Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W przypadku federacji zapytań, zapytania są przekazywane do obcej bazy danych przy użyciu interfejsów API JDBC. Zapytanie jest wykonywane zarówno w usłudze Databricks, jak i przy użyciu zdalnych obliczeń. Federacja zapytań jest używana dla źródeł, takich jak MySQL, PostgreSQL, Redshift, Teradata i nie tylko.
Dlaczego warto używać federacji Lakehouse?
Koncepcja Lakehouse podkreśla centralne magazynowanie danych w celu zmniejszenia ich nadmiarowości i izolacji. Twoja organizacja może mieć wiele systemów danych w środowisku produkcyjnym i może być konieczne wykonywanie zapytań dotyczących danych w połączonych systemach z wielu powodów:
- Raportowanie na żądanie.
- Praca nad dowodem słuszności koncepcji.
- Faza eksploracyjna nowych potoków lub raportów ETL.
- Obsługiwanie obciążeń podczas migracji stopniowej.
W każdym z tych scenariuszy federacja zapytań pozwala na szybsze uzyskiwanie wglądu, ponieważ można wykonywać zapytania dotyczące danych w miejscu i unikać złożonego i czasochłonnego przetwarzania ETL.
Federacja zapytań jest przeznaczona dla przypadków użycia, gdy:
- Nie chcesz wczytywać danych do Azure Databricks.
- Chcesz, aby zapytania korzystały z obliczeń w zewnętrznym systemie bazy danych.
- Chcesz korzystać z zalet interfejsów katalogowych Unity Catalog i zarządzania danymi, w tym szczegółowej kontroli dostępu, śledzenia pochodzenia danych i wyszukiwania.
Federacja zapytań a program Lakeflow Connect
Federacja zapytań umożliwia wykonywanie zapytań dotyczących zewnętrznych źródeł danych bez przenoszenia danych. Databricks zaleca pozyskiwanie danych przy użyciu zarządzanych łączników Lakeflow Connect, ponieważ są one skalowalne do obsługi dużych wolumenów danych i obniżają opóźnienie zapytań. Jednak możesz chcieć wykonać zapytanie dotyczące danych bez ich przenoszenia. Jeśli masz wybór między zarządzanymi konektorami pobierania danych i federacją zapytań, wybierz federację zapytań na potrzeby raportowania ad hoc lub pracy nad dowodami koncepcji w potokach ETL.
Jeśli twoje źródło to obsługuje, łączniki pozyskiwania oparte na zapytaniach są lekką alternatywą dla łączników CDC Connect w ramach Lakeflow. Odpytują źródło bezpośrednio zgodnie z harmonogramem, korzystając z kolumny kursora, bez konieczności używania bramy lub magazynu przejściowego. Używaj łączników pozyskiwania opartych na zapytaniach, gdy potrzebujesz cyklicznego pozyskiwania, ale nie masz dostępnej infrastruktury CDC.
Omówienie konfiguracji federacji zapytań
Aby udostępnić zestaw danych do wykonywania zapytań tylko do odczytu przy użyciu federacji Lakehouse, tworzysz następujące elementy:
- Połączenie, zabezpieczalny obiekt w Unity Catalog, który określa ścieżkę i poświadczenia do dostępu do zewnętrznego systemu bazy danych.
- Katalog obcy, zabezpieczany obiekt w katalogu Unity, który odzwierciedla bazę danych w zewnętrznym systemie danych, umożliwiając wykonywanie zapytań tylko do odczytu w tym systemie danych w obszarze roboczym Azure Databricks, zarządzanie dostępem przy użyciu katalogu Unity.
Obsługiwane źródła danych
Federacja zapytań obsługuje połączenia z następującymi źródłami:
- MySQL
- PostgreSQL
- Teradata
- Oracle
- Amazon Redshift
- Salesforce Data 360
- Snowflake
- Microsoft SQL Server
- Azure Synapse (SQL Data Warehouse)
- Google BigQuery
- Databricks
Wymagania dotyczące połączenia
Wymagania dotyczące obszaru roboczego:
- Obszar roboczy z dostępem do Unity Catalog. Obszary robocze utworzone po 9 listopada 2023 r. są automatycznie włączane dla Unity Catalog, w tym automatyczne aprowizowanie metastore. Nie musisz tworzyć metastore'u ręcznie, chyba że obszar roboczy został stworzony przed automatycznym włączeniem i nie został włączony dla Unity Catalog. Zobacz Automatyczne uruchamianie Unity Catalog.
Wymagania dotyczące obliczeń:
- Łączność sieciowa pomiędzy zasobem obliczeniowym a docelowymi systemami baz danych. Zobacz Zalecenia dotyczące sieci dla Lakehouse Federation.
- Azure Databricks obliczenia muszą używać środowiska Databricks Runtime 13.3 LTS lub nowszego w trybie dostępu Standard lub Dedicated.
- Magazyny SQL muszą być w wersji pro lub bezserwerowej i muszą używać wersji 2023.40 lub nowszej.
Wymagane uprawnienia:
- Aby utworzyć połączenie, musisz być administratorem magazynu metadanych lub użytkownikiem z uprawnieniami
CREATE CONNECTIONw magazynie metadanych Unity Catalog dołączonym do obszaru roboczego. W obszarach roboczych, które zostały automatycznie włączone do katalogu Unity, administratorzy obszaru roboczego mają domyślnie uprawnienieCREATE CONNECTION. - Aby utworzyć katalog zagraniczny, musisz mieć uprawnienie
CREATE CATALOGw metastore i być właścicielem połączenia lub mieć uprawnieniaCREATE FOREIGN CATALOGdla połączenia. W obszarach roboczych, które zostały automatycznie włączone do katalogu Unity, administratorzy obszaru roboczego mają domyślnie uprawnienieCREATE CATALOG.
Dodatkowe wymagania dotyczące uprawnień są określone w każdej sekcji dotyczącej poszczególnych zadań.
Tworzenie połączenia
Połączenie określa ścieżkę dostępu i dane uwierzytelniające do zewnętrznego systemu bazodanowego. Aby utworzyć połączenie, możesz użyć Eksploratora wykazu lub polecenia CREATE CONNECTION SQL w notesie Azure Databricks lub edytorze zapytań SQL usługi Databricks.
Note
Do utworzenia połączenia można również użyć interfejsu API REST usługi Databricks lub interfejsu wiersza polecenia usługi Databricks. Zobacz POST /api/2.1/unity-catalog/connections oraz polecenia Unity Catalog.
Wymagane uprawnienia: administrator magazynu metadanych lub użytkownik z uprawnieniami CREATE CONNECTION .
Eksplorator wykazu
W obszarze roboczym Azure Databricks kliknij pozycję
 Catalog.
Catalog.W górnej części okienka Wykaz kliknij
 Ikona Dodaj i wybierz pozycję Utwórz połączenie z menu.
Ikona Dodaj i wybierz pozycję Utwórz połączenie z menu.Wprowadź przyjazną dla użytkownika nazwę połączenia.
Wybierz typ połączenia (dostawca bazy danych, taki jak MySQL lub PostgreSQL).
(Opcjonalnie) Dodaj komentarz.
Kliknij przycisk Dalej.
Wprowadź właściwości połączenia (takie jak informacje o hoście, ścieżka i poświadczenia dostępu).
Każdy typ połączenia wymaga różnych informacji o połączeniu. Zapoznaj się z artykułem dotyczącym typu połączenia wymienionego w spisie treści po lewej stronie.
Kliknij pozycję Utwórz połączenie.
Wprowadź nazwę wykazu obcego.
(Opcjonalnie) Kliknij pozycję Testuj połączenie , aby potwierdzić, że działa.
Kliknij pozycję Utwórz katalog.
Wybierz obszary robocze, w których użytkownicy mogą uzyskiwać dostęp do utworzonego katalogu. Możesz wybrać opcję Wszystkie obszary robocze mają dostęplub kliknij Przypisać do obszarów roboczych, wybierz obszary robocze, a następnie kliknij Przypisz.
Zmień właściciela , który będzie mógł zarządzać dostępem do wszystkich obiektów w katalogu. Zacznij wpisywać nazwę podmiotu w polu tekstowym, a następnie kliknij ten podmiot w wynikach wyszukiwania.
Nadaj przywileje w katalogu. Kliknij Zezwól:
- Określ podmioty, które będą miały dostęp do obiektów w katalogu. Zacznij wpisywać nazwę podmiotu w polu tekstowym, a następnie kliknij ten podmiot w wynikach wyszukiwania.
- Wybierz ustawienia wstępne przywilejów, aby przyznać każdemu podmiotowi. Wszyscy użytkownicy konta domyślnie otrzymują
BROWSE.- Wybierz Czytnik danych z menu rozwijanego, aby nadać
readuprawnienia do obiektów w katalogu. - Wybierz pozycję Edytor danych z menu rozwijanego, aby przyznać
readimodifyuprawnienia do obiektów w wykazie. - Ręcznie wybierz uprawnienia do udzielenia.
- Wybierz Czytnik danych z menu rozwijanego, aby nadać
- Kliknij Grant.
- Kliknij przycisk Dalej.
- Na stronie Metadane określ pary klucz-wartość dla tagów. Aby uzyskać więcej informacji, zobacz Zastosuj tagi do obiektów zabezpieczalnych w Unity Catalog.
- (Opcjonalnie) Dodaj komentarz.
- Kliknij przycisk Zapisz.
SQL
Uruchom następujące polecenie w notesie lub edytorze zapytań SQL. Ten przykład dotyczy połączeń z bazą danych PostgreSQL. Opcje różnią się od typu połączenia. Zapoznaj się z artykułem dotyczącym typu połączenia wymienionego w spisie treści po lewej stronie.
CREATE CONNECTION <connection-name> TYPE postgresql
OPTIONS (
host '<hostname>',
port '<port>',
user '<user>',
password '<password>'
);
Zalecamy użycie Azure Databricks secrets zamiast ciągów w postaci zwykłego tekstu w przypadku poufnych wartości, takich jak poświadczenia. Przykład:
CREATE CONNECTION <connection-name> TYPE postgresql
OPTIONS (
host '<hostname>',
port '<port>',
user secret ('<secret-scope>','<secret-key-user>'),
password secret ('<secret-scope>','<secret-key-password>')
)
Aby uzyskać informacje na temat konfigurowania wpisów tajnych, zobacz Zarządzanie wpisami tajnymi.
Aby uzyskać informacje na temat zarządzania istniejącymi połączeniami, zobacz Zarządzanie połączeniami dla Lakehouse Federation.
Utwórz katalog zagraniczny
Note
Jeśli używasz interfejsu użytkownika do utworzenia połączenia ze źródłem danych, uwzględnione jest tworzenie katalogu zewnętrznego i możesz pominąć ten krok.
Katalog obcy odzwierciedla bazę danych w zewnętrznym systemie danych, dzięki czemu można wykonywać zapytania oraz zarządzać dostępem do danych w tej bazie danych przy użyciu Azure Databricks i Unity Catalog. Aby utworzyć wykaz obcy, należy użyć połączenia ze źródłem danych, które zostało już zdefiniowane.
Aby utworzyć katalog zewnętrzny, możesz użyć Eksploratora Katalogów lub polecenia SQL w notesie Azure Databricks lub edytorze zapytań SQL. Możesz również użyć API Unity Catalog. Zobacz dokumentację referencyjną Azure Databricks.
Metadane obcego katalogu są synchronizowane z Unity Catalog przy każdej interakcji z katalogiem. Aby sprawdzić mapowanie typów danych między Unity Catalogiem a źródłem danych, zapoznaj się z sekcją Mapowania typów danych w dokumentacji każdego źródła danych.
Wymagane uprawnienia:CREATE CATALOG uprawnienia do magazynu metadanych i właścicielstwo połączenia lub CREATE FOREIGN CATALOG uprawnienie do połączenia.
Eksplorator wykazu
W obszarze roboczym Azure Databricks kliknij pozycję
Catalog, aby otworzyć Eksplorator wykazu.W górnej części okienka Wykaz kliknij ikonę
Dodaj dane i wybierz opcję Utwórz wykaz z menu.Alternatywnie na stronie Szybki dostęp kliknij na przycisk Wykazy, a następnie kliknij na przycisk Utwórz katalog.
Postępuj zgodnie z instrukcjami dotyczącymi tworzenia katalogów obcych w Tworzenie katalogów.
SQL
Uruchom następujące polecenie SQL w notesie lub edytorze zapytań SQL. Elementy w nawiasach są opcjonalne. Zastąp wartości zastępcze:
-
<catalog-name>: nazwa katalogu w Azure Databricks. -
<connection-name>: obiekt połączenia określający źródło danych, ścieżkę i poświadczenia dostępu. -
<database-name>: nazwa bazy danych, którą chcesz replikować jako katalog w Azure Databricks. Nie jest to wymagane w przypadku bazy danych MySQL, która używa dwuwarstwowej przestrzeni nazw. -
<external-catalog-name>: Databricks-to-Databricks tylko: nazwa katalogu w zewnętrznym obszarze roboczym Databricks, który jest odwzorowywany. Zobacz Tworzenie obcego katalogu.
CREATE FOREIGN CATALOG [IF NOT EXISTS] <catalog-name> USING CONNECTION <connection-name>
OPTIONS (database '<database-name>');
Aby uzyskać informacje na temat zarządzania katalogami obcymi i pracy z nimi, zobacz Zarządzanie katalogami obcymi i praca z nimi.
Odświeżanie metadanych
Unity Catalog automatycznie odświeża metadane dla tabel zewnętrznych w czasie wykonywania zapytania. Jeśli schemat zewnętrznego katalogu ulegnie zmianie, Unity Catalog pobiera najnowsze metadane w trakcie uruchamiania zapytania. To zachowanie utrzymuje bieżący schemat i jest optymalne dla większości obciążeń.
Jednak usługa Databricks zaleca ręczne odświeżanie metadanych w następujących przypadkach:
- Aby zachować spójność dla tabel obcych, do których uzyskują dostęp silniki zewnętrzne. Ścieżki pomijające środowisko Databricks Runtime nie wyzwalają automatycznych odświeżeń, co może spowodować nieaktualne metadane.
- Aby zwiększyć wydajność obciążeń, w których chcesz uniknąć odświeżania metadanych podczas wykonywania zapytania. Aktywne odświeżanie metadanych umożliwia szybsze uruchamianie zapytań przy użyciu buforowanych metadanych. Takie podejście jest szczególnie przydatne natychmiast po utworzeniu wykazu obcego, ponieważ pierwsze zapytanie w przeciwnym razie wyzwala pełne odświeżanie.
Zautomatyzuj odświeżanie metadanych za pomocą zadań Lakeflow
Zaplanuj okresowe odświeżanie metadanych przy użyciu zadania Lakeflow za pomocą polecenia SQL. Przykład:
-- Refresh an entire catalog
> REFRESH FOREIGN CATALOG some_catalog;
-- Refresh a specific schema
> REFRESH FOREIGN SCHEMA some_catalog.some_schema;
-- Refresh a specific table
> REFRESH FOREIGN TABLE some_catalog.some_schema.some_table;
Skonfiguruj zadanie do uruchamiania w regularnych odstępach czasu w zależności od częstotliwości przewidywania zmian schematu zewnętrznego.
Ładowanie danych z tabel obcych za pomocą zmaterializowanych widoków
Usługa Databricks zaleca ładowanie danych zewnętrznych przy użyciu federacji zapytań podczas tworzenia zmaterializowanych widoków. Zobacz zmaterializowane widoki.
W przypadku korzystania z federacji zapytań użytkownicy mogą odwoływać się do danych federacyjnych w następujący sposób:
CREATE MATERIALIZED VIEW xyz AS SELECT * FROM federated_catalog.federated_schema.federated_table;
Wyświetlanie zapytań federacyjnych generowanych przez system
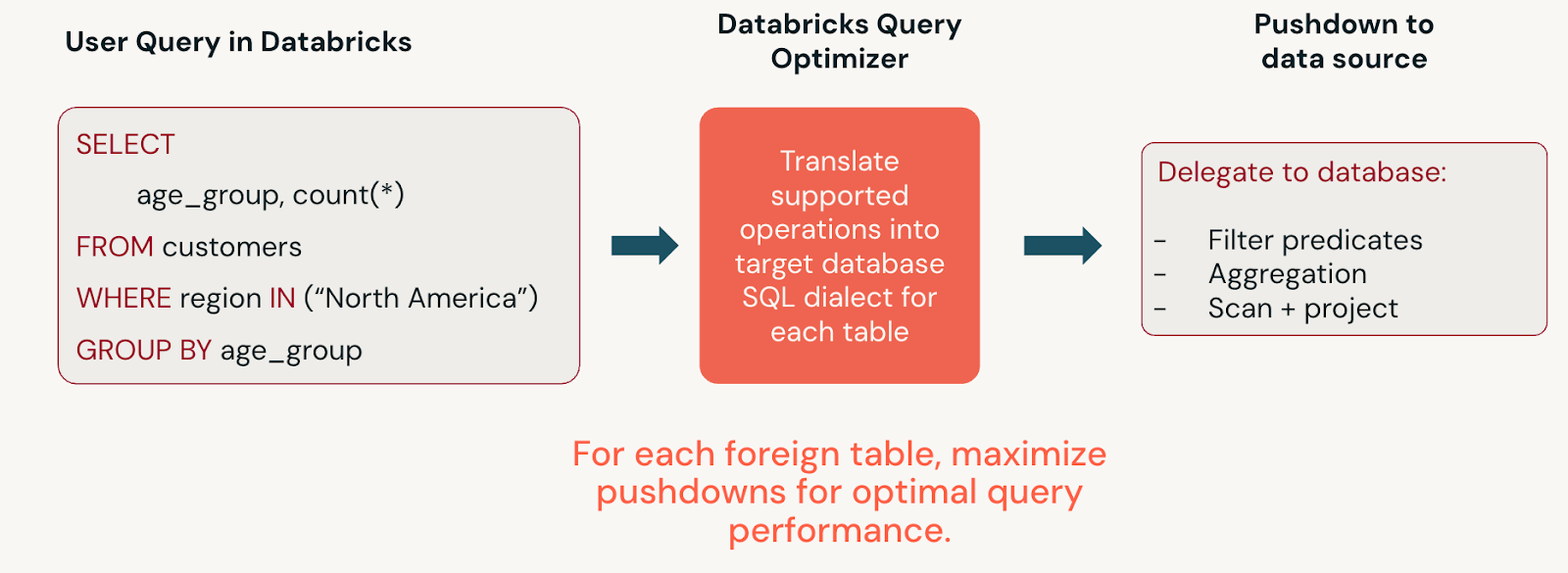
Federacja zapytań tłumaczy instrukcje SQL usługi Databricks na instrukcje, które można wypchnąć do federacyjnego źródła danych. Aby wyświetlić wygenerowaną instrukcję SQL, kliknij węzeł skanowania obcego źródła danych na wykresie w widoku profilu zapytania lub uruchom instrukcję SQL EXPLAIN FORMATTED. Zobacz sekcję Obsługiwane wypychanie w dokumentacji każdego źródła danych, aby uzyskać pokrycie.
Limitations
- Zapytania są tylko do odczytu. Jedynym wyjątkiem jest sytuacja, gdy federacja Lakehouse jest używana do zintegrowania starszego magazynu metadanych Hive w obszarze roboczym (federacja katalogu). W tym scenariuszu tabele obce są zapisywalne. Zobacz Co oznacza zapis do katalogu zagranicznego w federacyjnym magazynie metadanych Hive?.
- Ograniczanie połączeń jest określane przy użyciu limitu współbieżnych zapytań SQL usługi Databricks. Nie ma żadnych ograniczeń dotyczących połączeń między magazynami. Zobacz logikę kolejkowania i skalowania automatycznego.
- Buforowanie zapytań usługi Databricks (pamięć podręczna wyników i pamięć podręczna dysku) nie jest obsługiwane w przypadku zapytań federacyjnych. Oznacza to, że
use_cached_resultparametr nie ma zastosowania do zapytań względem źródeł federacyjnych. - Tabele i schematy o nazwach, które są nieprawidłowe w Unity Catalog, nie są obsługiwane i są ignorowane przez Unity Catalog podczas tworzenia katalogu zewnętrznego. Zobacz listę reguł nazewnictwa i ograniczeń w temacie Ograniczenia.
- Nazwy tabel i nazwy schematów są konwertowane na małe litery w Unity Catalog. Jeśli spowoduje to kolizje nazw, usługa Databricks nie może zagwarantować, który obiekt zostanie zaimportowany do wykazu obcego.
- Dla każdej odwołanej tabeli obcej, Databricks planuje zapytanie podrzędne w systemie zdalnym, aby zwrócić podzbiór danych z tej tabeli, a następnie zwraca wynik do jednego zadania wykonawczego Databricks w jednym strumieniu. Jeśli zestaw wyników jest zbyt duży, wykonawca może mieć problemy z brakiem pamięci.
- Tryb dedykowanego dostępu (dawniej tryb dostępu pojedynczego użytkownika) jest dostępny tylko dla użytkowników, którzy są właścicielami połączenia.
- Lakehouse Federation nie może federować zdalnych tabel z identyfikatorami uwzględniającymi wielkość liter w przypadku połączeń Azure Synapse lub Redshift.
Przydziały zasobów
Azure Databricks wymusza limity zasobów dla wszystkich zabezpieczalnych obiektów katalogu Unity. Te limity przydziału są wymienione w temacie Limity zasobów. Katalogi obce i wszystkie zawarte w nich obiekty są uwzględniane w całkowitym użyciu limitu przydziału.
Jeśli oczekujesz przekroczenia tych limitów zasobów, skontaktuj się z zespołem ds. kont Azure Databricks.
Można monitorować zużycie limitu przydziałów za pomocą zasobów API Unity Catalog. Zobacz Monitorowanie użycia przydziałów zasobów w Unity Catalog.