Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Skalowanie automatyczne bazy danych Lakebase znajduje się w wersji beta w następujących regionach: eastus2, westeurope, westus.
Autoskalowanie bazy danych Lakebase to najnowsza wersja bazy danych Lakebase z automatycznym skalowaniem obliczeniowym, skalowaniem do zera, rozgałęzianiem i natychmiastowym przywracaniem. Aby porównać funkcje z zarezerwowaną wersją Lakebase, zobacz wybór pomiędzy wersjami.
Funkcja Reverse ETL w usłudze Lakebase synchronizuje tabele Unity Catalog z bazą danych Postgres, dzięki czemu aplikacje mogą bezpośrednio używać danych wyselekcjonowanych w ramach lakehouse. Usługa Lakehouse jest zoptymalizowana pod kątem analizy i wzbogacania, podczas gdy usługa Lakebase została zaprojektowana pod kątem obciążeń operacyjnych wymagających szybkich zapytań i spójności transakcyjnej.
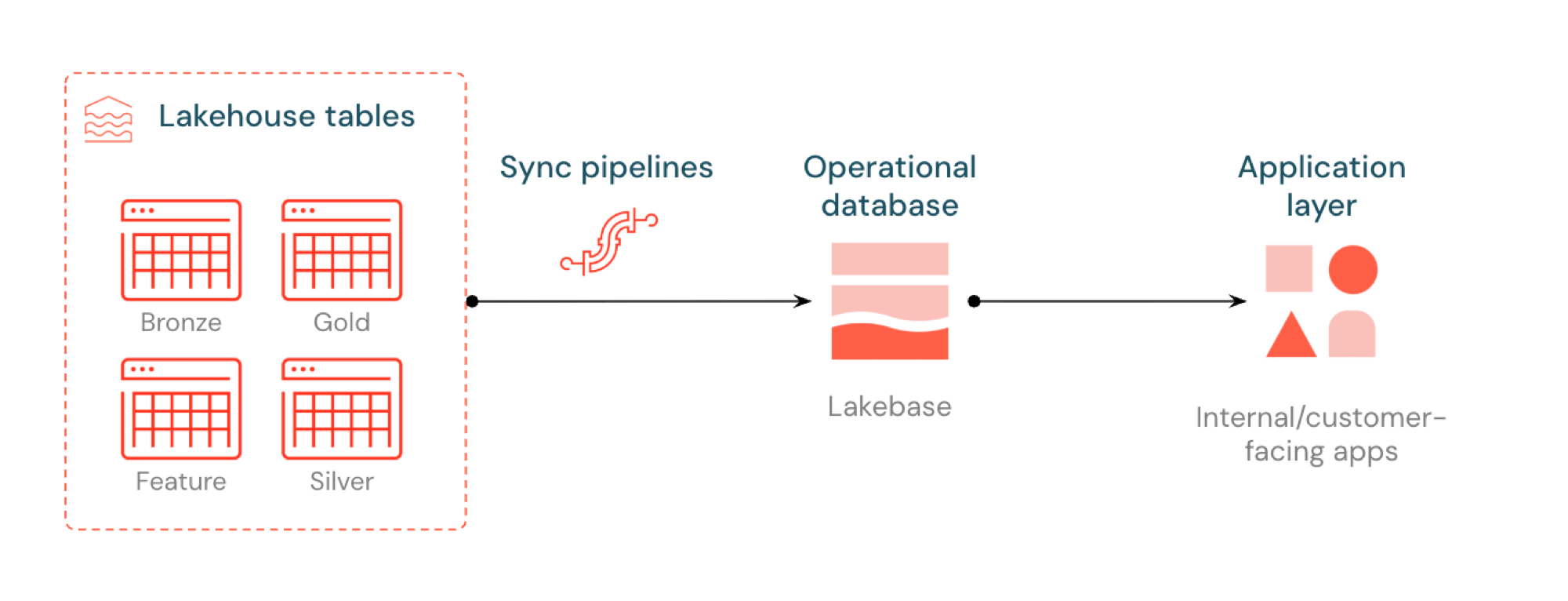
Co to jest odwrotna funkcja ETL?
