Så här distribuerar du Meta Llama 3.1-modeller med Azure AI Studio
Viktigt!
Vissa av de funktioner som beskrivs i den här artikeln kanske bara är tillgängliga i förhandsversionen. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
I den här artikeln får du lära dig mer om Meta Llama-modellfamiljen. Du får också lära dig hur du använder Azure AI Studio för att distribuera modeller från den här uppsättningen till serverlösa API:er med betala per användning-fakturering eller till hanterad beräkning.
Viktigt!
Läs mer om tillkännagivandet av Meta Llama 3.1 405B Instruct och andra Llama 3.1-modeller som är tillgängliga nu på Azure AI Model Catalog: Microsoft Tech Community Blog och från Meta Announcement Blog.
Nu tillgänglig på Azure AI Models-as-a-Service:
Meta-Llama-3.1-405B-InstructMeta-Llama-3.1-70B-InstructMeta-Llama-3.1-8B-Instruct
Meta Llama 3.1-serien med flerspråkiga stora språkmodeller (LLMs) är en samling förtränad och instruktionsanpassade generativa modeller i 8B-, 70B- och 405B-storlekar (text in/ut). Alla modeller stöder lång kontextlängd (128 000) och är optimerade för slutsatsdragning med stöd för grupperad fråge attention (GQA). Llama 3.1-instruktionen finjusterade endast textmodeller (8B, 70B, 405B) är optimerade för användningsfall för flerspråkig dialog och överträffar många av de tillgängliga chattmodellerna med öppen källkod på vanliga branschmått.
Se följande GitHub-exempel för att utforska integreringar med LangChain, LiteLLM, OpenAI och Azure API.
Distribuera Meta Llama 3.1 405B Instruera som ett serverlöst API
Meta Llama 3.1-modeller – till exempel Meta Llama 3.1 405B Instruct – kan distribueras som ett serverlöst API med betala per användning, vilket ger ett sätt att använda dem som ett API utan att vara värd för dem i din prenumeration samtidigt som företagets säkerhets- och efterlevnadsorganisationer behöver det. Det här distributionsalternativet kräver inte kvot från din prenumeration. Meta Llama 3.1-modeller distribueras som ett serverlöst API med betala per användning-fakturering via Microsoft Azure Marketplace, och de kan lägga till fler användningsvillkor och priser.
Azure Marketplace-modellerbjudanden
Följande modeller är tillgängliga på Azure Marketplace för Llama 3.1 och Llama 3 när de distribueras som en tjänst med betala per användning:
Om du behöver distribuera en annan modell distribuerar du den till hanterad beräkning i stället.
Förutsättningar
En Azure-prenumeration med en giltig betalningsmetod. Kostnadsfria azure-prenumerationer eller utvärderingsprenumerationer fungerar inte. Om du inte har en Azure-prenumeration skapar du ett betalt Azure-konto för att börja.
En AI Studio-hubb. Det serverlösa API-modelldistributionserbjudandet för Meta Llama 3.1 och Llama 3 är endast tillgängligt med hubbar som skapats i dessa regioner:
- East US
- USA, östra 2
- USA, norra centrala
- USA, södra centrala
- USA, västra
- USA, västra 3
- Sverige, centrala
En lista över regioner som är tillgängliga för var och en av modellerna som stöder serverlösa API-slutpunktsdistributioner finns i Regiontillgänglighet för modeller i serverlösa API-slutpunkter.
Ett AI Studio-projekt i Azure AI Studio.
Rollbaserade åtkomstkontroller i Azure (Azure RBAC) används för att bevilja åtkomst till åtgärder i Azure AI Studio. Om du vill utföra stegen i den här artikeln måste ditt användarkonto tilldelas rollen ägare eller deltagare för Azure-prenumerationen. Alternativt kan ditt konto tilldelas en anpassad roll som har följande behörigheter:
I Azure-prenumerationen – för att prenumerera på AI Studio-projektet till Azure Marketplace-erbjudandet, en gång för varje projekt, per erbjudande:
Microsoft.MarketplaceOrdering/agreements/offers/plans/readMicrosoft.MarketplaceOrdering/agreements/offers/plans/sign/actionMicrosoft.MarketplaceOrdering/offerTypes/publishers/offers/plans/agreements/readMicrosoft.Marketplace/offerTypes/publishers/offers/plans/agreements/readMicrosoft.SaaS/register/action
I resursgruppen – för att skapa och använda SaaS-resursen:
Microsoft.SaaS/resources/readMicrosoft.SaaS/resources/write
I AI Studio-projektet – för att distribuera slutpunkter (rollen Azure AI Developer innehåller redan dessa behörigheter):
Microsoft.MachineLearningServices/workspaces/marketplaceModelSubscriptions/*Microsoft.MachineLearningServices/workspaces/serverlessEndpoints/*
Mer information om behörigheter finns i Rollbaserad åtkomstkontroll i Azure AI Studio.
Skapa en ny distribution
Så här skapar du en distribution:
Logga in på Azure AI Studio.
Välj
Meta-Llama-3.1-405B-Instructdistribuera från Azure AI Studio-modellkatalogen.Du kan också initiera distributionen genom att starta projektet i AI Studio. Välj ett projekt och välj sedan Distributioner>+ Skapa.
På sidan Information för
Meta-Llama-3.1-405B-Instructväljer du Distribuera och sedan Serverlöst API med Azure AI Content Safety.Välj det projekt där du vill distribuera dina modeller. Om du vill använda distributionserbjudandet betala per användning måste din arbetsyta tillhöra regionen USA, östra 2 eller Sverige, centrala .
I distributionsguiden väljer du länken till Azure Marketplace-villkor för att lära dig mer om användningsvillkoren. Du kan också välja fliken Information om Marketplace-erbjudande för att lära dig mer om priser för den valda modellen.
Om det här är första gången du distribuerar modellen i projektet måste du prenumerera på ditt projekt för det specifika erbjudandet (till exempel
Meta-Llama-3.1-405B-Instruct) från Azure Marketplace. Det här steget kräver att ditt konto har behörigheter för Azure-prenumerationer och resursgruppsbehörigheter som anges i förhandskraven. Varje projekt har en egen prenumeration på det specifika Azure Marketplace-erbjudandet, vilket gör att du kan styra och övervaka utgifter. Välj Prenumerera och Distribuera.Kommentar
Att prenumerera ett projekt på ett visst Azure Marketplace-erbjudande (i det här fallet Meta-Llama-3-70B) kräver att ditt konto har deltagar- eller ägaråtkomst på prenumerationsnivå där projektet skapas. Alternativt kan ditt användarkonto tilldelas en anpassad roll som har behörigheter för Azure-prenumerationen och behörigheter för resursgrupper som anges i förhandskraven.
När du har registrerat projektet för det specifika Azure Marketplace-erbjudandet behöver efterföljande distributioner av samma erbjudande i samma projekt inte prenumerera igen. Därför behöver du inte ha behörigheter på prenumerationsnivå för efterföljande distributioner. Om det här scenariot gäller för dig väljer du Fortsätt att distribuera.
Ge distributionen ett namn. Det här namnet blir en del av URL:en för distributions-API:et. Den här URL:en måste vara unik i varje Azure-region.
Välj distribuera. Vänta tills distributionen är klar och du omdirigeras till sidan Distributioner.
Välj Öppna på lekplatsen för att börja interagera med modellen.
Du kan gå tillbaka till sidan Distributioner, välja distributionen och notera slutpunktens mål-URL och den hemliga nyckeln, som du kan använda för att anropa distributionen och generera slutföranden.
Du hittar alltid slutpunktens information, URL och åtkomstnycklar genom att gå till projektsidan och välja Distributioner på den vänstra menyn.
Mer information om fakturering för Meta Llama-modeller som distribueras med betala per användning finns i Kostnads- och kvotöverväganden för Llama 3-modeller som distribueras som en tjänst.




