Моделирование гравитации для нескольких тел в нескольких движках
В примере D3D12nBodyGravity показано, как выполнять вычисления в асинхронном режиме. Пример запускает несколько потоков с очередью команд вычислений и планирует вычислительные работы на ГРАФИЧЕСКОм процессоре, который выполняет моделирование гравитации n-тела. Каждый поток работает с двумя буферами, полными данных о положении и скорости. При каждой итерации шейдер вычислений считывает данные о текущем положении и скорости из одного буфера и записывает следующую итерацию в другой буфер. После завершения итерации вычислительный шейдер переключает буфер SRV для чтения данных о положении и скорости, а какой — для записи обновлений положения/скорости путем изменения состояния ресурсов в каждом буфере.
- Создание корневых сигнатур
- Создание буферов SRV и UAV
- Создание буферов вершин и CBV
- Синхронизация потоков отрисовки и вычислений
- Запуск примера
- Связанные темы
Создание корневых сигнатур
Начнем с создания графической и корневой сигнатуры вычислений в методе LoadAssets . Обе корневые сигнатуры имеют представление буфера корневой констант (CBV) и таблицу дескрипторов представления ресурсов шейдера (SRV). Корневая сигнатура вычислений также содержит таблицу дескрипторов представления неупорядоченного доступа (UAV).
// Create the root signatures.
{
CD3DX12_DESCRIPTOR_RANGE ranges[2];
ranges[0].Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 1, 0);
ranges[1].Init(D3D12_DESCRIPTOR_RANGE_TYPE_UAV, 1, 0);
CD3DX12_ROOT_PARAMETER rootParameters[RootParametersCount];
rootParameters[RootParameterCB].InitAsConstantBufferView(0, 0, D3D12_SHADER_VISIBILITY_ALL);
rootParameters[RootParameterSRV].InitAsDescriptorTable(1, &ranges[0], D3D12_SHADER_VISIBILITY_VERTEX);
rootParameters[RootParameterUAV].InitAsDescriptorTable(1, &ranges[1], D3D12_SHADER_VISIBILITY_ALL);
// The rendering pipeline does not need the UAV parameter.
CD3DX12_ROOT_SIGNATURE_DESC rootSignatureDesc;
rootSignatureDesc.Init(_countof(rootParameters) - 1, rootParameters, 0, nullptr, D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT);
ComPtr<ID3DBlob> signature;
ComPtr<ID3DBlob> error;
ThrowIfFailed(D3D12SerializeRootSignature(&rootSignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1, &signature, &error));
ThrowIfFailed(m_device->CreateRootSignature(0, signature->GetBufferPointer(), signature->GetBufferSize(), IID_PPV_ARGS(&m_rootSignature)));
// Create compute signature. Must change visibility for the SRV.
rootParameters[RootParameterSRV].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL;
CD3DX12_ROOT_SIGNATURE_DESC computeRootSignatureDesc(_countof(rootParameters), rootParameters, 0, nullptr);
ThrowIfFailed(D3D12SerializeRootSignature(&computeRootSignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1, &signature, &error));
ThrowIfFailed(m_device->CreateRootSignature(0, signature->GetBufferPointer(), signature->GetBufferSize(), IID_PPV_ARGS(&m_computeRootSignature)));
}
Создание буферов SRV и UAV
Буферы SRV и UAV состоят из массива данных о положении и скорости.
// Position and velocity data for the particles in the system.
// Two buffers full of Particle data are utilized in this sample.
// The compute thread alternates writing to each of them.
// The render thread renders using the buffer that is not currently
// in use by the compute shader.
struct Particle
{
XMFLOAT4 position;
XMFLOAT4 velocity;
};
| Поток вызовов | Параметры |
|---|---|
| XMFLOAT4 |
Создание буферов вершин и CBV
Для графического конвейера CBV представляет собой структуру , содержащую две матрицы, используемые геометрическим шейдером. Геометрический шейдер принимает положение каждой частицы в системе и создает четырехугольник для его представления с помощью этих матриц.
struct ConstantBufferGS
{
XMMATRIX worldViewProjection;
XMMATRIX inverseView;
// Constant buffers are 256-byte aligned in GPU memory. Padding is added
// for convenience when computing the struct's size.
float padding[32];
};
| Поток вызовов | Параметры |
|---|---|
| XMMATRIX |
В результате буфер вершин, используемый вершинным шейдером, фактически не содержит позиционных данных.
// "Vertex" definition for particles. Triangle vertices are generated
// by the geometry shader. Color data will be assigned to those
// vertices via this struct.
struct ParticleVertex
{
XMFLOAT4 color;
};
| Поток вызовов | Параметры |
|---|---|
| XMFLOAT4 |
Для конвейера вычислений CBV представляет собой структуру , содержащую некоторые константы, используемые при моделировании гравитации n-тела в вычислительном шейдере.
struct ConstantBufferCS
{
UINT param[4];
float paramf[4];
};
Синхронизация потоков отрисовки и вычислений
После инициализации всех буферов начнется отрисовка и вычислительная работа. Поток вычислений будет изменять состояние двух буферов позиции и скорости между SRV и UAV по мере выполнения итерирования по симуляции, а поток отрисовки должен убедиться, что он планирует работу в графическом конвейере, работающем на SRV. Ограждения используются для синхронизации доступа к двум буферам.
В потоке отрисовки:
// Render the scene.
void D3D12nBodyGravity::OnRender()
{
// Let the compute thread know that a new frame is being rendered.
for (int n = 0; n < ThreadCount; n++)
{
InterlockedExchange(&m_renderContextFenceValues[n], m_renderContextFenceValue);
}
// Compute work must be completed before the frame can render or else the SRV
// will be in the wrong state.
for (UINT n = 0; n < ThreadCount; n++)
{
UINT64 threadFenceValue = InterlockedGetValue(&m_threadFenceValues[n]);
if (m_threadFences[n]->GetCompletedValue() < threadFenceValue)
{
// Instruct the rendering command queue to wait for the current
// compute work to complete.
ThrowIfFailed(m_commandQueue->Wait(m_threadFences[n].Get(), threadFenceValue));
}
}
// Record all the commands we need to render the scene into the command list.
PopulateCommandList();
// Execute the command list.
ID3D12CommandList* ppCommandLists[] = { m_commandList.Get() };
m_commandQueue->ExecuteCommandLists(_countof(ppCommandLists), ppCommandLists);
// Present the frame.
ThrowIfFailed(m_swapChain->Present(0, 0));
MoveToNextFrame();
}
| Поток вызовов | Параметры |
|---|---|
| InterlockedExchange | |
| InterlockedGetValue | |
| GetCompletedValue | |
| Ожидание | |
| ID3D12CommandList | |
| ExecuteCommandLists | |
| IDXGISwapChain1::Present1 |
Чтобы немного упростить выборку, вычислительный поток ожидает завершения gpu каждой итерации перед планированием дополнительных вычислительных работ. На практике приложения, скорее всего, хотят, чтобы очередь вычислений была заполнена, чтобы обеспечить максимальную производительность gpu.
В потоке вычислений:
DWORD D3D12nBodyGravity::AsyncComputeThreadProc(int threadIndex)
{
ID3D12CommandQueue* pCommandQueue = m_computeCommandQueue[threadIndex].Get();
ID3D12CommandAllocator* pCommandAllocator = m_computeAllocator[threadIndex].Get();
ID3D12GraphicsCommandList* pCommandList = m_computeCommandList[threadIndex].Get();
ID3D12Fence* pFence = m_threadFences[threadIndex].Get();
while (0 == InterlockedGetValue(&m_terminating))
{
// Run the particle simulation.
Simulate(threadIndex);
// Close and execute the command list.
ThrowIfFailed(pCommandList->Close());
ID3D12CommandList* ppCommandLists[] = { pCommandList };
pCommandQueue->ExecuteCommandLists(1, ppCommandLists);
// Wait for the compute shader to complete the simulation.
UINT64 threadFenceValue = InterlockedIncrement(&m_threadFenceValues[threadIndex]);
ThrowIfFailed(pCommandQueue->Signal(pFence, threadFenceValue));
ThrowIfFailed(pFence->SetEventOnCompletion(threadFenceValue, m_threadFenceEvents[threadIndex]));
WaitForSingleObject(m_threadFenceEvents[threadIndex], INFINITE);
// Wait for the render thread to be done with the SRV so that
// the next frame in the simulation can run.
UINT64 renderContextFenceValue = InterlockedGetValue(&m_renderContextFenceValues[threadIndex]);
if (m_renderContextFence->GetCompletedValue() < renderContextFenceValue)
{
ThrowIfFailed(pCommandQueue->Wait(m_renderContextFence.Get(), renderContextFenceValue));
InterlockedExchange(&m_renderContextFenceValues[threadIndex], 0);
}
// Swap the indices to the SRV and UAV.
m_srvIndex[threadIndex] = 1 - m_srvIndex[threadIndex];
// Prepare for the next frame.
ThrowIfFailed(pCommandAllocator->Reset());
ThrowIfFailed(pCommandList->Reset(pCommandAllocator, m_computeState.Get()));
}
return 0;
}
Запуск примера
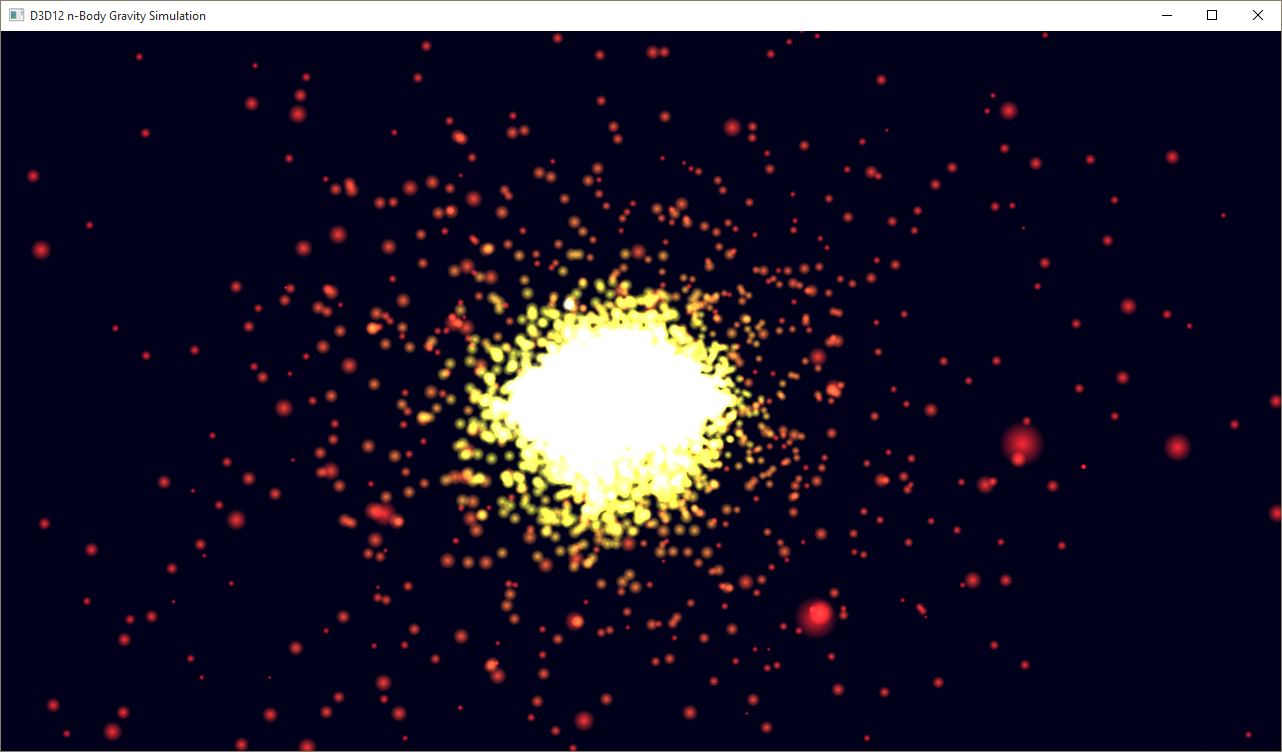
Связанные темы
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по