Метрики для Шлюза приложений
Шлюз приложений публикует точки данных в Azure Monitor для производительности Шлюз приложений и внутренних экземпляров. Эти точки данных называются метриками и являются числовыми значениями в упорядоченном наборе данных временных рядов. Метрики описывают некоторые аспекты шлюза приложений в определенное время. При наличии запросов, передаваемых через Шлюз приложений, он измеряет и отправляет его метрики с 60-секундным интервалом. Если нет запросов, передаваемых через Шлюз приложений или нет данных для метрики, метрика не сообщается. Дополнительные сведения см. в статье Обзор метрик в Microsoft Azure.
Примечание
Дополнительные сведения о прокси-сервере TLS/TCP см . в справочнике по данным.
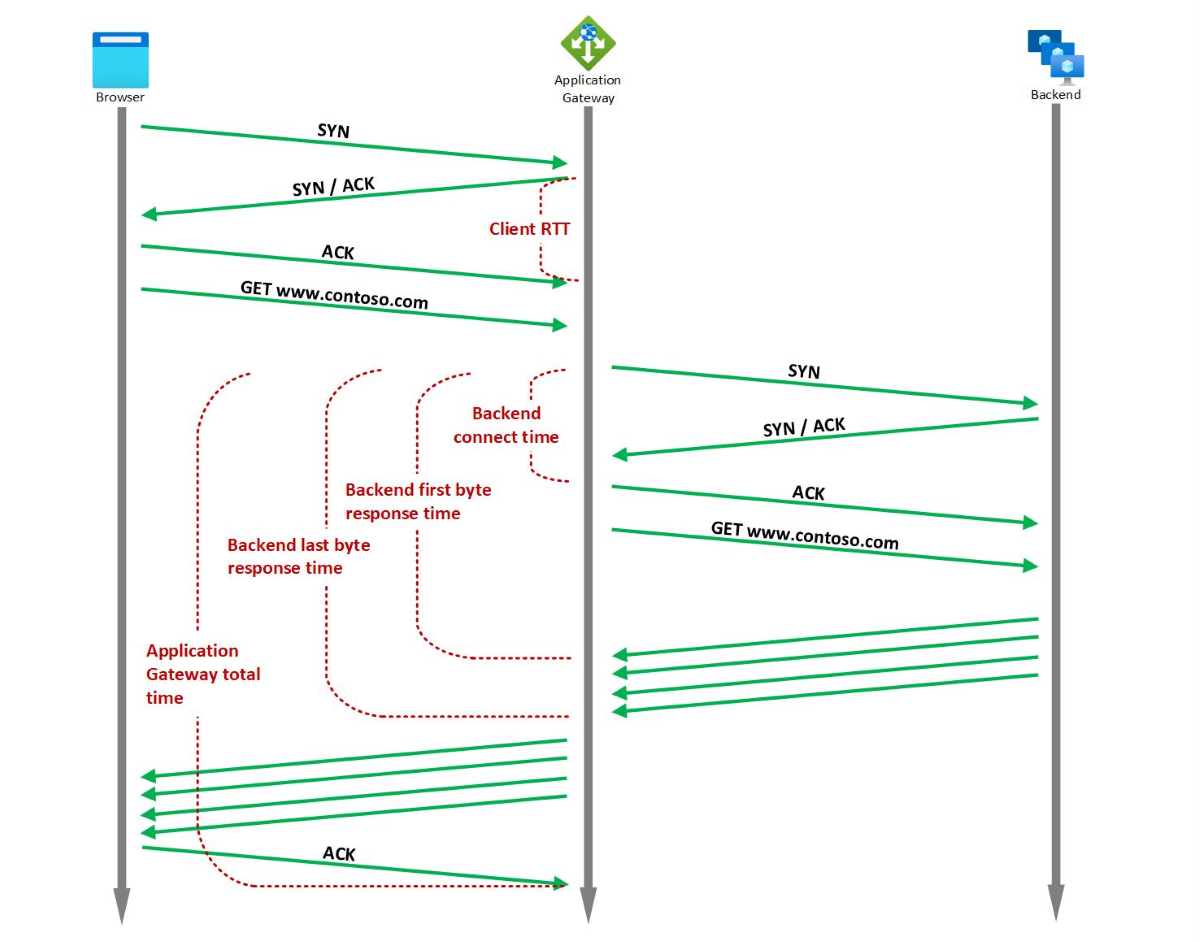
Шлюз приложений предоставляет несколько встроенных метрик времени, связанных с запросом и ответом, которые измеряются в миллисекундах.
Примечание
Если в Шлюз приложений есть несколько прослушивателя, всегда фильтруйте по измерению прослушивателя при сравнении различных метрик задержки, чтобы получить понятное вывод.
Примечание
Задержка может наблюдаться в данных метрик, так как все метрики агрегируются в течение одной минуты. Эта задержка может отличаться для разных экземпляров шлюза приложений в зависимости от времени начала метрики.
Вы можете использовать метрики времени для определения того, связано ли наблюдаемое замедление из-за клиентской сети, Шлюз приложений производительности, насыщенности стека TCP серверной и серверной серверной части, производительности серверного приложения или большого размера файла. Дополнительные сведения см. в разделе "Метрики времени".
