Apache Sqoop är ett verktyg för att överföra data mellan Apache Hadoop-kluster och relationsdatabaser. Den har ett kommandoradsgränssnitt.
Du kan använda Sqoop för att importera data till HDFS från relationsdatabaser som MySQL, PostgreSQL, Oracle och SQL Server och exportera HDFS-data till sådana databaser. Sqoop kan använda MapReduce och Apache Hive för att konvertera data på Hadoop. Avancerade funktioner omfattar inkrementell inläsning, formatering med hjälp av SQL och uppdatering av datauppsättningar. Sqoop fungerar parallellt för att uppnå dataöverföring med hög hastighet.
Kommentar
Sqoop-projektet har dragits tillbaka. Sqoop flyttades till Apache Attic i juni 2021. Webbplatsen, nedladdningar och problemspåraren förblir öppna. Mer information finns i Apache Sqoop på Apache Attic .
Apache, Apache Spark®, Apache Hadoop®, Apache HBase, Apache Hive, Apache Ranger®, Apache Storm®, Apache Sqoop®, Apache Kafka® och flame-logotypen är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i USA och/eller andra länder.® Inget godkännande från Apache Software Foundation underförstås av användningen av dessa märken.
Sqoop-arkitektur och -komponenter
Det finns två versioner av Sqoop: Sqoop1 och Sqoop2. Sqoop1 är ett enkelt klientverktyg, medan Sqoop2 har en klient-/serverarkitektur. De är inte kompatibla med varandra och de skiljer sig åt i användningen. Sqoop2 är inte komplett och är inte avsett för produktionsdistribution.
Sqoop1-arkitektur
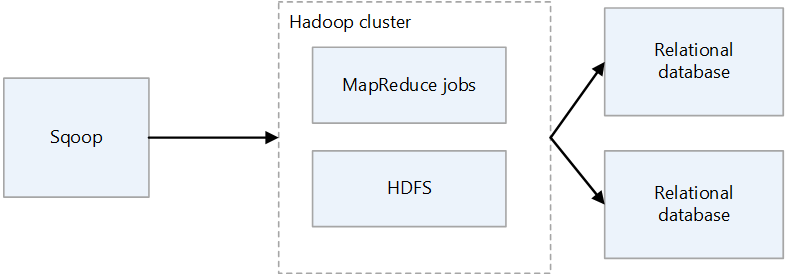
Importera och exportera Sqoop1
Importera
Läser data från relationsdatabaser och matar ut data till HDFS. Varje post i relationsdatabastabellen matas ut som en enskild rad i HDFS. Text, SequenceFiles och Avro är de filformat som kan skrivas till HDFS.
Exporteraera
Läser data från HDFS och överför dem till relationsdatabaser. Målrelationsdatabaserna stöder både infogning och uppdatering.
Sqoop2-arkitektur
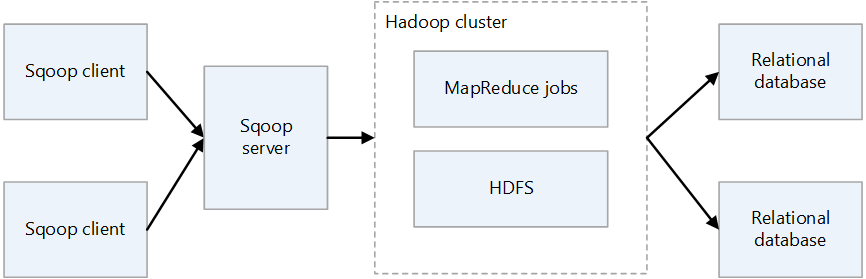
Sqoop-server
Tillhandahåller en startpunkt för Sqoop-klienter.
Sqoop-klient
Interagerar med Sqoop-servern. Klienten kan finnas på valfri nod, förutsatt att klienten kan kommunicera med servern. Eftersom klienten bara behöver kommunicera med servern behöver du inte göra inställningar som med MapReduce.
Utmaningar för Sqoop lokalt
Här är några vanliga utmaningar med en lokal Sqoop-distribution:
- Det kan vara svårt att skala, beroende på maskinvaru- och datacenterkapacitet.
- Det kan inte enkelt skalas på begäran.
- När stödet upphör för åldrande infrastruktur kan du tvingas att ersätta och uppgradera.
