Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Ten łącznik może być używany w analizie czasu rzeczywistego w usłudze Microsoft Fabric. Skorzystaj z instrukcji w tym artykule z następującymi wyjątkami:
- W razie potrzeby utwórz bazy danych, korzystając z instrukcji w temacie Tworzenie bazy danych KQL.
- W razie potrzeby utwórz tabele, korzystając z instrukcji w temacie Tworzenie pustej tabeli.
- Pobierz identyfikatory URI zapytań lub pozyskiwania, korzystając z instrukcji w temacie Copy URI (Kopiowanie identyfikatora URI).
- Uruchamianie zapytań w zestawie zapytań języka KQL.
Azure Data Explorer to szybka, w pełni zarządzana usługa analizy danych. Oferuje ona analizę w czasie rzeczywistym na dużych ilościach danych przesyłanych strumieniowo z wielu źródeł, takich jak aplikacje, witryny internetowe i urządzenia IoT. Usługa Azure Data Explorer umożliwia iteracyjne eksplorowanie danych oraz identyfikowanie wzorców i anomalii w celu ulepszania produktów, ulepszania środowisk klientów, monitorowania urządzeń i zwiększania operacji. Ułatwia to eksplorowanie nowych pytań i uzyskiwanie odpowiedzi w ciągu kilku minut.
Azure Data Factory to w pełni zarządzana, oparta na chmurze usługa integracji danych. Można jej użyć do wypełnienia bazy danych usługi Azure Data Explorer danymi z istniejącego systemu. Może to pomóc zaoszczędzić czas podczas tworzenia rozwiązań analitycznych.
Podczas ładowania danych do usługi Azure Data Explorer usługa Data Factory zapewnia następujące korzyści:
- Łatwa konfiguracja: uzyskaj intuicyjny, pięcioetapowy kreator bez konieczności obsługi skryptów.
- Obsługa rozbudowanego magazynu danych: uzyskaj wbudowaną obsługę zaawansowanego zestawu lokalnych i opartych na chmurze magazynów danych. Aby uzyskać szczegółową listę, zobacz tabelę Obsługiwanych magazynów danych.
- Bezpieczne i zgodne: dane są przesyłane za pośrednictwem protokołu HTTPS lub usługi Azure ExpressRoute. Obecność usługi globalnej gwarantuje, że dane nigdy nie opuszczają granicy geograficznej.
- Wysoka wydajność: Szybkość ładowania danych wynosi do 1 gigabajta na sekundę (GBps) w usłudze Azure Data Explorer. Aby uzyskać więcej informacji, zobacz działanie Kopiuj wydajność.
W tym artykule użyjesz narzędzia do kopiowania danych usługi Data Factory, aby załadować dane z usługi Amazon Simple Storage Service (S3) do usługi Azure Data Explorer. Możesz wykonać podobny proces, aby skopiować dane z innych magazynów danych, takich jak:
- Azure Blob Storage
- Azure SQL Database
- Azure SQL Data Warehouse
- Google BigQuery
- Wyrocznia
- System plików
Wymagania wstępne
- Subskrypcja platformy Azure. Utwórz bezpłatne konto platformy Azure.
- Baza danych i klaster usługi Azure Data Explorer. Utwórz klaster i bazę danych.
- Źródło danych.
Tworzenie fabryki danych
Zaloguj się w witrynie Azure Portal.
W okienku po lewej stronie wybierz pozycję Utwórz fabrykę danych analizy> zasobów.>

W okienku Nowa fabryka danych podaj wartości pól w poniższej tabeli:
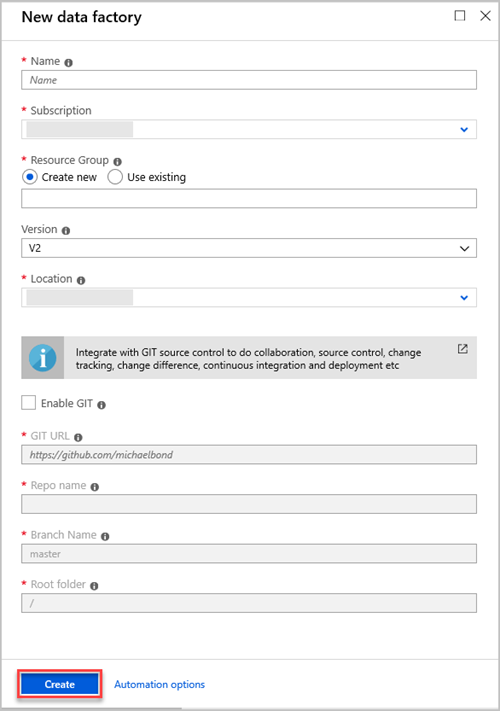
Ustawienie Wartość do wprowadzenia Nazwa/nazwisko W polu wprowadź globalnie unikatową nazwę fabryki danych. Jeśli wystąpi błąd, nazwa fabryki danych "LoadADXDemo" jest niedostępna, wprowadź inną nazwę fabryki danych. Aby uzyskać reguły nazewnictwa artefaktów usługi Data Factory, zobacz Reguły nazewnictwa usługi Data Factory. Subskrypcja Z listy rozwijanej wybierz subskrypcję platformy Azure, w której ma zostać utworzona fabryka danych. Grupa zasobów Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę nowej grupy zasobów. Jeśli masz już grupę zasobów, wybierz pozycję Użyj istniejącej. Wersja Na liście rozwijanej wybierz pozycję V2. Lokalizacja Z listy rozwijanej wybierz lokalizację fabryki danych. Na liście są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych używane przez fabrykę danych mogą istnieć w innych lokalizacjach lub regionach. Wybierz pozycję Utwórz.
Aby monitorować proces tworzenia, wybierz pozycję Powiadomienia na pasku narzędzi. Po utworzeniu fabryki danych wybierz ją.
Zostanie otwarte okienko Fabryka danych .
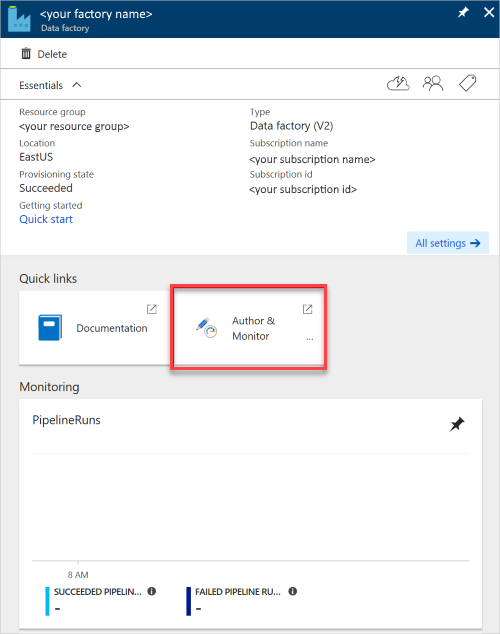
Aby otworzyć aplikację w osobnym okienku, wybierz kafelek Tworzenie i monitorowanie .
Ładowanie danych do usługi Azure Data Explorer
Dane można załadować z wielu typów magazynów danych do usługi Azure Data Explorer. W tym artykule omówiono sposób ładowania danych z usługi Amazon S3.
Dane można załadować na jeden z następujących sposobów:
- W interfejsie użytkownika usługi Azure Data Factory w okienku po lewej stronie wybierz ikonę Autor . Jest to wyświetlane w sekcji "Tworzenie fabryki danych" w sekcji Tworzenie fabryki danych przy użyciu interfejsu użytkownika usługi Azure Data Factory.
- W narzędziu do kopiowania danych usługi Azure Data Factory, jak pokazano w artykule Używanie narzędzia do kopiowania danych do kopiowania danych.
Kopiowanie danych z usługi Amazon S3 (źródło)
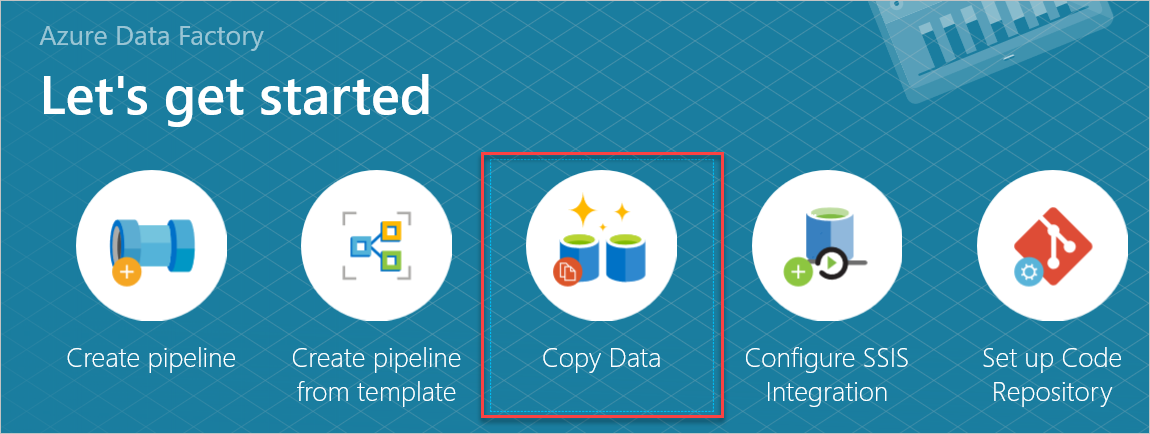
W okienku Rozpocznij pracę otwórz narzędzie Do kopiowania danych, wybierając pozycję Kopiuj dane.
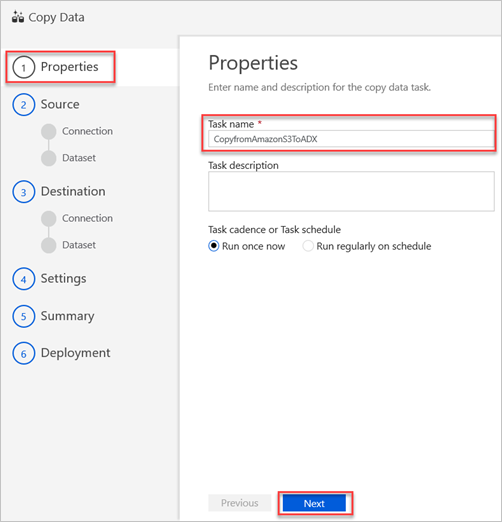
W okienku Właściwości w polu Nazwa zadania wprowadź nazwę, a następnie wybierz przycisk Dalej.
W okienku Źródłowy magazyn danych wybierz pozycję Utwórz nowe połączenie.
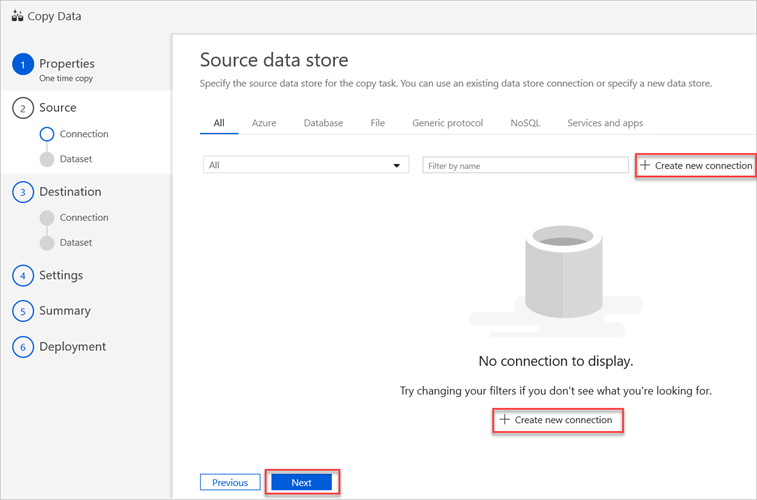
Wybierz pozycję Amazon S3, a następnie wybierz pozycję Kontynuuj.
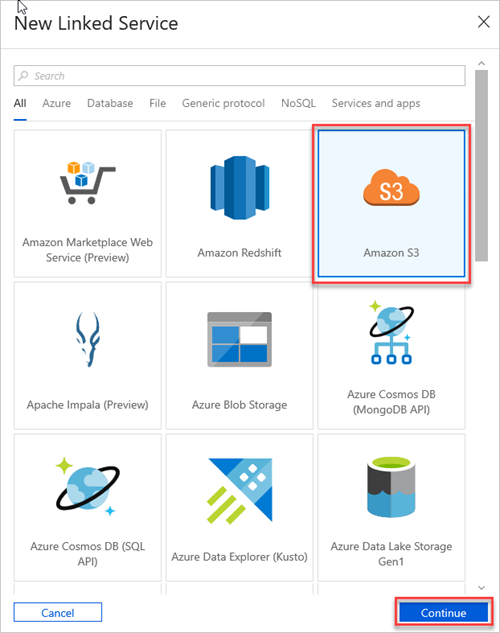
W okienku Nowa połączona usługa (Amazon S3) wykonaj następujące czynności:
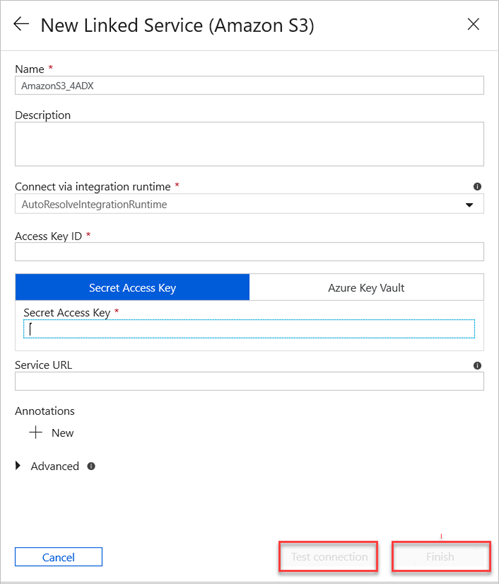
a. W polu Nazwa wprowadź nazwę nowej połączonej usługi.
b. Z listy rozwijanej Połącz za pomocą środowiska Integration Runtime wybierz wartość.
c. W polu Identyfikator klucza dostępu wprowadź wartość.
Uwaga
W usłudze Amazon S3, aby zlokalizować klucz dostępu, wybierz swoją nazwę użytkownika Amazon na pasku nawigacyjnym, a następnie wybierz pozycję Moje poświadczenia zabezpieczeń.
d. W polu Klucz dostępu tajnego wprowadź wartość.
e. Aby przetestować utworzone połączenie połączonej usługi, wybierz pozycję Testuj połączenie.
f. Wybierz Zakończ.
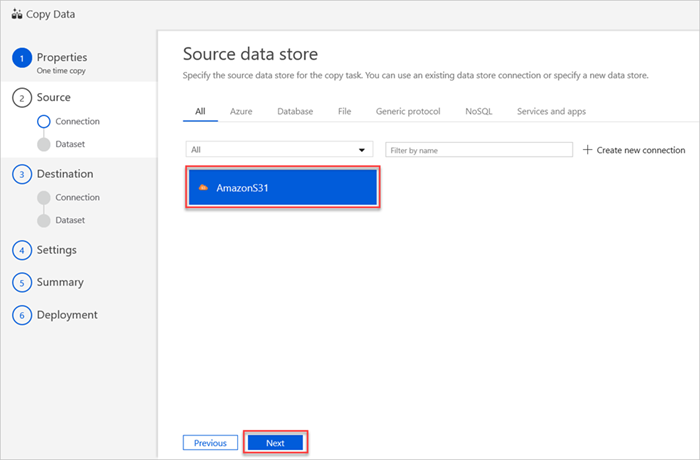
W okienku Źródłowy magazyn danych zostanie wyświetlone nowe połączenie AmazonS31.
Wybierz Dalej.
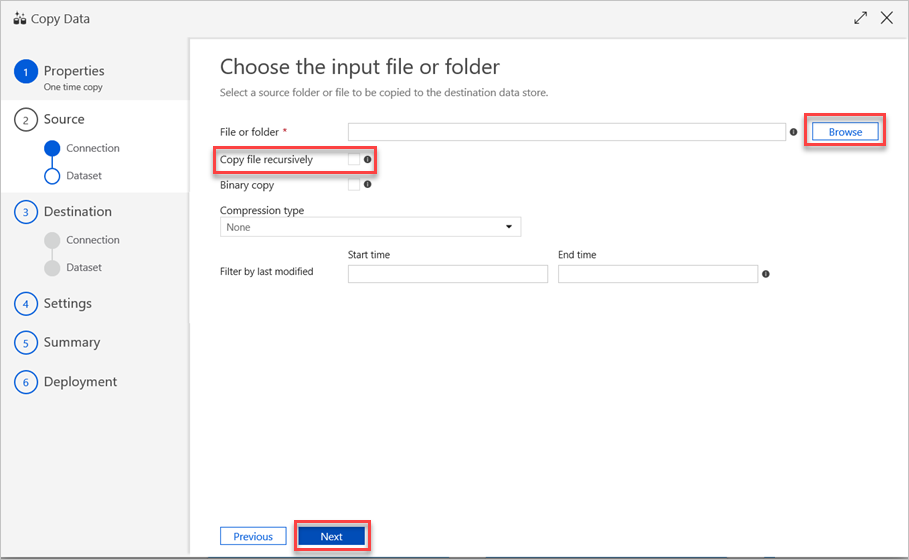
W okienku Wybierz plik wejściowy lub folder wykonaj następujące czynności:
a. Przejdź do pliku lub folderu, który chcesz skopiować, a następnie wybierz go.
b. Wybierz żądane zachowanie kopiowania. Upewnij się, że pole wyboru Kopia binarna zostało wyczyszczone.
c. Wybierz Dalej.
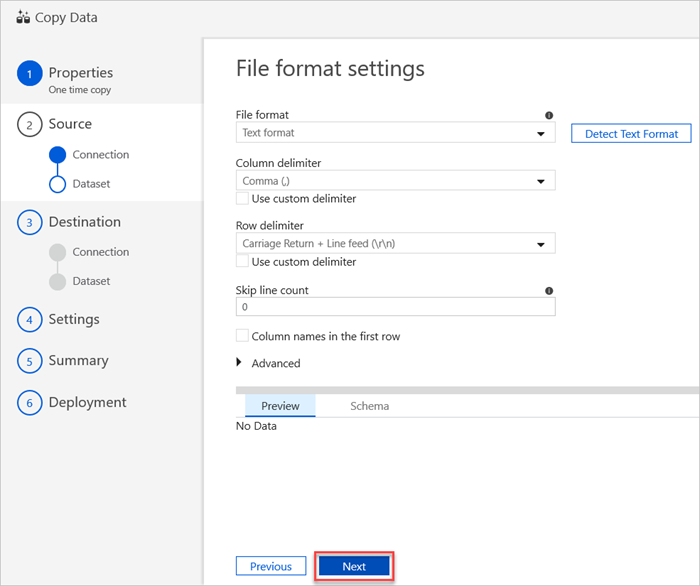
W okienku Ustawienia formatu pliku wybierz odpowiednie ustawienia pliku. Następnie wybierz pozycję Dalej.
Kopiowanie danych do usługi Azure Data Explorer (miejsce docelowe)
Nowa połączona usługa Azure Data Explorer jest tworzona w celu skopiowania danych do tabeli docelowej (ujścia) usługi Azure Data Explorer określonej w tej sekcji.
Uwaga
Użyj działania polecenia usługi Azure Data Factory, aby uruchomić polecenia zarządzania usługi Azure Data Explorer i użyć dowolnego pozyskiwania z poleceń zapytań, takich jak .set-or-replace.
Tworzenie połączonej usługi Azure Data Explorer
Aby utworzyć połączoną usługę Azure Data Explorer, wykonaj następujące czynności:
Aby użyć istniejącego połączenia magazynu danych lub określić nowy magazyn danych, w okienku Docelowy magazyn danych wybierz pozycję Utwórz nowe połączenie.
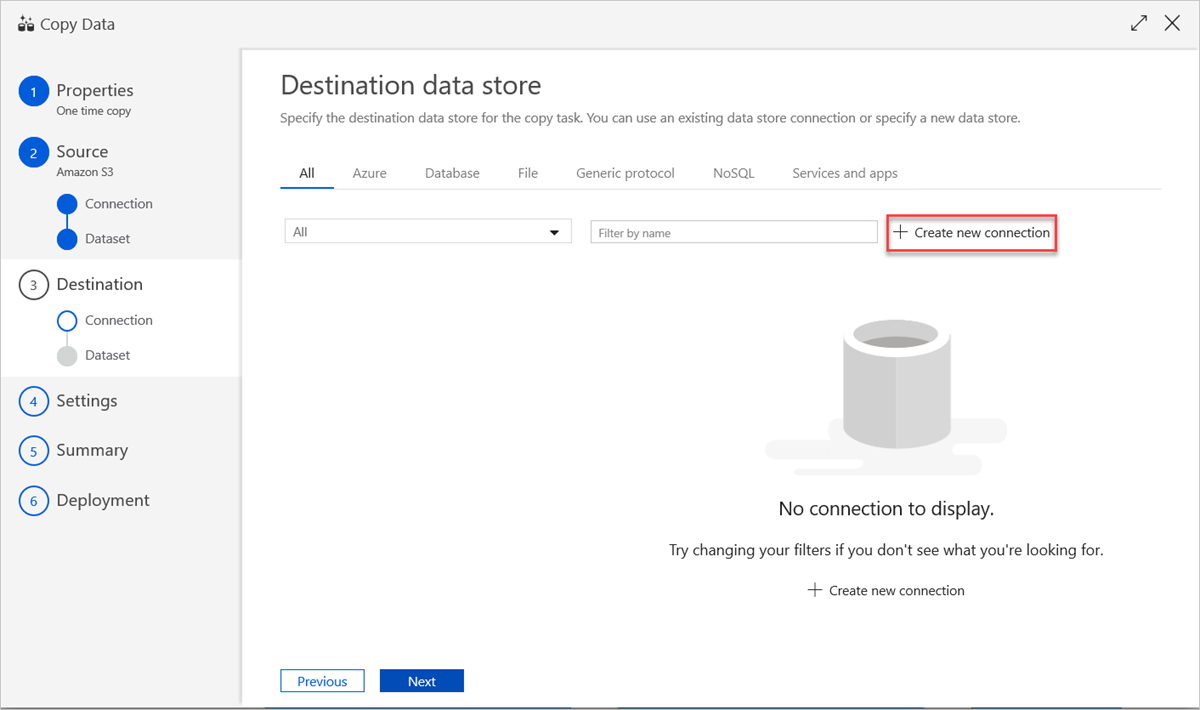
W okienku Nowa połączona usługa wybierz pozycję Azure Data Explorer, a następnie wybierz pozycję Kontynuuj.

W okienku Nowa połączona usługa (Azure Data Explorer) wykonaj następujące czynności:
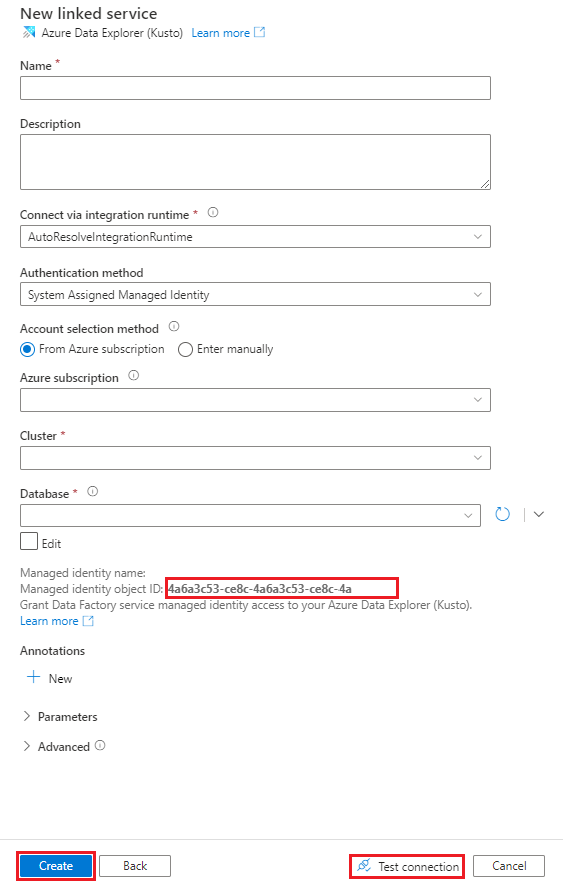
W polu Nazwa wprowadź nazwę połączonej usługi Azure Data Explorer.
W obszarze Metoda uwierzytelniania wybierz pozycję Tożsamość zarządzana przypisana przez system lub jednostka usługi.
Aby uwierzytelnić się przy użyciu tożsamości zarządzanej, przyznaj tożsamości zarządzanej dostęp do bazy danych przy użyciu nazwy tożsamości zarządzanej lub identyfikatora obiektu tożsamości zarządzanej.
Aby uwierzytelnić się przy użyciu jednostki usługi:
- W polu Dzierżawa wprowadź nazwę dzierżawy.
- W polu Identyfikator jednostki usługi wprowadź identyfikator jednostki usługi.
- Wybierz pozycję Klucz jednostki usługi, a następnie w polu Klucz jednostki usługi wprowadź wartość klucza.
Uwaga
- Jednostka usługi jest używana przez usługę Azure Data Factory do uzyskiwania dostępu do usługi Azure Data Explorer. Aby utworzyć jednostkę usługi, przejdź do sekcji Tworzenie jednostki usługi Microsoft Entra.
- Aby przypisać uprawnienia do tożsamości zarządzanej lub jednostki usługi lub , zobacz Zarządzanie uprawnieniami.
- Nie używaj metody usługi Azure Key Vault ani tożsamości zarządzanej przypisanej przez użytkownika.
W obszarze Metoda wyboru konta wybierz jedną z następujących opcji:
Wybierz Z subskrypcji Azure, a następnie na liście rozwijanej wybierz swoją subskrypcję Azure i klaster.
Uwaga
- Kontrolka listy rozwijanej Klaster zawiera tylko klastry skojarzone z subskrypcją.
- Klaster musi mieć odpowiednią jednostkę SKU w celu uzyskania najlepszej wydajności.
Wybierz pozycję Wprowadź ręcznie, a następnie wprowadź punkt końcowy.
Z listy rozwijanej Baza danych wybierz nazwę bazy danych. Alternatywnie zaznacz pole wyboru Edytuj , a następnie wprowadź nazwę bazy danych.
Aby przetestować utworzone połączenie połączonej usługi, wybierz pozycję Testuj połączenie. Jeśli możesz nawiązać połączenie z połączoną usługą, w okienku zostanie wyświetlony zielony znacznik wyboru i komunikat Połączenie zakończyło się pomyślnie .
Wybierz pozycję Utwórz , aby ukończyć tworzenie połączonej usługi.
Konfigurowanie połączenia danych usługi Azure Data Explorer
Po utworzeniu połączonego połączenia z usługą zostanie otwarte okienko Docelowy magazyn danych, a utworzone połączenie będzie dostępne do użycia. Aby skonfigurować połączenie, wykonaj następujące czynności:
Wybierz Dalej.
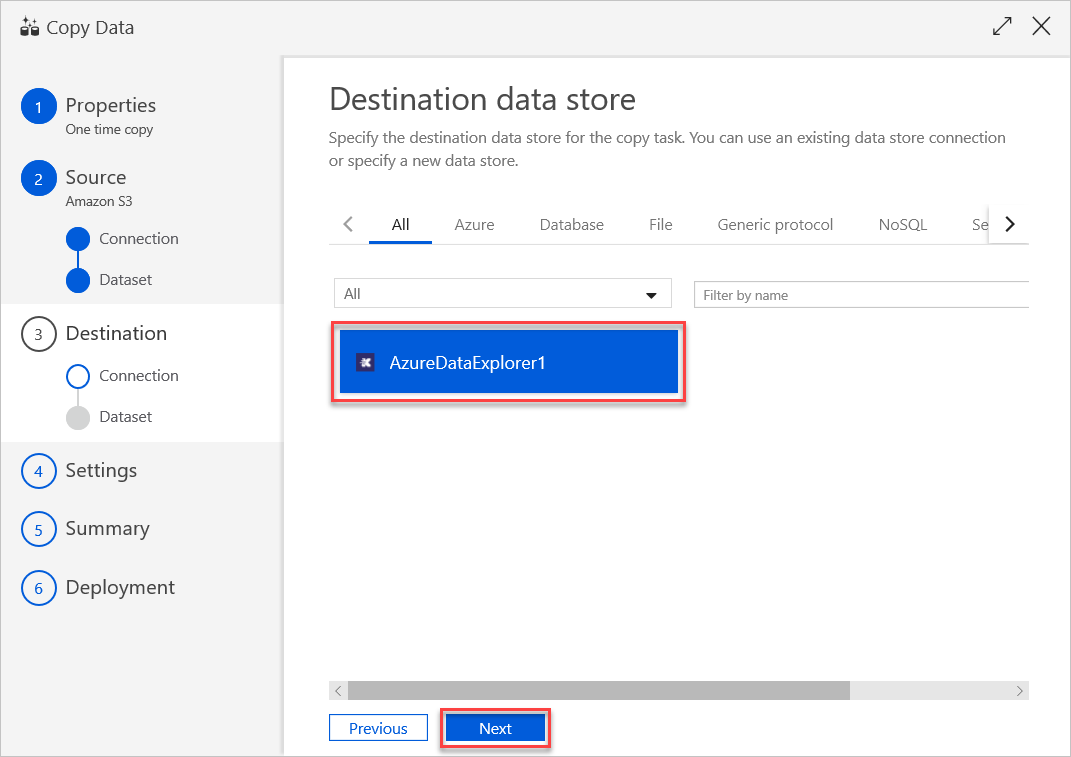
W okienku Mapowanie tabeli ustaw nazwę tabeli docelowej, a następnie wybierz pozycję Dalej.
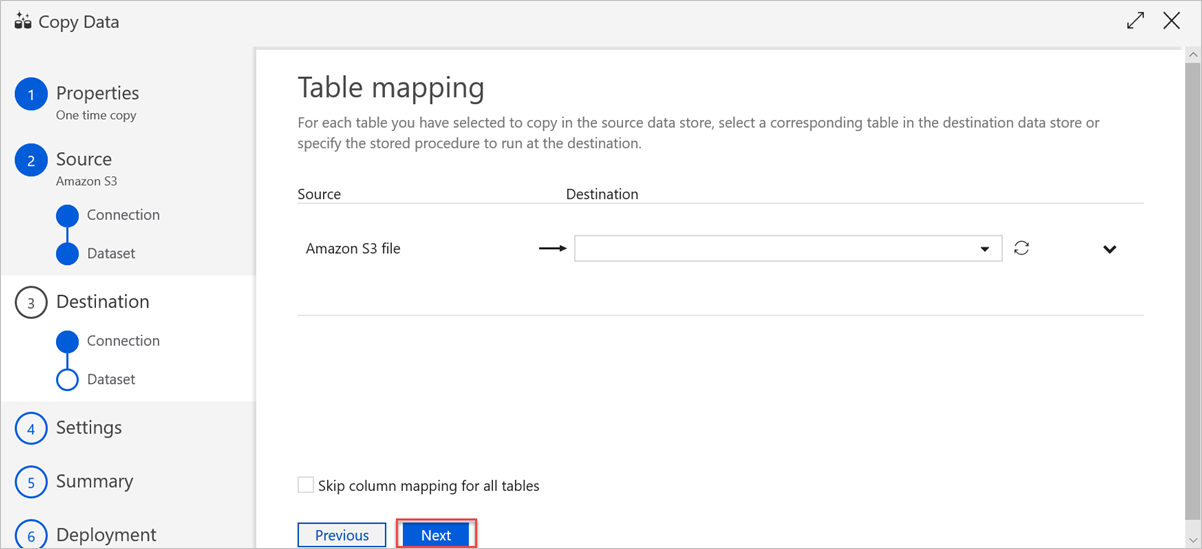
W okienku Mapowanie kolumn mają miejsce następujące mapowania:
a. Pierwsze mapowanie jest wykonywane przez usługę Azure Data Factory zgodnie z mapowaniem schematu usługi Azure Data Factory. Należy wykonać następujące czynności:
Ustaw mapowania kolumn dla tabeli docelowej usługi Azure Data Factory. Domyślne mapowanie jest wyświetlane ze źródła do tabeli docelowej usługi Azure Data Factory.
Anuluj wybór kolumn, których nie trzeba definiować.
b. Drugie mapowanie występuje, gdy te dane tabelaryczne są pozyskiwane do usługi Azure Data Explorer. Mapowanie jest wykonywane zgodnie z regułami mapowania woluminów CSV. Nawet jeśli dane źródłowe nie mają formatu CSV, usługa Azure Data Factory konwertuje dane na format tabelaryczny. Dlatego mapowanie woluminów CSV jest jedynym odpowiednim mapowaniem na tym etapie. Należy wykonać następujące czynności:
(Opcjonalnie) W obszarze Właściwości ujścia usługi Azure Data Explorer (Kusto) dodaj odpowiednią nazwę mapowania pozyskiwania, aby można było użyć mapowania kolumn.
Jeśli nazwa mapowania pozyskiwania nie jest określona, zostanie użyta kolejność mapowania według nazw zdefiniowana w sekcji Mapowania kolumn. Jeśli mapowanie według nazw nie powiedzie się, usługa Azure Data Explorer próbuje pozyskać dane w kolejności położenia według kolumny (czyli mapowania według pozycji domyślnej).
Wybierz Dalej.
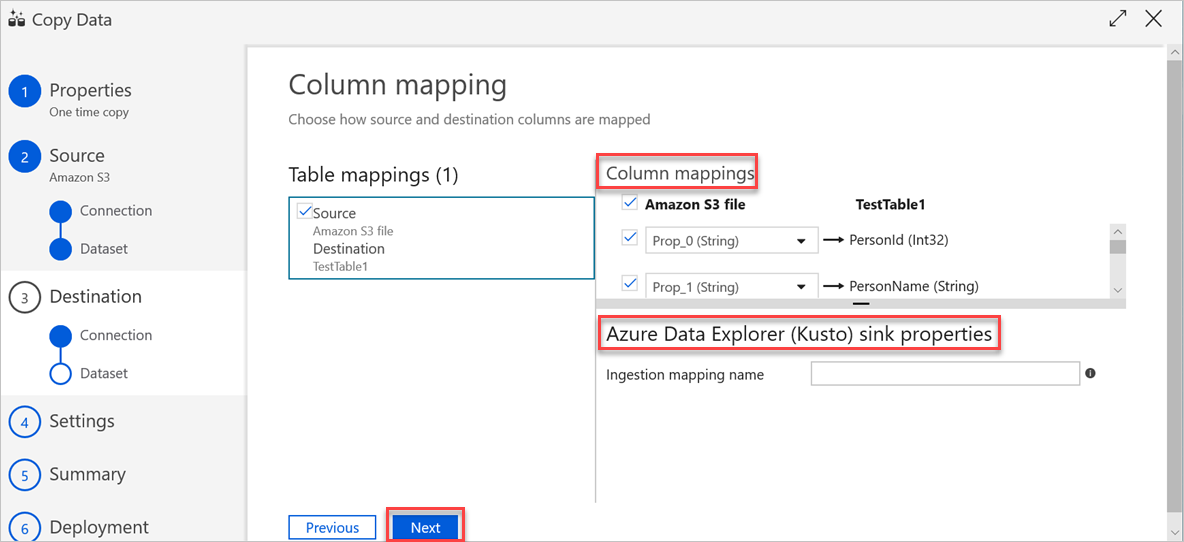
W okienku Ustawienia wykonaj następujące czynności:
a. W obszarze Ustawienia odporności na uszkodzenia wprowadź odpowiednie ustawienia.
b. W obszarze Ustawienia wydajności opcja Włącz przemieszczanie nie ma zastosowania, a ustawienia zaawansowane obejmują zagadnienia dotyczące kosztów. Jeśli nie masz określonych wymagań, pozostaw te ustawienia w następujący sposób.
c. Wybierz Dalej.
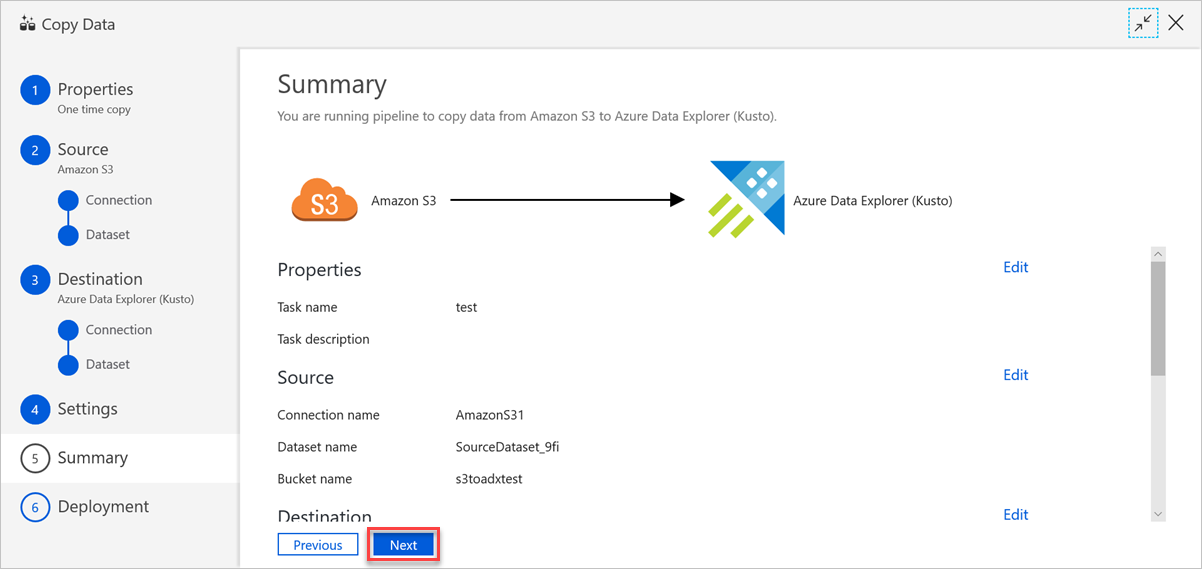
W okienku Podsumowanie przejrzyj ustawienia, a następnie wybierz pozycję Dalej.
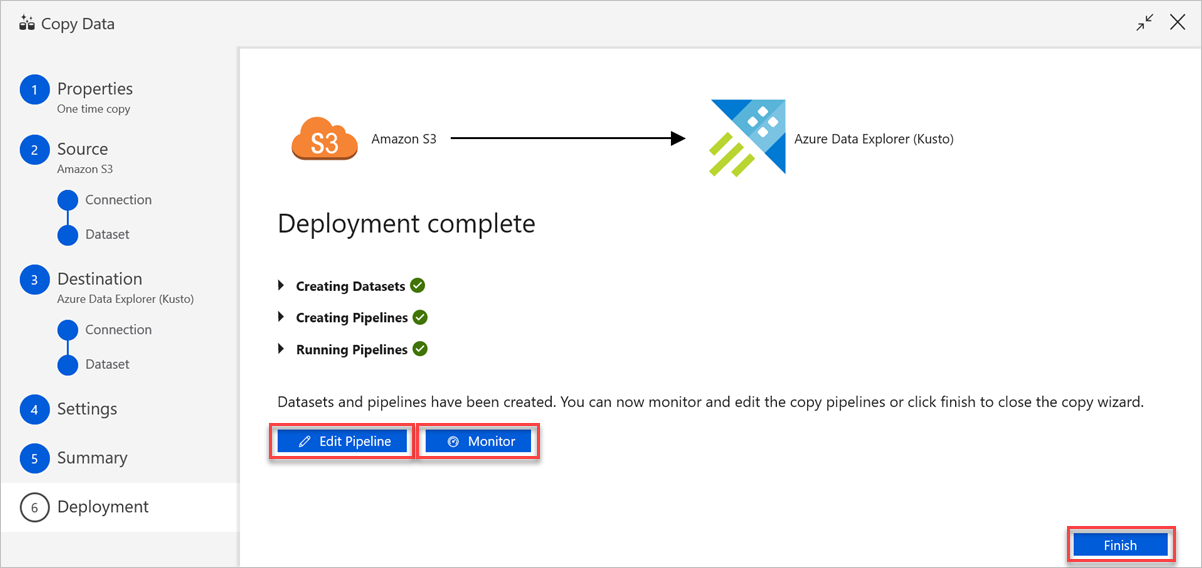
W okienku Ukończenie wdrażania wykonaj następujące czynności:
a. Aby przełączyć się na kartę Monitor i wyświetlić stan potoku (czyli postęp, błędy i przepływ danych), wybierz pozycję Monitoruj.
b. Aby edytować połączone usługi, zestawy danych i potoki, wybierz pozycję Edytuj potok.
c. Wybierz pozycję Zakończ , aby ukończyć zadanie kopiowania danych.
Powiązana zawartość
- Dowiedz się więcej o łączniku usługi Azure Data Explorer dla usługi Azure Data Factory.
- Edytowanie połączonych usług, zestawów danych i potoków w interfejsie użytkownika usługi Data Factory.
- Wykonywanie zapytań dotyczących danych w internetowym interfejsie użytkownika usługi Azure Data Explorer.