Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel leert u hoe u een Indexeerfunctie voor OneLake-bestanden configureert voor het extraheren van doorzoekbare gegevens en metagegevensgegevens uit een lakehouse boven op OneLake.
Als u de indexeerfunctie wilt configureren en uitvoeren, kunt u het volgende gebruiken:
- 2024-05-01-preview REST API of een nieuwere PREVIEW REST API.
- Een bètapakket van Azure SDK dat de functie biedt.
- Wizard Gegevens importeren in Azure Portal.
- Wizard Importeren en Vectoriseren van gegevens in de Azure portal.
In dit artikel worden de REST API's gebruikt om elke stap te illustreren.
Vereisten
Een Infrastructuurwerkruimte. Volg deze zelfstudie om een Fabric-werkruimte te maken.
Een lakehouse in een Fabric-werkruimte. Volg deze zelfstudie om een lakehouse te maken.
Tekstgegevens. Als u binaire gegevens hebt, kunt u analyse van AI-verrijkingsafbeeldingen gebruiken om tekst te extraheren of beschrijvingen van afbeeldingen te genereren. Bestandsinhoud kan de indexeerlimieten voor uw zoekservicelaag niet overschrijden.
Inhoud in de locatie Bestanden van uw lakehouse. U kunt gegevens toevoegen door:
- Rechtstreeks uploaden naar een lakehouse
- Gegevenspijplijnen van Microsoft Fabric gebruiken
- Voeg snelkoppelingen toe vanuit externe gegevensbronnen, zoals Amazon S3 of Google Cloud Storage.
Een AI-Search-service geconfigureerd voor een door het systeem beheerde identiteit of door de gebruiker toegewezen beheerde identiteit. De AI-Search-service moet zich in dezelfde tenant bevinden als de Microsoft Fabric-werkruimte.
Een roltoewijzing inzender in de Werkruimte van Microsoft Fabric waar het lakehouse zich bevindt. Stappen worden beschreven in de sectie Machtigingen verlenen van dit artikel.
Een REST-client voor het formuleren van REST-aanroepen die vergelijkbaar zijn met de aanroepen die in dit artikel worden weergegeven.
Ondersteunde taken
U kunt deze indexeerfunctie gebruiken voor de volgende taken:
- Gegevensindexering en incrementele indexering: de indexeerfunctie kan bestanden en bijbehorende metagegevens van gegevenspaden in een lakehouse indexeren. Er worden nieuwe en bijgewerkte bestanden en metagegevens gedetecteerd via ingebouwde wijzigingsdetectie. U kunt gegevensvernieuwing configureren volgens een planning of op aanvraag.
- Verwijderingsdetectie: de indexeerfunctie kan verwijderingen detecteren via aangepaste metagegevens voor de meeste bestanden en snelkoppelingen. Hiervoor moeten metagegevens aan bestanden worden toegevoegd om aan te geven dat ze 'voorlopig verwijderd' zijn, zodat ze kunnen worden verwijderd uit de zoekindex. Op dit moment is het niet mogelijk om verwijderingen te detecteren in Snelkoppelingsbestanden van Google Cloud Storage of Amazon S3, omdat aangepaste metagegevens niet worden ondersteund voor deze gegevensbronnen.
- Toegepaste AI via vaardighedensets:Vaardighedensets worden volledig ondersteund door de Indexeerfunctie voor OneLake-bestanden. Dit omvat belangrijke functies zoals geïntegreerde vectorisatie waarmee stappen voor het segmenteren en insluiten van gegevens worden toegevoegd.
- Parseringsmodi: de indexeerfunctie ondersteunt JSON-parseringsmodi als u JSON-matrices of regels wilt parseren in afzonderlijke zoekdocumenten. Het biedt ook ondersteuning voor de parseermodus van Markdown.
- Compatibiliteit met andere functies: De OneLake-indexeerfunctie is ontworpen om naadloos te werken met andere indexeerfuncties, zoals foutopsporingssessies, indexeerfunctiecache voor incrementele verrijkingen en kennisarchief.
Ondersteunde documentindelingen
De indexeerfunctie voor OneLake-bestanden kan tekst extraheren uit de volgende documentindelingen:
- CSV (zie CSV-blobs indexeren)
- EML
- EPUB
- GZ
- HTML
- JSON (zie JSON-blobs indexeren)
- KML (XML voor geografische weergaven)
- Microsoft Office-indelingen: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (e-mailberichten van Outlook), XML (zowel 2003 als 2006 WORD XML)
- Documentindelingen openen: ODT, ODS, ODP
- Tekstbestanden zonder opmaak (zie ook Indexering van tekst zonder opmaak)
- RTF
- XML
- POSTCODE
Ondersteunde sneltoetsen
De volgende OneLake-snelkoppelingen worden ondersteund door de indexeerfunctie voor OneLake-bestanden:
OneLake-snelkoppeling (een snelkoppeling naar een ander OneLake-exemplaar)
Beperkingen in deze preview
Parquet-bestandstypen (inclusief Delta Parquet) worden momenteel niet ondersteund.
Het verwijderen van bestanden wordt niet ondersteund voor snelkoppelingen voor Amazon S3 en Google Cloud Storage.
Deze indexeerfunctie biedt geen ondersteuning voor de locatie-inhoud van oneLake-werkruimtetabel.
Deze indexeerfunctie biedt geen ondersteuning voor SQL-query's, maar de query die in de configuratie van de gegevensbron wordt gebruikt, is uitsluitend bedoeld om optioneel de map of snelkoppeling voor toegang toe te voegen.
Er is geen ondersteuning voor het opnemen van bestanden uit mijn werkruimte in OneLake, omdat dit een persoonlijke opslagplaats per gebruiker is.
Gegevens voorbereiden voor indexering
Voordat u indexering instelt, controleert u de brongegevens om te bepalen of er wijzigingen vooraf moeten worden aangebracht. Een indexeerfunctie kan inhoud van één container tegelijk indexeren. Standaard worden alle bestanden in de container verwerkt. U hebt verschillende opties voor meer selectieve verwerking:
Plaats bestanden in een virtuele map. Een definitie van een indexeerfunctiegegevensbron bevat een queryparameter die een lakehouse-submap of snelkoppeling kan zijn. Als deze waarde is opgegeven, worden alleen de bestanden in de submap of snelkoppeling in het lakehouse geïndexeerd.