Använda Meta Llama-modeller som en tjänst
Modeller som distribueras som en tjänst kan användas med hjälp av antingen chatt- eller slutförande-API:et, beroende på vilken typ av modell du distribuerade.
Välj projektet eller hubben och välj sedan Distributioner på den vänstra menyn.
Leta upp och välj den
Meta-Llama-3.1-405B-Instructdistribution som du skapade.Välj Öppna på lekplatsen.
Välj Visa kod och kopiera slutpunkts-URL:en och nyckelvärdet.
Gör en API-begäran baserat på vilken typ av modell du distribuerade.
- För slutförandemodeller, till exempel
Meta-Llama-3-8B, använder du API:et/completions. - För chattmodeller, till exempel
Meta-Llama-3.1-405B-Instruct, använder du API:et/chat/completions.
Mer information om hur du använder API:erna finns i referensavsnittet.
- För slutförandemodeller, till exempel
Referens för Meta Llama 3.1-modeller som distribuerats som en tjänst
Llama-modeller accepterar både Azure AI Model Inference-API :et på vägen /chat/completions eller ett Llama Chat-API på /v1/chat/completions. På samma sätt kan textavslut genereras med hjälp av API:et för Azure AI-modellinferens på vägen /completions eller ett Llama Completions-API på/v1/completions
Schemat API för Azure AI Model Inference finns i artikeln referens för Chattslutföranden och en OpenAPI-specifikation kan hämtas från själva slutpunkten.
API för slutförande
Använd metoden POST för att skicka begäran till /v1/completions vägen:
Begär
POST /v1/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Schema för begäran
Payload är en JSON-formaterad sträng som innehåller följande parametrar:
| Nyckel | Typ | Standardvärde | beskrivning |
|---|---|---|---|
prompt |
string |
Ingen standard. Det här värdet måste anges. | Uppmaningen att skicka till modellen. |
stream |
boolean |
False |
Direktuppspelning gör att de genererade token kan skickas som databaserade serverutskickade händelser när de blir tillgängliga. |
max_tokens |
integer |
16 |
Det maximala antalet token som ska genereras i slutförandet. Tokenantalet för din fråga plus max_tokens får inte överskrida modellens kontextlängd. |
top_p |
float |
1 |
Ett alternativ till sampling med temperatur, som kallas kärnsampling, där modellen tar hänsyn till resultatet av tokens med top_p sannolikhetsmassa. Så 0,1 innebär att endast token som består av den översta 10 % sannolikhetsmassan beaktas. Vi rekommenderar vanligtvis att du top_p ändrar eller temperature, men inte båda. |
temperature |
float |
1 |
Provtagningstemperaturen som ska användas, mellan 0 och 2. Högre värden innebär att modellexemplen i större utsträckning distribuerar token. Noll betyder girig sampling. Vi rekommenderar att du ändrar detta eller top_p, men inte båda. |
n |
integer |
1 |
Hur många slutföranden som ska genereras för varje fråga. Obs! Eftersom den här parametern genererar många slutföranden kan den snabbt förbruka din tokenkvot. |
stop |
array |
null |
Sträng eller en lista med strängar som innehåller ordet där API:et slutar generera ytterligare token. Den returnerade texten innehåller inte stoppsekvensen. |
best_of |
integer |
1 |
Genererar best_of slutföranden på serversidan och returnerar den "bästa" (den med den lägsta loggens sannolikhet per token). Resultat kan inte strömmas. När det används med nkontrollerar du antalet kandidatavslut och n anger hur många som ska returneras–best_of måste vara större än nbest_of . Obs! Eftersom den här parametern genererar många slutföranden kan den snabbt förbruka din tokenkvot. |
logprobs |
integer |
null |
Ett tal som anger att loggens sannolikheter ska inkluderas på de logprobs mest sannolika token och valda token. Om logprobs det till exempel är 10 returnerar API:et en lista över de 10 mest sannolika token. API:et returnerar alltid logprob för den samplade token, så det kan finnas upp till logprobs+1 element i svaret. |
presence_penalty |
float |
null |
Tal mellan -2.0 och 2.0. Positiva värden straffar nya token baserat på om de visas i texten hittills, vilket ökar modellens sannolikhet att prata om nya ämnen. |
ignore_eos |
boolean |
True |
Om du vill ignorera EOS-token och fortsätta generera token när EOS-token har genererats. |
use_beam_search |
boolean |
False |
Om du vill använda strålsökning i stället för sampling. I sådana fall best_of måste vara större än 1 och temperature måste vara 0. |
stop_token_ids |
array |
null |
Lista över ID:er för token som, när de genereras, stoppar ytterligare tokengenerering. De returnerade utdata innehåller stopptoken såvida inte stopptoken är särskilda token. |
skip_special_tokens |
boolean |
null |
Om du vill hoppa över särskilda token i utdata. |
Exempel
Brödtext
{
"prompt": "What's the distance to the moon?",
"temperature": 0.8,
"max_tokens": 512
}
Svarsschema
Svarsnyttolasten är en ordlista med följande fält.
| Nyckel | Typ | Beskrivning |
|---|---|---|
id |
string |
En unik identifierare för slutförandet. |
choices |
array |
Listan över slutförandeval som modellen genererade för indataprompten. |
created |
integer |
Unix-tidsstämpeln (i sekunder) för när slutförandet skapades. |
model |
string |
Den model_id som används för slutförande. |
object |
string |
Objekttypen, som alltid text_completionär . |
usage |
object |
Användningsstatistik för slutförandebegäran. |
Dricks
I strömningsläget är för varje segment av svar finish_reason alltid null, förutom från den sista som avslutas med en nyttolast [DONE].
Objektet choices är en ordlista med följande fält.
| Nyckel | Typ | Beskrivning |
|---|---|---|
index |
integer |
Valindex. När best_of> 1 kanske indexet i den här matrisen inte är i ordning och kanske inte är 0 till n-1. |
text |
string |
Resultat av slutförande. |
finish_reason |
string |
Anledningen till att modellen slutade generera token: - stop: modellen träffade en naturlig stopppunkt eller en angivet stoppsekvens. - length: om maximalt antal token har nåtts. - content_filter: När RAI modereras och CMP tvingar moderering. - content_filter_error: ett fel under modereringen och kunde inte fatta beslut om svaret. - null: API-svaret pågår fortfarande eller är ofullständigt. |
logprobs |
object |
Loggannolikorna för de genererade token i utdatatexten. |
Objektet usage är en ordlista med följande fält.
| Nyckel | Type | Värde |
|---|---|---|
prompt_tokens |
integer |
Antal token i prompten. |
completion_tokens |
integer |
Antal token som genererats i slutförandet. |
total_tokens |
integer |
Totalt antal token. |
Objektet logprobs är en ordlista med följande fält:
| Nyckel | Type | Värde |
|---|---|---|
text_offsets |
array av integers |
Positionen eller indexet för varje token i slutförandeutdata. |
token_logprobs |
array av float |
Markerad logprobs från ordlistan i top_logprobs matrisen. |
tokens |
array av string |
Valda token. |
top_logprobs |
array av dictionary |
Matris med ordlista. I varje ordlista är nyckeln token och värdet är prob. |
Exempel
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "text_completion",
"created": 217877,
"choices": [
{
"index": 0,
"text": "The Moon is an average of 238,855 miles away from Earth, which is about 30 Earths away.",
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 7,
"total_tokens": 23,
"completion_tokens": 16
}
}
Chatt-API
Använd metoden POST för att skicka begäran till /v1/chat/completions vägen:
Begär
POST /v1/chat/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Schema för begäran
Payload är en JSON-formaterad sträng som innehåller följande parametrar:
| Nyckel | Typ | Standardvärde | beskrivning |
|---|---|---|---|
messages |
string |
Ingen standard. Det här värdet måste anges. | Meddelandet eller historiken för meddelanden som ska användas för att fråga modellen. |
stream |
boolean |
False |
Direktuppspelning gör att de genererade token kan skickas som databaserade serverutskickade händelser när de blir tillgängliga. |
max_tokens |
integer |
16 |
Det maximala antalet token som ska genereras i slutförandet. Tokenantalet för din fråga plus max_tokens får inte överskrida modellens kontextlängd. |
top_p |
float |
1 |
Ett alternativ till sampling med temperatur, som kallas kärnsampling, där modellen tar hänsyn till resultatet av tokens med top_p sannolikhetsmassa. Så 0,1 innebär att endast token som består av den översta 10 % sannolikhetsmassan beaktas. Vi rekommenderar vanligtvis att du top_p ändrar eller temperature, men inte båda. |
temperature |
float |
1 |
Provtagningstemperaturen som ska användas, mellan 0 och 2. Högre värden innebär att modellexemplen i större utsträckning distribuerar token. Noll betyder girig sampling. Vi rekommenderar att du ändrar detta eller top_p, men inte båda. |
n |
integer |
1 |
Hur många slutföranden som ska genereras för varje fråga. Obs! Eftersom den här parametern genererar många slutföranden kan den snabbt förbruka din tokenkvot. |
stop |
array |
null |
Sträng eller en lista med strängar som innehåller ordet där API:et slutar generera ytterligare token. Den returnerade texten innehåller inte stoppsekvensen. |
best_of |
integer |
1 |
Genererar best_of slutföranden på serversidan och returnerar den "bästa" (den med den lägsta loggens sannolikhet per token). Resultat kan inte strömmas. När det används med nkontrollerar du antalet kandidatavslut och n anger hur många som ska returneras–best_of måste vara större än nbest_of . Obs! Eftersom den här parametern genererar många slutföranden kan den snabbt förbruka din tokenkvot. |
logprobs |
integer |
null |
Ett tal som anger att loggens sannolikheter ska inkluderas på de logprobs mest sannolika token och valda token. Om logprobs det till exempel är 10 returnerar API:et en lista över de 10 mest sannolika token. API:et returnerar alltid logprob för den samplade token, så det kan finnas upp till logprobs+1 element i svaret. |
presence_penalty |
float |
null |
Tal mellan -2.0 och 2.0. Positiva värden straffar nya token baserat på om de visas i texten hittills, vilket ökar modellens sannolikhet att prata om nya ämnen. |
ignore_eos |
boolean |
True |
Om du vill ignorera EOS-token och fortsätta generera token när EOS-token har genererats. |
use_beam_search |
boolean |
False |
Om du vill använda strålsökning i stället för sampling. I sådana fall best_of måste vara större än 1 och temperature måste vara 0. |
stop_token_ids |
array |
null |
Lista över ID:er för token som, när de genereras, stoppar ytterligare tokengenerering. De returnerade utdata innehåller stopptoken såvida inte stopptoken är särskilda token. |
skip_special_tokens |
boolean |
null |
Om du vill hoppa över särskilda token i utdata. |
Objektet messages har följande fält:
| Nyckel | Type | Värde |
|---|---|---|
content |
string |
Innehållet i meddelandet. Innehåll krävs för alla meddelanden. |
role |
string |
Rollen som meddelandets författare. En av system, usereller assistant. |
Exempel
Brödtext
{
"messages":
[
{
"role": "system",
"content": "You are a helpful assistant that translates English to Italian."},
{
"role": "user",
"content": "Translate the following sentence from English to Italian: I love programming."
}
],
"temperature": 0.8,
"max_tokens": 512,
}
Svarsschema
Svarsnyttolasten är en ordlista med följande fält.
| Nyckel | Typ | Beskrivning |
|---|---|---|
id |
string |
En unik identifierare för slutförandet. |
choices |
array |
Listan över slutförandeval som modellen genererade för indatameddelandena. |
created |
integer |
Unix-tidsstämpeln (i sekunder) för när slutförandet skapades. |
model |
string |
Den model_id som används för slutförande. |
object |
string |
Objekttypen, som alltid chat.completionär . |
usage |
object |
Användningsstatistik för slutförandebegäran. |
Dricks
I strömningsläget är för varje segment av svar finish_reason alltid null, förutom från den sista som avslutas med en nyttolast [DONE]. I varje choices objekt ändras nyckeln för messages av delta.
Objektet choices är en ordlista med följande fält.
| Nyckel | Typ | Beskrivning |
|---|---|---|
index |
integer |
Valindex. När best_of> 1 kanske indexet i den här matrisen inte är i ordning och kanske inte är 0 till n-1. |
messages eller delta |
string |
Chattens slutförande resulterar i messages objekt. När strömningsläget används delta används nyckeln. |
finish_reason |
string |
Anledningen till att modellen slutade generera token: - stop: modellen träffade en naturlig stopppunkt eller en angivet stoppsekvens. - length: om maximalt antal token har nåtts. - content_filter: När RAI modereras och CMP tvingar moderering - content_filter_error: ett fel under modereringen och kunde inte fatta beslut om svaret - null: API-svaret pågår fortfarande eller är ofullständigt. |
logprobs |
object |
Loggannolikorna för de genererade token i utdatatexten. |
Objektet usage är en ordlista med följande fält.
| Nyckel | Type | Värde |
|---|---|---|
prompt_tokens |
integer |
Antal token i prompten. |
completion_tokens |
integer |
Antal token som genererats i slutförandet. |
total_tokens |
integer |
Totalt antal token. |
Objektet logprobs är en ordlista med följande fält:
| Nyckel | Type | Värde |
|---|---|---|
text_offsets |
array av integers |
Positionen eller indexet för varje token i slutförandeutdata. |
token_logprobs |
array av float |
Markerad logprobs från ordlistan i top_logprobs matrisen. |
tokens |
array av string |
Valda token. |
top_logprobs |
array av dictionary |
Matris med ordlista. I varje ordlista är nyckeln token och värdet är prob. |
Exempel
Nedan finns ett exempel på svar:
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "chat.completion",
"created": 2012359,
"model": "",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "Sure, I\'d be happy to help! The translation of ""I love programming"" from English to Italian is:\n\n""Amo la programmazione.""\n\nHere\'s a breakdown of the translation:\n\n* ""I love"" in English becomes ""Amo"" in Italian.\n* ""programming"" in English becomes ""la programmazione"" in Italian.\n\nI hope that helps! Let me know if you have any other sentences you\'d like me to translate."
}
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 40,
"completion_tokens": 30
}
}
Distribuera Meta Llama-modeller till hanterad beräkning
Förutom att distribuera med den hanterade tjänsten betala per användning kan du även distribuera Meta Llama 3.1-modeller till hanterad beräkning i AI Studio. När du distribueras till hanterad beräkning kan du välja all information om infrastrukturen som kör modellen, inklusive de virtuella datorer som ska användas och antalet instanser för att hantera den belastning du förväntar dig. Modeller som distribueras till hanterad beräkning förbrukar kvoter från din prenumeration. Följande modeller från 3.1-versionsvågen är tillgängliga för hanterad beräkning:
Meta-Llama-3.1-8B-Instruct(FT stöds)Meta-Llama-3.1-70B-Instruct(FT stöds)Meta-Llama-3.1-8B(FT stöds)Meta-Llama-3.1-70B(FT stöds)Llama Guard 3 8BPrompt Guard
Följ de här stegen för att distribuera en modell som Meta-Llama-3.1-70B-Instruct till en hanterad beräkning i Azure AI Studio.
Välj den modell som du vill distribuera från Azure AI Studio-modellkatalogen.
Du kan också initiera distributionen genom att starta projektet i AI Studio. Välj projektet och välj sedan Distributioner>+ Skapa.
På sidan Information för modellen väljer du Distribuera bredvid knappen Visa licens.
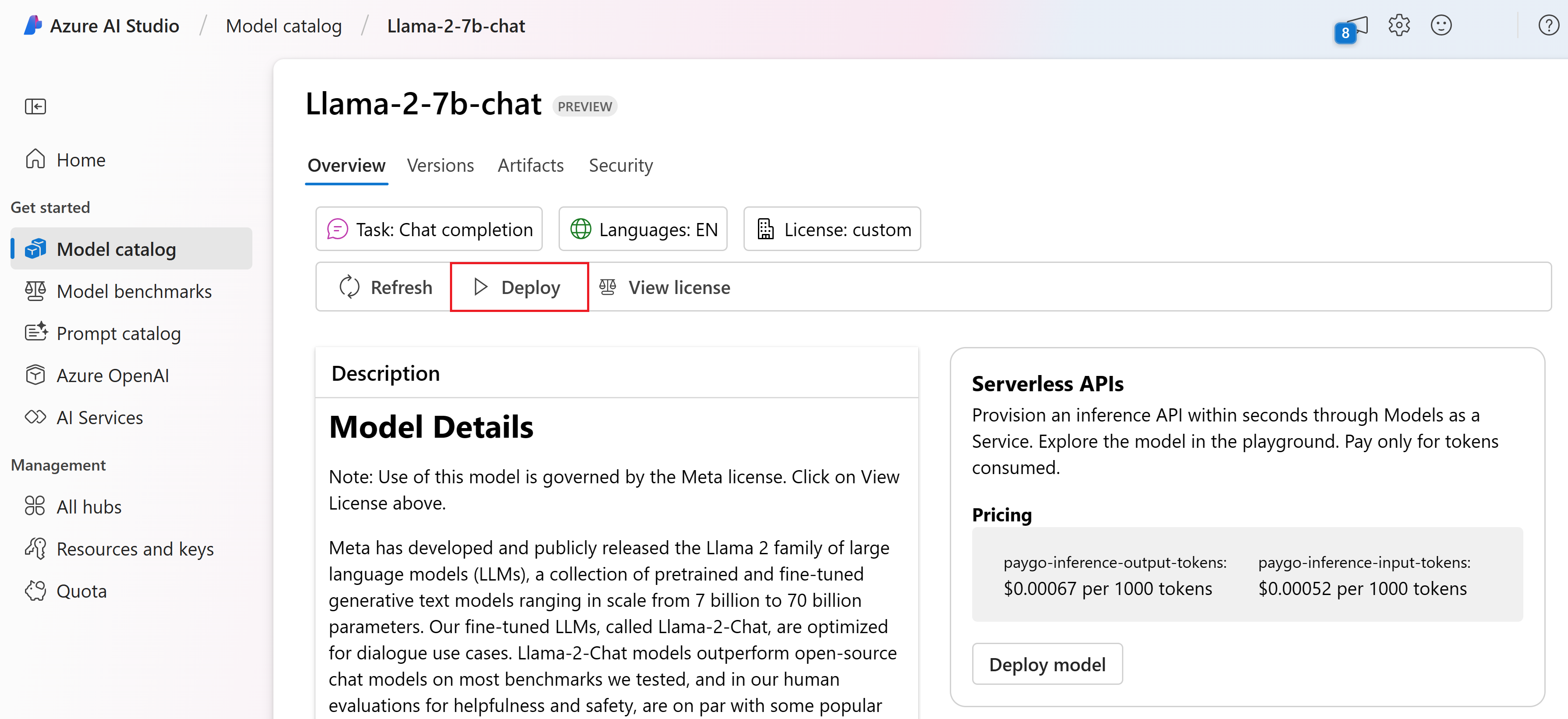
På sidan Distribuera med Azure AI Content Safety (förhandsversion) väljer du Hoppa över Azure AI Content Safety så att du kan fortsätta att distribuera modellen med hjälp av användargränssnittet.
Dricks
I allmänhet rekommenderar vi att du väljer Aktivera Azure AI Content Safety (rekommenderas) för distribution av Llama-modellen. Det här distributionsalternativet stöds för närvarande endast med Python SDK och det sker i en notebook-fil.
Välj Fortsätt.
Välj det projekt där du vill skapa en distribution.
Dricks
Om du inte har tillräckligt med kvot i det valda projektet kan du använda alternativet Jag vill använda delad kvot och jag bekräftar att slutpunkten tas bort om 168 timmar.
Välj den virtuella datorn och antalet instanser som du vill tilldela distributionen.
Välj om du vill skapa den här distributionen som en del av en ny slutpunkt eller en befintlig. Slutpunkter kan vara värdar för flera distributioner samtidigt som resurskonfigurationen är exklusiv för var och en av dem. Distributioner under samma slutpunkt delar slutpunkts-URI:n och dess åtkomstnycklar.
Ange om du vill aktivera insamling av slutsatsdragningsdata (förhandsversion).
Välj distribuera. Efter en liten stund öppnas slutpunktens informationssida.
Vänta tills slutpunkten har skapats och distributionen har slutförts. Det här steget kan ta några minuter.
Välj fliken Förbruka i distributionen för att hämta kodexempel som kan användas för att använda den distribuerade modellen i ditt program.

Använda Llama 2-modeller som distribuerats till hanterad beräkning
Referens om hur du anropar Llama-modeller som distribuerats till hanterad beräkning finns i modellens kort i Azure AI Studio-modellkatalogen. Varje modells kort har en översiktssida som innehåller en beskrivning av modellen, exempel för kodbaserad slutsatsdragning, finjustering och modellutvärdering.
Fler slutsatsdragningsexempel
| Paket | Exempelnotebook |
|---|---|
| CLI med curl- och Python-webbbegäranden | webrequests.ipynb |
| OpenAI SDK (experimentell) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| LiteLLM SDK | litellm.ipynb |
Kostnad och kvoter
Kostnads- och kvotöverväganden för Meta Llama 3.1-modeller som distribueras som en tjänst
Meta Llama 3.1-modeller som distribueras som en tjänst erbjuds av Meta via Azure Marketplace och integreras med Azure AI Studio för användning. Du hittar prissättningen för Azure Marketplace när du distribuerar eller finjusterar modellerna.
Varje gång ett projekt prenumererar på ett visst erbjudande från Azure Marketplace skapas en ny resurs för att spåra de kostnader som är kopplade till förbrukningen. Samma resurs används för att spåra kostnader som är kopplade till slutsatsdragning och finjustering. Flera mätare är dock tillgängliga för att spåra varje scenario oberoende av varandra.
Mer information om hur du spårar kostnader finns i Övervaka kostnader för modeller som erbjuds i hela Azure Marketplace.

Kvot hanteras per distribution. Varje distribution har en hastighetsgräns på 400 000 token per minut och 1 000 API-begäranden per minut. För närvarande begränsar vi dock en distribution per modell per projekt. Kontakta Microsoft Azure Support om de aktuella hastighetsgränserna inte räcker för dina scenarier.
Kostnads- och kvotöverväganden för Meta Llama 3.1-modeller som distribueras som hanterad beräkning
För distribution och slutsatsdragning av Meta Llama 3.1-modeller med hanterad beräkning använder du kärnkvoten för virtuella datorer (VM) som är tilldelad till din prenumeration per region. När du registrerar dig för Azure AI Studio får du en standard VM-kvot för flera VM-familjer som är tillgängliga i regionen. Du kan fortsätta att skapa distributioner tills du når din kvotgräns. När du når den här gränsen kan du begära en kvotökning.
Innehållsfiltrering
Modeller som distribueras som ett serverlöst API med betala per användning skyddas av Azure AI Content Safety. När du distribueras till hanterad beräkning kan du välja bort den här funktionen. Med Azure AI-innehållssäkerhet aktiverat passerar både prompten och slutförandet genom en uppsättning klassificeringsmodeller som syftar till att identifiera och förhindra utdata från skadligt innehåll. Systemet för innehållsfiltrering identifierar och vidtar åtgärder för specifika kategorier av potentiellt skadligt innehåll i både inkommande prompter och slutföranden av utdata. Läs mer om Azure AI Content Safety.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för