Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano, w jaki sposób generacja wspomagana pobieraniem pozwala LLM-om traktować źródła danych jako zasób wiedzy bez konieczności trenowania.
LLM-y mają obszerne bazy wiedzy dzięki szkoleniu. W przypadku większości scenariuszy możesz wybrać moduł LLM przeznaczony dla Twoich wymagań, ale te moduły LLM nadal wymagają dodatkowego szkolenia w celu zrozumienia określonych danych. Generowanie wspomagane wyszukiwaniem pozwala udostępnić dane LLM-om bez ich wcześniejszego trenowania.
Jak działa RAG
Aby przeprowadzić generowanie wspomagane odzyskiwaniem, należy tworzyć osadzenia dla danych wraz z typowymi pytaniami na ich temat. Można to zrobić na bieżąco lub utworzyć i zapisać osadzenia za pomocą rozwiązania wektorowej bazy danych.
Gdy użytkownik zadaje pytanie, funkcja LLM używa osadzania do porównywania pytania użytkownika z danymi i znajdowania najbardziej odpowiedniego kontekstu. Kontekst ten i pytanie użytkownika trafiają następnie do LLM w podpowiedzi, a LLM generuje odpowiedź na podstawie Twoich danych.
Podstawowy proces RAG
Aby wykonać operację RAG, należy przetworzyć każde źródło danych, którego chcesz użyć do pobierania. Podstawowy proces jest następujący:
- Podziel duże dane na elementy, którymi można zarządzać.
- Przekonwertuj fragmenty na format możliwy do wyszukania.
- Przechowuj przekonwertowane dane w lokalizacji, która umożliwia wydajny dostęp. Ponadto ważne jest przechowywanie odpowiednich metadanych w przypadku cytatów lub odwołań, gdy usługa LLM udostępnia odpowiedzi.
- Przekaż przekonwertowane dane do usługi LLMs w monitach.
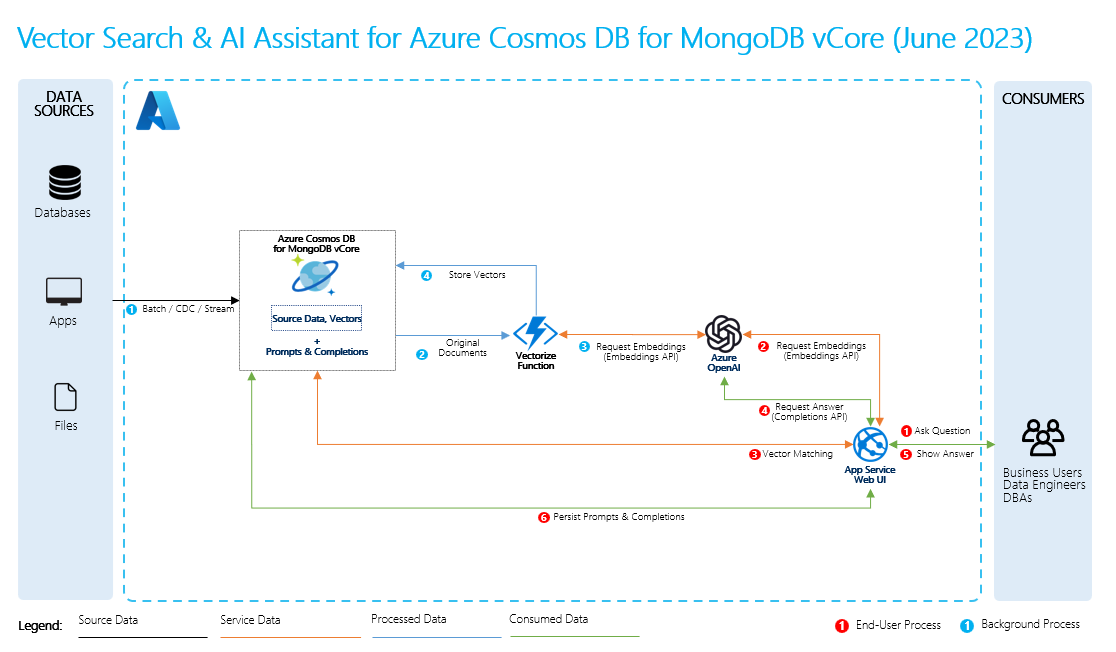
- Dane źródłowe: to miejsce, w którym istnieją twoje dane. Może to być plik/folder na maszynie, plik w magazynie w chmurze, zasób danych usługi Azure Machine Learning, repozytorium Git lub baza danych SQL.
- Fragmentowanie danych: dane w źródle muszą zostać przekonwertowane na zwykły tekst. Na przykład dokumenty programu Word lub pliki PDF muszą być otwierane i konwertowane na tekst. Tekst jest następnie podzielony na mniejsze fragmenty.
- Konwertowanie tekstu na wektory: są to osadzanie. Wektory to liczbowe reprezentacje pojęć konwertowanych na sekwencje liczbowe, co ułatwia komputerom zrozumienie relacji między tymi pojęciami.
- Linki między danymi źródłowymi i osadzeniami: te informacje są przechowywane jako metadane w utworzonych fragmentach, które następnie pomagają LLM w generowaniu cytatów podczas tworzenia odpowiedzi.
Zobacz także
Współpracuj z nami w serwisie GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy i żądania ściągnięcia. Więcej informacji znajdziesz w naszym przewodniku dla współtwórców.