Falha desencadeia depuração de trabalho com o Kit de Ferramentas do Azure para IntelliJ (visualização)
Este artigo fornece orientação passo a passo sobre como usar as Ferramentas HDInsight no Kit de Ferramentas do Azure para IntelliJ para executar aplicativos de depuração de falha do Spark.
Pré-requisitos
Kit de desenvolvimento Oracle Java. Este tutorial usa Java versão 8.0.202.
IntelliJ IDEA. Este artigo usa o IntelliJ IDEA Community 2019.1.3.
Kit de Ferramentas do Azure para IntelliJ. Consulte Instalando o Kit de Ferramentas do Azure para IntelliJ.
Conecte-se ao cluster HDInsight. Consulte Conectar-se ao cluster HDInsight.
Explorador de Armazenamento do Microsoft Azure. Consulte Baixar o Gerenciador de Armazenamento do Microsoft Azure.
Criar um projeto com modelo de depuração
Crie um projeto spark2.3.2 para continuar a depuração de falha, execute o arquivo de exemplo de depuração de tarefa de falha neste documento.
Abra o IntelliJ IDEA. Abra a janela Novo projeto .
a. Selecione Azure Spark/HDInsight no painel esquerdo.
b. Selecione Spark Project with Failure Task Debugging Sample(Preview)(Scala) na janela principal.
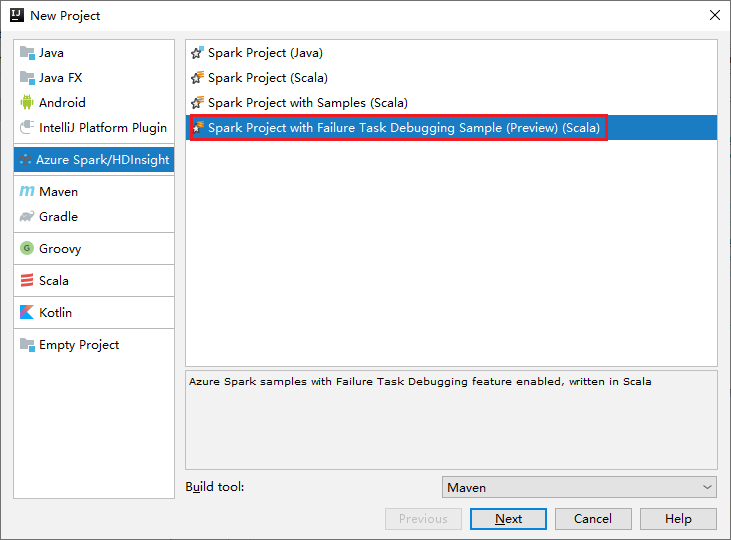
c. Selecione Seguinte.
Na janela Novo projeto, execute as seguintes etapas:
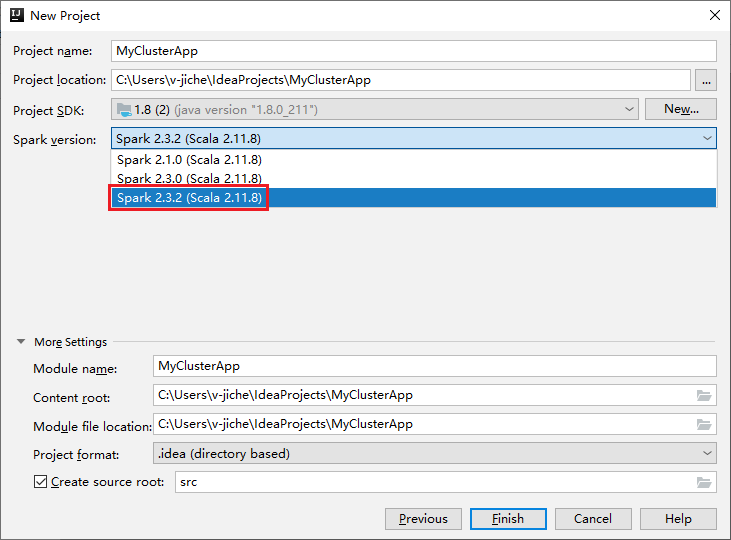
a. Insira um nome e um local do projeto.
b. Na lista suspensa SDK do projeto, selecione Java 1.8 para cluster do Spark 2.3.2.
c. Na lista suspensa Versão do Spark , selecione Spark 2.3.2(Scala 2.11.8).
d. Selecione Concluir.
Selecione src>main>scala para abrir seu código no projeto. Este exemplo usa o script AgeMean_Div( ).
Executar um aplicativo Spark Scala/Java em um cluster HDInsight
Crie um aplicativo Scala/Java do Spark e execute o aplicativo em um cluster do Spark executando as seguintes etapas:
Clique em Adicionar configuração para abrir a janela Executar/Depurar configurações.

Na caixa de diálogo Executar/Depurar Configurações, selecione o sinal de adição (+). Em seguida, selecione a opção Apache Spark no HDInsight .
Alterne para a guia Executar remotamente no cluster . Insira informações para Nome, Cluster Spark e Nome da classe Principal. Nossas ferramentas suportam depuração com Executores. Os numExectors, o valor padrão é 5, e é melhor não definir acima de 3. Para reduzir o tempo de execução, você pode adicionar spark.yarn.maxAppAttempts em Configurações de trabalho e definir o valor como 1. Clique no botão OK para salvar a configuração.
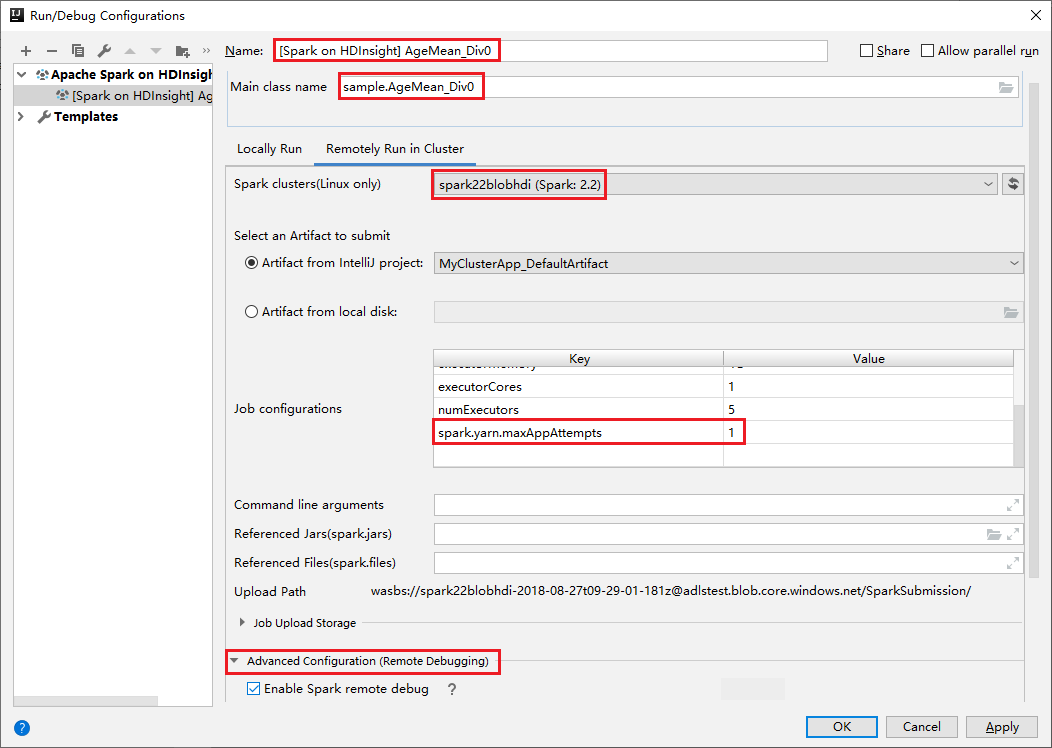
A configuração agora é salva com o nome que você forneceu. Para visualizar os detalhes da configuração, selecione o nome da configuração. Para fazer alterações, selecione Editar configurações.
Depois de concluir as configurações configurações, você pode executar o projeto no cluster remoto.

Você pode verificar o ID do aplicativo na janela de saída.

Baixar perfil de trabalho com falha
Se o envio do trabalho falhar, você poderá baixar o perfil do trabalho com falha para a máquina local para depuração adicional.
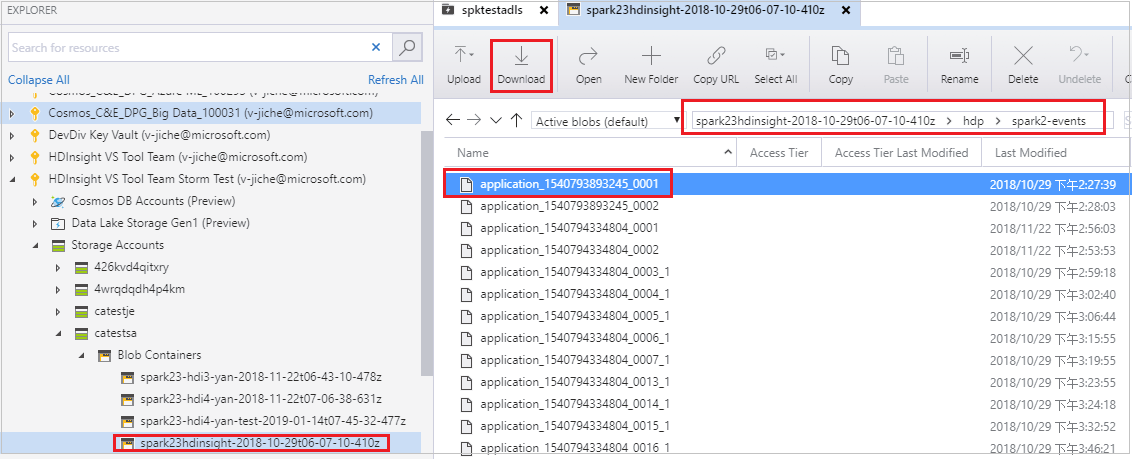
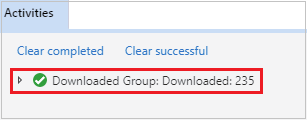
Abra o Gerenciador de Armazenamento do Microsoft Azure, localize a conta HDInsight do cluster para o trabalho com falha, baixe os recursos do trabalho com falha do local correspondente: \hdp\spark2-events\.spark-failures\<application ID> para uma pasta local. A janela de atividades mostrará o progresso do download.
Configurar o ambiente de depuração local e depurar em caso de falha
Abra o projeto original ou crie um novo projeto e associe-o ao código-fonte original. Atualmente, apenas a versão spark2.3.2 é suportada para depuração de falhas.
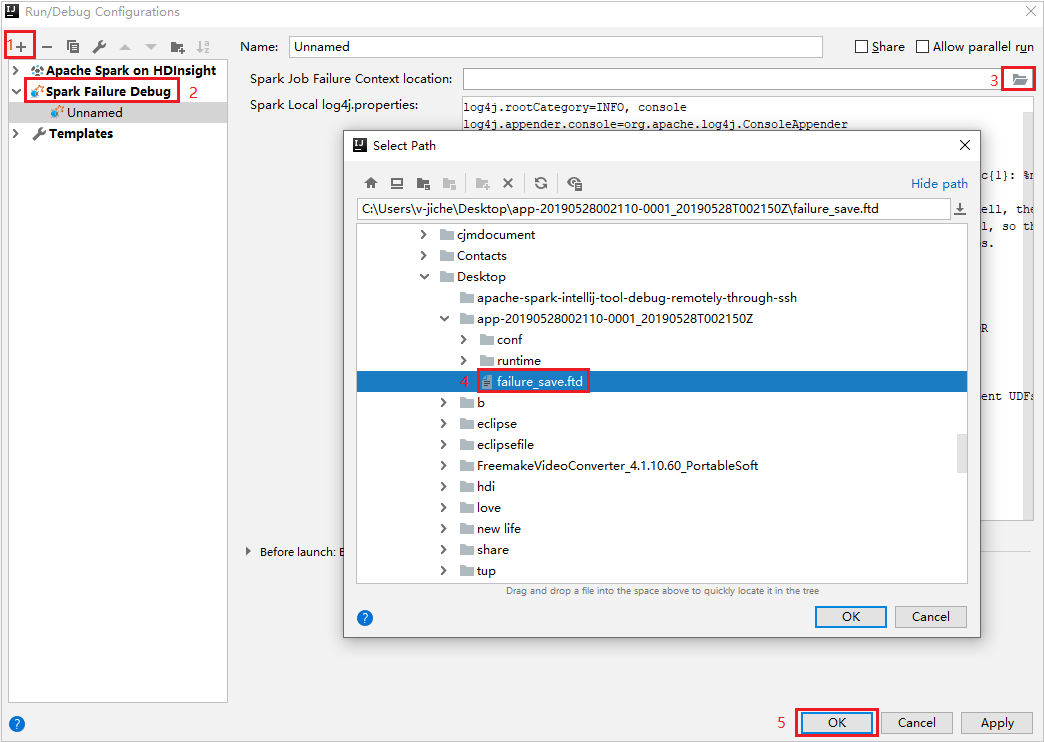
No IntelliJ IDEA, crie um arquivo de configuração de depuração de falha do Spark, selecione o arquivo FTD dos recursos de trabalho com falha baixados anteriormente para o campo Local do contexto de falha do trabalho do Spark.
Clique no botão de execução local na barra de ferramentas, o erro será exibido na janela Executar.
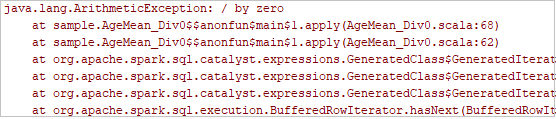
Defina o ponto de interrupção como o log indica e, em seguida, clique no botão de depuração local para fazer a depuração local exatamente como seus projetos Scala / Java normais no IntelliJ.
Após a depuração, se o projeto for concluído com êxito, você poderá reenviar o trabalho com falha para sua faísca no cluster HDInsight.
Próximos passos
Cenários
- Apache Spark com BI: faça análise de dados interativa usando o Spark no HDInsight com ferramentas de BI
- Apache Spark com Machine Learning: use o Spark no HDInsight para analisar a temperatura do edifício usando dados de HVAC
- Apache Spark com Machine Learning: use o Spark no HDInsight para prever resultados de inspeção de alimentos
- Análise de log do site usando o Apache Spark no HDInsight
Criar e executar aplicações
- Criar uma aplicação autónoma com o Scala
- Executar trabalhos remotamente em um cluster Apache Spark usando o Apache Livy
Ferramentas e extensões
- Usar o Kit de Ferramentas do Azure para IntelliJ para criar aplicativos Apache Spark para um cluster HDInsight
- Use o Kit de Ferramentas do Azure para IntelliJ para depurar aplicativos Apache Spark remotamente por meio de VPN
- Usar as Ferramentas do HDInsight no Kit de Ferramentas do Azure para Eclipse para criar aplicativos Apache Spark
- Usar blocos de anotações Apache Zeppelin com um cluster Apache Spark no HDInsight
- Kernels disponíveis para o Jupyter Notebook no cluster Apache Spark para HDInsight
- Use pacotes externos com o Jupyter Notebooks
- Instalar o Jupyter no computador e ligar a um cluster do Spark do HDInsight