Azure OpenAI в данных
Используйте эту статью, чтобы узнать о Azure OpenAI On Your Data, что упрощает подключение, прием и создание корпоративных данных для быстрого создания персонализированных копилотов (предварительная версия). Он улучшает понимание пользователей, ускоряет выполнение задач, повышает эффективность работы и помогает принимать решения.
Что такое Azure OpenAI в данных
Azure OpenAI On Your Data позволяет выполнять расширенные модели ИИ, такие как GPT-35-Turbo и GPT-4 на собственных корпоративных данных, не требуя обучения или точной настройки моделей. Вы можете общаться поверх и анализировать данные с большей точностью. Вы можете указать источники для поддержки ответов на основе последних сведений, доступных в указанных источниках данных. Доступ к Azure OpenAI On Your Data можно получить с помощью REST API с помощью пакета SDK или веб-интерфейса на портале Azure AI Foundry. Вы также можете создать веб-приложение, которое подключается к данным, чтобы включить расширенное решение чата или развернуть его непосредственно в качестве копилота в Copilot Studio (предварительная версия).
Разработка с помощью Azure OpenAI в данных
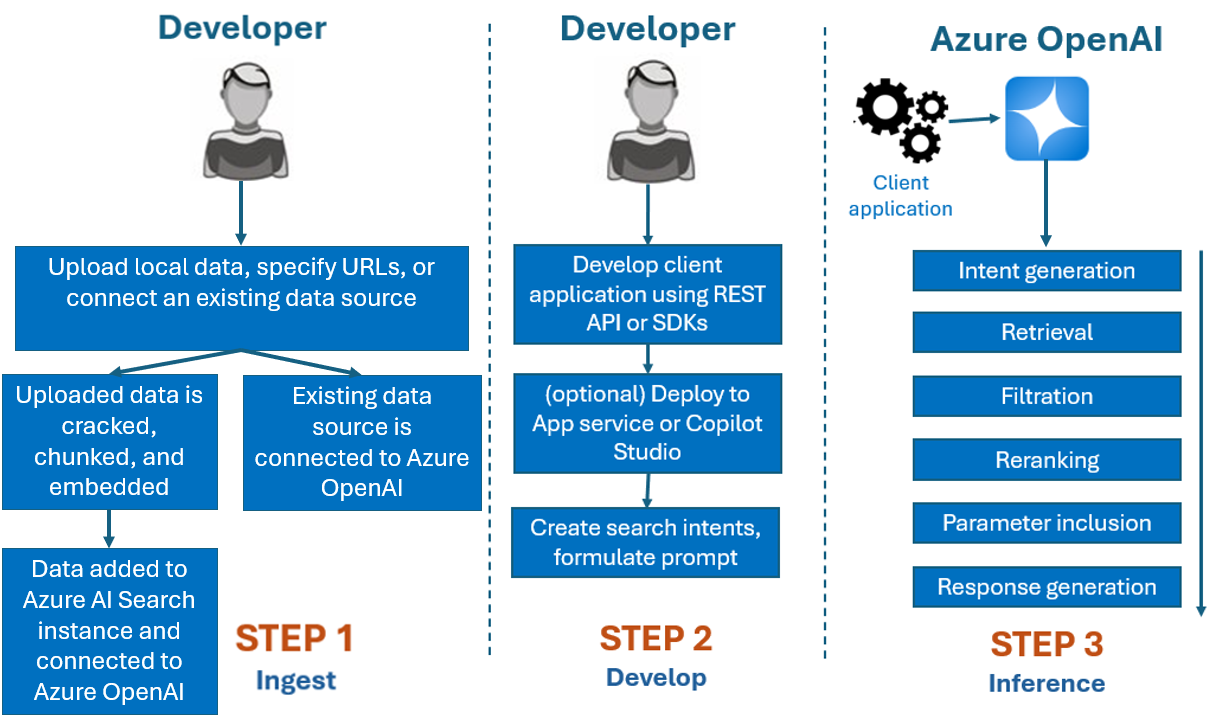
Как правило, процесс разработки, используемый с Azure OpenAI On Your Data, — это:
Прием. Отправка файлов с помощью портала Azure AI Foundry или API приема. Это позволяет взломать, фрагментировать и внедрить данные в экземпляр поиска ИИ Azure, который можно использовать моделями Azure OpenAI. Если у вас есть существующий поддерживаемый источник данных, вы также можете подключить его напрямую.
Разработка. После использования Azure OpenAI On Your Data начните разработку приложения с помощью доступных REST API и пакетов SDK, доступных на нескольких языках. Он создаст запросы и намерения поиска для передачи в службу Azure OpenAI.
Вывод. После развертывания приложения в предпочитаемой среде он отправит запросы в Azure OpenAI, которые будут выполнять несколько шагов перед возвратом ответа:
Создание намерений: служба определит намерение запроса пользователя определить правильный ответ.
Извлечение. Служба извлекает соответствующие блоки доступных данных из подключенного источника данных, запрашивая его. Например, с помощью семантического или векторного поиска. Для влияния на извлечение используются такие параметры , как строгость и количество извлеченных документов.
Фильтрация и повторная обработка. Результаты поиска на шаге извлечения улучшаются путем ранжирования и фильтрации данных для уточнения релевантности.
Создание ответов: полученные данные отправляются вместе с другими сведениями, такими как системное сообщение в большую языковую модель (LLM) и ответ отправляется в приложение.
Чтобы приступить к работе, подключите источник данных с помощью портала Azure AI Foundry и начните задавать вопросы и чаты в ваших данных.
Управление доступом на основе ролей Azure (Azure RBAC) для добавления источников данных
Чтобы использовать Azure OpenAI в данных полностью, необходимо задать одну или несколько ролей Azure RBAC. Дополнительные сведения см . в azure OpenAI в конфигурации данных.
Форматы данных и типы файлов
Azure OpenAI On Your Data поддерживает следующие типы файлов:
.txt.md.html.docx.pptx.pdf
Существует ограничение отправки, и есть некоторые предостережения о структуре документов и о том, как это может повлиять на качество ответов из модели:
Если вы преобразуете данные из неподдерживаемого формата в поддерживаемый формат, оптимизируйте качество ответа модели, гарантируя преобразование:
- Не приводит к значительной потере данных.
- Не добавляет неожиданный шум к данным.
Если в файлах имеется особое форматирование, например таблицы и столбцы или пункты маркированных списков, подготовьте данные с помощью скрипта подготовки данных, доступного на веб-сайте GitHub.
Для документов и наборов данных с длинными текстовыми строками следует использовать имеющийся скрипт подготовки данных. Этот скрипт разбивает данные на отдельные блоки, за счет чего ответы модели становятся более точными. Этот скрипт также поддерживает сканированные PDF-файлы и изображения.
Поддерживаемые источники данных
Для отправки данных необходимо подключиться к источнику данных. Если вы хотите использовать данные для чата с моделью Azure OpenAI, данные блокируются в индексе поиска, чтобы соответствующие данные можно было найти на основе запросов пользователей.
Встроенная векторная база данных в виртуальном ядере Azure Cosmos DB для MongoDB изначально поддерживает интеграцию с Azure OpenAI On Your Data.
Для некоторых источников данных, таких как отправка файлов с локального компьютера (предварительная версия) или данных, содержащихся в учетной записи хранения BLOB-объектов (предварительная версия), используется поиск ИИ Azure. При выборе следующих источников данных данные будут приема в индекс поиска ИИ Azure.
| Прием данных с помощью поиска ИИ Azure | Description |
|---|---|
| Поиск по искусственному интеллекту Azure | Используйте существующий индекс поиска ИИ Azure с помощью Azure OpenAI On your Data. |
| Отправка файлов (предварительная версия) | Отправьте файлы с локального компьютера, чтобы храниться в базе данных Хранилище BLOB-объектов Azure и входить в поиск по искусственному интеллекту Azure. |
| URL-адрес или веб-адрес (предварительная версия) | Веб-содержимое из URL-адресов хранится в Хранилище BLOB-объектов Azure. |
| Хранилище BLOB-объектов Azure (предварительная версия) | Отправьте файлы из Хранилище BLOB-объектов Azure для приема в индекс поиска ИИ Azure. |

- Поиск по искусственному интеллекту Azure
- Векторная база данных в Azure Cosmos DB для MongoDB
- Хранилище BLOB-объектов Azure (предварительная версия)
- Отправка файлов (предварительная версия)
- URL-адрес или веб-адрес (предварительная версия)
- Elasticsearch (предварительная версия)
- MongoDB Atlas (предварительная версия)
Возможно, вам потребуется использовать индекс поиска ИИ Azure, если требуется:
- Настройте процесс создания индекса.
- Повторно используйте индекс, созданный до приема данных из других источников данных.
Примечание.
- Чтобы использовать существующий индекс, он должен иметь по крайней мере одно поле для поиска.
- Задайте для параметра CORS Allow Origin Type параметр
allи параметр*"Разрешенные источники".
Типы поиска
Azure OpenAI On Your Data предоставляет следующие типы поиска, которые можно использовать при добавлении источника данных.
Векторный поиск с помощью моделей внедрения Ada, доступных в выбранных регионах
Чтобы включить векторный поиск, требуется существующая модель внедрения, развернутая в ресурсе Azure OpenAI. Выберите развертывание внедрения при подключении данных, а затем выберите один из типов векторного поиска в разделе "Управление данными". Если вы используете Поиск ИИ Azure в качестве источника данных, убедитесь, что в индексе есть векторный столбец.
Если вы используете собственный индекс, можно настроить сопоставление полей при добавлении источника данных, чтобы определить поля, которые будут сопоставлены при ответе на вопросы. Чтобы настроить сопоставление полей, выберите "Использовать сопоставление настраиваемых полей" на странице источника данных при добавлении источника данных.
Внимание
- Семантический поиск зависит от дополнительных цен. Чтобы включить семантический поиск или векторный поиск, необходимо выбрать базовый или более высокий номер SKU . Дополнительные сведения см . в разделе "Разница в ценовой категории" и ограничения служб.
- Чтобы повысить качество получения информации и ответов модели, рекомендуем включить семантический поиск для следующих исходных языков: английский, арабский, испанский, итальянский, итальянский, китайский, корейский, португальский, русский, французский и японский.
| Параметр поиска | Тип извлечения | Дополнительные цены? | Льготы |
|---|---|---|---|
| keyword | Поиск по ключевым словам | Нет дополнительных цен. | Выполняет быстрый и гибкий анализ запросов и сопоставление по полям с возможностью поиска, используя термины или фразы в любом поддерживаемом языке, с операторами или без них. |
| семантический | Семантический поиск | Дополнительные цены на использование семантического поиска . | Улучшает точность и релевантность результатов поиска с помощью рерантера (с моделями ИИ) для понимания семантического смысла терминов и документов, возвращаемых первоначальным рангером поиска. |
| vector | Векторный поиск | Дополнительные цены на учетную запись Azure OpenAI от вызова модели внедрения. | Позволяет находить документы, аналогичные данным входным данным запроса, на основе векторных внедрения содержимого. |
| hybrid (vector + keyword) | Гибридная среда поиска векторов и поиска ключевых слов | Дополнительные цены на учетную запись Azure OpenAI от вызова модели внедрения. | Выполняет поиск сходства по полям векторов с помощью векторных внедрения, а также поддерживает гибкий анализ запросов и полнотекстовый поиск по буквенно-цифровым полям с помощью запросов терминов. |
| hybrid (vector + keyword) + семантика | Гибрид векторного поиска, семантического поиска и поиска ключевых слов. | Дополнительные цены на учетную запись Azure OpenAI от вызова модели внедрения и дополнительных цен на использование семантического поиска . | Использует векторные внедрения, распознавание речи и гибкий анализ запросов для создания расширенных возможностей поиска и создания приложений искусственного интеллекта, которые могут обрабатывать сложные и разнообразные сценарии извлечения информации. |
интеллектуальный поиск.
Azure OpenAI On Your Data включает интеллектуальный поиск данных. Семантический поиск включен по умолчанию, если у вас есть как семантический поиск, так и поиск ключевых слов. При внедрении моделей интеллектуальный поиск по умолчанию использует гибридный и семантический поиск.
Управление доступом на уровне документа
Примечание.
Управление доступом на уровне документа поддерживается при выборе службы "Поиск ИИ Azure" в качестве источника данных.
Azure OpenAI On Your Data позволяет ограничить документы, которые можно использовать в ответах для разных пользователей с фильтрами безопасности поиска Azure. При включении доступа на уровне документов результаты поиска, возвращаемые из службы "Поиск ИИ Azure" и используемые для создания ответа, обрезаются на основе членства пользователей в группе Microsoft Entra. Доступ на уровне документа можно включить только в существующих индексах поиска ИИ Azure. Дополнительные сведения см . в разделе Azure OpenAI в сети данных и конфигурации доступа.
Сопоставление полей индекса
Если вы используете собственный индекс, вам будет предложено на портале Azure AI Foundry определить поля, которые необходимо сопоставить с ответами на вопросы при добавлении источника данных. Можно указать несколько полей для данных содержимого и включать все поля, имеющие текст, относящиеся к вашему варианту использования.

В этом примере поля, сопоставленные с данными содержимого и заголовок , предоставляют сведения модели для ответа на вопросы. Заголовок также используется для заголовка текста ссылки. Поле, сопоставленный с именем файла, создает имена ссылок в ответе.
Правильное сопоставление этих полей помогает убедиться, что модель имеет лучшее качество отклика и ссылок. Кроме того, его можно настроить в API с помощью fieldsMapping параметра.
Фильтр поиска (API)
Если вы хотите реализовать дополнительные критерии на основе значений для выполнения запросов, можно настроить фильтр поиска с помощью filter параметра в REST API.
Прием данных в поиск azure AI
По состоянию на сентябрь 2024 года API приема переключились на интегрированную векторизацию. Это обновление не изменяет существующие контракты API. Встроенная векторизация, новое предложение службы "Поиск ИИ Azure", использует предварительно созданные навыки для блокирования и внедрения входных данных. Служба приема данных в Azure OpenAI больше не использует пользовательские навыки. После миграции на интегрированную векторизацию процесс приема прошел некоторые изменения и в результате создаются только следующие ресурсы:
{job-id}-index-
{job-id}-indexer, если указано почасовое или ежедневное расписание, в противном случае индексатор очищается в конце процесса приема. {job-id}-datasource
Контейнер блоков больше недоступен, так как эта функция теперь изначально управляется поиском ИИ Azure.
Подключение к данным
Необходимо выбрать способ проверки подлинности подключения из Azure OpenAI, поиска ИИ Azure и хранилища BLOB-объектов Azure. Вы можете выбрать управляемое удостоверение , назначаемое системой, или ключ API. Выбрав ключ API в качестве типа проверки подлинности, система автоматически заполняет ключ API для подключения с помощью поиска ИИ Azure, Azure OpenAI и Хранилище BLOB-объектов Azure ресурсов. Выбрав управляемое удостоверение, назначенное системой, проверка подлинности будет зависеть от назначения роли. Управляемое удостоверение , назначаемое системой, выбрано по умолчанию для обеспечения безопасности.

После нажатия следующей кнопки программа автоматически проверит настройку, чтобы использовать выбранный метод проверки подлинности. Если возникла ошибка, ознакомьтесь со статьей о назначениях ролей, чтобы обновить настройку.
После исправления установки нажмите кнопку "Далее ", чтобы проверить и продолжить. Пользователи API также могут настроить проверку подлинности с назначенным управляемым удостоверением и ключами API.









Развертывание в copilot (предварительная версия), приложение Teams (предварительная версия) или веб-приложение
После подключения Azure OpenAI к данным его можно развернуть с помощью кнопки "Развернуть" на портале Azure AI Foundry.

Это дает несколько вариантов развертывания решения.
Вы можете развернуть в copilot в Copilot Studio (предварительная версия) непосредственно на портале Azure AI Foundry, что позволяет перенести беседы в различные каналы, такие как Microsoft Teams, веб-сайты, Dynamics 365 и другие каналы Azure Служба Bot. Клиент, используемый в службе Azure OpenAI и Copilot Studio (предварительная версия), должен совпадать. Дополнительные сведения см. в статье "Использование подключения к Azure OpenAI On Your Data".
Примечание.
Развертывание в copilot в Copilot Studio (предварительная версия) доступно только в регионах США.
Настройка доступа и сети для Azure OpenAI в данных
Вы можете использовать Azure OpenAI On Your Data и защитить данные и ресурсы с помощью управления доступом на основе ролей, виртуальных сетей и частных конечных точек на основе идентификатора Microsoft. Вы также можете ограничить документы, которые можно использовать в ответах для разных пользователей с фильтрами безопасности поиска ВИ Azure. См . сведения об Azure OpenAI Для доступа к данным и конфигурации сети.
Рекомендации
Используйте следующие разделы, чтобы узнать, как улучшить качество ответов, заданных моделью.
Параметр приема
При приеме данных в службу "Поиск ИИ Azure" можно изменить следующие дополнительные параметры в API приема или студии.
Размер блока (предварительная версия)
Azure OpenAI On Your Data обрабатывает документы, разделяя их на блоки перед их приемом. Размер блока — это максимальный размер с точки зрения количества маркеров любого блока в индексе поиска. Размер блока и количество извлеченных документов вместе управляют объемом сведений (токенов) в запросе, отправляемого в модель. Как правило, размер блока, умноженный на количество извлеченных документов, — это общее количество маркеров, отправляемых в модель.
Настройка размера блока для вашего варианта использования
Размер блока по умолчанию — 1024 токенов. Однако, учитывая уникальность данных, вы можете найти другой размер блока (например, 256, 512 или 1536 токенов).
Настройка размера блока может повысить производительность чат-бота. При поиске оптимального размера блока требуется некоторые пробные и ошибки, сначала учитывая характер набора данных. Меньший размер блока обычно лучше подходит для наборов данных с прямыми фактами и меньшим контекстом, в то время как более крупный размер блока может оказаться полезным для более контекстной информации, хотя это может повлиять на производительность извлечения.
Небольшой размер блока, как 256, создает более детализированные блоки. Этот размер также означает, что модель будет использовать меньше маркеров для создания выходных данных (если количество извлеченных документов очень высоко), потенциально затратив меньше. Меньшие блоки также означают, что модели не нужно обрабатывать и интерпретировать длинные разделы текста, уменьшая шум и отвлекающий фактор. Эта детализация и фокус, однако, представляют собой потенциальную проблему. Важные сведения могут быть не одними из наиболее извлеченных фрагментов, особенно если количество извлеченных документов имеет низкое значение, например 3.
Совет
Имейте в виду, что изменение размера блока требует повторного приема документов, поэтому рекомендуется сначала настроить параметры среды выполнения, такие как строгость и количество извлеченных документов. Попробуйте изменить размер блока, если вы по-прежнему не получаете нужные результаты:
- Если вы сталкиваетесь с большим количеством ответов, таких как "Я не знаю" для вопросов с ответами, которые должны находиться в ваших документах, рассмотрите возможность уменьшения размера блока до 256 или 512, чтобы повысить степень детализации.
- Если чат-бот предоставляет некоторые правильные сведения, но отсутствуют другие, что становится очевидным в цитатах, увеличение размера блока до 1536 может помочь получить более контекстную информацию.
Параметры среды выполнения
Вы можете изменить следующие дополнительные параметры в разделе параметров данных на портале Azure AI Foundry и API. При обновлении этих параметров вам не нужно повторно отправлять данные.
| Наименование параметра | Description |
|---|---|
| Ограничение ответов на данные | Этот флаг настраивает подход чат-бота к обработке запросов, не связанных с источником данных, или когда поиск документов недостаточно для полного ответа. Если этот параметр отключен, модель дополняет свои ответы собственными знаниями в дополнение к документам. Если этот параметр включен, модель пытается использовать только документы для ответов.
inScope Это параметр в API и задано значение true по умолчанию. |
| Извлеченные документы | Этот параметр представляет собой целое число, которое можно задать для 3, 5, 10 или 20, и определяет количество блоков документов, предоставленных большой языковой модели для формирования окончательного ответа. По умолчанию это значение равно 5. Процесс поиска может быть шумным, а иногда из-за фрагментирования релевантной информации может распространяться по нескольким блокам в индексе поиска. Выбор номера top-K, например 5, гарантирует, что модель может извлечь соответствующую информацию, несмотря на ограничения поиска и блокирования. Однако увеличение числа слишком большое может отвлекать модель. Кроме того, максимальное количество документов, которые можно эффективно использовать, зависит от версии модели, так как каждая из них имеет другой размер контекста и емкость для обработки документов. Если вы обнаружите, что ответы отсутствуют в важном контексте, попробуйте увеличить этот параметр.
topNDocuments Это параметр в API и имеет значение 5 по умолчанию. |
| Строгость | Определяет агрессивность системы в фильтрации документов поиска на основе их показателей сходства. Система запрашивает поиск Azure или другие хранилища документов, а затем решает, какие документы предоставляются для больших языковых моделей, таких как ChatGPT. Фильтрация неуместных документов может значительно повысить производительность сквозного чат-бота. Некоторые документы исключены из результатов top-K, если они имеют низкие оценки сходства перед пересылкой их в модель. Это управляется целым значением от 1 до 5. При задании этого значения значение равно 1 означает, что система будет минимально фильтровать документы на основе сходства поиска с пользовательским запросом. И наоборот, параметр 5 указывает, что система будет агрессивно фильтровать документы, применяя очень высокий порог сходства. Если вы обнаружите, что чат-бот пропускает соответствующие сведения, уменьшите строгость фильтра (задайте значение ближе к 1), чтобы включить дополнительные документы. И наоборот, если неуместные документы отвлекают ответы, увеличьте пороговое значение (задайте значение ближе к 5).
strictness Это параметр в API и задано значение 3 по умолчанию. |
Справочные материалы
Модель может вернуться "TYPE":"UNCITED_REFERENCE" вместо "TYPE":CONTENT API документов, извлекаемых из источника данных, но не включенных в ссылку. Это может быть полезно для отладки, и вы можете управлять этим поведением, изменив строгость и извлеченные параметры среды выполнения документов , описанные выше.
Системное сообщение
Вы можете определить системное сообщение, чтобы управлять ответом модели при использовании Azure OpenAI On Your Data. Это сообщение позволяет настроить ответы поверх шаблона расширенного создания (RAG), используемого Azure OpenAI On Your Data. Системное сообщение используется в дополнение к внутреннему базовому запросу для предоставления интерфейса. Для поддержки этого мы усекаем системное сообщение после определенного количества маркеров , чтобы модель могли отвечать на вопросы с помощью данных. Если вы определяете дополнительное поведение поверх интерфейса по умолчанию, убедитесь, что системный запрос подробно описан и объясняет точную ожидаемую настройку.
После добавления набора данных можно использовать раздел "Системное сообщение " на портале Azure AI Foundry или role_informationпараметр в API.

Потенциальные шаблоны использования
Определение роли
Вы можете определить роль, которую требуется помощнику. Например, если вы создаете бот поддержки, вы можете добавить "Вы являетесь помощником по поддержке инцидентов эксперта, который помогает пользователям решать новые проблемы".
Определение типа извлекаемых данных
Вы также можете добавить характер данных, которые вы предоставляете помощнику.