- Det finns en brist på interna verktyg att tillhandahålla:
- Kostnadstransparens
- Övervakning
- DevOps
- Automation
Att tänka på
- När du migrerar Sqoop till Azure måste du överväga dess anslutning om din datakälla förblir lokal. Du kan upprätta en VPN-anslutning via Internet mellan Azure och ditt befintliga lokala nätverk, eller så kan du använda Azure ExpressRoute för att upprätta en privat anslutning.
- När du migrerar Sqoop till Azure HDInsight bör du överväga din Sqoop-version. HDInsight stöder endast Sqoop1, så om du använder Sqoop2 i din lokala miljö måste du ersätta den med Sqoop1 i HDInsight eller hålla Sqoop2 oberoende.
- När du migrerar Sqoop till Azure Data Factory måste du överväga datafilformat. Data Factory stöder inte SequenceFile-formatet. Bristen på stöd kan vara ett problem om Sqoop-implementeringen importerar data i SequenceFile-format. Mer information finns i Filformat.
Migreringsmetod
Azure har flera migreringsmål för Apache Sqoop. Beroende på krav och produktfunktioner kan du välja mellan virtuella Azure IaaS-datorer (VM), Azure HDInsight och Azure Data Factory.
Här är ett beslutsdiagram för att välja ett migreringsmål:
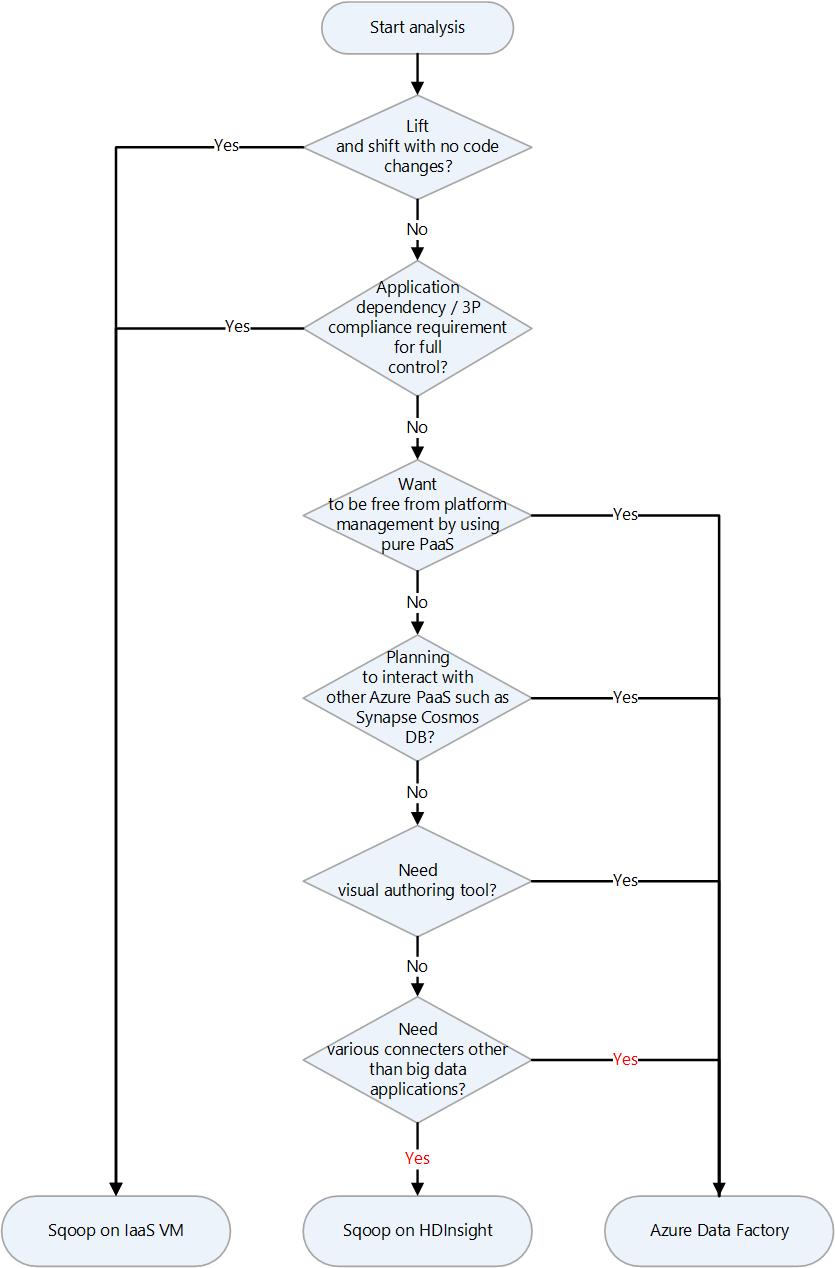
Migreringsmålen beskrivs i följande avsnitt:
Lyfta och flytta migrering till Azure IaaS
Om du väljer virtuella Azure IaaS-datorer som migreringsmål för din lokala Sqoop kan du utföra en lift and shift-migrering. Du använder samma version av Sqoop för att skapa en helt kontrollerbar miljö. Därför behöver du inte göra några ändringar i Sqoop-programvaran. Sqoop fungerar med ett Hadoop-kluster och migreras vanligtvis tillsammans med ett Hadoop-kluster. Följande artiklar är guider för en lift and shift-migrering av ett Hadoop-kluster. Välj den artikel som gäller för den tjänst som ska migreras.
Förberedelse för migrering
För att förbereda migreringen planerar du för migrering och upprättar en nätverksanslutning.
Planera en migrering
Samla in följande information för att förbereda migreringen av din lokala Sqoop. Informationen hjälper dig att fastställa storleken på den virtuella måldatorn och planera programvarukomponenterna och nätverkskonfigurationerna.
| Artikel | Bakgrund |
|---|---|
| Aktuell värdstorlek | Hämta information om processorn, minnet, disken och andra komponenter i värden eller den virtuella datorn där Sqoop-klienten eller servern körs. Du använder den här informationen för att uppskatta den basstorlek som krävs för din virtuella Azure-dator. |
| Värd- och programmått | Hämta information om resursanvändning (CPU, minne, disk och andra komponenter) för den dator som kör Sqoop-klienten och beräkna de resurser som faktiskt används. Om du använder mindre resurser än vad som har allokerats till värden kan du överväga att minska storleken när du migrerar till Azure. När du har identifierat den mängd resurser som krävs väljer du den typ av virtuell dator som du vill migrera till genom att referera till storleken på den virtuella Azure-datorn. |
| Sqoop-version | Kontrollera versionen av den lokala Sqoop för att avgöra vilken version av Sqoop som ska installeras på den virtuella Azure-datorn. Om du använder en distribution som Cloudera eller Hortonworks beror versionen av komponenten på vilken version av distributionen. |
| Köra jobb och skript | Identifiera de jobb som kör Sqoop och metoderna för att schemalägga dem. Jobben och metoderna är kandidater för migrering. |
| Databaser som ska anslutas | Identifiera de databaser som Sqoop ansluter till enligt import- och exportkommandona i Sqoop-jobben. När du har identifierat dem måste du se om du kan ansluta till dessa databaser när du har migrerat Sqoop till dina virtuella Azure-datorer. Om vissa av de databaser som du ansluter till fortfarande är lokala behöver du en nätverksanslutning mellan lokalt och Azure. Mer information finns i avsnittet Upprätta en nätverksanslutning . |
| Plugin-program | Identifiera de Sqoop-plugin-program som du använder och ta reda på om du kan migrera dem. |
| Hög tillgänglighet, affärskontinuitet, haveriberedskap | Avgör om de felsökningstekniker som du använder lokalt kan användas i Azure. Om du till exempel har en aktiv/väntelägeskonfiguration på två noder förbereder du två virtuella Azure-datorer för Sqoop-klienter som har samma konfiguration. Samma sak gäller när du konfigurerar haveriberedskap. |
Upprätta en nätverksanslutning
Om några av de databaser som du ansluter för att förbli lokala behöver du en nätverksanslutning mellan lokalt och Azure.
Det finns två huvudsakliga alternativ för att ansluta lokalt och Azure i ett privat nätverk:
VPN Gateway
Du kan använda Azure VPN Gateway för att skicka krypterad trafik mellan ditt virtuella Azure-nätverk och din lokala plats via det offentliga Internet. Den här tekniken är billig och lätt att konfigurera. Men på grund av den krypterade anslutningen via Internet garanteras inte kommunikationsbandbredden. Om du behöver garantera bandbredden bör du välja ExpressRoute, vilket är det andra alternativet. Mer information om VPN-alternativet finns i Vad är VPN Gateway? och VPN Gateway-design.
ExpressRoute
ExpressRoute kan ansluta ditt lokala nätverk till Azure eller Till Microsoft 365 med hjälp av en privat anslutning som tillhandahålls av en anslutningsleverantör. ExpressRoute går inte via det offentliga Internet, så det är säkrare, mer tillförlitligt och har mer konsekventa svarstider än anslutningar via Internet. Dessutom kan bandbreddsalternativen för den rad som du köper garantera stabila svarstider. Mer information finns i Vad är Azure ExpressRoute?.
Om dessa privata anslutningsmetoder inte uppfyller dina behov kan du betrakta Azure Data Factory som ett migreringsmål. Med den lokala integrationskörningen i Data Factory kan du överföra data från en lokal plats till Azure utan att behöva konfigurera ett privat nätverk.
Migrera data och inställningar
När du migrerar lokal Sqoop till virtuella Azure-datorer inkluderar du följande data och inställningar:
Sqoop-konfigurationsfiler: Det beror på din miljö, men följande filer ingår ofta:
sqoop-site.xmlsqoop-env.xmlpassword-fileoraoop-site.xml, om du använder Oraoop
Sparade jobb: Om du sparade jobb i Sqoop-metaarkivet
sqoop job --createmed hjälp av kommandot måste du migrera dem. Metaarkivets sparandemål definieras i sqoop-site.xml. Om det delade metaarkivet inte har angetts letar du efter de sparade jobben i .sqoop-underkatalogen för hemkatalogen för användaren som kör metaarkivet.Du kan använda följande kommandon för att se information om de sparade jobben.
Hämta listan över sparade jobb:
sqoop job --listVisa parametrar för sparade jobb
sqoop job --show <job-id>
Skript: Om du har skriptfiler som kör Sqoop måste du migrera dem.
Scheduler: Om du schemalägger körningen av Sqoop måste du identifiera dess schemaläggare, till exempel ett Linux cron-jobb eller ett jobbhanteringsverktyg. Sedan måste du överväga om schemaläggaren kan migreras till Azure.
Plugin-program: Om du använder anpassade plugin-program i Sqoop, till exempel en anslutning till en extern databas, måste du migrera dem. Om du har skapat en korrigeringsfil tillämpar du korrigeringen på den migrerade Sqoop.
Migrera till HDInsight
HDInsight paketar Apache Hadoop-komponenter och HDInsight-plattformen i ett paket som distribueras i ett kluster. I stället för att migrera själva Sqoop till Azure är det mer typiskt att köra Sqoop på ett HDInsight-kluster. Mer information om hur du använder HDInsight för att köra ramverk med öppen källkod, till exempel Hadoop och Spark, finns i Vad är Azure HDInsight? och guide till migrering av stordataarbetsbelastningar till Azure HDInsight.
Se följande artiklar för komponentversionerna i HDInsight.
Migrera till Data Factory
Azure Data Factory är en fullständigt hanterad, serverlös dataintegreringstjänst. Den kan skalas på begäran enligt faktorer som datavolym. Det har ett GUI för intuitiv redigering och utveckling med hjälp av Python-, .NET- och Azure Resource Manager-mallar (ARM-mallar).
Anslutning till datakällor
Se lämplig artikel för en lista över standard-Sqoop-anslutningsappar:
Data Factory har ett stort antal anslutningsappar. Mer information finns i Översikt över Azure Data Factory och Azure Synapse Analytics-anslutningsappen.
Följande tabell är ett exempel som visar de Data Factory-anslutningsappar som ska användas för Sqoop1 version 1.4.7 och Sqoop2 version 1.99.7. Se till att läsa den senaste dokumentationen eftersom listan över versioner som stöds kan ändras.
| Sqoop1 – 1.4.7 | Sqoop2 – 1.99.7 | Data Factory | Att tänka på |
|---|---|---|---|
| MySQL JDBC-anslutningsprogram | Allmänt JDBC-anslutningsprogram | MySQL, Azure Database for MySQL | |
| MySQL Direct Connector | Saknas | Saknas | Direct Connector använder mysqldump för att mata in och mata ut data utan att gå via JDBC. Metoden är annorlunda i Data Factory, men MySQL-anslutningsappen kan användas i stället. |
| Microsoft SQL Connector | Allmänt JDBC-anslutningsprogram | SQL Server, Azure SQL Database, Azure SQL Managed Instance | |
| PostgreSQL-anslutningsprogram | PostgreSQL, allmän JDBC-anslutning | Azure Database for PostgreSQL | |
| PostgreSQL Direct Connector | Saknas | Saknas | Direct Connector går inte igenom JDBC och använder kommandot COPY för att mata in och mata ut data. Metoden är annorlunda i Data Factory, men PostgreSQL-anslutningsappen kan användas i stället. |
| pg_bulkload-anslutningsprogram | Saknas | Saknas | Läs in i PostgreSQL med hjälp av pg_bulkload. Metoden är annorlunda i Data Factory, men PostgreSQL-anslutningsappen kan användas i stället. |
| Netezza Connector | Allmänt JDBC-anslutningsprogram | Netteza | |
| Data connector för Oracle och Hadoop | Allmänt JDBC-anslutningsprogram | Oracle | |
| Ej tillämpligt | FTP-anslutningsprogram | FTP | |
| Ej tillämpligt | SFTP-anslutningsprogram | SFTP | |
| Ej tillämpligt | Kafka-anslutningsprogram | Ej tillämpligt | Data Factory kan inte ansluta direkt till Kafka. Överväg att använda Spark Streaming som Azure Databricks eller HDInsight för att ansluta till Kafka. |
| Ej tillämpligt | Kite Connector | Ej tillämpligt | Data Factory kan inte ansluta direkt till Kite. |
| HDFS | HDFS | HDFS | Data Factory stöder HDFS som källa, men inte som mottagare. |
Ansluta till databaser lokalt
Om du efter att ha migrerat Sqoop till Data Factory fortfarande behöver kopiera data mellan ett datalager i ditt lokala nätverk och Azure bör du överväga att använda följande metoder:
Lokal Integration Runtime
Om du försöker integrera data i en privat nätverksmiljö där det inte finns någon direkt kommunikationsväg från den offentliga molnmiljön kan du göra följande för att förbättra säkerheten:
- Installera en lokalt installerad integrationskörning i den lokala miljön, antingen i den interna brandväggen eller i det virtuella privata nätverket.
- Skapa en HTTPS-baserad utgående anslutning från den lokalt installerade integrationskörningen till Azure för att upprätta en anslutning för dataflytt.
Lokalt installerad integrationskörning stöds endast i Windows. Du kan också uppnå skalbarhet och hög tillgänglighet genom att installera och associera lokalt installerade integrationskörningar på flera datorer. Lokalt installerad integrationskörning ansvarar också för att skicka datatransformeringsaktiviteter till resurser som inte är lokala eller i det virtuella Azure-nätverket.
Information om hur du konfigurerar lokalt installerad integrationskörning finns i Skapa och konfigurera en lokalt installerad integrationskörning.
Hanterat virtuellt nätverk med hjälp av en privat slutpunkt
Om du har en privat anslutning mellan lokalt och Azure (till exempel ExpressRoute eller VPN Gateway) kan du använda hanterat virtuellt nätverk och en privat slutpunkt i Data Factory för att upprätta en privat anslutning till dina lokala databaser. Du kan använda virtuella nätverk för att vidarebefordra trafik till dina lokala resurser, som du ser i följande diagram, för att få åtkomst till dina lokala resurser utan att gå via Internet.

Ladda ned en Visio-fil med den här arkitekturen.
Mer information finns i Självstudie: Så här får du åtkomst till lokal SQL Server från Data Factory Managed VNet med privat slutpunkt.
Nätverksalternativ
Data Factory har två nätverksalternativ:
Båda skapar ett privat nätverk och hjälper till att skydda processen för dataintegrering. De kan användas samtidigt.
Hanterat virtuellt nätverk
Du kan distribuera integreringskörningen, som är Data Factory-körningen, i ett hanterat virtuellt nätverk. Genom att distribuera en privat slutpunkt, till exempel ett datalager som ansluter till det hanterade virtuella nätverket, kan du förbättra säkerheten för dataintegrering i ett stängt privat nätverk.

Ladda ned en Visio-fil med den här arkitekturen.
Mer information finns i Hanterat virtuellt Azure Data Factory-nätverk.
