Zautomatyzowane uczenie maszynowe (AutoML)?
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
Zautomatyzowane uczenie maszynowe, nazywane również zautomatyzowanym uczeniem maszynowym lub rozwiązaniem AutoML, to proces automatyzacji czasochłonnych, iteracyjnych zadań tworzenia modelu uczenia maszynowego. Umożliwia ona analitykom danych, analitykom i deweloperom tworzenie modeli uczenia maszynowego o wysokiej skali, wydajności i produktywności przy jednoczesnym utrzymaniu jakości modelu. Zautomatyzowane uczenie maszynowe w usłudze Azure Machine Learning opiera się na przełomie naszego działu badań firmy Microsoft.
Tradycyjne opracowywanie modeli uczenia maszynowego wymaga dużej ilości zasobów, co wymaga dużej wiedzy i czasu na tworzenie i porównywanie dziesiątek modeli. Dzięki zautomatyzowanemu uczeniu maszynowemu przyspieszysz czas potrzebny na uzyskanie gotowych do produkcji modeli uczenia maszynowego z dużą łatwością i wydajnością.
Sposoby korzystania z rozwiązania AutoML w usłudze Azure Machine Learning
Usługa Azure Machine Learning oferuje następujące dwa środowiska do pracy z zautomatyzowanym uczeniem maszynowym. Zapoznaj się z poniższymi sekcjami, aby zrozumieć dostępność funkcji w każdym środowisku (wersja 1).
W przypadku klientów korzystających z kodu zestaw SDK języka Python usługi Azure Machine Learning. Wprowadzenie do samouczka: korzystanie ze zautomatyzowanego uczenia maszynowego do przewidywania opłat za taksówkę (wersja 1).
W przypadku klientów korzystających z ograniczonej/braku kodu Azure Machine Learning studio pod adresem https://ml.azure.com. Rozpocznij pracę z następującymi samouczkami:
Ustawienia eksperymentu
Poniższe ustawienia umożliwiają skonfigurowanie eksperymentu zautomatyzowanego uczenia maszynowego.
| Zestaw SDK języka Python | Środowisko internetowe programu Studio | |
|---|---|---|
| Dzielenie danych na zestawy trenowania/walidacji | ✓ | ✓ |
| Obsługuje zadania uczenia maszynowego: klasyfikacja, regresja, & prognozowanie | ✓ | ✓ |
| Obsługuje zadania przetwarzania obrazów: klasyfikacja obrazów, segmentacja wystąpienia wykrywania & obiektów | ✓ | |
| Optymalizuje na podstawie podstawowej metryki | ✓ | ✓ |
| Obsługuje zasoby obliczeniowe usługi Azure Machine Learning jako docelowy obiekt obliczeniowy | ✓ | ✓ |
| Konfigurowanie horyzontu prognozy, okna kroczącego & opóźnień docelowych | ✓ | ✓ |
| Ustawianie kryteriów zakończenia | ✓ | ✓ |
| Ustawianie iteracji współbieżnych | ✓ | ✓ |
| Usuwanie kolumn | ✓ | ✓ |
| Blokuj algorytmy | ✓ | ✓ |
| Krzyżowa walidacja | ✓ | ✓ |
| Obsługuje szkolenie w klastrach usługi Azure Databricks | ✓ | |
| Wyświetlanie nazw funkcji zaprojektowanych | ✓ | |
| Podsumowanie cechowania | ✓ | |
| Cechowanie świąt | ✓ | |
| Poziomy szczegółowości pliku dziennika | ✓ |
Ustawienia modelu
Te ustawienia można zastosować do najlepszego modelu w wyniku eksperymentu zautomatyzowanego uczenia maszynowego.
| Zestaw SDK języka Python | Środowisko internetowe programu Studio | |
|---|---|---|
| Najlepsza rejestracja modelu, wdrożenie, objaśnienie | ✓ | ✓ |
| Włączanie modeli stosu stosu dla zespołu głosowego & | ✓ | ✓ |
| Pokaż najlepszy model na podstawie metryki innej niż podstawowa | ✓ | |
| Włączanie/wyłączanie zgodności modelu ONNX | ✓ | |
| Testowanie modelu | ✓ | • (wersja zapoznawcza) |
Ustawienia sterowania zadaniami
Te ustawienia umożliwiają przeglądanie i kontrolowanie zadań eksperymentu oraz zadań podrzędnych.
| Zestaw SDK języka Python | Środowisko internetowe programu Studio | |
|---|---|---|
| Tabela podsumowania zadań | ✓ | ✓ |
| Anulowanie zadań & podrzędnych | ✓ | ✓ |
| Uzyskiwanie barier ochronnych | ✓ | ✓ |
| Wstrzymywanie zadań wznawiania & | ✓ |
Kiedy używać rozwiązania AutoML: klasyfikacja, regresja, prognozowanie, przetwarzanie obrazów & NLP
Zastosuj zautomatyzowane uczenie maszynowe, jeśli chcesz, aby usługa Azure Machine Learning trenowała i dostrajała model przy użyciu określonej metryki docelowej. Zautomatyzowane uczenie maszynowe demokratyzuje proces opracowywania modelu uczenia maszynowego i umożliwia użytkownikom, bez względu na ich wiedzę na temat nauki o danych, zidentyfikowanie kompleksowego potoku uczenia maszynowego dla dowolnego problemu.
Specjaliści ml i deweloperzy w różnych branżach mogą używać zautomatyzowanego uczenia maszynowego do:
- Implementowanie rozwiązań uczenia maszynowego bez obszernej wiedzy programistycznej
- Oszczędzaj czas i zasoby
- Korzystanie z najlepszych rozwiązań dotyczących nauki o danych
- Zapewnianie elastycznego rozwiązywania problemów
Klasyfikacja
Klasyfikacja to typowe zadanie uczenia maszynowego. Klasyfikacja to rodzaj uczenia nadzorowanego, w którym modele uczą się przy użyciu danych treningowych i stosują te informacje do nowych danych. Usługa Azure Machine Learning oferuje funkcje doboru cech przeznaczone specjalnie dla tych zadań, takie jak funkcje doboru cech tekstu głębokiej sieci neuronowej na potrzeby klasyfikacji. Dowiedz się więcej o opcjach cechowania (wersja 1).
Głównym celem modeli klasyfikacji jest przewidywanie, na podstawie informacji uzyskanych z danych treningowych, do których kategorii trafią nowe dane. Typowe przykłady klasyfikacji obejmują wykrywanie oszustw, rozpoznawanie pisma ręcznego i wykrywanie obiektów. Dowiedz się więcej i zobacz przykład tworzenia modelu klasyfikacji za pomocą zautomatyzowanego uczenia maszynowego (wersja 1).
Zobacz przykłady klasyfikacji i zautomatyzowanego uczenia maszynowego w tych notesach języka Python: wykrywanie oszustw, przewidywanie marketingu i klasyfikacja danych grupy dyskusyjnej
Regresja
Podobnie jak w przypadku klasyfikacji, zadania regresji są również typowym zadaniem uczenia nadzorowanego.
Różni się od klasyfikacji, w której przewidywane wartości wyjściowe są podzielone na kategorie, modele regresji przewidują liczbowe wartości wyjściowe na podstawie niezależnych predyktorów. W regresji celem jest pomoc w ustanowieniu relacji między zmiennymi tych niezależnych predyktorów przez oszacowanie wpływu jednej zmiennej na inne. Przykładem może być cena samochodu na podstawie takich cech jak spalanie, ocena bezpieczeństwa itp. Dowiedz się więcej i zobacz przykład regresji zautomatyzowanego uczenia maszynowego (wersja 1).
Zobacz przykłady regresji i zautomatyzowanego uczenia maszynowego, aby uzyskać przewidywania w tych notesach języka Python: przewidywanie wydajności procesora CPU,
Prognozowanie szeregów czasowych
Tworzenie prognoz jest integralną częścią każdej firmy, niezależnie od tego, czy dotyczy to przychodu, zapasów, sprzedaży czy zapotrzebowania klientów. Za pomocą zautomatyzowanego uczenia maszynowego możesz połączyć techniki oraz podejścia i uzyskać zalecaną prognozę szeregów czasowych o wysokiej jakości. Dowiedz się więcej na ten temat: zautomatyzowane uczenie maszynowe na potrzeby prognozowania szeregów czasowych (wersja 1).
Zautomatyzowany eksperyment szeregów czasowych jest traktowany jako problem regresji wielowariancji. Wcześniejsze wartości szeregów czasowych są "przestawne", aby stać się dodatkowymi wymiarami regresora wraz z innymi predyktorami. Takie podejście, w przeciwieństwie do klasycznych metod szeregów czasowych, ma zaletę naturalnie dołączania wielu zmiennych kontekstowych i ich relacji ze sobą podczas trenowania. Zautomatyzowane uczenie maszynowe uczy się pojedynczego, ale często wewnętrznie rozgałęzionego modelu dla wszystkich elementów w zestawie danych i horyzontach przewidywania. Dzięki temu dostępnych jest więcej danych do szacowania parametrów modelu i uogólniania, aby niesłaniać serii staje się możliwe.
Zaawansowana konfiguracja prognozowania obejmuje:
- wykrywanie świąt i cechowanie
- time-series and DNN learners (Auto-ARIMA, Prophet, ForecastTCN)
- obsługa wielu modeli za pomocą grupowania
- weryfikacja krzyżowa przy użyciu źródła kroczącego
- konfigurowalne opóźnienia
- funkcje agregacji okna kroczącego
Zobacz przykłady regresji i zautomatyzowanego uczenia maszynowego, aby uzyskać przewidywania w tych notesach języka Python: Prognozowanie sprzedaży, Prognozowanie popytu i Prognozowanie codziennych aktywnych użytkowników usługi GitHub.
Przetwarzanie obrazów
Obsługa zadań przetwarzania obrazów umożliwia łatwe generowanie modeli wytrenowanych na danych obrazów w scenariuszach, takich jak klasyfikacja obrazów i wykrywanie obiektów.
Daje to następujące możliwości:
- Bezproblemowa integracja z funkcją etykietowania danych usługi Azure Machine Learning
- Używanie danych oznaczonych etykietami do generowania modeli obrazów
- Zoptymalizuj wydajność modelu, określając algorytm modelu i dostrajając hiperparametry.
- Pobierz lub wdróż wynikowy model jako usługę internetową w usłudze Azure Machine Learning.
- Operacjonalizacja na dużą skalę, korzystając z możliwości usługi Azure Machine Learning MLOps i potoków uczenia maszynowego (wersja 1).
Tworzenie modeli automatycznego uczenia maszynowego na potrzeby zadań przetwarzania obrazów jest obsługiwane za pośrednictwem zestawu SDK języka Python usługi Azure Machine Learning. Dostęp do wynikowych zadań eksperymentowania, modeli i danych wyjściowych można uzyskać z interfejsu użytkownika Azure Machine Learning studio.
Dowiedz się, jak skonfigurować trenowanie automatycznego uczenia maszynowego dla modeli przetwarzania obrazów.

Zautomatyzowane uczenie maszynowe dla obrazów obsługuje następujące zadania przetwarzania obrazów:
| Zadanie | Opis |
|---|---|
| Klasyfikacja obrazów z użyciem wielu klas | Zadania, w których obraz jest klasyfikowany tylko za pomocą pojedynczej etykiety z zestawu klas — na przykład każdy obraz jest klasyfikowany jako obraz, na którym jest „kot”, „pies” lub „kaczka” |
| Klasyfikacja obrazów z użyciem wielu etykiet | Zadania, w których obraz może mieć jedną lub więcej etykiet z zestawu etykiet — na przykład obraz może być oznaczony jako ten, na którym jest zarówno „kot”, jak i „pies” |
| Wykrywanie obiektów | Zadania do identyfikowania obiektów na obrazie i lokalizowania każdego obiektu za pomocą pola ograniczenia, np. lokalizowanie wszystkich psów i kotów na obrazie i rysowanie pola ograniczenia wokół każdego z nich. |
| Segmentacja wystąpień | Zadania do identyfikowania obiektów na obrazie na poziomie pikseli i rysowania wielokąta wokół każdego obiektu na obrazie. |
Przetwarzanie języka naturalnego: NLP
Obsługa zadań przetwarzania języka naturalnego (NLP) w zautomatyzowanym uczeniu maszynowym umożliwia łatwe generowanie modeli wytrenowanych na danych tekstowych na potrzeby klasyfikacji tekstu i scenariuszy rozpoznawania jednostek nazwanych. Tworzenie zautomatyzowanych modeli NLP wytrenowanych przez uczenie maszynowe jest obsługiwane za pośrednictwem zestawu SDK języka Python usługi Azure Machine Learning. Dostęp do wynikowych zadań eksperymentowania, modeli i danych wyjściowych można uzyskać z interfejsu użytkownika Azure Machine Learning studio.
Funkcja NLP obsługuje następujące funkcje:
- Kompleksowe trenowanie głębokiej sieci neuronowej NLP przy użyciu najnowszych wstępnie wytrenowanych modeli BERT
- Bezproblemowa integracja z etykietowaniem danych usługi Azure Machine Learning
- Używanie danych oznaczonych etykietami do generowania modeli nlp
- Obsługa wielu języków językowych w 104 językach
- Uczenie rozproszone przy użyciu struktury Horovod
Dowiedz się, jak skonfigurować trenowanie automatycznego uczenia maszynowego dla modeli NLP (wersja 1).
Jak działa zautomatyzowane uczenie maszynowe
Podczas trenowania usługa Azure Machine Learning tworzy wiele potoków równolegle, które umożliwiają wypróbowanie różnych algorytmów i parametrów. Usługa iteruje za pomocą algorytmów uczenia maszynowego w połączeniu z wyborami funkcji, gdzie każda iteracja generuje model z wynikiem trenowania. Im wyższy wynik, tym lepiej model jest uznawany za "dopasowany" do danych. Zostanie zatrzymany po osiągnięciu kryteriów wyjścia zdefiniowanych w eksperymencie.
Korzystając z usługi Azure Machine Learning, możesz zaprojektować i uruchomić eksperymenty zautomatyzowanego trenowania uczenia maszynowego, wykonując następujące kroki:
Zidentyfikuj problem uczenia maszynowego , który ma zostać rozwiązany: klasyfikacja, prognozowanie, regresja lub przetwarzanie obrazów.
Wybierz, czy chcesz użyć zestawu SDK języka Python, czy środowiska internetowego studio: dowiedz się więcej o parzystości między zestawem SDK języka Python i środowiskiem internetowym studio.
- W przypadku ograniczonego lub braku środowiska kodu wypróbuj środowisko internetowe Azure Machine Learning studio pod adresemhttps://ml.azure.com
- W przypadku deweloperów języka Python zapoznaj się z zestawem SDK języka Python usługi Azure Machine Learning (wersja 1)
Określ źródło i format oznaczonych danymi treningowymi: tablice Numpy lub ramka danych biblioteki Pandas
Skonfiguruj docelowy obiekt obliczeniowy na potrzeby trenowania modelu, takiego jak komputer lokalny, obliczenia usługi Azure Machine Learning, zdalne maszyny wirtualne lub usługa Azure Databricks z zestawem SDK w wersji 1.
Skonfiguruj parametry zautomatyzowanego uczenia maszynowego , które określają liczbę iteracji w różnych modelach, ustawienia hiperparametrów, zaawansowane przetwarzanie wstępne/cechowanie oraz metryki, które należy przyjrzeć podczas określania najlepszego modelu.
Prześlij zadanie szkoleniowe.
Przeglądanie wyników
Na poniższym diagramie przedstawiono ten proces.
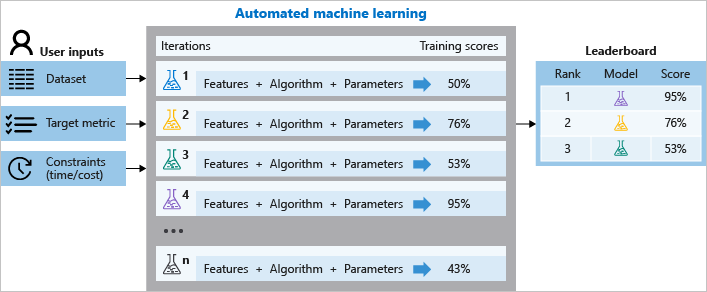
Możesz również sprawdzić zarejestrowane informacje o zadaniu, które zawierają metryki zebrane podczas zadania. Zadanie trenowania tworzy serializowany obiekt (.pkl plik) języka Python, który zawiera model i przetwarzanie wstępne danych.
Podczas tworzenia modeli można również dowiedzieć się, jak ważne lub istotne są funkcje dla wygenerowanych modeli.
Wskazówki dotyczące lokalnych i zdalnych docelowych obiektów obliczeniowych uczenia maszynowego zarządzanego
Interfejs internetowy zautomatyzowanego uczenia maszynowego zawsze używa zdalnego celu obliczeniowego. Jednak w przypadku korzystania z zestawu SDK języka Python należy wybrać lokalne środowisko obliczeniowe lub zdalny docelowy obiekt obliczeniowy na potrzeby zautomatyzowanego trenowania uczenia maszynowego.
- Lokalne obliczenia: trenowanie odbywa się na lokalnym komputerze przenośnym lub w obliczeniach maszyn wirtualnych.
- Zdalne obliczenia: trenowanie odbywa się w klastrach obliczeniowych usługi Machine Learning.
Wybieranie docelowego obiektu obliczeniowego
Podczas wybierania celu obliczeniowego należy wziąć pod uwagę następujące czynniki:
- Wybierz lokalne zasoby obliczeniowe: jeśli scenariusz dotyczy początkowych eksploracji lub pokazów przy użyciu małych danych i krótkich pociągów (tj. sekund lub kilku minut na zadanie podrzędne), szkolenie na komputerze lokalnym może być lepszym wyborem. Nie ma czasu instalacji, zasoby infrastruktury (komputer lub maszyna wirtualna) są dostępne bezpośrednio.
- Wybierz zdalny klaster obliczeniowy uczenia maszynowego: jeśli trenujesz z większymi zestawami danych, takimi jak w środowisku produkcyjnym, tworząc modele, które wymagają dłuższych pociągów, obliczenia zdalne zapewnią znacznie lepszą wydajność czasu kompleksowego, ponieważ
AutoMLzrównają pociągi między węzłami klastra. W przypadku zdalnego przetwarzania obliczeniowego czas uruchamiania wewnętrznej infrastruktury doda około 1,5 minut na zadanie podrzędne oraz dodatkowe minuty dla infrastruktury klastra, jeśli maszyny wirtualne nie są jeszcze uruchomione.
Zalety i wady
Weź pod uwagę te zalety i wady podczas wybierania użycia lokalnego a zdalnego.
| Pros (zalety) | Minusy (handicapy) | |
|---|---|---|
| Lokalny obiekt docelowy obliczeniowy | ||
| Klastry obliczeniowe zdalnego uczenia maszynowego |
Dostępność funkcji
Więcej funkcji jest dostępnych, gdy używasz zdalnego przetwarzania obliczeniowego, jak pokazano w poniższej tabeli.
| Cecha | Zdalne | Lokalne |
|---|---|---|
| Przesyłanie strumieniowe danych (obsługa dużych danych, do 100 GB) | ✓ | |
| DNN-BERT oparte na cechach tekstowych i trenowanie | ✓ | |
| Obsługa gotowego procesora GPU (trenowanie i wnioskowanie) | ✓ | |
| Obsługa klasyfikacji obrazów i etykietowania | ✓ | |
| Modele Auto-ARIMA, Prophet i ForecastTCN na potrzeby prognozowania | ✓ | |
| Wiele zadań/iteracji równolegle | ✓ | |
| Tworzenie modeli z możliwościami interpretacji w interfejsie użytkownika środowiska internetowego programu AutoML Studio | ✓ | |
| Dostosowywanie inżynierii funkcji w interfejsie użytkownika środowiska internetowego programu Studio | ✓ | |
| Dostrajanie hiperparametrów usługi Azure Machine Learning | ✓ | |
| Obsługa przepływu pracy potoku usługi Azure Machine Learning | ✓ | |
| Kontynuuj zadanie | ✓ | |
| Prognozowanie | ✓ | ✓ |
| Tworzenie i uruchamianie eksperymentów w notesach | ✓ | ✓ |
| Rejestrowanie i wizualizowanie informacji i metryk eksperymentu w interfejsie użytkownika | ✓ | ✓ |
| Zabezpieczenia danych | ✓ | ✓ |
Trenowanie, walidacja i testowanie danych
Za pomocą zautomatyzowanego uczenia maszynowego udostępniasz dane szkoleniowe do trenowania modeli uczenia maszynowego i możesz określić typ weryfikacji modelu do wykonania. Zautomatyzowane uczenie maszynowe przeprowadza walidację modelu w ramach szkolenia. Oznacza to, że zautomatyzowane uczenie maszynowe używa danych weryfikacji do dostrajania hiperparametrów modelu na podstawie zastosowanego algorytmu w celu znalezienia najlepszej kombinacji, która najlepiej pasuje do danych treningowych. Jednak te same dane weryfikacji są używane dla każdej iteracji dostrajania, która wprowadza stronniczość oceny modelu, ponieważ model nadal poprawia i pasuje do danych walidacji.
Aby potwierdzić, że takie stronniczości nie są stosowane do ostatecznego zalecanego modelu, zautomatyzowane uczenie maszynowe obsługuje używanie danych testowych do oceny końcowego modelu zalecanego przez zautomatyzowane uczenie maszynowe na końcu eksperymentu. Po podaniu danych testowych w ramach konfiguracji eksperymentu rozwiązania AutoML ten zalecany model jest domyślnie testowany na końcu eksperymentu (wersja zapoznawcza).
Ważne
Testowanie modeli przy użyciu zestawu danych testowego w celu oceny wygenerowanych modeli jest funkcją w wersji zapoznawczej. Ta funkcja jest eksperymentalną funkcją w wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
Dowiedz się, jak skonfigurować eksperymenty rozwiązania AutoML do używania danych testowych (wersja zapoznawcza) z zestawem SDK (wersja 1) lub za pomocą Azure Machine Learning studio.
Możesz również przetestować dowolny istniejący zautomatyzowany model uczenia maszynowego (wersja zapoznawcza) (wersja 1)), w tym modele z zadań podrzędnych, udostępniając własne dane testowe lub odkładając część danych treningowych.
Inżynieria cech
Inżynieria funkcji to proces używania wiedzy o domenie danych w celu tworzenia funkcji, które pomagają algorytmom uczenia maszynowego lepiej się uczyć. W usłudze Azure Machine Learning stosowane są techniki skalowania i normalizacji w celu ułatwienia inżynierii cech. Łącznie te techniki i inżynieria cech są określane jako cechowanie.
W przypadku eksperymentów zautomatyzowanego uczenia maszynowego cechowanie jest stosowane automatycznie, ale można je również dostosować na podstawie danych. Dowiedz się więcej o tym, jakie cechowanie jest uwzględnione (wersja 1) i jak rozwiązanie AutoML pomaga zapobiegać nadmiernemu dopasowywaniu i nierównowagowaniu danych w modelach.
Uwaga
Zautomatyzowane kroki cechowania uczenia maszynowego (normalizacja funkcji, obsługa brakujących danych, konwertowanie tekstu na liczbowe itp.) stają się częścią podstawowego modelu. W przypadku korzystania z modelu przewidywania te same kroki cechowania stosowane podczas trenowania są stosowane automatycznie do danych wejściowych.
Dostosowywanie cechowania
Dostępne są również dodatkowe techniki inżynierii cech, takie jak kodowanie i przekształcenia.
Włącz to ustawienie za pomocą:
Azure Machine Learning studio: Włącz automatyczną cechę w sekcji Wyświetl dodatkową konfigurację, wykonując następujące kroki (wersja 1).
Zestaw SDK języka Python: określ
"feauturization": 'auto' / 'off' / 'FeaturizationConfig'w obiekcie AutoMLConfig . Dowiedz się więcej na temat włączania cechowania (wersja 1).
Modele zespołów
Zautomatyzowane uczenie maszynowe obsługuje modele zespołów, które są domyślnie włączone. Uczenie zespołowe poprawia wyniki uczenia maszynowego i wydajność predykcyjną, łącząc wiele modeli w przeciwieństwie do korzystania z pojedynczych modeli. Iteracji zespołu są wyświetlane jako ostatnie iteracji zadania. Zautomatyzowane uczenie maszynowe używa metod głosowania i stosu zespołów do łączenia modeli:
- Głosowanie: przewiduje na podstawie ważonej średniej prawdopodobieństwa przewidywanej klasy (dla zadań klasyfikacji) lub przewidywanych celów regresji (w przypadku zadań regresji).
- Stos: stos łączy heterogeniczne modele i trenuje metamodel na podstawie danych wyjściowych poszczególnych modeli. Bieżące domyślne meta-modele to LogisticsRegression na potrzeby zadań klasyfikacji i ElasticNet na potrzeby zadań regresji/prognozowania.
Algorytm wyboru zespołu Caruana z posortowaną inicjacją zespołu służy do decydowania, które modele mają być używane w ramach zespołu. Na wysokim poziomie ten algorytm inicjuje zespół z maksymalnie pięcioma modelami z najlepszymi wynikami i sprawdza, czy te modele znajdują się w granicach 5% najlepszego wyniku, aby uniknąć słabego początkowego zespołu. Następnie dla każdej iteracji zespołu zostanie dodany nowy model do istniejącego zespołu, a wynikowy wynik jest obliczany. Jeśli nowy model poprawił istniejący wynik zespołu, zespół zostanie zaktualizowany, aby uwzględnić nowy model.
Zobacz instrukcje (wersja 1), aby zmienić domyślne ustawienia zespołu w zautomatyzowanym uczeniu maszynowym.
AutoML & ONNX
Za pomocą usługi Azure Machine Learning możesz użyć zautomatyzowanego uczenia maszynowego do utworzenia modelu języka Python i przekonwertowania go na format ONNX. Gdy modele są w formacie ONNX, mogą być uruchamiane na różnych platformach i urządzeniach. Dowiedz się więcej o przyspieszaniu modeli uczenia maszynowego za pomocą narzędzia ONNX.
Zobacz sposób konwertowania na format ONNX w tym przykładzie notesu Jupyter. Dowiedz się, które algorytmy są obsługiwane w programie ONNX (wersja 1).
Środowisko uruchomieniowe ONNX obsługuje również język C#, dzięki czemu można użyć modelu wbudowanego automatycznie w aplikacjach języka C# bez konieczności ponownego odzyskiwania ani żadnych opóźnień sieci, które wprowadzono w punktach końcowych REST. Dowiedz się więcej na temat używania modelu ONNX rozwiązania AutoML w aplikacji .NET z ML.NET i wnioskowania modeli ONNX za pomocą interfejsu API języka C# środowiska uruchomieniowego ONNX.
Następne kroki
Istnieje wiele zasobów, które umożliwiają rozpoczęcie pracy z rozwiązaniem AutoML.
Samouczki/ instrukcje
Samouczki to kompleksowe przykłady wprowadzające scenariuszy rozwiązania AutoML.
Aby uzyskać pierwsze środowisko kodu, postępuj zgodnie z artykułem Samouczek: trenowanie modelu regresji przy użyciu języka AutoML i języka Python (wersja 1).
Aby uzyskać małe lub niekodowe środowisko, zobacz Samouczek: trenowanie modelu klasyfikacji bez kodu AutoML w Azure Machine Learning studio.
Aby użyć rozwiązania AutoML do trenowania modeli przetwarzania obrazów, zobacz Samouczek: trenowanie modelu wykrywania obiektów przy użyciu rozwiązania AutoML i języka Python (wersja 1).
Artykuły z instrukcjami zawierają dodatkowe szczegóły dotyczące funkcji zautomatyzowanych ofert uczenia maszynowego. Na przykład
Konfigurowanie ustawień eksperymentów automatycznego trenowania
Dowiedz się, jak trenować modele prognozowania przy użyciu danych szeregów czasowych (wersja 1).
Dowiedz się, jak trenować modele przetwarzania obrazów przy użyciu języka Python (wersja 1).
Dowiedz się, jak wyświetlić wygenerowany kod na podstawie zautomatyzowanych modeli uczenia maszynowego.
Przykłady notesów Jupyter
Przejrzyj szczegółowe przykłady kodu i przypadki użycia w repozytorium notesów GitHub, aby zapoznać się z przykładami zautomatyzowanego uczenia maszynowego.
Dokumentacja zestawu SDK języka Python
Pogłębij swoją wiedzę na temat wzorców projektowych i specyfikacji klas zestawu SDK, aby uzyskać dokumentację referencyjną klasy AutoML.
Uwaga
Funkcje zautomatyzowanego uczenia maszynowego są również dostępne w innych rozwiązaniach firmy Microsoft, takich jak ML.NET, HDInsight, Power BI i SQL Server