Bestanden opnemen of uitsluiten op bestandstype. De lijst met ondersteunde documentindelingen kan u helpen bepalen welke bestanden u wilt uitsluiten. U kunt bijvoorbeeld afbeeldings- of audiobestanden uitsluiten die geen doorzoekbare tekst bieden. Deze mogelijkheid wordt beheerd via configuratie-instellingen in de indexeerfunctie.
Willekeurige bestanden opnemen of uitsluiten. Als u om welke reden dan ook een specifiek bestand wilt overslaan, kunt u metagegevenseigenschappen en -waarden toevoegen aan bestanden in uw OneLake Lakehouse. Wanneer een indexeerfunctie deze eigenschap tegenkomt, wordt het bestand of de inhoud ervan in de indexeringsuitvoering overgeslagen.
Bestandsopname en uitsluiting worden behandeld in de configuratiestap van de indexeerfunctie . Als u geen criteria instelt, rapporteert de indexeerfunctie een niet-in aanmerking komend bestand als een fout en gaat verder. Als er voldoende fouten optreden, kan de verwerking stoppen. U kunt fouttolerantie opgeven in de configuratie-instellingen van de indexeerfunctie.
Een indexeerfunctie maakt doorgaans één zoekdocument per bestand, waarbij de tekstinhoud en metagegevens worden vastgelegd als doorzoekbare velden in een index. Als bestanden hele bestanden zijn, kunt u ze mogelijk parseren in meerdere zoekdocumenten. U kunt bijvoorbeeld rijen in een CSV-bestand parseren om één zoekdocument per rij te maken. Als u één document in kleinere passages wilt segmenteren om gegevens te vectoriseren, kunt u overwegen geïntegreerde vectorisatie te gebruiken.
Metagegevens van bestanden indexeren
Bestandsmetagegevens kunnen ook worden geïndexeerd en dat is handig als u denkt dat een van de standaard- of aangepaste metagegevenseigenschappen nuttig is in filters en query's.
Door de gebruiker opgegeven metagegevenseigenschappen worden exacte bewoordingen geëxtraheerd. Als u de waarden wilt ontvangen, moet u het veld definiëren in de zoekindex van het type Edm.String, met dezelfde naam als de metagegevenssleutel van de blob. Als een blob bijvoorbeeld een metagegevenssleutel Priority met waarde Highheeft, moet u een veld definiëren met de naam Priority in uw zoekindex en wordt deze gevuld met de waarde High.
Eigenschappen van standaardbestandsmetagegevens kunnen worden geëxtraheerd in vergelijkbare benoemde en getypte velden, zoals hieronder wordt vermeld. De indexeerfunctie voor OneLake-bestanden maakt automatisch interne veldtoewijzingen voor deze metagegevenseigenschappen, waarbij de oorspronkelijke naam met afbreekstreepjes ('metadata-storage-name') wordt geconverteerd naar een onderstrepingsteken equivalente naam ('metadata_storage_name').
U moet nog steeds de onderstrepingstekenvelden toevoegen aan de indexdefinitie, maar u kunt veldtoewijzingen van de indexeerfunctie weglaten omdat de indexeerfunctie de koppeling automatisch maakt.
metadata_storage_name (
Edm.String) - de bestandsnaam. Als u bijvoorbeeld een bestand /mydatalake/my-folder/submap/resume.pdf hebt, isresume.pdfde waarde van dit veld.metadata_storage_path (
Edm.String) - de volledige URI van de blob, inclusief het opslagaccount. Bijvoorbeeldhttps://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String) - inhoudstype zoals opgegeven door de code die u hebt gebruikt om de blob te uploaden. Bijvoorbeeld:application/octet-stream.metadata_storage_last_modified (
Edm.DateTimeOffset) - laatste wijzigingstijdstempel voor de blob. Azure AI Search gebruikt deze tijdstempel om gewijzigde blobs te identificeren, om te voorkomen dat alles na de eerste indexering opnieuw wordt geïndexeerde.metadata_storage_size (
Edm.Int64) - blobgrootte in bytes.metadata_storage_content_md5 (
Edm.String) - MD5-hash van de blobinhoud, indien beschikbaar.
Ten slotte kunnen metagegevenseigenschappen die specifiek zijn voor de documentindeling van de bestanden die u indexeert, ook worden weergegeven in het indexschema. Zie eigenschappen voor inhoudsmetagegevens voor meer informatie over inhoudsspecifieke metagegevens.
Het is belangrijk om aan te geven dat u geen velden hoeft te definiëren voor alle bovenstaande eigenschappen in uw zoekindex. U hoeft alleen de eigenschappen vast te leggen die u nodig hebt voor uw toepassing.
Machtigingen verlenen
De OneLake-indexeerfunctie maakt gebruik van tokenverificatie en op rollen gebaseerde toegang voor verbindingen met OneLake. Machtigingen worden toegewezen in OneLake. Er zijn geen machtigingsvereisten voor de fysieke gegevensarchieven die back-ups maken van de snelkoppelingen. Als u bijvoorbeeld indexeert vanuit AWS, hoeft u geen zoekservicemachtigingen te verlenen in AWS.
De minimale roltoewijzing voor uw zoekservice-id is Inzender.
