Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
W usłudze Azure Machine Learning można używać monitorowania modeli do ciągłego śledzenia wydajności modeli uczenia maszynowego w środowisku produkcyjnym. Monitorowanie modelu zapewnia szeroki zakres sygnałów obserwacyjnych. Ostrzega również o potencjalnych problemach. Podczas monitorowania sygnałów i metryk wydajności modeli w środowisku produkcyjnym można ocenić krytyczne ryzyko związane z modelami. Możesz również zidentyfikować martwe punkty, które mogą niekorzystnie wpłynąć na Twoją firmę.
W tym artykule przedstawiono sposób wykonywania następujących zadań:
- Konfigurowanie wbudowanego i zaawansowanego monitorowania modeli wdrożonych w punktach końcowych online Azure Machine Learning
- Monitorowanie metryk wydajności modeli w środowisku produkcyjnym
- Monitorowanie modeli wdrożonych poza usługą Azure Machine Learning lub wdrożonych w punktach końcowych usługi Azure Machine Learning wsadowych
- Konfigurowanie niestandardowych sygnałów i metryk do użycia w monitorowaniu modelu
- Interpretowanie wyników monitorowania
- Integrowanie monitorowania modelu usługi Azure Machine Learning z usługą Azure Event Grid
Wymagania wstępne
Interfejs wiersza polecenia platformy Azure i
mlrozszerzenie interfejsu wiersza polecenia platformy Azure, zainstalowane i skonfigurowane. Aby uzyskać więcej informacji, zobacz Instalowanie i konfigurowanie interfejsu wiersza polecenia (wersja 2).Powłoka Bash lub zgodna powłoka, taka jak powłoka w systemie Linux lub Podsystem Windows dla systemu Linux. Przykłady Azure CLI w tym artykule przyjmują, że używasz tego typu powłoki.
Obszar roboczy usługi Azure Machine Learning. Aby uzyskać instrukcje dotyczące tworzenia obszaru roboczego, zobacz Konfigurowanie.
Konto użytkownika, które ma co najmniej jedną z następujących ról kontroli dostępu na podstawie ról (RBAC) platformy Azure:
- Rola właściciela obszaru roboczego usługi Azure Machine Learning
- Rola Współautor dla obszaru roboczego usługi Azure Machine Learning
- Rola niestandardowa, która ma
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*uprawnienia
Aby uzyskać więcej informacji, zobacz Zarządzanie dostępem do obszarów roboczych usługi Azure Machine Learning.
Aby monitorować punkt końcowy online zarządzany przez usługę Azure Machine Learning lub punkt końcowy online platformy Kubernetes:
Model wdrożony w punkcie końcowym online usługi Azure Machine Learning. Zarządzane punkty końcowe online i punkty końcowe online Kubernetes są wspierane. Aby uzyskać instrukcje dotyczące wdrażania modelu w punkcie końcowym online usługi Azure Machine Learning, zobacz Wdrażanie i ocenianie modelu uczenia maszynowego przy użyciu punktu końcowego online.
Zbieranie danych dla Twojego wdrożenia modelu jest włączone. Zbieranie danych można włączyć podczas kroku wdrażania dla punktów końcowych online usługi Azure Machine Learning. Aby uzyskać więcej informacji, zobacz Zbieranie danych produkcyjnych z modeli wdrożonych na potrzeby wnioskowania w czasie rzeczywistym.
Aby monitorować model wdrożony w punkcie końcowym wsadowym usługi Azure Machine Learning lub wdrożony poza usługą Azure Machine Learning:
- Sposób zbierania danych produkcyjnych i rejestrowania ich jako zasobu danych usługi Azure Machine Learning
- Metoda ciągłego aktualizowania zarejestrowanego zasobu danych na potrzeby monitorowania modelu
- (Zalecane) Rejestracja modelu w obszarze roboczym usługi Azure Machine Learning na potrzeby śledzenia pochodzenia
Konfigurowanie bezserwerowej puli obliczeniowej platformy Spark
Zaplanowano uruchamianie zadań monitorowania modelu w bezserwerowych pulach obliczeniowych platformy Spark. Obsługiwane są następujące typy wystąpień usługi Azure Virtual Machines:
- Standard_E4s_v3
- Standard_E8s_v3
- Standard_E16s_v3
- Standard_E32s_v3
- Standardowa_E64s_v3
Aby określić typ wystąpienia maszyny wirtualnej podczas wykonywania procedur opisanych w tym artykule, wykonaj następujące czynności:
Podczas tworzenia monitora przy użyciu interfejsu wiersza polecenia platformy Azure należy użyć pliku konfiguracji YAML. W tym pliku ustaw create_monitor.compute.instance_type wartość na typ, którego chcesz użyć.
Konfigurowanie gotowego do użycia monitorowania modelu
Rozważmy scenariusz, w którym wdrażasz model w środowisku produkcyjnym w punkcie końcowym online usługi Azure Machine Learning i włączasz zbieranie danych w czasie wdrażania. W takim przypadku usługa Azure Machine Learning zbiera dane wnioskowania produkcyjnego i automatycznie przechowuje je w usłudze Azure Blob Storage. Monitorowanie modelu usługi Azure Machine Learning umożliwia ciągłe monitorowanie tych danych wnioskowania produkcyjnego.
Możesz użyć interfejsu wiersza polecenia platformy Azure, zestawu SDK języka Python lub programu Studio na potrzeby gotowej konfiguracji monitorowania modelu. Konfiguracja monitorowania modelu gotowego do użycia zapewnia następujące możliwości monitorowania:
- Usługa Azure Machine Learning automatycznie wykrywa zasób danych wnioskowania produkcyjnego skojarzony z wdrożeniem online usługi Azure Machine Learning i używa zasobu danych do monitorowania modelu.
- Zasób danych referencyjnych porównania jest ustawiany jako ostatni, poprzedni zasób danych wnioskowania produkcyjnego.
- Konfiguracja monitorowania automatycznie obejmuje i śledzi następujące wbudowane sygnały monitorowania: dryf danych, dryf przewidywania i jakość danych. Dla każdego sygnału monitorowania usługa Azure Machine Learning używa:
- Najnowszy zasób danych dotyczący wnioskowania z wcześniejszej produkcji jako zasób danych referencyjnych do porównań.
- Inteligentne wartości domyślne metryk i progów.
- Zadanie monitorowania jest skonfigurowane do uruchamiania zgodnie z regularnym harmonogramem. To zadanie przechwytuje sygnały monitorujące i ocenia każdy rezultat metryki względem odpowiedniego progu. Domyślnie po przekroczeniu dowolnego progu usługa Azure Machine Learning wysyła wiadomość e-mail z alertem do użytkownika, który skonfigurował monitor.
Aby skonfigurować wbudowane monitorowanie modelu, wykonaj następujące kroki.
W interfejsie wiersza polecenia platformy Azure używa się az ml schedule do zaplanowania zadania monitorującego.
Utwórz definicję monitorowania w pliku YAML. Aby zobaczyć przykładową definicję gotową do użycia, zapoznaj się z następującym kodem YAML, który jest również dostępny w repozytorium azureml-examples.
Przed użyciem tej definicji dostosuj wartości, aby dopasować je do środowiska. Dla
endpoint_deployment_idużyj wartości w formacieazureml:<endpoint-name>:<deployment-name>.# out-of-box-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: credit_default_model_monitoring display_name: Credit default model monitoring description: Credit default model monitoring setup with minimal configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: # specify a spark compute for monitoring job instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification # model task type: [classification, regression, question_answering] endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id alert_notification: # emails to get alerts emails: - abc@example.com - def@example.comUruchom następujące polecenie, aby utworzyć model:
az ml schedule create -f ./out-of-box-monitoring.yaml


Konfigurowanie zaawansowanego monitorowania modelu
Usługa Azure Machine Learning oferuje wiele możliwości ciągłego monitorowania modeli. Aby uzyskać kompleksową listę tych funkcji, zobacz Możliwości monitorowania modeli. W wielu przypadkach należy skonfigurować monitorowanie modelu, które obsługuje zaawansowane zadania monitorowania. Poniższa sekcja zawiera kilka przykładów zaawansowanego monitorowania:
- Korzystanie z wielu sygnałów monitorowania dla szerokiego widoku
- Użycie historycznych danych trenowania modelu lub danych walidacji jako zasobu danych referencyjnych porównania
- Monitorowanie N najważniejszych funkcji i poszczególnych funkcji
Konfigurowanie ważności funkcji
Ważność funkcji reprezentuje względne znaczenie każdej funkcji wejściowej do danych wyjściowych modelu. Na przykład temperatura może być ważniejsza dla prognozy modelu niż wysokość. Po włączeniu istotności cech możesz zapewnić widoczność cech, które nie powinny powodować dryfowania lub problemów z jakością danych w produkcji.
Aby włączyć ważność cechy z dowolnymi sygnałami, takimi jak między innymi dryf danych lub jakość danych, należy podać następujące elementy:
- Twój zasób danych szkoleniowych jako
reference_datazasób danych. - Właściwość
reference_data.data_column_names.target_column, która jest nazwą kolumny wyjściowej modelu lub kolumny przewidywania.
Po włączeniu ważności cechy zobaczysz ważność cechy dla każdej cechy, którą monitorujesz w usłudze Azure Machine Learning Studio.
Alerty można włączać lub wyłączać dla każdego sygnału, ustawiając alert_enabled właściwość podczas korzystania z zestawu SDK języka Python lub interfejsu wiersza polecenia platformy Azure.
Do skonfigurowania zaawansowanego monitorowania modelu można użyć interfejsu wiersza polecenia platformy Azure, zestawu SDK języka Python lub programu Studio.
Utwórz definicję monitorowania w pliku YAML. Aby zapoznać się z przykładową definicją zaawansowaną, zobacz następujący kod YAML, który jest również dostępny w repozytorium azureml-examples.
Przed użyciem tej definicji dostosuj następujące ustawienia i inne, aby spełniały potrzeby środowiska:
- Dla
endpoint_deployment_idużyj wartości w formacieazureml:<endpoint-name>:<deployment-name>. - W odniesieniu do
pathsekcji danych wejściowych referencyjnych, należy użyć wartości w formacieazureml:<reference-data-asset-name>:<version>. - W przypadku
target_columnelementu użyj nazwy kolumny wyjściowej zawierającej wartości przewidywane przez model, na przykładDEFAULT_NEXT_MONTH. - W przypadku
features, wymień funkcje, takie jakSEX,EDUCATIONiAGE, które mają być używane w zaawansowanym sygnale jakości danych. - W obszarze
emailswyświetl listę adresów e-mail, których chcesz użyć w przypadku powiadomień.
# advanced-model-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with advanced configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:credit-default:main monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 # use training data as comparison reference dataset type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH features: top_n_feature_importance: 10 # monitor drift for top 10 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_data_quality: type: data_quality # reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training features: # monitor data quality for 3 individual features only - SEX - EDUCATION alert_enabled: true metric_thresholds: numerical: null_value_rate: 0.05 categorical: out_of_bounds_rate: 0.03 feature_attribution_drift_signal: type: feature_attribution_drift # production_data: is not required input here # Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data # Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH alert_enabled: true metric_thresholds: normalized_discounted_cumulative_gain: 0.9 alert_notification: emails: - abc@example.com - def@example.com- Dla
Uruchom następujące polecenie, aby utworzyć model:
az ml schedule create -f ./advanced-model-monitoring.yaml






Konfigurowanie monitorowania wydajności modelu
W przypadku korzystania z monitorowania modelu usługi Azure Machine Learning można śledzić wydajność modeli w środowisku produkcyjnym, obliczając ich metryki wydajności. Obecnie obsługiwane są następujące metryki wydajności modelu:
- W przypadku modeli klasyfikacji:
- Dokładność
- Dokładność
- Odwołaj
- W przypadku modeli regresji:
- Średni błąd bezwzględny (MAE)
- Błąd średniokwadratowy (MSE)
- Błąd średniokwadratowy (RMSE)
Wymagania wstępne dotyczące monitorowania wydajności modelu
Dane wyjściowe dla modelu produkcyjnego (przewidywania modelu) z unikatowym identyfikatorem dla każdego wiersza. Jeśli używasz modułu zbierającego dane Azure Machine Learning do zbierania danych produkcyjnych, dla każdego żądania wnioskowania zostanie Ci podany identyfikator korelacji. Moduł zbierający dane oferuje również możliwość rejestrowania własnego unikatowego identyfikatora z aplikacji.
Uwaga
W przypadku monitorowania wydajności modelu usługi Azure Machine Learning zalecamy, aby użyć kolektora danych Azure Machine Learning do rejestrowania unikatowego identyfikatora we własnej kolumnie.
Dane referencyjne (wartości rzeczywiste) z unikatowym identyfikatorem dla każdego wiersza. Unikatowy identyfikator danego wiersza powinien być zgodny z unikatowym identyfikatorem danych wyjściowych modelu dla tego konkretnego żądania wnioskowania. Ten unikatowy identyfikator służy do łączenia danych rzeczywistych z danymi wyjściowymi modelu.
Jeżeli nie masz danych rzeczywistych, nie możesz przeprowadzać monitorowania efektywności modelu. Rzeczywiste dane są napotykane na poziomie aplikacji, więc Twoim obowiązkiem jest ich zbieranie, gdy będą dostępne. Należy również zachować zasób danych w usłudze Azure Machine Learning, który zawiera te podstawowe dane prawdy.
(Opcjonalnie) Wstępnie złączony zasób danych tabelarycznych z wynikami modelu i danymi rzeczywistymi już połączonymi razem.
Wymagania dotyczące monitorowania wydajności modelu podczas korzystania z modułu zbierającego dane
Usługa Azure Machine Learning generuje identyfikator korelacji dla Użytkownika, gdy spełniasz następujące kryteria:
- Używasz kolektora danych Azure Machine Learning do zbierania danych dotyczących produkcji i wnioskowania.
- Nie podajesz własnego unikatowego identyfikatora dla każdego wiersza jako oddzielnej kolumny.
Wygenerowany identyfikator korelacji jest uwzględniony w rejestrowanym obiekcie JSON. Moduł zbierający dane grupuje jednak wiersze wysyłane w krótkim odstępie czasu. W tym samym obiekcie JSON znajdują się wiersze wsadowe. W każdym obiekcie wszystkie wiersze mają ten sam identyfikator korelacji.
Aby rozróżnić wiersze w obiekcie JSON, monitorowanie wydajności modelu usługi Azure Machine Learning używa indeksowania w celu określenia kolejności wierszy w obiekcie. Jeśli na przykład partia zawiera trzy wiersze, a identyfikator korelacji to test, pierwszy wiersz ma identyfikator test_0, drugi wiersz ma identyfikator test_1, a trzeci wiersz ma identyfikator test_2. Aby dopasować unikatowe identyfikatory danych podstawowych do identyfikatorów zebranych danych wyjściowych modelu produkcyjnego wnioskowania, należy odpowiednio zastosować indeks do każdego identyfikatora korelacji. Jeśli zarejestrowany obiekt JSON ma tylko jeden wiersz, użyj correlationid_0 jako wartości correlationid.
Aby uniknąć używania tego indeksowania, zalecamy zarejestrowanie unikalnego identyfikatora w oddzielnej kolumnie. Umieść tę kolumnę w ramce danych pandas, zapisywanej przez moduł zbierania danych usługi Azure Machine Learning. W konfiguracji monitorowania modelu można następnie określić nazwę tej kolumny, aby połączyć dane wyjściowe modelu z danymi rzeczywistymi. Tak długo, jak identyfikatory wierszy w obu zasobach danych są takie same, monitorowanie modelu Azure Machine Learning może przeprowadzać monitorowanie wydajności modeli.
Przykładowy przepływ pracy monitorowania wydajności modelu
Aby zrozumieć pojęcia związane z monitorowaniem wydajności modelu, rozważ poniższy przykładowy przepływ pracy. Dotyczy scenariusza, w którym wdrażasz model w celu przewidywania, czy transakcje kart kredytowych są fałszywe:
- Skonfiguruj wdrożenie tak, aby używało modułu zbierającego dane w celu zbierania danych wnioskowania produkcyjnego modelu (danych wejściowych i wyjściowych). Zapisz dane wyjściowe w kolumnie o nazwie
is_fraud. - Dla każdego wiersza zebranych danych wnioskowania zarejestruj unikatowy identyfikator. Unikatowy identyfikator może pochodzić z aplikacji lub użyć
correlationidwartości, którą usługa Azure Machine Learning unikatowo generuje dla każdego zarejestrowanego obiektu JSON. - Gdy dostępne są dane rzeczywiste,
is_fraudzarejestruj i zamapuj każdy wiersz na ten sam unikatowy identyfikator, który jest logowany dla odpowiedniego wiersza w danych wyjściowych modelu. - Zarejestruj zasób danych w usłudze Azure Machine Learning i użyj go do zbierania oraz zarządzania danymi prawdziwymi
is_fraud. - Utwórz sygnał monitorowania wydajności modelu, który wykorzystuje unikatowe kolumny identyfikatorów do łączenia wyników inferencji modelu z rzeczywistymi danymi prawdziwymi.
- Oblicz metryki wydajności modelu.
Po spełnieniu wymagań wstępnych dotyczących monitorowania wydajności modelu wykonaj następujące kroki, aby skonfigurować monitorowanie modelu:
Utwórz definicję monitorowania w pliku YAML. Poniższa przykładowa specyfikacja definiuje monitorowanie modelu przy użyciu danych wnioskowania produkcyjnego. Przed użyciem tej definicji dostosuj następujące ustawienia i inne, aby spełniały potrzeby środowiska:
- Dla
endpoint_deployment_idużyj wartości w formacieazureml:<endpoint-name>:<deployment-name>. - Dla każdej
pathwartości w sekcji danych wejściowych użyj wartości w formacieazureml:<data-asset-name>:<version>. -
predictionDla wartości użyj nazwy kolumny wyjściowej zawierającej wartości przewidywane przez model. -
actualDla wartości użyj nazwy kolumny podstawy prawdy zawierającej rzeczywiste wartości, które próbuje przewidzieć model. - Dla wartości
correlation_idużyj nazw kolumn, które są wykorzystywane do łączenia danych wyjściowych z danymi rzeczywistymi. - W obszarze
emailswyświetl listę adresów e-mail, których chcesz użyć w przypadku powiadomień.
# model-performance-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: model_performance_monitoring display_name: Credit card fraud model performance description: Credit card fraud model performance trigger: type: recurrence frequency: day interval: 7 schedule: hours: 10 minutes: 15 create_monitor: compute: instance_type: standard_e8s_v3 runtime_version: "3.3" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment monitoring_signals: fraud_detection_model_performance: type: model_performance production_data: input_data: path: azureml:credit-default-main-model_outputs:1 type: mltable data_column_names: prediction: is_fraud correlation_id: correlation_id reference_data: input_data: path: azureml:my_model_ground_truth_data:1 type: mltable data_column_names: actual: is_fraud correlation_id: correlation_id data_context: ground_truth alert_enabled: true metric_thresholds: tabular_classification: accuracy: 0.95 precision: 0.8 alert_notification: emails: - abc@example.com- Dla
Uruchom następujące polecenie, aby utworzyć model:
az ml schedule create -f ./model-performance-monitoring.yaml





Konfigurowanie monitorowania modelu danych produkcyjnych
Można również monitorować modele, które wdrażasz do wsadowych punktów końcowych Azure Machine Learning lub które są wdrażane poza usługą Azure Machine Learning. Jeśli nie masz wdrożenia, ale masz dane produkcyjne, możesz użyć tych danych do ciągłego monitorowania modelu. Aby monitorować te modele, musisz mieć możliwość:
- Zbieranie danych wnioskowania produkcyjnego z modeli wdrożonych w środowisku produkcyjnym.
- Zarejestruj dane wnioskowania produkcyjnego jako zasób danych usługi Azure Machine Learning i zapewnij ciągłe aktualizacje danych.
- Podaj niestandardowy składnik przetwarzania wstępnego danych i zarejestruj go jako składnik usługi Azure Machine Learning, jeśli nie używasz modułu zbierającego dane do zbierania danych. Bez tego niestandardowego składnika przetwarzania wstępnego danych system monitorowania modelu usługi Azure Machine Learning nie może przetworzyć danych w formie tabelarycznej, która obsługuje przedziały czasu.
Niestandardowy składnik przetwarzania wstępnego musi mieć następujące podpisy wejściowe i wyjściowe:
| Dane wejściowe lub wyjściowe | Nazwa podpisu | Typ | Opis | Przykładowa wartość |
|---|---|---|---|---|
| dane wejściowe | data_window_start |
Literału | Godzina rozpoczęcia okna danych w formacie ISO8601 | 2023-05-01T04:31:57.012Z |
| dane wejściowe | data_window_end |
Literału | Godzina zakończenia okna danych w formacie ISO8601 | 2023-05-01T04:31:57.012Z |
| dane wejściowe | input_data |
uri_folder | Zebrane dane wnioskowania produkcyjnego zarejestrowane jako zasób danych usługi Azure Machine Learning | azureml:myproduction_dane_inferencyjne:1 |
| We/Wy | preprocessed_data |
mltable | Zasób danych tabelarycznych pasujący do podzestawu schematu danych referencyjnych |
Aby zapoznać się z przykładem niestandardowego składnika przetwarzania wstępnego danych, zobacz custom_preprocessing w repozytorium GitHub azuremml-examples.
Aby uzyskać instrukcje dotyczące rejestrowania składnika usługi Azure Machine Learning, zobacz Rejestrowanie składnika w obszarze roboczym.
Po zarejestrowaniu danych produkcyjnych i składnika przetwarzania wstępnego można skonfigurować monitorowanie modelu.
Utwórz plik YAML definicji monitorowania podobny do poniższego. Przed użyciem tej definicji dostosuj następujące ustawienia i inne, aby spełniały potrzeby środowiska:
- Dla
endpoint_deployment_idużyj wartości w formacieazureml:<endpoint-name>:<deployment-name>. - Dla
pre_processing_componentużyj wartości w formacieazureml:<component-name>:<component-version>. Określ dokładną wersję, taką jak1.0.0, a nie1. - Dla każdego
pathelementu użyj wartości w formacieazureml:<data-asset-name>:<version>. -
target_columnDla wartości użyj nazwy kolumny wyjściowej zawierającej wartości przewidywane przez model. - W obszarze
emailswyświetl listę adresów e-mail, których chcesz użyć w przypadku powiadomień.
# model-monitoring-with-collected-data.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with your own production data trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_inputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_training_data:1 # use training data as comparison baseline type: mltable data_context: training data_column_names: target_column: is_fraud features: top_n_feature_importance: 20 # monitor drift for top 20 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_prediction_drift: # monitoring signal name, any user defined name works type: prediction_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_outputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset type: mltable data_context: validation alert_enabled: true metric_thresholds: categorical: pearsons_chi_squared_test: 0.02 alert_notification: emails: - abc@example.com - def@example.com- Dla
Uruchom następujące polecenie, aby utworzyć model.
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
Konfigurowanie monitorowania modelu przy użyciu niestandardowych sygnałów i metryk
W przypadku korzystania z monitorowania modelu usługi Azure Machine Learning można zdefiniować niestandardowy sygnał i zaimplementować dowolną wybraną metrykę do monitorowania modelu. Możesz zarejestrować niestandardowy sygnał jako składnik usługi Azure Machine Learning. Gdy zadanie monitorowania modelu jest uruchamiane zgodnie z określonym harmonogramem, oblicza metryki zdefiniowane w ramach sygnału niestandardowego, podobnie jak w przypadku dryfu danych, dryfu przewidywania i wstępnie zdefiniowanych sygnałów jakości danych.
Aby skonfigurować niestandardowy sygnał do użycia na potrzeby monitorowania modelu, należy najpierw zdefiniować sygnał niestandardowy i zarejestrować go jako składnik usługi Azure Machine Learning. Składnik usługi Azure Machine Learning musi mieć następujące podpisy wejściowe i wyjściowe.
Podpis wejściowy składnika
Ramka danych wejściowych składnika powinna zawierać następujące elementy:
- Struktura zawierająca dane przetworzone przez
mltablekomponent przetwarzania wstępnego. - Dowolna liczba literałów, z których każda reprezentuje zaimplementowaną metryki w ramach niestandardowego składnika sygnału. Jeśli na przykład zaimplementujesz metrykę
std_deviation, potrzebujesz danych wejściowych dla metrykistd_deviation_threshold. Generalnie, powinno istnieć jedno dane wejściowe o nazwie<metric-name>_thresholdna każdą metrykę.
| Nazwa podpisu | Typ | Opis | Przykładowa wartość |
|---|---|---|---|
production_data |
mltable | Zasób danych tabelarycznych pasujący do podzestawu schematu danych referencyjnych | |
std_deviation_threshold |
Literału | Odpowiedni próg dla zaimplementowanej metryki | 2 |
Podpis wyjściowy składnika
Port wyjściowy składnika powinien mieć następujący podpis:
| Nazwa podpisu | Typ | Opis |
|---|---|---|
signal_metrics |
mltable | Struktura mltable zawierająca obliczone metryki. Aby zapoznać się ze schematem tego podpisu, zobacz następną sekcję signal_metrics schematu. |
schemat signal_metrics
Ramka danych wyjściowych składnika powinna zawierać cztery kolumny: group, , metric_namemetric_valuei threshold_value.
| Nazwa podpisu | Typ | Opis | Przykładowa wartość |
|---|---|---|---|
group |
Literału | Grupowanie logiczne najwyższego poziomu, które należy zastosować do metryki niestandardowej | KWOTA TRANSAKCJI |
metric_name |
Literału | Nazwa metryki niestandardowej | odchylenie_standardowe |
metric_value |
numeryczny | Wartość metryki niestandardowej | 44,896.082 |
threshold_value |
numeryczny | Próg metryki niestandardowej | 2 |
W poniższej tabeli przedstawiono przykładowe dane wyjściowe z niestandardowego składnika sygnału, który oblicza metrykę std_deviation :
| grupa | metric_value | metric_name | wartość progowa |
|---|---|---|---|
| KWOTA TRANSAKCJI | 44,896.082 | odchylenie_standardowe | 2 |
| LOCALHOUR | 3.983 | odchylenie_standardowe | 2 |
| KWOTATRANSAKCJIUSD | 54 004,902 | odchylenie_standardowe | 2 |
| DIGITALITEMCOUNT | 7.238 | odchylenie_standardowe | 2 |
| Fizyczna Ilość Przedmiotów | 5.509 | odchylenie_standardowe | 2 |
Aby zapoznać się z przykładem niestandardowej definicji składnika sygnału i kodu obliczeniowego metryki, zobacz custom_signal w repozytorium azureml-examples.
Aby uzyskać instrukcje dotyczące rejestrowania składnika usługi Azure Machine Learning, zobacz Rejestrowanie składnika w obszarze roboczym.
Po utworzeniu i zarejestrowaniu niestandardowego składnika sygnału w usłudze Azure Machine Learning wykonaj następujące kroki, aby skonfigurować monitorowanie modelu:
Utwórz definicję monitorowania w pliku YAML podobnym do poniższego. Przed użyciem tej definicji dostosuj następujące ustawienia i inne, aby spełniały potrzeby środowiska:
- Dla
component_idużyj wartości w formacieazureml:<custom-signal-name>:1.0.0. - W sekcji
pathdanych wejściowych użyj wartości w formacieazureml:<production-data-asset-name>:<version>. - Dla elementu
pre_processing_component:- Jeśli używasz modułu zbierającego dane do zbierania danych, możesz pominąć
pre_processing_componentwłaściwość . - Jeśli nie używasz modułu zbierającego dane i chcesz użyć składnika do wstępnego przetwarzania danych produkcyjnych, użyj wartości w formacie
azureml:<custom-preprocessor-name>:<custom-preprocessor-version>.
- Jeśli używasz modułu zbierającego dane do zbierania danych, możesz pominąć
- W obszarze
emailswyświetl listę adresów e-mail, których chcesz użyć w przypadku powiadomień.
# custom-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: my-custom-signal trigger: type: recurrence frequency: day # Possible frequency values include "minute," "hour," "day," "week," and "month." interval: 7 # Monitoring runs every day when you use the value 1. create_monitor: compute: instance_type: "standard_e4s_v3" runtime_version: "3.3" monitoring_signals: customSignal: type: custom component_id: azureml:my_custom_signal:1.0.0 input_data: production_data: input_data: type: uri_folder path: azureml:my_production_data:1 data_context: test data_window: lookback_window_size: P30D lookback_window_offset: P7D pre_processing_component: azureml:custom_preprocessor:1.0.0 metric_thresholds: - metric_name: std_deviation threshold: 2 alert_notification: emails: - abc@example.com- Dla
Uruchom następujące polecenie, aby utworzyć model:
az ml schedule create -f ./custom-monitoring.yaml
Interpretowanie wyników monitorowania
Po skonfigurowaniu monitora modelu i zakończeniu pierwszego uruchomienia możesz wyświetlić wyniki w usłudze Azure Machine Learning Studio.
W studio w obszarze Zarządzanie wybierz pozycję Monitorowanie. Na stronie Monitorowanie wybierz nazwę monitora modelu, aby wyświetlić jego stronę przeglądu. Na tej stronie przedstawiono model monitorowania, punkt końcowy i wdrożenie. Zawiera on również szczegółowe informacje o skonfigurowanych sygnałach. Na poniższej ilustracji przedstawiono stronę przeglądu monitorowania zawierającą sygnały dotyczące dryfu danych i jakości danych.
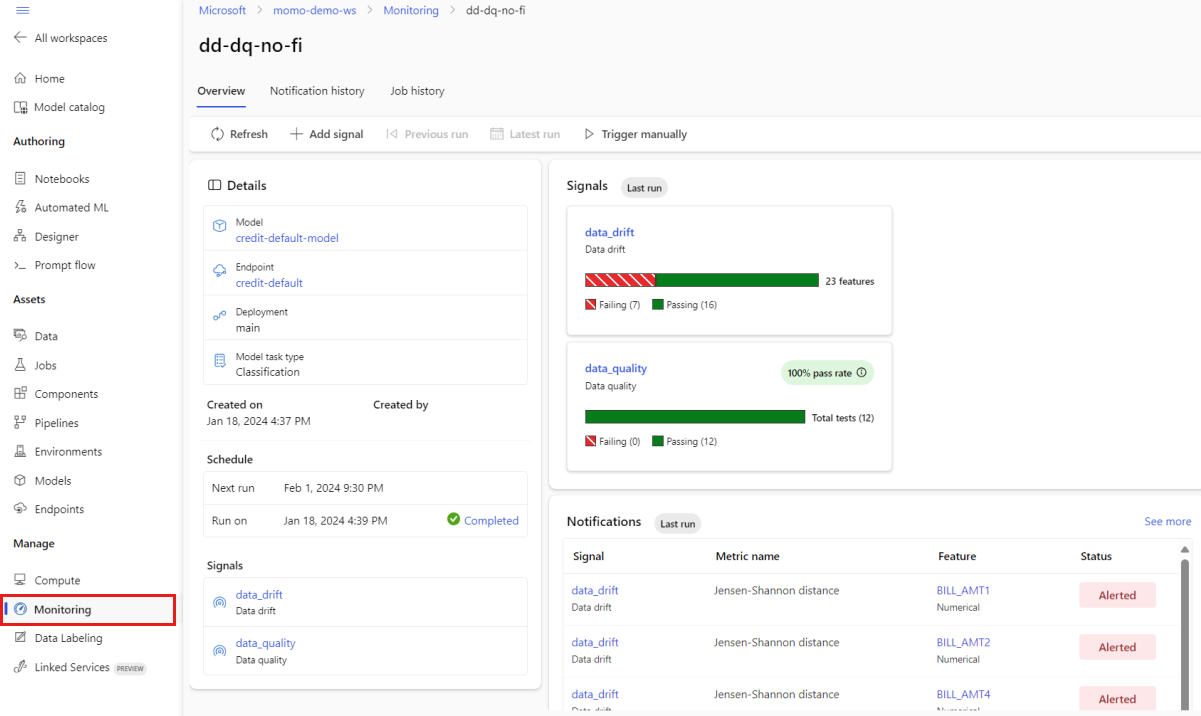
Zapoznaj się z sekcją Powiadomienia na stronie przeglądu. W tej sekcji można zobaczyć funkcję dla każdego sygnału, który narusza skonfigurowany próg dla odpowiedniej metryki.
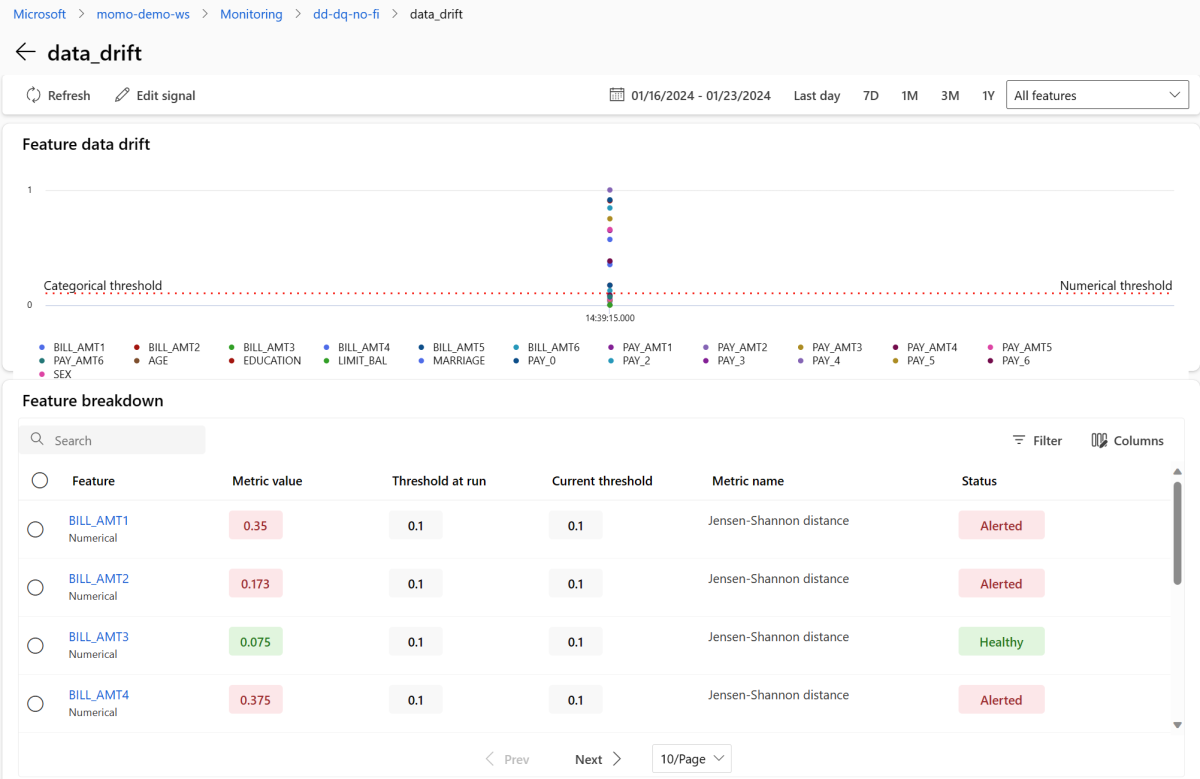
W sekcji Sygnały wybierz pozycję data_drift , aby wyświetlić szczegółowe informacje na temat sygnału dryfu danych. Na stronie szczegółów można zobaczyć wartość metryki dryfu danych dla każdej funkcji liczbowej i kategorii uwzględnionej przez konfigurację monitorowania. Jeśli monitor ma więcej niż jedną sesję, zobaczysz linię trendu dla każdej cechy.
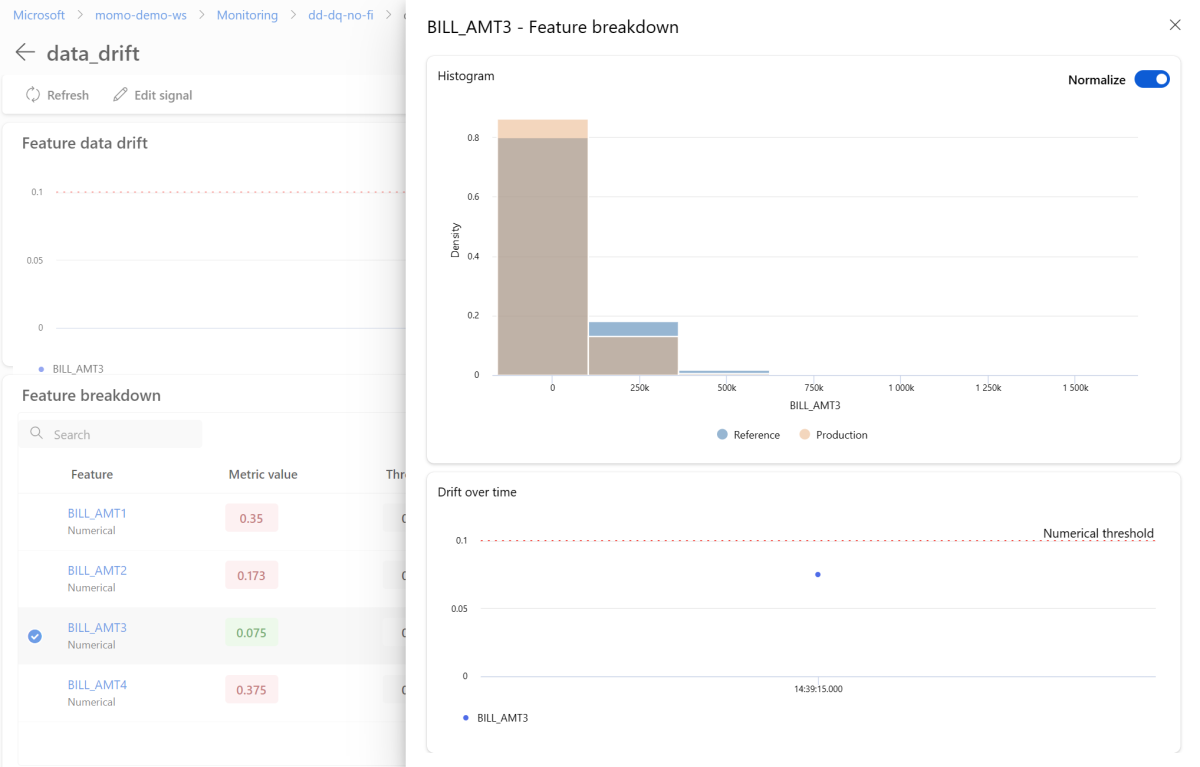
Na stronie szczegółów wybierz nazwę pojedynczej funkcji. Zostanie otwarty szczegółowy widok przedstawiający dystrybucję produkcyjną w porównaniu z dystrybucją referencyjną. Możesz również użyć tego widoku do śledzenia dryfu w czasie dla funkcji.
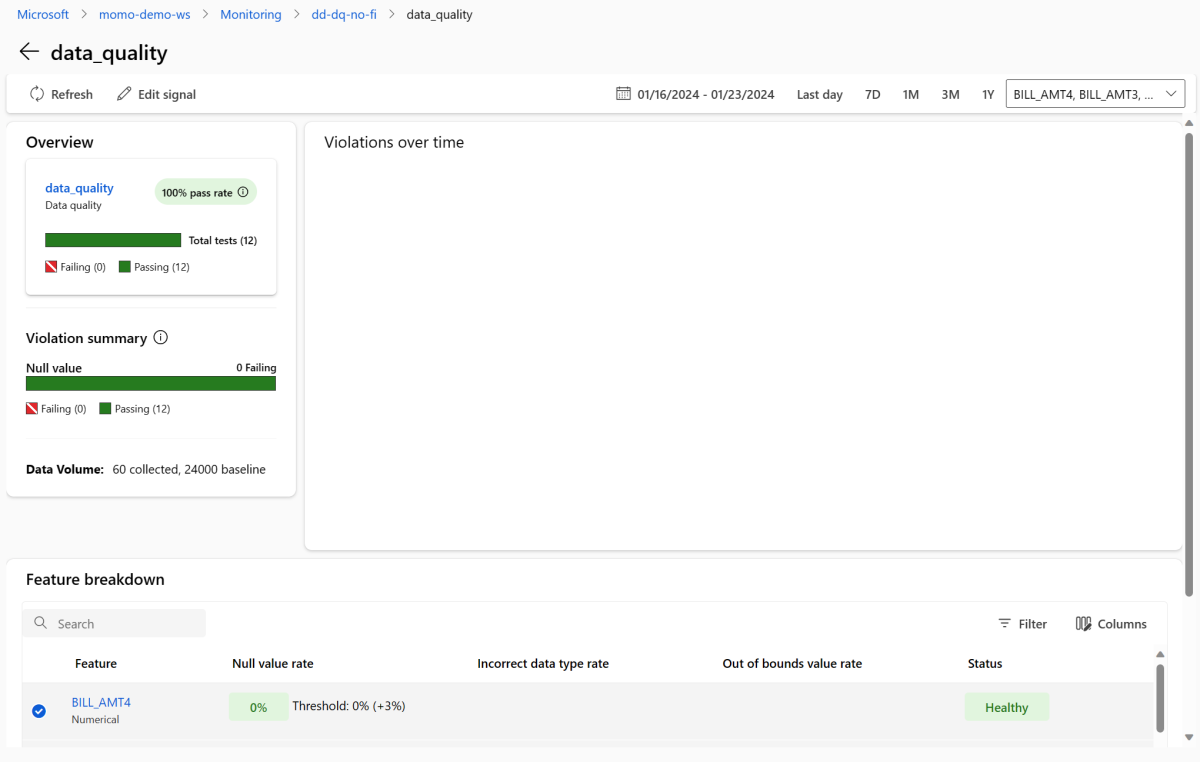
Wróć do strony przeglądu monitorowania. W sekcji Sygnały wybierz pozycję data_quality , aby wyświetlić szczegółowe informacje o tym sygnałie. Na tej stronie można zobaczyć współczynniki wartości null, wartości poza granicami oraz współczynniki błędów typów danych dla każdej monitorowanej cechy.




Monitorowanie modelu jest procesem ciągłym. W przypadku korzystania z monitorowania modelu usługi Azure Machine Learning można skonfigurować wiele sygnałów monitorowania w celu uzyskania szerokiego wglądu w wydajność modeli w środowisku produkcyjnym.
Integrowanie monitorowania modelu usługi Azure Machine Learning z usługą Event Grid
Korzystając z Event Grid, można skonfigurować zdarzenia generowane przez monitorowanie modelu Azure Machine Learning, które uruchamiają aplikacje, procesy oraz przepływy pracy CI/CD. Można odbierać zdarzenia za pośrednictwem różnych programów obsługi zdarzeń, takich jak Azure Event Hubs, Azure Functions i Azure Logic Apps. Gdy monitory wykrywają dryf, można podjąć działania programowo, na przykład uruchamiając potok uczenia maszynowego, aby ponownie wytrenować model i wdrożyć go ponownie.
Aby zintegrować monitorowanie modelu usługi Azure Machine Learning z usługą Event Grid, wykonaj kroki opisane w poniższych sekcjach.
Tworzenie tematu systemowego
Jeśli nie masz tematu systemu usługi Event Grid do użycia do monitorowania, utwórz go. Aby uzyskać instrukcje, zobacz Tworzenie, wyświetlanie i zarządzanie tematami systemu usługi Event Grid w witrynie Azure Portal.
Tworzenie subskrypcji zdarzeń
W witrynie Azure Portal przejdź do obszaru roboczego usługi Azure Machine Learning.
Wybierz opcję Zdarzenia, a następnie wybierz opcję Subskrypcja zdarzeń.
Obok pozycji Nazwa wprowadź nazwę subskrypcji zdarzeń, taką jak MonitoringEvent.
W obszarze Typy zdarzeń wybierz tylko Zmieniono stan uruchomienia.
Ostrzeżenie
Wybierz tylko stan uruchomienia zmieniony dla typu zdarzenia. Nie wybieraj Wykryto dryf zestawu danych, który odnosi się do dryfu danych w wersji 1, a nie do monitorowania modelu Azure Machine Learning.
Wybierz kartę Filtry . W obszarze Filtry zaawansowane wybierz pozycję Dodaj nowy filtr, a następnie wprowadź następujące wartości:
- W obszarze Klucz wprowadź dane. RunTags.azureml_modelmonitor_threshold_breached.
- Pod Operatorem wybierz opcję Ciąg zawiera.
- W obszarze Wartość wprowadź nie powiodło się z powodu co najmniej jednej funkcji naruszającej progi metryk.

Gdy używasz tego filtru, zdarzenia są generowane, gdy stan uruchomienia dowolnego monitora w obszarze roboczym usługi Azure Machine Learning ulegnie zmianie. Stan uruchomienia może ulec zmianie z ukończonego na niepowodzeniem lub z niepowodzenia na ukończone.
Aby filtrować na poziomie monitorowania, wybierz ponownie pozycję Dodaj nowy filtr , a następnie wprowadź następujące wartości:
- W obszarze Klucz wprowadź dane. RunTags.azureml_modelmonitor_threshold_breached.
- Pod Operatorem wybierz opcję Ciąg zawiera.
- W obszarze Wartość wprowadź nazwę sygnału monitora, dla którego chcesz filtrować zdarzenia, takie jak credit_card_fraud_monitor_data_drift. Wprowadzona nazwa musi być zgodna z nazwą sygnału monitorowania. Każdy sygnał używany w filtrowaniu powinien mieć nazwę w formacie
<monitor-name>_<signal-description>zawierającym nazwę monitora i opis sygnału.
Wybierz kartę Podstawowe . Skonfiguruj punkt końcowy, który ma służyć jako program obsługi zdarzeń, taki jak Event Hubs.
Wybierz pozycję Utwórz , aby utworzyć subskrypcję zdarzeń.

Wyświetl zdarzenia
Po przechwyceniu zdarzeń można je wyświetlić na stronie punktu końcowego programu obsługi zdarzeń:

Zdarzenia można również wyświetlić na karcie Metryki usługi Azure Monitor:
