Kopiowanie danych z platformy SAP HANA przy użyciu usługi Azure Data Factory lub Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób używania działania kopiowania w potokach usługi Azure Data Factory i usługi Synapse Analytics do kopiowania danych z bazy danych SAP HANA. Jest on oparty na artykule omówienie działania kopiowania, który przedstawia ogólne omówienie działania kopiowania.
Napiwek
Aby dowiedzieć się więcej o ogólnej obsłudze scenariusza integracji danych SAP, zobacz oficjalny dokument dotyczący integracji danych SAP ze szczegółowym wprowadzeniem do każdego łącznika SAP, porównania i wskazówek.
Obsługiwane możliwości
Ten łącznik SAP HANA jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/ujście) | (2) |
| Działanie Lookup | (2) |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Aby uzyskać listę magazynów danych obsługiwanych jako źródła/ujścia przez działanie kopiowania, zobacz tabelę Obsługiwane magazyny danych.
W szczególności ten łącznik SAP HANA obsługuje następujące elementy:
- Kopiowanie danych z dowolnej wersji bazy danych SAP HANA.
- Kopiowanie danych z modeli informacji platformy HANA (takich jak widoki analityczne i obliczeniowe) i tabel wierszy/kolumn.
- Kopiowanie danych przy użyciu uwierzytelniania podstawowego lub windows .
- Równoległe kopiowanie ze źródła sap HANA. Aby uzyskać szczegółowe informacje, zobacz sekcję Kopiowanie równoległe z platformy SAP HANA .
Napiwek
Aby skopiować dane do magazynu danych SAP HANA, użyj ogólnego łącznika ODBC. Zobacz sekcję ujścia platformy SAP HANA ze szczegółowymi informacjami. Zwróć uwagę, że połączone usługi dla łącznika SAP HANA i łącznika ODBC mają inny typ, dlatego nie można ich ponownie użyć.
Wymagania wstępne
Aby użyć tego łącznika SAP HANA, należy wykonać następujące czynności:
- Skonfiguruj własne środowisko Integration Runtime. Aby uzyskać szczegółowe informacje, zobacz artykuł Self-hosted Integration Runtime (Self-hosted Integration Runtime ).
- Zainstaluj sterownik ODBC platformy SAP HANA na maszynie Integration Runtime. Sterownik SAP HANA ODBC można pobrać z Centrum pobierania oprogramowania SAP. Wyszukaj za pomocą słowa kluczowego SAP HANA CLIENT for Windows.
Wprowadzenie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi z platformą SAP HANA przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę z platformą SAP HANA w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie kliknij pozycję Nowy:
Wyszukaj pozycję SAP i wybierz łącznik SAP HANA.

Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
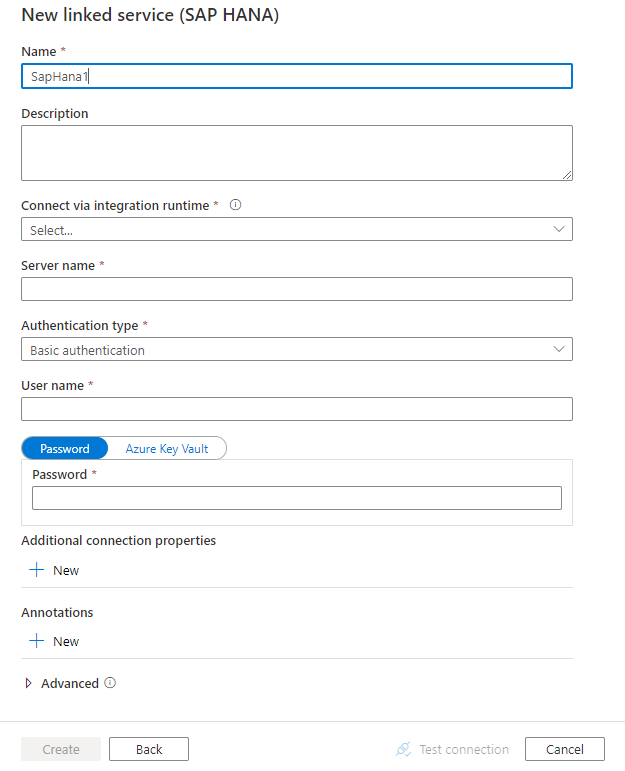
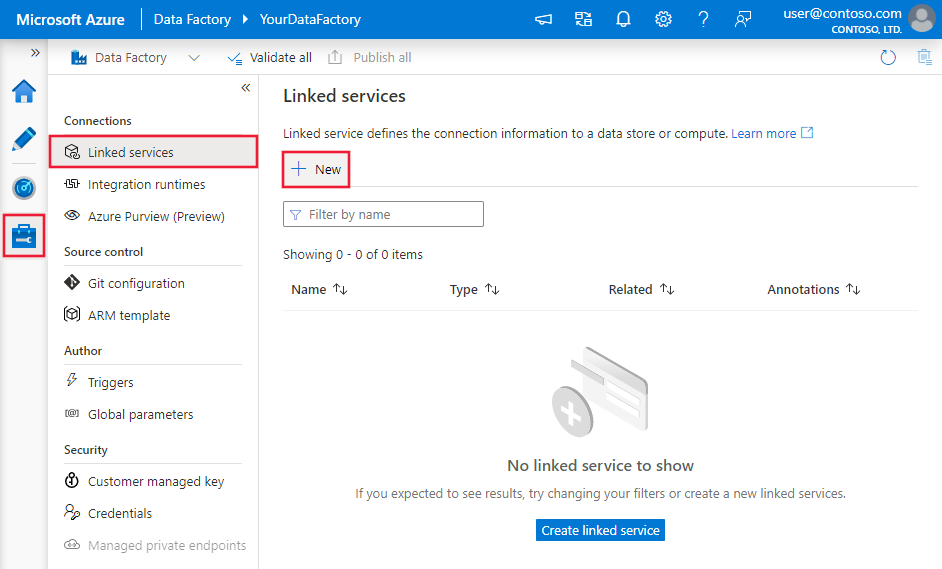
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla łącznika SAP HANA.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane w przypadku połączonej usługi SAP HANA:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na: SapHana | Tak |
| Parametry połączenia | Określ informacje potrzebne do nawiązania połączenia z platformą SAP HANA przy użyciu uwierzytelniania podstawowego lub uwierzytelniania systemu Windows. Zapoznaj się z poniższymi przykładami. W parametry połączenia serwer/port jest obowiązkowy (domyślny port to 30015), a nazwa użytkownika i hasło są obowiązkowe podczas korzystania z uwierzytelniania podstawowego. Aby uzyskać dodatkowe ustawienia zaawansowane, zobacz Właściwości połączenia ODBC platformy SAP HANA Możesz również umieścić hasło w usłudze Azure Key Vault i ściągnąć konfigurację hasła z parametry połączenia. Zapoznaj się z artykułem Przechowywanie poświadczeń w usłudze Azure Key Vault , aby uzyskać więcej szczegółów. |
Tak |
| userName | Określ nazwę użytkownika podczas korzystania z uwierzytelniania systemu Windows. Przykład: user@domain.com |
Nie. |
| hasło | Określ hasło dla konta użytkownika. Oznacz to pole jako element SecureString w celu bezpiecznego przechowywania go lub odwołuj się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. | Nie. |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Środowisko Integration Runtime (Self-hosted) jest wymagane zgodnie z wymaganiami wstępnymi. | Tak |
Przykład: użyj uwierzytelniania podstawowego
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;UID=<userName>;PWD=<Password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Przykład: używanie uwierzytelniania systemu Windows
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Jeśli używasz połączonej usługi SAP HANA z następującym ładunkiem, nadal jest ona obsługiwana zgodnie z rzeczywistym użyciem, podczas gdy zaleca się korzystanie z nowej usługi w przyszłości.
Przykład:
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"server": "<server>:<port (optional)>",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Pełna lista sekcji i właściwości dostępnych do definiowania zestawów danych znajduje się w artykule dotyczącym zestawów danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych SAP HANA.
Aby skopiować dane z platformy SAP HANA, obsługiwane są następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na: SapHanaTable | Tak |
| schema | Nazwa schematu w bazie danych SAP HANA. | Nie (jeśli określono "zapytanie" w źródle działania) |
| table | Nazwa tabeli w bazie danych SAP HANA. | Nie (jeśli określono "zapytanie" w źródle działania) |
Przykład:
{
"name": "SAPHANADataset",
"properties": {
"type": "SapHanaTable",
"typeProperties": {
"schema": "<schema name>",
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<SAP HANA linked service name>",
"type": "LinkedServiceReference"
}
}
}
Jeśli używasz RelationalTable wpisanego zestawu danych, nadal jest on obsługiwany w stanie rzeczywistym, podczas gdy zaleca się korzystanie z nowego zestawu danych w przyszłości.
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło sap HANA.
OPROGRAMOWANIE SAP HANA jako źródło
Napiwek
Aby efektywnie pozyskiwać dane z platformy SAP HANA przy użyciu partycjonowania danych, dowiedz się więcej w sekcji Kopiowanie równoległe z platformy SAP HANA .
Aby skopiować dane z platformy SAP HANA, w sekcji źródła działania kopiowania są obsługiwane następujące właściwości:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na: SapHanaSource | Tak |
| zapytanie | Określa zapytanie SQL do odczytu danych z wystąpienia sap HANA. | Tak |
| partitionOptions | Określa opcje partycjonowania danych używane do pozyskiwania danych z platformy SAP HANA. Dowiedz się więcej z sekcji Kopiowanie równoległe z platformy SAP HANA . Dozwolone wartości to: Brak (wartość domyślna), PhysicalPartitionsOfTable, SapHanaDynamicRange. Dowiedz się więcej z sekcji Kopiowanie równoległe z platformy SAP HANA . PhysicalPartitionsOfTable Można go używać tylko podczas kopiowania danych z tabeli, ale nie do wykonywania zapytań. Jeśli opcja partycji jest włączona (czyli nie None), stopień równoległości równoczesnego ładowania danych z platformy SAP HANA jest kontrolowany przez parallelCopies ustawienie działania kopiowania. |
Fałszywy |
| partitionSettings | Określ grupę ustawień partycjonowania danych. Zastosuj, gdy opcja partycji to SapHanaDynamicRange. |
Fałszywy |
| partitionColumnName | Określ nazwę kolumny źródłowej, która będzie używana przez partycję do kopiowania równoległego. Jeśli nie zostanie określony, indeks lub klucz podstawowy tabeli zostanie automatycznie wykryty i użyty jako kolumna partycji. Zastosuj, gdy opcja partycji to SapHanaDynamicRange. Jeśli używasz zapytania do pobierania danych źródłowych, podłącz element w ?AdfHanaDynamicRangePartitionCondition klauzuli WHERE. Zobacz przykład w sekcji Kopiowanie równoległe z platformy SAP HANA . |
Tak w przypadku korzystania z SapHanaDynamicRange partycji. |
| packetSize | Określa rozmiar pakietu sieciowego (w kilobajtach), aby podzielić dane na wiele bloków. Jeśli masz dużą ilość danych do skopiowania, zwiększenie rozmiaru pakietu może zwiększyć szybkość odczytu z platformy SAP HANA w większości przypadków. Testy wydajnościowe są zalecane podczas dostosowywania rozmiaru pakietu. | L.p. Wartość domyślna to 2048 (2 MB). |
Przykład:
"activities":[
{
"name": "CopyFromSAPHANA",
"type": "Copy",
"inputs": [
{
"referenceName": "<SAP HANA input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SapHanaSource",
"query": "<SQL query for SAP HANA>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Jeśli używasz RelationalSource źródła kopii wpisanej, nadal jest obsługiwana zgodnie z rzeczywistym użyciem, podczas gdy zaleca się użycie nowego źródła.
Kopiowanie równoległe z platformy SAP HANA
Łącznik SAP HANA zapewnia wbudowane partycjonowanie danych w celu równoległego kopiowania danych z platformy SAP HANA. Opcje partycjonowania danych można znaleźć w tabeli Źródłowe działania kopiowania.
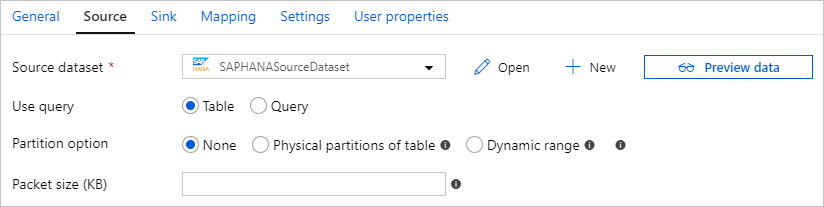
Po włączeniu kopii partycjonowanej usługa uruchamia zapytania równoległe względem źródła SAP HANA w celu pobrania danych według partycji. Stopień równoległy jest kontrolowany przez parallelCopies ustawienie działania kopiowania. Jeśli na przykład ustawiono parallelCopies wartość cztery, usługa jednocześnie generuje i uruchamia cztery zapytania na podstawie określonej opcji partycji i ustawień, a każde zapytanie pobiera część danych z platformy SAP HANA.
Zaleca się włączenie kopiowania równoległego przy użyciu partycjonowania danych, szczególnie w przypadku pozyskiwania dużej ilości danych z platformy SAP HANA. Poniżej przedstawiono sugerowane konfiguracje dla różnych scenariuszy. Podczas kopiowania danych do magazynu danych opartego na plikach zaleca się zapisywanie w folderze jako wielu plików (tylko określ nazwę folderu), w tym przypadku wydajność jest lepsza niż zapisywanie w jednym pliku.
| Scenariusz | Sugerowane ustawienia |
|---|---|
| Pełne ładowanie z dużej tabeli. | Opcja partycji: fizyczne partycje tabeli. Podczas wykonywania usługa automatycznie wykrywa typ partycji fizycznej określonej tabeli SAP HANA i wybiera odpowiednią strategię partycji: - Partycjonowanie zakresu: pobierz kolumnę partycji i zakresy partycji zdefiniowane dla tabeli, a następnie skopiuj dane według zakresu. - Partycjonowanie skrótów: użyj klucza partycji skrótu jako kolumny partycji, a następnie partycjonuj i skopiuj dane na podstawie zakresów obliczanych przez usługę. - Partycjonowanie okrężne lub brak partycji: użyj klucza podstawowego jako kolumny partycji, a następnie podziel na partycję i skopiuj dane na podstawie zakresów obliczanych przez usługę. |
| Załaduj dużą ilość danych przy użyciu zapytania niestandardowego. | Opcja partycji: partycja zakresu dynamicznego. Zapytanie: SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>.Kolumna partycji: określ kolumnę używaną do stosowania partycji zakresu dynamicznego. Podczas wykonywania usługa najpierw oblicza zakresy wartości określonej kolumny partycji, równomiernie rozkładając wiersze w wielu zasobnikach zgodnie z liczbą unikatowych wartości kolumn partycji ustawieniem kopiowania równoległego, a następnie zastępuje ?AdfHanaDynamicRangePartitionCondition filtrem zakres wartości kolumn partycji dla każdej partycji i wysyła do platformy SAP HANA.Jeśli chcesz użyć wielu kolumn jako kolumny partycji, możesz połączyć wartości każdej kolumny jako jedną kolumnę w zapytaniu i określić ją jako kolumnę partycji, taką jak SELECT * FROM (SELECT *, CONCAT(<KeyColumn1>, <KeyColumn2>) AS PARTITIONCOLUMN FROM <TABLENAME>) WHERE ?AdfHanaDynamicRangePartitionCondition. |
Przykład: zapytanie z partycjami fizycznymi tabeli
"source": {
"type": "SapHanaSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Przykład: zapytanie z partycją zakresu dynamicznego
"source": {
"type": "SapHanaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "SapHanaDynamicRange",
"partitionSettings": {
"partitionColumnName": "<Partition_column_name>"
}
}
Mapowanie typów danych dla platformy SAP HANA
Podczas kopiowania danych z platformy SAP HANA następujące mapowania są używane z typów danych SAP HANA do tymczasowych typów danych używanych wewnętrznie w usłudze. Zobacz Mapowania schematu i typu danych, aby dowiedzieć się, jak działanie kopiowania mapuje schemat źródłowy i typ danych na ujście.
| Typ danych SAP HANA | Typ danych usługi tymczasowej |
|---|---|
| ALFANUM | String |
| BIGINT | Int64 |
| DWÓJKOWY | Bajt[] |
| BINTEXT | String |
| BLOB | Bajt[] |
| BOOL | Byte |
| CLOB | String |
| DATE | DateTime |
| DZIESIĘTNY | Dziesiętne |
| PODWÓJNY | Liczba rzeczywista |
| SPŁAWIK | Liczba rzeczywista |
| LICZBA CAŁKOWITA | Int32 |
| NCLOB | String |
| NVARCHAR | String |
| PRAWDZIWY | Pojedynczy |
| DRUGI IDENTYFIKATOR | DateTime |
| KRÓTKI TEKST | String |
| SMALLDECIMAL | Dziesiętne |
| SMALLINT | Int16 |
| TYP STGEOMETRYTYPE | Bajt[] |
| TYP PUNKTU STPOINT | Bajt[] |
| TEKST | String |
| TIME | przedział_czasu |
| TINYINT | Byte |
| VARCHAR | String |
| TIMESTAMP | DateTime |
| VARBINARY | Bajt[] |
Ujście sap HANA
Obecnie łącznik SAP HANA nie jest obsługiwany jako ujście, podczas gdy można użyć ogólnego łącznika ODBC ze sterownikiem SAP HANA do zapisywania danych na platformie SAP HANA.
Postępuj zgodnie z wymaganiami wstępnymi , aby skonfigurować własne środowisko Integration Runtime i najpierw zainstalować sterownik SAP HANA ODBC. Utwórz połączoną usługę ODBC, aby nawiązać połączenie z magazynem danych SAP HANA, jak pokazano w poniższym przykładzie, a następnie odpowiednio utworzyć zestaw danych i ujścia działania kopiowania z typem ODBC. Dowiedz się więcej z artykułu o łączniku ODBC.
{
"name": "SAPHANAViaODBCLinkedService",
"properties": {
"type": "Odbc",
"typeProperties": {
"connectionString": "Driver={HDBODBC};servernode=<HANA server>.clouddatahub-int.net:30015",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz obsługiwane magazyny danych.