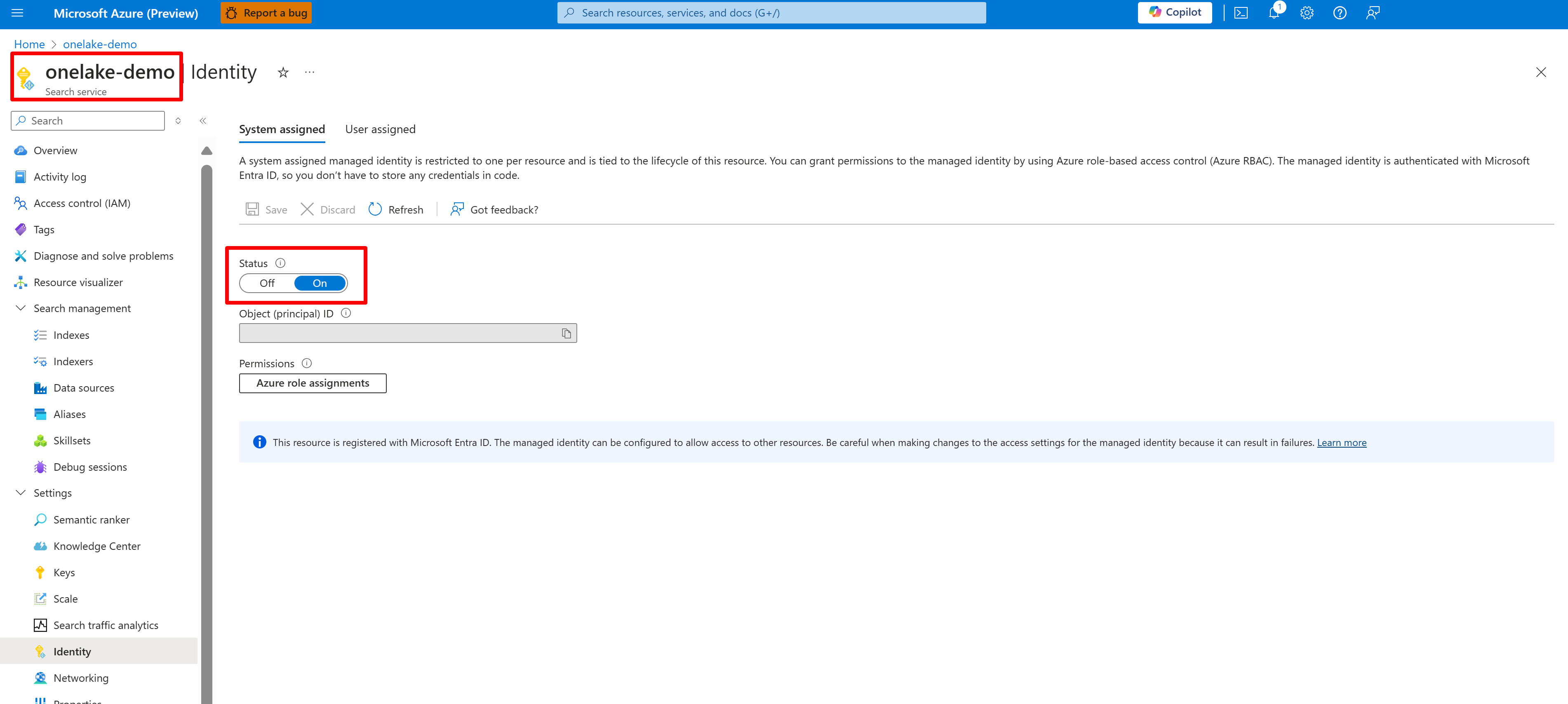
Configureer een door een systeem of door de gebruiker beheerde identiteit voor uw AI-Search-service.
In de volgende schermopname ziet u een door het systeem beheerde identiteit voor een zoekservice met de naam 'onelake-demo'.
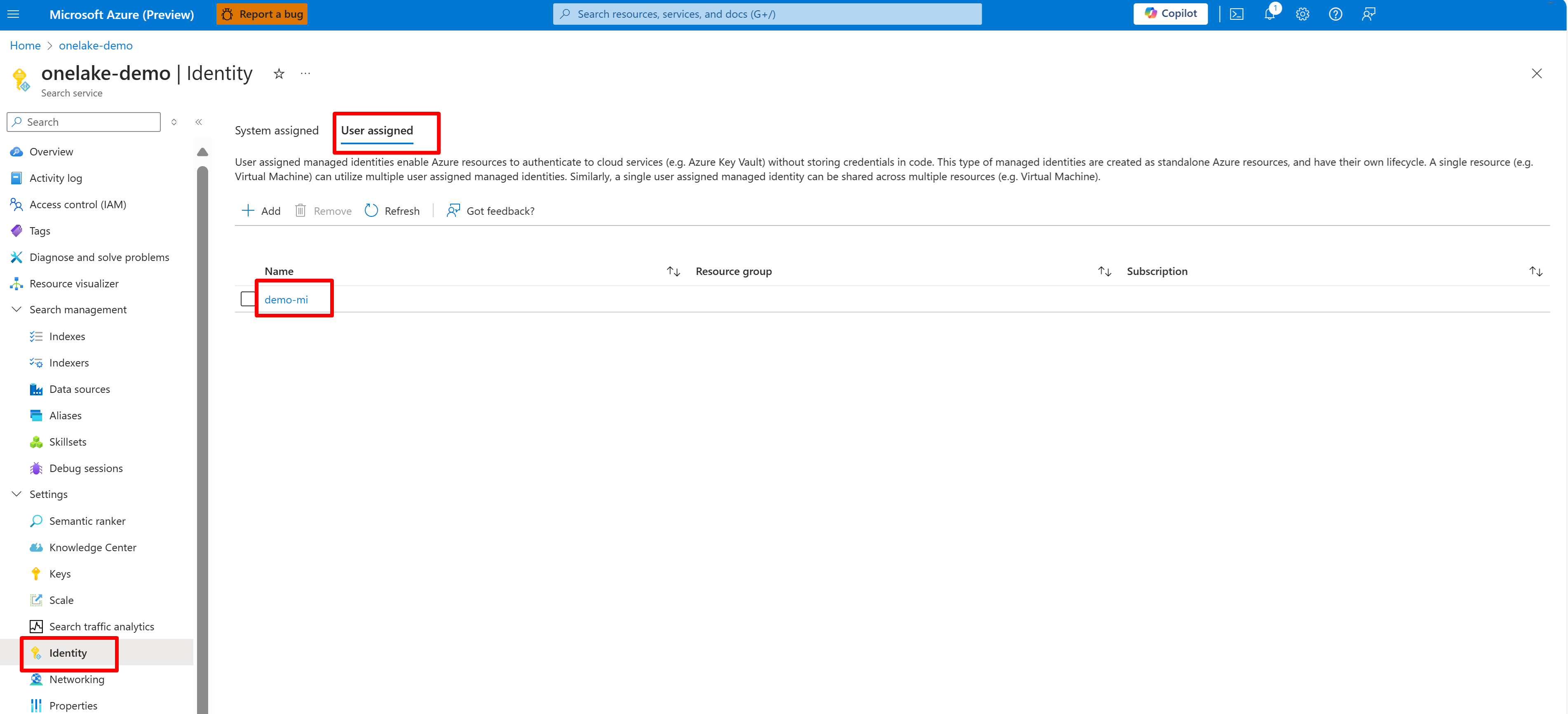
In deze schermopname ziet u een door de gebruiker beheerde identiteit voor dezelfde zoekservice.
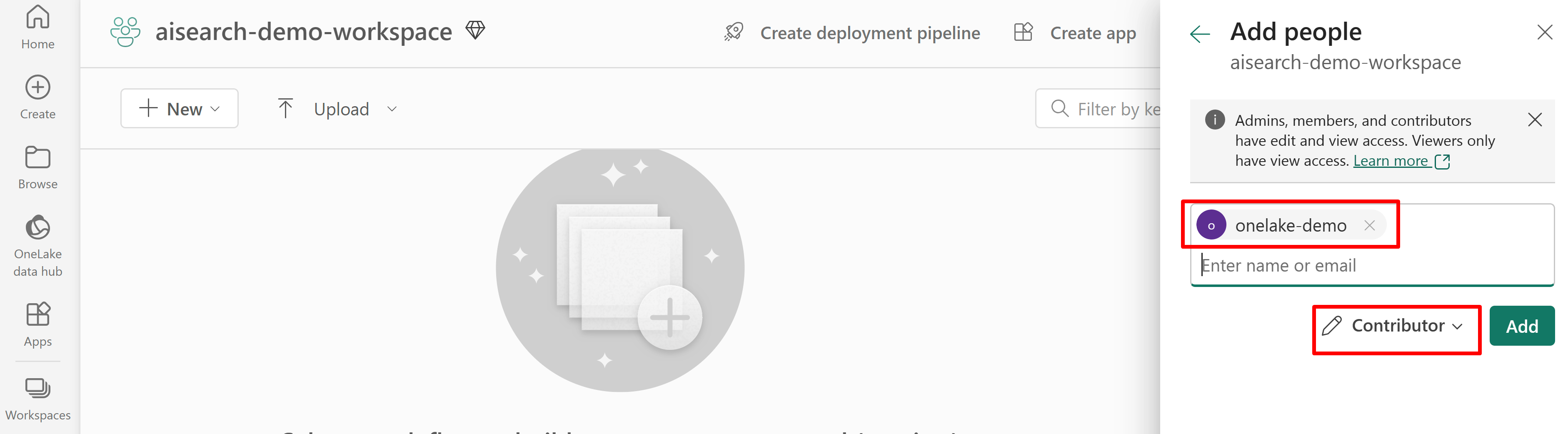
Verdeel machtigingen voor zoekservicetoegang tot de Fabric-werkruimte. De zoekservice maakt de verbinding namens de indexeerfunctie.
Als u een door het systeem toegewezen beheerde identiteit gebruikt, zoekt u naar de naam van de AI-Search-service. Zoek naar de naam van de identiteitsresource voor een door de gebruiker toegewezen beheerde identiteit.
In de volgende schermopname ziet u een roltoewijzing inzender met behulp van een door het systeem beheerde identiteit.
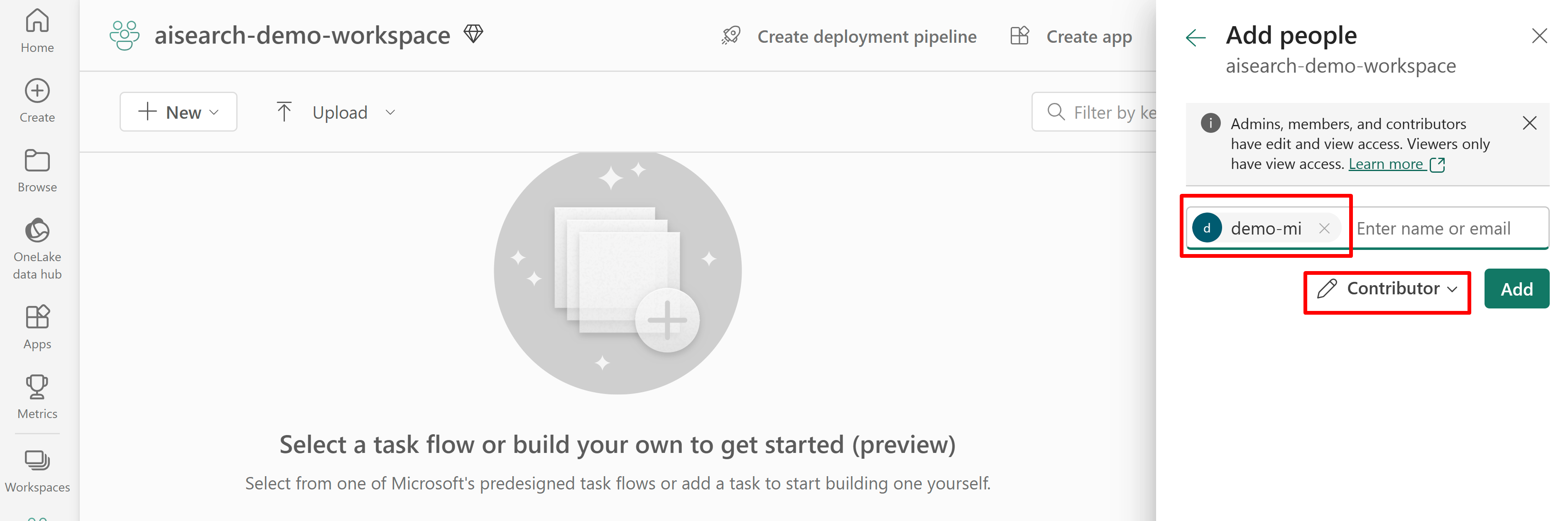
In deze schermopname ziet u een roltoewijzing inzender met behulp van een door de gebruiker toegewezen beheerde identiteit:




De gegevensbron definiëren
Een gegevensbron wordt gedefinieerd als een onafhankelijke resource, zodat deze kan worden gebruikt door meerdere indexeerfuncties. U moet de REST API 2024-05-01-preview gebruiken om de gegevensbron te maken.
Gebruik de REST API voor het maken of bijwerken van een gegevensbron om de definitie ervan in te stellen. Dit zijn de belangrijkste stappen van de definitie.
Ingesteld
"type"op"onelake"(vereist).Haal de GUID van de Microsoft Fabric-werkruimte en de GUID van Lakehouse op:
Ga naar het Lakehouse waar u gegevens uit de URL wilt importeren. Het moet er ongeveer uitzien als in dit voorbeeld: "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi". Kopieer de volgende waarden die worden gebruikt in de definitie van de gegevensbron:
Kopieer de werkruimte-GUID, die we aanroepen
{FabricWorkspaceGuid}, die direct na 'groepen' in de URL wordt vermeld. In dit voorbeeld is dit 000000000-0000-0000-0000-00000000000000000.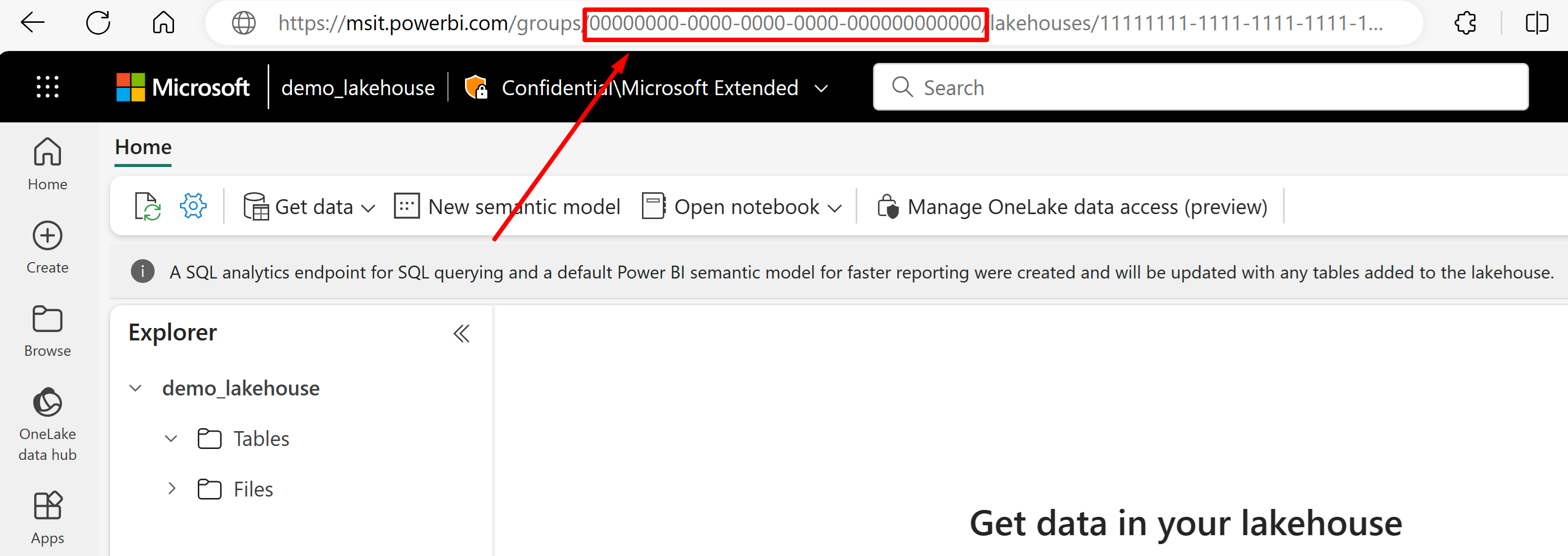
Kopieer de lakehouse-GUID die we aanroepen
{lakehouseGuid}, die direct na 'lakehouses' in de URL wordt vermeld. In dit voorbeeld is dit 11111111-11111-11111-11111-11111111111.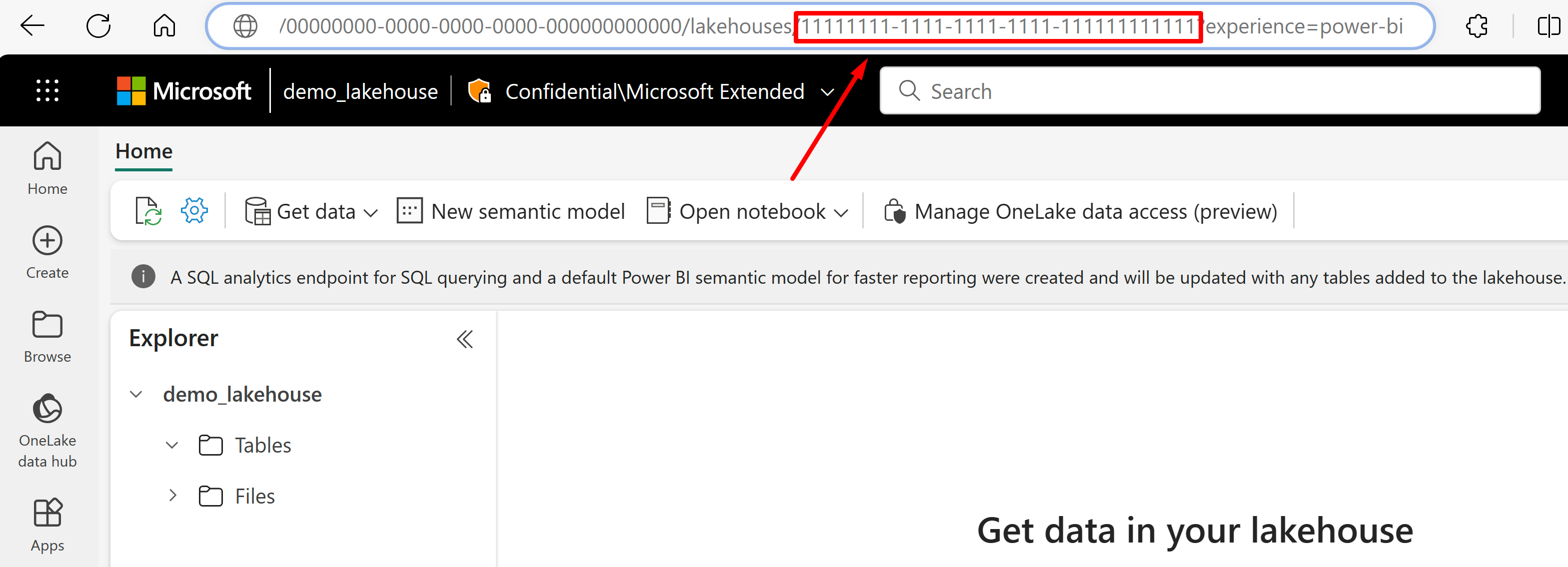
Stel
"credentials"deze in op de GUID van de Microsoft Fabric-werkruimte door de waarde te vervangen{FabricWorkspaceGuid}die u in de vorige stap hebt gekopieerd. Dit is de OneLake voor toegang met de beheerde identiteit die u verderop in deze handleiding instelt."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }Stel
"container.name"deze in op de lakehouse-GUID en vervang deze door{lakehouseGuid}de waarde die u in de vorige stap hebt gekopieerd. Gebruik"query"deze optie om desgewenst een lakehouse-submap of snelkoppeling op te geven."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Stel de verificatiemethode in met behulp van de door de gebruiker toegewezen beheerde identiteit of ga verder met de volgende stap voor door het systeem beheerde identiteit.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }De
userAssignedIdentitywaarde kan worden gevonden door toegang te krijgen tot de{userAssignedManagedIdentity}resource, onder Eigenschappen en deze wordt aangeroepenId.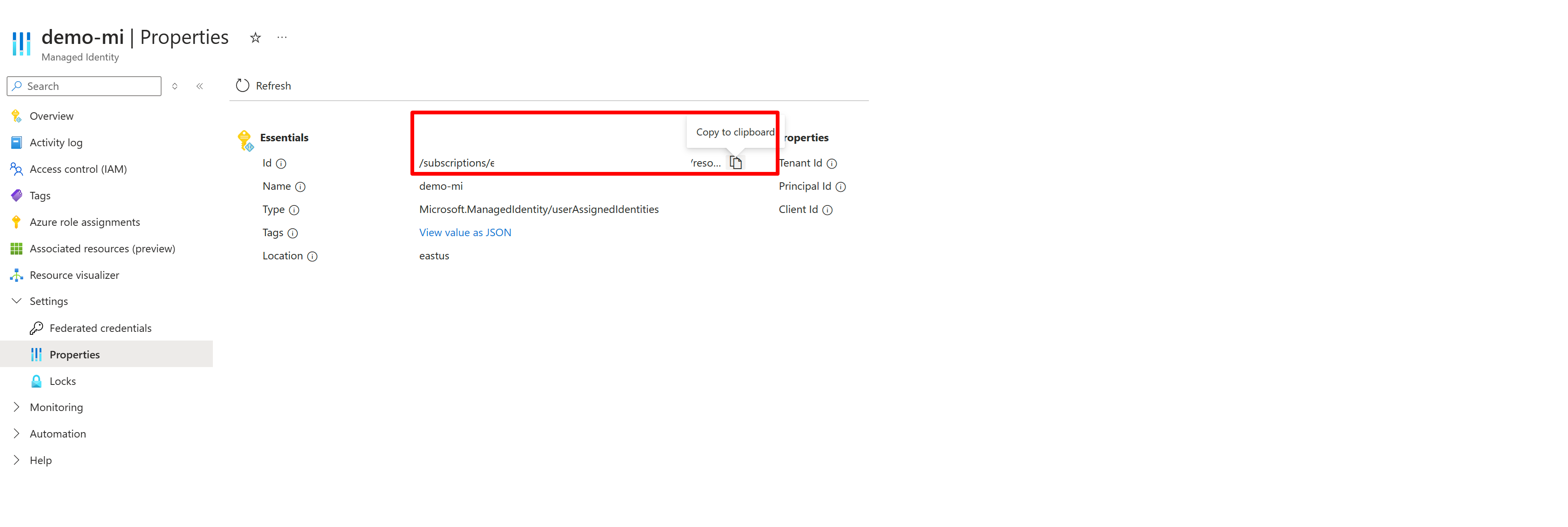
Voorbeeld:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }Gebruik eventueel een door het systeem toegewezen beheerde identiteit. De 'identiteit' wordt verwijderd uit de definitie als u een door het systeem toegewezen beheerde identiteit gebruikt.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Voorbeeld:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



Verwijderingen detecteren via aangepaste metagegevens
De definitie van de indexeerfunctie voor OneLake-bestanden kan een beleid voor voorlopig verwijderen bevatten als u wilt dat de indexeerfunctie een zoekdocument verwijdert wanneer het brondocument wordt gemarkeerd voor verwijdering.
Als u automatische bestandsverwijdering wilt inschakelen, gebruikt u aangepaste metagegevens om aan te geven of een zoekdocument uit de index moet worden verwijderd.
Werkstroom vereist drie afzonderlijke acties:
- Het bestand voorlopig verwijderen in OneLake
- Indexeerfunctie verwijdert het zoekdocument in de index
- Het bestand in OneLake hard verwijderen
'Voorlopig verwijderen' vertelt de indexeerfunctie wat u moet doen (verwijder het zoekdocument). Als u eerst het fysieke bestand in OneLake verwijdert, hoeft de indexeerfunctie niets te lezen en is het bijbehorende zoekdocument in de index zwevend.
Er zijn stappen die u moet volgen in Zowel OneLake als Azure AI Search, maar er zijn geen andere functieafhankelijkheden.
Voeg in het Lakehouse-bestand een aangepast sleutel-waardepaar met metagegevens toe aan het bestand om aan te geven dat het bestand is gemarkeerd voor verwijdering. U kunt bijvoorbeeld de eigenschap IsDeleted een naam geven, ingesteld op false. Wanneer u het bestand wilt verwijderen, wijzigt u het in waar.
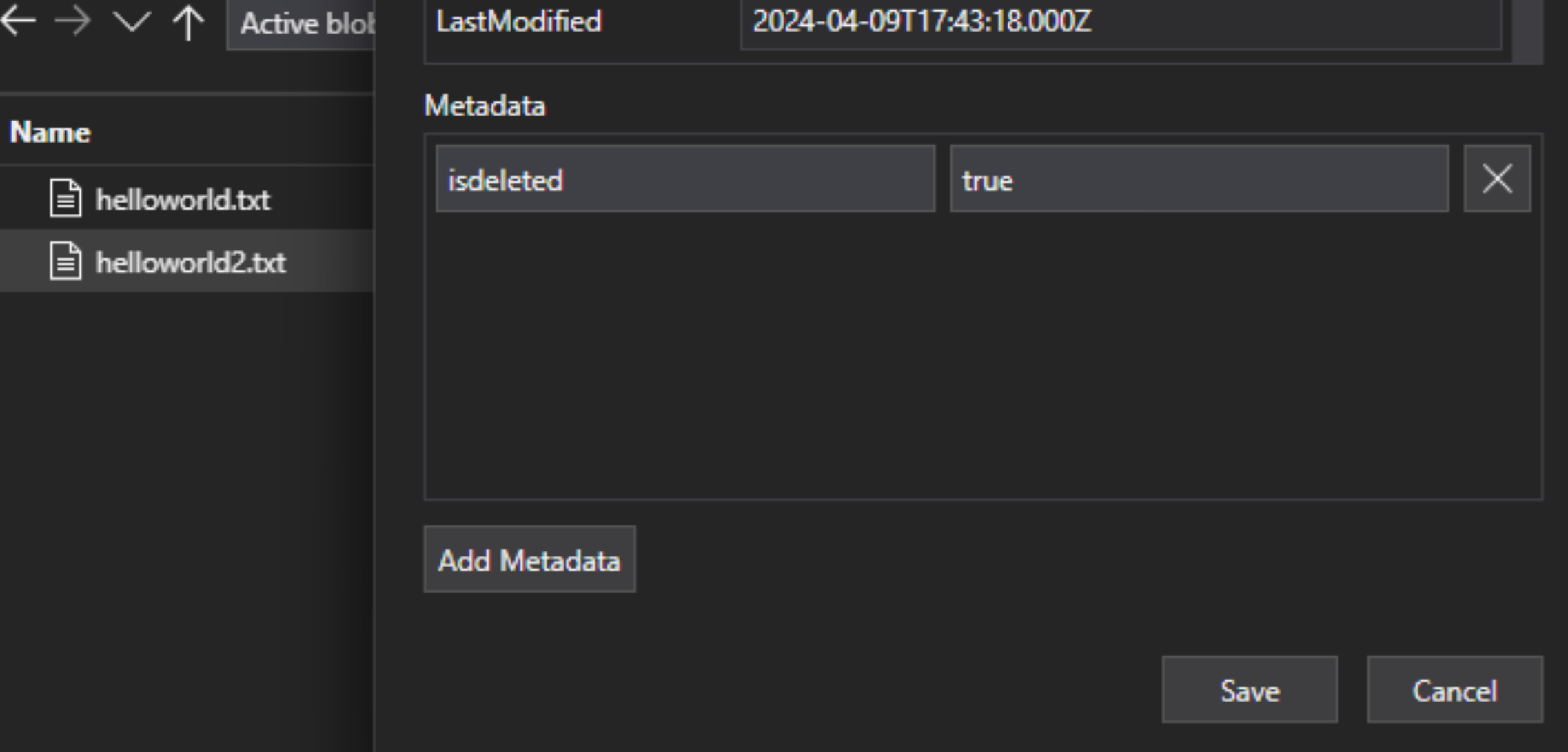
Bewerk in Azure AI Search de definitie van de gegevensbron om een eigenschap dataDeletionDetectionPolicy op te nemen. Het volgende beleid beschouwt bijvoorbeeld dat een bestand moet worden verwijderd als het een metagegevenseigenschap IsDeleted heeft met de waarde true:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

Nadat de indexeerfunctie het document uit de zoekindex heeft uitgevoerd en verwijderd, kunt u vervolgens het fysieke bestand in de data lake verwijderen.
Enkele belangrijke punten zijn:
Het plannen van een indexeerfunctieuitvoering helpt dit proces te automatiseren. We raden planningen aan voor alle incrementele indexeringsscenario's.
Als het verwijderingsdetectiebeleid niet is ingesteld op de eerste uitvoering van de indexeerfunctie, moet u de indexeerfunctie opnieuw instellen zodat de bijgewerkte configuratie wordt gelezen.
Zoals u weet, wordt verwijderingsdetectie niet ondersteund voor Snelkoppelingen voor Amazon S3 en Google Cloud Storage vanwege de afhankelijkheid van aangepaste metagegevens.
Zoekvelden toevoegen aan een index
Voeg in een zoekindex velden toe om de inhoud en metagegevens van uw OneLake Data Lake-bestanden te accepteren.
Een index maken of bijwerken om zoekvelden te definiëren waarmee bestandsinhoud en metagegevens worden opgeslagen:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Maak een documentsleutelveld ('sleutel': true'). Voor bestandsinhoud zijn de beste kandidaten metagegevenseigenschappen.
metadata_storage_path(standaard) volledig pad naar het object of bestand. Het sleutelveld ('ID' in dit voorbeeld) wordt gevuld met waarden uit metadata_storage_path omdat dit de standaardwaarde is.metadata_storage_name, alleen bruikbaar als namen uniek zijn. Als u dit veld als sleutel wilt gebruiken, gaat u naar"key": truedeze velddefinitie.Een aangepaste metagegevenseigenschap die u aan uw bestanden toevoegt. Deze optie vereist dat uw bestandsuploadproces die metagegevenseigenschap toevoegt aan alle blobs. Omdat de sleutel een vereiste eigenschap is, kunnen alle bestanden waarvoor een waarde ontbreekt, niet worden geïndexeerd. Als u een aangepaste metagegevenseigenschap als sleutel gebruikt, moet u geen wijzigingen aanbrengen in die eigenschap. Indexeerfuncties voegen dubbele documenten toe voor hetzelfde bestand als de sleuteleigenschap wordt gewijzigd.
Metagegevenseigenschappen bevatten vaak tekens, zoals
/en-, die ongeldig zijn voor documentsleutels. Omdat de indexeerfunctie een eigenschap base64EncodeKeys heeft (standaard true), codeert deze automatisch de metagegevenseigenschap, zonder dat er configuratie of veldtoewijzing is vereist.Voeg een inhoudsveld toe om geëxtraheerde tekst uit elk bestand op te slaan via de eigenschap 'inhoud' van het bestand. U hoeft deze naam niet te gebruiken, maar hiermee kunt u gebruikmaken van impliciete veldtoewijzingen.
Voeg velden toe voor standaardmetagegevenseigenschappen. De indexeerfunctie kan aangepaste metagegevenseigenschappen, standaardmetagegevenseigenschappen en inhoudsspecifieke metagegevenseigenschappen lezen.
De indexeerfunctie voor OneLake-bestanden configureren en uitvoeren
Zodra de index en gegevensbron zijn gemaakt, kunt u de indexeerfunctie maken. De configuratie van de indexeerfunctie geeft de invoer, parameters en eigenschappen aan die het gedrag van de uitvoeringstijd regelen. U kunt ook opgeven welke delen van een blob u wilt indexeren.
Maak of werk een indexeerfunctie bij door deze een naam te geven en te verwijzen naar de gegevensbron en doelindex:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Stel batchSize in als de standaardwaarde (10 documenten) onder het gebruik of overweldigende beschikbare resources valt. Standaard batchgrootten zijn gegevensbronspecifiek. Met bestandsindexering wordt de batchgrootte ingesteld op 10 documenten in de herkenning van de grotere gemiddelde documentgrootte.
Bepaal onder Configuratie welke bestanden worden geïndexeerd op basis van bestandstype of laat u niet opgegeven om alle bestanden op te halen.
Geef
"indexedFileNameExtensions"een door komma's gescheiden lijst met bestandsextensies op (met een voorlooppunt). Doe hetzelfde om"excludedFileNameExtensions"aan te geven welke extensies moeten worden overgeslagen. Als dezelfde extensie zich in beide lijsten bevindt, wordt deze uitgesloten van indexering.Stel onder 'configuratie' 'dataToExtract' in om te bepalen welke delen van de bestanden worden geïndexeerd:
'contentAndMetadata' is de standaardwaarde. Hiermee geeft u op dat alle metagegevens en tekstuele inhoud die uit het bestand is geëxtraheerd, worden geïndexeerd.
'storageMetadata' geeft aan dat alleen de standaardbestandseigenschappen en door de gebruiker opgegeven metagegevens worden geïndexeerd. Hoewel de eigenschappen worden gedocumenteerd voor Azure-blobs, zijn de bestandseigenschappen hetzelfde voor OneLkae, met uitzondering van de sas-gerelateerde metagegevens.
'allMetadata' geeft aan dat standaardbestandseigenschappen en metagegevens voor gevonden inhoudstypen worden geëxtraheerd uit de bestandsinhoud en geïndexeerd.
Stel onder Configuratie 'parsingMode' in als bestanden moeten worden toegewezen aan meerdere zoekdocumenten of als ze bestaan uit tekst zonder opmaak, JSON-documenten of CSV-bestanden.
Geef veldtoewijzingen op als er verschillen zijn in veldnaam of -type, of als u meerdere versies van een bronveld in de zoekindex nodig hebt.
Bij het indexeren van bestanden kunt u veldtoewijzingen vaak weglaten omdat de indexeerfunctie ingebouwde ondersteuning heeft voor het toewijzen van de eigenschappen 'inhoud' en metagegevens aan velden met vergelijkbare namen en getypte velden in een index. Voor eigenschappen van metagegevens vervangt de indexeerfunctie automatisch afbreekstreepjes door onderstrepingstekens
-in de zoekindex.
Maak een indexeerfunctie voor meer informatie over andere eigenschappen. Zie Indexeerfunctie (REST) maken in de REST API voor de volledige lijst met parameterbeschrijvingen. De parameters zijn hetzelfde voor OneLake.
Standaard wordt een indexeerfunctie automatisch uitgevoerd wanneer u deze maakt. U kunt dit gedrag wijzigen door 'uitgeschakeld' in te stellen op waar. Als u de uitvoering van de indexeerfunctie wilt beheren, voert u een indexeerfunctie op aanvraag uit of plaatst u deze in een schema.
De status van de indexeerfunctie controleren
Hier vindt u meer informatie over meerdere benaderingen voor het bewaken van de status en uitvoeringsgeschiedenis van de indexeerfunctie.
Afhandeling van fouten
Fouten die vaak optreden tijdens het indexeren, zijn niet-ondersteunde inhoudstypen, ontbrekende inhoud of oversized bestanden. Standaard stopt de indexeerfunctie voor OneLake-bestanden zodra er een bestand met een niet-ondersteund inhoudstype wordt weergegeven. Het is echter mogelijk dat indexering wordt voortgezet, zelfs als er fouten optreden en later fouten opsporen in afzonderlijke documenten.
Tijdelijke fouten zijn gebruikelijk voor oplossingen met meerdere platforms en producten. Als u de indexeerfunctie echter volgens een schema houdt (bijvoorbeeld om de 5 minuten), moet de indexeerfunctie in staat zijn om deze fouten in de volgende uitvoering te herstellen.
Er zijn vijf indexeerfuncties die het antwoord van de indexeerfunctie bepalen wanneer er fouten optreden.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
Volgende stappen
Bekijk hoe de wizard Gegevens importeren en vectoriseren werkt en probeer het uit voor deze indexeerfunctie. U kunt geïntegreerde vectorisatie gebruiken om te segmenteren en insluitingen te maken voor vectoren of hybride zoekopdrachten met behulp van een standaardschema.