- Определите тему или область набора данных, например "финансовый отчет", "академический документ" или "отчет об инциденте". Например, для технической поддержки можно добавить сообщение "Вы отвечаете на запросы, используя информацию из аналогичных инцидентов в извлеченных документах".
- Если данные имеют определенные характеристики, вы можете добавить эти сведения в системное сообщение. Например, если документы находятся на японском языке, можно добавить "Вы извлекаете японские документы, и их следует внимательно читать на японском языке и отвечать на них на японском языке".
- Если документы включают структурированные данные, такие как таблицы из финансового отчета, вы также можете добавить этот факт в системный запрос. Например, если данные содержат таблицы, можно добавить "Вы предоставляете данные в виде таблиц, относящихся к финансовым результатам, и вы должны прочитать строку таблицы по строке, чтобы выполнить вычисления, чтобы ответить на вопросы пользователя".
Определение стиля выходных данных
Вы также можете изменить выходные данные модели, определив системное сообщение. Например, если вы хотите убедиться, что ответы помощника находятся на французском языке, можно добавить запрос, например "Вы являетесь помощником по искусственному интеллекту, который помогает пользователям, которые понимают французскую информацию о поиске информации. Вопросы пользователя могут быть на английском или французском языках. Внимательно прочитайте извлеченные документы и ответьте на них на французском языке. Пожалуйста, переводите знания из документов на французский, чтобы убедиться, что все ответы находятся на французском языке".
Подтверждение критического поведения
Azure OpenAI On Your Data работает, отправляя инструкции в большую языковую модель в виде запросов пользователей с помощью данных. Если в приложении имеется определенное поведение, можно повторить поведение в системном сообщении, чтобы повысить ее точность. Например, чтобы управлять моделью только ответами из документов, можно добавить "Пожалуйста, ответьте только с использованием извлеченных документов и без использования знаний. Создайте ссылки для получения документов для каждого утверждения в ответе. Если не удается ответить на вопрос пользователя с помощью извлеченных документов, объясните причину того, почему документы относятся к запросам пользователей. В любом случае не отвечайте на свои знания».
Подсказки по проектированию
Существует множество трюков в проектировании запросов, которые можно попытаться улучшить выходные данные. Один из примеров — это цепочка мыслей, где можно добавить сообщение "Давайте посмотрим пошаговую информацию в извлеченных документах для ответа на запросы пользователей. Извлеките соответствующие знания для запросов пользователей из документов пошаговые инструкции и сформируйте ответ вниз из извлеченных сведений из соответствующих документов".
Примечание.
Системное сообщение используется для изменения ответа помощника GPT на вопрос пользователя на основе полученной документации. Это не влияет на процесс извлечения. Если вы хотите предоставить инструкции по процессу извлечения, лучше включить их в вопросы. Системное сообщение является только руководством. Модель может не соответствовать каждой инструкции, указанной, так как она была загрумирована с определенными поведениями, такими как объективность, и избегая спорных заявлений. Непредвиденное поведение может произойти, если системное сообщение противоречит этим поведению.
Максимальный ответ
Задайте ограничение на количество маркеров для ответа модели. Верхний предел для Azure OpenAI в данных составляет 1500. Это эквивалентно настройке max_tokens параметра в API.
Ограничение ответов на данные
Этот параметр поощряет модель реагировать только на данные и выбирается по умолчанию. При отмене выбора этого параметра модель может более легко применить свои внутренние знания для реагирования. Определите правильный выбор на основе варианта использования и сценария.
Взаимодействие с моделью
Используйте следующие методики для получения наилучших результатов при чате с моделью.
Журнал бесед
- Прежде чем начать новую беседу (или задать вопрос, который не связан с предыдущими), снимите журнал чата.
- Получение различных ответов на один и тот же вопрос между первым поворотом беседы и последующими поворотами можно ожидать, так как журнал беседы изменяет текущее состояние модели. Если вы получаете неправильные ответы, сообщите о ней как о проблеме качества.
Ответ модели
Если вы не удовлетворены ответом модели для конкретного вопроса, попробуйте сделать вопрос более конкретным или более универсальным, чтобы узнать, как модель реагирует, и соответствующим образом обработать свой вопрос.
Длина вопроса
Избегайте задавать длинные вопросы и разбивайте их на несколько вопросов, если это возможно. Модели GPT имеют ограничения на количество маркеров, которые они могут принимать. Ограничения маркеров учитываются: вопрос пользователя, системное сообщение, извлеченные документы поиска (блоки), внутренние запросы, журнал бесед (если таковые имеются) и ответ. Если вопрос превышает ограничение маркера, он будет усечен.
Поддержка нескольких лингвистов
В настоящее время поиск ключевых слов и семантический поиск в Azure OpenAI On Your Data поддерживает запросы на том же языке, что и данные в индексе. Например, если данные на японском языке, то входные запросы также должны находиться на японском языке. Для получения перекрестного документа рекомендуется создавать индекс с включенным векторным поиском .
Чтобы повысить качество получения информации и ответа модели, рекомендуется включить семантический поиск на следующих языках: английский, французский, испанский, португальский, итальянский, итальянский, китайский(zh), японский, корейский, русский, арабский
Мы рекомендуем использовать системное сообщение для информирования модели о том, что данные используются на другом языке. Например:
**Вы являетесь помощником по искусственному интеллекту, который помогает пользователям извлекать информацию из извлеченных японских документов. Внимательно изучите японские документы, прежде чем сформулировать ответ. Запрос пользователя будет находиться на японском языке, и вы также должны ответить на японском языке".
Если у вас есть документы на нескольких языках, рекомендуется создать новый индекс для каждого языка и подключить их отдельно к Azure OpenAI.
Потоковая передача данных
Запрос потоковой передачи можно отправить с помощью stream параметра, позволяя отправлять и получать данные постепенно, не ожидая ответа всего API. Это может повысить производительность и взаимодействие с пользователем, особенно для больших или динамических данных.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Журнал бесед для улучшения результатов
При чате с моделью, предоставление журнала чата поможет модели вернуть более качественные результаты. Вам не нужно включать context свойство сообщений помощника в запросы API для повышения качества ответа. Примеры см . в справочной документации по API.
Вызов функции
Некоторые модели Azure OpenAI позволяют определять средства и tool_choice параметры для включения вызовов функций. Вы можете настроить вызов функции с помощью REST API/chat/completions. Если оба toolsисточника данных находятся в запросе, применяется следующая политика.
- Если
tool_choiceэтоnoneтак, средства игнорируются, а для создания ответа используются только источники данных. - В противном случае, если
tool_choiceон не указан или указан какautoобъект, источники данных игнорируются, а ответ будет содержать имя выбранных функций и аргументы, если таковые имеются. Даже если модель не выбирает функцию, источники данных по-прежнему игнорируются.
Если указанная выше политика не соответствует вашей необходимости, рассмотрите другие варианты, например : поток запросов или API помощников.
Оценка использования токенов для Azure OpenAI в данных
Azure OpenAI On Your Data Retrieval Дополненное поколение (RAG) — это служба, которая использует службу поиска (например, поиск azure AI) и поколение (модели Azure OpenAI), чтобы пользователи получили ответы на свои вопросы на основе предоставленных данных.
В рамках этого конвейера RAG существует три шага на высоком уровне:
Переформатировать запрос пользователя в список намерений поиска. Это делается путем вызова модели с запросом, включающим инструкции, вопрос пользователя и журнал бесед. Давайте вызовем этот запрос намерения.
Для каждого намерения из службы поиска извлекаются несколько блоков документов. После фильтрации неуместных блоков на основе заданного пользователем порога строгости и повторной обработки или агрегирования блоков на основе внутренней логики выбирается указанное пользователем количество блоков документов.
Эти блоки документов, а также вопросы пользователя, журнал бесед, сведения о роли и инструкции отправляются в модель, чтобы создать окончательный ответ модели. Давайте вызовем этот запрос поколения.
В общей сложности существует два вызова модели:
Для обработки намерения: оценка маркера для запроса намерения включает те, которые относятся к вопросу пользователя, журналу бесед и инструкциям, отправленным в модель для создания намерений.
Для создания ответа: оценка маркера для запроса на создание включает в себя те, которые относятся к вопросу пользователя, журналу бесед, полученному списку фрагментов документов, сведениям о роли и инструкциям, отправленным в него для создания.
Для оценки общего токена модели необходимо учитывать созданные выходные маркеры (намерения и ответ). Суммирование всех четырех столбцов ниже дает среднее общее количество маркеров, используемых для создания ответа.
| Модель | Число маркеров запроса создания | Число маркеров запроса намерения | Число маркеров ответа | Число маркеров намерения |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
Приведенные выше числа основаны на тестировании набора данных с помощью следующих компонентов:
- Беседы 191
- 250 вопросов
- 10 средних токенов на вопрос
- 4 беседы в среднем по одной беседе
И следующие параметры.
| Параметр | Значение |
|---|---|
| Количество извлеченных документов | 5 |
| Строгость | 3 |
| Размер блока | 1024 |
| Ограничение ответов на прием данных? | Истина |
Эти оценки зависят от значений, заданных для указанных выше параметров. Например, если для количества извлеченных документов задано значение 10, а строгость имеет значение 1, число маркеров увеличится. Если возвращенные ответы не ограничиваются приемными данными, в модели меньше инструкций, а количество маркеров будет уменьшаться.
Оценки также зависят от характера запрашиваемых документов и вопросов. Например, если вопросы открыты, ответы, скорее всего, будут длиннее. Аналогичным образом, более длинное системное сообщение будет способствовать более длинному запросу, который потребляет больше маркеров, и если журнал беседы длинный, запрос будет длиннее.
| Модель | Максимальные маркеры для системного сообщения |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
В приведенной выше таблице показано максимальное количество маркеров, которые можно использовать для системного сообщения. Чтобы просмотреть максимальные маркеры для ответа модели, см . статью о моделях. Кроме того, следующие маркеры также используют:
Мета-запрос: если вы ограничиваете ответы от модели на содержимое данных заземления (
inScope=Trueв API), максимальное количество маркеров выше. В противном случае (например, еслиinScope=False) максимальное значение меньше. Это число является переменной в зависимости от длины маркера вопроса пользователя и журнала бесед. Эта оценка включает базовый запрос и запрос на перезапись запросов для извлечения.Вопрос пользователя и журнал: переменная, но ограничена 2000 токенами.
Извлеченные документы (блоки): количество маркеров, используемых извлекаемыми блоками документов, зависит от нескольких факторов. Верхняя граница для этого — это количество извлеченных блоков документа, умноженное на размер блока. Однако он будет усечен на основе маркеров, доступных маркеров для конкретной модели, используемой после подсчета остальных полей.
20% доступных маркеров зарезервированы для ответа модели. Остальные 80% доступных маркеров включают мета-запрос, журнал вопросов пользователя и беседы и системное сообщение. Оставшийся бюджет токена используется фрагментами извлеченных документов.
Чтобы вычислить количество маркеров, потребляемых входными данными (например, вопросом, сведениями о системном сообщении или роли), используйте следующий пример кода.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
Устранение неполадок
Чтобы устранить сбои операций, всегда ищите ошибки или предупреждения, указанные в ответе API или на портале Azure AI Foundry. Ниже приведены некоторые распространенные ошибки и предупреждения:
Неудачные задания приема
Проблемы с ограничениями квот
Не удалось создать индекс с именем X в службе Y. Превышена квота индекса для этой службы. Сначала необходимо удалить неиспользуемые индексы, добавить задержку между запросами на создание индекса или обновить службу для более высоких ограничений.
Превышена квота стандартного индексатора X для этой службы. В настоящее время у вас есть индексаторы X уровня "Стандартный". Сначала необходимо удалить неиспользуемые индексаторы, изменить индексатор executionMode или обновить службу для более высоких ограничений.
Решение.
Обновление до более высокой ценовой категории или удаление неиспользуемых ресурсов.
Проблемы с временем ожидания предварительной обработки
Не удалось выполнить навык, так как сбой запроса веб-API
Не удалось выполнить навык, так как ответ на навык веб-API недопустим
Решение.
Разбиите входные документы на небольшие документы и повторите попытку.
Проблемы с разрешениями
Этот запрос не авторизован для выполнения этой операции
Решение.
Это означает, что учетная запись хранения недоступна с указанными учетными данными. В этом случае проверьте учетные данные учетной записи хранения, передаваемые API, и убедитесь, что учетная запись хранения не скрыта за частной конечной точкой (если частная конечная точка не настроена для этого ресурса).
Ошибки 503 при отправке запросов с помощью службы "Поиск ИИ Azure"
Каждое сообщение пользователя может переводиться на несколько поисковых запросов, все из которых отправляются в ресурс поиска параллельно. Это может привести к регулированию, если количество реплик поиска и секций низко. Максимальное количество запросов в секунду, которое может поддерживать одна секция и одна реплика, может быть недостаточно. В этом случае рассмотрите возможность увеличения реплик и секций или добавления логики спящего и повторного выполнения в приложении. Дополнительные сведения см. в документации по поиску ИИ Azure.
Поддержка региональной доступности и модели
| Область/регион | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Восточная Австралия | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Восточная Канада | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Восточная часть США | ✅ | ✅ | ✅ | |||||
| Восточная часть США 2 | ✅ | ✅ | ✅ | ✅ | ||||
| Центральная Франция | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Восточная Япония | ✅ | |||||||
| Центрально-северная часть США | ✅ | ✅ | ✅ | |||||
| Восточная Норвегия; | ✅ | ✅ | ||||||
| Центрально-южная часть США | ✅ | ✅ | ||||||
| Южная Индия | ✅ | ✅ | ||||||
| Центральная Швеция | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Северная Швейцария | ✅ | ✅ | ✅ | |||||
| южная часть Соединенного Королевства | ✅ | ✅ | ✅ | ✅ | ||||
| западная часть США | ✅ | ✅ | ✅ |
**Это реализация только для текста
Если ресурс Azure OpenAI находится в другом регионе, вы не сможете использовать Azure OpenAI On Your Data.