Hadoop-migrering till Azure
Apache Hadoop tillhandahåller ett distribuerat filsystem och ett ramverk för att använda MapReduce-tekniker för att analysera och transformera mycket stora datamängder. En viktig egenskap hos Hadoop är partitionering av data och beräkning över många (tusentals) värdar. Beräkningar görs parallellt nära data. Ett Hadoop-kluster skalar beräkningskapacitet, lagringskapacitet och I/O-bandbredd helt enkelt genom att lägga till maskinvara för råvaror.
Den här artikeln är en översikt över migrering av Hadoop till Azure. De andra artiklarna i det här avsnittet innehåller migreringsvägledning för specifika Hadoop-komponenter. Dessa är:
- Apache HDFS-migrering till Azure
- Apache HBase-migrering till Azure
- Apache Kafka-migrering till Azure
- Apache Sqoop-migrering till Azure
Hadoop tillhandahåller ett omfattande ekosystem med tjänster och ramverk. De här artiklarna beskriver inte Hadoop-komponenterna och Azure-implementeringarna i detalj. I stället ger de vägledning och överväganden på hög nivå för att fungera som utgångspunkt för att migrera dina lokala och molnbaserade Hadoop-program till Azure.
Apache, Apache Spark®, Apache Hadoop®, Apache HBase, Apache Hive, Apache Ranger®, Apache Sentry®, Apache ZooKeeper®, Apache Storm®, Apache Sqoop®, Apache Flink®, Apache Kafka® och flamlogotypen är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i USA och/eller andra länder.® Inget godkännande från Apache Software Foundation underförstås av användningen av dessa märken.
De viktigaste komponenterna i ett Hadoop-system visas i följande tabell. För varje komponent finns en kort beskrivning och migreringsinformation som:
- Länkar till beslutsflödesscheman för beslut om migreringsstrategier
- En lista över möjliga Azure-måltjänster
| Komponent | beskrivning | Beslutsflödesscheman | Riktade Azure-tjänster |
|---|---|---|---|
| Apache HDFS | Distribuerat filsystem | Planera datamigreringen, förkontrollera före datamigrering | Azure Data Lake Storage |
| Apache HBase | Kolumnorienterad tabelltjänst | Välja landningsmål för Apache HBase, välja lagring för Apache HBase i Azure | HBase på en virtuell dator (VM), HBase i Azure HDInsight, Azure Cosmos DB |
| Apache Spark | Ramverk för databehandling | Välja landningsmål för Apache Spark i Azure | Spark i HDInsight, Azure Synapse Analytics, Azure Databricks |
| Apache Hive | Infrastruktur för informationslager | Välja landningsmål för Hive, Välja måldatabas för Hive-metadata | Hive på en virtuell dator, Hive i HDInsight, Azure Synapse Analytics |
| Apache Ranger | Ramverk för övervakning och hantering av datasäkerhet | Enterprise Security Package för HDInsight, Microsoft Entra ID, Ranger på en virtuell dator | |
| Apache Sentry | Ramverk för övervakning och hantering av datasäkerhet | Välja landningsmål för Apache Sentry i Azure | Sentry och Ranger på en virtuell dator, Enterprise Security Package för HDInsight, Microsoft Entra ID |
| Apache MapReduce | Ramverk för distribuerad beräkning | MapReduce, Spark | |
| Apache Zookeeper | Distribuerad samordningstjänst | ZooKeeper på en virtuell dator, inbyggd lösning i PaaS (Plattform som en tjänst) | |
| Apache YARN | Resource Manager för Hadoop-ekosystemet | YARN på en virtuell dator, inbyggd lösning i PaaS | |
| Apache Sqoop | Kommandoradsgränssnittsverktyg för överföring av data mellan Apache Hadoop-kluster och relationsdatabaser | Välja landningsmål för Apache Sqoop i Azure | Sqoop på en virtuell dator, Sqoop i HDInsight, Azure Data Factory |
