Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
System.IO.Pipelines jest biblioteką zaprojektowaną w celu ułatwienia operacji we/wy o wysokiej wydajności na platformie .NET. Pakiet jest przeznaczony dla platformy .NET Standard w celu zapewnienia szerokiej zgodności, programu .NET Framework i nowoczesnej platformy .NET. W nowoczesnych wersjach System.IO.Pipelines platformy .NET jest zawarta w strukturze udostępnionej i nie wymaga oddzielnego pakietu NuGet.
Biblioteka jest również dostępna jako pakiet NuGet System.IO.Pipelines .
Jaki problem rozwiązuje system.IO.Pipelines?
Aplikacje, które analizują dane przesyłane strumieniowo, składają się ze standardowego kodu o wielu wyspecjalizowanych i nietypowych przepływach kodu. Standardowy i specjalny kod przypadku jest złożony i trudny do utrzymania.
System.IO.Pipelines został zaprojektowany w celu:
- Mają wysoką wydajność analizowania danych przesyłanych strumieniowo.
- Zmniejsz złożoność kodu.
Ten kod jest typowy dla serwera TCP, który odbiera komunikaty rozdzielane wierszami (rozdzielane przez '\n') z klienta:
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
Powyższy kod ma kilka problemów:
- Cała wiadomość (koniec wiersza) może nie zostać odebrana w jednym wywołaniu metody
ReadAsync. - Ignoruje wynik
stream.ReadAsync.stream.ReadAsyncZwraca ilość odczytanych danych. - Nie obsługuje przypadku, gdy wiele linii jest odczytywanych podczas pojedynczego wywołania
ReadAsync. - Przydziela tablicę
bytez każdym odczytem.
Aby rozwiązać powyższe problemy, wprowadź następujące zmiany:
Buforuj dane przychodzące do momentu znalezienia nowego wiersza.
Przeanalizuj wszystkie wiersze zwrócone w buforze.
Wiersz może być większy niż 1 KB (1024 bajty). Kod musi zmienić rozmiar buforu wejściowego, dopóki ogranicznik nie zostanie znaleziony tak, aby pasował do kompletnego wiersza wewnątrz buforu.
- Jeśli rozmiar buforu zostanie zmieniony, więcej kopii buforu jest wykonywanych, gdy pojawiają się dłuższe wiersze w danych wejściowych.
- Aby zmniejszyć zmarnowane miejsce, skompaktuj bufor używany do odczytywania wierszy.
Rozważ użycie buforowania, aby uniknąć wielokrotnego przydzielania pamięci.
Ten kod rozwiązuje niektóre z tych problemów:
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer.
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer.
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool.
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes.
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data.
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed,
bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset.
var lineLength = linePosition - bytesConsumed;
// Process the line.
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line consumed (including \n).
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
Poprzedni kod jest złożony i nie dotyczy wszystkich zidentyfikowanych problemów. Sieć o wysokiej wydajności zwykle oznacza pisanie złożonego kodu w celu zmaksymalizowania wydajności.
System.IO.Pipelines został zaprojektowany tak, aby ułatwić pisanie tego typu kodu.
Fajka
Użyj klasy Pipe, aby utworzyć parę PipeWriter/PipeReader. Wszystkie dane zapisane w obiekcie PipeWriter są dostępne w pliku PipeReader:
var pipe = new Pipe();
PipeReader reader = pipe.Reader;
PipeWriter writer = pipe.Writer;
Podstawowe użycie rury
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket.
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader.
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// By completing PipeWriter, tell the PipeReader that there's no more data coming.
await writer.CompleteAsync();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line))
{
// Process the line.
ProcessLine(line);
}
// Tell the PipeReader how much of the buffer has been consumed.
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming.
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete.
await reader.CompleteAsync();
}
bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
// Look for a EOL in the buffer.
SequencePosition? position = buffer.PositionOf((byte)'\n');
if (position == null)
{
line = default;
return false;
}
// Skip the line + the \n.
line = buffer.Slice(0, position.Value);
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
return true;
}
Dwie pętle obsługują odczyt i zapis:
-
FillPipeAsyncodczytuje zSocketi zapisuje doPipeWriter. -
ReadPipeAsyncodczytuje zPipeReaderwierszy przychodzących i analizuje je.
Nie są przydzielane jawne bufory. Całe zarządzanie buforami jest delegowane na implementacje PipeReader i PipeWriter. Delegowanie zarządzania buforami ułatwia kodowi koncentrowanie się wyłącznie na logice biznesowej.
W pierwszej pętli:
- PipeWriter.GetMemory(Int32) jest wywoływane w celu pobrania pamięci z bazowego modułu zapisywania.
-
PipeWriter.Advance(Int32) jest wywoływana, aby poinformować
PipeWriter, ile danych zostało zapisanych do bufora. -
PipeWriter.FlushAsync jest wywoływane w celu udostępnienia danych
PipeReader.
W drugiej pętli element PipeReader zużywa bufory zapisane przez PipeWriter. Bufory pochodzą z gniazda. Wywołanie metody PipeReader.ReadAsync:
Zwraca element ReadResult zawierający dwa ważne informacje:
- Dane, które zostały odczytane w postaci ReadOnlySequence<T>.
- Wartość logiczna
IsCompletedwskazująca, czy osiągnięto koniec danych (EOF).
Po znalezieniu ogranicznika końca wiersza (EOL) i przeanalizowaniu wiersza:
- Logika przetwarza bufor, aby pominąć już przetworzone dane.
-
PipeReader.AdvanceTo jest wywoływany, aby poinformować
PipeReader, ile danych zostało wykorzystanych i zbadanych.
Pętle czytnika i zapisującego kończą się wywołaniem PipeReader.Complete i PipeWriter.Complete. Wywołanie Complete zwalnia pamięć przydzieloną przez program Pipe .
Przeciwciśnienie i sterowanie przepływem
W idealnym przypadku czytanie i analizowanie współpracują ze sobą:
- Wątek odczytu pobiera dane z sieci i umieszcza je w buforach.
- Wątek analizy jest odpowiedzialny za konstruowanie odpowiednich struktur danych.
Zazwyczaj analizowanie zajmuje więcej czasu niż tylko kopiowanie bloków danych z sieci:
- Wątek odczytu wyprzedza wątek analizowania.
- Wątek odczytu musi zwolnić lub przydzielić więcej pamięci do przechowywania danych dla wątku analizowania.
W celu uzyskania optymalnej wydajności istnieje równowaga między częstymi wstrzymaniami i przydzielaniem większej ilości pamięci.
Aby rozwiązać powyższy problem, Pipe ma dwa ustawienia umożliwiające sterowanie przepływem danych:
- PauseWriterThreshold: określa, ile danych należy buforować przed wywołaniami wstrzymywania FlushAsync .
- ResumeWriterThreshold: Określa ilość danych, które czytelnik musi obserwować przed wznowieniem wywołań do PipeWriter.FlushAsync.
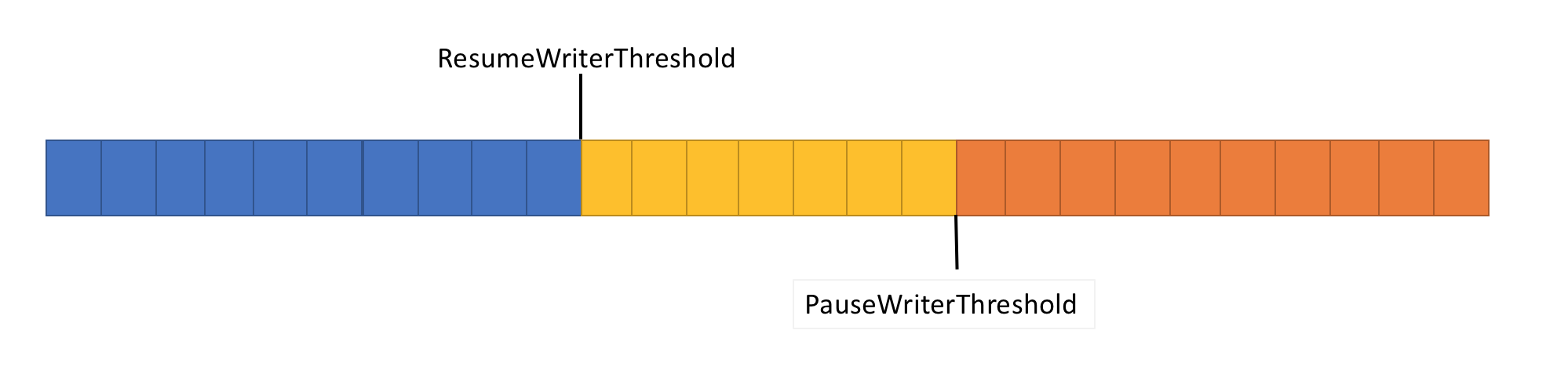
- Zwraca niekompletny
ValueTask<FlushResult>, gdy ilość danych wPipeprzekroczyPauseWriterThreshold. - Kończy
ValueTask<FlushResult>się, gdy staje się niższy niżResumeWriterThreshold.
Dwie wartości są używane w celu zapobiegania szybkiemu przełączaniu, które może wystąpić, jeśli używa się tylko jednej wartości.
Przykłady
// The Pipe will start returning incomplete tasks from FlushAsync until
// the reader examines at least 5 bytes.
var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5);
var pipe = new Pipe(options);
Harmonogram Rurociągów
Zwykle podczas używania async i await, kod asynchroniczny jest wznawiany na jednym z: TaskScheduler lub bieżącym SynchronizationContext.
Podczas wykonywania operacji we/wy ważne jest, aby mieć precyzyjną kontrolę nad miejscem wykonywania operacji we/wy. Ta kontrolka umożliwia efektywne korzystanie z pamięci podręcznych procesora CPU. Wydajne buforowanie ma kluczowe znaczenie dla aplikacji o wysokiej wydajności, takich jak serwery internetowe. PipeScheduler zapewnia kontrolę nad miejscem uruchomienia wywołań zwrotnych asynchronicznych. Domyślnie:
- Bieżący
jest używany. - Jeśli nie ma
SynchronizationContext, używa puli wątków do uruchamiania wywołań zwrotnych.
public static void Main(string[] args)
{
var writeScheduler = new SingleThreadPipeScheduler();
var readScheduler = new SingleThreadPipeScheduler();
// Tell the Pipe what schedulers to use and disable the SynchronizationContext.
var options = new PipeOptions(readerScheduler: readScheduler,
writerScheduler: writeScheduler,
useSynchronizationContext: false);
var pipe = new Pipe(options);
}
// This is a sample scheduler that async callbacks on a single dedicated thread.
public class SingleThreadPipeScheduler : PipeScheduler
{
private readonly BlockingCollection<(Action<object> Action, object State)> _queue =
new BlockingCollection<(Action<object> Action, object State)>();
private readonly Thread _thread;
public SingleThreadPipeScheduler()
{
_thread = new Thread(DoWork);
_thread.Start();
}
private void DoWork()
{
foreach (var item in _queue.GetConsumingEnumerable())
{
item.Action(item.State);
}
}
public override void Schedule(Action<object?> action, object? state)
{
if (state is not null)
{
_queue.Add((action, state));
}
// else log the fact that _queue.Add was not called.
}
}
PipeScheduler.ThreadPool to implementacja PipeScheduler , która kolejkuje wywołania zwrotne do puli wątków.
PipeScheduler.ThreadPool jest domyślnym i ogólnie najlepszym wyborem.
PipeScheduler.Inline może powodować niezamierzone konsekwencje, takie jak zakleszczenia.
Resetowanie rurociągu
Ponowne wykorzystanie Pipe obiektu jest często wydajne. Aby zresetować potok, wywołaj PipeReaderReset po zakończeniu zarówno PipeReader, jak i PipeWriter.
PipeReader
PipeReader zarządza pamięcią w imieniu wywołującego.
Zawsze dzwonijPipeReader.AdvanceTo po wywołaniu metody PipeReader.ReadAsync. To pozwala PipeReader wiedzieć, kiedy obiekt wywołujący zakończył używanie pamięci, co umożliwia jej śledzenie. Element ReadOnlySequence<T> zwrócony z PipeReader.ReadAsync jest prawidłowy tylko do momentu wywołania PipeReader.AdvanceTo. Niedozwolone jest używanie ReadOnlySequence<T> po wywołaniu PipeReader.AdvanceTo.
PipeReader.AdvanceTo przyjmuje dwa SequencePosition argumenty:
- Pierwszy argument określa, ile pamięci zostało zużyte.
- Drugi argument określa, ile buforu zaobserwowano.
Oznaczanie danych jako wykorzystanych oznacza, że potok może zwrócić pamięć do podstawowej puli buforów. Oznaczenie danych jako obserwowanych kontroluje, co zrobi następne wywołanie PipeReader.ReadAsync. Oznaczenie wszystkiego jako zaobserwowanego oznacza, że następne wywołanie PipeReader.ReadAsync nie zwróci, dopóki nie będzie więcej danych zapisanych w potoku. Każda inna wartość sprawia, że następne wywołanie PipeReader.ReadAsync powoduje natychmiastowe zwrócenie obserwowanych i nieobserwowanych danych, ale nie danych, które zostały już zużyte.
