Синхронизация с несколькими ядрами
Большинство современных GPU содержат несколько независимых обработчиков, которые предоставляют специализированные функциональные возможности. Многие имеют один или несколько выделенных обработчиков копирования, и вычислительный модуль, как правило, отличается от 3D-ядра. Каждая из этих подсистем может выполнять команды параллельно друг с другом. Direct3D 12 обеспечивает точный доступ к трехмерной, вычислительной и копируемой подсистеме, используя очереди и списки команд.
На следующей схеме показаны потоки ЦП заголовка, каждая из которых заполняет одну или несколько очередей копирования, вычислений и трехмерных очередей. 3D-очередь может управлять всеми тремя ядрами GPU; очередь вычислений может управлять подсистемами вычислений и копирования; и очередь копирования просто обработчик копирования.
По мере заполнения очередей различными потоками не может быть простой гарантии порядка выполнения, поэтому потребность в механизмах синхронизации, когда заголовок требует их.
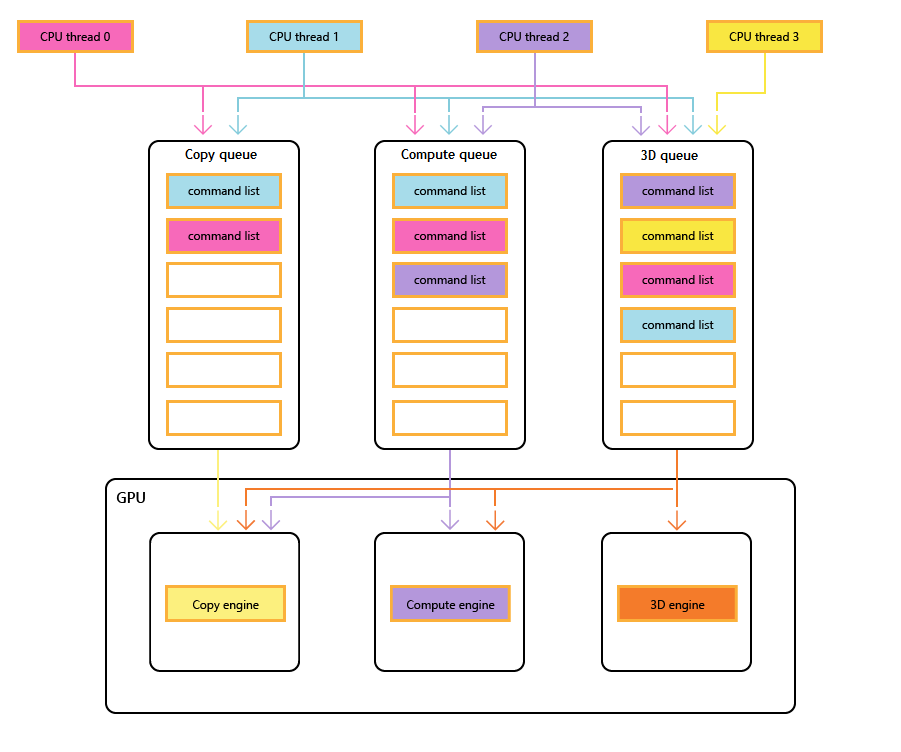
На следующем рисунке показано, как заголовок может запланировать работу нескольких обработчиков GPU, включая синхронизацию между ядрами при необходимости: она показывает рабочие нагрузки для каждого ядра с межпроцессорными зависимостями. В этом примере обработчик копирования сначала копирует некоторую геометрию, необходимую для отрисовки. Подсистема трехмерного анализа ожидает завершения этих копий и отрисовывает предварительную передачу по геометрии. Затем это используется подсистемой вычислений. Результаты подсистемы вычислений диспетчеризации, а также несколько операций копирования текстур в подсистеме копирования используются обработчиком трехмерных данных для окончательного вызова рисования.
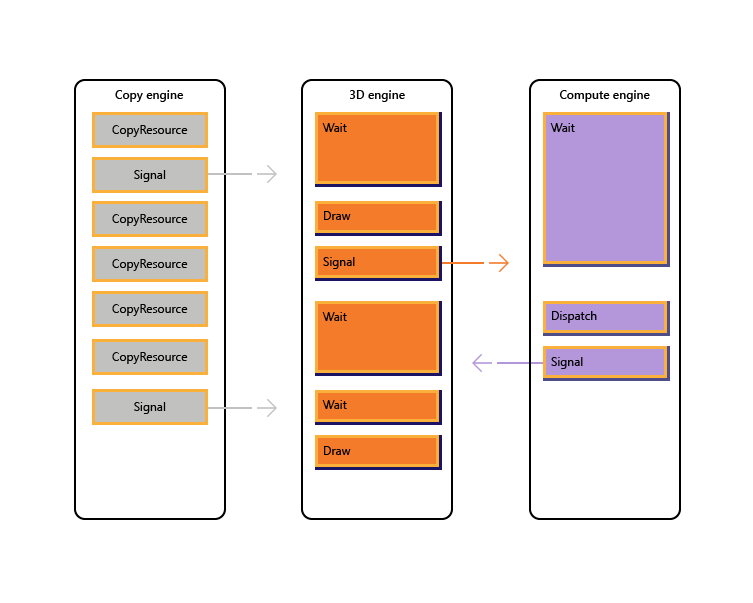
В следующем псевдокоде показано, как заголовок может отправить такую рабочую нагрузку.
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
Следующий псевдокод иллюстрирует синхронизацию между обработчиками копирования и трехмерных модулей для выполнения выделения кучи памяти через кольцевой буфер. Названия имеют гибкость, чтобы выбрать правильный баланс между максимизацией параллелизма (через большой буфер) и сокращением потребления памяти и задержки (через небольшой буфер).
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
Direct3D 12 позволяет избежать случайного возникновения неэффективных проблем, вызванных непредвиденными задержками синхронизации. Кроме того, он позволяет внедрять синхронизацию на более высоком уровне, где необходимая синхронизация может быть определена с большей уверенностью. Вторая проблема, из-за которой адреса с несколькими ядрами были более явными, что включает переходы между 3D и видео, которые традиционно были дорогостоящими из-за синхронизации между несколькими контекстами ядра.
В частности, следующие сценарии можно устранить с помощью Direct3D 12.
- Асинхронная и низкоприоритетная работа GPU. Это позволяет одновременно выполнять операции с низкоприоритетными рабочими и атомарными операциями GPU, которые позволяют одному потоку GPU использовать результаты другого несинхронизованного потока без блокировки.
- Высокоприоритетная работа вычислений. При использовании фоновых вычислений можно прервать трехмерную отрисовку, чтобы выполнить небольшую работу с высокоприоритетными вычислительными ресурсами. Результаты этой работы можно получить рано для дополнительной обработки на ЦП.
- Фоновая работа вычислений. Отдельная очередь с низким приоритетом для вычислительных рабочих нагрузок позволяет приложению использовать резервные циклы GPU для выполнения фоновых вычислений без негативного влияния на основные задачи отрисовки (или других). Фоновые задачи могут включать распаковку ресурсов или обновление имитаций или структур ускорения. Фоновые задачи следует синхронизировать на ЦП редко (примерно один раз на кадр), чтобы избежать остановки или замедления работы переднего плана.
- Потоковая передача и отправка данных. Отдельная очередь копирования заменяет концепции D3D11 исходных данных и обновления ресурсов. Несмотря на то, что приложение отвечает за дополнительные сведения в модели Direct3D 12, эта ответственность связана с питанием. Приложение может управлять объемом системной памяти, посвященной буферизации данных отправки. Приложение может выбрать время и способ (ЦП и GPU, блокировка и неблокировка) для синхронизации, а также отслеживать ход выполнения и управлять объемом работы в очереди.
- Увеличение параллелизма. Приложения могут использовать более глубокие очереди для фоновых рабочих нагрузок (например, декодирование видео) при наличии отдельных очередей для работы переднего плана.
В Direct3D 12 концепция очереди команд представляет собой представление API примерно последовательной последовательности работы, отправленной приложением. Барьеры и другие методы позволяют выполнять эту работу в конвейере или вне порядка, но приложение видит только одну временную шкалу завершения. Это соответствует немедленному контексту в D3D11.
Устройство Direct3D 12 имеет методы для создания и извлечения очередей команд различных типов и приоритетов. Большинство приложений должны использовать очереди команд по умолчанию, так как они позволяют совместно использовать другие компоненты. Приложения с дополнительными требованиями параллелизма могут создавать дополнительные очереди. Очереди задаются типом списка команд, который они используют.
См. следующие методы создания ID3D12Device.
- CreateCommandQueue: создает очередь команд на основе сведений в структуре Direct3D 12_COMMAND_QUEUE_DESC.
- CreateCommandList: создает список команд типа Direct3D 12_COMMAND_LIST_TYPE.
- CreateFence: создает забор, отметив флаги в Direct3D 12_FENCE_FLAGS. Ограждения используются для синхронизации очередей.
Очереди всех типов (3D, вычислений и копирования) используют один и тот же интерфейс и являются всеми списками команд.
См. следующие методы ID3D12CommandQueue.
- ExecuteCommandLists: отправляет массив списков команд для выполнения. Каждый список команд определяется ID3D12CommandList.
- Сигнал: задает значение забора, когда очередь (запущенная на GPU) достигает определенной точки.
- ожидание: очередь ожидает, пока указанный забор не достигнет указанного значения.
Обратите внимание, что пакеты не используются в очередях, поэтому этот тип нельзя использовать для создания очереди.
API с несколькими ядрами предоставляет явные API для создания и синхронизации с помощью заборов. Забор — это конструкция синхронизации, контролируемая значением UINT64. Значения ограждения задаются приложением. Операция сигнала изменяет значение забора и блоки операций ожидания, пока забор не достигнет запрошенного значения или больше. Событие можно запустить, когда забор достигает определенного значения.
Ознакомьтесь с методами интерфейса ID3D12Fence.
- GetCompletedValue: возвращает текущее значение забора.
- SetEventOnCompletion: вызывает событие, когда забор достигает заданного значения.
- Signal: задает забор заданному значению.
Заборы позволяют ЦП получить доступ к текущему значению ограждения, а ЦП ожидает и сигналов.
Метод Signal в интерфейсе ID3D12Fence обновляет ограждение с стороны ЦП. Это обновление происходит немедленно. Метод Signal на ID3D12CommandQueue обновляет ограждение с стороны GPU. Это обновление происходит после завершения всех других операций в очереди команд.
Все узлы в настройке с несколькими двигателями могут считывать и реагировать на любой забор, достигающий правильного значения.
Приложения задают свои собственные значения забора, хорошая отправная точка может увеличить забор один раз на кадр.
Забор можетперемотку. Это означает, что значение забора не требуется исключительно увеличиваться. Если операция Signal выполняется в двух разных очередях команд или если два потока ЦП вызывает Сигнал на заборе, может возникнуть гонка, чтобы определить, какой Сигнал завершается последним, и поэтому какое значение забора остается. Если забор перевернется, все новые ожидания (включая SetEventOnCompletion запросы) будут сравниваться с новым более низким значением забора, и поэтому может быть не удовлетворено, даже если значение забора ранее было достаточно высоким, чтобы удовлетворить их. Если гонка происходит, между значением, которое будет удовлетворять выдающееся ожидание, и меньшее значение, которое не будет, ожидание будет удовлетворено независимо от того, какое значение остается после этого.
API-интерфейсы ограждения предоставляют мощные функции синхронизации, но могут создавать потенциально трудные проблемы для отладки. Рекомендуется использовать каждый забор только для указания хода выполнения на одной временной шкале, чтобы предотвратить гонки между сигнализаторами.
Все три типа списка команд используют интерфейс ID3D12GraphicsCommandList, однако для копирования и вычислений поддерживается только подмножество методов.
Списки команд копирования и вычислений могут использовать следующие методы.
Списки команд вычислений также могут использовать следующие методы.
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- Отмена
- диспетчера
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
Списки команд вычислений должны задать вычислительный PSO при вызове SetPipelineState.
Пакеты нельзя использовать с списками или очередями команд вычислений или копирования.
В этом примере показано, как можно использовать синхронизацию ограждения для создания конвейера вычислительных работ в очереди (на которую ссылается pComputeQueue), которая используется графическими работами в очереди pGraphicsQueue. Операции вычислений и графики конвейерируются с помощью графической очереди, используюющей результат вычислений из нескольких кадров назад, и событие ЦП используется для регулирования общего объема рабочих очередей.
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
Для поддержки этой конвейерной обработки должен быть буфер ComputeGraphicsLatency+1 различных копий данных, передаваемых из очереди вычислений в графическую очередь. Списки команд должны использовать uav и косвенное использование для чтения и записи из соответствующей "версии" данных в буфере. Очередь вычислений должна ждать, пока графическая очередь не завершит чтение данных кадра N, прежде чем она сможет записать кадр N+ComputeGraphicsLatency.
Обратите внимание, что объем очереди вычислений, работающих относительно ЦП, не зависит напрямую от объема буферизации, необходимого, однако очередь GPU работает за пределами объема доступного буферного пространства менее ценно.
Альтернативным механизмом, чтобы избежать косвенного обращения, будет создавать несколько списков команд, соответствующих каждой из "переименованных" версий данных. В следующем примере используется этот метод, расширяя предыдущий пример, чтобы разрешить асинхронным запуску вычислительных и графических очередей.
Следующий пример позволяет графике асинхронно отображаться из очереди вычислений. Между двумя этапами по-прежнему существует фиксированный объем буферных данных, однако теперь графика работает независимо и использует наиболее up-to-date результат этапа вычислений, известный на ЦП при очереди графической работы. Это будет полезно, если графические работы обновляются другим источником, например входными данными пользователя. Необходимо иметь несколько списков команд, чтобы позволить ComputeGraphicsLatency кадрам графической работы одновременно выполняться, а функция UpdateGraphicsCommandList представляет обновление списка команд, чтобы включить самые последние входные данные и читать из вычислительных данных из соответствующего буфера.
Очередь вычислений по-прежнему должна ждать завершения очереди графики с буферами канала, но третий забор (pGraphicsComputeFence) представлен таким образом, чтобы ход выполнения вычислений графики работал и прогресс графики в целом можно отслеживать. Это отражает тот факт, что теперь последовательные графические кадры могут считываться из одного результата вычислений или пропускать результат вычислений. Более эффективный, но немного более сложный дизайн будет использовать только один графический забор и сохранить сопоставление с вычислительными кадрами, используемыми каждым графическим кадром.
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + CommandListIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
Чтобы получить доступ к ресурсу в нескольких очередях, приложение должно соответствовать следующим правилам.
Доступ к ресурсам (см. Direct3D 12_RESOURCE_STATES) определяется классом типа очереди, а не объектом очереди. Существует два класса типа очереди: очередь вычислений и трехмерного типа является одним классом типа, Copy — это второй класс типа. Таким образом, ресурс, имеющий барьер для состояния NON_PIXEL_SHADER_RESOURCE в одной трехмерной очереди, можно использовать в этом состоянии в любом трехмерном или вычислительном очереди, при условии требований к синхронизации, которые требуют сериализации большинства операций записи. Состояния ресурсов, совместно используемые между двумя классами типов (COPY_SOURCE и COPY_DEST), считаются различными состояниями для каждого класса типа. Таким образом, если ресурс переходит на COPY_DEST в очереди копирования, он недоступен в качестве назначения копирования из трехмерных или вычислительных очередей и наоборот.
Чтобы свести итоги.
- Очередь "object" — это любая отдельная очередь.
- Очередь "тип" — это любой из этих трех: вычислений, 3D и копирования.
- Класс типа очереди является одним из этих двух: Compute/3D и Copy.
Флаги COPY (COPY_DEST и COPY_SOURCE), используемые в качестве начальных состояний, представляют состояния в классе типа 3D/Compute. Чтобы изначально использовать ресурс в очереди копирования, он должен начинаться в состоянии COMMON. Общее состояние можно использовать для всех использования в очереди копирования с помощью неявных переходов состояния.
Несмотря на то, что состояние ресурса совместно используется во всех очередях вычислений и трехмерных очередей, не допускается одновременно записывать данные в ресурс в разных очередях. "Одновременно" здесь означает, что несинхронизировано, отметив, что несинхронизированное выполнение невозможно на некотором оборудовании. Применяются следующие правила.
- Одновременно может записывать только одну очередь в ресурс.
- Несколько очередей могут считывать из ресурса, пока они не считывают байты, изменяемые средством записи (чтение байтов, которые одновременно записываются, выдает неопределенные результаты).
- Забор должен использоваться для синхронизации после записи, прежде чем другая очередь может считывать записанные байты или делать любой доступ на запись.
Возвращаемые буферы должны находиться в состоянии 12_RESOURCE_STATE_COMMON Direct3D.
руководство по программированию Direct3D 12
Использование барьеров ресурсов для синхронизации состояний ресурсов в Direct3D 12
управление памятью в Direct3D 12