Kopiowanie danych do lub z usługi Azure Data Explorer przy użyciu usługi Azure Data Factory lub Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób używania działania kopiowania w potokach usługi Azure Data Factory i usługi Synapse Analytics do kopiowania danych do lub z usługi Azure Data Explorer. Jest on oparty na artykule omówienie działania kopiowania, który zawiera ogólne omówienie działania kopiowania.
Napiwek
Aby dowiedzieć się więcej na temat integracji usługi Azure Data Explorer z usługą, przeczytaj temat Integracja usługi Azure Data Explorer.
Obsługiwane możliwości
Ten łącznik usługi Azure Data Explorer jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/ujście) | (1) (2) |
| Przepływ danych mapowania (źródło/ujście) | (1) |
| Działanie Lookup | (1) (2) |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Możesz skopiować dane z dowolnego obsługiwanego magazynu danych źródłowych do usługi Azure Data Explorer. Możesz również skopiować dane z usługi Azure Data Explorer do dowolnego obsługiwanego magazynu danych ujścia. Aby uzyskać listę magazynów danych obsługiwanych przez działanie kopiowania jako źródła lub ujścia, zobacz tabelę Obsługiwane magazyny danych.
Uwaga
Kopiowanie danych do lub z usługi Azure Data Explorer za pośrednictwem lokalnego magazynu danych przy użyciu własnego środowiska Integration Runtime jest obsługiwane w wersji 3.14 lub nowszej.
Za pomocą łącznika usługi Azure Data Explorer można wykonać następujące czynności:
- Kopiowanie danych przy użyciu uwierzytelniania tokenu aplikacji Entra firmy Microsoft przy użyciu jednostki usługi.
- Jako źródło pobierz dane przy użyciu zapytania KQL (Kusto).
- Jako ujście dołącz dane do tabeli docelowej.
Wprowadzenie
Napiwek
Aby zapoznać się z przewodnikiem po łączniku usługi Azure Data Explorer, zobacz Kopiowanie danych do/z usługi Azure Data Explorer i kopiowanie zbiorcze z bazy danych do usługi Azure Data Explorer.
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z usługą Azure Data Explorer przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z usługą Azure Data Explorer w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj pozycję Eksplorator i wybierz łącznik Usługi Azure Data Explorer (Kusto).
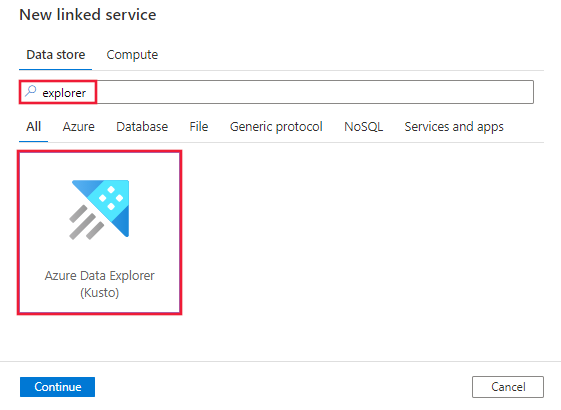
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
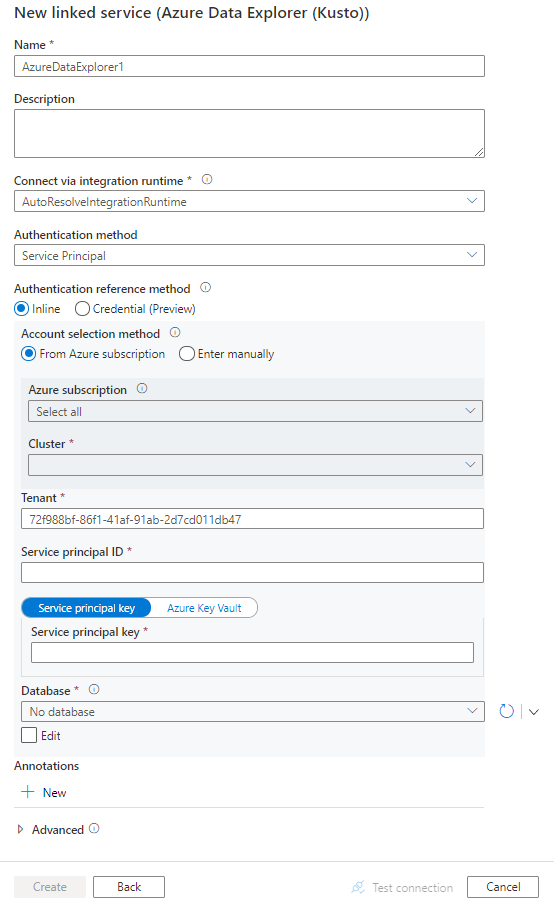
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek specyficznych dla łącznika usługi Azure Data Explorer.
Właściwości połączonej usługi
Łącznik usługi Azure Data Explorer obsługuje następujące typy uwierzytelniania. Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje:
- Uwierzytelnianie jednostki usługi
- Uwierzytelnianie tożsamości zarządzanej przypisanej przez system
- Uwierzytelnianie tożsamości zarządzanej przypisanej przez użytkownika
Uwierzytelnianie nazwy głównej usługi
Aby użyć uwierzytelniania jednostki usługi, wykonaj następujące kroki, aby uzyskać jednostkę usługi i udzielić uprawnień:
Zarejestruj aplikację w Platforma tożsamości Microsoft. Aby dowiedzieć się, jak to zrobić, zobacz Szybki start: rejestrowanie aplikacji przy użyciu Platforma tożsamości Microsoft. Zanotuj te wartości, których użyjesz do zdefiniowania połączonej usługi:
- Application ID
- Klucz aplikacji
- Identyfikator dzierżawy
Przyznaj jednostce usługi prawidłowe uprawnienia w usłudze Azure Data Explorer. Zobacz Zarządzanie uprawnieniami bazy danych usługi Azure Data Explorer, aby uzyskać szczegółowe informacje na temat ról i uprawnień oraz zarządzania uprawnieniami. Ogólnie rzecz biorąc, musisz:
- Jako źródło przyznaj co najmniej rolę podglądu bazy danych bazie danych
- Jako ujście przyznaj co najmniej rolę użytkownika Baza danych bazie danych do bazy danych
Uwaga
Gdy używasz interfejsu użytkownika do tworzenia, domyślnie konto użytkownika logowania jest używane do wyświetlania listy klastrów, baz danych i tabel usługi Azure Data Explorer. Możesz wybrać wyświetlanie listy obiektów przy użyciu jednostki usługi, klikając listę rozwijaną obok przycisku odświeżania lub ręcznie wprowadź nazwę, jeśli nie masz uprawnień do tych operacji.
Następujące właściwości są obsługiwane dla połączonej usługi Azure Data Explorer:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na AzureDataExplorer. | Tak |
| endpoint | Adres URL punktu końcowego klastra usługi Azure Data Explorer z formatem .https://<clusterName>.<regionName>.kusto.windows.net |
Tak |
| database | Nazwa bazy danych. | Tak |
| tenant | Określ informacje o dzierżawie (nazwę domeny lub identyfikator dzierżawy), w ramach których znajduje się aplikacja. Jest to nazywane "identyfikatorem urzędu" w usłudze Kusto parametry połączenia. Pobierz go, umieszczając wskaźnik myszy w prawym górnym rogu witryny Azure Portal. | Tak |
| servicePrincipalId | Określ identyfikator klienta aplikacji. Jest to nazywane "Identyfikatorem klienta aplikacji Microsoft Entra" w usłudze Kusto parametry połączenia. | Tak |
| servicePrincipalKey | Określ klucz aplikacji. Jest to nazywane "kluczem aplikacji Microsoft Entra" w usłudze Kusto parametry połączenia. Oznacz to pole jako securestring , aby bezpiecznie przechowywać je lub odwoływać się do bezpiecznych danych przechowywanych w usłudze Azure Key Vault. | Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime, jeśli magazyn danych znajduje się w sieci prywatnej. Jeśli nie zostanie określony, zostanie użyte domyślne środowisko Azure Integration Runtime. | Nie. |
Przykład: używanie uwierzytelniania klucza jednostki usługi
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"tenant": "<tenant name/id e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
}
}
Uwierzytelnianie tożsamości zarządzanej przypisanej przez system
Aby dowiedzieć się więcej o tożsamościach zarządzanych dla zasobów platformy Azure, zobacz Tożsamości zarządzane dla zasobów platformy Azure.
Aby użyć uwierzytelniania tożsamości zarządzanej przypisanej przez system, wykonaj następujące kroki, aby udzielić uprawnień:
Pobierz informacje o tożsamości zarządzanej, kopiując wartość identyfikatora obiektu tożsamości zarządzanej wygenerowanego wraz z fabryką lub obszarem roboczym usługi Synapse.
Przyznaj tożsamości zarządzanej prawidłowe uprawnienia w usłudze Azure Data Explorer. Zobacz Zarządzanie uprawnieniami bazy danych usługi Azure Data Explorer, aby uzyskać szczegółowe informacje na temat ról i uprawnień oraz zarządzania uprawnieniami. Ogólnie rzecz biorąc, musisz:
- Jako źródło przyznaj bazie danych rolę podglądu bazy danych.
- Jako ujście przyznaj rolę Ingestor bazy danych i Podgląd bazy danych do bazy danych.
Uwaga
Gdy używasz interfejsu użytkownika do tworzenia, konto użytkownika logowania jest używane do wyświetlania listy klastrów, baz danych i tabel usługi Azure Data Explorer. Wprowadź nazwę ręcznie, jeśli nie masz uprawnień do tych operacji.
Następujące właściwości są obsługiwane dla połączonej usługi Azure Data Explorer:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na AzureDataExplorer. | Tak |
| endpoint | Adres URL punktu końcowego klastra usługi Azure Data Explorer z formatem .https://<clusterName>.<regionName>.kusto.windows.net |
Tak |
| database | Nazwa bazy danych. | Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime, jeśli magazyn danych znajduje się w sieci prywatnej. Jeśli nie zostanie określony, zostanie użyte domyślne środowisko Azure Integration Runtime. | Nie. |
Przykład: używanie uwierzytelniania tożsamości zarządzanej przypisanej przez system
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
}
}
}
Uwierzytelnianie tożsamości zarządzanej przypisanej przez użytkownika
Aby dowiedzieć się więcej o tożsamościach zarządzanych dla zasobów platformy Azure, zobacz Tożsamości zarządzane dla zasobów platformy Azure
Aby użyć uwierzytelniania tożsamości zarządzanej przypisanej przez użytkownika, wykonaj następujące kroki:
Utwórz jedną lub wiele tożsamości zarządzanych przypisanych przez użytkownika i przyznaj uprawnienie w usłudze Azure Data Explorer. Zobacz Zarządzanie uprawnieniami bazy danych usługi Azure Data Explorer, aby uzyskać szczegółowe informacje na temat ról i uprawnień oraz zarządzania uprawnieniami. Ogólnie rzecz biorąc, musisz:
- Jako źródło przyznaj co najmniej rolę podglądu bazy danych bazie danych
- Jako ujście przyznaj co najmniej rolę ingestor bazy danych do bazy danych
Przypisz jedną lub wiele tożsamości zarządzanych przypisanych przez użytkownika do fabryki danych lub obszaru roboczego usługi Synapse i utwórz poświadczenia dla każdej tożsamości zarządzanej przypisanej przez użytkownika.
Następujące właściwości są obsługiwane dla połączonej usługi Azure Data Explorer:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na AzureDataExplorer. | Tak |
| endpoint | Adres URL punktu końcowego klastra usługi Azure Data Explorer z formatem .https://<clusterName>.<regionName>.kusto.windows.net |
Tak |
| database | Nazwa bazy danych. | Tak |
| poświadczenia | Określ tożsamość zarządzaną przypisaną przez użytkownika jako obiekt poświadczeń. | Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime, jeśli magazyn danych znajduje się w sieci prywatnej. Jeśli nie zostanie określony, zostanie użyte domyślne środowisko Azure Integration Runtime. | Nie. |
Przykład: używanie uwierzytelniania tożsamości zarządzanej przypisanej przez użytkownika
{
"name": "AzureDataExplorerLinkedService",
"properties": {
"type": "AzureDataExplorer",
"typeProperties": {
"endpoint": "https://<clusterName>.<regionName>.kusto.windows.net ",
"database": "<database name>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
}
}
}
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz Zestawy danych. W tej sekcji wymieniono właściwości obsługiwane przez zestaw danych usługi Azure Data Explorer.
Aby skopiować dane do usługi Azure Data Explorer, ustaw właściwość type zestawu danych na Wartość AzureDataExplorerTable.
Obsługiwane są następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na AzureDataExplorerTable. | Tak |
| table | Nazwa tabeli, do którego odwołuje się połączona usługa. | Tak dla ujścia; Nie dla źródła |
Przykład właściwości zestawu danych:
{
"name": "AzureDataExplorerDataset",
"properties": {
"type": "AzureDataExplorerTable",
"typeProperties": {
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure Data Explorer linked service name>",
"type": "LinkedServiceReference"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz Potoki i działania. Ta sekcja zawiera listę właściwości, które obsługują źródła i ujścia usługi Azure Data Explorer.
Usługa Azure Data Explorer jako źródło
Aby skopiować dane z usługi Azure Data Explorer, ustaw właściwość type w źródle działanie Kopiuj na wartość AzureDataExplorerSource. Następujące właściwości są obsługiwane w sekcji źródło działania kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na: AzureDataExplorerSource | Tak |
| zapytanie | Żądanie tylko do odczytu podane w formacie KQL. Użyj niestandardowego zapytania KQL jako odwołania. | Tak |
| queryTimeout | Czas oczekiwania przed przekroczeniem limitu czasu żądania zapytania. Wartość domyślna to 10 minut (00:10:00); dozwolona wartość maksymalna to 1 godzina (01:00:00). | Nie. |
| noTruncation | Wskazuje, czy obcinać zwrócony zestaw wyników. Domyślnie wynik jest obcinany po 500 000 rekordów lub 64 megabajtach (MB). Obcięcie jest zdecydowanie zalecane, aby zapewnić prawidłowe zachowanie działania. | Nie. |
Uwaga
Domyślnie źródło usługi Azure Data Explorer ma limit rozmiaru 500 000 rekordów lub 64 MB. Aby pobrać wszystkie rekordy bez obcinania, możesz określić set notruncation; na początku zapytania. Aby uzyskać więcej informacji, zobacz Limity zapytań.
Przykład:
"activities":[
{
"name": "CopyFromAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "AzureDataExplorerSource",
"query": "TestTable1 | take 10",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
},
"inputs": [
{
"referenceName": "<Azure Data Explorer input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
]
}
]
Azure Data Explorer jako ujście
Aby skopiować dane do usługi Azure Data Explorer, ustaw właściwość type w ujściu działania kopiowania na wartość AzureDataExplorerSink. Następujące właściwości są obsługiwane w sekcji ujścia działania kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type ujścia działania kopiowania musi być ustawiona na: AzureDataExplorerSink. | Tak |
| ingestionMappingName | Nazwa wstępnie utworzonego mapowania w tabeli Kusto. Aby zamapować kolumny ze źródła na usługę Azure Data Explorer (która ma zastosowanie do wszystkich obsługiwanych magazynów i formatów źródłowych, w tym formatów CSV/JSON/Avro), możesz użyć mapowania kolumn działania kopiowania (niejawnie według nazwy lub jawnie skonfigurowane) i/lub mapowań usługi Azure Data Explorer. | Nie. |
| additionalProperties | Torba właściwości, która może służyć do określania dowolnych właściwości pozyskiwania, które nie są jeszcze ustawiane przez ujście usługi Azure Data Explorer. W szczególności może być przydatne do określania tagów pozyskiwania. Dowiedz się więcej na temat usługi Azure Data Explore data ingestion doc. | Nie. |
Przykład:
"activities":[
{
"name": "CopyToAzureDataExplorer",
"type": "Copy",
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataExplorerSink",
"ingestionMappingName": "<optional Azure Data Explorer mapping name>",
"additionalProperties": {<additional settings for data ingestion>}
}
},
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Data Explorer output dataset name>",
"type": "DatasetReference"
}
]
}
]
Właściwości przepływu mapowania danych
Podczas przekształcania danych w przepływie mapowania danych można odczytywać dane i zapisywać je w tabelach w usłudze Azure Data Explorer. Aby uzyskać więcej informacji, zobacz przekształcanie źródła i przekształcanie ujścia w przepływach danych mapowania. Możesz użyć zestawu danych usługi Azure Data Explorer lub wbudowanego zestawu danych jako typu źródła i ujścia.
Przekształcanie źródła
W poniższej tabeli wymieniono właściwości obsługiwane przez źródło usługi Azure Data Explorer. Te właściwości można edytować na karcie Opcje źródła.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Table | W przypadku wybrania pozycji Tabela jako danych wejściowych przepływ danych pobierze wszystkie dane z tabeli określonej w zestawie danych usługi Azure Data Explorer lub w opcjach źródłowych podczas korzystania z wbudowanego zestawu danych. | Nie. | String | (tylko w przypadku wbudowanego zestawu danych) tableName |
| Query | Żądanie tylko do odczytu podane w formacie KQL. Użyj niestandardowego zapytania KQL jako odwołania. | Nie. | String | zapytanie |
| Timeout | Czas oczekiwania przed przekroczeniem limitu czasu żądania zapytania. Wartość domyślna to "172000" (2 dni) | Nie. | Integer | timeout |
Przykłady skryptów źródłowych usługi Azure Data Explorer
Jeśli używasz zestawu danych usługi Azure Data Explorer jako typu źródła, skojarzony skrypt przepływu danych to:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'table | take 10',
format: 'query') ~> AzureDataExplorerSource
Jeśli używasz wbudowanego zestawu danych, skojarzony skrypt przepływu danych to:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'table | take 10',
store: 'azuredataexplorer') ~> AzureDataExplorerSource
Przekształcenie ujścia
W poniższej tabeli wymieniono właściwości obsługiwane przez ujście usługi Azure Data Explorer. Te właściwości można edytować na karcie Ustawienia . W przypadku korzystania z wbudowanego zestawu danych zostaną wyświetlone dodatkowe ustawienia, które są takie same jak właściwości opisane w sekcji właściwości zestawu danych.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Akcja tabeli | Określa, czy należy ponownie utworzyć lub usunąć wszystkie wiersze z tabeli docelowej przed zapisem. - Brak: żadna akcja nie zostanie wykonana w tabeli. - Utwórz ponownie: tabela zostanie porzucona i utworzona ponownie. Wymagane w przypadku dynamicznego tworzenia nowej tabeli. - Obcinanie: wszystkie wiersze z tabeli docelowej zostaną usunięte. |
Nie. | true lub false |
odtworzyć truncate |
| Skrypty pre-sql i post | Określ wiele skryptów poleceń sterowania Kusto, które będą wykonywane przed (przetwarzanie wstępne) i po (przetwarzanie końcowe) dane są zapisywane w bazie danych ujścia. | Nie. | String | preSQLs; postSQLs |
| Timeout | Czas oczekiwania przed przekroczeniem limitu czasu żądania zapytania. Wartość domyślna to "172000" (2 dni) | Nie. | Integer | timeout |
Przykłady skryptów ujścia usługi Azure Data Explorer
Jeśli używasz zestawu danych usługi Azure Data Explorer jako typu ujścia, skojarzony skrypt przepływu danych to:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
preSQLs:['pre SQL scripts'],
postSQLs:['post SQL script'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Jeśli używasz wbudowanego zestawu danych, skojarzony skrypt przepływu danych to:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
store: 'azuredataexplorer',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureDataExplorerSink
Właściwości działania wyszukiwania
Aby uzyskać więcej informacji na temat właściwości, zobacz Działanie wyszukiwania.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych przez działanie kopiowania jako źródła i ujścia, zobacz obsługiwane magazyny danych.
Dowiedz się więcej na temat kopiowania danych z usług Azure Data Factory i Synapse Analytics do usługi Azure Data Explorer.