Dotyczy: ✔️ Maszyny wirtualne z systemem Linux Maszyny ✔️ wirtualne z systemem Windows ✔️ — elastyczne zestawy ✔️ skalowania
Rozmiary maszyn wirtualnych platformy Azure zostały zaprojektowane w celu zapewnienia szerokiej gamy opcji hostowania serwerów i ich obciążeń w chmurze. Rozmiary są podzielone na różne rodziny i typy, z których każdy jest zoptymalizowany pod kątem określonych celów. Użytkownicy mogą wybrać najbardziej odpowiedni rozmiar maszyny wirtualnej na podstawie ich wymagań, takich jak procesor CPU, pamięć, magazyn i przepustowość sieci.
W tym artykule opisano rozmiary, omówiono dostępne rozmiary i przedstawiono różne opcje dla wystąpień maszyn wirtualnych platformy Azure, których można użyć do uruchamiania aplikacji i obciążeń.
Napiwek
Wypróbuj narzędzie selektora Maszyny wirtualne, aby znaleźć inne rozmiary, które najlepiej pasują do obciążenia.
Rozmiar maszyny wirtualnej i nazewnictwo serii
Rozmiary maszyn wirtualnych platformy Azure są zgodne z określonymi konwencjami nazewnictwa, aby określić różne funkcje i specyfikacje. Każdy znak w nazwie reprezentuje różne aspekty maszyny wirtualnej. Należą do nich rodzina maszyn wirtualnych, liczba procesorów wirtualnych i dodatkowe funkcje, takie jak magazyn w warstwie Premium lub dołączone akceleratory.
Nazewnictwo maszyn wirtualnych jest dalej podzielone na nazwę "Seria" i nazwę "Rozmiar". Nazwy rozmiarów obejmują dodatkowe znaki reprezentujące liczbę procesorów wirtualnych, typ magazynu itp.
Kategoria
opis
Linki
Type
Podstawowa kategoryzacja według zamierzonego obciążenia.
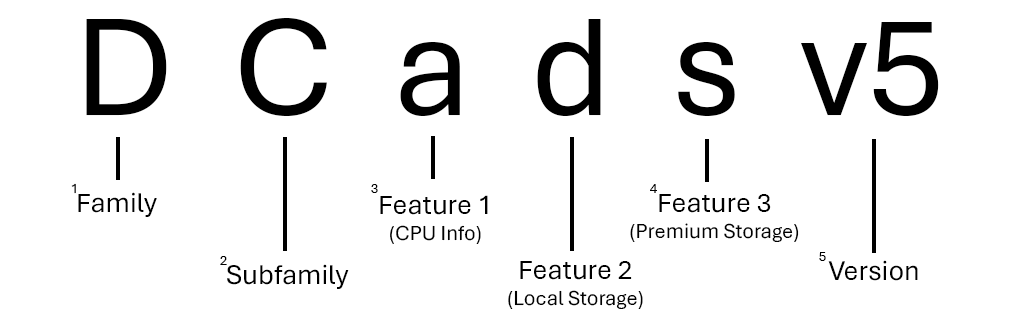
Poniżej przedstawiono podział serii rozmiarów "Ogólnego przeznaczenia, DCads_v5 serii".
1 Większość rodzin jest reprezentowana przy użyciu jednej litery, ale inne, takie jak rozmiary procesora GPU (ND-series, NV-seriesitp.) używają dwóch.
2 Większość podsymalików jest reprezentowana z pojedynczą wyższą literą, ale inne (takie jak Ebsv5-series) są nadal uważane za subfamilies ich rodziny rodziców ze względu na różnice cech.
3 Jeśli na liście nie ma litery funkcji procesora CPU, seria używa procesorów Intel x86-64. Jeśli procesor CPU to AMD, jest on wymieniony jako a. Jeśli procesor CPU jest oparty na usłudze ARM (Microsoft Cobalt lub Ampere Altra), jest on wymieniony jako p.
4 Może istnieć dowolna liczba dodatkowych funkcji w nazwie rozmiaru. Nie może być żadnych (Dv5-series) lub może być trzy (Dplds_v6-series).
5 Numery wersji są wyświetlane tylko w nazwie rozmiaru, jeśli istnieje wiele wersji tej samej serii. Jeśli używasz pierwszej wersji serii (HB-series, B-seriesitp.), często nie jest uwzględniana w nazwie rozmiaru.
Uwaga
Nie wszystkie rozmiary będą miały podfamilie, akceleratory obsługi lub określą dostawcę procesora CPU. Aby uzyskać więcej informacji na temat konwencji nazewnictwa rozmiarów maszyn wirtualnych, zobacz Konwencje nazewnictwa rozmiarów maszyn wirtualnych platformy Azure.
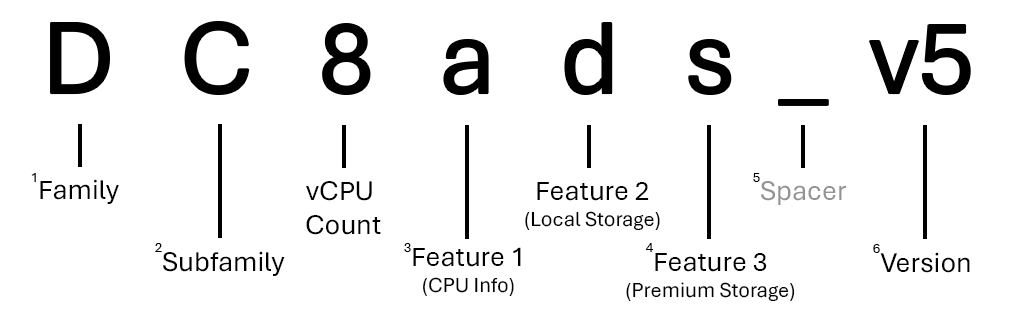
Poniżej przedstawiono podział rozmiaru "Standard_DC8ads_v5" w serii "DCadsv5"
1 Większość rodzin jest reprezentowana przy użyciu jednej litery, ale inne, takie jak rozmiary procesora GPU (ND-series, NV-seriesitp.) używają dwóch.
2 Większość podsymalików jest reprezentowana z pojedynczą wyższą literą, ale inne (takie jak Ebsv5-series) są nadal uważane za subfamilies ich rodziny rodziców ze względu na różnice cech.
3 Jeśli na liście nie ma litery funkcji procesora CPU, seria używa procesorów Intel x86-64. Jeśli procesor CPU to AMD, zostanie wyświetlony jako a. Jeśli procesor CPU jest oparty na usłudze ARM (Microsoft Cobalt lub Ampere Altra), zostanie wyświetlony jako p.
4 Może istnieć dowolna liczba dodatkowych funkcji w nazwie rozmiaru. Nie może być żadnych (Dv5-series) lub może być trzy (Dplds_v6-series).
5 Spacery mogą być wyświetlane wiele razy w nazwie rozmiaru, na przykład w .ND_H100_v5-series W takim przypadku oddzielają identyfikator procesora GPU od pozostałej części nazwy rozmiaru.
6 Numery wersji są wyświetlane tylko w nazwie rozmiaru, jeśli istnieje wiele wersji tej samej serii. Jeśli używasz pierwszej wersji serii (HB-series, B-seriesitp.), często nie jest uwzględniana w nazwie rozmiaru.
Uwaga
Nie wszystkie rozmiary będą miały podfamilie, akceleratory obsługi lub określą dostawcę procesora CPU. Aby uzyskać więcej informacji na temat konwencji nazewnictwa rozmiarów maszyn wirtualnych, zobacz Konwencje nazewnictwa rozmiarów maszyn wirtualnych platformy Azure.
Lista rodzin rozmiarów maszyn wirtualnych według typu
Ta sekcja zawiera listę wszystkich serii rozmiarów bieżącej generacji z kartami przeznaczonymi dla każdej rodziny rozmiarów. Każda grupa ma kolumnę "Lista serii" z połączoną listą wszystkich dostępnych serii rozmiarów. Te linki prowadzą do strony rodziny dla tej serii, gdzie można znaleźć szczegółowe informacje na temat każdego rozmiaru w tej serii lub przejść do strony serii dla listy rozmiarów w tej serii.
Aby dowiedzieć się więcej na temat rodziny rozmiarów, kliknij kartę "rodzina" w każdej sekcji typów. Możesz tam przeczytać podsumowanie rodziny, zobaczyć obciążenia, dla których jest zalecane, i wyświetlić pełną stronę rodzinną ze specyfikacjami dla wszystkich serii w tej rodzinie.
Ogólnego przeznaczenia
Rozmiary maszyn wirtualnych ogólnego przeznaczenia zapewniają zrównoważony stosunek procesora CPU do pamięci. Idealne rozwiązanie na potrzeby testowania i wdrażania, małych i średnich baz danych oraz serwerów internetowych o małym lub średnim ruchu.
Rodzina "A" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych ogólnego przeznaczenia platformy Azure. Są one przeznaczone dla obciążeń na poziomie podstawowym, takich jak środowiska programistyczne i testowe, małe i średnie bazy danych oraz serwery internetowe o niskim natężeniu ruchu.
Opłacalność: Maszyny wirtualne z serii A to niektóre z najbardziej przyjaznych dla budżetu opcji dostępnych na platformie Azure, dzięki czemu są one dobrym wyborem dla projektów z ograniczonymi zasobami finansowymi lub tymi, które nie wymagają wysokiej wydajności możliwości obliczeniowych.
Ogólne obciążenia: maszyny wirtualne serii A są dobrze dostosowane do obsługi podstawowych aplikacji, lekkich serwerów internetowych i małych baz danych, które nie wymagają rozbudowanej wydajności procesora CPU, pamięci lub operacji we/wy.
Aplikacje na poziomie podstawowym: maszyny wirtualne serii A mogą służyć jako dobry punkt wyjścia do wdrażania aplikacji, które nie powinny być znacznie skalowane. Zapewniają one platformę dla aplikacji i usług, które wymagają mniejszej mocy obliczeniowej.
Rodzina B
Rodzina "B" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych ogólnego przeznaczenia platformy Azure. Chociaż tradycyjne maszyny wirtualne platformy Azure zapewniają stałą wydajność procesora CPU, maszyny wirtualne serii B są jedynym typem maszyn wirtualnych, które używają środków na aprowizację wydajności procesora CPU. Maszyny wirtualne serii B wykorzystują model kredytowy procesora CPU do śledzenia ilości używanego procesora CPU — maszyna wirtualna gromadzi środki na użycie procesora CPU, gdy obciążenie działa poniżej podstawowego progu wydajności procesora CPU i używa środków podczas uruchamiania powyżej podstawowego progu wydajności procesora CPU do momentu wykorzystania wszystkich środków. Po zniesieniu wszystkich środków na użycie procesora CPU maszyna wirtualna serii B jest ograniczana z powrotem do podstawowej wydajności procesora CPU, dopóki nie zgromadzi środków na ponowne zwiększenie wydajności procesora CPU.
Elastyczność użycia: maszyny wirtualne rodziny B najlepiej nadają się do obciążeń, które nie wymagają stałej pełnej wydajności procesora CPU.
Idealne aplikacje: maszyny wirtualne rodziny B są idealnymi aplikacjami, w tym serwerami internetowymi, weryfikacją koncepcji, małymi bazami danych i środowiskami kompilacji deweloperskich.
Wymagania dotyczące wydajności: Niektóre obciążenia często mają wymagania dotyczące wydajności z możliwością zwiększenia wydajności, co oznacza, że wymagają one tylko sporadycznie wysokiej wydajności. Maszyny wirtualne rodziny B doskonale nadają się do tego przypadku użycia.
Rodzina D
Rodzina "D" rozmiarów maszyn wirtualnych to jeden z rozmiarów maszyn wirtualnych ogólnego przeznaczenia platformy Azure. Są one przeznaczone dla różnych wymagających obciążeń, takich jak aplikacje dla przedsiębiorstw, serwery internetowe i aplikacje, środowiska programistyczne i testowe oraz zadania przetwarzania wsadowego. Wyposażony w szybsze procesory i większą ilość pamięci na rdzeń niż maszyny wirtualne serii A oferują silną równowagę wydajności, dzięki czemu są odpowiednie dla aplikacji wymagających zarówno wysokiej mocy obliczeniowej, jak i znacznych zasobów pamięci. Są one szczególnie preferowane w przypadku uruchamiania aplikacji klasy korporacyjnej, obsługujących serwery internetowe o średnim natężeniu ruchu i wykonujące przetwarzanie wsadowe intensywnie korzystające z danych.
Zrównoważona wydajność: maszyny wirtualne serii D zapewniają solidną równowagę między możliwościami procesora i rozmiarem pamięci, co sprawia, że są odpowiednie dla większości obciążeń produkcyjnych. Są one wyposażone w szybsze procesory w porównaniu z serią A i zapewniają więcej pamięci na rdzeń.
Aplikacje dla przedsiębiorstw: doskonale nadają się do uruchamiania aplikacji dla przedsiębiorstw, takich jak SAP, Microsoft Dynamics lub duże relacyjne bazy danych, które wymagają dużej mocy obliczeniowej i dużej ilości pamięci.
Środowiska programistyczne i testowe: dzięki zrównoważonym zasobom maszyny wirtualne serii D są idealne dla środowisk programistycznych i testowych, w których deweloperzy muszą ściśle symulować warunki produkcyjne.
Serwery sieci Web i aplikacji: zapewniają niezbędne zasoby do hostowania serwerów internetowych i serwerów aplikacji, które mają umiarkowany i duży ruch, zapewniając bezproblemowe i dynamiczne środowisko użytkownika.
Przetwarzanie wsadowe: maszyny wirtualne serii D są wydajne do obsługi zadań przetwarzania wsadowego, które wymagają szybkiego przetwarzania dużych ilości danych dzięki szybkim procesorom i dużej ilości pamięci.
Serwery gier: wysokiej wydajności maszyn wirtualnych serii D sprawiają, że są one odpowiednie dla serwerów gier, w których opóźnienia i szybkość mają kluczowe znaczenie dla dobrego środowiska użytkownika.
Rodzina kontrolerów domeny
Rodzina serii "DC" to jedno z wystąpień maszyn wirtualnych ogólnego przeznaczenia skoncentrowanych na zabezpieczeniach platformy Azure. Są one przeznaczone do przetwarzania poufnego , oferując rozszerzoną ochronę danych i integralność przy użyciu różnych sprzętowych zaufanych środowisk wykonywania (TEE). Te maszyny wirtualne działają dobrze w przypadku wielu ogólnych obciążeń obliczeniowych, systemów handlu elektronicznego, frontonów internetowych, rozwiązań wirtualizacji pulpitu, poufnych baz danych, innych aplikacji dla przedsiębiorstw i innych.
Ochrona danych: maszyny wirtualne serii DC są idealne dla aplikacji, które zarządzają, przechowują i przetwarzają dane poufne, takie jak dane osobowe, dane finansowe, rekordy kondycji i inne typy informacji poufnych. Szyfrowanie oparte na sprzęcie zapewnia ochronę danych magazynowanych i podczas przetwarzania.
Zgodność z przepisami: W przypadku firm, które muszą spełniać rygorystyczne wymagania prawne dotyczące prywatności i zabezpieczeń danych (takich jak RODO, HIPAA lub przepisy branżowe dotyczące branży finansowej), maszyny wirtualne serii DC zapewniają środowisko zapewniające bezpieczeństwo sprzętu, które może pomóc spełnić te wymagania dotyczące zgodności.
Optymalizacja pod kątem obliczeń
Rozmiary maszyn wirtualnych zoptymalizowane pod kątem obliczeń mają wysoki stosunek procesora CPU do pamięci. Te rozmiary są dobre dla serwerów internetowych o średnim natężeniu ruchu, urządzeń sieciowych, procesów wsadowych i serwerów aplikacji.
Aby dowiedzieć się więcej o określonej rodzinie lub serii rozmiarów, kliknij kartę dla tej rodziny i przewiń, aby znaleźć odpowiednią serię rozmiarów.
Rodzina F
Rodzina "F" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych zoptymalizowanych pod kątem obliczeń platformy Azure. Są one przeznaczone dla obciążeń wymagających wysokiej wydajności procesora CPU, takich jak przetwarzanie wsadowe, serwery internetowe, analiza i gry. Dzięki wysokiemu współczynnikowi procesora CPU do pamięci maszyny wirtualne serii F są wyposażone w zaawansowane procesory do obsługi aplikacji wymagających większej pojemności procesora w stosunku do pamięci. Sprawia to, że są one szczególnie skuteczne w scenariuszach, w których szybkie i wydajne przetwarzanie ma kluczowe znaczenie, dzięki czemu firmy mogą wydajnie i wydajnie uruchamiać aplikacje powiązane z obliczeniami.
Serwery internetowe: maszyny wirtualne serii F doskonale nadają się do hostowania serwerów internetowych i aplikacji, które wymagają znacznej możliwości obliczeniowej do wydajnego obsługi ruchu internetowego bez konieczności posiadania dużej ilości pamięci.
Przetwarzanie wsadowe: maszyny wirtualne serii F są idealne dla zadań wsadowych i innych zadań przetwarzania, które obejmują obsługę dużych ilości danych lub zadań w kolejce, ale są bardziej intensywnie obciążające procesor CPU niż intensywnie korzystające z pamięci.
Serwery aplikacji: aplikacje, które wymagają szybkiego przetwarzania i nie wymagają dużej ilości pamięci, mogą korzystać z maszyn wirtualnych serii F. Mogą one obejmować serwery aplikacji o średnim natężeniu ruchu, serwery zaplecza dla aplikacji dla przedsiębiorstw i inne podobne zadania.
Serwery gier: ze względu na wysoką wydajność procesora CPU maszyny wirtualne serii F są również odpowiednie dla serwerów gier, gdzie szybkie przetwarzanie ma kluczowe znaczenie dla dobrego środowiska gier.
Analiza: maszyny wirtualne serii F mogą być używane w aplikacjach do analizy danych, które wymagają szybkości przetwarzania w celu buforowania liczb i wykonywania obliczeń więcej niż wymagają dużej ilości pamięci.
Rodzina FX
Rodzina "FX" serii rozmiarów maszyn wirtualnych jest jedną z wyspecjalizowanych wystąpień maszyn wirtualnych zoptymalizowanych pod kątem obliczeń platformy Azure, zaprojektowanych głównie z obciążeniami wymagającymi znaczących możliwości procesora CPU. Te maszyny wirtualne korzystają z najnowszych procesorów Intel Ice Lake i są zoptymalizowane pod kątem zadań intensywnie korzystających z obliczeń, takich jak modelowanie finansowe, symulacje naukowe i duże obliczenia. Dzięki wysokiej częstotliwości i dużej pamięci podręcznej na rdzeń maszyny wirtualne serii FX zapewniają wyjątkową moc obliczeniową, co czyni je idealnym rozwiązaniem w scenariuszach wymagających rozbudowanych zasobów przetwarzania i szybkiego wykonywania złożonych operacji.
Elektroniczna automatyzacja projektowania (EDA): maszyny wirtualne serii FX są odpowiednie dla obciążeń EDA, które wymagają wysokich szybkości zegara procesora CPU i wysokich współczynników pamięci do procesora CPU. Te obciążenia korzystają z wysokiej wydajności pojedynczego rdzenia i dużej pojemności pamięci maszyn wirtualnych serii FX.
Przetwarzanie wsadowe: maszyny wirtualne serii FX doskonale nadają się do zadań przetwarzania wsadowego o wysokiej przepływności, takich jak te obejmujące analizę danych i transformację na dużą skalę, gdzie szybkie przetwarzanie ma kluczowe znaczenie.
Analiza danych: maszyny wirtualne serii FX są odpowiednie dla intensywnie korzystających aplikacji do analizy danych, zwłaszcza tych, które wymagają szybszej iteracji i przetwarzania dużych zestawów danych.
Optymalizacja pod kątem pamięci
Rozmiary maszyn wirtualnych zoptymalizowane pod kątem pamięci oferują wysoki stosunek pamięci do procesora CPU, który doskonale nadaje się do serwerów relacyjnych baz danych, średnich i dużych pamięci podręcznych oraz analizy w pamięci.
Aby dowiedzieć się więcej o określonej rodzinie lub serii rozmiarów, kliknij kartę dla tej rodziny i przewiń, aby znaleźć odpowiednią serię rozmiarów.
Rodzina E
Rodzina "E" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych zoptymalizowanych pod kątem pamięci platformy Azure. Są one przeznaczone dla obciążeń intensywnie korzystających z pamięci, takich jak duże bazy danych, analiza danych big data i aplikacje dla przedsiębiorstw, które wymagają znacznej ilości pamięci RAM w celu utrzymania wysokiej wydajności. Wyposażone w wysokie współczynniki pamięci do rdzeni, maszyny wirtualne serii E obsługują aplikacje i usługi, które korzystają z szybszego dostępu do danych i bardziej wydajnych możliwości przetwarzania danych. Sprawia to, że są one szczególnie odpowiednie w scenariuszach obejmujących bazy danych w pamięci i rozległe zadania przetwarzania danych, w których duże ilości pamięci mają kluczowe znaczenie dla optymalnej wydajności.
Obciążenia intensywnie korzystające z pamięci: maszyny wirtualne rodziny E są przeznaczone dla obciążeń wymagających dużego zużycia pamięci w celu wydajnego obsługi zadań, takich jak symulacje, obliczenia na dużą skalę w badaniach naukowych lub modelowanie ryzyka finansowego.
Duże bazy danych i serwery SQL: maszyny wirtualne rodziny E są idealne do hostowania dużych relacyjnych baz danych, takich jak SQL Server i NoSQL, które korzystają z dużych pojemności pamięci w celu zwiększenia wydajności przetwarzania danych i obsługi transakcji.
Aplikacje dla przedsiębiorstw: maszyny wirtualne rodziny E są odpowiednie dla aplikacji korporacyjnych intensywnie korzystających z zasobów, w tym systemów ERP i CRM na dużą skalę, gdzie dostępność dużej ilości pamięci ma kluczowe znaczenie dla zarządzania złożonymi transakcjami i obciążeniami użytkowników.
Aplikacje danych big data: maszyny wirtualne rodziny E są skuteczne w przypadku aplikacji do analizy danych big data, które muszą przetwarzać ogromne ilości danych w pamięci, aby przyspieszyć generowanie analiz i szczegółowych informacji.
Przetwarzanie w pamięci: maszyny wirtualne rodziny E są doskonałe dla baz danych w pamięci (np. SAP HANA), które wymagają dużej ilości pamięci RAM, aby zachować cały zestaw danych w pamięci, co pozwala na bardzo szybkie przetwarzanie danych i odpowiedzi na zapytania.
Magazyn danych: Maszyny wirtualne rodziny E zapewniają niezbędne zasoby dla rozwiązań do magazynowania danych, które obsługują i analizują duże zestawy danych, poprawiając wydajność zapytań i skracając czas odpowiedzi.
Rodzina Eb
Rodzina "Eb" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych zoptymalizowanych pod kątem pamięci platformy Azure. Są one przeznaczone dla obciążeń intensywnie korzystających z pamięci z wysoką wydajnością magazynu zdalnego, takich jak duże bazy danych, analiza danych big data i aplikacje dla przedsiębiorstw, które wymagają znacznej ilości pamięci RAM w celu utrzymania wysokiej wydajności. Wyposażone w wysokie współczynniki pamięci do rdzeni, maszyny wirtualne serii Eb obsługują aplikacje i usługi, które korzystają z szybszego dostępu do danych i bardziej wydajnych możliwości przetwarzania danych. Sprawia to, że są one szczególnie odpowiednie w scenariuszach obejmujących bazy danych w pamięci i rozległe zadania przetwarzania danych, w których duże ilości pamięci mają kluczowe znaczenie dla optymalnej wydajności.
Obciążenia intensywnie korzystające z pamięci: maszyny wirtualne rodziny Eb są przeznaczone dla obciążeń wymagających dużego zużycia pamięci w celu wydajnego obsługi zadań, takich jak symulacje, obliczenia na dużą skalę w badaniach naukowych lub modelowanie ryzyka finansowego.
Duże bazy danych i serwery SQL: maszyny wirtualne rodziny Eb są idealne do hostowania dużych relacyjnych baz danych, takich jak SQL Server i NoSQL, które korzystają z wysokiej pojemności pamięci w celu zwiększenia wydajności przetwarzania danych i obsługi transakcji.
Aplikacje dla przedsiębiorstw: maszyny wirtualne rodziny Eb są odpowiednie dla aplikacji dla przedsiębiorstw intensywnie korzystających z zasobów, w tym systemów ERP i CRM na dużą skalę, gdzie dostępność dużej ilości pamięci ma kluczowe znaczenie dla zarządzania złożonymi transakcjami i obciążeniami użytkowników.
Aplikacje danych big data: maszyny wirtualne rodziny Eb są skuteczne w przypadku aplikacji do analizy danych big data, które muszą przetwarzać ogromne ilości danych w pamięci, aby przyspieszyć generowanie analiz i szczegółowych informacji.
Przetwarzanie w pamięci: maszyny wirtualne rodziny Eb są doskonałe dla baz danych w pamięci (np. SAP HANA), które wymagają dużej ilości pamięci RAM, aby zachować cały zestaw danych w pamięci, co pozwala na bardzo szybkie przetwarzanie danych i odpowiedzi na zapytania.
Magazyn danych: Maszyny wirtualne rodziny eb zapewniają niezbędne zasoby dla rozwiązań do magazynowania danych, które obsługują i analizują duże zestawy danych, poprawiając wydajność zapytań i skracając czas odpowiedzi.
Rodzina EC
Podrodzina "EC" serii rozmiarów maszyn wirtualnych to jedno z skoncentrowanych na zabezpieczeniach wystąpień maszyn wirtualnych zoptymalizowanych pod kątem pamięci platformy Azure. Są one przeznaczone do przetwarzania poufnego z rozszerzoną ochroną i integralnością danych z różnymi sprzętowymi zaufanymi środowiskami wykonywania (TEE). Te wystąpienia są idealne dla obciążeń intensywnie korzystających z pamięci, takich jak duże bazy danych, analiza danych big data i aplikacje dla przedsiębiorstw, które wymagają znacznej ilości pamięci RAM w celu utrzymania wysokiej wydajności.
Obciążenia intensywnie korzystające z pamięci: każde obciążenie wymagające dużego zużycia pamięci w celu wydajnego obsługi zadań, takich jak symulacje, obliczenia na dużą skalę w badaniach naukowych lub modelowanie ryzyka finansowego.
Duże bazy danych i serwery SQL: są idealne do hostowania dużych relacyjnych baz danych, takich jak sql Server i NoSQL, które korzystają z wysokiej pojemności pamięci w celu zwiększenia wydajności przetwarzania danych i obsługi transakcji.
Aplikacje dla przedsiębiorstw: odpowiednie dla aplikacji dla przedsiębiorstw intensywnie korzystających z zasobów, w tym systemów ERP i CRM na dużą skalę, gdzie dostępność dużej ilości pamięci ma kluczowe znaczenie dla zarządzania złożonymi transakcjami i obciążeniami użytkowników.
Aplikacje danych big data: skuteczne w przypadku aplikacji do analizy danych big data, które muszą przetwarzać ogromne ilości danych w pamięci, aby przyspieszyć generowanie analiz i szczegółowych informacji.
Przetwarzanie w pamięci: takie jak bazy danych w pamięci (np. SAP HANA), które wymagają dużej ilości pamięci RAM, aby zachować cały zestaw danych w pamięci, co umożliwia bardzo szybkie przetwarzanie danych i odpowiedzi na zapytania.
Magazyn danych: Udostępnia niezbędne zasoby dla rozwiązań do magazynowania danych, które obsługują i analizują duże zestawy danych, poprawiając wydajność zapytań i skracając czas odpowiedzi.
Rodzina M
Rodzina "M" serii rozmiarów maszyn wirtualnych to jedno z ultra zoptymalizowanych pod kątem pamięci wystąpień maszyn wirtualnych platformy Azure przeznaczonych dla obciążeń wymagających bardzo dużej ilości pamięci, takich jak duże bazy danych w pamięci, magazynowanie danych i obliczenia o wysokiej wydajności (HPC). Wyposażone w znaczne pojemności pamięci RAM i wysokie możliwości procesorów wirtualnych, maszyny wirtualne rodziny M obsługują aplikacje i usługi, które wymagają ogromnej ilości pamięci i znacznej mocy obliczeniowej. Wysoka alokacja zasobów sprawia, że rodzina M jest szczególnie odpowiednia do obsługi zadań, takich jak ciężki program SQL Server i inne obciążenia RDBMS, złożone symulacje naukowe, przetwarzanie danych w czasie rzeczywistym i systemy planowania zasobów przedsiębiorstwa (ERP, large-scale enterprise resource planning), zapewniając najwyższą wydajność dla najbardziej wymagających aplikacji skoncentrowanych na danych.
Obciążenia programu SQL Server wymagające dużej ilości pamięci: rodzina M jest szczególnie skuteczna w przypadku uruchamiania maszyn z programem SQL Server z wysokimi wymaganiami dotyczącymi pamięci, takimi jak przetwarzanie transakcji online (OLTP) lub analiza danych.
Bazy danych w pamięci: rodzina M jest szczególnie skuteczna w przypadku uruchamiania baz danych w pamięci, które wymagają dużej ilości pamięci RAM, takiej jak SQL Server lub SAP HANA.
Aplikacje danych big data: rodzina M jest idealna do obsługi aplikacji danych big data , które wymagają przetwarzania i analizowania ogromnych zestawów danych w pamięci, poprawy wydajności i skrócenia czasu na szczegółowe informacje.
Magazynowanie danych: maszyny wirtualne rodziny M zapewniają wydajność i pamięć wymaganą dla aplikacji do magazynowania danych, ułatwiając szybsze wykonywanie zapytań i lepszą obsługę dużych ilości danych.
Aplikacje dla przedsiębiorstw: rodzina M obsługuje aplikacje dla przedsiębiorstw na dużą skalę, w tym systemy ERP i CRM, które korzystają z większej ilości pamięci w celu efektywnego zarządzania większymi zestawami danych i bardziej złożonymi transakcjami.
Duże obciążenia w środowiskach zwirtualizowanych: rodzina M jest dobrze wyposażona w obsługę dużych środowisk zwirtualizowanych, oferując znaczną ilość pamięci do hostowania wielu maszyn wirtualnych i aplikacji na jednym serwerze fizycznym.
Optymalizacja pod kątem magazynu
Rozmiary maszyn wirtualnych zoptymalizowanych pod kątem magazynu oferują wysoką przepływność dysku i operacje we/wy. Są idealne dla baz danych Big Data, SQL, Baz danych NoSQL, magazynowania danych i dużych transakcyjnych baz danych. Przykłady obejmują bazy danych Cassandra, MongoDB, Cloudera i Redis.
Aby dowiedzieć się więcej o określonej rodzinie lub serii rozmiarów, kliknij kartę dla tej rodziny i przewiń, aby znaleźć odpowiednią serię rozmiarów.
Rodzina L
Rodzina "L" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych zoptymalizowanych pod kątem magazynu platformy Azure. Są one przeznaczone dla obciążeń wymagających wysokiej przepływności dysku i operacji we/wy, takich jak bazy danych, aplikacje danych big data i magazynowanie danych. Wyposażone w wysoką przepływność dysku i duże pojemności magazynu na dysku lokalnym, maszyny wirtualne serii L obsługują aplikacje i usługi, które korzystają z małych opóźnień i dużych szybkości odczytu i zapisu sekwencyjnego. Sprawia to, że są one szczególnie odpowiednie do obsługi zadań, takich jak przetwarzanie dzienników na dużą skalę, analiza danych big data w czasie rzeczywistym i scenariusze obejmujące duże bazy danych, które wykonują częste operacje na dysku, zapewniając wydajną wydajność aplikacji o dużej ilości miejsca do magazynowania.
Aplikacje danych big data: maszyny wirtualne z rodziny L doskonale nadają się do przetwarzania, analizowania i manipulowania dużymi zestawami danych przechowywanymi bezpośrednio na dyskach lokalnych, co zapewnia wysoką wydajność operacji we/wy.
Serwery baz danych: maszyny wirtualne z rodziną L zapewniają niezbędną wydajność dysku lokalnego dla programów SQL Server, MySQL, PostgreSQL i innych serwerów baz danych, które korzystają z szybkiego dostępu do magazynu dysków.
Serwery plików: maszyny wirtualne rodziny L mogą być skutecznie używane jako serwery plików w sieci, obsługujące duże pliki i obsługujące je z wysoką przepływnością, szczególnie przydatne w środowiskach z dużymi plikami multimedialnymi.
Edytowanie i renderowanie wideo: wysoka przepływność dysku i pojemność maszyn wirtualnych rodziny L są korzystne dla zadań edycji i renderowania wideo, gdzie duże pliki wideo są często odczytywane i zapisywane na dysku.
Przyspieszony procesor GPU
Rozmiary maszyn wirtualnych zoptymalizowanych pod kątem procesora GPU to wyspecjalizowane maszyny wirtualne dostępne z pojedynczymi, wielokrotnymi lub ułamkami procesorów GPU. Te rozmiary są przeznaczone dla obciążeń intensywnie korzystających z obliczeń, intensywnie korzystających z grafiki i wizualizacji.
Aby dowiedzieć się więcej o określonej rodzinie lub serii rozmiarów, kliknij kartę dla tej rodziny i przewiń, aby znaleźć odpowiednią serię rozmiarów.
Rodzina NC
Rodzina podrzędna "NC" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych zoptymalizowanych pod kątem procesora GPU platformy Azure. Są one przeznaczone dla obciążeń intensywnie korzystających z obliczeń, takich jak sztuczna inteligencja i uczenie maszynowe, trenowanie modeli uczenia maszynowego, obliczenia o wysokiej wydajności (HPC) i aplikacje intensywnie korzystające z grafiki. Wyposażone w zaawansowane procesory GPU FIRMY NVIDIA, maszyny wirtualne z serii NC oferują znaczne przyspieszenie procesów wymagających dużej mocy obliczeniowej, w tym uczenia głębokiego, symulacji naukowych i renderowania 3D. Sprawia to, że są one szczególnie odpowiednie dla branż, takich jak badania technologiczne, rozrywka i inżynieria, gdzie szybkość renderowania i przetwarzania ma kluczowe znaczenie dla produktywności i innowacji.
Sztuczna inteligencja i uczenie maszynowe: maszyny wirtualne serii NC są idealne do trenowania złożonych modeli uczenia maszynowego i uruchamiania aplikacji sztucznej inteligencji. Procesory GPU FIRMY NVIDIA zapewniają znaczne przyspieszenie obliczeń zwykle związanych z uczeniem głębokim i innymi intensywnymi zadaniami trenowania.
Obliczenia o wysokiej wydajności (HPC): te maszyny wirtualne są odpowiednie do symulacji naukowych, renderowania i innych obciążeń HPC, które mogą być przyspieszane przez procesory GPU. Takie dziedziny jak inżynieria, badania medyczne i modelowanie finansowe często używają maszyn wirtualnych z serii NC do efektywnego obsługi potrzeb obliczeniowych.
Renderowanie grafiki: maszyny wirtualne serii NC są również używane do zastosowań intensywnie korzystających z grafiki, w tym do edycji wideo, renderowania 3D i przetwarzania grafiki w czasie rzeczywistym. Są one szczególnie przydatne w branżach, takich jak tworzenie gier i produkcja filmowa.
Wizualizacja zdalna: w przypadku aplikacji wymagających wysokiej klasy możliwości wizualizacji, takich jak CAD i efekty wizualne, maszyny wirtualne z serii NC mogą zapewnić zdalnie niezbędną moc procesora GPU, umożliwiając użytkownikom pracę nad złożonymi zadaniami graficznymi bez konieczności korzystania z zaawansowanego sprzętu lokalnego.
Symulacja i analiza: Te maszyny wirtualne są również odpowiednie do szczegółowych symulacji i analiz w takich obszarach, jak testowanie awarii samochodowych, obliczana dynamika płynów i modelowanie pogody, gdzie możliwości procesora GPU mogą znacznie przyspieszyć czas przetwarzania.
Rodzina ND
Rodzina "ND" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych przyspieszanych przez procesor GPU platformy Azure. Są one przeznaczone do uczenia głębokiego, badań nad sztuczną inteligencją i zadań obliczeniowych o wysokiej wydajności, które korzystają z zaawansowanego przyspieszania procesora GPU. Wyposażone w procesory GPU FIRMY NVIDIA, maszyny wirtualne serii ND oferują wyspecjalizowane możliwości trenowania i wnioskowania złożonych modeli uczenia maszynowego, ułatwiając szybsze obliczenia i wydajną obsługę dużych zestawów danych. To sprawia, że są one szczególnie odpowiednie dla aplikacji akademickich i komercyjnych w zakresie opracowywania i symulacji sztucznej inteligencji, gdzie najnowocześniejsze technologie procesora GPU mają kluczowe znaczenie dla osiągnięcia szybkich i dokładnych wyników w przetwarzaniu sieci neuronowej i innych zadaniach intensywnie korzystających z obliczeń.
Sztuczna inteligencja i uczenie głębokie: maszyny wirtualne rodziny ND są idealne do trenowania i wdrażania złożonych modeli uczenia głębokiego. Wyposażone w zaawansowane procesory GPU FIRMY NVIDIA zapewniają moc obliczeniową niezbędną do obsługi rozbudowanego trenowania sieci neuronowej z dużymi zestawami danych, co znacznie skraca czas trenowania.
Obliczenia o wysokiej wydajności (HPC): maszyny wirtualne rodziny ND są odpowiednie dla aplikacji HPC, które wymagają przyspieszenia procesora GPU. Pola takie jak badania naukowe, symulacje inżynieryjne (na przykład dynamika płynów obliczeniowych) i przetwarzanie genomiczne mogą korzystać z możliwości obliczeniowych z serii ND.
Rodzina NG
Rodzina "NG" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych zoptymalizowanych pod kątem procesora GPU platformy Azure, przeznaczone specjalnie do gier w chmurze i aplikacji pulpitu zdalnego. Wykorzystują zaawansowane procesory GPU AMD Zawiera Pro™, aby dostarczać wysokiej jakości interaktywne środowiska gier w chmurze, zoptymalizowane pod kątem renderowania złożonych grafiki i przesyłania strumieniowego wideo o wysokiej rozdzielczości. Dzięki temu gracze mogą cieszyć się bezproblemowym, dynamicznym środowiskiem gier dostępnym z dowolnego urządzenia. Ponadto maszyny wirtualne serii NG zapewniają wysokiej jakości, dynamiczne środowisko pulpitu zdalnego, dzięki czemu są idealne dla użytkowników wymagających niezawodnego, wysokiej wydajności dostępu do aplikacji klasycznych z dowolnego miejsca na świecie.
Cloud Gaming: maszyny wirtualne z rodziną NG wykorzystują zaawansowane procesory GPU AMD Amd Series™ PRO w celu dostarczania wysokiej jakości interaktywnych środowisk do gier w chmurze.
Zdalne destkop: maszyny wirtualne rodziny NG mogą być używane w aplikacjach pulpitu zdalnego, zapewniając użytkownikom wysokiej jakości, dynamiczne środowisko użytkownika.
Rodzina nvów
Rodzina "NV" serii rozmiarów maszyn wirtualnych to jedno z przyspieszonych wystąpień maszyn wirtualnych z procesorem GPU platformy Azure, przeznaczonych specjalnie dla aplikacji intensywnie korzystających z grafiki, takich jak renderowanie grafiki, symulacja i pulpity wirtualne. Wyposażony w procesory GPU FIRMY NVIDIA, maszyny wirtualne serii NV zapewniają niezawodną platformę do renderowania i przetwarzania zadań z dużą ilością grafiki, dzięki czemu są idealne dla organizacji wymagających wirtualnych stacji roboczych z zaawansowanymi możliwościami graficznymi. Te maszyny wirtualne obsługują scenariusze, w których niezbędna jest zdalna wizualizacja, współpraca w czasie rzeczywistym i wizualizacja 3D, umożliwiając użytkownikom wydajne uruchamianie aplikacji intensywnie korzystających z grafiki bezpośrednio ze środowiska chmury platformy Azure.
