Omówieniemartów danych
W tym artykule opisano i wyjaśniono ważne pojęcia dotyczące magazynów danych.
Omówienie modelu semantycznego (ustawienie domyślne)
Moduły datamarts udostępniają warstwę semantyczną, która jest automatycznie generowana i synchronizowana z zawartością tabel datamart, ich struktury i danych bazowych. Ta warstwa jest udostępniana w automatycznie generowanym modelu semantycznym. Ta automatyczna generacja i synchronizacja umożliwia dalsze opisywanie domeny danych, takich jak hierarchie, przyjazne nazwy i opisy. Można również ustawić formatowanie specyficzne dla ustawień regionalnych lub wymagań biznesowych. Za pomocą funkcji datamarts można tworzyć miary i ustandaryzowane metryki na potrzeby raportowania. Usługa Power BI (i inne narzędzia klienckie) może tworzyć wizualizacje i dostarczać wyniki dla takich obliczeń na podstawie danych w kontekście.
Domyślny model semantyczny usługi Power BI utworzony na podstawie schematu danych eliminuje konieczność nawiązywania połączenia z oddzielnym modelem semantycznym, konfigurowania harmonogramów odświeżania i zarządzania wieloma elementami danych. Zamiast tego możesz utworzyć logikę biznesową w zestawie danych, a jego dane będą natychmiast dostępne w usłudze Power BI, włączając następujące elementy:
- Dostęp do danych datamart za pośrednictwem centrum modelu semantycznego.
- Możliwość analizowania w programie Excel.
- Możliwość szybkiego tworzenia raportów w usługa Power BI.
- Nie trzeba odświeżać, synchronizować danych ani rozumieć szczegółów połączenia.
- Twórz rozwiązania w Internecie bez konieczności korzystania z programu Power BI Desktop.
W wersji zapoznawczej domyślna łączność modelu semantycznego jest dostępna tylko przy użyciu trybu DirectQuery . Na poniższej ilustracji przedstawiono sposób dopasowania modułów danych do kontinuum procesu, począwszy od nawiązywania połączenia z danymi, przez tworzenie raportów.
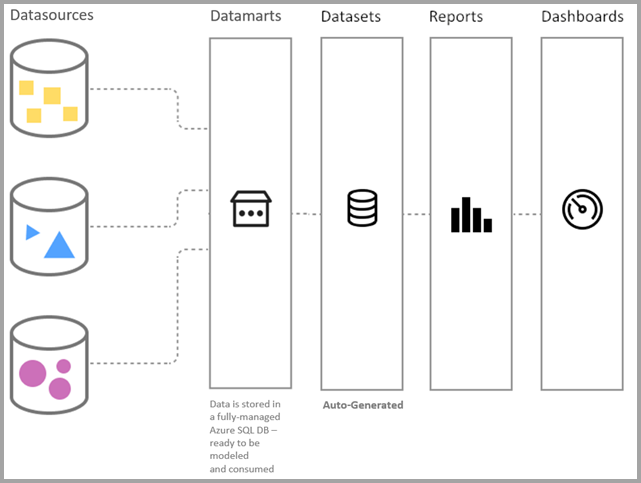
Domyślne modele semantyczne różnią się od tradycyjnych modeli semantycznych usługi Power BI w następujący sposób:
- Punkt końcowy XMLA obsługuje operacje tylko do odczytu, a użytkownicy nie mogą bezpośrednio edytować modelu semantycznego. Przy użyciu uprawnienia tylko do odczytu XMLA można wykonywać zapytania dotyczące danych w oknie zapytania.
- Domyślne modele semantyczne nie mają ustawień źródła danych, a użytkownicy nie muszą wprowadzać poświadczeń. Zamiast tego używają automatycznego logowania jednokrotnego (SSO) w przypadku zapytań.
- W przypadku operacji odświeżania semantyczne modele używają poświadczeń autora modelu semantycznego w celu nawiązania połączenia z punktem końcowym SQL zarządzanego obiektu datamart.
Użytkownicy programu Power BI Desktop mogą tworzyć modele złożone, umożliwiając nawiązywanie połączenia z semantycznym modelem schematu danych i wykonywanie następujących czynności:
- Wybierz określone tabele do przeanalizowania.
- Dodaj więcej źródeł danych.
Jeśli na koniec nie chcesz bezpośrednio używać domyślnego modelu semantycznego, możesz nawiązać połączenie z punktem końcowym SQL elementu datamart. Aby uzyskać więcej informacji, zobacz Tworzenie raportów przy użyciu funkcji datamarts.
Informacje o tym, co znajduje się w domyślnym modelu semantycznym
Obecnie tabele w zestawie datamart są automatycznie dodawane do domyślnego modelu semantycznego. Użytkownicy mogą również ręcznie wybierać tabele lub widoki na podstawie schematu danych, które mają zostać uwzględnione w modelu, aby uzyskać większą elastyczność. Obiekty znajdujące się w domyślnym modelu semantycznym zostaną utworzone jako układ w widoku modelu.
Synchronizacja w tle obejmująca obiekty (tabele i widoki) będzie czekać, aż model semantyczny podrzędny nie będzie używany do aktualizowania modelu semantycznego, honorując powiązaną nieaktualność. Użytkownicy zawsze mogą ręcznie wybierać tabele, których chcą lub nie chcą w modelu semantycznym.
Omówienie odświeżania przyrostowego i magazynów danych
Możesz tworzyć i modyfikować odświeżanie danych przyrostowych, podobnie jak przepływy danych i odświeżanie przyrostowe modelu semantycznego, przy użyciu edytora datamart. Odświeżanie przyrostowe rozszerza zaplanowane operacje odświeżania, zapewniając automatyczne tworzenie partycji i zarządzanie tabelami datamart, które często ładują nowe i zaktualizowane dane.
W przypadku większości magazynów danych odświeżanie przyrostowe będzie obejmować co najmniej jedną tabelę zawierającą dane transakcji, które często zmieniają się i mogą rosnąć wykładniczo, takie jak tabela faktów w schemacie relacyjnej lub star database. Jeśli używasz zasad odświeżania przyrostowego do partycjonowania tabeli i odświeżasz tylko najnowsze partycje importu, możesz znacznie zmniejszyć ilość danych, które należy odświeżyć.
Odświeżanie przyrostowe i dane w czasie rzeczywistym dla magazynów danych oferują następujące korzyści:
- Mniejsza liczba cykli odświeżania dla szybko zmieniających się danych
- Odświeżanie jest szybsze
- Odświeżanie jest bardziej niezawodne
- Zużycie zasobów zostało zmniejszone
- Umożliwia tworzenie dużych magazynów danych
- Łatwe konfigurowanie
Omówienie aktywnego buforowania
Aktywne buforowanie umożliwia automatyczne importowanie danych bazowych dla domyślnego modelu semantycznego, dzięki czemu nie trzeba zarządzać trybem przechowywania ani organizować go. Tryb importu dla domyślnego modelu semantycznego zapewnia przyspieszenie wydajności dla semantycznego modelu datamart przy użyciu szybkiego aparatu Vertipaq. W przypadku korzystania z proaktywnego buforowania usługa Power BI zmienia tryb przechowywania modelu do zaimportowania, który korzysta z aparatu w pamięci w usługach Power BI i Analysis Services.
Aktywne buforowanie działa w następujący sposób: po każdym odświeżeniu tryb przechowywania domyślnego modelu semantycznego zostanie zmieniony na Tryb DirectQuery. Proaktywne buforowanie tworzy model importu równoległego asynchronicznie i jest zarządzany przez element datamart i nie wpływa na dostępność ani wydajność elementu datamart. Zapytania przychodzące po zakończeniu domyślnego modelu semantycznego będą używać modelu importu.
Automatyczne generowanie modelu importu odbywa się w ciągu około 10 minut po wykryciu żadnych zmian w elemecie datamart. Semantyczny model importu zmienia się na następujące sposoby:
- Odświeżenia
- Nowe źródła danych
- Zmiany schematu:
- Nowe źródła danych
- Aktualizacje do kroków przygotowywania danych w usłudze Power Query Online
- Wszelkie aktualizacje modelowania, takie jak:
- Miary
- Hierarchie
- Opisy
Najlepsze rozwiązania dotyczące aktywnego buforowania
Użyj potoków wdrażania, aby wprowadzić zmiany, aby zapewnić najlepszą wydajność i zapewnić użytkownikom korzystanie z modelu importu. Korzystanie z potoków wdrażania jest już najlepszym rozwiązaniem w zakresie tworzenia magazynów danych, ale zapewnia to częściej korzystanie z proaktywnego buforowania.
Zagadnienia i ograniczenia dotyczące aktywnego buforowania
- Usługa Power BI obecnie ograniczy czas trwania operacji buforowania do 10 minut.
- Ograniczenia unikatowości/wartości innej niż null dla określonych kolumn zostaną wymuszone w modelu importu i nie powiedzie się kompilacji pamięci podręcznej, jeśli dane nie są zgodne.
Powiązana zawartość
Ten artykuł zawiera omówienie ważnych pojęć dotyczących schematu danych, które można zrozumieć.
Następujące artykuły zawierają więcej informacji na temat magazynów danych i usługi Power BI:
- Wprowadzenie do magazynów danych
- Wprowadzenie do funkcji datamarts
- Analizowaniemartów danych
- Tworzenie raportów przy użyciu funkcji datamarts
- Kontrola dostępu do magazynów danych
- Administracja istration datamarts
Aby uzyskać więcej informacji na temat przepływów danych i przekształcania danych, zobacz następujące artykuły:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla