Een model implementeren in een Azure Kubernetes Service-cluster met v1
Belangrijk
In dit artikel wordt uitgelegd hoe u de Azure Machine Learning CLI (v1) en Azure Machine Learning SDK voor Python (v1) gebruikt om een model te implementeren. Zie Een machine learning-model implementeren en beoordelen met behulp van een online-eindpunt voor de aanbevolen aanpak voor v2.
Meer informatie over het gebruik van Azure Machine Learning voor het implementeren van een model als een webservice in Azure Kubernetes Service (AKS). AKS is geschikt voor grootschalige productie-implementaties. Gebruik AKS als u een of meer van de volgende mogelijkheden nodig hebt:
- Snelle reactietijd
- Automatisch schalen van de geïmplementeerde service
- Logboekregistratie
- Gegevensverzameling modelleren
- Verificatie
- TLS-beëindiging
- Hardwareversnellingsopties zoals GPU en veld programmeerbare poortmatrices (FPGA)
Wanneer u implementeert in AKS, implementeert u in een AKS-cluster dat is verbonden met uw werkruimte. Zie Een Azure Kubernetes Service-cluster maken en koppelen voor meer informatie over het verbinden van een AKS-cluster met uw werkruimte.
Belangrijk
U wordt aangeraden lokaal fouten op te sporen voordat u implementeert in de webservice. Zie Problemen oplossen met een implementatie van een lokaal model voor meer informatie.
U kunt ook verwijzen naar Implementeren naar een lokaal notebook op GitHub.
Notitie
Azure Machine Learning-eindpunten (v2) bieden een verbeterde, eenvoudigere implementatie-ervaring. Eindpunten ondersteunen zowel realtime- als batchdeductiescenario's. Eindpunten bieden een uniforme interface voor het aanroepen en beheren van modelimplementaties in verschillende rekentypen. Zie Wat zijn Azure Machine Learning-eindpunten?
Vereisten
Een Azure Machine Learning-werkruimte. Zie Een Azure Machine Learning-werkruimte maken voor meer informatie.
Een machine learning-model dat is geregistreerd in uw werkruimte. Als u geen geregistreerd model hebt, raadpleegt u Machine Learning-modellen implementeren in Azure.
De Azure CLI-extensie (v1) voor Machine Learning Service, Azure Machine Learning Python SDK of de Azure Machine Learning Visual Studio Code-extensie.
Belangrijk
Sommige Azure CLI-opdrachten in dit artikel gebruiken de
azure-cli-mlextensie (of v1) voor Azure Machine Learning. Ondersteuning voor de v1-extensie eindigt op 30 september 2025. U kunt de v1-extensie tot die datum installeren en gebruiken.U wordt aangeraden vóór 30 september 2025 over te stappen op de
mlextensie of v2. Zie de Azure ML CLI-extensie en Python SDK v2 voor meer informatie over de v2-extensie.In de Python-codefragmenten in dit artikel wordt ervan uitgegaan dat de volgende variabelen zijn ingesteld:
ws- Stel deze in op uw werkruimte.model- Ingesteld op uw geregistreerde model.inference_config- Instellen op de deductieconfiguratie voor het model.
Zie Hoe en waar u modellen kunt implementeren voor meer informatie over het instellen van deze variabelen.
In de CLI-fragmenten in dit artikel wordt ervan uitgegaan dat u al een inferenceconfig.json document hebt gemaakt. Zie Machine Learning-modellen implementeren in Azure voor meer informatie over het maken van dit document.
Een AKS-cluster dat is verbonden met uw werkruimte. Zie Een Azure Kubernetes Service-cluster maken en koppelen voor meer informatie.
- Als u modellen wilt implementeren op GPU-knooppunten of FPGA-knooppunten (of een specifiek product), moet u een cluster maken met het specifieke product. Er is geen ondersteuning voor het maken van een secundaire knooppuntgroep in een bestaand cluster en het implementeren van modellen in de secundaire knooppuntgroep.
Implementatieprocessen begrijpen
De woordimplementatie wordt gebruikt in Kubernetes en Azure Machine Learning. Implementatie heeft verschillende betekenissen in deze twee contexten. In Kubernetes is een implementatie een concrete entiteit die is opgegeven met een declaratief YAML-bestand. Een Kubernetes-implementatie heeft een gedefinieerde levenscyclus en concrete relaties met andere Kubernetes-entiteiten zoals Pods en ReplicaSets. Meer informatie over Kubernetes vindt u in docs en video's op Wat is Kubernetes?
In Azure Machine Learning wordt de implementatie gebruikt in de meer algemene zin om uw projectresources beschikbaar te maken en op te schonen. De stappen die Azure Machine Learning als onderdeel van de implementatie beschouwt, zijn:
- De bestanden in uw projectmap zippen, waarbij de bestanden die zijn opgegeven in .amlignore of .gitignore worden genegeerd
- Uw rekencluster omhoog schalen (is gerelateerd aan Kubernetes)
- Het dockerfile bouwen of downloaden naar het rekenknooppunt (is gerelateerd aan Kubernetes)
- Het systeem berekent een hash van:
- De basisinstallatiekopieën
- Aangepaste docker-stappen (zie Een model implementeren met behulp van een aangepaste Docker-basisinstallatiekopieën)
- De YAML van de Conda-definitie (zie Softwareomgevingen maken en gebruiken in Azure Machine Learning)
- Het systeem gebruikt deze hash als sleutel in een zoekactie van de werkruimte Azure Container Registry (ACR)
- Als deze niet wordt gevonden, zoekt deze naar een overeenkomst in de globale ACR
- Als deze niet wordt gevonden, bouwt het systeem een nieuwe installatiekopieën die in de cache worden opgeslagen en naar de werkruimte ACR worden gepusht
- Het systeem berekent een hash van:
- Het zip-projectbestand downloaden naar tijdelijke opslag op het rekenknooppunt
- Het projectbestand opheffen
- Het rekenknooppunt dat wordt uitgevoerd
python <entry script> <arguments> - Logboeken, modelbestanden en andere bestanden opslaan die zijn geschreven naar ./outputs naar het opslagaccount dat is gekoppeld aan de werkruimte
- Rekenkracht omlaag schalen, inclusief het verwijderen van tijdelijke opslag (is gerelateerd aan Kubernetes)
Azure Machine Learning-router
Het front-endonderdeel (azureml-fe) waarmee binnenkomende deductieaanvragen naar geïmplementeerde services worden gerouteerd, wordt indien nodig automatisch geschaald. Schalen van azureml-fe is gebaseerd op het doel en de grootte van het AKS-cluster (aantal knooppunten). Het clusterdoel en de knooppunten worden geconfigureerd wanneer u een AKS-cluster maakt of koppelt. Er is één azureml-fe-service per cluster, die mogelijk op meerdere pods wordt uitgevoerd.
Belangrijk
Wanneer u een cluster gebruikt dat is geconfigureerd als dev-test, wordt de self-scaler uitgeschakeld. Zelfs voor FastProd-/DenseProd-clusters is self-scaler alleen ingeschakeld wanneer telemetrie laat zien dat deze nodig is.
Notitie
De maximale nettolading van de aanvraag is 100 MB.
Azureml-fe schaalt zowel omhoog (verticaal) om meer kernen te gebruiken, en uit (horizontaal) om meer pods te gebruiken. Wanneer u de beslissing neemt om omhoog te schalen, wordt de tijd die nodig is om binnenkomende deductieaanvragen te routeren gebruikt. Als deze tijd de drempelwaarde overschrijdt, treedt er een opschaalbewerking op. Als de tijd voor het routeren van binnenkomende aanvragen de drempelwaarde blijft overschrijden, treedt er een uitschaalbewerking op.
Wanneer u omlaag en omlaag schaalt, wordt het CPU-gebruik gebruikt. Als aan de drempelwaarde voor CPU-gebruik wordt voldaan, wordt de front-end eerst omlaag geschaald. Als het CPU-gebruik afneemt tot de drempelwaarde voor inschalen, gebeurt er een inschaalbewerking. Omhoog en uitschalen vindt alleen plaats als er voldoende clusterbronnen beschikbaar zijn.
Wanneer u omhoog of omlaag schaalt, worden azureml-fe-pods opnieuw opgestart om de cpu-/geheugenwijzigingen toe te passen. Opnieuw opstarten heeft geen invloed op de deductieaanvragen.
Informatie over de connectiviteitsvereisten voor het AKS-deductiecluster
Wanneer Azure Machine Learning een AKS-cluster maakt of koppelt, wordt het AKS-cluster geïmplementeerd met een van de volgende twee netwerkmodellen:
- Kubenet-netwerken: de netwerkresources worden doorgaans gemaakt en geconfigureerd als het AKS-cluster wordt geïmplementeerd.
- Azure Container Networking Interface (CNI)-netwerken: het AKS-cluster is verbonden met een bestaande virtuele netwerkresource en configuraties.
Voor Kubenet-netwerken wordt het netwerk gemaakt en juist geconfigureerd voor Azure Machine Learning Service. Voor het CNI-netwerk moet u de connectiviteitsvereisten begrijpen en ervoor zorgen dat DNS-omzetting en uitgaande connectiviteit voor AKS-deductie. U gebruikt bijvoorbeeld een firewall om netwerkverkeer te blokkeren.
In het volgende diagram ziet u de connectiviteitsvereisten voor AKS-deductie. Zwarte pijlen vertegenwoordigen de werkelijke communicatie en blauwe pijlen vertegenwoordigen de domeinnamen. Mogelijk moet u vermeldingen voor deze hosts toevoegen aan uw firewall of aan uw aangepaste DNS-server.
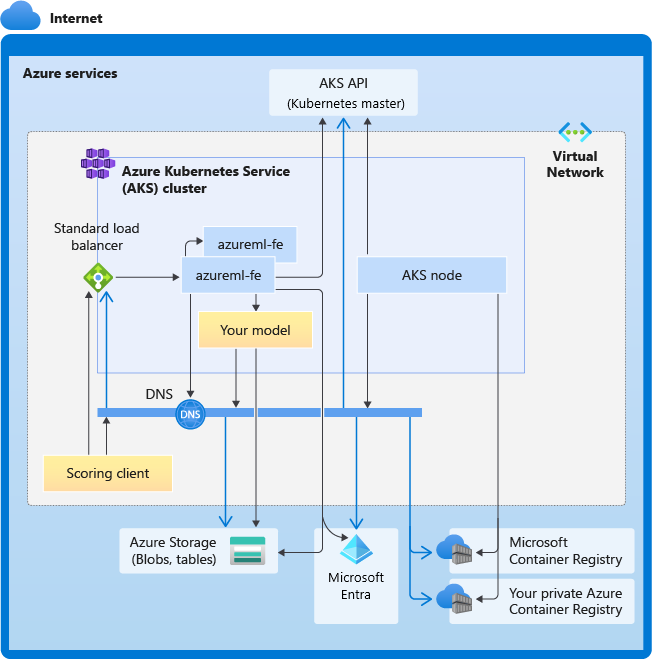
Zie Netwerkverkeer beperken met Azure Firewall in AKS voor algemene AKS-connectiviteitsvereisten.
Zie Inkomend en uitgaand netwerkverkeer configureren voor toegang tot Azure Machine Learning-services achter een firewall.
Algemene VEREISTEN voor DNS-omzetting
DNS-omzetting binnen een bestaand virtueel netwerk staat onder uw beheer. Bijvoorbeeld een firewall of aangepaste DNS-server. De volgende hosts moeten bereikbaar zijn:
| Hostnaam | Wordt gebruikt door |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS API-server |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Your Azure Container Registry (ACR) |
<account>.table.core.windows.net |
Azure Storage-account (tabelopslag) |
<account>.blob.core.windows.net |
Azure Storage-account (blobopslag) |
api.azureml.ms |
Microsoft Entra-verificatie |
ingest-vienna<region>.kusto.windows.net |
Kusto-eindpunt voor het uploaden van telemetrie |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
De domeinnaam van het eindpunt, als u automatisch hebt gegenereerd met Azure Machine Learning. Als u een aangepaste domeinnaam hebt gebruikt, hebt u deze vermelding niet nodig. |
Verbinding maken iviteitsvereisten in chronologische volgorde
Tijdens het maken of koppelen van AKS wordt de Azure Machine Learning-router (azureml-fe) geïmplementeerd in het AKS-cluster. Als u een Azure Machine Learning-router wilt implementeren, moet het AKS-knooppunt het volgende kunnen doen:
- DNS voor AKS-API-server oplossen
- DNS voor MCR oplossen om Docker-installatiekopieën voor Azure Machine Learning-router te downloaden
- Installatiekopieën downloaden van MCR, waarbij uitgaande connectiviteit is vereist
Direct nadat azureml-fe is geïmplementeerd, wordt geprobeerd te starten. Hiervoor moet u het volgende doen:
- DNS voor AKS-API-server oplossen
- Een query uitvoeren op de AKS-API-server om andere exemplaren van zichzelf te detecteren (dit is een service met meerdere pods)
- Verbinding maken naar andere exemplaren van zichzelf
Zodra azureml-fe is gestart, is de volgende verbinding vereist om goed te functioneren:
- Verbinding maken naar Azure Storage om dynamische configuratie te downloaden
- Dns voor Microsoft Entra-verificatieserver api.azureml.ms oplossen en ermee communiceren wanneer de geïmplementeerde service gebruikmaakt van Microsoft Entra-verificatie.
- Een query uitvoeren op de AKS-API-server om geïmplementeerde modellen te detecteren
- Communiceren met geïmplementeerde model-POD's
Op het moment van modelimplementatie moet het AKS-knooppunt voor een geslaagde modelimplementatie het volgende kunnen doen:
- DNS voor de ACR van de klant oplossen
- Afbeeldingen downloaden van de ACR van de klant
- DNS voor Azure-BLObs oplossen waar het model is opgeslagen
- Modellen downloaden van Azure-BLOBs
Nadat het model is geïmplementeerd en de service is gestart, detecteert azureml-fe het automatisch met behulp van de AKS-API en is deze gereed om de aanvraag naar het model te routeren. Het moet kunnen communiceren met model-POD's.
Notitie
Als voor het geïmplementeerde model connectiviteit is vereist (bijvoorbeeld het opvragen van een externe database of een andere REST-service of het downloaden van een BLOB), moeten zowel DNS-omzetting als uitgaande communicatie voor deze services zijn ingeschakeld.
Implementeren naar AKS
Als u een model wilt implementeren in AKS, maakt u een implementatieconfiguratie waarin de benodigde rekenresources worden beschreven. Bijvoorbeeld het aantal kernen en geheugen. U hebt ook een deductieconfiguratie nodig, waarin de omgeving wordt beschreven die nodig is om het model en de webservice te hosten. Zie Hoe en waar u modellen kunt implementeren voor meer informatie over het maken van de deductieconfiguratie.
Notitie
Het aantal modellen dat moet worden geïmplementeerd, is beperkt tot duizend modellen per implementatie (per container).
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Zie de volgende referentiedocumenten voor meer informatie over de klassen, methoden en parameters die in dit voorbeeld worden gebruikt:
Automatisch schalen
VAN TOEPASSING OP: Python SDK azureml v1
Het onderdeel dat automatische schaalaanpassing voor Azure Machine Learning-modelimplementaties afhandelt, is azureml-fe, een slimme aanvraagrouter. Omdat alle deductieaanvragen deze doorlopen, beschikt het over de benodigde gegevens om de geïmplementeerde modellen automatisch te schalen.
Belangrijk
Schakel Kubernetes Horizontal Pod Autoscaler (HPA) niet in voor modelimplementaties. Hierdoor concurreren de twee onderdelen voor automatisch schalen met elkaar. Azureml-fe is ontworpen voor het automatisch schalen van modellen die zijn geïmplementeerd door Azure Machine Learning, waarbij HPA het gebruik van modellen zou moeten raden of benaderen op basis van een algemeen metrische waarde, zoals CPU-gebruik of een aangepaste metrische configuratie.
Azureml-fe schaalt het aantal knooppunten in een AKS-cluster niet, omdat dit kan leiden tot onverwachte kostenstijgingen. In plaats daarvan wordt het aantal replica's voor het model binnen de grenzen van het fysieke cluster geschaald. Als u het aantal knooppunten in het cluster wilt schalen, kunt u het cluster handmatig schalen of de automatische schaalaanpassing van AKS-clusters configureren.
Automatische schaalaanpassing kan worden beheerd door instelling autoscale_target_utilization, autoscale_min_replicasen autoscale_max_replicas voor de AKS-webservice. In het volgende voorbeeld ziet u hoe u automatische schaalaanpassing inschakelt:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
Beslissingen om omhoog of omlaag te schalen, zijn gebaseerd op het gebruik van de huidige containerreplica's. Het aantal replica's dat bezet is (een aanvraag verwerken) gedeeld door het totale aantal huidige replica's is het huidige gebruik. Als dit aantal groter is autoscale_target_utilization, worden er meer replica's gemaakt. Als deze lager is, worden replica's verminderd. Standaard is het doelgebruik 70%.