| Apache Kafka | Mycket skalbart feltolerant distribuerat meddelandesystem | Välja landningsmål för Apache Kafka i Azure | Kafka på en virtuell dator, Event Hubs för Kafka, Kafka på HDInsight |
| Apache Atlas | Ramverk med öppen källkod för datastyrning och metadatahantering | Azure Purview |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
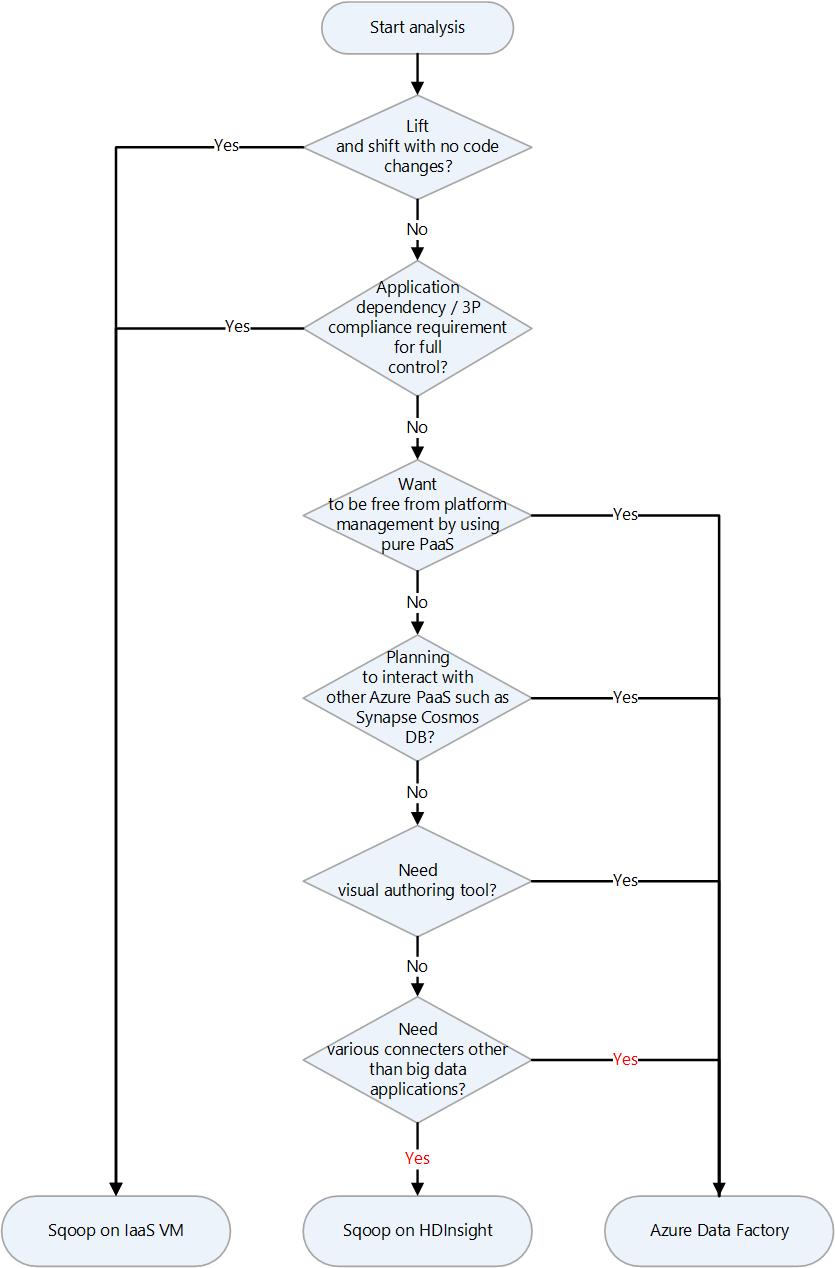{kind=link}
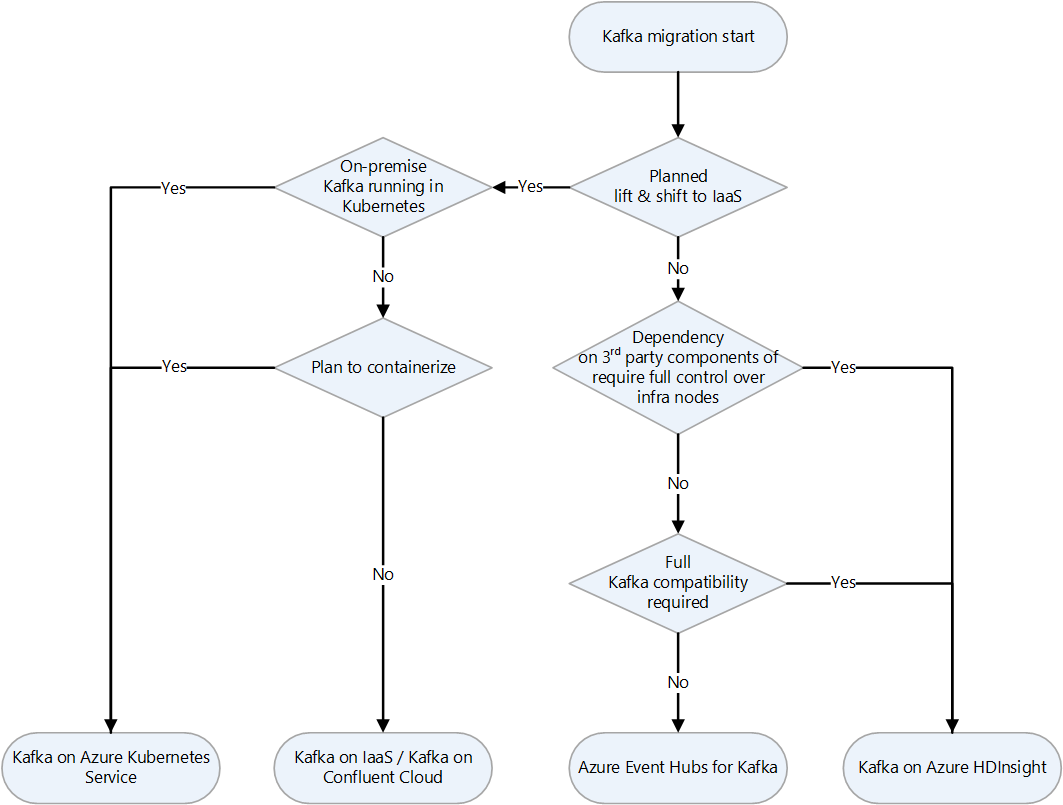{kind=link}
Följande diagram visar tre metoder för att migrera Hadoop-program:

Ladda ned en Visio-fil med den här arkitekturen.
Metoderna är:
- Omplatform med hjälp av Azure PaaS: Mer information finns i Modernisera med hjälp av Azure Synapse Analytics och Databricks.
- Lyft och flytta till HDInsight: Mer information finns i Lift and shift to HDInsight (Lift and shift to HDInsight).
- Lift and shift to IaaS(Lift and shift to IaaS): Mer information finns i Lift and shift to Azure infrastructure as a service (IaaS).
Följande diagram visar den här metoden:

Ladda ned en Visio-fil med den här arkitekturen.
Följande diagram visar den här metoden:

Ladda ned en Visio-fil med den här arkitekturen.
Mer information finns i Migrera lokala Apache Hadoop-kluster till Azure HDInsight.
Följande mönster visar en synpunkt på hur du distribuerar OSS på Azure IaaS med en nära integrering tillbaka till lokala system som Active Directory, Domänkontrollant och DNS. Distributionen följer vägledningen för landningszoner i företagsskala från Microsoft. Hanteringsfunktioner som övervakning, säkerhet, styrning och nätverk finns i en hanteringsprenumeration. Arbetsbelastningarna, alla IaaS-baserade, finns i en separat prenumeration. Mer information om landningszoner i företagsskala finns i Vad är en Azure-landningszon?.

Ladda ned en Visio-fil med den här arkitekturen.
- Lokal Active Directory synkroniseras med Microsoft Entra-ID med hjälp av Microsoft Entra Connect lokalt.
- Azure ExpressRoute ger säker och privat nätverksanslutning mellan lokalt och Azure.
- Hanteringsprenumerationen (eller hubben) tillhandahåller nätverks- och hanteringsfunktioner för distributionen. Det här mönstret är i linje med vägledningen för landningszoner i företagsskala från Microsoft.
- Tjänsterna som finns i hubbprenumerationen tillhandahåller nätverksanslutnings- och hanteringsfunktioner.
- NTP (finns på en virtuell Azure-dator) krävs för att hålla klockorna synkroniserade över alla virtuella datorer. När du kör flera program, till exempel HBase och ZooKeeper, bör du köra en NTP-tjänst (Network Time Protocol) eller en annan mekanism för tidssynkronisering i klustret. Alla noder bör använda samma tjänst för tidssynkronisering. Anvisningar om hur du konfigurerar NTP i Linux finns i 14.6. Grundläggande NTP-konfiguration.
- Azure Network Watcher innehåller verktyg för att övervaka, diagnostisera och hantera resurser i ett virtuellt Azure-nätverk. Network Watcher är utformat för att övervaka och reparera nätverkshälsan för IaaS-produkter, inklusive virtuella datorer, virtuella nätverk, programgatewayer och lastbalanserare.
- Azure Advisor analyserar din resurskonfiguration och användningstelemetri och rekommenderar sedan lösningar för att förbättra kostnadseffektiviteten, prestandan, tillförlitligheten och säkerheten för dina Azure-resurser.
- Azure Monitor tillhandahåller en omfattande lösning för att samla in, analysera och agera på telemetri från dina molnmiljöer och lokala miljöer. Det hjälper dig att förstå hur dina program fungerar så att du proaktivt kan identifiera problem som påverkar programmen och de resurser de är beroende av.
- Log Analytics-arbetsytan är en unik miljö för Azure Monitor-loggdata. Varje arbetsyta har sitt eget datalager och sin egen konfiguration. Datakällor och lösningar konfigureras för att lagra sina data på en viss arbetsyta. Du behöver en Log Analytics-arbetsyta om du tänker samla in data från följande källor:
- Azure-resurser i din prenumeration
- Lokala datorer som övervakas av System Center Operations Manager
- Enhetssamlingar från System Center Configuration Manager
- Diagnostik eller loggdata från Azure Storage
- Azure DevOps Lokalt installerad agent som finns på Azure Virtual Machine Scale Sets ger dig flexibilitet över storleken och avbildningen av datorer där agenter körs. Du anger en VM-skalningsuppsättning, ett antal agenter som ska behållas i vänteläge, ett maximalt antal virtuella datorer i skalningsuppsättningen. Azure Pipelines hanterar skalningen av dina agenter åt dig.
- Microsoft Entra ID-klientorganisationen synkroniseras med lokalni Active Directory via Microsoft Entra Connect-synkroniseringstjänster. Mer information finns i Microsoft Entra Connect Sync: Förstå och anpassa synkronisering.
- Microsoft Entra Domain Services (Microsoft Entra Domain Services) tillhandahåller LDAP- och Kerberos-funktioner i Azure. När du först distribuerar Microsoft Entra Domain Services konfigureras och startas en automatisk enkelriktad synkronisering för att replikera objekten från Microsoft Entra-ID. Den här envägssynkroniseringen fortsätter att köras i bakgrunden så att den hanterade Microsoft Entra Domain Services-domänen hålls uppdaterad med eventuella ändringar från Microsoft Entra ID. Det sker inte någon synkronisering från Microsoft Entra Domain Services tillbaka till Microsoft Entra ID.
- Tjänster som Azure DNS, Microsoft Defender för molnet och Azure Key Vault finns i hanteringsprenumerationen och tillhandahåller lösning av tjänst-/IP-adresser, enhetlig infrastruktursäkerhetshantering respektive funktioner för certifikat- respektive nyckelhantering.
- Peering för virtuella nätverk ger anslutning mellan virtuella nätverk som distribuerats i två prenumerationer: hantering (hubb) och arbetsbelastning (eker).
- I linje med landningszoner i företagsskala används arbetsbelastningsprenumerationer som värd för programarbetsbelastningar.
- Azure Data Lake Storage är en uppsättning funktioner som bygger på Azure Blob Storage för stordataanalys. I samband med stordataarbetsbelastningar kan Data Lake Storage användas som sekundär lagring för Hadoop. Data som skrivs till Data Lake Storage kan användas av andra Azure-tjänster som ligger utanför Hadoop-ramverket.
- Stordataarbetsbelastningar finns på en uppsättning oberoende virtuella Azure-datorer. Mer information finns i vägledningen för HDFS, HBase, Hive, Ranger och Spark i Azure IaaS.
- Azure DevOps är ett SaaS-erbjudande (software as a service) som tillhandahåller en integrerad uppsättning tjänster och verktyg för att hantera dina programvaruprojekt, från planering och utveckling till testning och distribution.
En av utmaningarna med att migrera arbetsbelastningar från lokala Hadoop till Azure är att distribuera för att uppnå önskad sluttillståndsarkitektur och -program. Projektet som beskrivs i Hadoop Migration på Azure PaaS är avsett att minska den betydande ansträngning som vanligtvis krävs för att distribuera PaaS-tjänsterna och programmet.
I det projektet tittar vi på sluttillståndsarkitekturen för stordataarbetsbelastningar i Azure och listar de komponenter som används i en Bicep-malldistribution. Med Bicep distribuerar vi bara de moduler som vi behöver för att distribuera arkitekturen. Vi tar upp förutsättningarna för mallen och de olika metoderna för att distribuera resurserna i Azure, till exempel One-click, Azure CLI, GitHub Actions och Azure DevOps Pipeline.
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Namrata Maheshwary | Senior Cloud Solution Architect
- Raja N | Direktör, kundframgång
- Hideo Takagi | Molnlösningsarkitekt
- Ram Yerrabotu | Senior Cloud Solution Architect
Övriga medarbetare:
- Ram Baskaran | Senior Cloud Solution Architect
- Jason Bouska | Senior programvarutekniker
- Eugene Chung | Senior Cloud Solution Architect
- Pawan Hosatti | Senior Cloud Solution Architect – Teknik
- Daman Kaur | Molnlösningsarkitekt
- Danny Liu | Senior Cloud Solution Architect – Teknik
- Jose Mendez Senior Cloud Solution Architect
- Ben Sadeghi | Senior Specialist
- Sunil Sattiraju | Senior Cloud Solution Architect
- Amanjeet Singh | Programhanteraren för huvudnamn
- Nagaraj Seeplapudur Venkatesan | Senior Cloud Solution Architect – Teknik
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
- Introduktion till Azure Data Lake Storage Gen2
- Vad är Apache Spark i Azure HDInsight?
- Vad är Apache Hadoop i Azure HDInsight?
- Vad är Apache HBase i Azure HDInsight?
- Vad är Apache Kafka i Azure HDInsight?
- Översikt över företagssäkerhet i Azure HDInsight
- Microsoft Entra-dokumentation.
- Dokumentation om Azure Cosmos DB
- Dokumentation om Azure Data Factory
- Dokumentation om Azure Databricks
- Dokumentation om Azure Event Hubs
- Azure Functions-dokumentation
- Dokumentation om Azure HDInsight
- Dokumentation om Datastyrning i Microsoft Purview
- Dokumentation om Azure Stream Analytics
- Azure Synapse Analytics