Wprowadzenie do korzystania z danych DICOM w obciążeniach analitycznych
W tym artykule opisano, jak rozpocząć korzystanie z danych DICOM® w obciążeniach analitycznych za pomocą usług Azure Data Factory i Microsoft Fabric.
Wymagania wstępne
Przed rozpoczęciem wykonaj następujące kroki:
- Utwórz konto magazynu z możliwościami usługi Azure Data Lake Storage Gen2, włączając hierarchiczną przestrzeń nazw:
- Utwórz kontener do przechowywania metadanych DICOM, na przykład o nazwie
dicom.
- Utwórz kontener do przechowywania metadanych DICOM, na przykład o nazwie
- Wdróż wystąpienie usługi DICOM.
- (Opcjonalnie) Wdróż usługę DICOM za pomocą usługi Data Lake Storage , aby umożliwić bezpośredni dostęp do plików DICOM.
- Utwórz wystąpienie usługi Data Factory :
- Włącz tożsamość zarządzaną przypisaną przez system.
- Utwórz jezioro w usłudze Fabric.
- Dodaj przypisania ról do przypisanej przez system tożsamości zarządzanej usługi Data Factory dla usługi DICOM i konta magazynu usługi Data Lake Storage Gen2:
- Dodaj rolę Czytelnik danych DICOM, aby udzielić uprawnień do usługi DICOM.
- Dodaj rolę Współautor danych obiektu blob usługi Storage, aby udzielić uprawnień do konta usługi Data Lake Storage Gen2.
Konfigurowanie potoku usługi Data Factory dla usługi DICOM
W tym przykładzie potok usługi Data Factory służy do zapisywania atrybutów DICOM dla wystąpień, serii i badań na koncie magazynu w formacie tabeli delty.
W witrynie Azure Portal otwórz wystąpienie usługi Data Factory i wybierz pozycję Uruchom studio , aby rozpocząć.

Tworzenie połączonych usług
Potoki usługi Data Factory odczytują ze źródeł danych i zapisują je w ujściach danych, które są zazwyczaj innymi usługami platformy Azure. Te połączenia z innymi usługami są zarządzane jako połączone usługi.
Potok w tym przykładzie odczytuje dane z usługi DICOM i zapisuje swoje dane wyjściowe na koncie magazynu, więc dla obu usług należy utworzyć połączoną usługę.
Tworzenie połączonej usługi dla usługi DICOM
W narzędziu Azure Data Factory Studio wybierz pozycję Zarządzaj z menu po lewej stronie. W obszarze Połączenie ions wybierz pozycję Połączone usługi, a następnie wybierz pozycję Nowe.
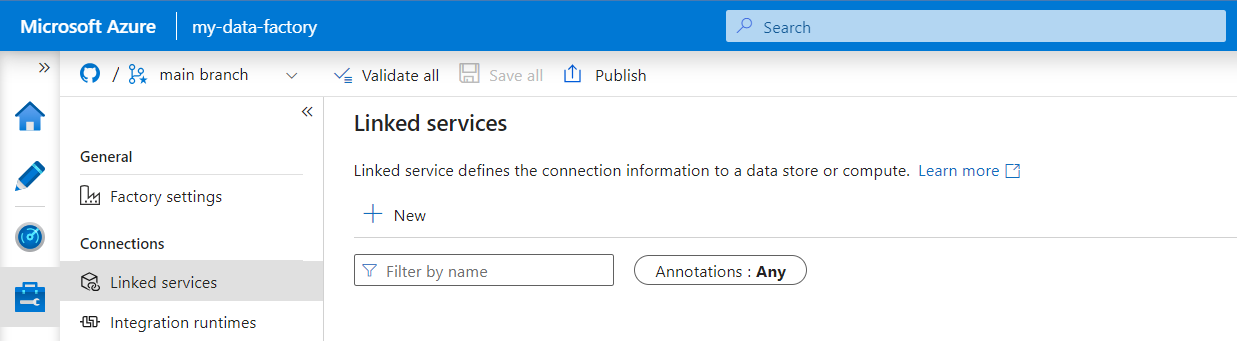
W okienku Nowa połączona usługa wyszukaj frazę REST. Wybierz kafelek REST, a następnie wybierz pozycję Kontynuuj.
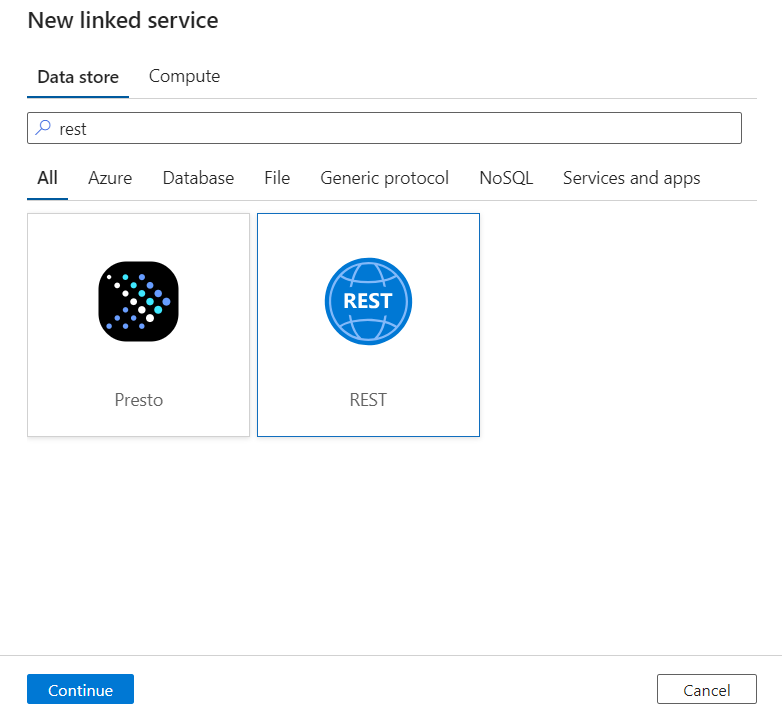
Wprowadź nazwę i opis połączonej usługi.
W polu Podstawowy adres URL wprowadź adres URL usługi dla usługi DICOM. Na przykład usługa DICOM o nazwie
contosoclinicwcontosohealthobszarze roboczym ma adres URLhttps://contosohealth-contosoclinic.dicom.azurehealthcareapis.comusługi .W polu Typ uwierzytelniania wybierz pozycję Tożsamość zarządzana przypisana przez system.
W polu Zasób usługi AAD wprowadź wartość
https://dicom.healthcareapis.azure.com. Ten adres URL jest taki sam dla wszystkich wystąpień usługi DICOM.Po wypełnieniu wymaganych pól wybierz pozycję Testuj połączenie , aby upewnić się, że role tożsamości są poprawnie skonfigurowane.
Po pomyślnym zakończeniu testu połączenia wybierz pozycję Utwórz.



Tworzenie połączonej usługi dla usługi Azure Data Lake Storage Gen2
W narzędziu Data Factory Studio wybierz pozycję Zarządzaj z menu po lewej stronie. W obszarze Połączenie ions wybierz pozycję Połączone usługi, a następnie wybierz pozycję Nowe.
W okienku Nowa połączona usługa wyszukaj ciąg Azure Data Lake Storage Gen2. Wybierz kafelek Azure Data Lake Storage Gen2, a następnie wybierz pozycję Kontynuuj.
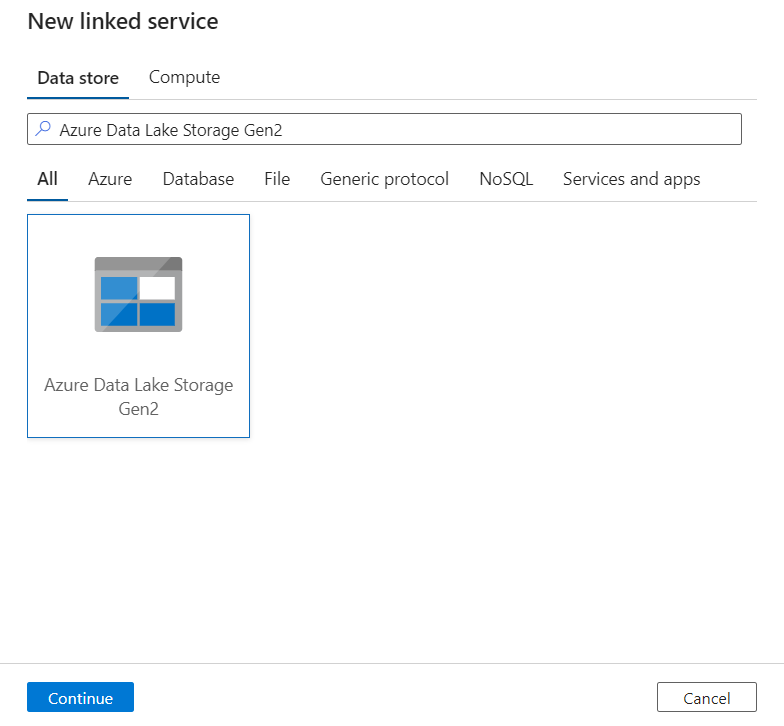
Wprowadź nazwę i opis połączonej usługi.
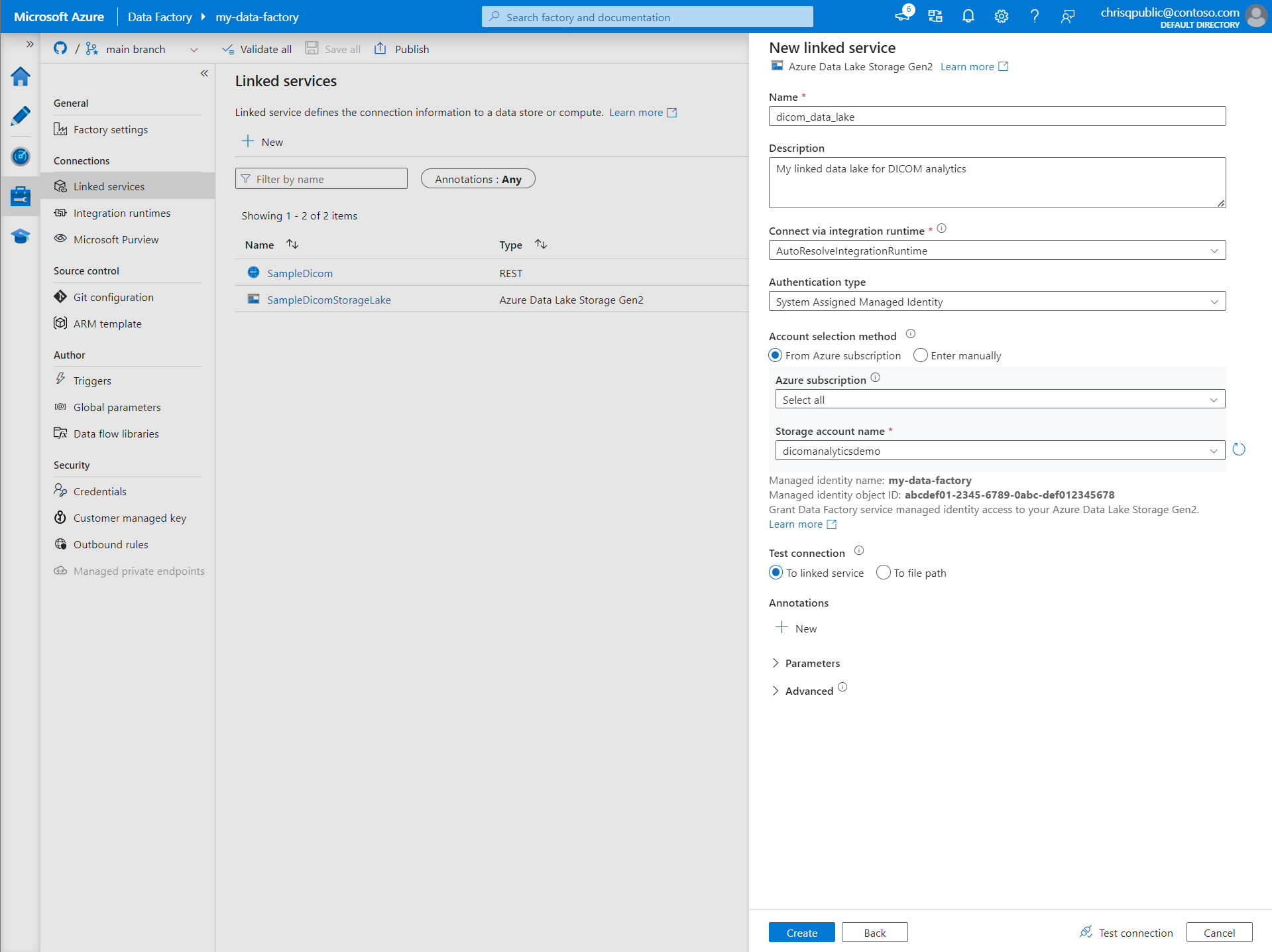
W polu Typ uwierzytelniania wybierz pozycję Tożsamość zarządzana przypisana przez system.
Wprowadź szczegóły konta magazynu, wprowadzając adres URL do konta magazynu ręcznie. Możesz też wybrać subskrypcję platformy Azure i konto magazynu z list rozwijanych.
Po wypełnieniu wymaganych pól wybierz pozycję Testuj połączenie , aby upewnić się, że role tożsamości są poprawnie skonfigurowane.
Po pomyślnym zakończeniu testu połączenia wybierz pozycję Utwórz.


Tworzenie potoku dla danych DICOM
Potoki usługi Data Factory to kolekcja działań , które wykonują zadanie, takie jak kopiowanie metadanych DICOM do tabel delty. W tej sekcji szczegółowo omówiono tworzenie potoku, który regularnie synchronizuje dane DICOM z tabelami delty w miarę dodawania, aktualizowania i usuwania danych z usługi DICOM.
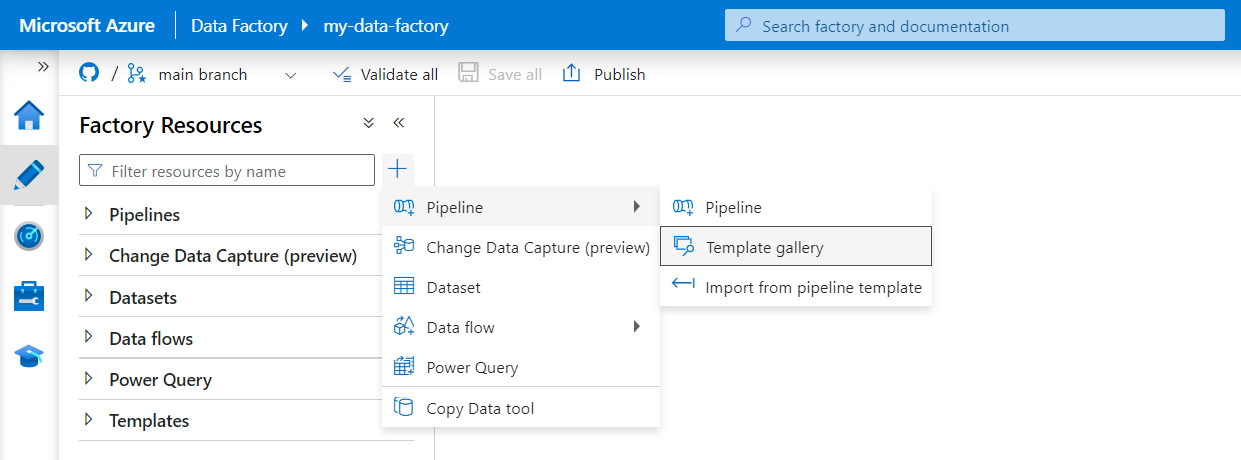
Wybierz pozycję Utwórz z menu po lewej stronie. W okienku Zasoby fabryki wybierz znak plus (+), aby dodać nowy zasób. Wybierz pozycję Potok , a następnie z menu wybierz pozycję Galeria szablonów.
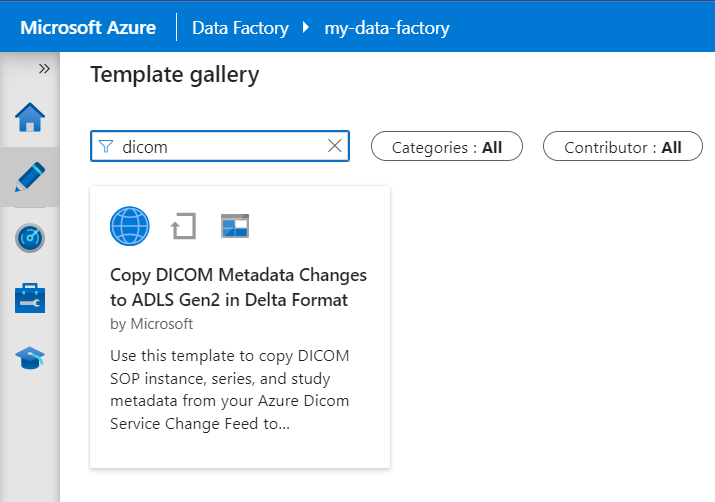
W galerii szablonów wyszukaj ciąg DICOM. Wybierz kafelek Kopiuj zmiany metadanych DICOM do usługi ADLS Gen2 w formacie różnicowym, a następnie wybierz pozycję Kontynuuj.
W sekcji Dane wejściowe wybierz połączone usługi utworzone wcześniej dla konta DICOM i usługi Data Lake Storage Gen2.
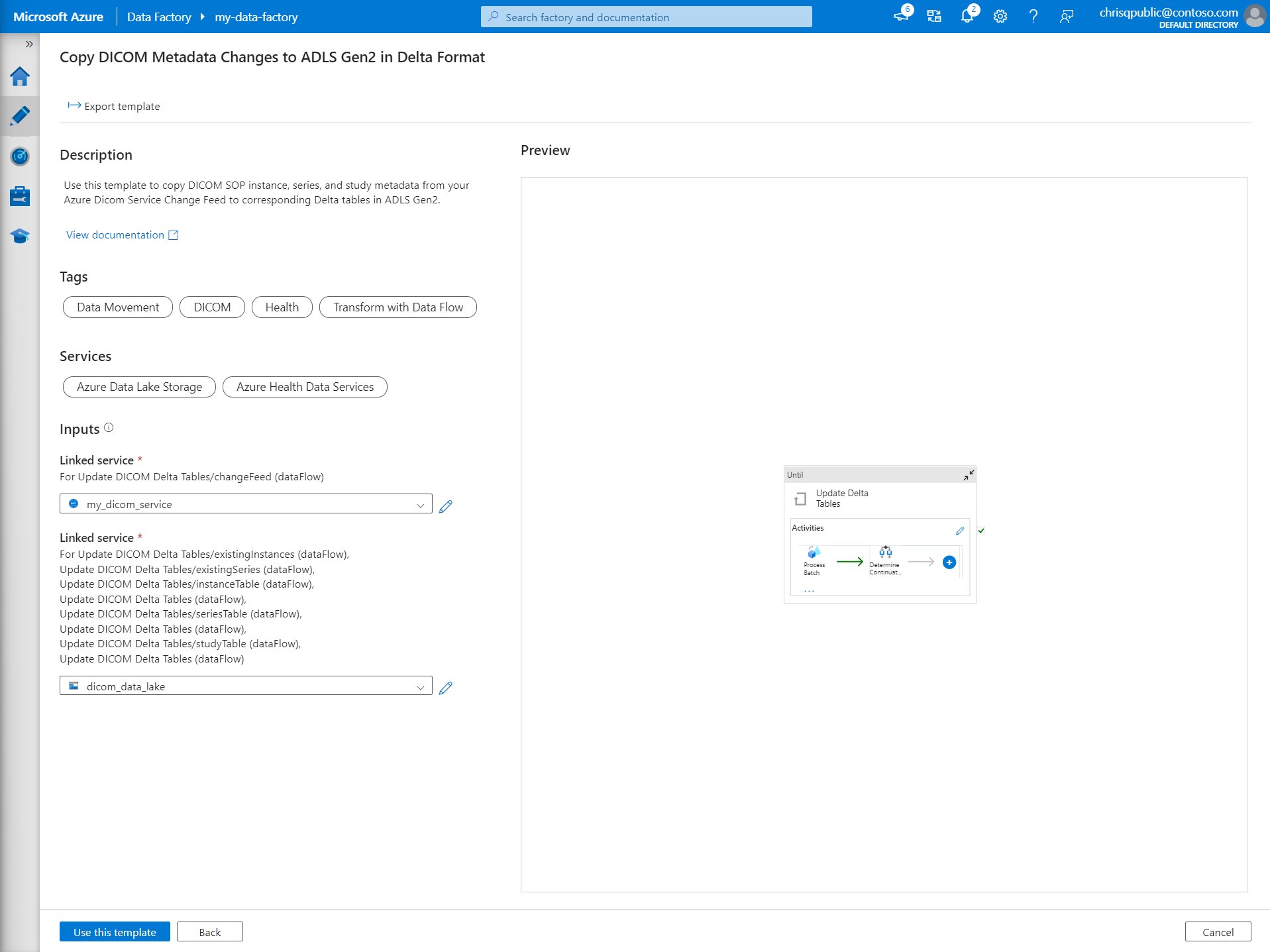
Wybierz pozycję Użyj tego szablonu , aby utworzyć nowy potok.



Tworzenie potoku dla danych DICOM
Jeśli usługa DICOM została utworzona za pomocą usługi Azure Data Lake Storage, musisz użyć szablonu niestandardowego do uwzględnienia nowego fileName parametru w potoku metadanych. Zamiast używać szablonu z galerii szablonów, wykonaj następujące kroki, aby skonfigurować potok.
Pobierz szablon z usługi GitHub. Plik szablonu jest skompresowanym (spakowany) folderem. Nie musisz wyodrębniać plików, ponieważ są one już przekazywane w skompresowanym formularzu.
W usłudze Azure Data Factory wybierz pozycję Autor z menu po lewej stronie. W okienku Zasoby fabryki wybierz znak plus (+), aby dodać nowy zasób. Wybierz pozycję Potok , a następnie wybierz pozycję Importuj z szablonu potoku.
W oknie Otwórz wybierz pobrany szablon. Wybierz Otwórz.
W sekcji Dane wejściowe wybierz połączone usługi utworzone dla usługi DICOM i konta usługi Azure Data Lake Storage Gen2.
Wybierz pozycję Użyj tego szablonu , aby utworzyć nowy potok.
Planowanie potoku
Potoki są zaplanowane przez wyzwalacze. Istnieją różne typy wyzwalaczy. Wyzwalacze harmonogramu umożliwiają wyzwalanie potoków zgodnie z harmonogramem zegara, co oznacza, że są one uruchamiane o określonych porach dnia, takich jak co godzinę lub codziennie o północy. Wyzwalacze ręczne wyzwalają potoki na żądanie, co oznacza, że są uruchamiane za każdym razem, gdy chcesz.
W tym przykładzie wyzwalacz okna wirowania jest używany do okresowego uruchamiania potoku w danym punkcie początkowym i regularnym interwale czasu. Aby uzyskać więcej informacji na temat wyzwalaczy, zobacz Wykonywanie i wyzwalacze potoku w usłudze Azure Data Factory lub Azure Synapse Analytics.
Tworzenie nowego wyzwalacza okna wirowania
Wybierz pozycję Utwórz z menu po lewej stronie. Wybierz potok dla usługi DICOM, a następnie wybierz pozycję Dodaj wyzwalacz i Nowy/Edytuj na pasku menu.
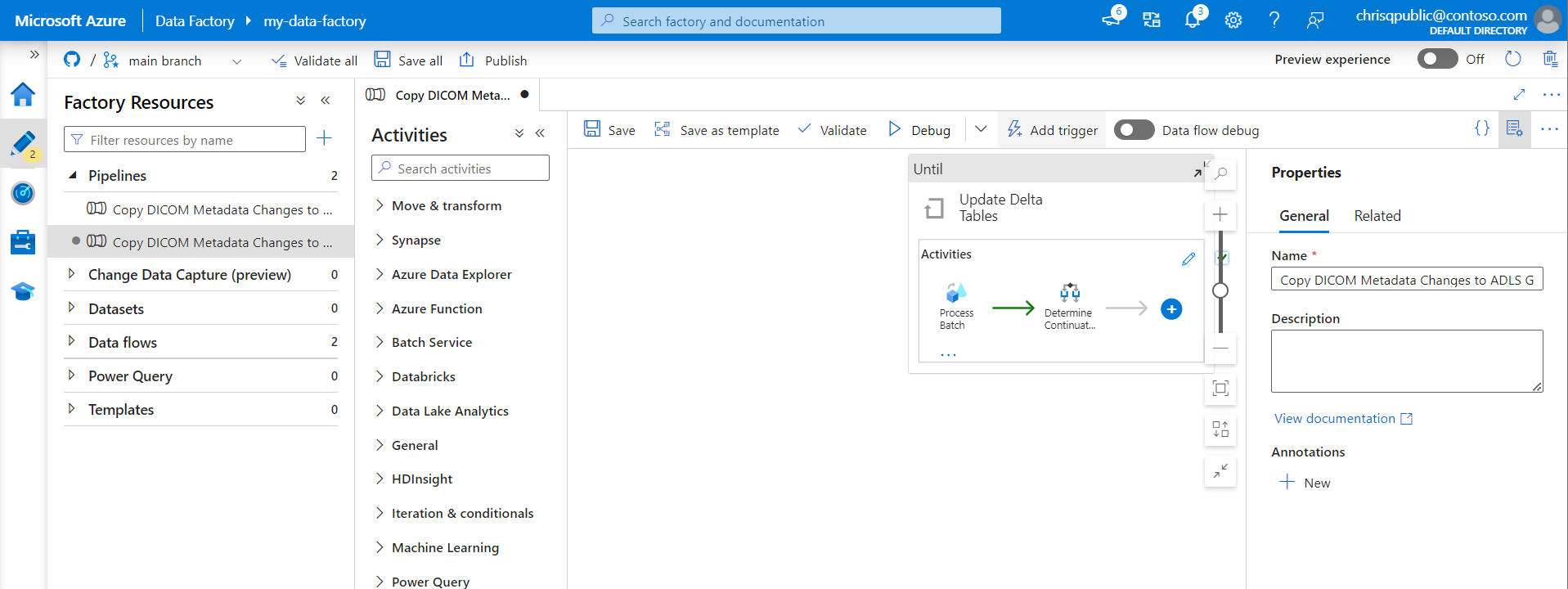
W okienku Dodawanie wyzwalaczy wybierz listę rozwijaną Wybierz wyzwalacz , a następnie wybierz pozycję Nowy.
Wprowadź nazwę i opis wyzwalacza.
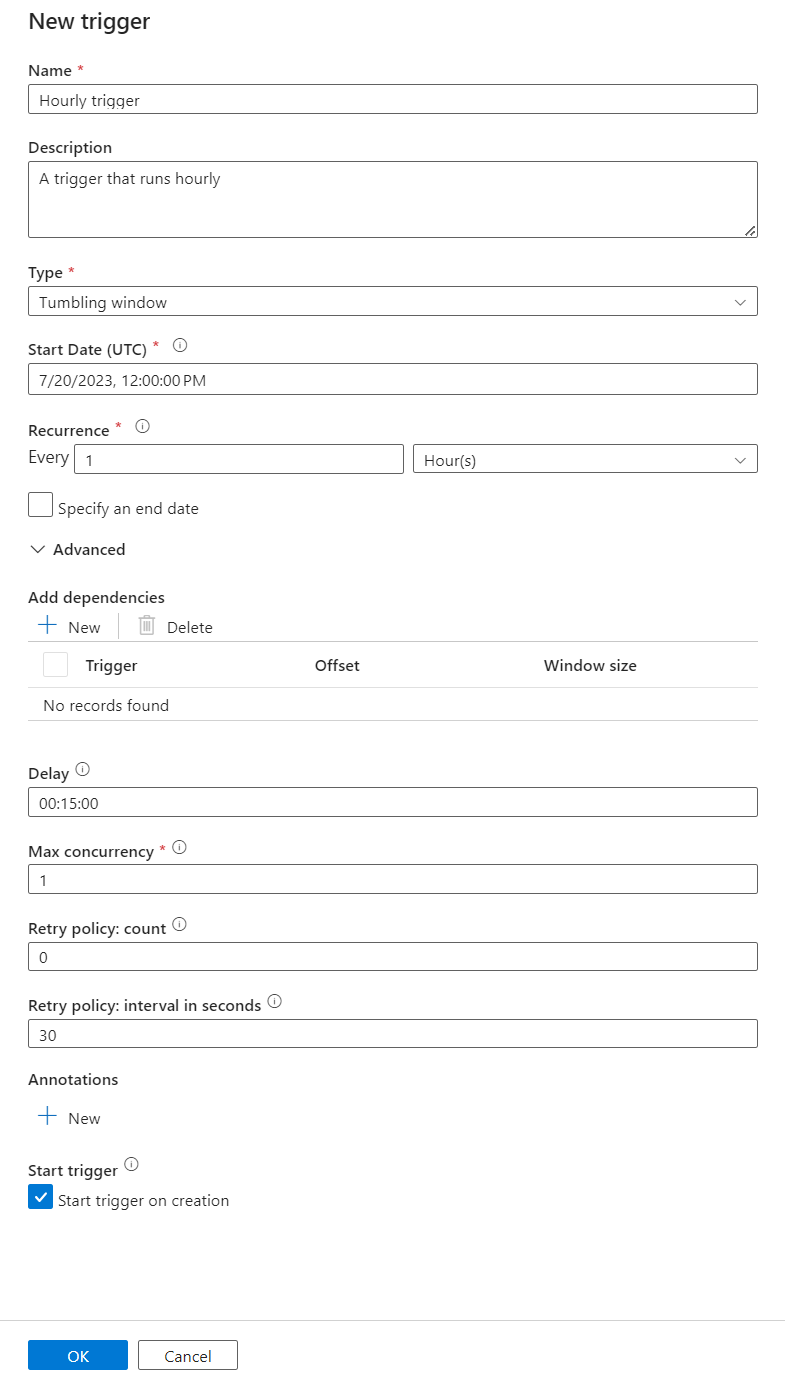
Wybierz pozycję Okno wirowania jako Typ.
Aby skonfigurować potok uruchamiany co godzinę, ustaw wartość Cykl na 1 godzinę.
Rozwiń sekcję Zaawansowane i wprowadź wartość Opóźnienie15 minut. To ustawienie umożliwia wykonywanie wszystkich oczekujących operacji na końcu godziny przed przetworzeniem.
Ustaw wartość Maksymalna współbieżność na 1 , aby zapewnić spójność między tabelami.
Wybierz przycisk OK , aby kontynuować konfigurowanie parametrów przebiegu wyzwalacza.


Konfigurowanie parametrów uruchamiania wyzwalacza
Wyzwalacze definiują czas uruchamiania potoku. Obejmują one również parametry przekazywane do wykonywania potoku. Szablon Copy DICOM Metadata Changes to Delta (Kopiowanie zmian metadanych DICOM w funkcji delta ) definiuje kilka parametrów opisanych w poniższej tabeli. Jeśli podczas konfiguracji nie podano żadnej wartości, wyświetlana wartość domyślna jest używana dla każdego parametru.
| Nazwa parametru | opis | Domyślna wartość |
|---|---|---|
| Batchsize | Maksymalna liczba zmian do pobrania w czasie ze zestawienia zmian (maksymalnie 200) | 200 |
| ApiVersion | Wersja interfejsu API dla usługi Azure DICOM (co najmniej 2) | 2 |
| StartTime | Czas rozpoczęcia inkluzywnego dla zmian DICOM | 0001-01-01T00:00:00Z |
| EndTime | Wyłączny czas zakończenia zmian DICOM | 9999-12-31T23:59:59Z |
| NazwaKontenera | Nazwa kontenera dla wynikowych tabel delty | dicom |
| InstanceTablePath | Ścieżka zawierająca tabelę delty dla wystąpień SOP DICOM w kontenerze | instance |
| SeriesTablePath | Ścieżka zawierająca tabelę delty dla serii DICOM w kontenerze | series |
| StudyTablePath | Ścieżka zawierająca tabelę delty dla badań DICOM w kontenerze | study |
| Czas przechowywania | Maksymalny czas przechowywania w godzinach dla danych w tabelach delty | 720 |
W okienku Parametry przebiegu wyzwalacza wprowadź wartość ContainerName zgodną z nazwą kontenera magazynu utworzonego w wymaganiach wstępnych.
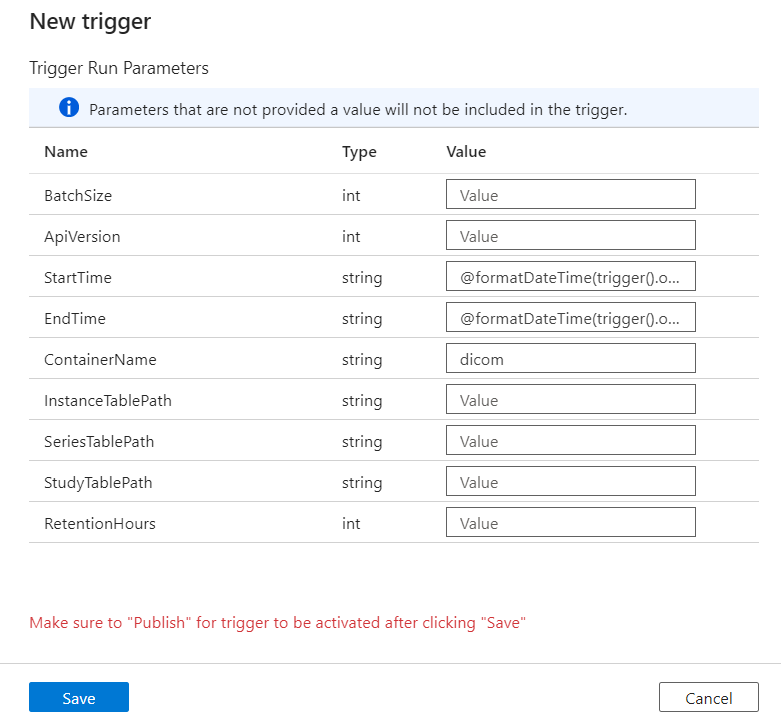
W obszarze StartTime użyj zmiennej systemowej
@formatDateTime(trigger().outputs.windowStartTime).W polu EndTime użyj zmiennej systemowej
@formatDateTime(trigger().outputs.windowEndTime).Wybierz pozycję Zapisz , aby utworzyć nowy wyzwalacz. Wybierz pozycję Publikuj , aby rozpocząć uruchamianie wyzwalacza zgodnie ze zdefiniowanym harmonogramem.


Po opublikowaniu wyzwalacza można go wyzwolić ręcznie przy użyciu opcji Wyzwól teraz . Jeśli godzina rozpoczęcia została ustawiona dla wartości w przeszłości, potok zostanie uruchomiony natychmiast.
Monitorowanie uruchomień potoku
Uruchomienia wyzwalacza i skojarzone z nimi uruchomienia potoku można monitorować na karcie Monitorowanie . W tym miejscu możesz przeglądać czas uruchamiania każdego potoku i czas jego uruchomienia. Możesz również potencjalnie debugować wszelkie utworzone problemy.

Microsoft Fabric
Sieć szkieletowa to rozwiązanie analityczne typu all-in-one, które znajduje się na platformie Microsoft OneLake. Korzystając z usługi Fabric lakehouse, można zarządzać danymi, strukturę i analizować je w usłudze OneLake w jednej lokalizacji. Wszystkie dane spoza usługi OneLake zapisane w usłudze Data Lake Storage Gen2 mogą być połączone z usługą OneLake jako skróty, aby korzystać z zestawu narzędzi usługi Fabric.
Tworzenie skrótów do tabel metadanych
Przejdź do lakehouse utworzonego w wymaganiach wstępnych. W widoku Eksploratora wybierz menu wielokropka (...) obok folderu Tabele.
Wybierz pozycję Nowy skrót , aby utworzyć nowy skrót do konta magazynu zawierającego dane analizy DICOM.
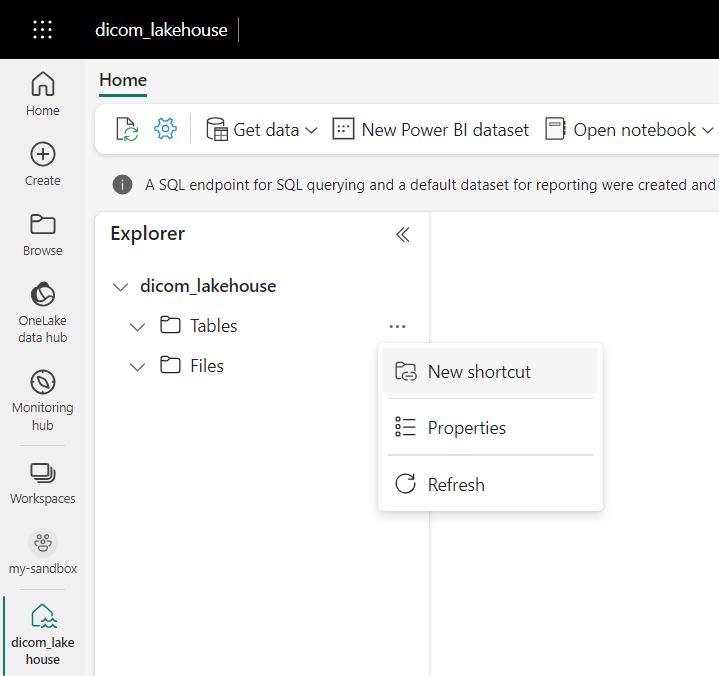
Wybierz pozycję Azure Data Lake Storage Gen2 jako źródło skrótu.
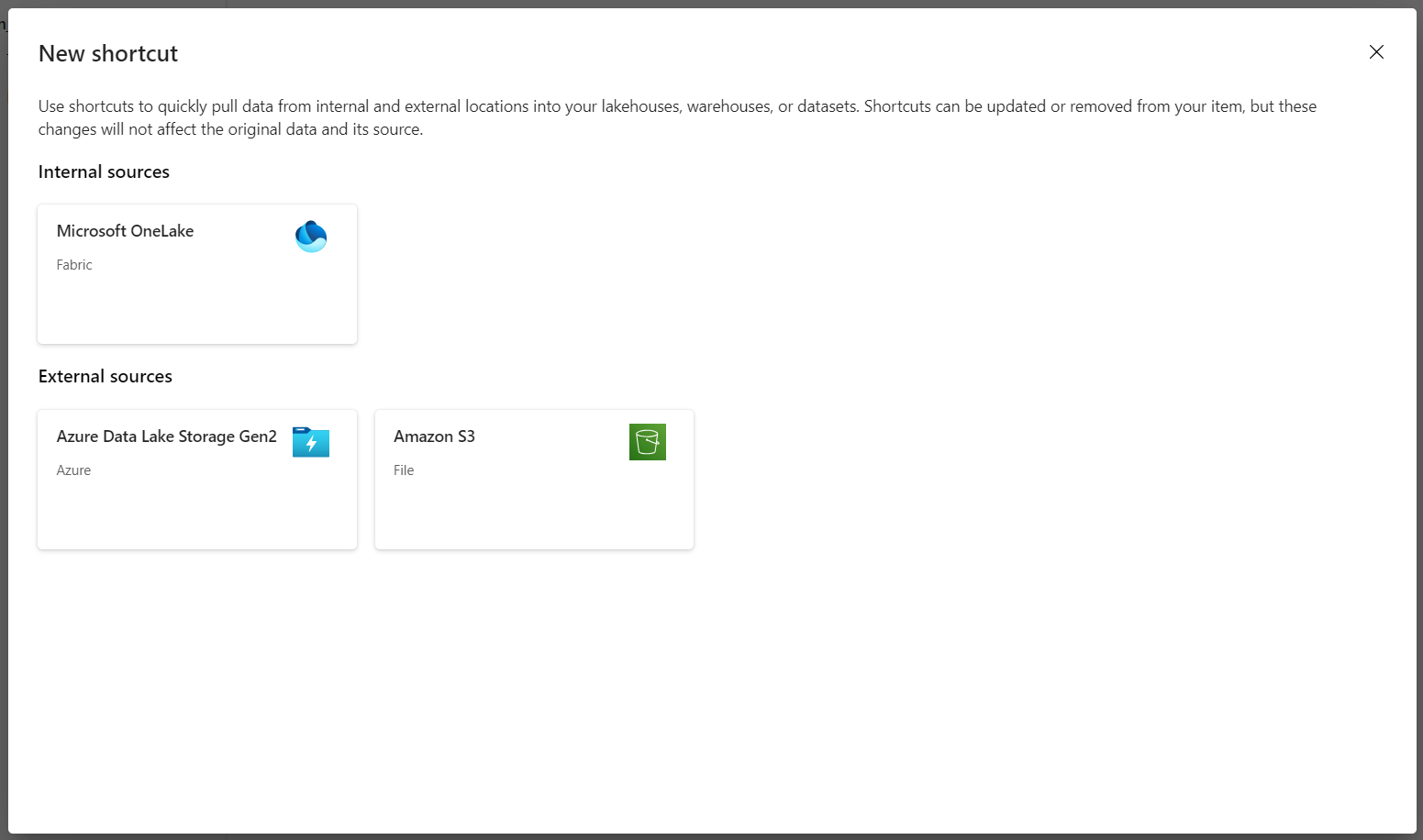
W obszarze ustawienia Połączenie ion wprowadź adres URL użyty w sekcji Połączone usługi.
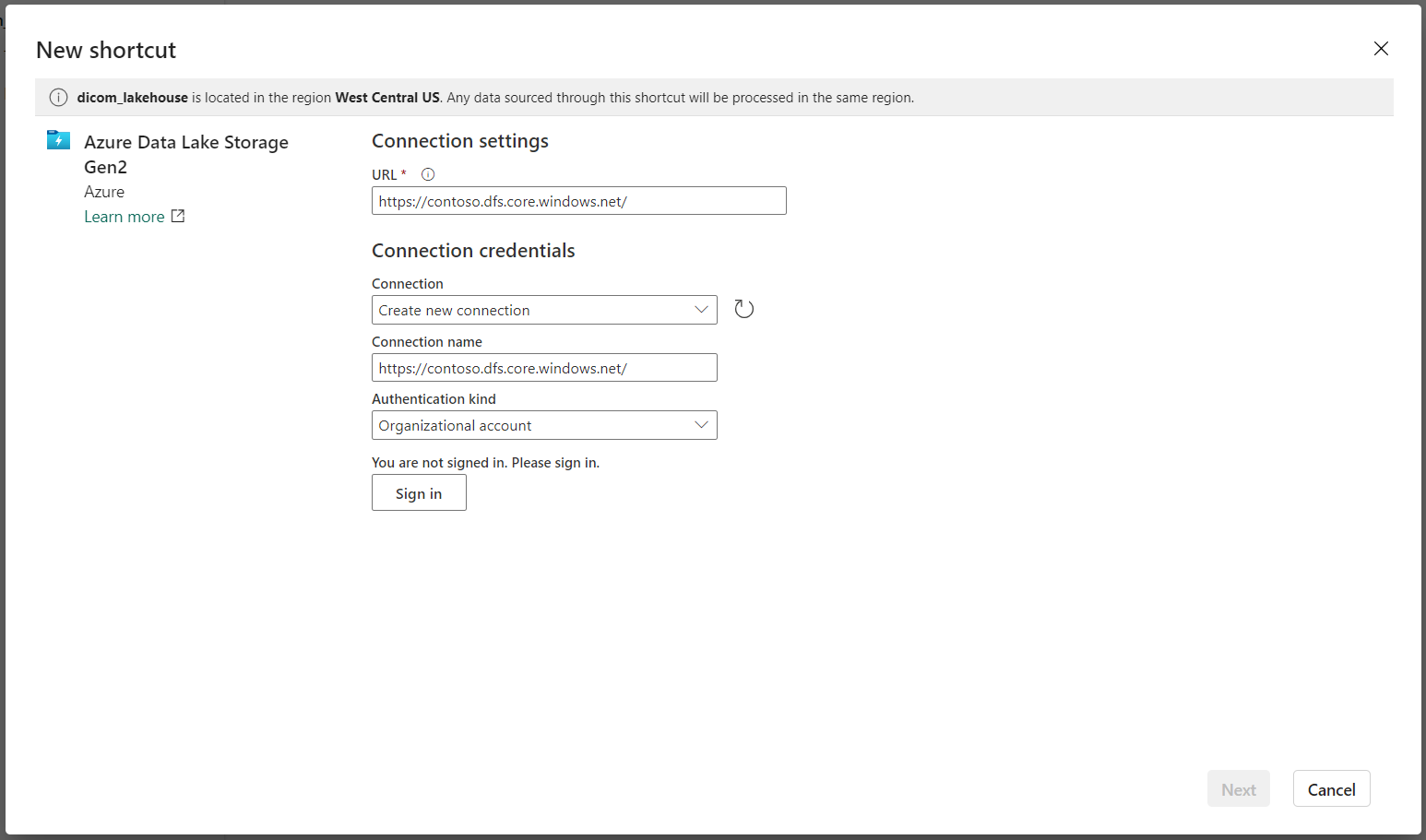
Wybierz istniejące połączenie lub utwórz nowe połączenie, wybierając rodzaj uwierzytelniania, którego chcesz użyć.
Uwaga
Istnieje kilka opcji uwierzytelniania między usługą Data Lake Storage Gen2 i siecią szkieletową. Możesz użyć konta organizacyjnego lub jednostki usługi. Nie zalecamy używania kluczy konta ani tokenów sygnatury dostępu współdzielonego.
Wybierz Dalej.
Wprowadź nazwę skrótu reprezentującą dane utworzone przez potok usługi Data Factory. Na przykład w przypadku tabeli delta nazwa skrótu
instancepowinna być prawdopodobnie wystąpieniem.Wprowadź ścieżkę podrzędną zgodną z parametrem
ContainerNamez konfiguracji parametrów uruchamiania i nazwę tabeli skrótu. Na przykład użyj polecenia/dicom/instancedla tabeli delta ze ścieżkąinstancew kontenerzedicom.Wybierz pozycję Utwórz , aby utworzyć skrót.
Powtórz kroki od 2 do 9, aby dodać pozostałe skróty do innych tabel delty na koncie magazynu (na przykład
seriesistudy).



Po utworzeniu skrótów rozwiń tabelę, aby wyświetlić nazwy i typy kolumn.

Tworzenie skrótów do plików
Jeśli używasz usługi DICOM z usługą Data Lake Storage, możesz dodatkowo utworzyć skrót do danych plików DICOM przechowywanych w usłudze Data Lake.
Przejdź do lakehouse utworzonego w wymaganiach wstępnych. W widoku Eksploratora wybierz menu wielokropka (...) obok folderu Pliki.
Wybierz pozycję Nowy skrót , aby utworzyć nowy skrót do konta magazynu zawierającego dane DICOM.
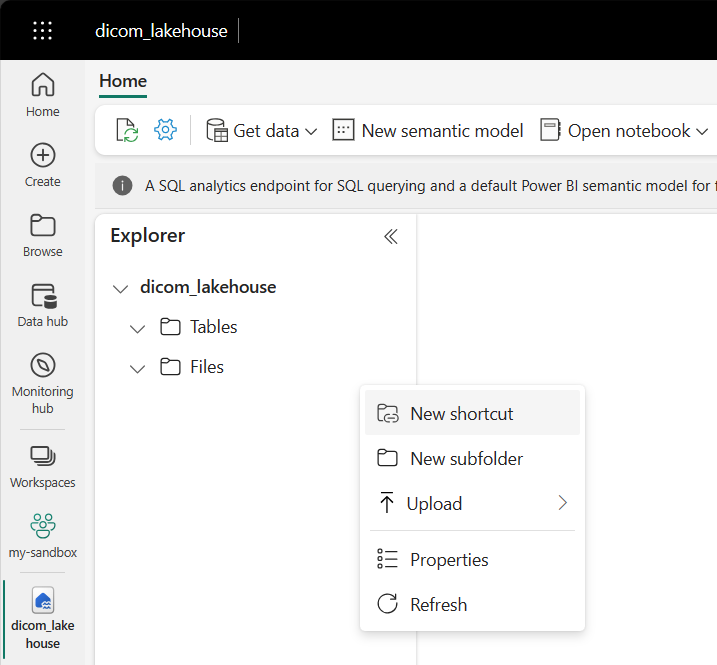
Wybierz pozycję Azure Data Lake Storage Gen2 jako źródło skrótu.
W obszarze ustawienia Połączenie ion wprowadź adres URL użyty w sekcji Połączone usługi.
Wybierz istniejące połączenie lub utwórz nowe połączenie, wybierając rodzaj uwierzytelniania, którego chcesz użyć.
Wybierz Dalej.
Wprowadź nazwę skrótu opisujący dane DICOM. Na przykład contoso-dicom-files.
Wprowadź ścieżkę podrzędną zgodną z nazwą kontenera magazynu i folderu używanego przez usługę DICOM. Jeśli na przykład chcesz połączyć się z folderem głównym, ścieżka podrzędna to /dicom/AHDS. Należy pamiętać, że folder główny jest zawsze
AHDS, ale opcjonalnie można połączyć się z folderem podrzędnym dla określonego obszaru roboczego lub wystąpienia usługi DICOM.Wybierz pozycję Utwórz , aby utworzyć skrót.


Uruchamianie notesów
Po utworzeniu tabel w usłudze Lakehouse można wykonywać zapytania względem nich z poziomu notesów usługi Fabric. Notesy można tworzyć bezpośrednio z usługi Lakehouse, wybierając pozycję Otwórz notes na pasku menu.
Na stronie notesu zawartość lakehouse nadal może być widoczna po lewej stronie, w tym nowo dodane tabele. W górnej części strony wybierz język notesu. Język można również skonfigurować dla poszczególnych komórek. W poniższym przykładzie użyto usługi Spark SQL.
Wykonywanie zapytań względem tabel przy użyciu usługi Spark SQL
W edytorze komórek wprowadź zapytanie Spark SQL, takie jak SELECT instrukcja.
SELECT * from instance
To zapytanie wybiera całą zawartość z instance tabeli. Gdy wszystko będzie gotowe, wybierz pozycję Uruchom komórkę , aby uruchomić zapytanie.

Po kilku sekundach wyniki zapytania pojawiają się w tabeli poniżej komórki, podobnie jak w przykładzie przedstawionym tutaj. Czas może być dłuższy, jeśli to zapytanie Spark jest pierwszym w sesji, ponieważ kontekst platformy Spark musi zostać zainicjowany.

Uzyskiwanie dostępu do danych plików DICOM w notesach
Jeśli użyto szablonu do utworzenia potoku i utworzenia skrótu do danych pliku DICOM, możesz użyć filePath kolumny w instance tabeli, aby skorelować metadane wystąpienia z danymi pliku.
SELECT sopInstanceUid, filePath from instance

Podsumowanie
W tym artykule zawarto informacje na temat wykonywania następujących czynności:
- Użyj szablonów usługi Data Factory, aby utworzyć potok z usługi DICOM do konta usługi Data Lake Storage Gen2.
- Skonfiguruj wyzwalacz, aby wyodrębnić metadane DICOM według harmonogramu godzinowego.
- Użyj skrótów, aby połączyć dane DICOM na koncie magazynu z usługą Fabric lakehouse.
- Użyj notesów, aby wykonywać zapytania dotyczące danych DICOM w lakehouse.
Następne kroki
Uwaga
DICOM® jest zastrzeżonym znakiem towarowym National Electrical Manufacturers Association for its Standards publikacji odnoszących się do cyfrowej komunikacji informacji medycznych.