Beslissingen om replica's toe te voegen zijn gretig en snel (ongeveer 1 seconde). Beslissingen om replica's te verwijderen zijn conservatief (ongeveer 1 minuut).
U kunt de vereiste replica's berekenen met behulp van de volgende code:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Zie de naslaginformatie over de AksWebservice-module voor meer informatie over het instellen autoscale_target_utilization, autoscale_max_replicasen autoscale_min_replicasraadpleegt u de naslaginformatie over de AksWebservice-module .
Web-serviceverificatie
Bij de implementatie in Azure Kubernetes Service is verificatie op basis van sleutels standaard ingeschakeld. U kunt ook verificatie op basis van tokens inschakelen. Verificatie op basis van tokens vereist dat clients een Microsoft Entra-account gebruiken om een verificatietoken aan te vragen, dat wordt gebruikt om aanvragen te doen voor de geïmplementeerde service.
Als u verificatie wilt uitschakelen , stelt u de parameter in bij het auth_enabled=False maken van de implementatieconfiguratie. In het volgende voorbeeld wordt verificatie uitgeschakeld met behulp van de SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
Zie het Azure Machine Learning-model gebruiken dat is geïmplementeerd als een webservice voor informatie over het verifiëren van een clienttoepassing.
Verificatie met sleutels
Als sleutelverificatie is ingeschakeld, kunt u de get_keys methode gebruiken om een primaire en secundaire verificatiesleutel op te halen:
primary, secondary = service.get_keys()
print(primary)
Belangrijk
Als u een sleutel opnieuw wilt genereren, gebruikt u service.regen_key.
Verificatie met tokens
Als u tokenverificatie wilt inschakelen, stelt u de token_auth_enabled=True parameter in wanneer u een implementatie maakt of bijwerkt. In het volgende voorbeeld wordt tokenverificatie met behulp van de SDK ingeschakeld:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
Als tokenverificatie is ingeschakeld, kunt u de get_token methode gebruiken om een JWT-token op te halen en de verlooptijd van dat token:
token, refresh_by = service.get_token()
print(token)
Belangrijk
U moet een nieuw token aanvragen na de tijd van refresh_by het token.
Microsoft raadt u ten zeerste aan uw Azure Machine Learning-werkruimte te maken in dezelfde regio als uw AKS-cluster. Als u wilt verifiëren met een token, roept de webservice de regio aan waarin uw Azure Machine Learning-werkruimte wordt gemaakt. Als de regio van uw werkruimte niet beschikbaar is, kunt u geen token ophalen voor uw webservice, zelfs niet als uw cluster zich in een andere regio bevindt dan uw werkruimte. Dit zorgt ervoor dat verificatie op basis van tokens niet beschikbaar is totdat de regio van uw werkruimte weer beschikbaar is. Bovendien, hoe groter de afstand tussen de regio van uw cluster en de regio van uw werkruimte, hoe langer het duurt om een token op te halen.
Als u een token wilt ophalen, moet u de Azure Machine Learning SDK of de opdracht az ml service get-access-token gebruiken.
Scannen op beveiligingsproblemen
Microsoft Defender voor Cloud biedt geïntegreerd beveiligingsbeheer en geavanceerde beveiliging tegen bedreigingen voor hybride cloudworkloads. U moet Microsoft Defender voor Cloud toestaan om uw resources te scannen en de aanbevelingen te volgen. Zie Containerbeveiliging in Microsoft Defender voor containers voor meer informatie.
Gerelateerde inhoud
- Op rollen gebaseerd toegangsbeheer van Azure gebruiken voor Kubernetes-autorisatie
- Een Azure Machine Learning-deductieomgeving beveiligen met virtuele netwerken
- Een aangepaste container gebruiken om een model te implementeren op een online-eindpunt
- Problemen met externe modelimplementatie oplossen
- Een geïmplementeerde webservice bijwerken
- TLS gebruiken om een webservice te beveiligen via Azure Machine Learning
- Een Azure Machine Learning-model gebruiken dat als een webservice is geïmplementeerd
- Gegevens van ML-webservice-eindpunten bewaken en verzamelen
- Gegevens verzamelen van modellen in productie