Scenariusze odczytu danych przesyłanych strumieniowo
Podczas odczytywania danych przesyłanych strumieniowo pojawia się kilka typowych wzorców:
- Biorąc pod uwagę strumień danych, przeanalizuj pojedynczy komunikat.
- Biorąc pod uwagę strumień danych, przeanalizuj wszystkie dostępne komunikaty.
W tych przykładach użyto metody TryParseLines do analizowania komunikatów z ReadOnlySequence<T>.
TryParseLines Analizuje pojedynczy komunikat i aktualizuje bufor wejściowy w celu przycinania przeanalizowanego komunikatu z buforu.
TryParseLines nie jest częścią platformy .NET; jest to metoda napisana przez użytkownika używana w poniższych sekcjach.
bool TryParseLines(ref ReadOnlySequence<byte> buffer, out Message message);
Odczytywanie pojedynczej wiadomości
Ten kod odczytuje pojedynczy komunikat z obiektu PipeReader i zwraca go do obiektu wywołującego.
async ValueTask<Message?> ReadSingleMessageAsync(PipeReader reader,
CancellationToken cancellationToken = default)
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
// In the event that no message is parsed successfully, mark consumed
// as nothing and examined as the entire buffer.
SequencePosition consumed = buffer.Start;
SequencePosition examined = buffer.End;
try
{
if (TryParseLines(ref buffer, out Message message))
{
// A single message was successfully parsed so mark the start of the
// parsed buffer as consumed. TryParseLines trims the buffer to
// point to the data after the message was parsed.
consumed = buffer.Start;
// Examined is marked the same as consumed here, so the next call
// to ReadSingleMessageAsync will process the next message if there's
// one.
examined = consumed;
return message;
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(consumed, examined);
}
}
return null;
}
Powyższy kod:
- Analizuje pojedynczy komunikat.
- Aktualizuje zużyte
SequencePositioni przeanalizowaneSequencePosition, aby wskazać początek przyciętego bufora wejściowego.
Dwa SequencePosition argumenty są aktualizowane, ponieważ TryParseLines usuwa przeanalizowany komunikat z buforu wejściowego. Ogólnie rzecz biorąc, podczas analizowania pojedynczego komunikatu z buforu zbadane stanowisko powinno być jednym z następujących elementów:
- Koniec wiadomości.
- Koniec buforu odbiorczego, jeśli nie odnaleziono wiadomości.
Pojedynczy przypadek komunikatu ma największy potencjał błędów. Przekazanie nieprawidłowych wartości do examined może spowodować wyjątek OutOfMemory lub pętlę nieskończoną. Aby uzyskać więcej informacji, zobacz sekcję Typowe problemy PipeReader w tym artykule.
Ważne
ReadSingleMessageAsync nie wywołuje metody PipeReader.CompleteAsync. Obiekt wywołujący jest odpowiedzialny za ukończenie elementu PipeReader. Wywołanie PipeReader.CompleteAsync wewnątrz ReadSingleMessageAsync sygnalizuje, że nie można odczytać więcej danych, co uniemożliwia odczytanie kolejnych komunikatów.
Odczytywanie wielu komunikatów
Ten kod odczytuje wszystkie komunikaty z obiektu PipeReader i wywołuje poszczególne wywołania ProcessMessageAsync .
async Task ProcessMessagesAsync(PipeReader reader, CancellationToken cancellationToken = default)
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Ponieważ ProcessMessagesAsync jest właścicielem pełnej pętli odczytu komunikatów, po jej zakończeniu wywołuje PipeReader.CompleteAsync. W przeciwieństwie do przypadku pojedynczej wiadomości obiekt wywołujący nie musi ukończyć czytnika.
ProcessMessagesAsync przejmuje pełną własność cyklu życia PipeReader.
Anulowanie
- Obsługuje przekazywanie elementu CancellationToken.
- Zgłasza błąd OperationCanceledException, jeśli
CancellationTokenzostanie anulowana podczas oczekiwania na odczyt. - Obsługuje sposób anulowania bieżącej operacji odczytu za pomocą PipeReader.CancelPendingRead, co pozwala uniknąć zgłaszania wyjątku. Wywołanie
PipeReader.CancelPendingReadpowoduje, że bieżące lub następne wywołanie PipeReader.ReadAsync zwraca ReadResult, z wartościąIsCanceledustawioną natrue. Przydatne do zatrzymania istniejącej pętli odczytu w sposób niedestrukcyjny i bez wyjątków.
private PipeReader reader;
public MyConnection(PipeReader reader)
{
this.reader = reader;
}
public void Abort()
{
// Cancel the pending read so the process loop ends without an exception.
reader.CancelPendingRead();
}
public async Task ProcessMessagesAsync()
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
if (result.IsCanceled)
{
// The read was canceled. You can quit without reading the existing data.
break;
}
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Typowe problemy z usługą PipeReader
Przekazanie nieprawidłowych wartości do
consumedlubexaminedmoże spowodować odczytanie już odczytanych danych.Przekazanie
buffer.Endw wyniku zbadania może spowodować:- Zatrzymane dane
- Ewentualny wyjątek braku pamięci (OOM), jeśli dane nie są przetwarzane. Na przykład
PipeReader.AdvanceTo(position, buffer.End)podczas przetwarzania jednej wiadomości na raz z buforu.
Przekazywanie nieprawidłowych wartości do
consumedlubexaminedmoże spowodować nieskończoną pętlę. Na przykładPipeReader.AdvanceTo(buffer.Start), jeślibuffer.Startsię nie zmieniło, spowoduje to, że następne wywołanie PipeReader.ReadAsync zwróci natychmiast, jeszcze zanim nadejdą nowe dane.Przekazywanie nieprawidłowych wartości do
consumedlubexaminedmoże spowodować nieskończone buforowanie (ostateczne OOM).Użycie ReadOnlySequence<T> po wywołaniu PipeReader.AdvanceTo może spowodować uszkodzenie pamięci (użycie po zwolnieniu).
Niepowodzenie wywołania Complete/CompleteAsync może spowodować wyciek pamięci.
Sprawdzanie ReadResult.IsCompleted i zamykanie logiki odczytu przed przetworzeniem buforu powoduje utratę danych. Warunek zakończenia pętli powinien być oparty na elementach
ReadResult.Buffer.IsEmptyiReadResult.IsCompleted. Wykonanie tego błędnie może spowodować nieskończoną pętlę.
Problematyczny kod
❌ Utrata danych
Element ReadResult może zwrócić końcowy segment danych, gdy IsCompleted jest ustawiony na true. Nie można odczytać tych danych przed zamknięciem pętli odczytu, co powoduje utratę danych.
Ostrzeżenie
NIE używaj następującego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Poniższy przykład został przedstawiony w celu wyjaśnienia typowych problemów usługi PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> dataLossBuffer = result.Buffer;
if (result.IsCompleted)
break;
Process(ref dataLossBuffer, out Message message);
reader.AdvanceTo(dataLossBuffer.Start, dataLossBuffer.End);
}
Ostrzeżenie
Nie używaj powyższego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Powyższy przykład jest dostarczany w celu wyjaśnienia typowych problemów PipeReader.
❌ Pętla nieskończona
Poniższa logika może prowadzić do nieskończonej pętli, jeśli Result.IsCompleted jest true, ale w buforze nigdy nie znajduje się pełna wiadomość.
Ostrzeżenie
NIE używaj następującego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Poniższy przykład został przedstawiony w celu wyjaśnienia typowych problemów usługi PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (result.IsCompleted && infiniteLoopBuffer.IsEmpty)
break;
Process(ref infiniteLoopBuffer, out Message message);
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Ostrzeżenie
Nie używaj powyższego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Powyższy przykład jest dostarczany w celu wyjaśnienia typowych problemów PipeReader.
Oto kolejny fragment kodu z tym samym problemem. Sprawdza, czy bufor jest niepusty przed sprawdzeniem ReadResult.IsCompleted. Ponieważ znajduje się w else ifpętli, działa w nieskończoność, jeśli w buforze nigdy nie ma pełnego komunikatu.
Ostrzeżenie
NIE używaj następującego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Poniższy przykład został przedstawiony w celu wyjaśnienia typowych problemów usługi PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (!infiniteLoopBuffer.IsEmpty)
Process(ref infiniteLoopBuffer, out Message message);
else if (result.IsCompleted)
break;
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Ostrzeżenie
Nie używaj powyższego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Powyższy przykład jest dostarczany w celu wyjaśnienia typowych problemów PipeReader.
❌ Aplikacja nie odpowiada
Bezwarunkowe wywoływanie PipeReader.AdvanceTo z buffer.End w pozycji examined może spowodować, że podczas analizowania pojedynczego komunikatu aplikacja przestanie odpowiadać. Następne wywołanie PipeReader.AdvanceTo nie zwróci wyniku aż do:
- W potoku jest więcej zapisanych danych.
- Nowe dane nie zostały wcześniej zbadane.
Ostrzeżenie
NIE używaj następującego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Poniższy przykład został przedstawiony w celu wyjaśnienia typowych problemów usługi PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> hangBuffer = result.Buffer;
Process(ref hangBuffer, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(hangBuffer.Start, hangBuffer.End);
if (message != null)
return message;
}
Ostrzeżenie
Nie używaj powyższego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Powyższy przykład jest dostarczany w celu wyjaśnienia typowych problemów PipeReader.
❌ Brak pamięci (OOM)
Przy następujących warunkach ten kod będzie buforować aż do momentu OutOfMemoryException wystąpienia.
- Nie ma maksymalnego rozmiaru komunikatu.
- Dane zwrócone z
PipeReadernie tworzą kompletnego komunikatu. Na przykład druga strona zapisuje duży komunikat (na przykład komunikat o rozmiarze 4 GB).
Ostrzeżenie
NIE używaj następującego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Poniższy przykład został przedstawiony w celu wyjaśnienia typowych problemów usługi PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> thisCouldOutOfMemory = result.Buffer;
Process(ref thisCouldOutOfMemory, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(thisCouldOutOfMemory.Start, thisCouldOutOfMemory.End);
if (message != null)
return message;
}
Ostrzeżenie
Nie używaj powyższego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Powyższy przykład jest dostarczany w celu wyjaśnienia typowych problemów PipeReader.
❌ Uszkodzenie pamięci
Podczas zapisywania pomocników odczytujących bufor skopiuj dowolny zwrócony ładunek przed wywołaniem metody Advance. Poniższy przykład zwraca pamięć, która została przez Pipe wyrzucona i może zostać ponownie użyta do następnej operacji (odczyt/zapis).
Ostrzeżenie
NIE używaj następującego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Poniższy przykład został przedstawiony w celu wyjaśnienia typowych problemów usługi PipeReader.
public class Message
{
public ReadOnlySequence<byte> CorruptedPayload { get; set; }
}
Environment.FailFast("This code is terrible, don't use it!");
Message message = null;
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
ReadHeader(ref buffer, out int length);
if (length <= buffer.Length)
{
message = new Message
{
// Slice the payload from the existing buffer
CorruptedPayload = buffer.Slice(0, length)
};
buffer = buffer.Slice(length);
}
if (result.IsCompleted)
break;
reader.AdvanceTo(buffer.Start, buffer.End);
if (message != null)
{
// This code is broken since reader.AdvanceTo() was called with a position *after* the buffer
// was captured.
break;
}
}
return message;
}
Ostrzeżenie
Nie używaj powyższego kodu. Użycie tego przykładu spowoduje utratę danych, zawieszanie się, problemy z zabezpieczeniami i nie powinny być kopiowane. Powyższy przykład jest dostarczany w celu wyjaśnienia typowych problemów PipeReader.
PipeWriter
Menedżer buforów PipeWriter zarządza zapisywaniem w imieniu wywołującego.
PipeWriter implementuje IBufferWriter<byte>.
IBufferWriter<byte> zapewnia dostęp do buforów w celu wykonywania operacji zapisu bez dodatkowych kopii buforu.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
// Request at least 5 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(5);
// Write directly into the buffer.
int written = Encoding.ASCII.GetBytes("Hello".AsSpan(), memory.Span);
// Tell the writer how many bytes were written.
writer.Advance(written);
await writer.FlushAsync(cancellationToken);
}
Poprzedni kod:
- Żąda buforu o rozmiarze co najmniej 5 bajtów z
PipeWriterprzy użyciu GetMemory. - Zapisuje bajty dla ciągu ASCII
"Hello"do zwracanegoMemory<byte>. - Wywołanie Advance wskazuje liczbę bajtów zapisanych w buforze.
- Opróżnia element
PipeWriter, który wysyła bajty do urządzenia bazowego.
Poprzednia metoda zapisu używa buforów dostarczonych przez PipeWriter. Również może użyć PipeWriter.WriteAsync, które:
- Kopiuje istniejący bufor do
PipeWriter. - Wywołuje GetSpan, Advance w odpowiednich przypadkach i wywołuje FlushAsync.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer, there's no need to call Advance here
// (Write does that).
await writer.WriteAsync(helloBytes, cancellationToken);
}
Anulowanie
FlushAsync obsługuje przekazywanie elementu CancellationToken. Przekazywanie CancellationToken skutkuje OperationCanceledException w przypadku anulowania tokenu, gdy czekanie na opróżnianie jest w toku.
PipeWriter.FlushAsync obsługuje sposób anulowania bieżącej operacji opróżniania za pośrednictwem PipeWriter.CancelPendingFlush bez zgłaszania wyjątku. Wywołanie PipeWriter.CancelPendingFlush powoduje, że bieżące lub następne wywołanie PipeWriter.FlushAsync lub PipeWriter.WriteAsync zwraca FlushResult z ustawioną wartością IsCanceled na true. Jest to przydatne w celu powstrzymania odprowadzania w sposób niedestrukcyjny i bez wyjątków.
Typowe problemy z PipeWriter
- GetSpan i GetMemory zwraca bufor z co najmniej żądaną ilością pamięci. Nie zakładaj dokładnych rozmiarów buforu.
- Kolejne wywołania nie gwarantują zwrócenia tego samego bufora ani bufora o tym samym rozmiarze.
- Po wywołaniu Advance polecenia należy zażądać nowego buforu, aby kontynuować zapisywanie większej ilości danych. Nie można zapisać wcześniej uzyskanego buforu.
- Wywołanie GetMemory lub GetSpan, podczas gdy istnieje niekompletne wywołanie FlushAsync, nie jest bezpieczne.
- Wywoływanie Complete lub CompleteAsync w przypadku braku pływu danych może spowodować uszkodzenie pamięci.
Porady dotyczące PipeReader i PipeWriter
Skorzystaj z poniższych wskazówek, aby pomyślnie użyć System.IO.Pipelines klas:
- Zawsze należy ukończyć działania PipeReader i PipeWriter, w tym również obsługę wyjątków, jeśli dotyczy.
- Zawsze dzwonij PipeReader.AdvanceTo po wywołaniu metody PipeReader.ReadAsync.
-
awaitPipeWriter.FlushAsync Okresowo podczas pisania i zawsze sprawdzaj wartość FlushResult.IsCompleted. Przerwij pisanie, jeśliIsCompletedma wartośćtrue, ponieważ oznacza to, że czytelnik jest ukończony i nie dba już o to, co zostało napisane. - Po napisaniu czegoś, do czego
PipeReaderma mieć dostęp, zadzwoń na PipeWriter.FlushAsync. - Nie wywołuj
FlushAsync, jeśli czytelnik nie może rozpocząć, dopókiFlushAsyncsię nie zakończy, ponieważ może to spowodować zakleszczenie. - Upewnij się, że tylko jeden kontekst jest właścicielem elementu
PipeReaderlubPipeWriterlub uzyskuje do nich dostęp. Te typy nie są bezpieczne dla wątków. - Nigdy nie uzyskuj dostępu do ReadResult.Buffer po wywołaniu PipeReader.AdvanceTo lub ukończeniu
PipeReader.
IDuplexPipe
IDuplexPipe to umowa dla typów, które obsługują zarówno odczytywanie, jak i pisanie. Na przykład połączenie sieciowe jest reprezentowane przez element IDuplexPipe.
W przeciwieństwie do Pipe, który zawiera PipeReader i PipeWriter, IDuplexPipe reprezentuje jedną stronę pełnego dwustronnego połączenia. Zapis w obiekcie PipeWriter nie będzie odczytywany z pliku PipeReader.
Strumienie
Podczas odczytywania lub zapisywania danych strumienia zwykle używa się deserializatora do odczytu i serializatora do zapisu. Większość z tych interfejsów API do odczytu i zapisu strumieni ma parametr Stream. Aby ułatwić integrację z tymi istniejącymi interfejsami API, PipeReader i PipeWriter udostępniają metodę AsStream.
AsStream zwraca implementację Stream wokół PipeReader lub PipeWriter.
Przykład usługi Stream
Twórz instancje PipeReader i PipeWriter za pomocą statycznych metod Create, korzystając z obiektu Stream oraz opcjonalnych odpowiednich opcji tworzenia.
Zezwalać StreamPipeReaderOptions na kontrolowanie tworzenia wystąpienia PipeReader przy użyciu następujących parametrów.
-
StreamPipeReaderOptions.BufferSize to minimalny rozmiar buforu w bajtach używany podczas wynajmowania pamięci z puli, a wartość domyślna to
4096. -
StreamPipeReaderOptions.LeaveOpen flaga określa, czy podstawowy strumień jest pozostawiony otwarty po zakończeniu
PipeReader, a wartość domyślna tofalse. -
StreamPipeReaderOptions.MinimumReadSize reprezentuje próg pozostałych bajtów w buforze przed przydzieleniu nowego buforu, a wartość domyślna to
1024. to , który jest używany podczas przydzielania pamięci, a domyślną wartością jest .
Zezwalać StreamPipeWriterOptions na kontrolowanie tworzenia wystąpienia PipeWriter przy użyciu następujących parametrów.
-
StreamPipeWriterOptions.LeaveOpen flaga określa, czy podstawowy strumień jest pozostawiony otwarty po zakończeniu
PipeWriter, a wartość domyślna tofalse. -
StreamPipeWriterOptions.MinimumBufferSize reprezentuje minimalny rozmiar bufora używanego podczas wynajmowania pamięci z Pool, a domyślnie jest ustawiony na
4096. to , który jest używany podczas przydzielania pamięci, a domyślną wartością jest .
Ważne
Podczas tworzenia wystąpień PipeReader i PipeWriter za pomocą metod Create, należy uwzględnić okres istnienia obiektu Stream. Jeśli potrzebujesz dostępu do strumienia po zakończeniu działania czytnika lub zapisującego, ustaw flagę LeaveOpen na true w opcjach twórczych. W przeciwnym razie strumień jest zamknięty.
Ten kod demonstruje tworzenie wystąpień PipeReader oraz PipeWriter przy użyciu metod Create ze strumienia.
using System.Buffers;
using System.IO.Pipelines;
using System.Text;
class Program
{
static async Task Main()
{
using var stream = File.OpenRead("lorem-ipsum.txt");
var reader = PipeReader.Create(stream);
var writer = PipeWriter.Create(
Console.OpenStandardOutput(),
new StreamPipeWriterOptions(leaveOpen: true));
WriteUserCancellationPrompt();
var processMessagesTask = ProcessMessagesAsync(reader, writer);
var userCanceled = false;
var cancelProcessingTask = Task.Run(() =>
{
while (char.ToUpperInvariant(Console.ReadKey().KeyChar) != 'C')
{
WriteUserCancellationPrompt();
}
userCanceled = true;
// No exceptions thrown
reader.CancelPendingRead();
writer.CancelPendingFlush();
});
await Task.WhenAny(cancelProcessingTask, processMessagesTask);
Console.WriteLine(
$"\n\nProcessing {(userCanceled ? "cancelled" : "completed")}.\n");
}
static void WriteUserCancellationPrompt() =>
Console.WriteLine("Press 'C' to cancel processing...\n");
static async Task ProcessMessagesAsync(
PipeReader reader,
PipeWriter writer)
{
try
{
while (true)
{
ReadResult readResult = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = readResult.Buffer;
try
{
if (readResult.IsCanceled)
{
break;
}
if (TryParseLines(ref buffer, out string message))
{
FlushResult flushResult =
await WriteMessagesAsync(writer, message);
if (flushResult.IsCanceled || flushResult.IsCompleted)
{
break;
}
}
if (readResult.IsCompleted)
{
if (!buffer.IsEmpty)
{
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
catch (Exception ex)
{
Console.Error.WriteLine(ex);
}
finally
{
await reader.CompleteAsync();
await writer.CompleteAsync();
}
}
static bool TryParseLines(
ref ReadOnlySequence<byte> buffer,
out string message)
{
SequencePosition? position;
StringBuilder outputMessage = new();
while(true)
{
position = buffer.PositionOf((byte)'\n');
if (!position.HasValue)
break;
outputMessage.Append(Encoding.ASCII.GetString(buffer.Slice(buffer.Start, position.Value)))
.AppendLine();
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
};
message = outputMessage.ToString();
return message.Length != 0;
}
static ValueTask<FlushResult> WriteMessagesAsync(
PipeWriter writer,
string message) =>
writer.WriteAsync(Encoding.ASCII.GetBytes(message));
}
Aplikacja używa StreamReader do odczytywania pliku lorem-ipsum.txt jako strumienia, przy czym plik musi kończyć się pustym wierszem. Element FileStream jest przekazywany do PipeReader.Create, który tworzy obiekt PipeReader. Następnie aplikacja konsolowa przekazuje swój standardowy strumień wyjściowy do PipeWriter.Create przy użyciu Console.OpenStandardOutput(). Przykład obsługuje anulowanie.
Współpracuj z nami w serwisie GitHub
Źródło tej zawartości można znaleźć w witrynie GitHub, gdzie można również tworzyć i przeglądać problemy i żądania ściągnięcia. Więcej informacji znajdziesz w naszym przewodniku dla współtwórców.