Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Gebruik HDInsight Tools in Azure Toolkit voor Eclipse om Apache Spark-toepassingen te ontwikkelen die zijn geschreven in Scala en deze rechtstreeks vanuit de Eclipse IDE naar een Azure HDInsight Spark-cluster te verzenden. U kunt de invoegtoepassing HDInsight Tools op verschillende manieren gebruiken:
- Een Scala Spark-toepassing ontwikkelen en verzenden in een HDInsight Spark-cluster.
- Toegang tot uw Azure HDInsight Spark-clusterbronnen.
- Een Scala Spark-toepassing lokaal ontwikkelen en uitvoeren.
Vereiste voorwaarden
Apache Spark-cluster op HDInsight. Zie Apache Spark-clusters maken in Azure HDInsight voor instructies.
Eclipse IDE. In dit artikel wordt de Eclipse IDE voor Java-ontwikkelaars gebruikt.
Vereiste invoegtoepassingen installeren
De Azure Toolkit voor Eclipse installeren
Zie Azure Toolkit voor Eclipse installeren voor installatie-instructies.
De Scala-invoegtoepassing installeren
Wanneer u Eclipse opent, detecteert HDInsight Tools automatisch of u de Scala-invoegtoepassing hebt geïnstalleerd. Selecteer OK om door te gaan en volg de instructies voor het installeren van de invoegtoepassing vanuit Eclipse Marketplace. Start de IDE opnieuw nadat de installatie is voltooid.
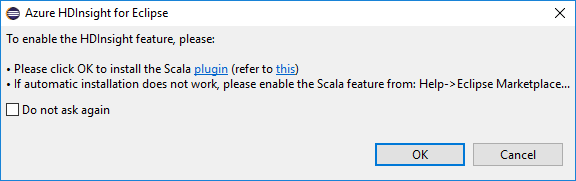
Invoegtoepassingen bevestigen
Navigeer naar Help>Eclipse Marketplace....
Selecteer het tabblad Geïnstalleerd .
U ziet ten minste het volgende:
- Azure Toolkit voor Eclipse-versie<>.
- Scala IDE-versie<>.
Aanmelden bij uw Azure-abonnement
Start Eclipse IDE.
Ga naar Venster>Weergave>weergeven overig...>Meld u aan...
Navigeer in het dialoogvenster Weergave weergeven naar Azure>Explorer en selecteer Openen.
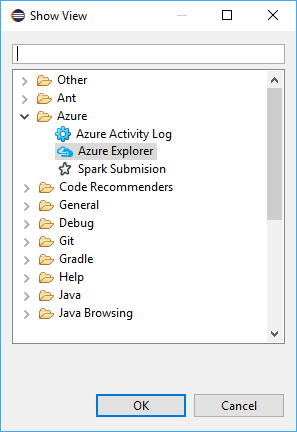
Klik in Azure Explorer met de rechtermuisknop op het Azure-knooppunt en selecteer Aanmelden.
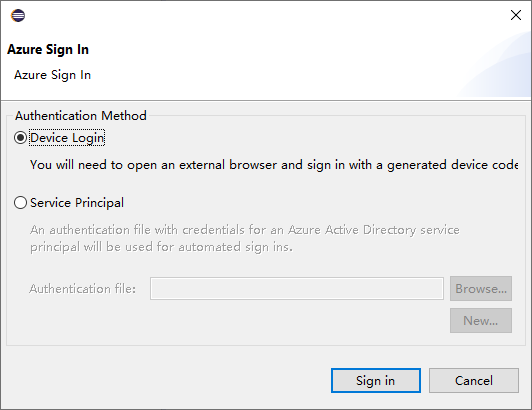
Kies in het dialoogvenster Aanmelden bij Azure de verificatiemethode, selecteer Aanmelden en voltooi het aanmeldingsproces.
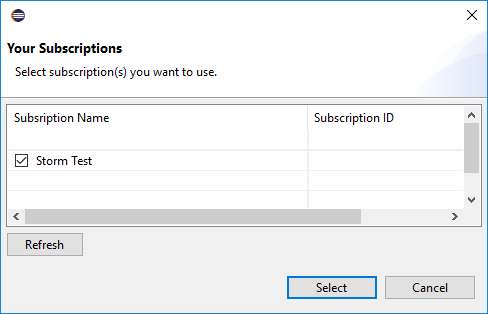
Nadat u bent aangemeld, worden in het dialoogvenster Uw abonnementen alle Azure-abonnementen weergegeven die zijn gekoppeld aan de referenties. Druk op Selecteren om het dialoogvenster te sluiten.
Navigeer vanuit Azure Explorer naar Azure>HDInsight om de HDInsight Spark-clusters onder uw abonnement te zien.
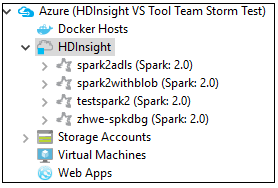
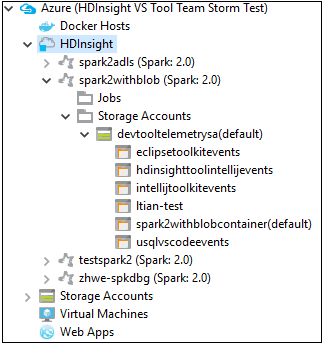
U kunt een clusternaamknooppunt verder uitbreiden om de resources (bijvoorbeeld opslagaccounts) te zien die zijn gekoppeld aan het cluster.
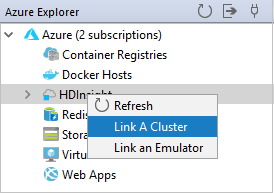
Een cluster koppelen
U kunt een normaal cluster koppelen met behulp van de door Ambari beheerde gebruikersnaam. Op dezelfde manier kunt u voor een HDInsight-cluster dat lid is van een domein een koppeling maken met behulp van het domein en de gebruikersnaam, zoals user1@contoso.com.
Klik in Azure Explorer met de rechtermuisknop op HDInsight en selecteer Een cluster koppelen.
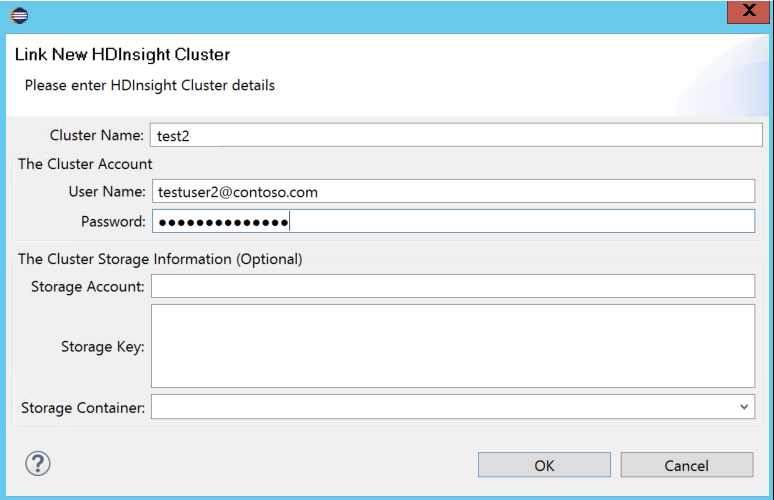
Voer clusternaam, gebruikersnaam en wachtwoord in en selecteer OK. Voer desgewenst het opslagaccount en de opslagsleutel in, en selecteer vervolgens de opslagcontainer, zodat de opslagverkenner in de linkerboomstructuur kan werken.
Opmerking
We gebruiken de gekoppelde opslagsleutel, gebruikersnaam en wachtwoord wanneer het cluster zowel is aangemeld bij het Azure-abonnement als wanneer een cluster is gekoppeld.
Wanneer de huidige focus zich op de opslagtoets bevindt, moet u Ctrl +TAB gebruiken om u te richten op het volgende veld in het dialoogvenster voor de gebruiker met het toetsenbord.
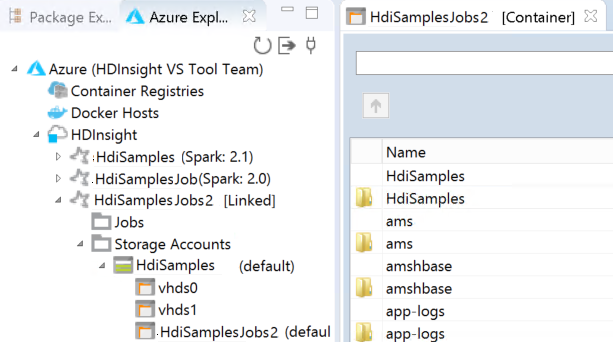
U kunt het gekoppelde cluster zien onder HDInsight. U kunt nu een toepassing verzenden naar dit gekoppelde cluster.
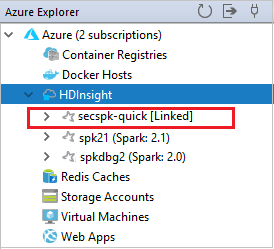
U kunt een cluster ook ontkoppelen vanuit Azure Explorer.
Een Spark Scala-project instellen voor een HDInsight Spark-cluster
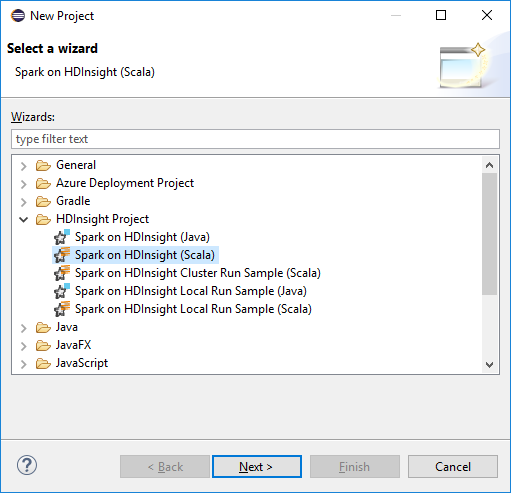
Selecteer Bestand>nieuw>project...in de Eclipse IDE-werkruimte.
In de wizard Nieuw Project selecteer HDInsight Project>Spark op HDInsight (Scala). Klik vervolgens op Volgende.
Geef in het dialoogvenster Nieuw HDInsight Scala-project de volgende waarden op en selecteer vervolgens Volgende:
- Voer een naam in voor het project.
- In het JRE gebied, zorg ervoor dat een uitvoeringsomgeving JRE is ingesteld op JavaSE-1.7 of hoger.
- In het gebied Spark-bibliotheek kunt u Maven gebruiken om de Spark SDK-optie te configureren . Ons hulpprogramma integreert de juiste versie voor Spark SDK en Scala SDK. U kunt ook de optie Spark SDK handmatig toevoegen kiezen, downloaden en Spark SDK handmatig toevoegen.
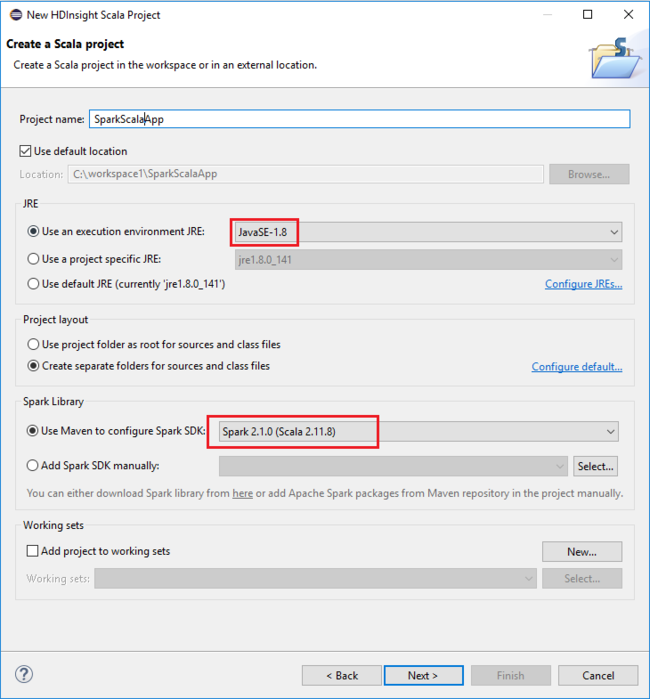
Controleer de details in het volgende dialoogvenster en selecteer Voltooien.
Een Scala-toepassing maken voor een HDInsight Spark-cluster
Vouw vanuit Package Explorer het project uit dat u eerder hebt gemaakt. Klik met de rechtermuisknop op src, selecteer Nieuw>overige....
In het dialoogvenster Een wizard selecteren, selecteer Scala Wizards>Scala Object. Klik vervolgens op Volgende.
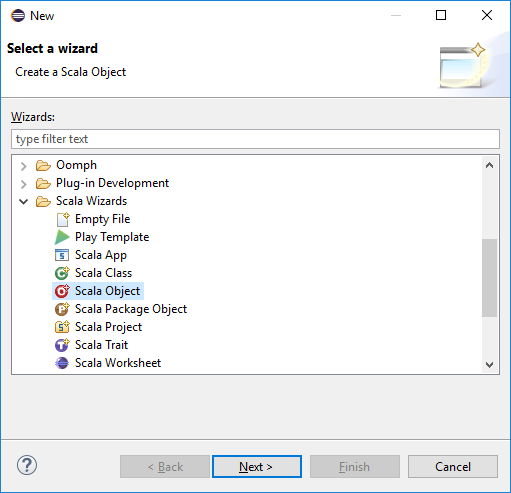
Voer in het dialoogvenster Nieuw bestand maken een naam in voor het object en selecteer Voltooien. Er wordt een teksteditor geopend.
Vervang in de teksteditor de huidige inhoud door de onderstaande code:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Voer de toepassing uit op een HDInsight Spark-cluster:
a. Klik in Package Explorer met de rechtermuisknop op de projectnaam en selecteer Spark-toepassing verzenden naar HDInsight.
b. Geef in het dialoogvenster Spark-verzending de volgende waarden op en selecteer Verzenden:
Selecteer bij Clusternaam het HDInsight Spark-cluster waarop u de toepassing wilt uitvoeren.
Selecteer een artefact in het Eclipse-project of selecteer een artefact op een harde schijf. De standaardwaarde is afhankelijk van het item waarop u met de rechtermuisknop klikt vanuit Package Explorer.
In de vervolgkeuzelijst Hoofdklassenaam worden in de indienwizard alle objectnamen uit uw project weergegeven. Selecteer of voer een in die u wilt uitvoeren. Als u een artefact van een harde schijf hebt geselecteerd, moet u de naam van de hoofdklasse handmatig invoeren.
Omdat voor de toepassingscode in dit voorbeeld geen opdrachtregelargumenten of verwijzingen naar JAR's of bestanden zijn vereist, kunt u de resterende tekstvakken leeg laten.
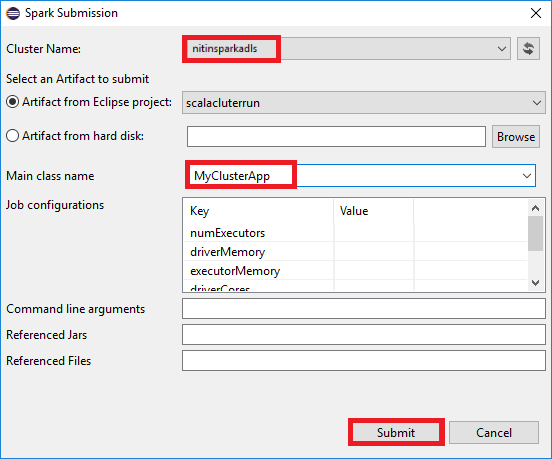
Het tabblad Spark-indiening moet beginnen met het weergeven van de voortgang. U kunt de toepassing stoppen door de rode knop te selecteren in het venster Spark-indiening . U kunt de logboeken voor deze specifieke toepassing ook bekijken door het wereldbolpictogram te selecteren (aangeduid met het blauwe vak in de afbeelding).
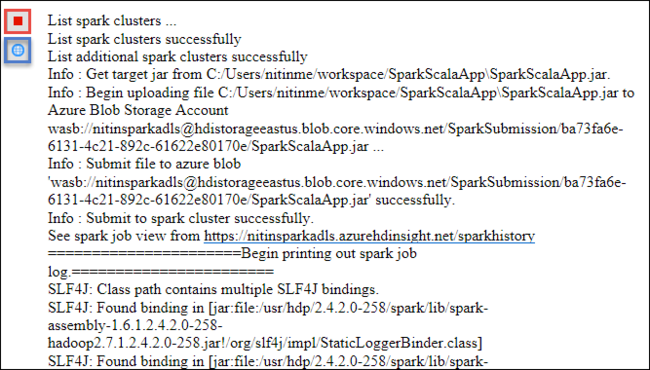
HDInsight Spark-clusters openen en beheren met behulp van HDInsight Tools in Azure Toolkit voor Eclipse
U kunt verschillende bewerkingen uitvoeren met behulp van HDInsight Tools, waaronder toegang tot de taakuitvoer.
Toegang tot de taakweergave
Vouw in Azure ExplorerHDInsight uit, en vervolgens de Spark-clusternaam, en selecteer daarna Taken.
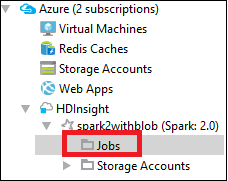
Selecteer de Jobs node. Als de Java-versie lager is dan 1.8, herinnert HDInsight Tools u er automatisch aan dat u de invoegtoepassing E(fx)clipse installeert. Selecteer OK om door te gaan en volg de wizard om deze te installeren vanuit Eclipse Marketplace en start Eclipse opnieuw.
Open de taakweergave vanuit het knooppunt Taken . In het rechterdeelvenster worden op het tabblad Spark-taakweergave alle toepassingen weergegeven die op het cluster zijn uitgevoerd. Selecteer de naam van de toepassing waarvoor u meer details wilt zien.
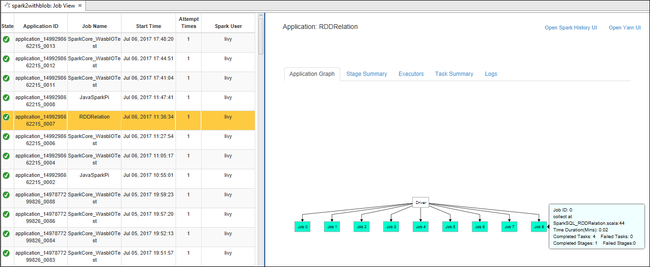
U kunt vervolgens een van deze acties uitvoeren:
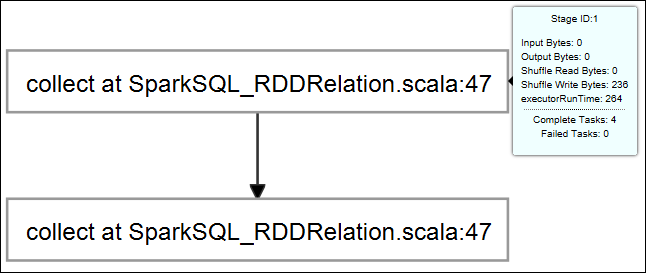
Beweeg de muisaanwijzer over de taakgrafiek. Er wordt basisinformatie over de actieve taak weergegeven. Selecteer de taakgrafiek en u kunt de fasen en informatie zien die door elke taak worden gegenereerd.
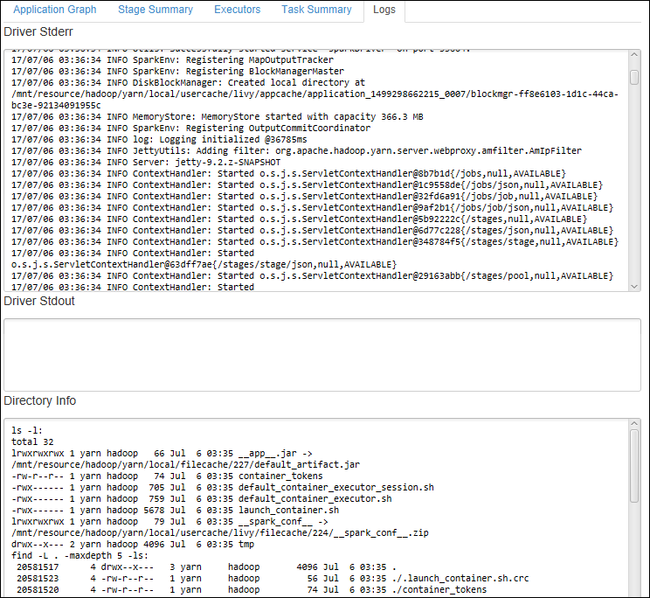
Selecteer het tabblad Logboek om veelgebruikte logboeken weer te geven, waaronder Driver Stderr, Driver Stdout en Directory Info.
Open de gebruikersinterface voor Spark-geschiedenis en de Apache Hadoop YARN-gebruikersinterface (op toepassingsniveau) door de hyperlinks boven aan het venster te selecteren.
Toegang tot de opslagcontainer voor het cluster
Vouw in Azure Explorer het HDInsight-hoofdknooppunt uit om een lijst weer te geven met HDInsight Spark-clusters die beschikbaar zijn.
Vouw de clusternaam uit om het opslagaccount en de standaardopslagcontainer voor het cluster te zien.
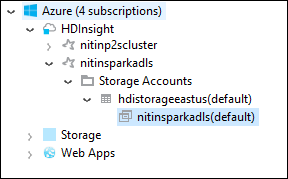
Selecteer de naam van de opslagcontainer die is gekoppeld aan het cluster. Dubbelklik in het rechterdeelvenster op de map HVACOut . Open een van de onderdeelbestanden om de uitvoer van de toepassing te bekijken.
Toegang tot de Spark-geschiedenisserver
Klik in Azure Explorer met de rechtermuisknop op de naam van uw Spark-cluster en selecteer vervolgens de gebruikersinterface voor Spark-geschiedenis openen. Wanneer u hierom wordt gevraagd, voert u de beheerdersreferenties voor het cluster in. U hebt deze opgegeven tijdens het inrichten van het cluster.
In het dashboard van de Spark-geschiedenisserver gebruikt u de naam van de toepassing om te zoeken naar de toepassing die u zojuist hebt uitgevoerd. In de voorgaande code stelt u de naam van de toepassing in met behulp van
val conf = new SparkConf().setAppName("MyClusterApp"). De naam van uw Spark-toepassing was dus MyClusterApp.
De Apache Ambari-portal starten
Klik in Azure Explorer met de rechtermuisknop op de naam van uw Spark-cluster en selecteer Vervolgens Open Cluster Management Portal (Ambari).
Wanneer u hierom wordt gevraagd, voert u de beheerdersreferenties voor het cluster in. U hebt deze opgegeven tijdens het inrichten van het cluster.
Azure-abonnementen beheren
Standaard geeft HDInsight Tool in Azure Toolkit voor Eclipse de Spark-clusters van al uw Azure-abonnementen weer. Indien nodig kunt u de abonnementen opgeven waarvoor u toegang wilt krijgen tot het cluster.
Klik in Azure Explorer met de rechtermuisknop op het Azure-hoofdknooppunt en selecteer Abonnementen beheren.
Schakel in het dialoogvenster de selectievakjes uit voor het abonnement dat u niet wilt openen en selecteer vervolgens Sluiten. U kunt afmelden ook selecteren als u zich wilt afmelden bij uw Azure-abonnement.
Een Spark Scala-toepassing lokaal uitvoeren
U kunt HDInsight Tools in Azure Toolkit for Eclipse gebruiken om Spark Scala-toepassingen lokaal op uw werkstation uit te voeren. Deze toepassingen hebben doorgaans geen toegang nodig tot clusterbronnen, zoals een opslagcontainer, en u kunt ze lokaal uitvoeren en testen.
Voorwaarde
Terwijl u de lokale Spark Scala-toepassing uitvoert op een Windows-computer, krijgt u mogelijk een uitzondering zoals uitgelegd in SPARK-2356. Deze uitzondering treedt op omdat WinUtils.exe ontbreekt in Windows.
Als u deze fout wilt oplossen, moet u Winutils.exe naar een locatie zoals C:\WinUtils\bin, en vervolgens de omgevingsvariabele toevoegen HADOOP_HOME en de waarde van de variabele instellen op C\WinUtils.
Een lokale Spark Scala-toepassing uitvoeren
Start Eclipse en maak een project. Maak in het dialoogvenster Nieuw project de volgende keuzes en selecteer vervolgens Volgende.
Selecteer in de wizard Nieuw projectHDInsight Project>Spark op HDInsight Local Run Sample (Scala). Klik vervolgens op Volgende.
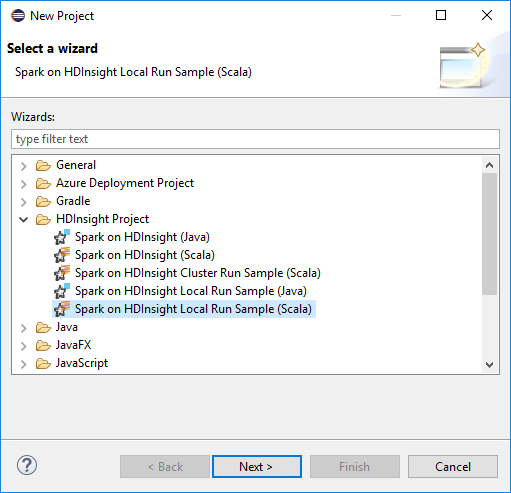
Volg stap 3 tot en met 6 uit de eerdere sectie Een Spark Scala-project instellen voor een HDInsight Spark-cluster om de projectdetails op te geven.
Met de sjabloon wordt een voorbeeldcode (LogQuery) toegevoegd in de map src, die lokaal op uw computer kan worden uitgevoerd.
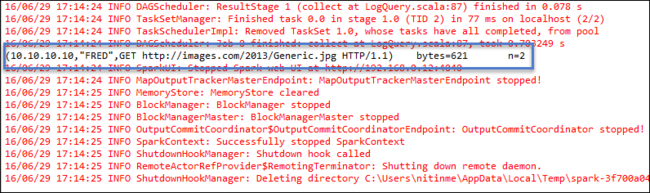
Klik met de rechtermuisknop op LogQuery.scala en selecteer Uitvoeren als>1 Scala-toepassing. Uitvoer zoals deze wordt weergegeven op het tabblad Console :
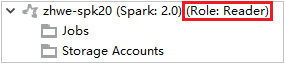
Alleen lezer-rol
Wanneer gebruikers een taak verzenden naar een cluster met alleen-lezen rechten, zijn Ambari-aanmeldgegevens vereist.
Cluster koppelen vanuit contextmenu
Meld u aan met een account voor alleen-lezen.
Vouw vanuit Azure ExplorerHDInsight uit om HDInsight-clusters weer te geven die zich in uw abonnement bevinden. De clusters die als Rol:Lezer zijn gemarkeerd, hebben alleen de rolmachtigingen van de lezer.
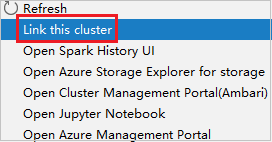
Klik met de rechtermuisknop op het cluster met de machtiging alleen-lezenrol. Selecteer Dit cluster koppelen in het contextmenu om het cluster te koppelen. Voer de Ambari-gebruikersnaam en het wachtwoord in.
Als het cluster succesvol is gekoppeld, wordt HDInsight vernieuwd. De fase van het cluster wordt gekoppeld.
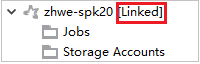
Cluster koppelen door de node 'Jobs' uit te vouwen
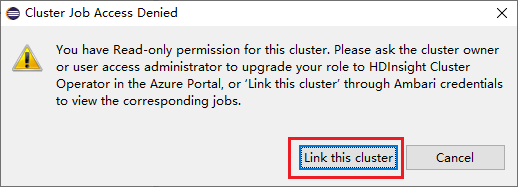
Klik op de knop Jobs, er verschijnt een venster Clustertaaktoegang geweigerd.
Klik op Dit cluster koppelen om het cluster te koppelen.
Cluster koppelen vanuit het venster voor Spark-indiening
Maak een HDInsight-project.
Klik met de rechtermuisknop op het pakket. Selecteer vervolgens Spark-toepassing verzenden naar HDInsight.
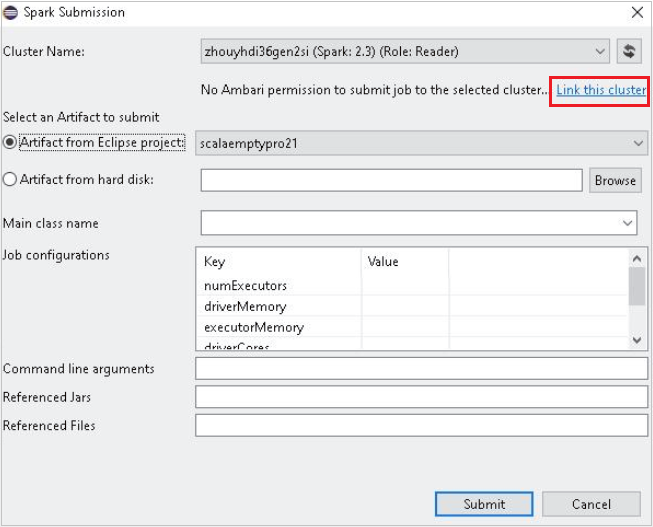
Selecteer een cluster dat alleen-lezen machtigingen heeft voor Cluster Naam. Waarschuwingsbericht wordt weergegeven. U kunt op Dit cluster koppelen klikken om het cluster te koppelen.
Opslagaccounts weergeven
Klik voor clusters met de alleen-lezer machtiging op de Opslagaccounts node en het venster Opslagtoegang geweigerd verschijnt.
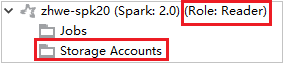
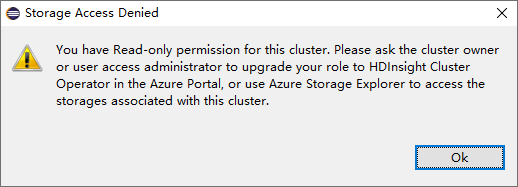
Klik voor gekoppelde clusters op het knooppunt Opslagaccounts , het venster Toegang geweigerd voor opslag wordt weergegeven.
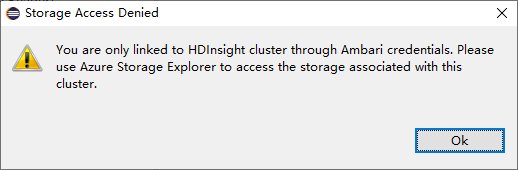
Bekende problemen
Wanneer u Een cluster koppelen gebruikt, zou ik u voorstellen om de opslagreferentie op te geven.
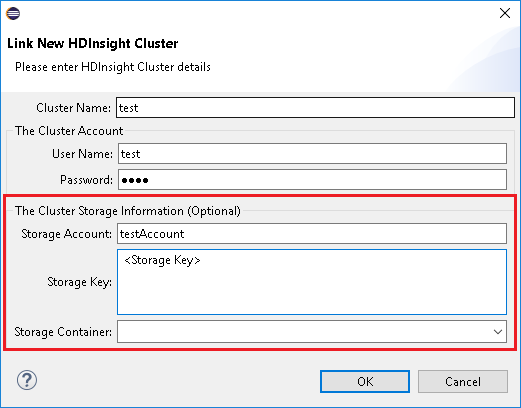
Er zijn twee manieren om de taken in te dienen. Als er opslagreferenties worden opgegeven, wordt de batchmodus gebruikt om de taak te verzenden. Anders wordt de interactieve modus gebruikt. Als het cluster bezet is, krijgt u mogelijk de foutmelding hieronder.


Zie ook
Scenariën
- Apache Spark met BI: Interactieve gegevensanalyse uitvoeren met Spark in HDInsight met BI-hulpprogramma's
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken voor het analyseren van de gebouwtemperatuur met behulp van HVAC-gegevens
- Apache Spark met Machine Learning: Spark in HDInsight gebruiken om resultaten van voedselinspectie te voorspellen
- Analyse van websitelogboeken met Apache Spark in HDInsight
Toepassingen maken en uitvoeren
- Een zelfstandige toepassing maken met behulp van Scala
- Apache Livy gebruiken om taken op afstand uit te voeren in een Apache Spark-cluster
Hulpmiddelen en extensies
- Azure Toolkit voor IntelliJ gebruiken om Spark Scala-toepassingen te maken en te verzenden
- Azure Toolkit voor IntelliJ gebruiken om op afstand fouten in Apache Spark-toepassingen op te sporen via VPN
- Azure Toolkit voor IntelliJ gebruiken om op afstand fouten in Apache Spark-toepassingen op te sporen via SSH
- Apache Zeppelin-notebooks gebruiken met een Apache Spark-cluster in HDInsight
- Kernels beschikbaar voor Jupyter Notebook in Apache Spark-cluster voor HDInsight
- Externe pakketten gebruiken met Jupyter Notebooks
- Jupyter op uw computer installeren en verbinding maken met een HDInsight Spark-cluster