Private Link
Du kan använda Azure Private Link för Azure Data Factory för att ansluta till Data Factory.

Ladda ned en Visio-fil med den här arkitekturen.
Mer information finns i Vad är en privat slutpunkt? och Private Link-dokumentation.
Prestanda för datakopiering
Sqoop förbättrar dataöverföringsprestanda med hjälp av MapReduce för parallell bearbetning. När du har migrerat Sqoop kan Data Factory justera prestanda och skalbarhet för scenarier som utför storskaliga datamigreringar.
En dataintegreringsenhet (DIU) är en Data Factory-prestandaenhet. Det är en kombination av processor-, minnes- och nätverksresursallokering. Data Factory kan justera upp till 256 DIU:er för kopieringsaktiviteter som använder Azure-integreringskörningen. Mer information finns i Dataintegreringsenheter.
Om du använder lokalt installerad integrationskörning kan du förbättra prestanda genom att skala den dator som är värd för den lokalt installerade integrationskörningen. Den maximala utskalningen är fyra noder.
Mer information om hur du gör justeringar för att uppnå önskad prestanda finns i guiden Kopiera aktivitetsprestanda och skalbarhet.
Tillämpa SQL
Sqoop kan importera resultatuppsättningen för en SQL-fråga, som du ser i det här exemplet:
$ sqoop import \
--query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \
--split-by a.id --target-dir /user/foo/joinresults
Data Factory kan också fråga databasen och kopiera resultatuppsättningen:
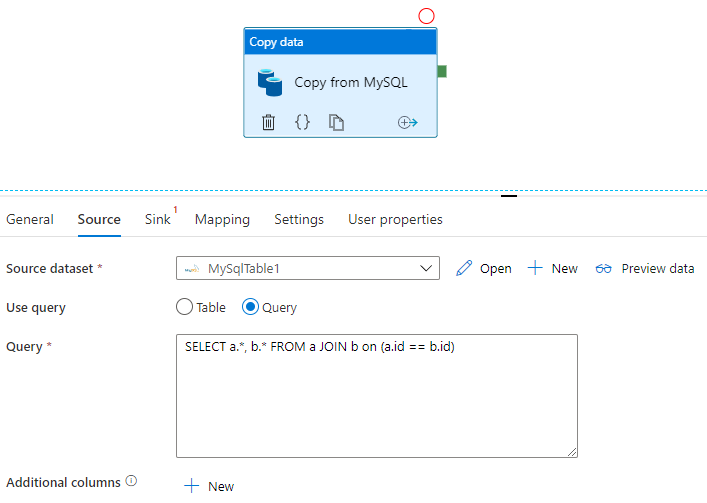
Se Kopiera aktivitetsegenskaper för ett exempel som hämtar resultatuppsättningen för en fråga i en MySQL-databas.
Dataomvandling
Både Data Factory och HDInsight kan utföra olika datatransformeringsaktiviteter.
Transformera data med hjälp av Data Factory-aktiviteter
Data Factory kan utföra en mängd olika datatransformeringsaktiviteter, till exempel dataflöde och dataomvandling. För båda definierar du omvandlingarna med hjälp av ett visuellt användargränssnitt. Du kan också använda aktiviteter för olika Hadoop-komponenter i HDInsight, Databricks, lagrade procedurer och andra anpassade aktiviteter. Överväg att använda dessa aktiviteter när du migrerar Sqoop och vill inkludera datatransformeringar i processen. Mer information finns i Transformera data i Azure Data Factory .
Transformera data med hjälp av HDInsight-aktiviteter
De olika HDInsight-aktiviteterna i en Azure Data Factory-pipeline, inklusive Hive, Pig, MapReduce, Streaming och Spark, kan köra program och frågor på antingen ditt eget kluster eller på ett HDInsight-kluster på begäran. Om du migrerar en Sqoop-implementering som använder datatransformeringslogik i Hadoop-ekosystemet är det enkelt att migrera omvandlingarna till HDInsight-aktiviteter. Mer information finns i följande artiklar.
- Transformera data med Hadoop Hive-aktivitet i Azure Data Factory eller Synapse Analytics
- Transformera data med hjälp av Hadoop MapReduce-aktivitet i Azure Data Factory eller Synapse Analytics
- Transformera data med Hadoop Pig-aktivitet i Azure Data Factory eller Synapse Analytics
- Transformera data med Spark-aktivitet i Azure Data Factory och Synapse Analytics
- Transformera data med hadoop-strömningsaktivitet i Azure Data Factory eller Synapse Analytics
File format
Sqoop stöder text, SequenceFile och Avro som filformat när data importeras till HDFS. Data Factory stöder inte HDFS som en datamottagare, men den använder Azure Data Lake Storage eller Azure Blob Storage som fillagring. Mer information om HDFS-migrering finns i Apache HDFS-migrering.
De format som stöds för att Data Factory ska kunna skriva till fillagring är text, binär, Avro, JSON, ORC och Parquet, men inte SequenceFile. Du kan använda en aktivitet som Spark för att konvertera en fil till SequenceFile med hjälp saveAsSequenceFileav :
data.saveAsSequenceFile(<path>)
Schemaläggning av jobb
Sqoop tillhandahåller inte scheduler-funktioner. Om du kör Sqoop-jobb på en schemaläggare måste du migrera den funktionen till Data Factory. Data Factory kan använda utlösare för att schemalägga körningen av datapipelinen. Välj en Data Factory-utlösare enligt din befintliga schemaläggningskonfiguration. Här är typerna av utlösare.
- Schemautlösare: En schemautlösare kör pipelinen enligt ett schema för väggklockan.
- Utlösare för rullande fönster: En utlösare för rullande fönster körs regelbundet från en angiven starttid samtidigt som dess tillstånd bibehålls.
- Händelsebaserad utlösare: En händelsebaserad utlösare utlöser pipelinen som svar på händelsen. Det finns två typer av händelsebaserade utlösare:
- Utlösare för lagringshändelse: En utlösare för lagringshändelser utlöser pipelinen som svar på en lagringshändelse, till exempel att skapa, ta bort eller skriva till en fil.
- Anpassad händelseutlösare: En utlösare för anpassad händelse utlöser pipelinen som svar på en händelse som skickas till ett anpassat ämne i ett händelserutnät. Information om anpassade ämnen finns i Anpassade ämnen i Azure Event Grid.
Mer information om utlösare finns i Pipelinekörning och utlösare i Azure Data Factory eller Azure Synapse Analytics.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Namrata Maheshwary | Senior Cloud Solution Architect
- Raja N | Direktör, kundframgång
- Hideo Takagi | Molnlösningsarkitekt
- Ram Yerrabotu | Senior Cloud Solution Architect
Övriga medarbetare:
- Ram Baskaran | Senior Cloud Solution Architect
- Jason Bouska | Senior programvarutekniker
- Eugene Chung | Senior Cloud Solution Architect
- Pawan Hosatti | Senior Cloud Solution Architect – Teknik
- Daman Kaur | Molnlösningsarkitekt
- Danny Liu | Senior Cloud Solution Architect – Teknik
- Jose Mendez Senior Cloud Solution Architect
- Ben Sadeghi | Senior Specialist
- Sunil Sattiraju | Senior Cloud Solution Architect
- Amanjeet Singh | Programhanteraren för huvudnamn
- Nagaraj Seeplapudur Venkatesan | Senior Cloud Solution Architect – Teknik
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
Introduktion till Azure-produkter
- Introduktion till Azure Data Lake Storage Gen2
- Vad är Apache Spark i Azure HDInsight?
- Vad är Apache Hadoop i Azure HDInsight?
- Vad är Apache HBase i Azure HDInsight?
- Vad är Apache Kafka i Azure HDInsight?
- Översikt över företagssäkerhet i Azure HDInsight
Produktreferens för Azure
- Microsoft Entra-dokumentation.
- Dokumentation om Azure Cosmos DB
- Dokumentation om Azure Data Factory
- Dokumentation om Azure Databricks
- Dokumentation om Azure Event Hubs
- Azure Functions-dokumentation
- Dokumentation om Azure HDInsight
- Dokumentation om Datastyrning i Microsoft Purview
- Dokumentation om Azure Stream Analytics
- Azure Synapse Analytics
Övrigt
- Enterprise Security Package för Azure HDInsight
- Utveckla Java MapReduce-program för Apache Hadoop i HDInsight
- Använda Apache Sqoop med Hadoop i HDInsight
- Översikt över Apache Spark Streaming
- Självstudier för strukturerad direktuppspelning
- Använda Azure Event Hubs från Apache Kafka-program