Infrastruktura pulpitu wirtualnego (VDI): maszyny wirtualne rodziny NV są odpowiednie dla pulpitów wirtualnych wymagających możliwości procesora GPU dla zadań, takich jak projektowanie graficzne, edytowanie wideo i aplikacje CAD. Zapewniają one graficzną wydajność niezbędną do bezproblemowego działania w scenariuszach pulpitu zdalnego.
Wizualizacja 3D: maszyny wirtualne rodziny NV są idealne do uruchamiania aplikacji 3D wymagających renderowania o wysokiej wydajności, takich jak wizualizacje architektoniczne, obrazowanie medyczne i inne profesjonalne zadania graficzne.
Praca zdalna grafiki: maszyny wirtualne serii NV są korzystne dla branż, które korzystają z oprogramowania intensywnie korzystającego z grafiki, co umożliwia specjalistom dostęp do aplikacji, takich jak Adobe Photoshop, Autodesk AutoCAD lub Dassault BONN zdalnie z niemal natywną wydajnością.
Przetwarzanie obrazów o wysokiej rozdzielczości: maszyny wirtualne serii NV są idealne do obsługi bardzo dużych aplikacji vRAM, takich jak przetwarzanie obrazów o wysokiej rozdzielczości i analiza. Obejmuje to zadania w dziedzinach takich jak analiza geoprzestrzenna, przetwarzanie obrazów satelitarnych i profesjonalna edycja zdjęć, w których obsługa ogromnych plików obrazów i wykonywanie złożonych manipulacji w czasie rzeczywistym ma kluczowe znaczenie dla produktywności i wydajności.
Przesyłanie strumieniowe wideo: maszyny wirtualne rodziny NV są odpowiednie do przesyłania strumieniowego zawartości wideo o wysokiej rozdzielczości, w tym filmów szkoleniowych i zdarzeń wirtualnych, zapewniając wysokiej jakości dostarczanie bez lokalnych ograniczeń sprzętowych.
Przyspieszona funkcja FPGA
Rozmiary maszyn wirtualnych zoptymalizowane pod kątem fpGA to wyspecjalizowane maszyny wirtualne dostępne z pojedynczymi lub wieloma układami FPGA. Te rozmiary są przeznaczone dla obciążeń intensywnie korzystających z obliczeń. Ten artykuł zawiera informacje o liczbie i typach układów FPGA, procesorów wirtualnych, dysków danych i kart sieciowych. Przepływność magazynu i przepustowość sieci są również uwzględniane dla każdego rozmiaru w tym grupowaniu.
Aby dowiedzieć się więcej o określonej rodzinie lub serii rozmiarów, kliknij kartę dla tej rodziny i przewiń, aby znaleźć odpowiednią serię rozmiarów.
Rodzina NP
Podfałd "NP" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych zoptymalizowanych pod kątem magazynu platformy Azure. Są one przeznaczone dla obciążeń wymagających wysokiej przepływności dysku i operacji we/wy, takich jak bazy danych, aplikacje danych big data i magazynowanie danych. Wysoka przepływność dysku i duże pojemności magazynu dysków lokalnych na maszynach wirtualnych serii L obsługują aplikacje i usługi, które korzystają z małych opóźnień i dużych szybkości odczytu i zapisu sekwencyjnego. Dzięki temu są one odpowiednie do obsługi zadań, takich jak przetwarzanie dzienników na dużą skalę, analiza danych big data w czasie rzeczywistym i scenariusze obejmujące duże bazy danych, które wykonują częste operacje na dysku, zapewniając wydajną wydajność dla aplikacji o dużej pojemności magazynu.
Przetwarzanie danych w czasie rzeczywistym: maszyny wirtualne rodziny NP są excel w środowiskach, w których dane muszą być przetwarzane w czasie rzeczywistym z minimalnym opóźnieniem, na przykład w handlu finansowym, analizie w czasie rzeczywistym i przetwarzaniu danych sieciowych.
Niestandardowa sztuczna inteligencja i uczenie maszynowe: maszyny wirtualne rodziny NP są odpowiednie do przyspieszania zadań wnioskowania sztucznej inteligencji i uczenia maszynowego, gdzie układ FPGA może być zaprogramowany w celu wykonywania określonych algorytmów czasami szybciej niż typowe rozwiązania oparte na procesorze CPU lub procesorze GPU.
Genomics i Life Sciences: maszyny wirtualne rodziny NP mogą znacznie przyspieszyć zadania sekwencjonowania genomicznego i inne aplikacje nauk życiowych, które korzystają z niestandardowego przyspieszania sprzętowego.
Transkodowanie wideo i przesyłanie strumieniowe: układy FPGA mogą służyć do przyspieszania zadań przetwarzania wideo, takich jak transkodowanie i przesyłanie strumieniowe wideo w czasie rzeczywistym, optymalizowanie wydajności i skracanie czasu przetwarzania.
Przetwarzanie sygnałów: maszyny wirtualne rodziny NP są idealne dla aplikacji telekomunikacyjnych i przetwarzania sygnałów, w których konieczna jest szybka manipulacja i analiza sygnałów.
Przyspieszanie bazy danych: maszyny wirtualne rodziny NP mogą ulepszać operacje bazy danych, zwłaszcza w przypadku niestandardowych operacji wyszukiwania i zapytań baz danych na dużą skalę, odciążając te zadania do fpGA.
Obliczenia o wysokiej wydajności
Maszyny wirtualne obliczeń o wysokiej wydajności platformy Azure są zoptymalizowane pod kątem różnych obciążeń HPC, takich jak obliczeniowa dynamika płynów, analiza elementów skończonych, analiza frontonu i zaplecza EDA, renderowanie, dynamika molekularna, geoscience obliczeniowa, symulacja pogody i analiza ryzyka finansowego.
Aby dowiedzieć się więcej o określonej rodzinie lub serii rozmiarów, kliknij kartę dla tej rodziny i przewiń, aby znaleźć odpowiednią serię rozmiarów.
Podfałd "HB" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych z rodziny H zoptymalizowanych pod kątem obliczeń o wysokiej wydajności (HPC) platformy Azure. Są one przeznaczone dla obciążeń intensywnie korzystających z obliczeń, takich jak dynamika płynów obliczeniowych, analiza elementów skończonych i symulacje naukowe na dużą skalę. Procesory AMD EPYC o wysokiej wydajności i szybkiej pamięci na maszynach wirtualnych serii HB oferują wyjątkową przepustowość procesora i pamięci, co czyni je idealnym rozwiązaniem dla aplikacji wymagających rozbudowanych zasobów obliczeniowych do wykonywania obliczeń na dużą skalę i przetwarzania danych. Sprawia to, że są one odpowiednie dla branż, takich jak inżynieria, badania naukowe i analiza danych, w których szybkość i dokładność przetwarzania mają kluczowe znaczenie dla produktywności i innowacji.
Obliczeniowa dynamika płynów (CFD): maszyny wirtualne rodziny HB są idealne do symulacji w takich dziedzinach jak lotnictwo, projektowanie motoryzacyjne i produkcja, gdzie obliczenia dynamiki płynów intensywnie korzystają.
Finite Element Analysis (FEA): maszyny wirtualne rodziny HB są odpowiednie do analiz inżynieryjnych, które symulują zjawiska fizyczne, wymagając intensywnej mocy obliczeniowej do modelowania złożonych systemów i materiałów.
Prognozowanie pogody: maszyny wirtualne rodziny HB mogą obsługiwać ogromne zestawy danych i złożone symulacje wymagane do modelowania pogody o wysokiej rozdzielczości i prognozowania.
Przetwarzanie sejsmiczne: używane w przemyśle naftowym i gazowym maszyny wirtualne rodziny HB mogą przetwarzać dane sejsmiczne, aby pomóc w mapie i zrozumieniu struktur podpowierzchniowych.
Badania naukowe: maszyny wirtualne rodziny HB obsługują szeroką gamę badań naukowych, które wymagają modelowania matematycznego na dużą skalę, w tym fizyki i symulacji chemii obliczeniowej.
Genomiki i bioinformatyka: maszyny wirtualne rodziny HB są również używane w nauce o życiu do analizy genomicznej, gdzie duże ilości danych muszą być szybko przetwarzane w celu dekodowania informacji genetycznych.
Rodzina "HC" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych zoptymalizowanych pod kątem obliczeń o wysokiej wydajności (HPC) platformy Azure. Są one przeznaczone dla obciążeń intensywnie korzystających z obliczeń, które wymagają znacznej mocy procesora CPU, takich jak sekwencjonowanie genomiczne, symulacje inżynieryjne i modelowanie finansowe. Wysokowydajne procesory Intel Xeon Scalable i szybka pamięć na maszynach wirtualnych serii HC oferują wyjątkowe możliwości obliczeniowe i przepustowość pamięci, co czyni je idealnym rozwiązaniem dla aplikacji wymagających intensywnej mocy obliczeniowej do obsługi złożonych obliczeń i wydajnych ogromnych zestawów danych. Te maszyny wirtualne są przeznaczone dla sektorów, takich jak opieka zdrowotna, finanse i inżynieria, gdzie szybkie przetwarzanie danych i dokładność symulacji mają kluczowe znaczenie dla zaawansowanych badań i rozwoju.
Sekwencjonowanie genomiczne: maszyny wirtualne serii HC zapewniają moc obliczeniową potrzebną do sekwencjonowania genomicznego, umożliwiając naukowcom szybkie przetwarzanie i analizowanie dużych zestawów danych genetycznych.
Symulacje inżynieryjne: idealne rozwiązanie do uruchamiania złożonych symulacji w takich dziedzinach jak przemysł motoryzacyjny, lotnictwo i inżynieria mechaniczna. Te symulacje często obejmują analizę elementów skończonych (FEA) i obliczeniową dynamikę płynów (CFD).
Modelowanie finansowe: te maszyny wirtualne mogą obsługiwać wysokie wymagania aplikacji finansowych, w tym analizę ryzyka i symulacje ilościowe, które wymagają ogromnych zasobów obliczeniowych w celu szybkiego wykonywania wielu obliczeń.
Badania naukowe: maszyny wirtualne serii HC obsługują szeroką gamę potrzeb naukowych, szczególnie w dziedzinie fizyki i chemii, gdzie kluczowe znaczenie mają obliczenia na dużą skalę i analizę danych.
Prognozowanie pogody i symulacja klimatu: są one używane w meteorologii do modelowania pogody o wysokiej rozdzielczości i symulacji klimatu, które wymagają przetwarzania dużych zestawów danych i wykonywania złożonych symulacji.
Rodzina "HX" serii rozmiarów maszyn wirtualnych to jedno z wystąpień maszyn wirtualnych zoptymalizowanych pod kątem obliczeń o wysokiej wydajności (HPC) platformy Azure. Są one przeznaczone dla obciążeń intensywnie korzystających z pamięci, które wymagają zarówno dużej ilości pamięci RAM, jak i znacznej wydajności procesora CPU, takich jak bazy danych w pamięci, analiza danych big data i złożone symulacje naukowe. Ekspansywna pamięć i zaawansowane procesory CPU na maszynach wirtualnych serii HX zapewniają niezbędne zasoby do wydajnego obsługi dużych zestawów danych i szybkiego przetwarzania danych. Te maszyny wirtualne są przeznaczone dla sektorów, takich jak usługi finansowe, badania naukowe i planowanie zasobów przedsiębiorstwa, gdzie zarządzanie i analizowanie dużych ilości danych w czasie rzeczywistym ma kluczowe znaczenie dla sukcesu operacyjnego i innowacji.
Bazy danych w pamięci: maszyny wirtualne serii HX doskonale nadają się do hostowania baz danych w pamięci, które wymagają dużej ilości pamięci do obsługi dużych zestawów danych w pamięci RAM w celu uzyskania bardzo szybkiego przetwarzania i dostępu.
Analiza danych big data: mogą obsługiwać aplikacje do analizy danych big data, które muszą przetwarzać ogromne ilości danych w pamięci, aby przyspieszyć analizę, co ma kluczowe znaczenie dla podejmowania decyzji w czasie rzeczywistym.
Genomic Research: Badania genomics często obejmują analizę danych na dużą skalę, gdzie duża pojemność pamięci może znacznie zwiększyć wydajność, umożliwiając więcej zestawów danych przechowywanych w pamięci, przyspieszając analizę.
Symulacje finansowe: Instytucje finansowe używają maszyn wirtualnych serii HX do platform handlowych o wysokiej częstotliwości i symulacji zarządzania ryzykiem, które wymagają szybkiego przetwarzania dużych ilości danych w celu przewidywania trendów akcji lub obliczania ryzyka kredytowego w czasie rzeczywistym.
Systemy ERP: Duże systemy planowania zasobów przedsiębiorstwa (ERP) korzystają z dużej mocy pamięci i przetwarzania maszyn wirtualnych serii HX w celu zarządzania i przetwarzania rozbudowanych danych przedsiębiorstwa oraz obsługi dużej liczby współbieżnych użytkowników.
Zawartość rozmiaru platformy learn
Aby uzyskać informacje o cenach różnych rozmiarów, zobacz strony cennika dla systemu Linux lub Windows.
Aby uzyskać informacje na temat używania interfejsu API REST do wykonywania zapytań dotyczących rozmiarów maszyn wirtualnych, zobacz następujące tematy:
Zapoznaj się z usługą Azure Dedicated Hosts dla serwerów fizycznych, które mogą hostować co najmniej jedną maszynę wirtualną przypisaną do jednej subskrypcji platformy Azure.

 1 Większość rodzin jest reprezentowana przy użyciu jednej litery, ale inne, takie jak rozmiary procesora GPU (
1 Większość rodzin jest reprezentowana przy użyciu jednej litery, ale inne, takie jak rozmiary procesora GPU (