Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo explica como atualizar um índice existente no Azure AI Search com alterações de esquema ou alterações de conteúdo por meio de indexação incremental. Ele explica as circunstâncias em que as reconstruções são necessárias e fornece recomendações para mitigar os efeitos das reconstruções em solicitações de consulta em andamento.
Durante o desenvolvimento ativo, é comum descartar e reconstruir índices quando você está iterando sobre o design do índice. A maioria dos desenvolvedores trabalha com uma pequena amostra representativa de seus dados para que a reindexação seja mais rápida.
Para alterações de esquema em aplicativos já em produção, recomendamos criar e testar um novo índice que execute lado a lado um índice existente. Utilize um alias de índice para alternar para o novo índice, evitando assim alterações no código da aplicação.
Atualizar conteúdo
A indexação incremental e a sincronização de um índice em relação a alterações nos dados de origem são fundamentais para a maioria dos aplicativos de pesquisa. Esta seção explica o fluxo de trabalho para adicionar, remover ou substituir o conteúdo de um índice de pesquisa por meio da API REST, mas os SDKs do Azure fornecem funcionalidade equivalente.
O corpo do pedido contém um ou mais documentos a indexar. No âmbito do pedido, cada documento no índice é:
- Identificado por uma chave exclusiva que diferencia maiúsculas de minúsculas.
- Associado a uma ação: "upload", "delete", "merge" ou "mergeOrUpload".
- Preenchido com um conjunto de pares nome/valor para cada campo que você está adicionando ou atualizando.
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (name/value pairs matching index schema)
...
},
...
]
}
Primeiro, use as APIs para carregar documentos, como Documents - Index (REST) ou uma API equivalente nos SDKs do Azure. Para obter mais informações sobre técnicas de indexação, consulte Carregar documentos.
Para uma atualização grande, o envio em lote (até 1.000 documentos por lote, ou cerca de 16 MB por lote, o que ocorrer primeiro) é recomendado e melhora significativamente o desempenho da indexação.
Defina o
@search.actionparâmetro na API para determinar o efeito em documentos existentes.Ação Efeito eliminar Remove todo o documento do índice. Se você quiser remover um campo individual, use mesclar em vez disso, definindo o campo em questão como nulo. Documentos e campos excluídos não liberam espaço imediatamente no índice. A cada poucos minutos, um processo em segundo plano executa a exclusão física. Quer utilize o portal do Azure ou uma API para devolver estatísticas de índice, pode esperar um pequeno atraso antes de a eliminação ser refletida no portal do Azure e através de APIs. intercalação Atualiza um documento que já existe e falha em um documento que não pode ser encontrado. A mesclagem substitui os valores existentes. Por esse motivo, certifique-se de verificar se há campos de coleta que contenham vários valores, como campos do tipo Collection(Edm.String). Por exemplo, se umtagscampo começar com um valor de["budget"]e você executar uma mesclagem com["economy", "pool"], o valor final dotagscampo será["economy", "pool"]. Não será["budget", "economy", "pool"].
O mesmo comportamento se aplica a coleções complexas. Se o documento contiver um campo de coleção complexo chamado Salas com um valor de[{ "Type": "Budget Room", "BaseRate": 75.0 }], e você executar uma mesclagem com um valor de[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }], o valor final do campo Salas será[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }]. Ele não acrescentará ou mesclará valores novos e existentes.mesclarOuCarregar Comporta-se como mesclar se o documento existir e carregar se o documento for novo. Esta é a ação mais comum para atualizações incrementais. carregamento Semelhante a um "upsert", em que o documento é inserido, caso seja novo, e atualizado ou substituído, se já existir. Se o documento estiver faltando valores que o índice exige, o valor do campo do documento é definido como null.
As consultas continuam a ser executadas durante a indexação, mas se você estiver atualizando ou removendo campos existentes, poderá esperar resultados mistos e uma maior incidência de limitação.
Nota
Não há garantias de ordenação quanto a qual ação no corpo da solicitação é executada primeiro. Não é recomendável ter várias ações de "mesclagem" associadas ao mesmo documento em um único corpo de solicitação. Se houver várias ações de "mesclagem" necessárias para o mesmo documento, execute a mesclagem do lado do cliente antes de atualizar o documento no índice de pesquisa.
Respostas
O código de status 200 é retornado para uma resposta bem-sucedida, o que significa que todos os itens foram armazenados de forma durável e começarão a ser indexados. A indexação é executada em segundo plano e torna novos documentos disponíveis (ou seja, consultáveis e pesquisáveis) alguns segundos após a conclusão da operação de indexação. O atraso específico depende da carga no serviço.
A indexação bem-sucedida é indicada pela propriedade status sendo definida como true para todos os itens, bem como a statusCode propriedade sendo definida como 201 (para documentos recém-carregados) ou 200 (para documentos mesclados ou excluídos):
{
"value": [
{
"key": "unique_key_of_new_document",
"status": true,
"errorMessage": null,
"statusCode": 201
},
{
"key": "unique_key_of_merged_document",
"status": true,
"errorMessage": null,
"statusCode": 200
},
{
"key": "unique_key_of_deleted_document",
"status": true,
"errorMessage": null,
"statusCode": 200
}
]
}
O código de status 207 é retornado quando pelo menos um item não foi indexado com êxito. Os itens que não foram indexados têm o campo de status definido como false. As errorMessage propriedades e statusCode indicam o motivo do erro de indexação:
{
"value": [
{
"key": "unique_key_of_document_1",
"status": false,
"errorMessage": "The search service is too busy to process this document. Please try again later.",
"statusCode": 503
},
{
"key": "unique_key_of_document_2",
"status": false,
"errorMessage": "Document not found.",
"statusCode": 404
},
{
"key": "unique_key_of_document_3",
"status": false,
"errorMessage": "Index is temporarily unavailable because it was updated with the 'allowIndexDowntime' flag set to 'true'. Please try again later.",
"statusCode": 422
}
]
}
A errorMessage propriedade indica o motivo do erro de indexação, se possível.
A tabela a seguir explica os vários códigos de status por documento que podem ser retornados na resposta. Alguns códigos de status indicam problemas com a própria solicitação, enquanto outros indicam condições de erro temporárias. Este último você deve tentar novamente após um atraso.
| Código de estado | Significado | Repetível | Notas |
|---|---|---|---|
| 200 | O documento foi modificado ou eliminado com êxito. | n/d | As operações de eliminação são idempotentes. Ou seja, mesmo que uma chave de documento não exista no índice, tentar uma operação de exclusão com essa chave resulta em um código de status 200. |
| 201 | O documento foi criado com sucesso. | n/d | |
| 400 | Ocorreu um erro no documento que o impediu de ser indexado. | Não | A mensagem de erro na resposta indica o que está errado com o documento. |
| 404 | O documento não pôde ser mesclado porque a chave fornecida não existe no índice. | Não | Este erro não ocorre para carregamentos, uma vez que criam novos documentos, e não ocorre para eliminações porque são idempotentes. |
| 409 | Foi detetado um conflito de versão ao tentar indexar um documento. | Sim | Tal pode acontecer quando tenta indexar o mesmo documento mais do que uma vez em simultâneo. |
| 422 | O índice está temporariamente indisponível pois foi atualizado com o sinalizador “allowIndexDowntime” definido como “verdadeiro”. | Sim | |
| 429 | Demasiados pedidos | Sim | Se você receber esse código de erro durante a indexação, isso geralmente significa que você está com pouco armazenamento. À medida que você se aproxima dos limites de armazenamento, o serviço pode entrar em um estado em que você não pode adicionar ou atualizar até excluir alguns documentos. Para obter mais informações, consulte Planejar e gerenciar a capacidade se quiser mais armazenamento ou liberar espaço excluindo documentos. |
| 503 | O seu serviço de pesquisa está temporariamente indisponível, possivelmente devido a carga pesada. | Sim | Neste caso, o seu código deve aguardar antes de tentar de novo ou arrisca prolongar a indisponibilidade do serviço. |
Se o código do cliente encontrar frequentemente uma resposta 207, uma possível razão é que o sistema está sob carga. Você pode confirmar isso verificando se a propriedade statusCode é igual a 503. Se o statusCode for 503, recomendamos limitar as solicitações de indexação. Caso contrário, se o tráfego de indexação não diminuir, o sistema poderá começar a rejeitar todas as solicitações com erros 503.
O código de status 429 indica que você excedeu sua cota no número de documentos por índice. Você deve atualizar para limites de capacidade mais altos ou criar um novo índice.
Nota
Quando você carrega DateTimeOffset valores com informações de fuso horário em seu índice, o Azure AI Search normaliza esses valores para UTC. Por exemplo, 2024-01-13T14:03:00-08:00 é armazenado como 2024-01-13T22:03:00Z. Se você precisar armazenar informações de fuso horário, adicione uma coluna extra ao seu índice para esse ponto de dados.
Dicas para indexação incremental
Os indexadores automatizam a indexação incremental. Se você puder usar um indexador e se a fonte de dados oferecer suporte ao controle de alterações, poderá executá-lo em uma agenda recorrente para adicionar, atualizar ou substituir conteúdo pesquisável para que ele seja sincronizado com seus dados externos.
Se você estiver fazendo chamadas de índice diretamente por meio da API push, use
mergeOrUploadcomo ação de pesquisa.A carga deve incluir as chaves ou identificadores de cada documento que você deseja adicionar, atualizar ou excluir.
Se o índice incluir campos vetoriais e você definir a
storedpropriedade como false, certifique-se de fornecer o vetor na atualização parcial do documento, mesmo que o valor não seja alterado. Um efeito colateral da configuraçãostoredcomo false é que os vetores são descartados em uma operação de reindexação. Fornecer o vetor na carga útil dos documentos impede que isso aconteça.Para atualizar o conteúdo de campos e subcampos simples em tipos complexos, liste apenas os campos que deseja alterar. Por exemplo, se você só precisa atualizar um campo de descrição, a carga útil deve consistir na chave do documento e na descrição modificada. Omitir outros campos mantém seus valores existentes.
Para mesclar alterações embutidas na coleção de cadeias de caracteres, forneça o valor inteiro. Lembre-se do
tagsexemplo de campo da seção anterior. Novos valores substituem os valores antigos de um campo inteiro e não há mesclagem no conteúdo de um campo.
Aqui está um exemplo de API REST demonstrando estas dicas:
### Get Stay-Kay City Hotel by ID
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
### Change the description, city, and tags for Stay-Kay City Hotel
POST {{baseUrl}}/indexes/hotels-vector-quickstart/docs/search.index?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"value": [
{
"@search.action": "mergeOrUpload",
"HotelId": "1",
"Description": "I'm overwriting the description for Stay-Kay City Hotel.",
"Tags": ["my old item", "my new item"],
"Address": {
"City": "Gotham City"
}
}
]
}
### Retrieve the same document, confirm the overwrites and retention of all other values
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Atualizar um esquema de índice
O esquema de índice define as estruturas de dados físicas criadas no serviço de pesquisa, portanto, não há muitas alterações de esquema que você pode fazer sem incorrer em uma reconstrução completa.
Atualizações sem reconstrução
A lista a seguir enumera as alterações de esquema que podem ser introduzidas perfeitamente em um índice existente. Geralmente, a lista inclui novos campos e funcionalidades usadas durante a execução da consulta.
- Adicionar uma descrição do índice (visualização)
- Adicionar um campo novo
- Definir o
retrievableatributo em um campo existente - Atualizar
searchAnalyzernum campo que já tenha umindexAnalyzer - Adicionar uma nova definição de analisador em um índice (que pode ser aplicado a novos campos)
- Adicionar, atualizar ou excluir perfis de pontuação
- Adicionar, atualizar ou excluir synonymMaps
- Adicionar, atualizar ou excluir configurações semânticas
- Adicionar, atualizar ou excluir configurações de CORS
A ordem de operações é:
Revise o esquema com atualizações da lista anterior.
Atualizar esquema de índice no serviço de pesquisa.
Atualize o conteúdo do índice para corresponder ao esquema revisado se você adicionou um novo campo. Para todas as outras alterações, o conteúdo indexado existente é usado no estado em que se encontra.
Quando você atualiza um esquema de índice para incluir um novo campo, os documentos existentes no índice recebem um valor nulo para esse campo. No próximo trabalho de indexação, os valores dos dados de origem externa substituem os nulos adicionados pelo Azure AI Search.
Não deve haver interrupções de consulta durante as atualizações, mas os resultados da consulta variam à medida que as atualizações entram em vigor.
Atualizações que exigem uma reconstrução
Algumas modificações exigem a eliminação do índice e a sua reconstrução, substituindo o índice atual por um novo.
| Ação | Descrição |
|---|---|
| Eliminar um campo | Para remover fisicamente todos os vestígios de um campo, é necessário reconstruir o índice. Quando uma reconstrução imediata não é prática, você pode modificar o código do aplicativo para redirecionar o acesso para longe de um campo obsoleto ou usar searchFields e selecionar parâmetros de consulta para escolher quais campos serão pesquisados e retornados. Fisicamente, a definição e o conteúdo do campo permanecem no índice até a próxima reconstrução, quando você aplica um esquema que omite o campo em questão. |
| Alterar uma definição de campo | As revisões de um nome de campo, tipo de dados ou atributos de índice específicos (pesquisável, filtrável, classificável, facetable) exigem uma reconstrução completa. |
| Atribuir um analisador a um campo | Os analisadores são definidos em um índice, atribuídos a campos e, em seguida, invocados durante a indexação para informar como os tokens são criados. Você pode adicionar uma nova definição de analisador a um índice a qualquer momento, mas só pode atribuir um analisador quando o campo for criado. Isso é verdadeiro para as propriedades do analisador e do indexAnalyzer . A propriedade searchAnalyzer é uma exceção (você pode atribuir essa propriedade a um campo existente). |
| Atualizar ou excluir uma definição de analisador em um índice | Não é possível excluir ou alterar uma configuração existente do analisador (analisador, tokenizador, filtro de token ou filtro char) no índice, a menos que você reconstrua todo o índice. |
| Adicionar um campo a um sugeridor | Se um campo já existir e você quiser adicioná-lo a uma construção Sugestões , reconstrua o índice. |
| Atualize seu serviço ou camada | Se precisar de mais capacidade, verifique se pode atualizar o seu serviço ou mudar para um escalão de preços mais elevado. Caso contrário, você deve criar um novo serviço e reconstruir seus índices do zero. Para ajudar a automatizar esse processo, você pode usar um exemplo de código que faz backup do índice para uma série de arquivos JSON. Em seguida, você pode recriar o índice em um serviço de pesquisa especificado. |
A ordem de operações é:
Obtenha uma definição de índice caso precise dela para referência futura ou para usá-la como base para uma nova versão.
Considere o uso de uma solução de backup e restauração para preservar uma cópia do conteúdo do índice. Existem soluções em C# e em Python. Recomendamos a versão Python porque é mais atualizada.
Se você tiver capacidade em seu serviço de pesquisa, mantenha o índice existente enquanto cria e testa o novo.
Elimine o índice existente. As consultas direcionadas ao índice são imediatamente descartadas. Lembre-se de que excluir um índice é irreversível, destruindo o armazenamento físico para a coleção de campos e outras construções.
Postar um índice revisado, onde o corpo da solicitação inclui definições e configurações de campo alteradas ou modificadas.
Carregue o índice com documentos de uma fonte externa. Os documentos são indexados usando as definições e configurações de campo do novo esquema.
Quando você cria o índice, o armazenamento físico é alocado para cada campo no esquema de índice, com um índice invertido criado para cada campo pesquisável e um índice vetorial criado para cada campo vetorial. Os campos que não são pesquisáveis podem ser usados em filtros ou expressões, mas não têm índices invertidos e não são pesquisáveis como texto completo ou através de pesquisa difusa. Em uma reconstrução de índice, esses índices invertidos e índices vetoriais são excluídos e recriados com base no esquema de índice fornecido.
Para minimizar a interrupção no código do aplicativo, considere a criação de um alias de índice. O código do aplicativo faz referência ao alias, mas você pode atualizar o nome do índice para o qual o alias aponta.
Adicionar uma descrição para o índice (pré-visualização)
A partir da versão 2025-05-01-preview da REST API, um ddescription é agora suportado. Este texto legível por humanos é inestimável quando um sistema tem de aceder a vários índices e tomar uma decisão com base na descrição. Considere um servidor MCP (Model Context Protocol) que deve escolher o índice correto em tempo de execução. A decisão pode basear-se na descrição e não apenas no nome do índice.
Uma descrição de índice é uma atualização de esquema e você pode adicioná-la sem ter que reconstruir todo o índice.
- O comprimento da cadeia de caracteres é de no máximo 4.000 caracteres.
- O conteúdo deve ser legível por humanos, em Unicode. Seu caso de uso deve determinar qual idioma usar.
O suporte para uma descrição de índice é fornecido na API REST de visualização, no portal do Azure ou em um pacote SDK do Azure de pré-lançamento que fornece o recurso.
O portal do Azure dá suporte à API de visualização mais recente.
Entre no portal do Azure e encontre seu serviço de pesquisa.
Em Gerenciamento de pesquisa>Índices, selecione um índice.
Selecione Editar JSON.
Inserir
"description", seguido da descrição. O valor deve ser inferior a 4.000 caracteres e em Unicode.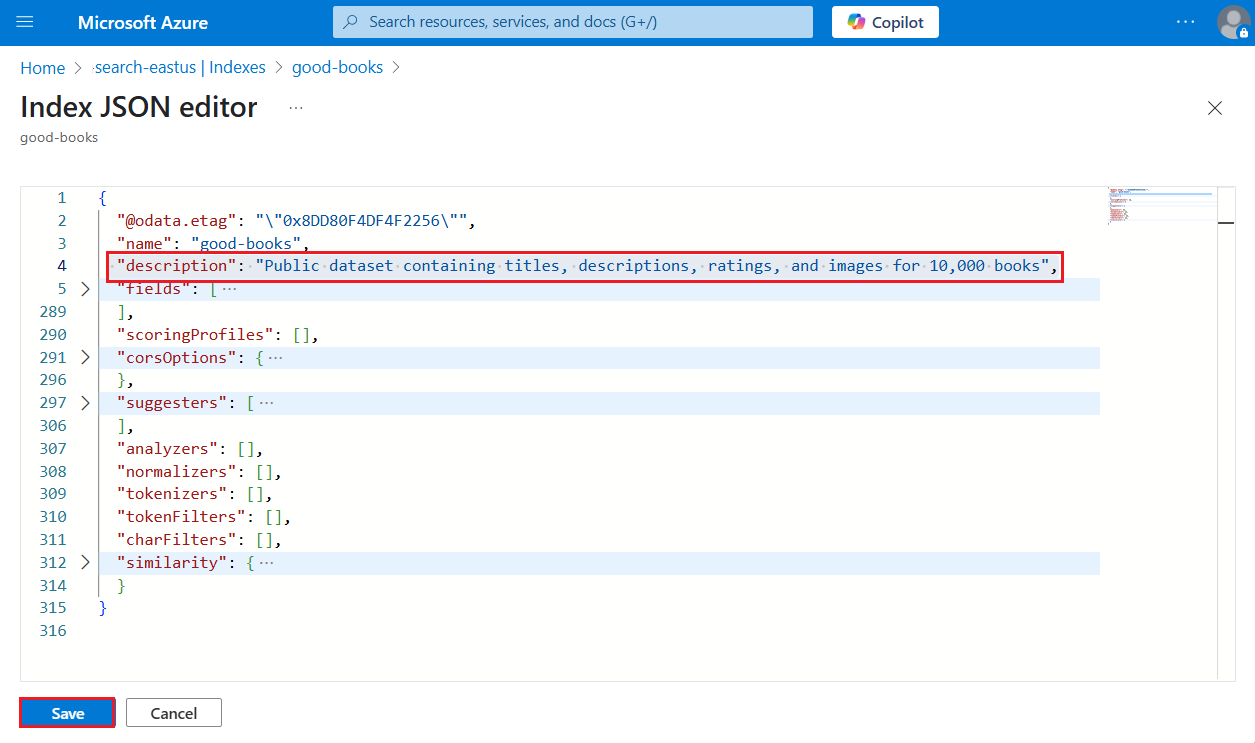
Salve o índice.
Equilibrando cargas de trabalho
A indexação não é executada em segundo plano, mas o serviço de pesquisa equilibrará quaisquer trabalhos de indexação em relação a consultas contínuas. Durante a indexação, você pode monitorar solicitações de consulta no portal do Azure para garantir que as consultas sejam concluídas em tempo hábil.
Se as cargas de trabalho de indexação introduzirem níveis inaceitáveis de latência de consulta, realize análises de desempenho e analise essas dicas de desempenho para obter uma possível atenuação.
Verificar se há atualizações
Você pode começar a consultar um índice assim que o primeiro documento for carregado. Se você souber a ID de um documento, a API REST do documento de pesquisa retornará o documento específico. Para testes mais amplos, você deve esperar até que o índice seja totalmente carregado e, em seguida, usar consultas para verificar o contexto que você espera ver.
Você pode usar o Search Explorer ou um cliente REST para verificar se há conteúdo atualizado.
Se você adicionou ou renomeou um campo, use select para retornar esse campo:
"search": "*",
"select": "document-id, my-new-field, some-old-field",
"count": true
O portal do Azure fornece o tamanho do índice e o tamanho do índice vetorial. Você pode verificar esses valores depois de atualizar um índice, mas lembre-se de esperar um pequeno atraso à medida que o serviço processa a alteração e contabilizar as taxas de atualização do portal, que podem ser de alguns minutos.
Eliminar documentos órfãos
O Azure AI Search dá suporte a operações no nível do documento para que você possa pesquisar, atualizar e excluir um documento específico isoladamente. O exemplo a seguir mostra como excluir um documento.
A exclusão de um documento não libera espaço imediatamente no índice. A cada poucos minutos, um processo em segundo plano executa a exclusão física. Quer utilize o portal do Azure ou uma API para devolver estatísticas de índice, pode esperar um pequeno atraso antes de a eliminação ser refletida no portal do Azure e nas métricas da API.
Identifique qual campo é a chave do documento. No portal do Azure, você pode exibir os campos de cada índice. As chaves de documento são campos de cadeia de caracteres e são indicadas com um ícone de chave para facilitar a sua localização.
Verifique os valores do campo chave do documento:
search=*&$select=HotelId. Uma cadeia de caracteres simples é simples, mas se o índice usa um campo codificado em base 64 ou se os documentos de pesquisa foram gerados a partir de umaparsingModeconfiguração, você pode estar trabalhando com valores com os quais não está familiarizado.Procure o documento para verificar o valor do ID do documento e para rever o seu conteúdo antes de o eliminar. Especifique a chave ou ID do documento na solicitação. Os exemplos a seguir ilustram uma cadeia de caracteres simples para o índice de exemplo Hotels e uma cadeia de caracteres codificada em base 64 para a chave metadata_storage_path do índice cog-search-demo.
GET https://[service name].search.windows.net/indexes/hotel-sample-index/docs/1111?api-version=2024-07-01GET https://[service name].search.windows.net/indexes/cog-search-demo/docs/aHR0cHM6Ly9oZWlkaWJsb2JzdG9yYWdlMi5ibG9iLmNvcmUud2luZG93cy5uZXQvY29nLXNlYXJjaC1kZW1vL2d1dGhyaWUuanBn0?api-version=2024-07-01Exclua o documento usando uma exclusão
@search.actionpara removê-lo do índice de pesquisa.POST https://[service name].search.windows.net/indexes/hotels-sample-index/docs/index?api-version=2024-07-01 Content-Type: application/json api-key: [admin key] { "value": [ { "@search.action": "delete", "id": "1111" } ] }