Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia usługi ADF można uaktualnić do Fabric, aby uzyskać dostęp do nowych funkcji w nauce o danych, analizie w czasie rzeczywistym i raportowaniu.
W tym artykule opisano sposób kopiowania danych do i z usługi delta lake przechowywanej w usłudze Azure Data Lake Store Gen2 lub Azure Blob Storage przy użyciu formatu różnicowego. Ten łącznik jest dostępny jako wbudowany zestaw danych w przepływach mapowania danych zarówno jako źródło, jak i ujście.
Właściwości przepływu mapowania danych
Ten łącznik jest dostępny jako wbudowany zestaw danych w przepływach mapowania danych zarówno jako źródło, jak i ujście.
Właściwości źródła
W poniższej tabeli wymieniono właściwości obsługiwane przez źródło różnicowe. Te właściwości można edytować na karcie Opcje źródła.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Formatuj | Format musi być następujący: delta |
tak | delta |
format |
| System plików | Kontener/system plików usługi delta lake | tak | String | fileSystem |
| Ścieżka do folderu | Katalog usługi delta lake | tak | String | folderPath |
| Typ kompresji | Typ kompresji tabeli delty | nie | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Poziom kompresji | Określ, czy kompresja zostanie ukończona tak szybko, jak to możliwe, czy też plik wynikowy powinien być optymalnie skompresowany. | wymagane, jeśli compressedType jest określony. |
Optimal lub Fastest |
compressionLevel |
| Podróż czasowa | Wybierz, czy wykonać zapytanie względem starszej migawki tabeli delty | nie | Zapytanie według sygnatury czasowej: sygnatura czasowa Zapytanie według wersji: liczba całkowita |
timestampAsOf versionAsOf |
| Zezwalaj na brak znalezionych plików | Jeśli wartość true, błąd nie jest zgłaszany, jeśli nie znaleziono żadnych plików | nie |
true lub false |
ignoreNoFilesFound |
Importowanie schematu
Funkcja Delta jest dostępna tylko jako wbudowany zestaw danych i domyślnie nie ma skojarzonego schematu. Aby uzyskać metadane kolumny, kliknij przycisk Importuj schemat na karcie Projekcja . Dzięki temu można odwoływać się do nazw kolumn i typów danych określonych przez korpus. Aby zaimportować schemat, sesja debugowania przepływu danych musi być aktywna i musisz mieć istniejący plik definicji jednostki CDM, aby wskazać.
Przykład skryptu źródła różnicowego
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
Właściwości ujścia
W poniższej tabeli wymieniono właściwości obsługiwane przez ujście różnicowe. Te właściwości można edytować na karcie Ustawienia .
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Formatuj | Format musi być następujący: delta |
tak | delta |
format |
| System plików | Kontener/system plików usługi delta lake | tak | String | fileSystem |
| Ścieżka do folderu | Katalog usługi delta lake | tak | String | folderPath |
| Typ kompresji | Typ kompresji tabeli delty | nie | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Poziom kompresji | Określ, czy kompresja zostanie ukończona tak szybko, jak to możliwe, czy też plik wynikowy powinien być optymalnie skompresowany. | wymagane, jeśli compressedType jest określony. |
Optimal lub Fastest |
compressionLevel |
| Vacuum | Usuwa pliki starsze niż określony czas trwania, który nie jest już istotny dla bieżącej wersji tabeli. Gdy zostanie określona wartość 0 lub mniejsza, operacja próżniowa nie jest wykonywana. | tak | Integer | próżnia |
| Akcja tabeli | Informuje usługę ADF, co należy zrobić z docelową tabelą delty w ujściu. Możesz pozostawić je w stanie rzeczywistym i dołączyć nowe wiersze, zastąpić istniejącą definicję tabeli i dane nowymi metadanymi i danymi albo zachować istniejącą strukturę tabeli, ale najpierw obcinać wszystkie wiersze, a następnie wstawiać nowe wiersze. | nie | Brak, Obcinanie, Zastępowanie | deltaTruncate, zastąp |
| Metoda aktualizacji | Po wybraniu opcji "Zezwalaj na wstawianie" lub zapisie w nowej tabeli delty obiekt docelowy odbiera wszystkie wiersze przychodzące niezależnie od zestawu zasad wierszy. Jeśli dane zawierają wiersze innych zasad wierszy, należy je wykluczyć przy użyciu poprzedniego przekształcenia filtru. Po wybraniu wszystkich metod aktualizacji jest wykonywane scalanie, w którym wiersze są wstawiane/usuwane/upserted/aktualizowane zgodnie z zasadami wierszy ustawionymi przy użyciu poprzedniego przekształcenia Alter Row. |
tak |
true lub false |
możliwość wstawienia możliwe do usunięcia upsertable możliwe do aktualizacji |
| Zoptymalizowany zapis | Osiągnij większą przepływność operacji zapisu dzięki optymalizacji wewnętrznego mieszania w funkcjach wykonawczych platformy Spark. W związku z tym można zauważyć mniej partycji i plików o większym rozmiarze | nie |
true lub false |
optymalizowaneZapisy: prawda |
| Autokompaktuj | Po zakończeniu każdej operacji zapisu platforma Spark automatycznie wykona OPTIMIZE polecenie w celu ponownego zorganizowania danych, co w razie potrzeby spowoduje zwiększenie wydajności odczytu w przyszłości większej liczby partycji |
nie |
true lub false |
autoKompakt: prawda |
Przykład skryptu ujścia różnicowego
Skojarzony skrypt przepływu danych to:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
Ujście różnicowe z oczyszczaniem partycji
Za pomocą tej opcji w obszarze Metoda aktualizacji powyżej (tj. update/upsert/delete) można ograniczyć liczbę sprawdzanych partycji. Tylko partycje spełniające ten warunek są pobierane z magazynu docelowego. Można określić stały zestaw wartości, które może przyjmować kolumna partycji.
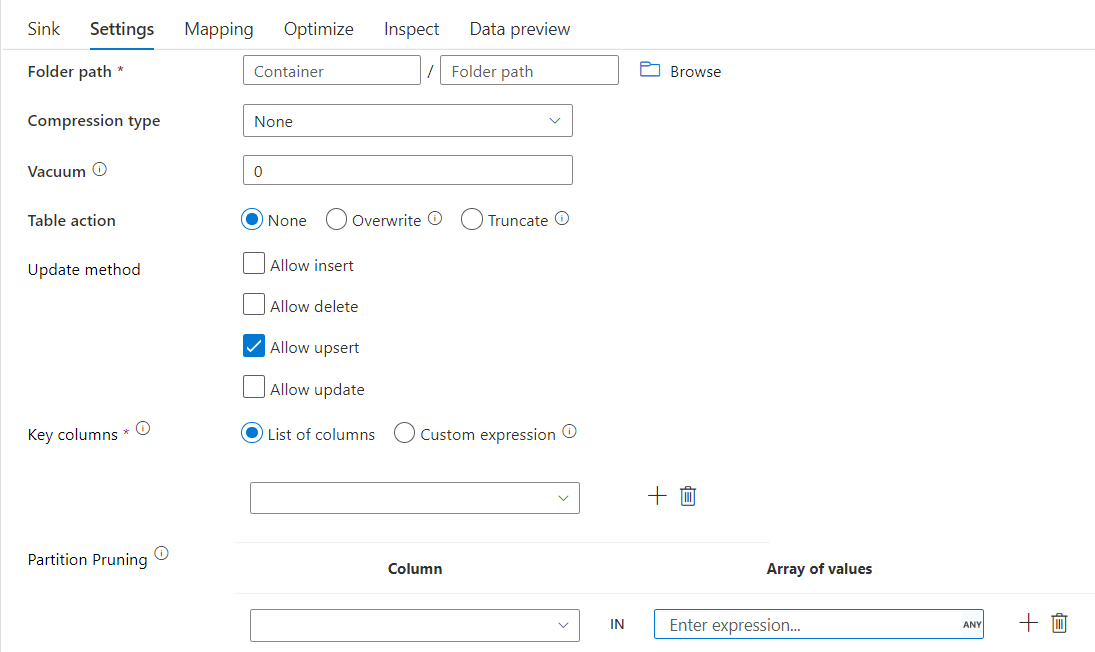
Przykładowy skrypt ujścia różnicowego z oczyszczaniem partycji
Przykładowy skrypt jest podawany w następujący sposób.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Funkcja Delta odczytuje tylko 2 partycje, w których part_col == 5 i 8 z docelowego magazynu różnicowego zamiast wszystkich partycji. part_col to kolumna, przez którą są partycjonowane docelowe dane różnicowe. Nie musi być obecny w danych źródłowych.
Opcje optymalizacji ujścia różnicowego
Na karcie Ustawienia znajdziesz trzy kolejne opcje optymalizacji przekształcenia ujścia różnicowego.
Gdy opcja Scal schemat jest włączona, umożliwia ewolucję schematu , tj. wszystkie kolumny, które znajdują się w bieżącym strumieniu przychodzącym, ale nie w docelowej tabeli delty, są automatycznie dodawane do jego schematu. Ta opcja jest obsługiwana we wszystkich metodach aktualizacji.
Po włączeniu automatycznego kompaktowania po pojedynczym zapisie transformacja sprawdza, czy pliki mogą być dodatkowo kompaktowane, i uruchamia szybkie zadanie OPTYMALIZACJI (z rozmiarami plików 128 MB zamiast 1 GB) w celu dalszego kompaktowania plików dla partycji, które mają największą liczbę małych plików. Automatyczne kompaktowanie ułatwia łączenie dużej liczby małych plików w mniejszą liczbę dużych plików. Automatyczne kompaktowanie jest uruchamiane tylko wtedy, gdy istnieje co najmniej 50 plików. Po wykonaniu operacji kompaktowania tworzy nową wersję tabeli i zapisuje nowy plik zawierający dane kilku poprzednich plików w kompaktowym skompresowanym formularzu.
Po włączeniu optymalizacji zapisu transformacja ujścia dynamicznie optymalizuje rozmiary partycji na podstawie rzeczywistych danych, próbując zapisać 128 MB plików dla każdej partycji tabeli. Jest to przybliżony rozmiar i może się różnić w zależności od właściwości zestawu danych. Zoptymalizowane zapisy zwiększają ogólną wydajność operacji zapisu i kolejnych operacji odczytu. Organizuje partycje tak, aby wydajność kolejnych operacji odczytu poprawiła się.
Napiwek
Zoptymalizowany proces zapisu spowolni ogólne zadanie ETL, ponieważ ujście wyda polecenie Spark Delta Lake Optimize po przetworzeniu danych. Zaleca się oszczędne używanie zoptymalizowanego zapisu. Jeśli na przykład masz potok danych godzinowych, wykonaj przepływ danych z zoptymalizowanym zapisem dziennym.
Znane ograniczenia
Podczas zapisywania w ujściu różnicowym istnieje znane ograniczenie, w którym liczba zapisanych wierszy nie będzie wyświetlana w danych wyjściowych monitorowania.
Powiązana zawartość
- Utwórz przekształcenie źródła w przepływie danych mapowania.
- Utwórz przekształcenie ujścia w przepływie danych mapowania.
- Utwórz przekształcenie alter row, aby oznaczyć wiersze jako wstawianie, aktualizowanie, upsert lub usuwanie.