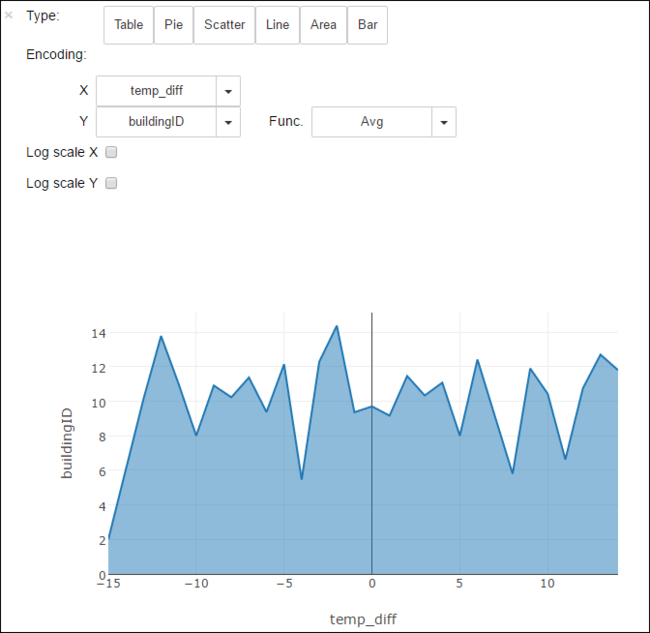
U kunt de resultaten ook in andere visualisaties bekijken. Zo ziet een gebiedsgrafiek voor dezelfde uitvoer er als volgt uit.
Wanneer u klaar bent met het uitvoeren van de toepassing, moet u de notebook afsluiten om de resources vrij te geven. Dit doet u door in het menu Bestand in de notebook te klikken op Sluiten en stoppen. Hiermee wordt de notebook afgesloten.
Volgende stappen
- Een zelfstandige Scala-toepassing maken die moet worden uitgevoerd in een Apache Spark-cluster
- HDInsight Tools gebruiken in Azure Toolkit voor IntelliJ om Apache Spark-toepassingen te maken voor HDInsight Spark Linux-cluster
- HDInsight Tools gebruiken in Azure Toolkit voor Eclipse om Apache Spark-toepassingen te maken voor HDInsight Spark Linux-cluster
- Azure Data Lake Storage Gen2 gebruiken met Azure HDInsight-clusters
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor