Wyodrębnianie tekstu i informacji z obrazów w wzbogacaniu sztucznej inteligencji
Dzięki wzbogacaniu sztucznej inteligencji usługa Azure AI Search oferuje kilka opcji tworzenia i wyodrębniania tekstu z możliwością wyszukiwania z obrazów, w tym:
- Funkcja OCR do optycznego rozpoznawania znaków tekstu i cyfr
- Analiza obrazów, która opisuje obrazy za pomocą funkcji wizualnych
- Umiejętności niestandardowe umożliwiające wywoływanie dowolnego zewnętrznego przetwarzania obrazów, które chcesz udostępnić
Za pomocą protokołu OCR można wyodrębnić tekst ze zdjęć lub obrazów zawierających tekst alfanumeryczny, taki jak słowo "STOP" w znaku zatrzymania. Dzięki analizie obrazu można wygenerować tekstową reprezentację obrazu, taką jak "mniszek" dla zdjęcia mniszek lub kolor "żółty". Możesz również wyodrębnić metadane dotyczące obrazu, takie jak jego rozmiar.
W tym artykule omówiono podstawy pracy z obrazami, a także opisano kilka typowych scenariuszy, takich jak praca z obrazami osadzonymi, umiejętności niestandardowe i nakładanie wizualizacji na oryginalnych obrazach.
Aby pracować z zawartością obrazu w zestawie umiejętności, potrzebne są następujące elementy:
- Pliki źródłowe zawierające obrazy
- Indeksator wyszukiwania skonfigurowany pod kątem akcji obrazu
- Zestaw umiejętności z wbudowanymi lub niestandardowymi umiejętnościami, które wywołują analizę OCR lub obrazów
- Indeks wyszukiwania z polami do odbierania analizowanych danych wyjściowych tekstu oraz mapowania pól wyjściowych w indeksatorze, który ustanawia skojarzenie.
Opcjonalnie można zdefiniować projekcje, aby akceptować dane wyjściowe analizowane obrazami w magazynie wiedzy na potrzeby scenariuszy wyszukiwania danych.
Konfigurowanie plików źródłowych
Przetwarzanie obrazów jest oparte na indeksatorze, co oznacza, że nieprzetworzone dane wejściowe muszą znajdować się w obsługiwanym źródle danych.
- Analiza obrazów obsługuje pliki JPEG, PNG, GIF i BMP
- Protokół OCR obsługuje pliki JPEG, PNG, BMP i TIF
Obrazy to autonomiczne pliki binarne lub osadzone w dokumentach (pliki PDF, RTF i pliki aplikacji firmy Microsoft). Z danego dokumentu można wyodrębnić maksymalnie 1000 obrazów. Jeśli w dokumencie znajduje się więcej niż 1000 obrazów, zostanie wyodrębnionych pierwszych 1000, a następnie zostanie wygenerowane ostrzeżenie.
Azure Blob Storage to najczęściej używany magazyn do przetwarzania obrazów w usłudze Azure AI Search. Istnieją trzy główne zadania związane z pobieraniem obrazów z kontenera obiektów blob:
Włącz dostęp do zawartości w kontenerze. Jeśli używasz pełnego dostępu parametry połączenia zawierającego klucz, klucz daje uprawnienie do zawartości. Alternatywnie możesz uwierzytelnić się przy użyciu identyfikatora Entra firmy Microsoft lub nawiązać połączenie jako zaufaną usługę.
Utwórz źródło danych typu "azureblob", które łączy się z kontenerem obiektów blob przechowującymi pliki.
Przejrzyj limity warstwy usług, aby upewnić się, że dane źródłowe są w zakresie maksymalnego rozmiaru i limitów ilości dla indeksatorów i wzbogacania.
Konfigurowanie indeksatorów na potrzeby przetwarzania obrazów
Po skonfigurowaniu plików źródłowych włącz normalizację obrazu, ustawiając imageAction parametr w konfiguracji indeksatora. Normalizacja obrazu pomaga uczynić obrazy bardziej jednolite do przetwarzania podrzędnego. Normalizacja obrazu obejmuje następujące operacje:
- Rozmiar dużych obrazów jest zmieniany na maksymalną wysokość i szerokość, aby były jednolite.
- W przypadku obrazów, które mają metadane orientacji, rotacja obrazów jest dostosowywana do ładowania w pionie.
Korekty metadanych są przechwytywane w typie złożonym utworzonym dla każdego obrazu. Nie można zrezygnować z wymagania normalizacji obrazu. Umiejętności iterujące obrazy, takie jak OCR i analiza obrazów, oczekują znormalizowanych obrazów.
Utwórz lub zaktualizuj indeksator , aby ustawić właściwości konfiguracji:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Ustaw
dataToExtractwartośćcontentAndMetadata(wymagane).Sprawdź, czy właściwość jest ustawiona
parsingModena wartość domyślną (wymagana).Ten parametr określa stopień szczegółowości dokumentów wyszukiwania utworzonych w indeksie. Tryb domyślny konfiguruje korespondencję jeden do jednego, aby jeden obiekt blob był wynikiem jednego dokumentu wyszukiwania. Jeśli dokumenty są duże lub jeśli umiejętności wymagają mniejszych fragmentów tekstu, możesz dodać umiejętność dzielenia tekstu, która dzieli dokument na stronicowanie na potrzeby przetwarzania. Jednak w przypadku scenariuszy wyszukiwania wymagany jest jeden obiekt blob na dokument, jeśli wzbogacanie obejmuje przetwarzanie obrazów.
Ustaw
imageActionopcję włączenia węzła normalized_images w drzewie wzbogacania (wymagane):generateNormalizedImagesw celu wygenerowania tablicy znormalizowanych obrazów w ramach łamania dokumentów.generateNormalizedImagePerPage(dotyczy tylko formatu PDF) w celu wygenerowania tablicy znormalizowanych obrazów, na których każda strona w pliku PDF jest renderowana do jednego obrazu wyjściowego. W przypadku plików innych niż PDF zachowanie tego parametru jest podobne, jak w przypadku ustawienia "generateNormalizedImages". Należy jednak pamiętać, że ustawienie "generateNormalizedImagePerPage" może sprawić, że operacja indeksowania będzie mniej wydajna zgodnie z projektem (zwłaszcza w przypadku dużych dokumentów), ponieważ trzeba wygenerować kilka obrazów.
Opcjonalnie dostosuj szerokość lub wysokość wygenerowanych znormalizowanych obrazów:
normalizedImageMaxWidth(w pikselach). Wartość domyślna to 2000. Wartość maksymalna to 10000.normalizedImageMaxHeight(w pikselach). Wartość domyślna to 2000. Wartość maksymalna to 10000.
Wartość domyślna 2000 pikseli znormalizowanych obrazów o maksymalnej szerokości i wysokości jest oparta na maksymalnych rozmiarach obsługiwanych przez umiejętności OCR i umiejętności analizy obrazów. Umiejętność OCR obsługuje maksymalną szerokość i wysokość 4200 dla języków innych niż angielski i 10000 dla języka angielskiego. Jeśli zwiększysz maksymalne limity, przetwarzanie może zakończyć się niepowodzeniem w przypadku większych obrazów w zależności od definicji zestawu umiejętności i języka dokumentów.
Opcjonalnie ustaw kryteria typu pliku, jeśli obciążenie jest przeznaczone dla określonego typu pliku. Konfiguracja indeksatora obiektów blob obejmuje ustawienia dołączania i wykluczania plików. Możesz odfiltrować pliki, których nie chcesz.
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
Informacje o znormalizowanych obrazach
Gdy imageAction jest ustawiona wartość inna niż "none", nowe pole normalized_images zawiera tablicę obrazów. Każdy obraz jest typem złożonym, który ma następujące elementy członkowskie:
| Element członkowski obrazu | opis |
|---|---|
| dane | Ciąg zakodowany w formacie BASE64 znormalizowanego obrazu w formacie JPEG. |
| width | Szerokość znormalizowanego obrazu w pikselach. |
| height | Wysokość znormalizowanego obrazu w pikselach. |
| originalWidth | Oryginalna szerokość obrazu przed normalizacją. |
| originalHeight | Oryginalna wysokość obrazu przed normalizacją. |
| rotationFromOriginal | Obrót w kierunku wskazówek zegara w stopniach, które miały miejsce w celu utworzenia znormalizowanych obrazów. Wartość z zakresu od 0 stopni do 360 stopni. Ten krok odczytuje metadane z obrazu generowanego przez aparat lub skaner. Zwykle wielokrotność 90 stopni. |
| contentOffset | Przesunięcie znaku w polu zawartości, z którego wyodrębniono obraz. To pole dotyczy tylko plików z obrazami osadzonymi. ZawartośćOffset dla obrazów wyodrębnionych z dokumentów PDF jest zawsze na końcu tekstu na stronie wyodrębnionej z dokumentu. Oznacza to, że obrazy są wyświetlane po całym tekście na tej stronie, niezależnie od oryginalnej lokalizacji obrazu na stronie. |
| pageNumber | Jeśli obraz został wyodrębniony lub renderowany z pliku PDF, to pole zawiera numer strony w pliku PDF, z którego został wyodrębniony lub renderowany, począwszy od 1. Jeśli obraz nie pochodzi z pliku PDF, to pole ma wartość 0. |
Przykładowa wartość normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
Definiowanie zestawów umiejętności na potrzeby przetwarzania obrazów
Ta sekcja uzupełnia artykuły referencyjne dotyczące umiejętności, zapewniając kontekst pracy z danymi wejściowymi umiejętności, danymi wyjściowymi i wzorcami, ponieważ odnoszą się one do przetwarzania obrazów.
Utwórz lub zaktualizuj zestaw umiejętności, aby dodać umiejętności.
Dodaj szablony dla funkcji OCR i Analizy obrazów z portalu lub skopiuj definicje z dokumentacji referencyjnej umiejętności. Wstaw je do tablicy umiejętności definicji zestawu umiejętności.
W razie potrzeby dołącz klucz wielosługowy do właściwości usług Azure AI zestawu umiejętności. Usługa Azure AI Search wykonuje wywołania rozliczanego zasobu usług Azure AI na potrzeby OCR i analizy obrazów dla transakcji, które przekraczają bezpłatny limit (20 na indeksator dziennie). Usługi azure AI muszą znajdować się w tym samym regionie co usługa wyszukiwania.
Jeśli oryginalne obrazy są osadzone w plikach PDF lub plikach aplikacji, takich jak PPTX lub DOCX, musisz dodać umiejętność scalania tekstu, jeśli chcesz, aby dane wyjściowe obrazu i dane wyjściowe tekstu zostały połączone. Praca z obrazami osadzonymi została omówiona dokładniej w tym artykule.
Po utworzeniu podstawowej struktury zestawu umiejętności i skonfigurowaniu usług sztucznej inteligencji platformy Azure można skoncentrować się na poszczególnych umiejętnościach obrazu, zdefiniowaniu danych wejściowych i kontekście źródłowym oraz mapowaniu danych wyjściowych na pola w indeksie lub magazynie wiedzy.
Uwaga
Zobacz Samouczek REST: używanie interfejsu REST i sztucznej inteligencji do generowania zawartości z możliwością wyszukiwania na podstawie obiektów blob platformy Azure, aby zapoznać się z przykładowym zestawem umiejętności, który łączy przetwarzanie obrazów z podrzędnym przetwarzaniem języka naturalnego. Przedstawia on sposób podawania danych wyjściowych obrazu umiejętności do rozpoznawania jednostek i wyodrębniania kluczowych fraz.
Informacje o danych wejściowych na potrzeby przetwarzania obrazów
Jak wspomniano, obrazy są wyodrębniane podczas pękania dokumentu, a następnie znormalizowane jako wstępny krok. Znormalizowane obrazy są danymi wejściowymi dowolnej umiejętności przetwarzania obrazów i są zawsze reprezentowane w wzbogaconym drzewie dokumentów na jeden z dwóch sposobów:
/document/normalized_images/*jest przeznaczony dla dokumentów, które są przetwarzane w całości./document/normalized_images/*/pagesjest przeznaczony dla dokumentów przetwarzanych we fragmentach (stronach).
Niezależnie od tego, czy używasz funkcji OCR i analizy obrazów w tym samym miejscu, dane wejściowe mają praktycznie taką samą konstrukcję:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Mapowanie danych wyjściowych na pola wyszukiwania
W zestawie umiejętności dane wyjściowe analizy obrazów i umiejętności OCR są zawsze tekstem. Tekst wyjściowy jest reprezentowany jako węzły w wewnętrznym wzbogaconym drzewie dokumentów, a każdy węzeł musi być mapowany na pola w indeksie wyszukiwania lub do projekcji w magazynie wiedzy, aby udostępnić zawartość w aplikacji.
W zestawie umiejętności przejrzyj sekcję
outputskażdej umiejętności, aby określić, które węzły istnieją w wzbogaconym dokumencie:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Utwórz lub zaktualizuj indeks wyszukiwania, aby dodać pola w celu zaakceptowania danych wyjściowych umiejętności.
W poniższym przykładzie kolekcji pól "zawartość" to zawartość obiektu blob. Wyrażenie "Metadata_storage_name" zawiera nazwę pliku (upewnij się, że jest to "możliwe do pobrania"). "Metadata_storage_path" to unikatowa ścieżka obiektu blob i jest domyślnym kluczem dokumentu. "Merged_content" to dane wyjściowe z scalania tekstu (przydatne, gdy obrazy są osadzone).
"Tekst" i "layoutText" to dane wyjściowe umiejętności OCR i muszą być kolekcją ciągów w celu przechwycenia wszystkich danych wyjściowych wygenerowanych przez OCR dla całego dokumentu.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Zaktualizuj indeksator , aby mapować dane wyjściowe zestawu umiejętności (węzły w drzewie wzbogacania) na pola indeksowania.
Wzbogacone dokumenty są wewnętrzne. Aby zewnętrznych węzłów w wzbogaconym drzewie dokumentów, skonfiguruj mapowanie pól wyjściowych, które określa, które pole indeksu odbiera zawartość węzła. Wzbogacone dane są uzyskiwane przez aplikację za pośrednictwem pola indeksu. W poniższym przykładzie pokazano węzeł "tekst" (dane wyjściowe OCR) w wzbogaconym dokumencie mapowanym na pole "tekst" w indeksie wyszukiwania.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Uruchom indeksator, aby wywołać pobieranie dokumentu źródłowego, przetwarzanie obrazów i indeksowanie.
Weryfikowanie wyników
Uruchom zapytanie względem indeksu, aby sprawdzić wyniki przetwarzania obrazów. Użyj Eksploratora wyszukiwania jako klienta wyszukiwania lub dowolnego narzędzia wysyłającego żądania HTTP. Poniższe zapytanie wybiera pola zawierające dane wyjściowe przetwarzania obrazów.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
Funkcja OCR rozpoznaje tekst w plikach obrazów. Oznacza to, że pola OCR ("tekst" i "layoutText") są puste, jeśli dokumenty źródłowe są czystym tekstem lub czystym obrazem. Podobnie pola analizy obrazów ("imageCaption" i "imageTags") są puste, jeśli dane wejściowe dokumentu źródłowego są ściśle tekstowe. Wykonanie indeksatora emituje ostrzeżenia, jeśli dane wejściowe obrazu są puste. Takie ostrzeżenia mają być oczekiwane, gdy węzły nie są wypełniane w wzbogaconym dokumencie. Pamiętaj, że indeksowanie obiektów blob umożliwia dołączanie lub wykluczanie typów plików, jeśli chcesz pracować z typami zawartości w izolacji. Możesz użyć tego ustawienia, aby zmniejszyć szum podczas przebiegów indeksatora.
Alternatywne zapytanie dotyczące sprawdzania wyników może zawierać pola "zawartość" i "merged_content". Zwróć uwagę, że te pola zawierają zawartość dla dowolnego pliku obiektów blob, nawet tych, w których nie wykonano przetwarzania obrazów.
Informacje o danych wyjściowych umiejętności
Dane wyjściowe umiejętności obejmują tekst (OCR), "layoutText" (OCR), "merged_content", "captions" (analiza obrazu), "tags" (analiza obrazu):
Wyrażenie "text" przechowuje dane wyjściowe wygenerowane przez OCR. Ten węzeł powinien być mapowany na pole typu
Collection(Edm.String). Istnieje jedno pole "tekstowe" dla dokumentu wyszukiwania składające się z ciągów rozdzielanych przecinkami dla dokumentów zawierających wiele obrazów. Poniższa ilustracja przedstawia dane wyjściowe OCR dla trzech dokumentów. Najpierw jest to dokument zawierający plik bez obrazów. Drugi to dokument (plik obrazu) zawierający jedno słowo "Microsoft". Trzeci to dokument zawierający wiele obrazów, niektóre bez żadnego tekstu ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]Element "layoutText" przechowuje informacje generowane przez OCR dotyczące lokalizacji tekstu na stronie, opisane pod względem pól ograniczenia i współrzędnych znormalizowanego obrazu. Ten węzeł powinien być mapowany na pole typu
Collection(Edm.String). Istnieje jedno pole "layoutText" na dokument wyszukiwania składający się z ciągów rozdzielanych przecinkami.Wyrażenie "merged_content" przechowuje dane wyjściowe umiejętności scalania tekstu i powinno być jednym dużym polem typu
Edm.Stringzawierającym nieprzetworzony tekst z dokumentu źródłowego z osadzonym tekstem zamiast obrazu. Jeśli pliki są tylko tekstem, funkcja OCR i analiza obrazów nie mają nic wspólnego, a "merged_content" jest taka sama jak "content" (właściwość obiektu blob, która zawiera zawartość obiektu blob).Wyrażenie "imageCaption" przechwytuje opis obrazu jako tagi poszczególnych osób i dłuższy opis tekstu.
Element "imageTags" przechowuje tagi dotyczące obrazu jako kolekcji słów kluczowych, jednej kolekcji dla wszystkich obrazów w dokumencie źródłowym.
Poniższy zrzut ekranu przedstawia obraz PDF zawierający tekst i obrazy osadzone. Pęknięcie dokumentu wykryło trzy osadzone obrazy: stado mew, mapa, orzeł. Inny tekst w przykładzie (w tym tytuły, nagłówki i tekst treści) został wyodrębniony jako tekst i wykluczony z przetwarzania obrazów.
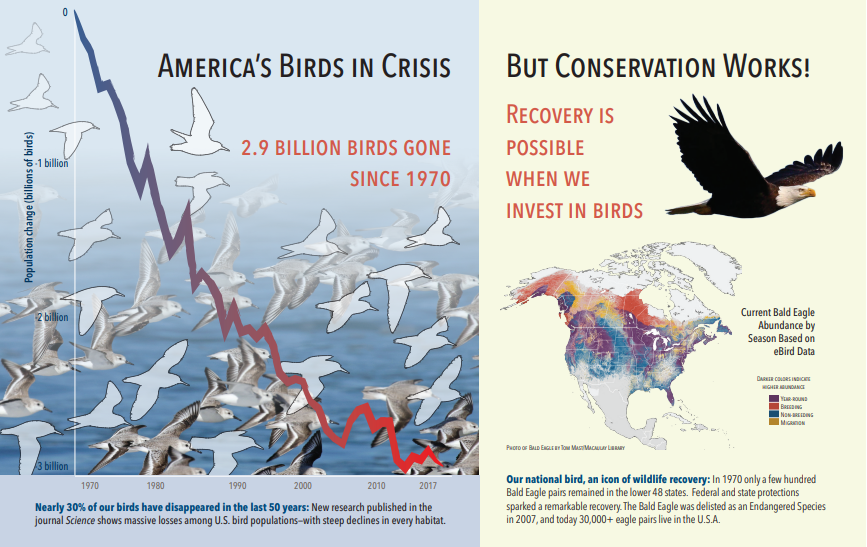
Dane wyjściowe analizy obrazu przedstawiono w poniższym kodzie JSON (wynik wyszukiwania). Definicja umiejętności umożliwia określenie, które funkcje wizualne są interesujące. W tym przykładzie utworzono tagi i opisy, ale istnieje więcej danych wyjściowych do wyboru.
Dane wyjściowe "imageCaption" to tablica opisów, jedna na obraz, oznaczona przez "tagi" składające się z pojedynczych wyrazów i dłuższych fraz opisujących obraz. Zwróć uwagę, że tagi składające się z "stada mew pływają w wodzie" lub "zbliżenie ptaka".
Dane wyjściowe "imageTags" to tablica pojedynczych tagów wymieniona w kolejności tworzenia. Zwróć uwagę, że tagi powtarzają się. Nie ma agregacji ani grupowania.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Scenariusz: Obrazy osadzone w plikach PDF
Gdy obrazy, które chcesz przetworzyć, są osadzone w innych plikach, takich jak PDF lub DOCX, potok wzbogacania wyodrębnia tylko obrazy, a następnie przekazuje je do OCR lub analizy obrazów do przetwarzania. Wyodrębnianie obrazów odbywa się w fazie pękania dokumentu, a po oddzieleniu obrazów pozostają one oddzielone, chyba że jawnie scalisz przetworzone dane wyjściowe z powrotem do tekstu źródłowego.
Scalanie tekstu służy do ponownego umieszczania danych wyjściowych przetwarzania obrazów w dokumencie. Mimo że scalanie tekstu nie jest trudnym wymaganiem, często jest wywoływane, aby dane wyjściowe obrazu (tekst OCR, układ OCRText, tagi obrazów, podpisy obrazów) mogły zostać przywrócone do dokumentu. W zależności od umiejętności dane wyjściowe obrazu zastępują osadzony obraz binarny odpowiednikiem tekstu w miejscu. Dane wyjściowe analizy obrazów można scalić w lokalizacji obrazu. Dane wyjściowe OCR są zawsze wyświetlane na końcu każdej strony.
Poniższy przepływ pracy przedstawia proces wyodrębniania, analizy, scalania i rozszerzania potoku w celu wypychania przetworzonych obrazów danych wyjściowych do innych umiejętności opartych na tekście, takich jak rozpoznawanie jednostek lub tłumaczenie tekstu.
Po nawiązaniu połączenia ze źródłem danych indeksator ładuje i pęka dokumenty źródłowe, wyodrębnia obrazy i tekst oraz kolejkuje każdy typ zawartości do przetwarzania. Tworzony jest wzbogacony dokument składający się tylko z węzła głównego (
"document").Obrazy w kolejce są znormalizowane i przekazywane do wzbogaconych dokumentów jako węzła
"document/normalized_images".Operacje wzbogacania obrazów są wykonywane przy użyciu
"/document/normalized_images"jako danych wejściowych.Dane wyjściowe obrazu są przekazywane do wzbogaconego drzewa dokumentów, a każde dane wyjściowe są przekazywane jako oddzielny węzeł. Dane wyjściowe różnią się w zależności od umiejętności (tekst i układTekst dla OCR, tagów i podpisów dla analizy obrazów).
Opcjonalne, ale zalecane, jeśli chcesz, aby dokumenty wyszukiwania zawierały tekst i tekst pochodzenia obrazu razem, scalanie tekstu jest uruchamiane, łącząc reprezentację tekstu tych obrazów z nieprzetworzonym tekstem wyodrębnionym z pliku. Fragmenty tekstu są konsolidowane w jeden duży ciąg, w którym tekst jest wstawiany najpierw w ciągu, a następnie dane wyjściowe tekstu OCR lub tagi obrazów i podpisy.
Dane wyjściowe scalania tekstu są teraz ostatecznym tekstem do analizy pod kątem wszelkich umiejętności podrzędnych, które wykonują przetwarzanie tekstu. Jeśli na przykład zestaw umiejętności zawiera zarówno rozpoznawanie OCR, jak i rozpoznawanie jednostek, dane wejściowe funkcji Rozpoznawanie jednostek powinny mieć wartość
"document/merged_text"(wartość targetName danych wyjściowych umiejętności scalania tekstu).Po wykonaniu wszystkich umiejętności wzbogacony dokument zostanie ukończony. W ostatnim kroku indeksatory odwołują się do mapowań pól wyjściowych w celu wysyłania wzbogaconej zawartości do poszczególnych pól w indeksie wyszukiwania.
Poniższy przykładowy zestaw umiejętności tworzy "merged_text" pole zawierające oryginalny tekst dokumentu z osadzonym tekstem OCRed zamiast obrazów osadzonych. Zawiera również umiejętności rozpoznawania jednostek, które używają "merged_text" jako danych wejściowych.
Składnia treści żądania
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Teraz, gdy masz pole merged_text, możesz mapować je jako pole z możliwością wyszukiwania w definicji indeksatora. Cała zawartość plików, w tym tekst obrazów, będzie można przeszukiwać.
Scenariusz: Wizualizowanie pól ograniczenia
Innym typowym scenariuszem jest wizualizowanie informacji o układzie wyników wyszukiwania. Możesz na przykład wyróżnić miejsce znalezienia fragmentu tekstu na obrazie w ramach wyników wyszukiwania.
Ponieważ krok OCR jest wykonywany na znormalizowanych obrazach, współrzędne układu znajdują się w znormalizowanych przestrzeni obrazu, ale jeśli trzeba wyświetlić oryginalny obraz, przekonwertuj punkty współrzędnych w układzie na oryginalny układ współrzędnych obrazu.
Poniższy algorytm ilustruje wzorzec:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Scenariusz: umiejętności dotyczące obrazów niestandardowych
Obrazy mogą być również przekazywane do i zwracane z umiejętności niestandardowych. Zestaw umiejętności base64 koduje obraz przekazywany do umiejętności niestandardowych. Aby użyć obrazu w ramach umiejętności niestandardowych, ustaw "/document/normalized_images/*/data" jako dane wejściowe niestandardowe umiejętności. W niestandardowym kodzie umiejętności zdekoduj ciąg base64 przed przekonwertowaniem go na obraz. Aby zwrócić obraz do zestawu umiejętności, zakoduj obraz base64 przed zwróceniem go do zestawu umiejętności.
Obraz jest zwracany jako obiekt o następujących właściwościach.
{
"$type": "file",
"data": "base64String"
}
Repozytorium przykładów języka Python usługi Azure Search zawiera kompletny przykład zaimplementowany w języku Python niestandardowej umiejętności, która wzbogaca obrazy.
Przekazywanie obrazów do umiejętności niestandardowych
W scenariuszach, w których potrzebujesz niestandardowej umiejętności do pracy nad obrazami, możesz przekazywać obrazy do umiejętności niestandardowej i zwracać tekst lub obrazy. Poniższy zestaw umiejętności pochodzi z przykładu.
Poniższy zestaw umiejętności pobiera znormalizowany obraz (uzyskany podczas pękania dokumentu) i wyprowadza wycinki obrazu.
Przykładowy zestaw umiejętności
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Przykład umiejętności niestandardowych
Sama umiejętność niestandardowa jest zewnętrzna dla zestawu umiejętności. W tym przypadku jest to kod języka Python, który najpierw wykonuje pętlę przez partię rekordów żądań w niestandardowym formacie umiejętności, a następnie konwertuje ciąg zakodowany w formacie base64 na obraz.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Podobnie jak w celu zwrócenia obrazu, zwróć ciąg zakodowany w formacie base64 w obiekcie JSON z właściwością $type file.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}
Zobacz też
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla