Zbiorcze kopiowanie z bazy danych do usługi Azure Data Explorer przy użyciu szablonu usługi Azure Data Factory
Azure Data Explorer to szybka, w pełni zarządzana usługa analizy danych. Oferuje ona analizę w czasie rzeczywistym na dużych ilościach danych przesyłanych strumieniowo z wielu źródeł, takich jak aplikacje, witryny internetowe i urządzenia IoT.
Aby skopiować dane z bazy danych w programie Oracle Server, Netezza, Teradata lub SQL Server do usługi Azure Data Explorer, musisz załadować ogromne ilości danych z wielu tabel. Zazwyczaj dane muszą być partycjonowane w każdej tabeli, aby można było ładować wiersze z wieloma wątkami równolegle z jedną tabelą. W tym artykule opisano szablon do użycia w tych scenariuszach.
Szablony usługi Azure Data Factory są wstępnie zdefiniowanymi potokami usługi Data Factory. Te szablony mogą pomóc w szybkim rozpoczęciu pracy z usługą Data Factory i skróceniu czasu opracowywania projektów integracji danych.
Tworzenie kopii zbiorczej z bazy danych do szablonu usługi Azure Data Explorer przy użyciu działań Lookup i ForEach . W celu szybszego kopiowania danych można użyć szablonu, aby utworzyć wiele potoków na bazę danych lub tabelę.
Ważne
Pamiętaj, aby użyć narzędzia odpowiedniego dla ilości danych, które chcesz skopiować.
- Użyj szablonu Kopiowanie zbiorcze z bazy danych do usługi Azure Data Explorer , aby skopiować duże ilości danych z baz danych, takich jak sql server i Google BigQuery do usługi Azure Data Explorer.
- Za pomocą narzędzia Data Factory Copy Data Tool skopiuj kilka tabel z małymi lub umiarkowanymi ilościami danych do usługi Azure Data Explorer.
Wymagania wstępne
- Subskrypcja platformy Azure. Utwórz bezpłatne konto platformy Azure.
- Baza danych i klaster usługi Azure Data Explorer. Utwórz klaster i bazę danych.
- Fabryka danych. Tworzenie fabryki danych.
- Źródło danych.
Tworzenie tabeli ControlTableDataset
ControlTableDataset wskazuje, jakie dane zostaną skopiowane ze źródła do miejsca docelowego w potoku. Liczba wierszy wskazuje łączną liczbę potoków potrzebnych do skopiowania danych. Należy zdefiniować element ControlTableDataset jako część źródłowej bazy danych.
Przykład formatu tabeli źródłowej programu SQL Server jest pokazany w następującym kodzie:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
Elementy kodu zostały opisane w poniższej tabeli:
| Właściwości | opis | Przykład |
|---|---|---|
| PartitionId | Kolejność kopiowania | 1 |
| Zapytanie źródłowe | Zapytanie wskazujące, które dane zostaną skopiowane podczas wykonywania potoku | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''> |
| ADXTableName | Nazwa tabeli docelowej | MyAdxTable |
Jeśli zestaw ControlTableDataset ma inny format, utwórz porównywalny zestaw ControlTableDataset dla formatu.
Używanie szablonu kopiowania zbiorczego z bazy danych do usługi Azure Data Explorer
W okienku Wprowadzenie wybierz pozycję Utwórz potok z szablonu , aby otworzyć okienko Galeria szablonów.
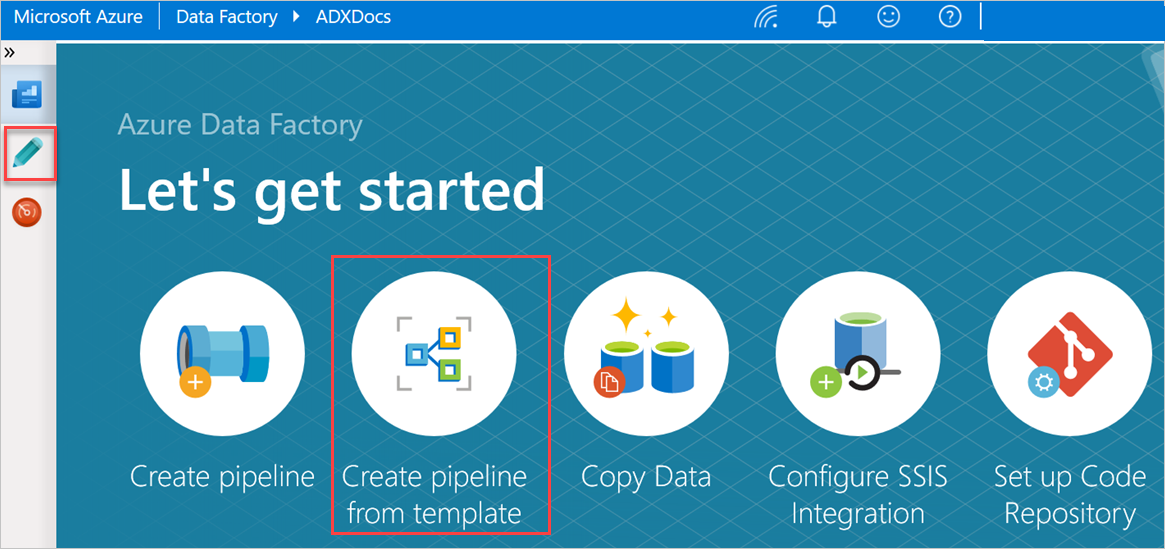
Wybierz szablon Kopiowanie zbiorcze z bazy danych do usługi Azure Data Explorer.
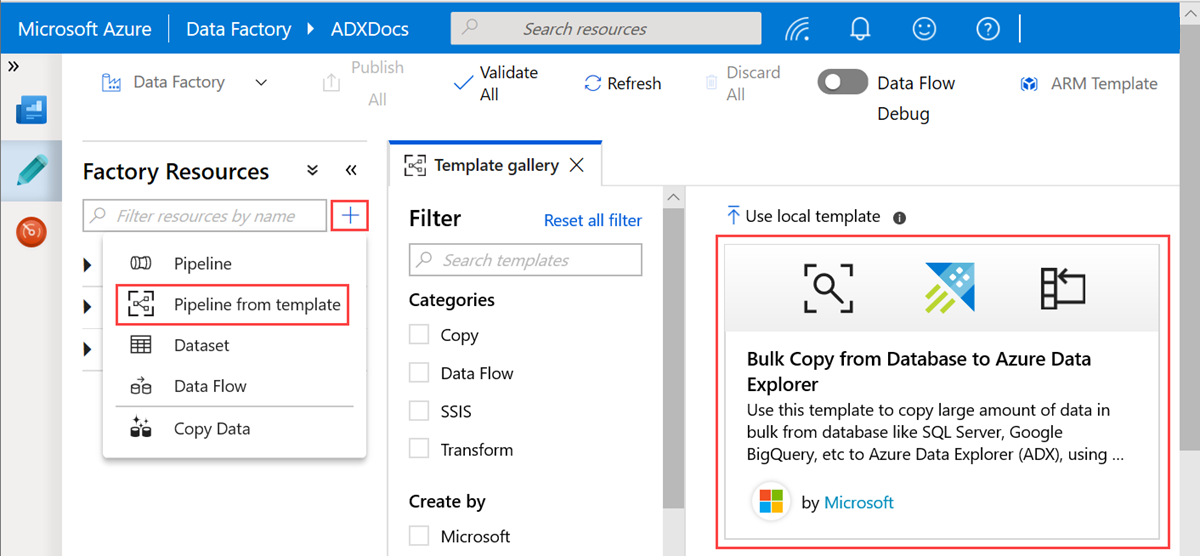
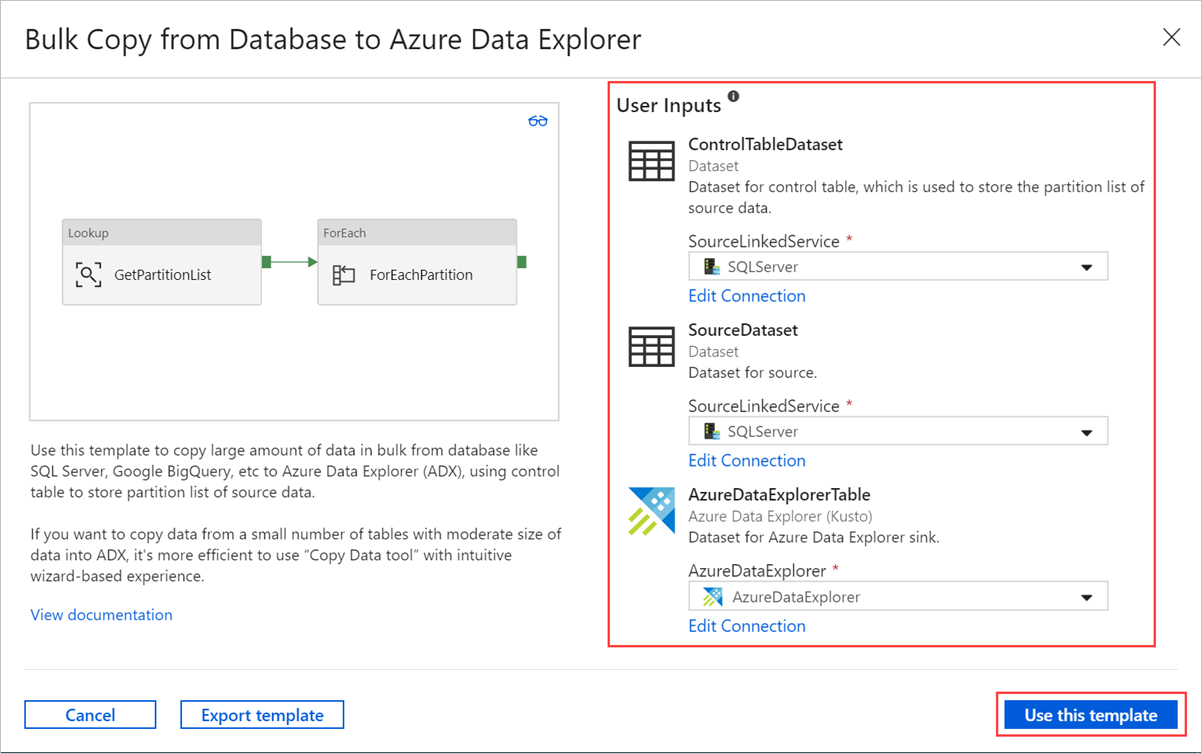
W okienku Kopiowanie zbiorcze z bazy danych do usługi Azure Data Explorer w obszarze Dane wejściowe użytkownika określ zestawy danych, wykonując następujące czynności:
a. Z listy rozwijanej ControlTableDataset wybierz połączoną usługę do tabeli kontrolnej, która wskazuje, jakie dane są kopiowane ze źródła do miejsca docelowego i gdzie zostaną umieszczone w miejscu docelowym.
b. Z listy rozwijanej SourceDataset wybierz połączoną usługę ze źródłową bazą danych.
c. Z listy rozwijanej AzureDataExplorerTable wybierz tabelę Azure Data Explorer. Jeśli zestaw danych nie istnieje, utwórz połączoną usługę Azure Data Explorer, aby dodać zestaw danych.
d. Wybierz Użyj tego szablonu.
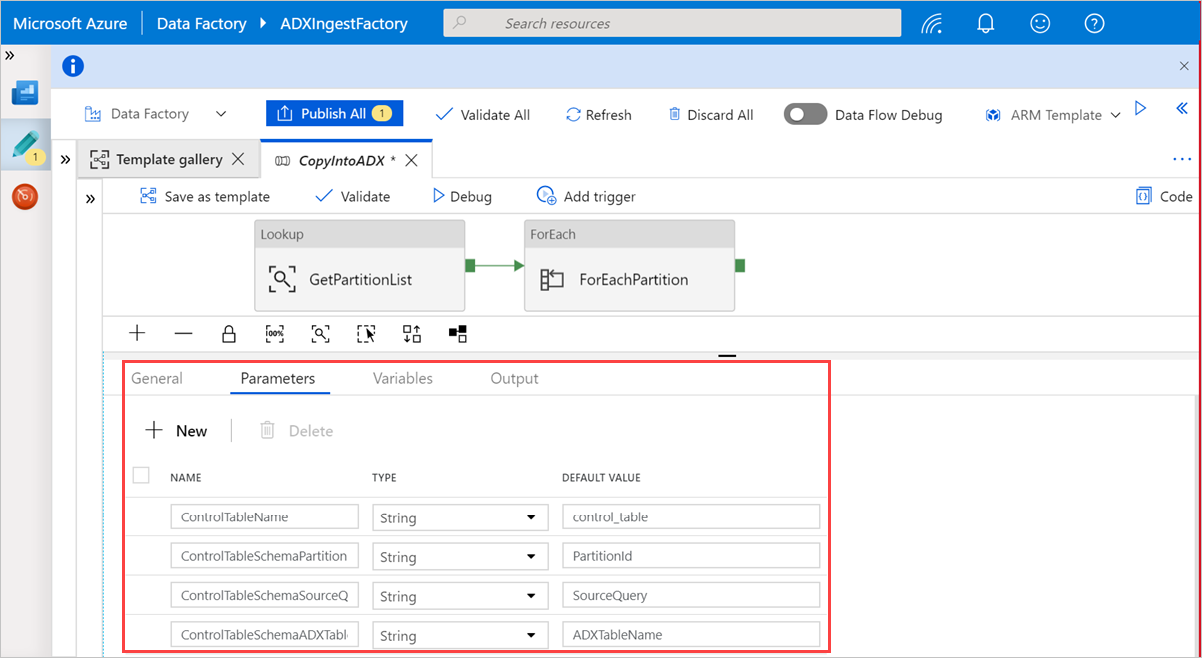
Wybierz obszar na kanwie poza działaniami, aby uzyskać dostęp do potoku szablonu. Wybierz kartę Parametry , aby wprowadzić parametry tabeli, w tym nazwę (nazwę tabeli sterującej) i wartość domyślną (nazwy kolumn).
W obszarze Odnośnik wybierz pozycję GetPartitionList , aby wyświetlić ustawienia domyślne. Zapytanie jest tworzone automatycznie.
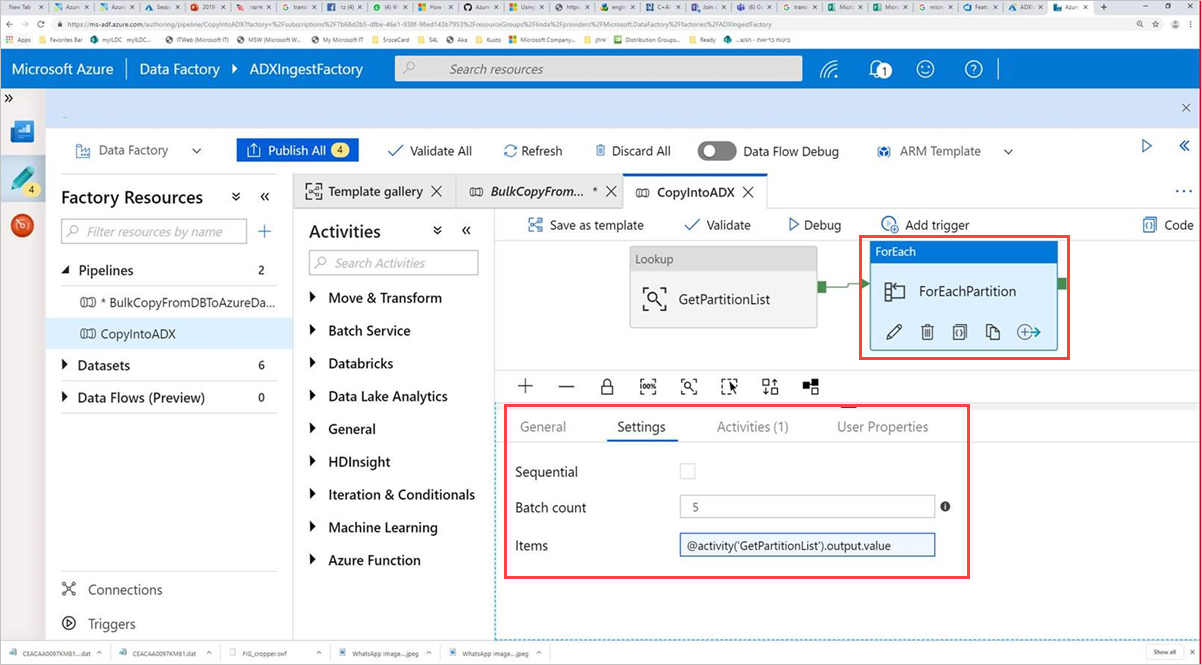
Wybierz działanie Polecenie, ForEachPartition, wybierz kartę Ustawienia , a następnie wykonaj następujące czynności:
a. W polu Liczba partii wprowadź liczbę z zakresu od 1 do 50. Ten wybór określa liczbę potoków uruchamianych równolegle do momentu osiągnięcia liczby wierszy ControlTableDataset .
b. Aby upewnić się, że partie potoku działają równolegle, nie zaznaczaj pola wyboru Sekwencyjne.
Napiwek
Najlepszym rozwiązaniem jest równoległe uruchamianie wielu potoków w celu szybszego kopiowania danych. Aby zwiększyć wydajność, należy podzielić dane w tabeli źródłowej i przydzielić jedną partycję na potok zgodnie z datą i tabelą.
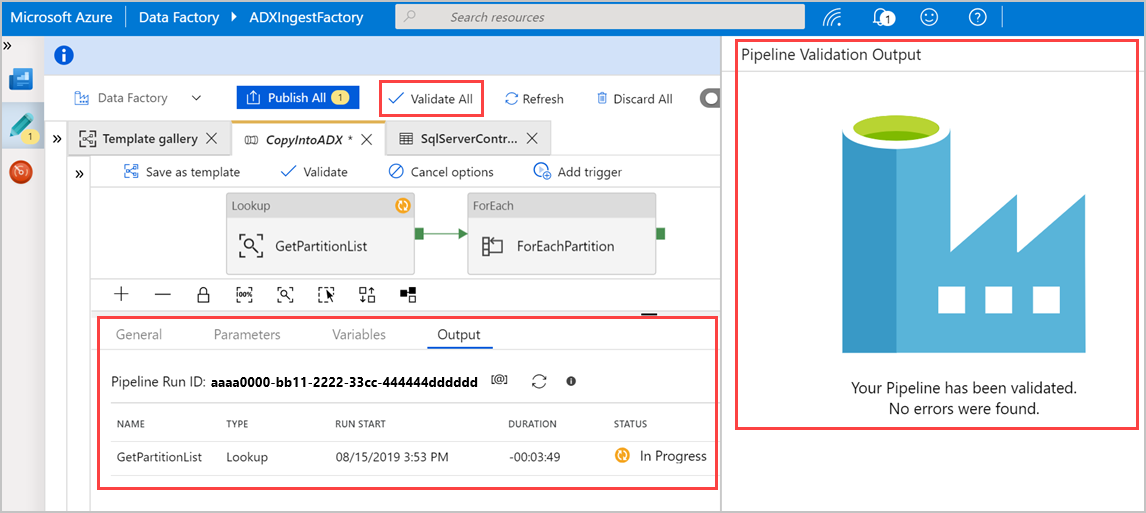
Wybierz pozycję Zweryfikuj wszystko , aby zweryfikować potok usługi Azure Data Factory, a następnie wyświetl wynik w okienku Dane wyjściowe weryfikacji potoku.
W razie potrzeby wybierz pozycję Debuguj, a następnie wybierz pozycję Dodaj wyzwalacz , aby uruchomić potok.
Teraz możesz użyć szablonu, aby efektywnie kopiować duże ilości danych z baz danych i tabel.
Powiązana zawartość
- Dowiedz się więcej o łączniku usługi Azure Data Explorer dla usługi Azure Data Factory.
- Edytowanie połączonych usług, zestawów danych i potoków w interfejsie użytkownika usługi Data Factory.
- Wykonywanie zapytań dotyczących danych w internetowym interfejsie użytkownika usługi Azure Data Explorer.