Funkcja Reverse ETL umożliwia przenoszenie danych o jakości analitycznej z katalogu Unity do bazy danych Lakebase Postgres, gdzie można udostępnić je aplikacjom wymagającym zapytań o niskich opóźnieniach (poniżej 10ms) i pełnych transakcji ACID. Pozwala ona wypełnić lukę między magazynem analitycznym a systemami operacyjnymi, utrzymując wyselekcjonowane dane użyteczne w aplikacjach czasu rzeczywistego.
Jak to działa
Zsynchronizowane tabele usługi Databricks tworzą zarządzaną kopię danych Unity Catalog w Lakebase. Podczas tworzenia zsynchronizowanej tabeli uzyskujesz:
- Nowa tabela katalogu Unity (tylko do odczytu, zarządzana przez pipeline synchronizacji)
- Tabela Postgres w usłudze Lakebase (z możliwością wykonywania zapytań przez aplikacje)
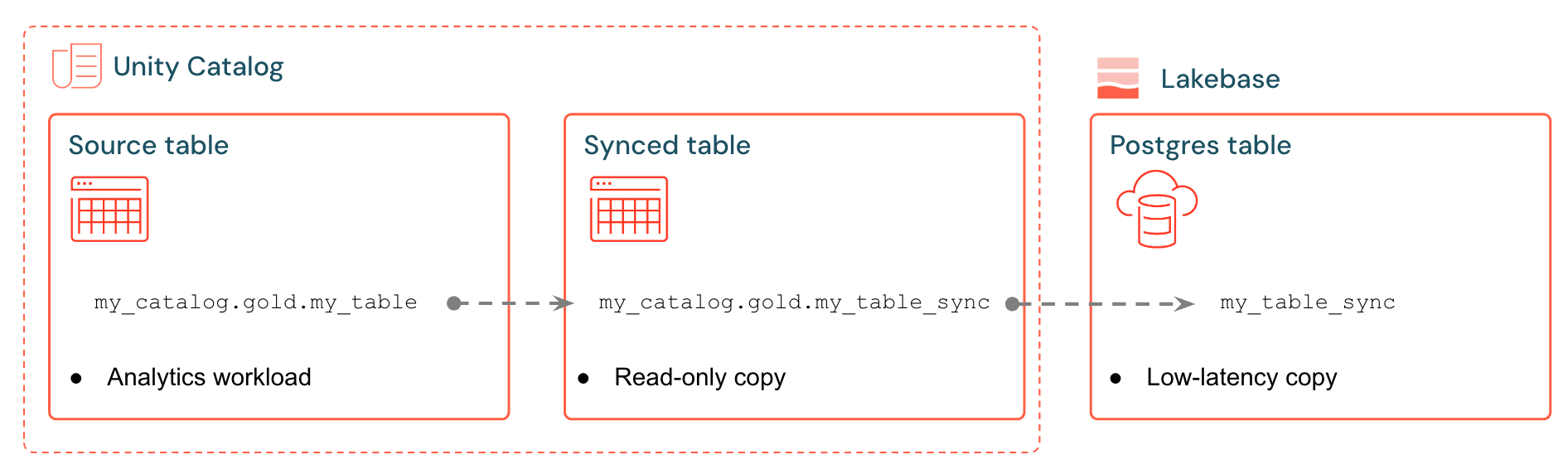
Na przykład można synchronizować złote tabele, funkcje inżynieryjne lub dane wyjściowe uczenia maszynowego z analytics.gold.user_profiles do nowej zsynchronizowanej tabeli analytics.gold.user_profiles_synced. W przypadku bazy danych Postgres nazwa schematu Unity Catalog staje się nazwą schematu Postgres, tak więc pojawia się jako "gold"."user_profiles_synced":
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
Aplikacje łączą się ze standardowymi sterownikami Postgres i wykonują zapytania o zsynchronizowane dane wraz z własnym stanem operacyjnym.
Potoki synchronizacji używają zarządzanych deklaratywnych potoków Lakeflow Spark, aby stale aktualizować zarówno tabelę zsynchronizowaną w katalogu Unity, jak i tabelę Postgres wraz z zmianami w tabeli źródłowej. Każda synchronizacja może używać maksymalnie 16 połączeń z bazą danych Lakebase.
Baza danych Lakebase Postgres obsługuje maksymalnie 1000 równoczesnych połączeń z gwarancjami transakcyjnymi, dzięki czemu aplikacje mogą odczytywać wzbogacone dane, a jednocześnie obsługiwać operacje wstawiania, aktualizacji i usuwania w tej samej bazie danych.
Tryby synchronizacji
Wybierz odpowiedni tryb synchronizacji na podstawie potrzeb aplikacji:
| Mode | Description | Najlepsze dla | Performance |
|---|---|---|---|
| Snapshot | Jednorazowa kopia wszystkich danych | Początkowa konfiguracja lub analiza historyczna | 10x wydajniejsze w przypadku modyfikowania >10% danych źródłowych |
| Wywołany | Zaplanowane aktualizacje uruchamiane na żądanie lub w odstępach czasu | Pulpity nawigacyjne, aktualizowane co godzinę/codziennie | Dobra równowaga między kosztami a opóźnieniami. Kosztowny w przypadku uruchamiania w 5-minutowych interwałach |
| Ciągły | Przesyłanie strumieniowe w czasie rzeczywistym z sekundami opóźnienia | Aplikacje na żywo (wyższe koszty z powodu dedykowanych obliczeń) | Najniższe opóźnienie, najwyższy koszt. Minimalna 15-sekundowa liczba interwałów |
Tryby inicjowane i ciągłe wymagają włączenia śledzenia zmian danych (CDF) w tabeli źródłowej. Jeśli usługa CDF nie jest włączona, w interfejsie użytkownika zostanie wyświetlone ostrzeżenie z dokładnym ALTER TABLE poleceniem do uruchomienia. Aby uzyskać więcej informacji na temat strumienia zmian danych, zobacz Używanie strumienia zmian danych Delta Lake w usłudze Databricks.
Przykładowe przypadki użycia
Odwrócone ETL w Lakebase obsługuje typowe scenariusze operacyjne.
- Silniki personalizacji, które wymagają zsynchronizowania świeżych profili użytkowników do Databricks Apps
- Aplikacje obsługujące przewidywania modelu lub wartości cech obliczone w lakehouse
- Pulpity dedykowane klientom, które wyświetlają KPI w czasie rzeczywistym
- Usługi wykrywania oszustw, które wymagają oceny ryzyka dostępne w celu natychmiastowego działania
- Narzędzia wspierające wzbogacające rekordy klientów o wyselekcjonowane dane z lakehouse'u
Tworzenie zsynchronizowanej tabeli (UI)
Zsynchronizowane tabele można tworzyć w interfejsie użytkownika usługi Databricks lub programowo za pomocą zestawu SDK. Przepływ pracy interfejsu użytkownika został opisany poniżej.
Wymagania wstępne
Potrzebujesz:
- Obszar roboczy usługi Databricks z włączoną usługą Lakebase.
- Projekt Lakebase (zobacz Tworzenie projektu).
- Tabela Unity Catalog z wyselekcjonowanymi danymi.
- Uprawnienia do tworzenia zsynchronizowanych tabel.
Aby uzyskać informacje na temat planowania pojemności i zgodności typów danych, zobacz Typy danych i zgodność oraz Planowanie pojemności.
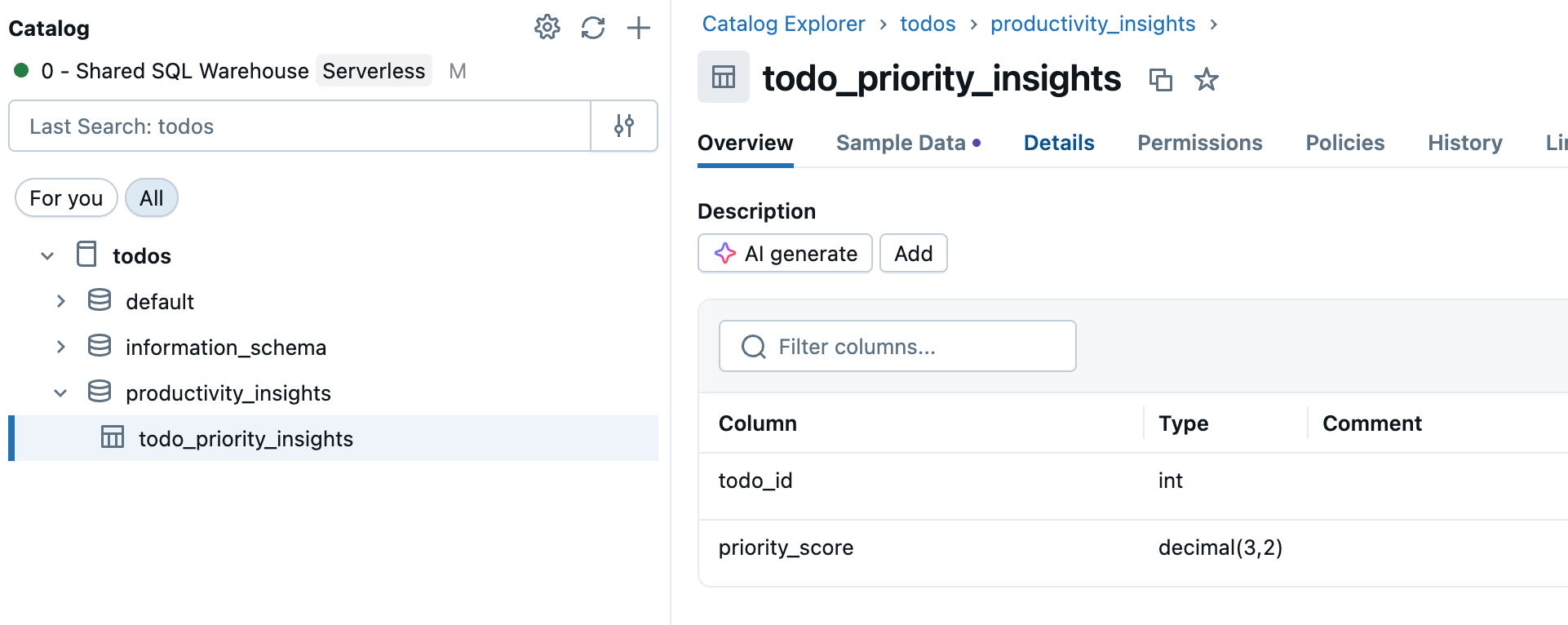
Krok 1. Wybieranie tabeli źródłowej
Przejdź do Catalog na pasku bocznym obszaru roboczego i wybierz tabelę Unity Catalog, którą chcesz zsynchronizować.
Krok 2: Włącz przepływ danych zmian (w razie potrzeby)
Jeśli planujesz używać trybów synchronizacji wyzwalanej lub ciągłej, tabela źródłowa wymaga włączenia kanału zmian danych. Sprawdź, czy tabela ma już włączoną usługę CDF, lub uruchom to polecenie w edytorze SQL lub notesie:
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Zastąp your_catalog.your_schema.your_table właściwą nazwą tabeli.
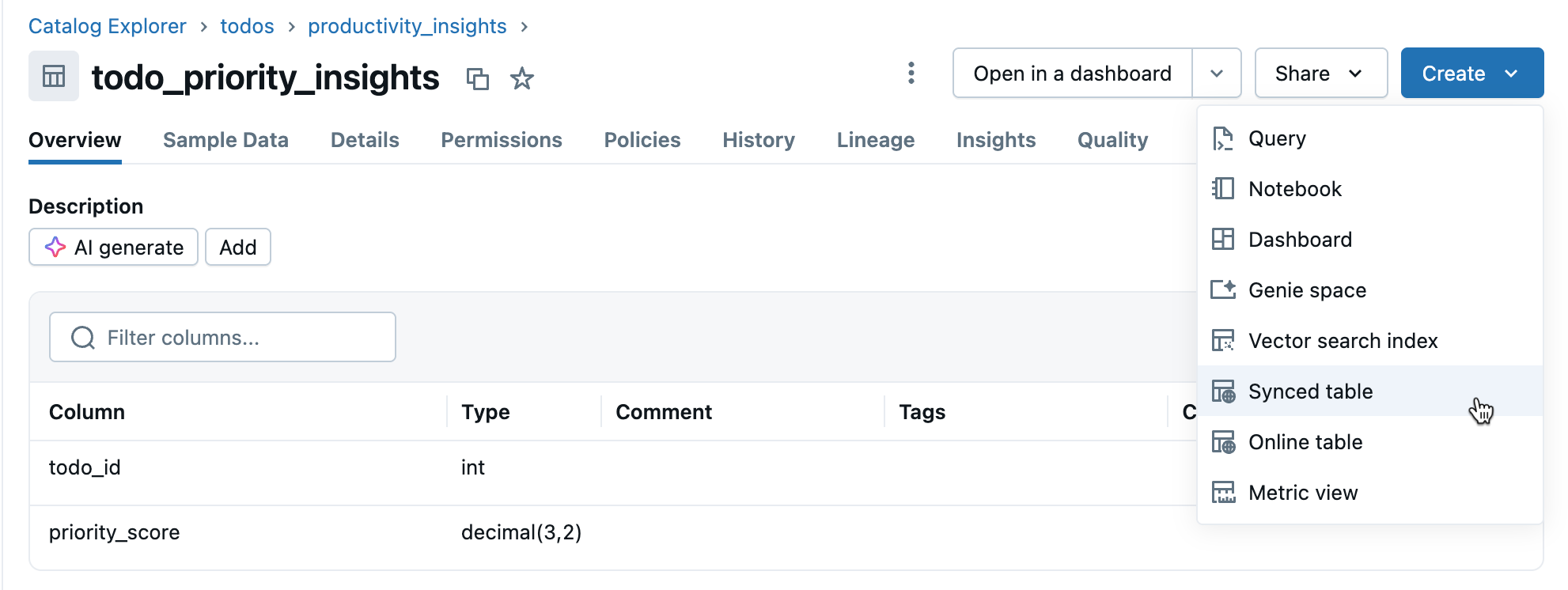
Krok 3. Tworzenie zsynchronizowanej tabeli
Kliknij pozycję Utwórz>zsynchronizowaną tabelę z widoku szczegółów tabeli.
Krok 4. Konfigurowanie
W oknie dialogowym Tworzenie zsynchronizowanej tabeli :
- Nazwa tabeli: wprowadź nazwę zsynchronizowanej tabeli (jest tworzona w tym samym wykazie i schemacie co tabela źródłowa). Spowoduje to utworzenie zarówno zsynchronizowanej tabeli katalogu Unity, jak i tabeli Postgres, którą można zapytać.
- Typ bazy danych: wybierz pozycję Bezserwerowa baza danych Lakebase (skalowanie automatyczne).
- Tryb synchronizacji: wybierz Migawka, Wyzwalany lub Ciągły w zależności od potrzeb (zobacz tryby synchronizacji powyżej).
- Skonfiguruj wybór projektu, gałęzi i bazy danych.
- Sprawdź, czy klucz podstawowy jest poprawny (zwykle wykryty automatycznie).
Jeśli wybrano tryb wyzwalany lub ciągły i nie włączono jeszcze Change Data Feed, zostanie wyświetlone ostrzeżenie z dokładnym poleceniem, które należy uruchomić. Aby uzyskać pytania dotyczące zgodności typów danych, zobacz Typy danych i zgodność.
Kliknij przycisk Utwórz , aby utworzyć zsynchronizowaną tabelę.
Krok 5. Monitorowanie
Po utworzeniu monitoruj zsynchronizowaną tabelę w katalogu. Karta Przegląd zawiera stan synchronizacji, konfigurację, stan potoku i znacznik czasu ostatniej synchronizacji. Użyj funkcji Synchronizuj teraz w celu ręcznego odświeżania.
Typy danych i zgodność
Typy danych Unity Catalog są mapowane na typy Postgres podczas tworzenia tabel zsynchronizowanych. Typy złożone (ARRAY, MAP, STRUCT) są przechowywane jako JSONB w usłudze Postgres.
| Typ kolumny źródłowej | Typ kolumny Postgres |
|---|---|
| BIGINT | BIGINT |
| BINARY | BYTEA |
| BOOLEAN | BOOLEAN |
| DATE | DATE |
| DZIESIĘTNE (p, s) | NUMERIC |
| Podwójny | PODWÓJNA PRECYZJA |
| FLOAT | PRAWDZIWY |
| INT | INTEGER |
| INTERWAŁ | INTERWAŁ |
| SMALLINT | SMALLINT |
| STRING | TEKST |
| TIMESTAMP | SYGNATURA CZASOWA ZE STREFĄ CZASOWĄ |
| TIMESTAMP_NTZ | ZNACZNIK CZASU BEZ STREFY CZASOWEJ |
| TINYINT | SMALLINT |
| ARRAY<, typ elementu> | JSONB |
| MAP<typKlucza,typWartości> | JSONB |
| STRUCT<fieldName:fieldType[, ...]> | JSONB |
Uwaga / Notatka
Typy GEOGRAPHY, GEOMETRY, VARIANT i OBJECT nie są obsługiwane.
Obsługa nieprawidłowych znaków
Niektóre znaki, takie jak bajty null (0x00), są dozwolone w kolumnach typu STRING, ARRAY, MAP lub STRUCT w Unity Catalog, ale nie są obsługiwane w kolumnach Postgres typu TEXT lub JSONB. Może to powodować niepowodzenia synchronizacji i błędy, takie jak:
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
Rozwiązania:
Wyczyść pola ciągów: usuń nieobsługiwane znaki przed zsynchronizowaniem. W przypadku bajtów null w kolumnach STRING:
SELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_tableKonwertuj na PLIK BINARNY: w przypadku kolumn STRING, w których jest konieczne zachowanie nieprzetworzonych bajtów, przekonwertuj na typ BINARNY.
Tworzenie programowe
W przypadku przepływów automatyzacji pracy można programowo tworzyć zsynchronizowane tabele przy użyciu SDK Databricks, interfejsu wiersza polecenia lub interfejsu API REST.
Zestaw SDK dla języka Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.database import (
SyncedDatabaseTable,
SyncedTableSpec,
NewPipelineSpec,
SyncedTableSchedulingPolicy
)
# Initialize the Workspace client
w = WorkspaceClient()
# Create a synced table
synced_table = w.database.create_synced_database_table(
SyncedDatabaseTable(
name="lakebase_catalog.schema.synced_table", # Full three-part name
spec=SyncedTableSpec(
source_table_full_name="analytics.gold.user_profiles",
primary_key_columns=["user_id"], # Primary key columns
scheduling_policy=SyncedTableSchedulingPolicy.TRIGGERED, # SNAPSHOT, TRIGGERED, or CONTINUOUS
new_pipeline_spec=NewPipelineSpec(
storage_catalog="lakebase_catalog",
storage_schema="staging"
)
),
)
)
print(f"Created synced table: {synced_table.name}")
# Check the status of a synced table
status = w.database.get_synced_database_table(name=synced_table.name)
print(f"Synced table status: {status.data_synchronization_status.detailed_state}")
print(f"Status message: {status.data_synchronization_status.message}")
CLI
# Create a synced table
databricks database create-synced-database-table \
--json '{
"name": "lakebase_catalog.schema.synced_table",
"spec": {
"source_table_full_name": "analytics.gold.user_profiles",
"primary_key_columns": ["user_id"],
"scheduling_policy": "TRIGGERED",
"new_pipeline_spec": {
"storage_catalog": "lakebase_catalog",
"storage_schema": "staging"
}
}
}'
# Check the status of a synced table
databricks database get-synced-database-table "lakebase_catalog.schema.synced_table"
interfejs API REST
export WORKSPACE_URL="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-token"
# Create a synced table
curl -X POST "$WORKSPACE_URL/api/2.0/database/synced_tables" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
--data '{
"name": "lakebase_catalog.schema.synced_table",
"spec": {
"source_table_full_name": "analytics.gold.user_profiles",
"primary_key_columns": ["user_id"],
"scheduling_policy": "TRIGGERED",
"new_pipeline_spec": {
"storage_catalog": "lakebase_catalog",
"storage_schema": "staging"
}
}
}'
# Check the status
curl -X GET "$WORKSPACE_URL/api/2.0/database/synced_tables/lakebase_catalog.schema.synced_table" \
-H "Authorization: Bearer $DATABRICKS_TOKEN"
Planowanie pojemności
Podczas planowania odwrotnej implementacji ETL należy wziąć pod uwagę następujące wymagania dotyczące zasobów:
- Wykorzystanie połączeń: Każda zsynchronizowana tabela używa do 16 połączeń z bazą danych Lakebase, które są liczone do limitu połączeń wystąpienia.
- Limity rozmiaru: Łączny limit rozmiaru danych logicznych we wszystkich zsynchronizowanych tabelach wynosi 8 TB. Poszczególne tabele nie mają limitów, ale usługa Databricks zaleca, aby tabele wymagające odświeżeń nie przekraczały 1 TB.
-
Wymagania dotyczące nazewnictwa: Nazwy baz danych, schematu i tabeli mogą zawierać tylko znaki alfanumeryczne i podkreślenia (
[A-Za-z0-9_]+). - Ewolucja schematu: obsługiwane są tylko zmiany schematu addytywnego (takie jak dodawanie kolumn) dla trybów wyzwalanych i ciągłych.
- Szybkość aktualizacji: w przypadku automatycznego skalowania w usłudze Lakebase potok synchronizacji obsługuje operacje ciągłego i wywołanego zapisu przy prędkości około 150 wierszy na sekundę na jednostkę pojemności (CU) oraz zapisy zrzutu danych z prędkością do 2000 wierszy na sekundę na jednostkę (CU).
Usuwanie zsynchronizowanej tabeli
Aby usunąć zsynchronizowaną tabelę, należy usunąć ją zarówno z katalogu Unity, jak i bazy danych Postgres.
Usuń z katalogu Unity: w Katalogu znajdź zsynchronizowaną tabelę, kliknij
 a następnie wybierz Usuń. Spowoduje to zatrzymanie odświeżania danych, ale pozostawia tabelę w usłudze Postgres.
a następnie wybierz Usuń. Spowoduje to zatrzymanie odświeżania danych, ale pozostawia tabelę w usłudze Postgres.Usuń z Postgres: Połącz się z bazą danych Lakebase i usuń tabelę w celu zwolnienia miejsca:
DROP TABLE your_database.your_schema.your_table;
Aby nawiązać połączenie z bazą danych Postgres, możesz użyć edytora SQL lub narzędzi zewnętrznych.
Dowiedz się więcej
| Zadanie | Description |
|---|---|
| Utwórz projekt | Konfigurowanie projektu Lakebase |
| Nawiązywanie połączenia z bazą danych | Informacje o opcjach połączenia dla usługi Lakebase |
| Zarejestruj bazę danych w Unity Catalog | Udostępnij swoje dane z Lakebase w katalogu Unity, aby zapewnić ujednoliconą kontrolę i umożliwić zapytania między źródłami. |
| Integracja katalogu Unity | Zrozumienie ładu i uprawnień |
Inne opcje
Aby zsynchronizować dane z systemami spoza usługi Databricks, zapoznaj się z rozwiązaniami reverse ETL Partner Connect, takimi jak Census lub Hightouch.