Например, если наблюдается всплеск времени отклика серверной части, но тенденция времени внутреннего подключения стабильна, можно определить, что шлюз приложений для задержки серверной части и время, затраченное на установку подключения, стабильно. Пик возникает из-за увеличения времени отклика серверного приложения. С другой стороны, если пик времени отклика серверной части первого байта связан с соответствующим пиком времени подключения серверной части, можно определить, что сеть между Шлюз приложений и серверным сервером или стек tcp серверной части имеет насыщенный.
Если вы заметили всплеск времени отклика серверной части последней байтовой части, но время отклика серверной части первого байта стабильно, вы можете вывести, что пик зависит от запрашиваемого файла большего размера.
Если значение общего времени Шлюза приложений резко изменяется, а значение времени получения последнего байта ответа от серверной части остается неизменным, это может указывать на проблемы с производительностью на Шлюзе приложений или проблемы с сетевым подключением между клиентом и Шлюзом приложений. Кроме того, если клиент RTT также имеет соответствующий пик, он указывает, что снижение связано с сетью между клиентом и Шлюз приложений.
Для Шлюз приложений доступны несколько метрик. Список см. в разделе Шлюз приложений метрик.
Для Шлюз приложений доступны несколько внутренних метрик. Список см. в разделе "Внутренние метрики".
Сведения о мониторинге WAF см. в разделе Метрики WAF версии 2 и Метрики WAF версии 1.
Перейдите к шлюзу приложений и выберите Метрики в разделе Мониторинг. Чтобы просмотреть доступные значения, выберите раскрывающийся список Метрика.
На следующем изображении приведен пример с тремя метриками, отображаемыми в течение последних 30 минут:

Текущий список метрик доступен на странице Метрики, поддерживаемые Azure Monitor.
Вы можете запустить правила генерации оповещений на основе метрик для ресурса. Например, оповещение может вызвать веб-перехватчик или отправить электронное сообщение администратору, если пропускная способность шлюза приложений будет больше или меньше порогового значения в указанный период времени либо равной этому значению.
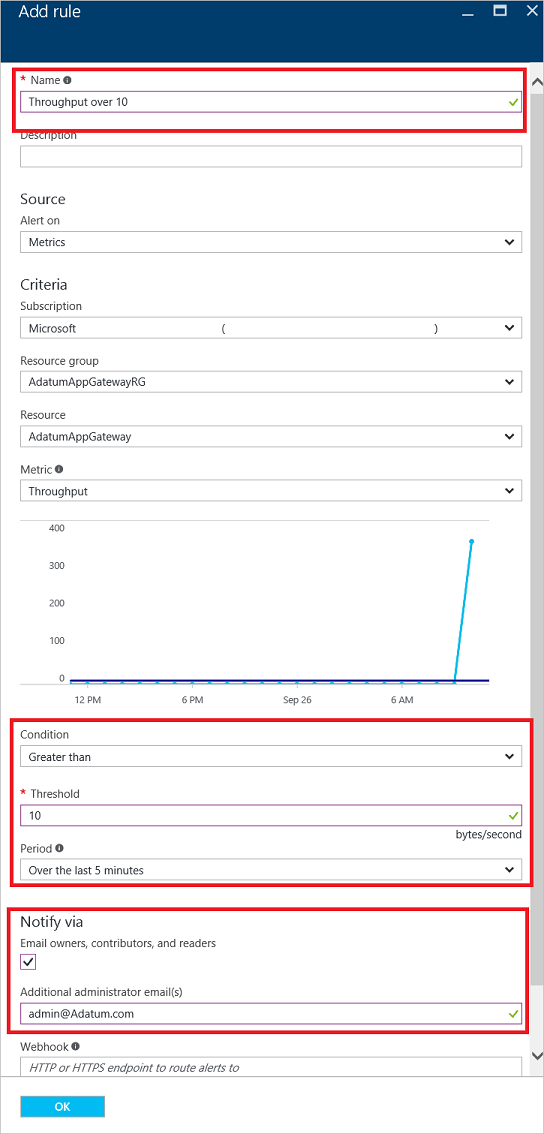
Приведенный ниже пример поможет вам создать правило генерации оповещений, согласно которому администратору отправляется электронное сообщение в случае нарушения порога пропускной способности.
Нажмите кнопку Добавить оповещение метрики, чтобы открыть страницу Добавление правила. Эту страницу также можно открыть со страницы метрик.

На странице Добавление правила заполните разделы для имени, условия и уведомления. После этого нажмите кнопку ОК.
С помощью селектора Условие выберите одно из четырех значений: Больше, Больше или равно, Меньше или Меньше или равно.
С помощью селектора Период выберите интервал от 5 минут до 6 часов.
Если выбрать владельцев электронной почты, участников и читателей, электронная почта может быть динамической на основе пользователей, имеющих доступ к такому ресурсу. В противном случае можно указать список пользователей с разделителями-запятыми в текстовом поле Дополнительные адреса электронной почты администратора.
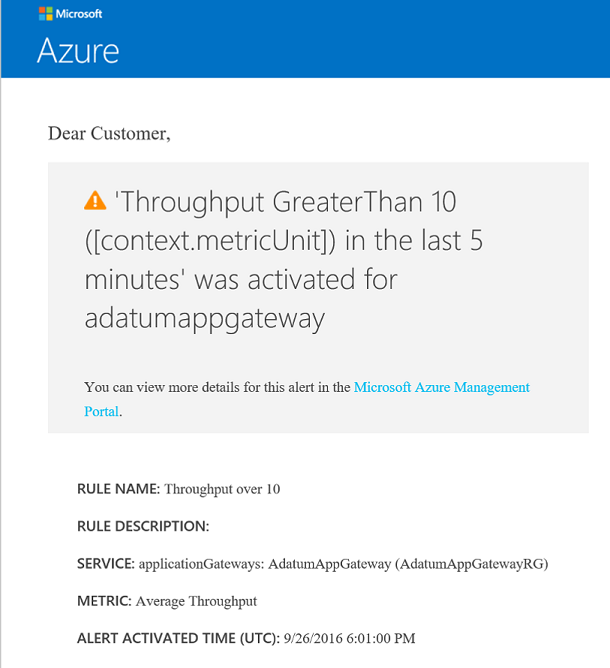
При нарушении порога вы получите примерно такое электронное сообщение:
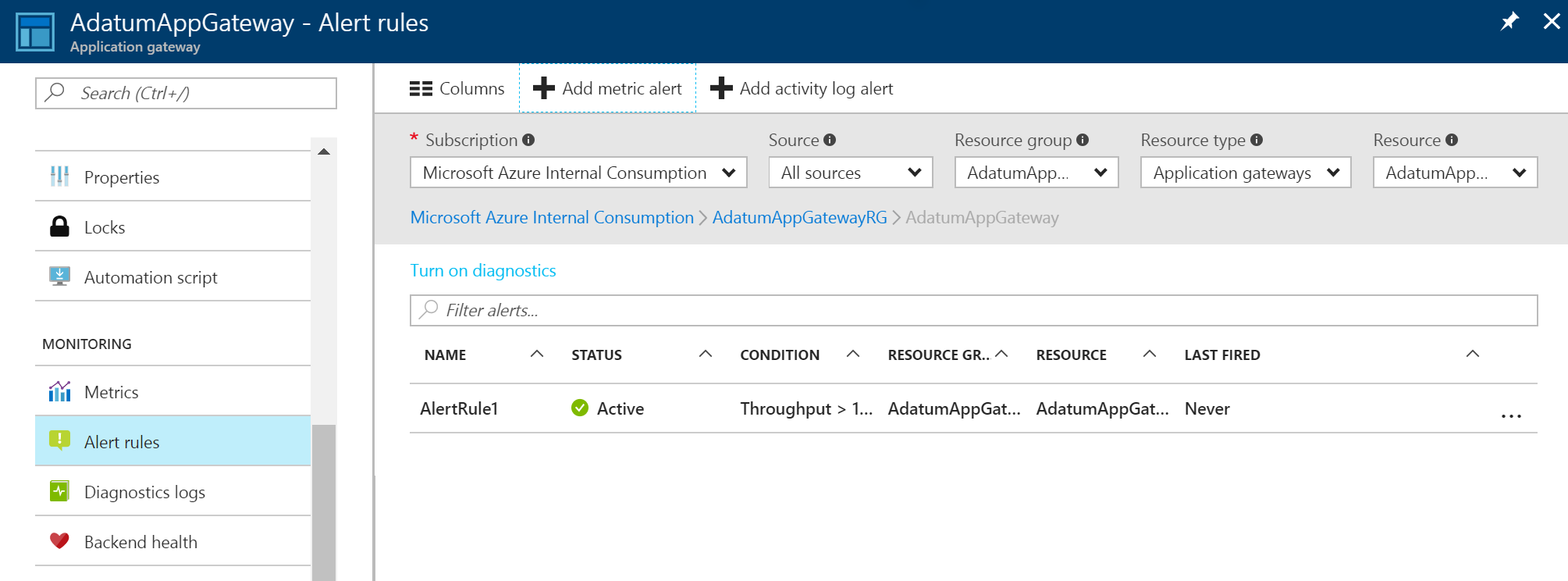
После создания оповещения метрики появится список оповещений. В нем содержатся все правила генерации оповещений.
Дополнительные сведения об уведомлениях для оповещений см. в статье Что такое оповещения в Microsoft Azure?
Чтобы лучше понять, как действуют веб-перехватчики и как их использовать с оповещениями, см. статью Настройка веб-перехватчиков для оповещений на основе метрик Azure.
- См. сведения о визуализации журналов счетчиков и событий с помощью журналов Azure Monitor.
- Прочтите запись блога Visualize your Azure Activity Log with Power BI (Визуализация журналов действий Azure с помощью Power BI).
- Прочтите запись блога View and analyze Azure Audit Logs in Power BI and more (Просмотр и анализ журналов аудита Azure с помощью Power BI и других средств).