Monitorowanie i diagnostyka usługi Azure Service Fabric
Ten artykuł zawiera omówienie monitorowania i diagnostyki dla usługi Azure Service Fabric. Monitorowanie i diagnostyka mają kluczowe znaczenie dla tworzenia, testowania i wdrażania obciążeń w dowolnym środowisku chmury. Możesz na przykład śledzić sposób używania aplikacji, akcje wykonywane przez platformę usługi Service Fabric, wykorzystanie zasobów z licznikami wydajności oraz ogólną kondycję klastra. Te informacje umożliwiają diagnozowanie i rozwiązywanie problemów oraz zapobieganie ich występowaniu w przyszłości. W następnych kilku sekcjach krótko wyjaśniono poszczególne obszary monitorowania usługi Service Fabric, które należy wziąć pod uwagę w przypadku obciążeń produkcyjnych.
Uwaga
Ten artykuł został niedawno zaktualizowany, aby użyć terminu Dzienniki usługi Azure Monitor zamiast usługi Log Analytics. Dane dziennika są nadal przechowywane w obszarze roboczym usługi Log Analytics i są nadal zbierane i analizowane przez tę samą usługę Log Analytics. Aktualizujemy terminologię, aby lepiej odzwierciedlać rolę dzienników w usłudze Azure Monitor. Aby uzyskać szczegółowe informacje, zobacz Zmiany terminologii usługi Azure Monitor.
Monitorowanie aplikacji
Monitorowanie aplikacji śledzi sposób użycia funkcji i składników aplikacji. Chcesz monitorować aplikacje, aby upewnić się, że problemy wpływające na użytkowników są przechwytywane. Odpowiedzialność za monitorowanie aplikacji zależy od użytkowników tworzących aplikację i jej usługi, ponieważ jest ona unikatowa dla logiki biznesowej aplikacji. Monitorowanie aplikacji może być przydatne w następujących scenariuszach:
- Ile ruchu doświadcza moja aplikacja? — Czy musisz skalować usługi, aby zaspokoić wymagania użytkowników lub rozwiązać potencjalne wąskie gardło w aplikacji?
- Czy moja usługa do obsługi wywołań zakończyła się pomyślnie i śledziła?
- Jakie działania są podejmowane przez użytkowników mojej aplikacji? - Zbieranie danych telemetrycznych może prowadzić przyszłe opracowywanie funkcji i lepszą diagnostykę błędów aplikacji
- Czy moja aplikacja zgłasza nieobsługiwane wyjątki?
- Co się dzieje w ramach usług uruchomionych wewnątrz moich kontenerów?
Doskonałym rozwiązaniem w zakresie monitorowania aplikacji jest to, że deweloperzy mogą używać dowolnych narzędzi i struktur, ponieważ znajduje się ona w kontekście aplikacji. Więcej informacji na temat rozwiązania platformy Azure do monitorowania aplikacji za pomocą usługi Azure Monitor Application Insights można dowiedzieć się w analizie zdarzeń za pomocą usługi Application Insights. Mamy również samouczek dotyczący konfigurowania tej konfiguracji dla aplikacji platformy .NET. W tym samouczku omówiono sposób instalowania odpowiednich narzędzi, przykładu pisania niestandardowych danych telemetrycznych w aplikacji oraz wyświetlania diagnostyki aplikacji i telemetrii w witrynie Azure Portal.
Monitorowanie platformy (klastra)
Użytkownik ma kontrolę nad tym, jakie dane telemetryczne pochodzą z aplikacji, ponieważ użytkownik pisze sam kod, ale co z diagnostyką z platformy Service Fabric? Jednym z celów usługi Service Fabric jest zapewnienie odporności aplikacji na awarie sprzętowe. Ten cel jest osiągany dzięki możliwości wykrywania problemów z infrastrukturą i szybkiego przełączania obciążeń w tryb failover do innych węzłów w klastrze. Ale w tym konkretnym przypadku co zrobić, jeśli same usługi systemowe mają problemy? A jeśli próbujesz wdrożyć lub przenieść obciążenie, naruszono reguły umieszczania usług? Usługa Service Fabric udostępnia diagnostykę tych funkcji i nie tylko, aby upewnić się, że masz informacje o aktywności wykonywanej w klastrze. Oto przykładowe scenariusze monitorowania klastra:
Usługa Service Fabric udostępnia kompleksowy zestaw zdarzeń z pudełka. Dostęp do tych zdarzeń usługi Service Fabric można uzyskać za pośrednictwem magazynu zdarzeń lub kanału operacyjnego (kanał zdarzeń udostępniany przez platformę).
Kanały zdarzeń usługi Service Fabric — w systemie Windows zdarzenia usługi Service Fabric są dostępne od jednego dostawcy ETW z zestawem odpowiednich
logLevelKeywordFilterselementów używanych do wybierania między kanałami operacyjnymi i danymi i komunikatami — jest to sposób oddzielania wychodzących zdarzeń usługi Service Fabric do filtrowania zgodnie z potrzebami. W systemie Linux zdarzenia usługi Service Fabric przechodzą przez narzędzie LTTng i są umieszczane w jednej tabeli usługi Storage, z której można je filtrować zgodnie z potrzebami. Te kanały zawierają wyselekcjonowane zdarzenia ustrukturyzowane, które mogą służyć do lepszego zrozumienia stanu klastra. Diagnostyka jest domyślnie włączona w czasie tworzenia klastra, która tworzy tabelę usługi Azure Storage, w której zdarzenia z tych kanałów są wysyłane do Ciebie w celu wykonywania zapytań w przyszłości.EventStore — magazyn zdarzeń to funkcja oferowana przez platformę, która udostępnia zdarzenia platformy Service Fabric dostępne w narzędziu Service Fabric Explorer i za pośrednictwem interfejsu API REST. Możesz zobaczyć widok migawki tego, co dzieje się w klastrze dla każdej jednostki, np. węzeł, usługa, aplikacja i zapytanie na podstawie czasu zdarzenia. Więcej informacji na temat magazynu zdarzeń można również uzyskać w sekcji EventStore Overview (Omówienie magazynu zdarzeń).
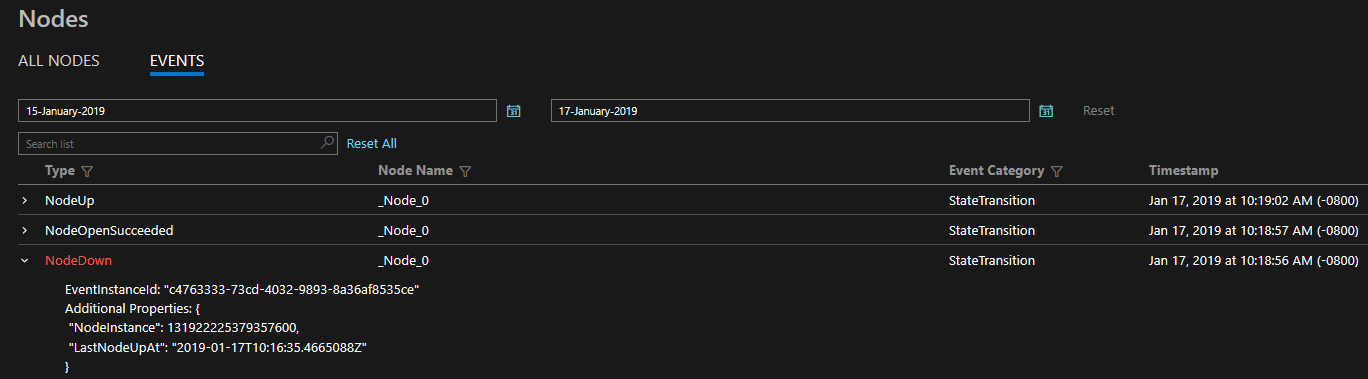
Udostępniona diagnostyka jest w formie kompleksowego zestawu zdarzeń. Te zdarzenia usługi Service Fabric ilustrują akcje wykonywane przez platformę w różnych jednostkach, takich jak węzły, aplikacje, usługi, partycje itp. W ostatnim scenariuszu powyżej, jeśli węzeł miał zostać wyłączony, platforma będzie emitować NodeDown zdarzenie i można je natychmiast powiadomić za pomocą wybranego narzędzia do monitorowania. Inne typowe przykłady obejmują ApplicationUpgradeRollbackStarted lub PartitionReconfigured podczas pracy w trybie failover. Te same zdarzenia są dostępne w klastrach systemów Windows i Linux.
Zdarzenia są wysyłane za pośrednictwem kanałów standardowych w systemach Windows i Linux i mogą być odczytywane przez dowolne narzędzie do monitorowania, które je obsługuje. Rozwiązanie usługi Azure Monitor to dzienniki usługi Azure Monitor. Możesz przeczytać więcej na temat integracji dzienników usługi Azure Monitor, która zawiera niestandardowy pulpit nawigacyjny operacyjny dla klastra i kilka przykładowych zapytań, z których można tworzyć alerty. Więcej pojęć związanych z monitorowaniem klastra jest dostępnych na poziomie platformy zdarzenia i generowania dzienników.
Monitorowanie kondycji
Platforma Service Fabric zawiera model kondycji, który zapewnia rozszerzone raportowanie kondycji dla stanu jednostek w klastrze. Każdy węzeł, aplikacja, usługa, partycja, replika lub wystąpienie ma stale aktualizowalny stan kondycji. Stan kondycji może mieć wartość "OK", "Ostrzeżenie" lub "Błąd". Zdarzenia usługi Service Fabric można traktować jako czasowniki wykonywane przez klaster w różnych jednostkach i kondycji jako przymiotniki dla każdej jednostki. Za każdym razem, gdy kondycja określonej jednostki przechodzi, zdarzenie będzie również emitowane. Dzięki temu możesz skonfigurować zapytania i alerty dotyczące zdarzeń kondycji w wybranym narzędziu do monitorowania, podobnie jak w przypadku każdego innego zdarzenia.
Ponadto umożliwiamy nawet użytkownikom zastępowanie kondycji jednostek. Jeśli aplikacja przechodzi uaktualnienie i testy weryfikacyjne kończą się niepowodzeniem, możesz zapisać w usłudze Service Fabric Health przy użyciu interfejsu API kondycji, aby wskazać, że aplikacja nie jest już w dobrej kondycji, a usługa Service Fabric automatycznie wycofa uaktualnienie. Aby uzyskać więcej informacji na temat modelu kondycji, zapoznaj się z wprowadzeniem do monitorowania kondycji usługi Service Fabric
Watchdogs
Ogólnie rzecz biorąc, watchdog to oddzielna usługa, która monitoruje kondycję i obciążenie usług, wysyła polecenia ping do punktów końcowych i zgłasza nieoczekiwane zdarzenia kondycji w klastrze. Może to pomóc w zapobieganiu błędom, które mogą nie być wykrywane tylko na podstawie wydajności pojedynczej usługi. Watchdogs to również dobre miejsce do hostowania kodu, który wykonuje akcje naprawcze, które nie wymagają interakcji użytkownika, takie jak czyszczenie plików dziennika w magazynie w określonych odstępach czasu. Jeśli chcesz w pełni zaimplementować usługę watchdog sf typu open source, która zawiera łatwy w użyciu model rozszerzalności watchdog i działa zarówno w klastrach systemu Windows, jak i Linux, zobacz projekt FabricObserver . FabricObserver to oprogramowanie gotowe do produkcji. Zachęcamy do wdrożenia serwera FabricObserver w klastrach testowych i produkcyjnych i rozszerzania go w celu zaspokojenia Twoich potrzeb za pomocą modelu wtyczek lub rozwidlania go i pisania własnych wbudowanych obserwatorów. Poprzednie (wtyczki) jest zalecanym podejściem.
Monitorowanie infrastruktury (wydajności)
Po omówieniu diagnostyki w aplikacji i na platformie jak wiemy, że sprzęt działa zgodnie z oczekiwaniami? Monitorowanie podstawowej infrastruktury jest kluczowym elementem zrozumienia stanu klastra i wykorzystania zasobów. Mierzenie wydajności systemu zależy od wielu czynników, które mogą być subiektywne w zależności od obciążeń. Te czynniki są zwykle mierzone za pomocą liczników wydajności. Te liczniki wydajności mogą pochodzić z różnych źródeł, w tym systemu operacyjnego, platformy .NET Framework lub samej platformy Usługi Service Fabric. Niektóre scenariusze, w których byłyby przydatne, to
- Czy wydajnie używam sprzętu? Czy chcesz używać sprzętu na poziomie 90% procesora CPU lub 10%. Jest to przydatne podczas skalowania klastra lub optymalizowania procesów aplikacji.
- Czy mogę proaktywnie przewidywać problemy z infrastrukturą? — wiele problemów jest poprzedzonych nagłymi zmianami (spadkami) wydajności, dzięki czemu można używać liczników wydajności, takich jak użycie operacji we/wy sieci i procesora CPU w celu proaktywnego przewidywania i diagnozowania problemów.
Listę liczników wydajności, które powinny być zbierane na poziomie infrastruktury, można znaleźć w sekcji Metryki wydajności.
Usługa Service Fabric udostępnia również zestaw liczników wydajności dla modeli programowania Reliable Services i Actors. Jeśli używasz jednego z tych modeli, te liczniki wydajności mogą zawierać informacje, aby upewnić się, że aktorzy są prawidłowo uruchamiani i w dół lub że niezawodne żądania obsługi są obsługiwane wystarczająco szybko. Aby uzyskać więcej informacji, zobacz Monitoring for Reliable Service Remoting and Performance monitoring for Reliable Actors (Monitorowanie komunikacji z usługą Reliable Service Remoting and Performance Monitoring for Reliable Actors).
Rozwiązanie usługi Azure Monitor do zbierania tych danych to dzienniki usługi Azure Monitor, podobnie jak monitorowanie na poziomie platformy. Agent usługi Log Analytics powinien zbierać odpowiednie liczniki wydajności i wyświetlać je w dziennikach usługi Azure Monitor.
Zalecana konfiguracja
Teraz, po przejściu do każdego obszaru monitorowania i przykładowych scenariuszy, poniżej przedstawiono podsumowanie narzędzi do monitorowania platformy Azure i skonfigurowanie potrzebne do monitorowania wszystkich powyższych obszarów.
- Monitorowanie aplikacji za pomocą usługi Application Insights
- Monitorowanie klastra za pomocą agenta diagnostyki i dzienników usługi Azure Monitor
- Monitorowanie infrastruktury za pomocą dzienników usługi Azure Monitor
Możesz również użyć i zmodyfikować przykładowy szablon usługi ARM znajdujący się tutaj , aby zautomatyzować wdrażanie wszystkich niezbędnych zasobów i agentów.
Inne rozwiązania do rejestrowania
Mimo że zalecane są dwa rozwiązania, dzienniki usługi Azure Monitor i usługa Application Insights mają wbudowaną integrację z usługą Service Fabric, wiele zdarzeń jest zapisywanych za pośrednictwem dostawców ETW i rozszerzalne z innymi rozwiązaniami rejestrowania. Należy również przyjrzeć się elastycznemu stosowi (zwłaszcza jeśli rozważasz uruchomienie klastra w środowisku offline), Dynatrace lub innej platformie preferencji. Mamy listę zintegrowanych partnerów dostępnych tutaj.
Kluczowe kwestie dla dowolnej wybranej platformy powinny obejmować, jak wygodne jest korzystanie z interfejsu użytkownika, możliwości wykonywania zapytań, dostępnych wizualizacji niestandardowych i pulpitów nawigacyjnych oraz dodatkowych narzędzi, które zapewniają w celu ulepszenia środowiska monitorowania.
Następne kroki
- Aby rozpocząć instrumentację aplikacji, zobacz Zdarzenia na poziomie aplikacji i generowanie dzienników.
- Zapoznaj się z krokami konfigurowania usługi Application Insights dla aplikacji za pomocą usługi Monitor i diagnozowania aplikacji ASP.NET Core w usłudze Service Fabric.
- Dowiedz się więcej o monitorowaniu platformy i zdarzeń zapewnianych przez usługę Service Fabric na poziomie platformy zdarzenia i generowania dzienników.
- Konfigurowanie integracji dzienników usługi Azure Monitor z usługą Service Fabric na stronie Konfigurowanie dzienników usługi Azure Monitor dla klastra
- Dowiedz się, jak skonfigurować dzienniki usługi Azure Monitor na potrzeby monitorowania kontenerów — monitorowanie i diagnostyka kontenerów systemu Windows w usłudze Azure Service Fabric.
- Zobacz przykładowe problemy diagnostyczne i rozwiązania z usługą Service Fabric w diagnozowaniu typowych scenariuszy
- Zapoznaj się z innymi produktami diagnostycznymi, które integrują się z usługą Service Fabric w partnerach diagnostycznych usługi Service Fabric
- Dowiedz się więcej na temat ogólnych zaleceń dotyczących monitorowania zasobów platformy Azure — Najlepsze rozwiązania — Monitorowanie i diagnostyka.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla